






快速排序
基本思想:
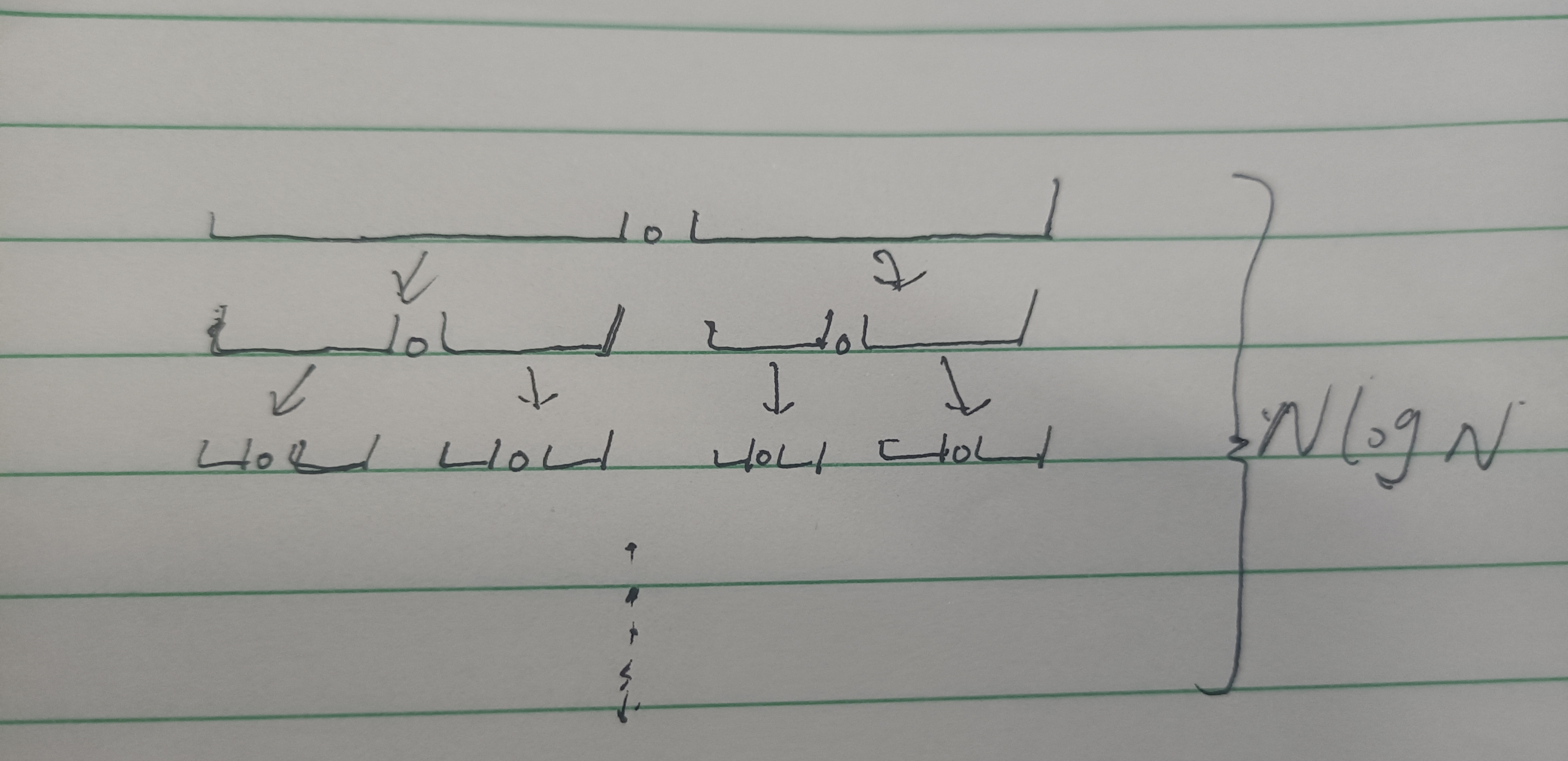
采用“分治”的思想,对于一组数据,选择一个基准元素(base),通常选择第一个或最后一个元素,通过第一轮扫描,比base小的元素都在base左边,比base大的元素都在base右边,再有同样的方法递归排序这两部分,直到序列中所有数据均有序为止。
也就是说,每一次划分区域时,基准元素base 一定会处在正确的位置,一个个的确定每一个元素位置的值。
void qSortArray(int array[], int start, int last)
{
int low = start;
int high = last;
if (low < high)
{
while (low < high)
{
while (array[low] <= array[start] && low < last)
{
low++;//满足小于基准的条件,指针右移
}
while (array[high] >= array[start] && high > start)
{
high--;//满足大于基准的条件,指针左移
}
if (low < high)
{
swap(array[low], array[high]);//交换两个不满足条件的元素
}
else
{
break;
}
}
swap(array[start], array[high]);//插入基准元素
qSortArray(array, start, high - 1);
qSortArray(array, high + 1, last);
}
}
但是,当数据中的重复元素变多的时候,快排的时间复杂度就会逐渐退化,当数据全部相同时,其时间复杂度为O(n^2);
所以需要进行调整,在基础快排中,我们将数据根据key大小划分为两个区间,在左区间上<= key,在右区间上大于key
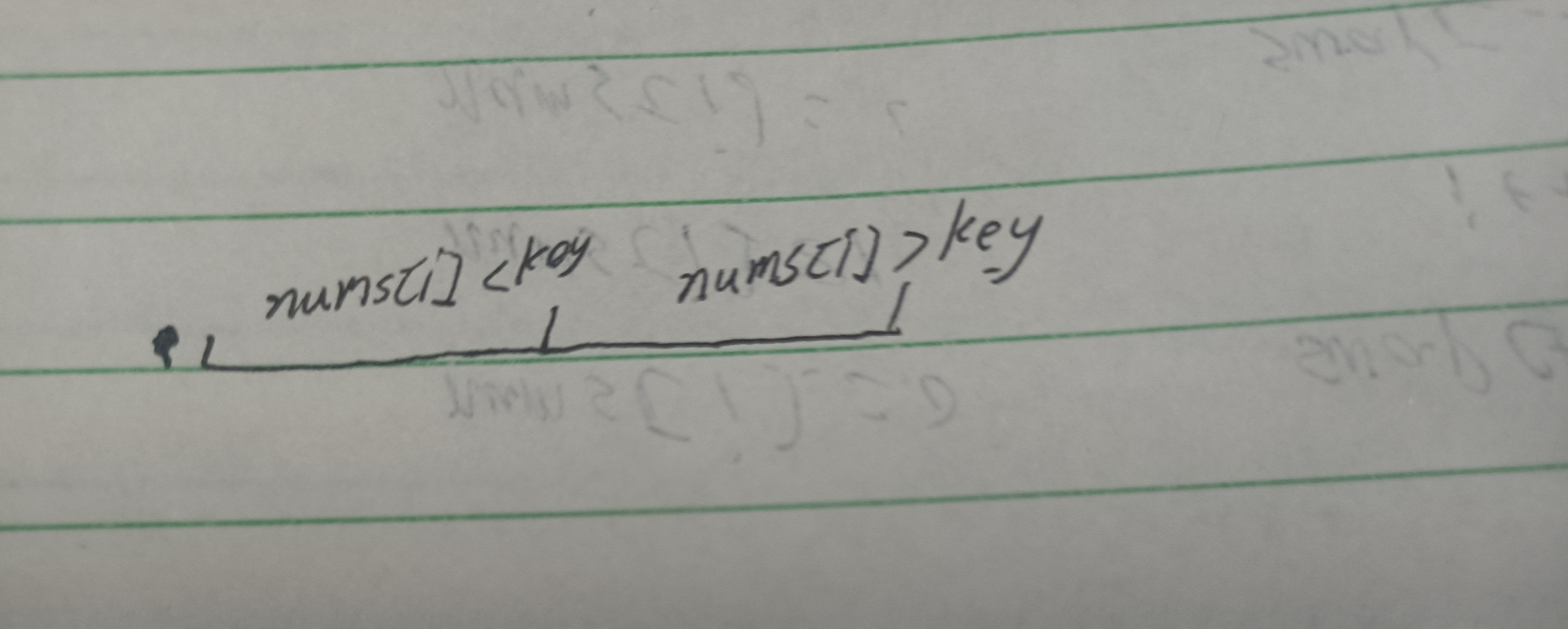
调整后,我们将其划分为三个区间,在中间留下了一个 =key的区间。
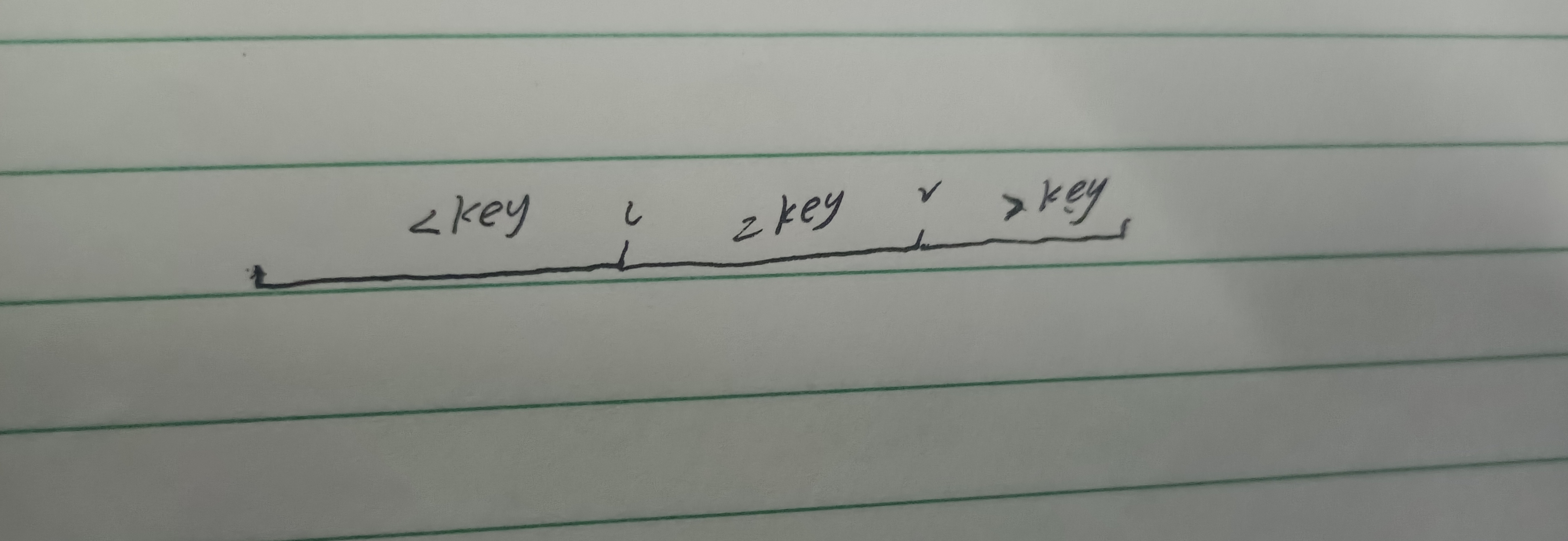
可知,以 l ,r 为分界线,划分出三个区间
[0,l] 区间 ,nums[i] < key
[l+1,r-1] 区间上, nums[i]==key
[r,n]上,nums[i]>key
所以,在 i 逐步遍历数组时,我们可以做如下操作
当nums[i]<key ,swap(nums[++l],nums[i++])
当nums[i]==key , i++
当nums[i]>key , swap(nums[–r],nums[i])
当此循环结束后,数组就会被划分为三个区间。
可以看到,每一次的数据划分后, 中间的==key的区间一定处于正确的位置,每一次划分都能确定一片区间,最后就能准确的排序整个数组。
int random(int l,int r)
{
int rd=rand();
return rd%(r-l+1)+l;
}
void quicksort(vector<int>& nums,int l,int r)
{
if(l>=r) return;
int key=nums[random(l,r)];
int i=l;
int left=l-1;
int right=r+1;
while(i<right)
{
if(nums[i]<key) swap(nums[++left],nums[i++]);
else if(nums[i]==key) i++;
else swap(nums[--right],nums[i]);
}
quicksort(nums,l,left);
quicksort(nums,right,r);
}
vector<int> sortArray(vector<int>& nums) {
srand(time(0));
quicksort(nums,0,nums.size()-1);
return nums;
}
当数据元素全部重复时,只需要一次遍历,就可以了。
同时,可以用快速选择算法解决Topk问题
链接: 最小k个数
链接: 数组中的第 K 个最大元素















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









