







 本文详细介绍了Dart VM的运行模式,包括从快照运行、AppJIT和AppAOT。重点阐述了Dart源代码的编译过程,如内核二进制文件的生成、类信息的惰性加载以及未优化和优化编译器的工作原理。此外,还讨论了内联缓存、动态调用的优化以及AOT编译的优势,如快速启动和性能提升。
本文详细介绍了Dart VM的运行模式,包括从快照运行、AppJIT和AppAOT。重点阐述了Dart源代码的编译过程,如内核二进制文件的生成、类信息的惰性加载以及未优化和优化编译器的工作原理。此外,还讨论了内联缓存、动态调用的优化以及AOT编译的优势,如快速启动和性能提升。

这里需要注意,该 Flutter 工具不处理 Dart 本身的解析, 相反它会生成另一个持久进程 frontend_server,它本质上是围绕 CFE 和一些 Flutter 特定的 Kernel-to-Kernel 转换的封装。
frontend_server 将 Dart 源代码编译为内核文件, 然后 flutter 将其发送到设备, 当开发人员请求热重载时 frontend_server 开始发挥作用:在这种情况下 frontend_server 可以重用先前编译中的 CFE 状态,并重新编译实际更改的库。
一旦内核二进制文件加载到 VM 中,它就会被解析以创建代表各种程序实体的对象,然而这个过程是惰性完成的:首先只加载关于库和类的基本信息,源自内核二进制文件的每个实体都保留一个指向二进制文件的指针,以便以后可以根据需要加载更多信息。

每当我们引用 VM 内部分配的对象时,我们都会使用 Untagged 前缀,因为这遵循了 VM 自己的命名约定:内部 VM 对象的布局由 C++ 类定义,名称以 Untagged头文件
runtime/vm/raw_object.h开头。例如dart::UntaggedClass是描述一个 Dart 类 VM 对象,dart::UntaggedField是一个 VM 对象
只有在运行时需要它时(例如查找类成员、分配实例等),有关类的信息才会完全反序列化,在这个阶段,类成员会从内核二进制文件中读取,然而在此阶段不会反序列化完整的函数体,只会反序列化它们的签名。

此时 methods 在运行时可以被成功解析和调用,因为已经从内核二进制文件加载了足够的信息,例如它可以解析和调用 main 库中的函数。
package:kernel/ast.dart定义了描述内核 AST 的类;package:front_end处理解析 Dart 源代码并从中构建内核 AST。dart::kernel::KernelLoader::LoadEntireProgram是将内核 AST 反序列化为相应 VM 对象的入口点;pkg/vm/bin/kernel_service.dart实现了内核服务隔离,runtime/vm/kernel_isolate.cc将 Dart 实现粘合到 VM 的其余部分;package:vm承载大多数基于内核的 VM 特定功能,例如各种内核到内核的转换;由于历史原因一些特定于 VM 的转换仍然存在于package:kernel中。
最初所有的函数都会有一个占位符,而不是它们的主体的实际可执行代码:它们指向 LazyCompileStub,它只是要求运行时系统为当前函数生成可执行代码,然后 tail-calls 这个新生成的代码。

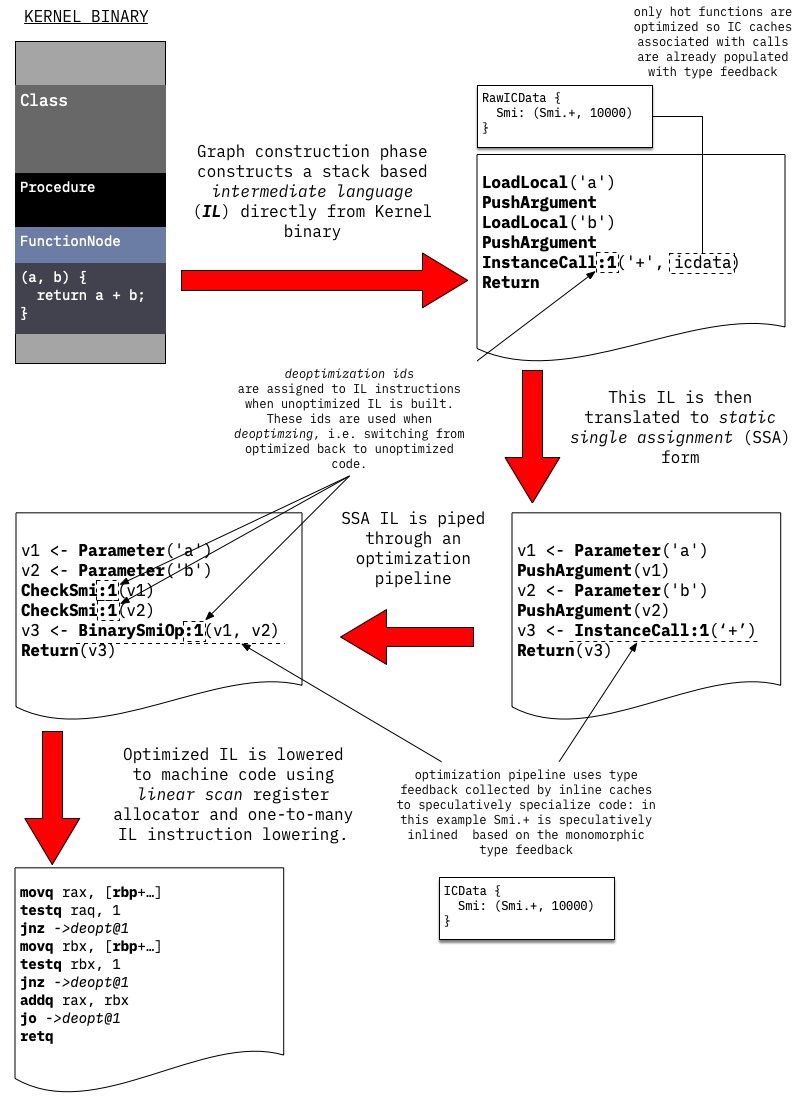
第一次编译函数时,是通过未优化编译器完成的。

未优化编译器分两遍生成机器代码:
- 1、遍历函数体的序列化 AST 以生成函数体的控制流图( CFG ),CFG 由填充有中间语言( IL ) 指令的基本块组成。在此阶段使用的 IL 指令类似于基于堆栈的虚拟机的指令:它们从堆栈中获取操作数,执行操作,然后将结果推送到同一堆栈。
实际上并非所有函数都具有实际的 Dart / Kernel AST 主体,例如在 C++ 中定义的本地函数或由 Dart VM 生成的人工
tear-off函数,在这些情况下,IL 只是凭空创建,而不是从内核 AST 生成。
- 2、生成的 CFG 使用一对多的底层 IL 指令直接编译为机器代码:每个 IL 指令扩展为多个机器语言指令。
在此阶段没有执行任何优化,未优化编译器的主要目标是快速生成可执行代码。
这也意味着:未优化的编译器不会尝试静态解析内核二进制文件中未解析的任何调用,VM 当前不使用基于虚拟表或接口表的调度,而是使用内联缓存实现动态调用。
内联缓存的原始实现,实际上是修补函数的 native 代码,因此得名内联缓存,内联缓存的想法可以追溯到 Smalltalk-80,请参阅 Smalltalk-80 系统的高效实现。
内联缓存背后的核心思想,是在特定的调用点中缓存方法解析的结果,VM 使用的内联缓存机制包括:
-
一个调用特定的缓存(
dart::UntaggedICData),它将接收者的类映射到一个方法,如果接收者是匹配的类,则应该调用该方法,缓存还存储一些辅助信息,例如调用频率计数器,用于跟踪给定类在此调用点上出现的频率; -
一个共享查找 stub ,它实现了方法调用的快速路径。这个 stub 搜索给定的缓存,以查看它是否包含与接收者的类匹配的条目。如果找到该条目,则 stub 将增加频率计数器和
tail-calls用缓存方法。否则 stub 将调用一个运行时系统助手来实现方法解析逻辑。如果方法解析成功,则缓存将被更新,后续调用将不需要进入运行时系统。
如下图所示,展示了与 animal.toFace() 调用关联的内联缓存的结构和状态,该缓存使用 Dog 的实例执行了两次,使用 Cat 的实例执行了一次C。

未优化的编译器本身足以执行任何 Dart 代码,然而它产生的代码相当慢,这就是为什么 VM 还实现了自适应优化编译管道的原因,自适应优化背后的想法是:使用运行程序的执行配置文件来驱动优化决策。
当未优化的代码运行时,它会收集以下信息:
- 如上所述,内联缓存收集有关在调用点观察到的接收器类型的信息;
- 函数和函数内的基本块相关联的执行计数器跟踪代码的热点区域;
当与函数关联的执行计数器达到一定阈值时,该函数被提交给后台优化编译器进行优化。
优化编译的启动方式与非优化编译的启动方式相同:通过遍历序列化内核 AST ,为正在优化的函数构建未优化的 IL。
然而不是直接将 IL 处理为机器代码,而是基于表单的优化 IL, 优化编译器继续将未优化的 IL 转换为静态单赋值(SSA) ,然后基于 SSA 的 IL 根据收集的类型反馈进行专业化的推测,并通过一系列Dart 的特定优化,例如:
- 内联(inlining);
- 范围分析(range analysis);
- 类型传播( type propagation);
- 代理选择(representation selection);
- 存储加载和加载转发(store-to-load and load-to-load forwarding);
- 全局值编号(global value numbering);
- 分配下沉(,allocation sinking)等,;
最后使用线性扫描寄存器和简单的一对多降低 IL 指令,将优化的 IL 转化为机器代码。
编译完成后,后台编译器会请求 mutator 线程进入安全点并将优化的代码附加到函数中。
广义上讲,当与线程相关联的状态(例如堆栈帧、堆等)一致,并且可以在不受线程本身中断的情况下访问或修改时,托管环境(虚拟机)中的线程被认为处于安全点。通常这意味着线程要么暂停,要么正在执行托管环境之外一些代码,例如运行非托管 native 代码。
下次调用此函数时, 它将使用优化的代码。 某些函数包含非常长的运行循环,对于那些函数,在函数仍在运行时,将执行从未优化代码切换到优化代码是有意义的。
这个过程被称为堆栈替换( OSR ),它的名字是因为:一个函数版本的堆栈帧被透明地替换为同一函数的另一个版本的堆栈帧。
编译器源代码位于
runtime/vm/compiler目录中;编译管道入口点是dart::CompileParsedFunctionHelper::Compile;IL 在runtime/vm/compiler/backend/il.h中定义;内核到 IL 的转换从dart::kernel::StreamingFlowGraphBuilder::BuildGraph开始,该函数还处理各种人工函数的 IL 构建;当InlineCacheMissHandler处理 IC 的未命中,dart::compiler::StubCodeCompiler::GenerateNArgsCheckInlineCacheStub为内联缓存存根生成机器代码;runtime/vm/compiler/compiler_pass.cc定义了优化编译器传递及其顺序;dart::JitCallSpecializer大多数基于类型反馈的专业化。
需要强调的是,优化编译器生成的代码,是在基于应用程序执行配置文件的专业推测下假设的。
例如,一个动态调用点只观察到一个 C 类的实例作为一个接收方,它将被转换成一个可以直接调用的对象,并通过检查来验证接收方是否有一个预期的 C 类。然而这些假设可能会在程序执行期间被违反:
void printAnimal(obj) {
print(‘Animal {’);
print(’ ${obj.toString()}’);
print(’}’);
}
// Call printAnimal(…) a lot of times with an intance of Cat.
// As a result printAnimal(…) will be optimized under the
// assumption that obj is always a Cat.
for (var i = 0; i < 50000; i++)
printAnimal(Cat());
// Now call printAnimal(…) with a Dog - optimized version
// can not handle such an object, because it was
// compiled under assumption that obj is always a Cat.
// This leads to deoptimization.
printAnimal(Dog());
每当代码正在做一些假设性优化时,它可能会在执行过程中被违反,所以它需要保证当出现违反假设的情况下,可以恢复原本的执行。
这个恢复过程又被称为去优化:当优化版本遇到它无法处理的情况时,它只是将执行转移到未优化函数的匹配点,并在那里继续执行,函数的未优化版本不做任何假设,可以处理所有可能的输入。
VM 通常在去优化后丢弃函数的优化版本,而之后再次重新优化它时,会 使用更新的类型反馈。
VM 有两种方式保护编译器做出的推测性假设:
- 内联检查(例如CheckSmi,CheckClassIL 指令)验证假设在编译器做出此假设的使用站点是否成立。例如将动态调用转换为直接调用时,编译器会在直接调用之前添加这些检查。
- Global guards 会运行时丢弃优化代码,当依赖的内容变化时。例如优化编译器可能会观察到某个
C类从未被扩展,并在类型传播过程中使用此信息。然而随后的动态代码加载或类终结可能会引入一个子类 C。此时运行时需要查找并丢弃在C没有子类的假设下编译的所有优化代码。运行时可能会在执行堆栈上找到一些现在无效的优化代码,在这种情况下受影响的帧将被标记为“去优化”,并在执行返回时取消优化。这种去优化被称为惰性去优化: 因为它被延迟执行,直到控制返回到优化的代码。
去优化器机制在
runtime/vm/deopt_instructions.cc中,它本质上是一个解优化指令的微型解释器,它描述了如何从优化代码的状态,重建未优化代码的所需状态。去优化指令由dart::CompilerDeoptInfo::CreateDeoptInfo在编译期间针对优化代码中的每个潜在"去优化"位置生成。
从快照运行
VM 能够将 isolate 的堆,或位于堆中的更精确地序列化对象的图称为二进制快照,然后可以使用快照在启动 VM isolates 时重新创建相同的状态。

快照的格式是底层的,并且针对快速启动进行了优化:它本质上是一个要创建的对象列表以及有关如何将它们连接在一起的说明。
快照背后的最初想法:VM 无需解析 Dart 源和逐步创建内部 VM 数据结构,而是可以将所有必要的
《Android学习笔记总结+最新移动架构视频+大厂安卓面试真题+项目实战源码讲义》
【docs.qq.com/doc/DSkNLaERkbnFoS0ZF】 完整内容开源分享
数据结构从快照中快速解包出来,然后进行 isolate up。
快照的想法源于 Smalltalk 图像,而后者又受到 Alan Kay 的硕士论文的启发。Dart VM 使用集群序列化格式,这类似于 《Parcels: a Fast and Feature-Rich Binary Deployment Technology》和《Clustered serialization with Fuel》论文中描述的技术。
最初快照不包括机器代码,但是后来在开发 AOT 编译器时添加了此功能。开发 AOT 编译器和带有代码的快照的动机:是为了允许在由于平台级别限制而无法进行 JIT 的平台上使用 VM。
带有代码的快照的工作方式几乎与普通快照相同,但有细微差别:它们包含一个代码部分,这部分与快照的其余部分不同,它不需要反序列化,此代码部分的放置方式允许它在映射到内存后直接成为堆的一部分。
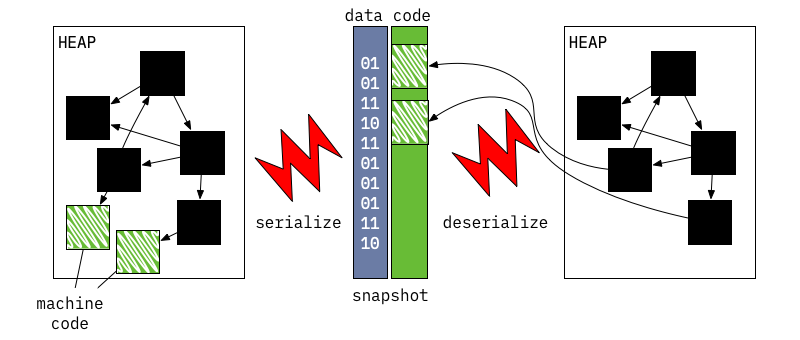
runtime/vm/clustered_snapshot.cc处理快照的序列化和反序列化; API 函数Dart_CreateXyzSnapshot[AsAssembly]负责写出堆的快照(例如Dart_CreateAppJITSnapshotAsBlobs和Dart_CreateAppAOTSnapshotAssembly);Dart_CreateIsolateGroup可选择获取快照数据以启动isolate。
从 AppJIT 快照运行
引入 AppJIT 快照是为了减少大型 Dart 应用程序的 JIT 预热时间,例如 dartanalyzer 或 dart2js。当这些工具用于小型项目时,它们花在实际工作上的时间与 VM 花在 JIT 编译这些应用程序上的时间一样多。
AppJIT 快照可以解决这个问题:可以使用一些模拟训练数据在 VM 上运行应用程序,然后将所有生成的代码和 VM 内部数据结构序列化为 AppJIT 快照,然后分发此快照,而不是以源(或内核二进制)形式分发应用程序。
从这个快照开始的 VM 仍然可以 JIT。

从 AppAOT 快照运行
AOT 快照最初是为无法进行 JIT 编译的平台引入的,但它们也可用于快速启动和更低性能损失的情况。
关于 JIT 和 AOT 的性能特征比较通常存在很多混淆的概念:
- JIT 可以访问正在运行的应用程序的本地类型信息和执行配置文件,但是它必须为预热付出代价;
- AOT 可以在全局范围内推断和证明各种属性(为此它必须支付编译时间),没有关于程序实际执行方式的信息, 但 AOT 编译代码几乎立即达到其峰值性能,几乎没有任何预热.
目前 Dart VM JIT 的峰值性能最好,而 Dart VM AOT 的启动时间最好。
无法进行 JIT 意味着:
- 1、AOT 快照必须包含可以在应用程序执行期间调用的每个函数的可执行代码;
- 2、可执行代码不得依赖任何可能在执行过程中会被违反的推测性假设;
为了满足这些要求,AOT 编译过程会进行全局静态分析(类型流分析或TFA),以确定应用程序的哪些部分可以从已知的入口点集合、分配哪些类的实例,以及类型如何在程序运转。
所有这些分析都是保守的:意味着它们在没办法和 JIT 一样执行更多的优化执行,因为它总是可以反优化为未优化的代码以实现正确的行为。
所有可能用到的函数都会被编译为本机代码,无需任何推测优化,而类型流信息仍然用专门代码处理(例如去虚拟化调用)。
编译完所有函数后,就可以拍摄堆的快照,然后就可以使用预编译运行时运行生成的快照,这是 Dart VM 的一种特殊变体,它不包括 JIT 和动态代码加载工具等组件。
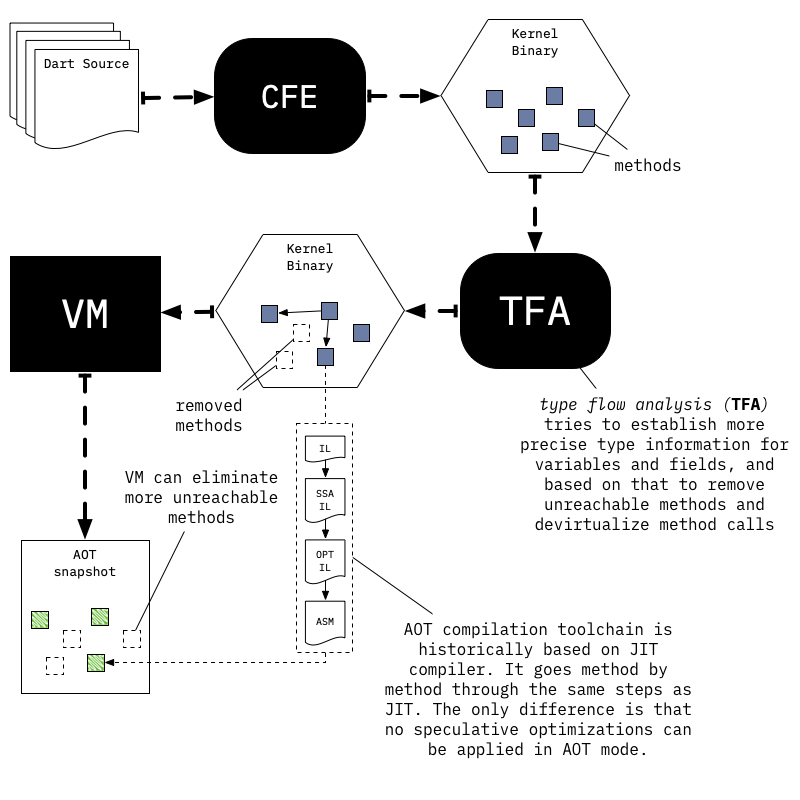
package:vm/transformations/type_flow/transformer.dart是基于 TFA 结果的类型流分析和转换的入口点;dart::Precompiler::DoCompileAll是 VM 中 AOT 编译循环的入口点。
可切换调用
即使进行了全局和局部分析,AOT 编译代码仍可能包含无法去虚拟化的调用(意味着它们无法静态解析)。为了补偿这种 AOT 编译代码,运行时使用 JIT 中的内联缓存技术扩展,此扩展版本称为 switchable calls。
JIT 部分已经描述了与调用点关联的每个内联缓存由两部分组成:
- 缓存对象(由
dart::UntaggedICData实例表示); - 要调用的本地代码块(例如
InlineCacheStub);
在 JIT 模式下,运行时只会更新缓存本身,但是在 AOT 运行时可以根据内联缓存的状态选择替换缓存和要调用的本机代码。

最初所有动态调用都以未链接状态开始,当达到第一次调用点 SwitchableCallMissStub 被调用时,它只是调用到运行帮手 DRT_SwitchableCallMiss 链接该调用位置。
之后 DRT_SwitchableCallMiss 会尝试将呼叫点转换为单态状态,在这种状态下调用点变成了直接调用,它通过一个特殊的入口点进入方法,该入口点验证接收者是否具有预期的类。

在上面的示例中,我们假设 obj.method() 第一次执行的实例是 C, 并 obj.method 解析为 C.method。
下次我们执行相同的调用点时,它将 C.method 直接调用,绕过任何类型的方法查找过程。
点变成了直接调用,它通过一个特殊的入口点进入方法,该入口点验证接收者是否具有预期的类。
[外链图片转存中…(img-ekfUaHAl-1638734734998)]
在上面的示例中,我们假设 obj.method() 第一次执行的实例是 C, 并 obj.method 解析为 C.method。
下次我们执行相同的调用点时,它将 C.method 直接调用,绕过任何类型的方法查找过程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









