







目录
IP协议
IP协议全称为“网际互连协议(Internet Protocol)”,IP协议是TCP/IP体系中的网络层协议。
在应用层我们解决了数据使用的问题,在传输层我们解决了数据如何传输的问题,虽然说是传输,但是也要有传输的介质,两个主机传输数据,一定要知道对端的主机在什么位置。所以IP协议就提供了一种将数据从主机A发送到主机B的能力,但是这个能力只是很大概率可以做成这件事,那么如何可靠的进行数据传输呢,那就是传输层要解决的了。
网络层就要在复杂的网络环境中确定一个合适的路径,路由器就是连接多个网络的硬件设备,因此数据在进行跨网络传输时一定需要经过多个路由器。
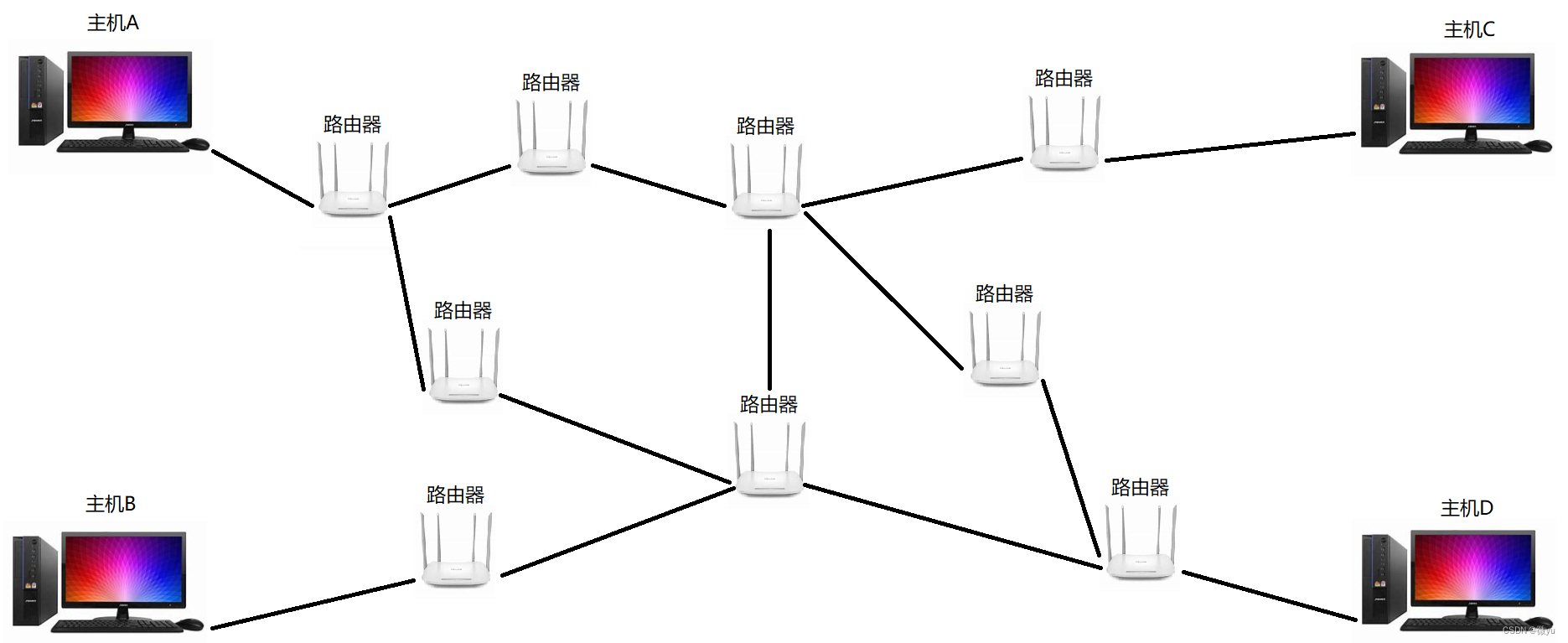
IP协议格式
此时的数据又变成了传输层的数据段,数据段中就有传输层报头、应用层报头还有数据。
说到协议就不得不提封装和解包,还有如何向上交付。
IP协议也采用固定长度20字节的报头,拿到IP协议报文后,读取4位首部长度,判断报文的长度是不是20,如果不是20,减去20就是选项,这个问题和TCP协议的4位首部长度的处理方式是一样的。其中8位协议就表明了是UDP协议还是TCP协议,通过这个8位协议就可以决定交给传输层的TCP还是UDP。IP协议是有16位总长度的,所以有效载荷的字节数就是16位总长度-4位首部长度 × 4。
其中4位版本填入的永远都是IPv4,就是4。
8位服务类型中,3位优先权(不再使用),4位TOS,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这4位相互冲突,只能选择一个。对于FTP文件传输协议,最大吞吐量比较重要。
8位生存时间,一个IP报文因为路由器的Bug,在网络中出现环路转发的问题,使它一直在占用网络资源,为了解决这种问题设置了8位生存时间,这个生存时间就是一个计数器,经过一个路由器就--,直到这个字段减到了0,这个报文直接被丢弃。
16位首部校验和,如果校验失败,报文直接被丢弃,丢弃也不用担心,TCP会进行超时重传。
32位源和目的IP地址,记录的就是报文从哪来,到哪去。
我们可以看出,IP协议和TCP协议有相似的地方,这也是为什么我们把网络协议栈叫做TCP/IP协议。
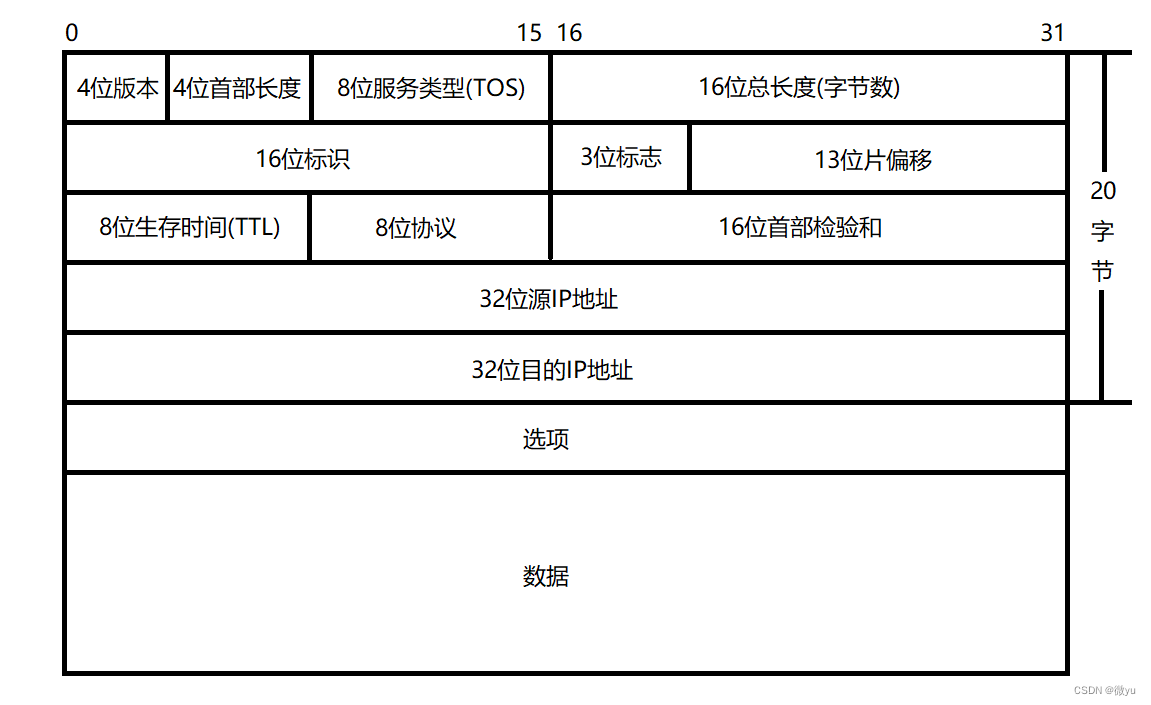
分片与组装
IP协议中还有三个位置没有说,分别是:16位标识、3位标志还有13位片偏移,在说他们之前,我们要再说一下这三个位置产生的原因:
- 在网络层下面就是数据链路层,数据链路层由于物理特征,它无法传输太大的数据。
- 它可以转发到网络中的字节数被限制为1500字节(Maximum Transmission Unit)。
- 如果想要发送超过1500字节的数据,网络层就要对数据进行分片。
- 通过分好的大小向对端发送,谁分片,谁组装,所以组装工作只能由对端的网络层进行,因为网络层向上交付的时候也必须是一个完整的报文,所以才要组装。
16位标识也就是IP报文的序号,如果没有分片,每一个IP报文的16位标识都是不一样的。
3位标志。第一位保留不使用;第二位为1表示禁止分片,如果超过报文长度超过MTU,网络层就会直接丢弃报文;第三位表示“更多分片”,没有分片就是0,如果分片了,该报文最后一个分片就是0,该报文其余的都是1,类似一个结束标志。
13位片偏移,该分片相对于该报文起始位置的偏移量,实际偏移的字节数 = 该位的值 × 8,除了最后一个分片之外,其他分片的长度必须是8的整数倍,否则报文就不连续了。
要完成这个工作,网络层要先识别报文之间的区别;要识别报文是否被分片;要识别哪些分片是开始,哪些分片是中间,哪些分片是结束;如果有一个分片丢失也要识别出来。
- 区别不同的报文可以根据16位标识。
- 没有被分片的报文的3位标志位的最后一位一定是0,且13位片偏移也一定是0。
- 分片的开始:更多分片位为1,片偏移位0。
- 分片的中间:更多分片位为1,片偏移位不为0。
- 分片的结束:更多分片位为0,片偏移位不为0。
- 收到分片后,根据偏移量进行升序排序,偏移量 = 上一个分片的偏移量 + 其“具体”长度。如果发现某时收到分片的偏移量与报头中的13位片偏移不符,那就证明有一个分片丢失了,成功计算到结尾就证明把所有分片都收取完了。
下面我们简单的来看一下分片和组装的过程。
假如要分3000字节的报文,每次发送最大就只能发送1500字节,分片之前是一个完整的报文,分片后也要是一个完整的报文,所以一定会多几个报头,这里假设报头不带选项,固定20字节。对于原始报文的切分就按照虚线切分。
第一个分片中自带报头,所以不用添加报头,大小就是1500字节,偏移量为0;第二个分片中没有报头,所以要添加报头,报头20字节,有效载荷只能是1480字节,偏移量为1500;最后一片给剩余的报文添加报头,偏移量是相对于原始报文的偏移量,不携带分片后添加的报头,所以最后一个偏移量是2980。
组装的时候就按序组装,除了第一个报文,其余的都要去掉报头。
事实上,分片的做法是很不推荐的。因为分片的行为是在网络层进行的,上面的传输层和应用层根本就不知道,IP协议要进行分片,那是不是增加了丢包的概率呢。
但是分不分片并不是网络层说了算的,是因为数据链路层不让发太大的数据,那解决这个问题还得看传输层和数据链路层。
网段划分
全球中主要使用的还是IPv4,32位能够表明的主机数量就是2的32次方个。
IP地址由网络号和主机号两部分构成:
- 网络号:保证不同的网段的标识是不同的,根据网络号可以标识不同的地区。
- 主机号:在同一个网段内,网络号是相同的,但是主机号一定是不同的。
两个网段通过两台路由器相连接,根据不同的网络标识区别两个网段,在同一个网段中根据主机标识区分不同主机。
这种设计在日常生活中也随处可见,比如我们的学号,前几位表示哪个学院,中间几位表示专业和班级,最后几位表示在班级中的几号。
那么为什么要进行这样的划分呢?
在网络通信中,一定会出现长距离传输,距离变长,可靠性要解决,如何定位目标主机也要解决,在公网中有许多的网段,有许多的主机,为了快速高效的定位才采用这样的方式,通过前几位就知道要去哪个地区、哪个省、哪个市和哪个小区,找到这个IP地址所在的网段,然后确定是哪一台主机,每确定一个位置就可以排除掉网络中大量主机,所以这种做法便于定位,而且高效。
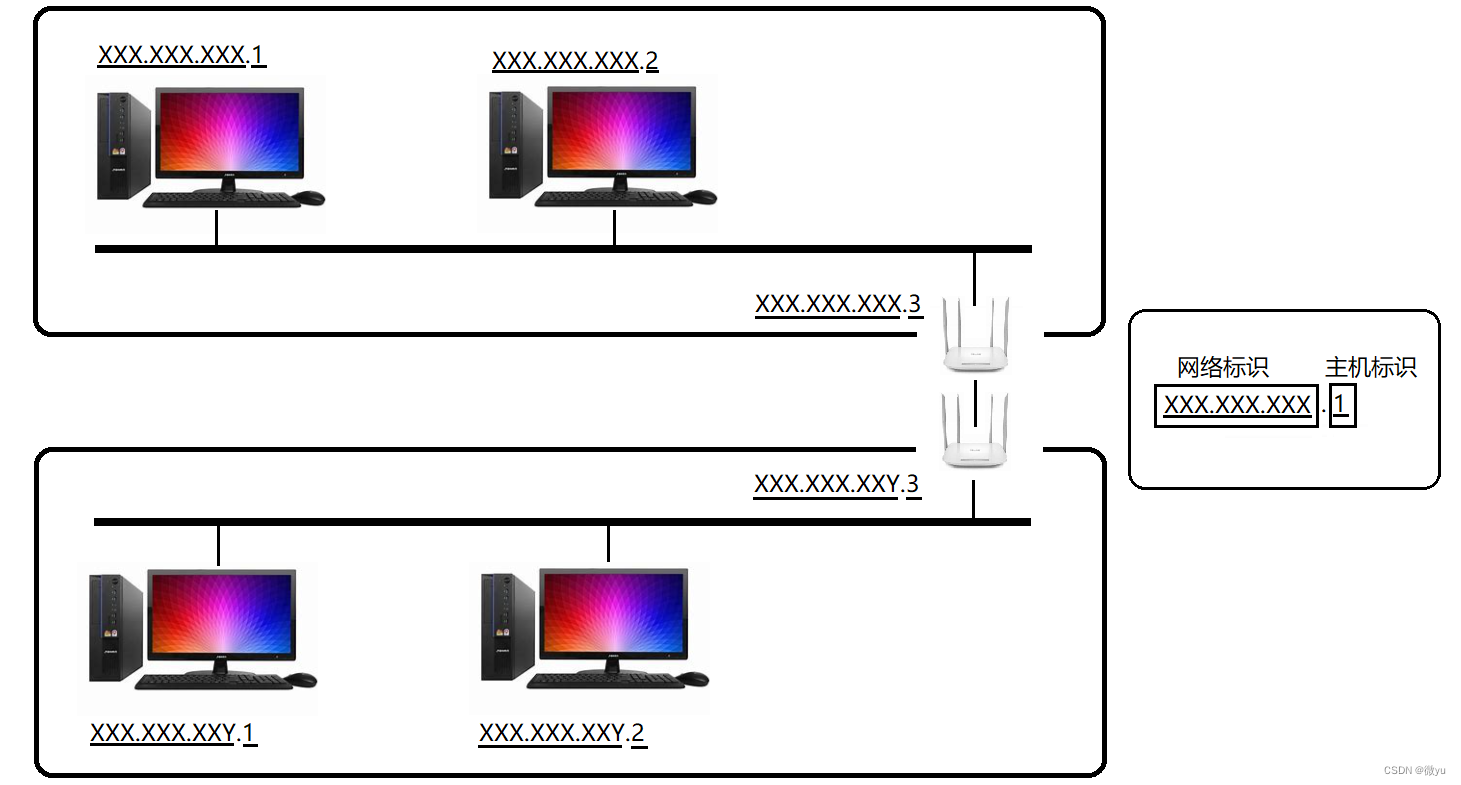
上面我们已经知道了网段划分的好处,那么如何进行网段划分呢?
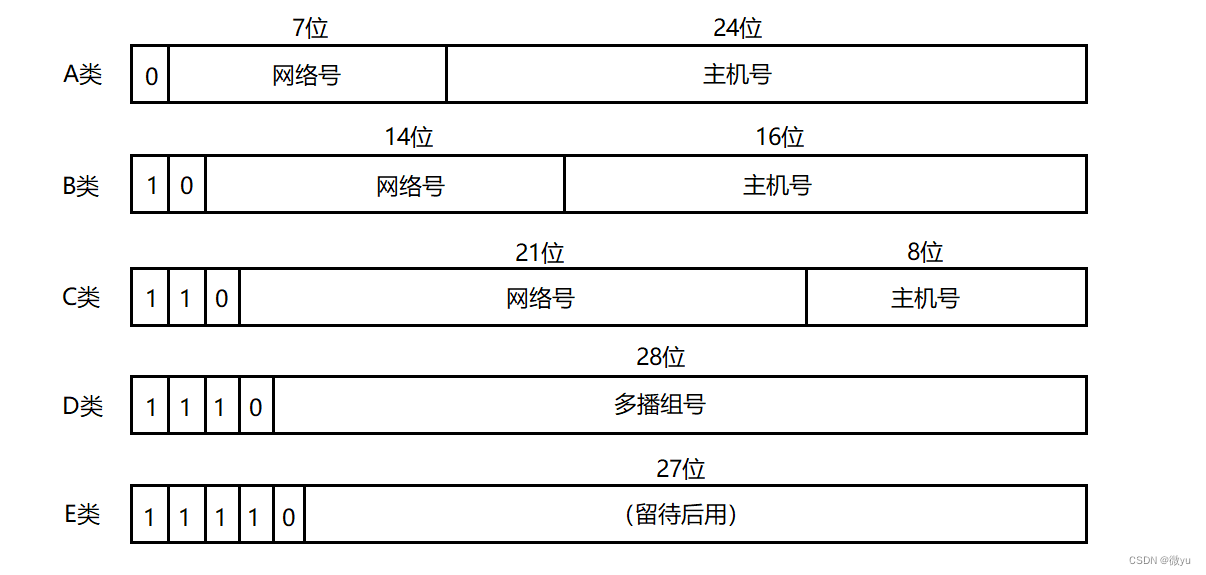
我们先来说一下过去的划分方式,将IP地址分为五类:
- A类:0.0.0.0到127.255.255.255。
- B类:128.0.0.0到191.255.255.255。
- C类:192.0.0.0到223.255.255.255。
- D类:224.0.0.0到239.255.255.255。
- E类:240.0.0.0到247.255.255.255。
判断一个IP地址是属于哪一类时,只需要遍历IP地址的前五个比特位,第几个比特位最先出现0值,那么这个IP地址对应就属于A、B、C、D、E类地址。但是这种方式的局限性很快就显现出来了,因为A类IP的数量较少,大多数都会选择B类IP,申请到B类IP后,主机号有2的16次方,就是65536台主机,但是一个局域网中不会由这么多主机,所以大部分的IP地址就浪费了,本来2的32次方都不够用,还要浪费。
所以我们来说一下子网划分方案——CIDR(Classless Inter-Domain Routing)。
- 为了区分IP地址中的网络号和主机号,于是引入了子网掩码(subnet mask)的概念。
- 每个路由器都有自己的子网掩码,它也是一个32位整数,开头部分是全“1”,结尾部分是全“0”。
- 将IP地址与当前网络的子网掩码进行“按位与(&)”操作,就能得到当前的网络号,也就可以得知当前IP所在的位置。
这样IP地址就被更细粒度的划分为一个更小的子网,通过不断划分,主机号越来越短,子网中可用的IP地址也会越少,这就可以减少IP地址被浪费的情况。
- 假如在某一个子网中将IP地址的前24位作为网络号,所以子网掩码以点分十进制的形式就是255.255.255.0。
- 此时一个IP地址与子网掩码按位与后,前24位不变,后8位就被清零了。
- 可以在IP地址后加一个“/”,后面的数字就是表示网络号的位数,例如:192.168.16.1/24,表示前24位为网络号。
当一个报文在公网中路由的时候,IP地址会与当前国家的路由器中的子网掩码(此时的子网掩码可能就是255.0.0.0)按位与拿到前几位,看看是哪个国家,然后把报文就传给对应的路由器,路由器中可能还不止一组子网掩码,通过路由器中的另一组子网掩码查出是哪个省的,把报文再交给对应的省,之后按照同样的方式按位与子网掩码,最后就可以找到目的主机。
每路过一个路由器,与子网掩码按位与后得到网络号,通过这个网络号就可以排除大部分主机。随着网络号的位数越来越大,主机号的位数越来越小,最终就可以找到目标主机,此次路由就结束了。
特殊IP地址
并不是所有的IP地址都能够作为主机的IP地址,有些IP地址本身就是具有特殊用途的。
- 127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1。
- 如果IP地址中的主机号全部为0,那这就是网络号,代表这个局域网。
- 如果IP地址中的主机号全部为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包。
IP地址的数量限制
IP地址(IPv4)是一个4字节32位的正整数,共有2的32次方个IP地址,也就是43亿多个IP地址。但TCP/IP协议规定,每个主机都需要有一个IP地址。
在未来的生活中,几乎所有的设备可能都要进行联网,那就要有对应的IP地址,所以这些IP地址是远远不够的,虽然CIDR的方案已经划分划分好了5类网络进行子网划分,但是它也只是减少了浪费,并没有增加IP地址。解决IP地址不足的方式也有:
- 动态分配IP地址:只给接入网络的设备分配IP地址,因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的,避免了IP地址强绑定于某一台设备,用到的就是DHCP协议。
- 当子网中新增主机时,需要为它分配一个IP地址;子网当中有主机断开网络时,需要回收它的IP地址,便于分配给后续新增的主机使用。
- 对于IP地址的分配和回收一般不会手动进行,而是采用DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)技术。
- DHCP是一个基于UDP的应用层协议,一般的路由器都带有DHCP功能,因此路由器也可以看作一个DHCP服务器。
- 当我们连接WiFi时需要输入密码,路由器验证你的账号和密码后,验证通过就给你动态分配了一个IP地址,然后你就可以通过这个IP地址进行网络通信。
- NAT技术:能够让不同局域网当中同时存在两个相同的IP地址,NAT技术不仅能解决IP地址不足的问题,而且还能够有效地避免来自网络外部的攻击,隐藏并保护网络内部的计算机,下面就来这个技术。
- IPv6:IPv6用16字节128位来表示一个IP地址,能够解决IPv4地址不足的问题,但它们是互不相干的两个协议,彼此并不兼容,修改成本过大,没有普及。
私有IP地址和公网IP地址
我们做出了如下规定,如果一个组织内部组建局域网,有一类IP不可以出现在公网中,这些IP地址只能用来组建局域网或子网,这些IP地址如下:
- 10.*,前8位是网络号,共16,777,216个地址。
- 172.16.*到172.31.*,前12位是网络号,共1,048,576个地址。
- 192.168.*,前16位是网络号,共65,536个地址。
在这个范围中的IP地址都称为私有IP,其余的都称为公网IP,这些私有IP地址就是RFC 1918规定用于组建局域网的IP地址。
打开我们电脑中的命令行模式,输入ipconfig,就可以看到,我的机器连接是WIFI,看到的就是这样。子网掩码表示前20位为网络号,默认网关就是局域网中的第一台主机也就是路由器,主机号就是1。
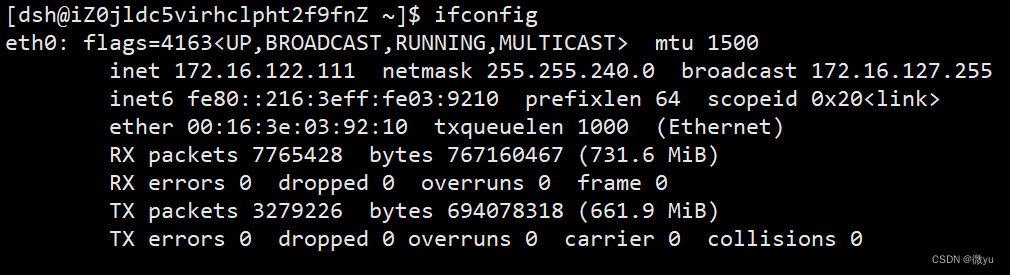
在云服务器下,使用ifconfig也可以查看,这里是172.16开头的IP地址。

首先我们要知道的是,网络通信的基础设施都是运营商搭建的,我们访问服务器的数据并不是直接发送到了对应的服务器,而是需要经过运营商建设的各种基站以及各种路由器,最终数据才能到达对应的服务器。
在家里连接网络的时候,都会联系运行商进行光纤入户,工作人员会给一个调试解调器(猫)和一个路由器,然后给家里的网络开户,配置一下路由器,让运营商认证家里的网络,也可以通过账号和密码配置路由器,之后就可以正常上网了,只要按时缴费就可以。不止是路由器,我们的手机号不也是要按时缴费的吗,欠费了就不能打电话,但是可以打给运营商,原因就是通信的路线是运营商搭建的。
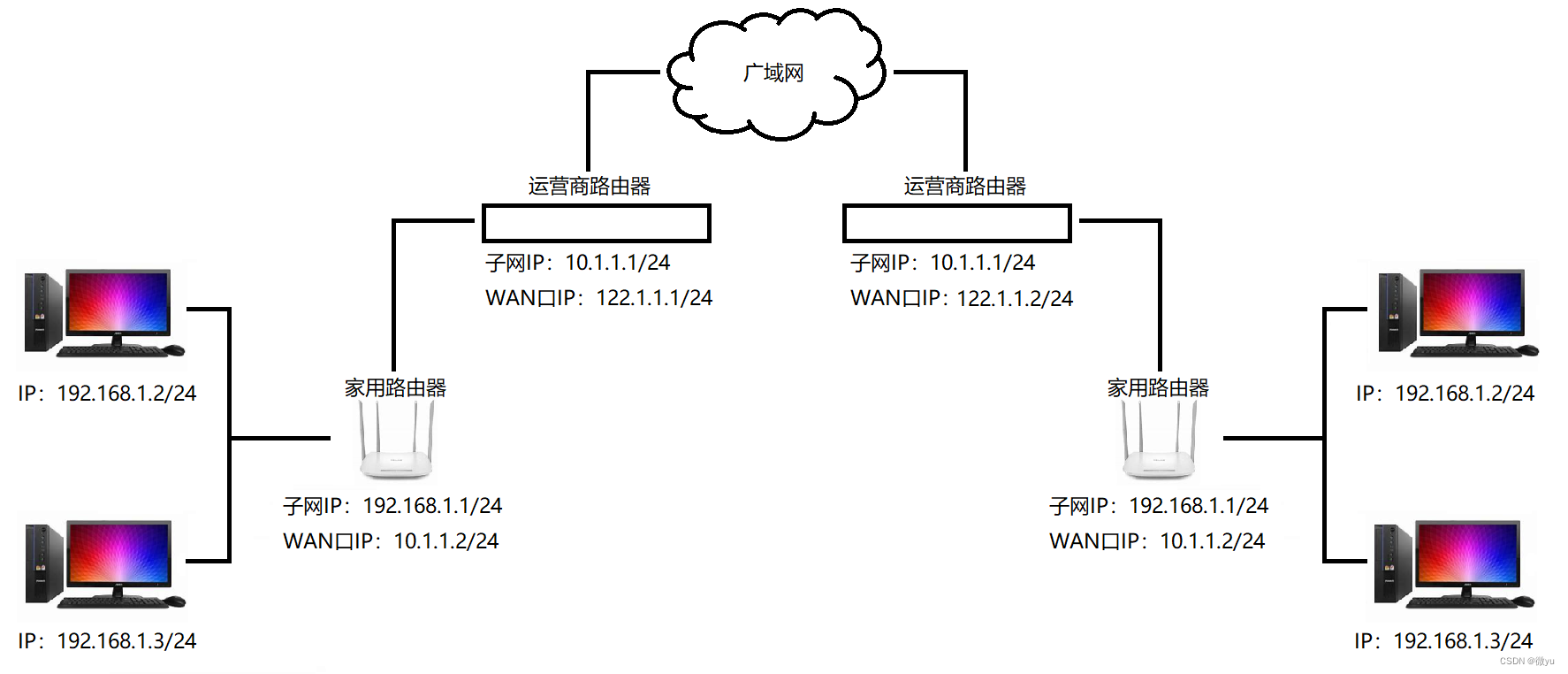
路由器是连接两个或多个网络的硬件设备,在路由器上有两种网络接口或两套地址,分别是LAN口和WAN口:
- 对内的LAN口(Local Area Network):表示自己构建的局域网(子网),子网IP。
- 对外的WAN口(Wide Area Network):表示自己也是别人构建的局域网中的一个机器的IP地址。
由上图可得知,在广域网中,多台运营商路由器的IP地址是不同的,但是他们所构建的局域网的IP是可以相同的。
因为私网IP已经不具备唯一性了,所以它不能出现在公网当中,因此子网内的主机在和外网进行通信时,路由器会不断将IP数据包报头中的源IP地址替换成路由器的WAN口IP地址,这样逐级替换,最终数据包中的源IP地址成为一个公网IP,这种技术成为NAT(Network Address Translation,网络地址转换)。
路由
路由就是数据问路的过程,问路就有三种结果,第一种:对方知道,并且告诉了你;第二种:对方不知道,但是它知道谁知道;第三种:对方也不知道。显然第三种在网络通信中是不允许发生的。
知道源IP和目的IP,通过路由器就可以实现下一步去哪(下一个局域网),比如在一个内网中,我要把数据发送到服务器,内网中的路由器中会有一个路由表,通过遍历表中的IP地址就可以知道下一次要去哪,直到找到目标服务器所在的局域网,然后通过主机号就可以找到是哪一台主机。
路由表是什么呢,在Linux下使用route命令就可以看到。
- Destination:表示目的网络的网络号,default叫做默认网关。
- Gateway:表示下一条的地址。
- Genmask:表示子网掩码。
- Flags:U表示正在被使用(Useful),G表示默认网关。
- Iface:表示转发接口。
当路由器收到一个报文,拿报文中的目的IP地址与路由表的每一条数据的子网掩码进行按位与操作,之后和Destination进行比较,如果都没有比较成功就转发到默认网关,转发的过程就是通过Iface显示的接口转发。
这就是我的机器下的转发接口。

路由表生成算法
路由可分为静态路由和动态路由:
- 静态路由:是指由网络管理员手工配置路由信息。
- 动态路由:是指路由器能够通过算法自动建立自己的路由表,并且能够根据实际情况进行调整。
路由表相关生成算法:距离向量算法、LS算法、Dijkstra算法等。
在这一篇文章的最后,我们已经知道了一个报文如何在网络中转发的策略。
数据从应用层中来,依次向下封装,决定使用哪一种传输层协议,之后再向下发送给网络层,网络层决定发送的策略,想要通过网络发送数据就要进行路由转发,到了这里,我们还要注意,网络层并不会转发数据,它只是提供了策略,数据到了网络层还要向下,下一层就是数据链路层,数据链路层就帮我们解决如何转发。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











