






自然语言处理
步骤
-
语料获取、语料预处理、文本向量化、模型构建、模型训练和模型评价6部分组成
分词
规则分词
-
正向最大匹配
-
-
逆向最大匹配
-
双向最大匹配法
-
正逆向中找分词数量最少的
-

规则分词缺陷:
-
基于规则的中文分词常常会遇到歧义问题和未登录词问题
-

-
未登录:词典中没有的词
-
统计分词

-
n—gram 语法模型
-
过程:求出每种分词方式的p(w_j),j表示第几种分词方式,选择最大的p(w_j)
-
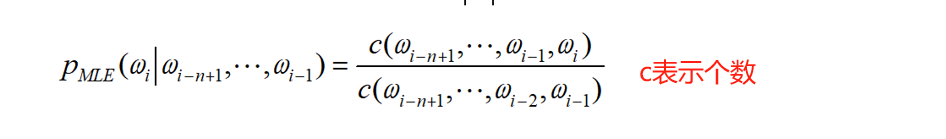
-

-
-
隐马尔可夫模型
-
A: 状态转移矩阵
-
-
B:状态观测矩阵
-
pi:初始状态矩阵
-
###########################################################################################
关键词提取
TF-IDF
-
p=文档词频*log总文档逆词频
-

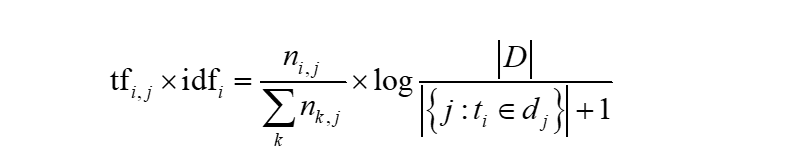
TextRank
-
与tf-idf对比
-
-
参考Pagerank 模型设计
-


TextRank核心

-
步骤
-

LAS(主题模型)
-
解决textrank/TF-IDF问题
-
-
主题模型实现原理
-


词袋模型BOW:
-
文档中分词,每个词为一个向量,l词频为向量长度
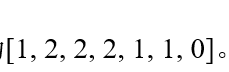
-
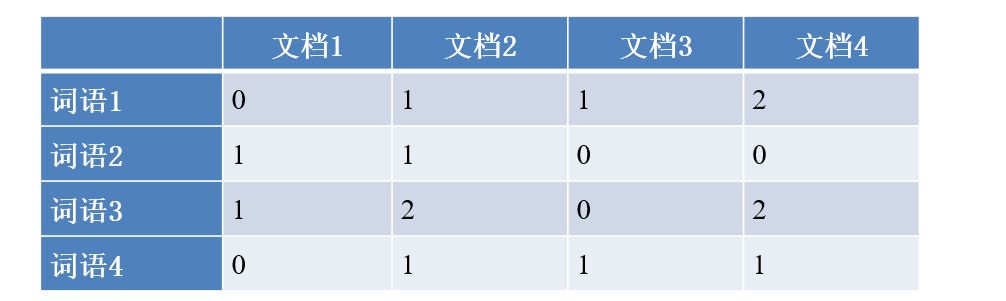
统计所有文档的向量形成矩阵
文本向量化
one-hot
-
缺陷


CBOW模型
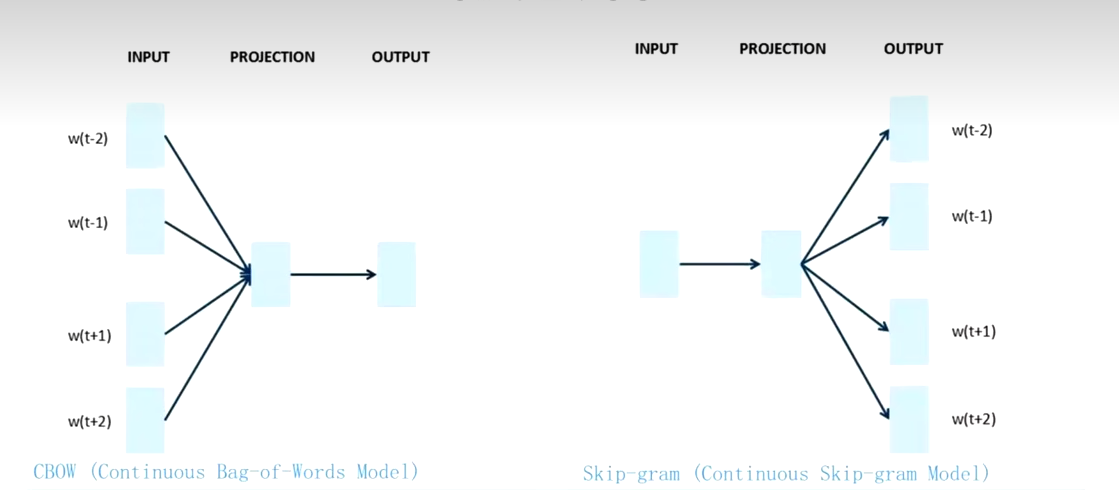

Skip-gram


Word2Vec
步骤:
-
Word2Vec模型获取一段文本的向量,
-
是先对文本分词,
-
提取文本的关键词,
-
用Word2Vec(利用Skip-gram)获取每个关键词的词向量(词偏移量),
-
计算所有关键词向量的平均值,
缺点这种方法只保留了句子或文本中词的信息,缺丢失了文本中的主题信息。
Doc2Vec模型
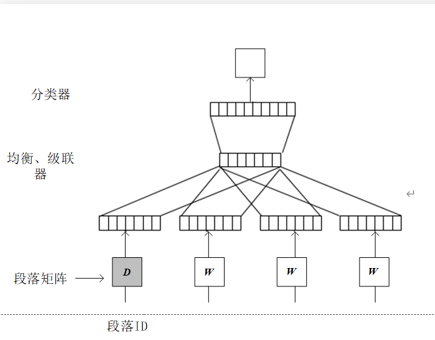
与Word2Vec模型类似,只是在Word2Vec模型输入层增添了一个与词向量同维度的段落向量,(看作是另一个词向量)
DM
Paragraph ID:与词向量长度相等的段落向量
输入:全文段落向量
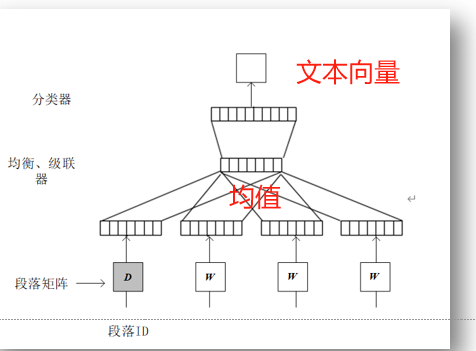
求均值
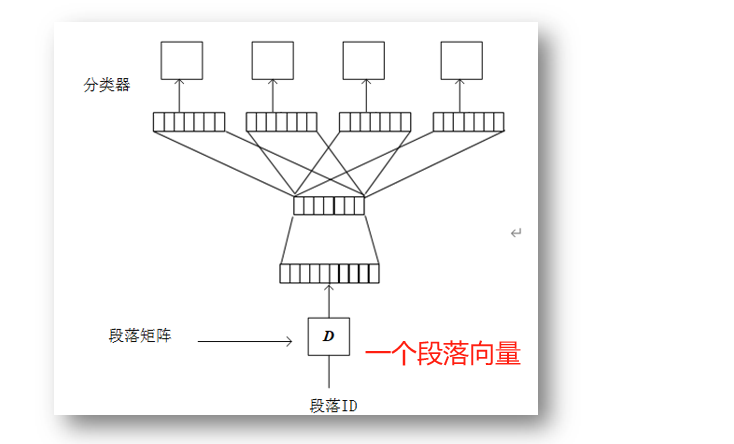
BDOW
预测上下段落中随机词的概率分布(输出为整个段落的词向量表达式)
word2vec计算文本相识度
-
文本预处理
-
提取关键词
-
关键词向量化(并将所有关键词的词向量相加,得到文本的向量化表示)
-
计算向量间余弦
doc2vec

文本分类
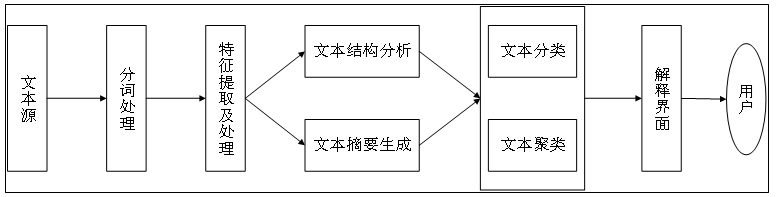
文本聚类
传统的文本聚类方法:
使用TF-IDF技术对文本进行向量化。
•然后使用K-Means等聚类手段对文本进行聚类处理。
主要聚类算法
•基于划分的聚类算法。
•基于层次的聚类算法。
•基于类算法。
•基于模密度的聚类算法。
•基于网格的聚型的聚类算法。
•基于模糊的聚类算法。
文本情感分析

基于情感词典的情感分析(题:基本原理)
-
基于情感词典的方法是在文本中提取相应的情感词、否定词和程度副词,
-
结合情感词典中情感词的得分情况、是否否定和程度级别进行相应的打分(正负),
-
最后得分的总和即为文本的情感分
缺点:需要规模较大的情感词典作为分析的基础
实现方法
首先对文档分词,找出文档中的情感词、否定词和程度副词。
情感词值*(否定-1) *程度副词值
所有词求和求和,大于0的归于正向,小于0的归于负向。
基于文本分类的情感分析(基本原理)
采用标注好情感类别的文本进行训练,构建情感分类器,
最后对情感分类器进行测试,输出结果为每个标签值的概率值,选择概率最高的情感倾向为分类结果。
实现方法
•特征提取:就是分类对象所展现的部分特点,是实现分类的依据。
•文本转化为特征向量(文本向量化doc2vec/word2vec)
•划分训练集与测试集:训练集用于训练文本,测试集用于测试分类算法的效果。
•构建分类器:构建分类器是运用机器学习的算法训练数据集,得出分类器。
验证分类器:使用测试数据集对分类器进行测试,通过比对测试结果,获得测试数据的准确率
LDA模型情感分析
-
正负面分类:文本句进行SnowNLP情感分析,
-
两边分词处理
-
两边建立LAD模型
-
LAD输出正负文本主题词(根据正负面文本输出的主题词后续优化,减少负面信息)
RNN
LSTM(等长)
RNN的一种变种,对其网络结构进行了改进,增加特殊的方式存储“记忆”避免梯度消失的特性,从而让RNN网络自身具备处理长期序列依赖的能力
seq2seq
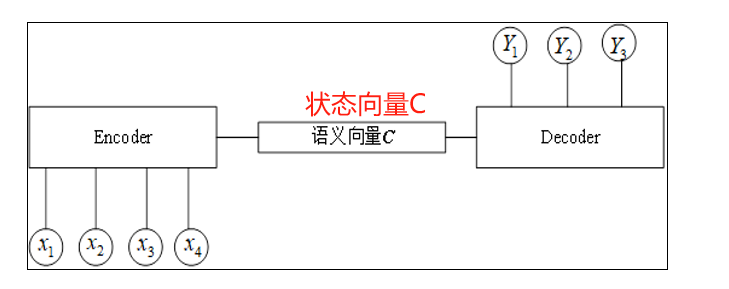
ENCODER-----DECODER都是一层RNN
















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









