






一、整型家族,包括:char,int,short,long
数据在内存中以二进制的形式储存。对整数来说:整数二进制有三种表现形式:原码,反码,补码。
而对正整数来说,原码,反码,补码相同。
对负整数来说,原码,反码,补码需要相互转化才能得出。
首先,根据数据的数值直接写出的二进制序列就是原码,其次,原码的符号位不变,其他的位按位取反得到反码,最后,反码加一得到补码。通过下面的代码来加深印象:
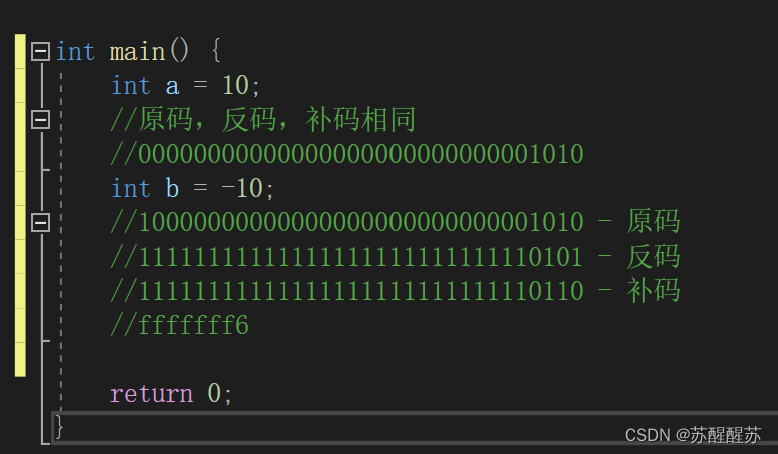
那么,着32位当中哪一个数字是符号为呢?当然是第一位数字。其中,0表示正数,1表示负数。
大端字节序和小端字节序存储的区别:
大端字节序:把数据的低位字节序的内容储存在高地址出,高位字节序的内容存放在低地址处。
小端字节序:把数据的低位字节序的内容存放在低地址处,高位字节序的内容存放在高地址处。
例如:有一个数0x11223344
| 11 | 22 | 33 | 44 |
我们知道地址的变化从左到右依次由低到高变化的,这就叫做大端字节序储存。
| 44 | 33 | 22 | 11 |
同理,这就叫做小端字节序储存。
如果要我们设计一个小程序来判断当前机器的字节序,我们怎么来设计呢?

我们怎么来解读这个代码呢?在此我也不多介绍,我们可以去自行探索。
signed 与 unsigned的区别是啥呢?
我们通过以下的代码来探索一下:

首先毫无疑问,我们存放的是负数,在内存中存放的是补码。注意,我们此时的数据类型为char,所以此时内存二进制的最后8位数。但是,我们输出规定要用%d输出,所以我们要补齐32位才能输出。那么我们怎么补,signed 和 unsigned有啥区别吗?当然,如果是有符号类型,我们在前面补1,如果是无符号类型,我们在前面补0。还有,我们是按照原来的类型进行整型提升。例如:
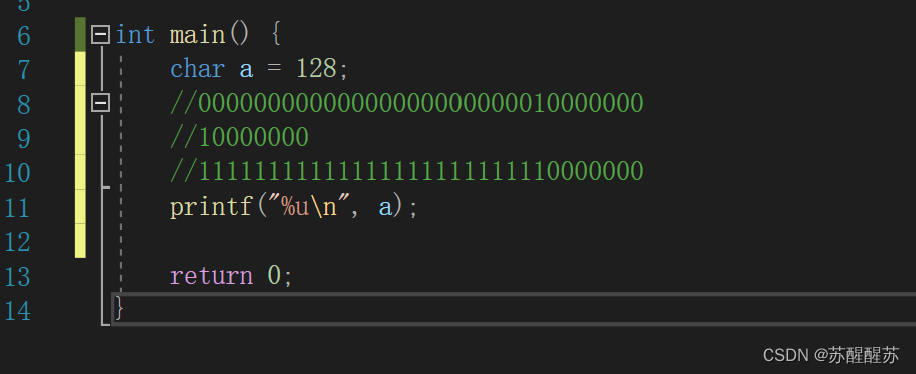
这里我们规定用%u来打印a,但是我们原来的a是有符号类型的,所以我们补就按照有符号类型的来补,所以补1。
二、浮点型家族 包括:float ,double,long double
首先,我们得记住一个公式:
(-1)^s *M*2^E
float : s(1bit) E(8bit) M(23bit)
double: s(1bit) E(11bit) M(52bit)
我们可以通过下面代码学习:
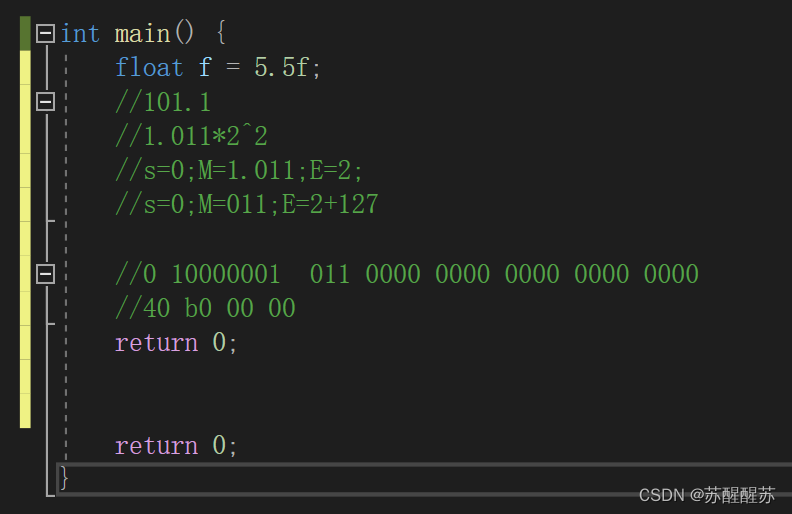

如果是正数s=0,负数s=1。
拿float类型举例子:32进制中,第一位数字表示s,正数为0,负数为1。紧接着的八位数字表示E的二进制。后面的23位为M。后面的23位是要先把M的小数部分先放进去,然后补足。
















 9029
9029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











