







容量单位从小到大的顺序依次为:TB、PB、EB、ZB。
.
用于设置环境变量的文件是 .bash_profile
.
设置免密登录时,将生成的公钥信息写到授权文件中
.
将HDFS文件下载到本地的命令是 hadoop fs -get。
.
不需要Java环境的支持是 MySQL
.
通配符是用于模糊匹配的特殊字符,可以在关键字查询中使用。在MySQL中,通配符主要有两种:% 和 _ 。其中,% 代表匹配任意多个字符(包括0个字符),_ 则代表匹配单个字符。
.
HBase 、Redis 和 MongoDB 都是常见的NoSQL数据库(非关系型数据库)
传统的关系型数据库:Oracle、MySQL、SQL Server
.
将 MySQL 中的数据传递到 HDFS,使用 Sqoop 的 import 命令。
.
Crontab、Oozie、Azkaban 都是常见的任务调度工具,可以用于执行定时、周期性或事件触发的任务。
虽然 Hive 可以通过编写脚本实现定时任务调度,但它本身并不是一个专门用于任务调度的工具。
.
Echarts:基于JavaScript的数据可视化图表库。由百度开发,现已成为Apache顶级项目。支持丰富的图表类型。
Echarts主要用于数据可视化,而不是数据的分析处理。
.
HBase 可以有列,可以没有列族(column family)。
.
HDFS 中的 block 默认保存 3 个备份。
.
Hadoop作者:Doug cutting
.
HDFS2.7.*以后 默认 Block Size 大小是 128MB
.
HDFS:Hadoop生态系统中分布式文件系统,存储大规模数据和支持数据访问,将数据分散储存在多个节点,提供高可靠性和高扩展性,方便数据处理和分析。
Map/Reduce:分布式计算模型,在大规模集群上并行处理大规模数据,将计算任务分解为Map和Reduce两阶段,Map:将输入数据转换为键值对。Reduce:将相同键的数据合并处理。通过分布式计算和数据并行化实现高性能、高可靠性、高扩展性的数据处理和分析。
Yarn:Hadoop 2.X资源管理器,管理Hadooop集群中资源分配和任务调度,将计算、存储资源统一管理,提供API和框架实现作业调度和任务管理,使Hadoop集群同时运行多个应用程序,提高了Hadoop集群资源利用率和应用程序的性能。
.
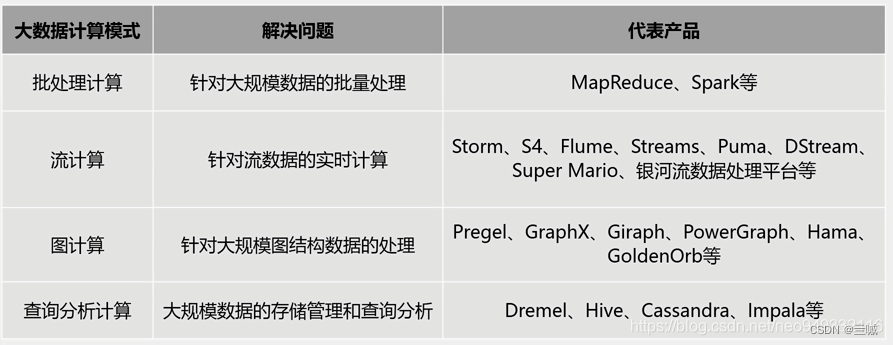
.
大数据、云计算、物联网是当前信息技术发展的三大趋势,之间存在紧密的关系和互相促进作用。
- 大数据技术是处理海量数据核心技术,通过分布式存储和计算,实现数据的高效处理和分析。
- 物联网技术收集和整合各种设备和传感器产生的数据,提供实时数据流和大量数据,为大数据技术提供数据源。
- 云计算技术提供高效的计算和存储资源,可以帮助大数据和物联网应用快速部署和扩展,降低成本和提高效率。
.
Hadoop生态系统重要组件:
- HDFS:Hadoop分布式文件系统,用于存储大规模数据集。
- MapReduce:Hadoop分布式计算框架,用于处理大规模数据集。
- YARN:Hadoop资源管理系统,用于管理计算集群的资源分配和任务调度。
- HBase:Hadoop生态系统中的分布式NoSQL数据库,用于存储非结构化和半结构化数据。
- Hive:Hadoop生态系统中的数据仓库系统,用于查询和分析大规模数据集。
- Spark:基于内存计算的分布式计算框架,在大规模集群上高速的数据处理和分析,支持多种计算模式和数据源。
.
HBase特点:
- 海量存储,存储大量的非结构化数据
- 列(簇)式存储,数据是基于列族进行存储的
- 高扩展性,通过动态增加节点来提高集群的存储能力
- 高并发,支持高并发的读写请求
- 稀疏,可以指定任意多的列,在列数据为空的情况下,不会占用存储空间
- 分布式的、面向列的NoSQL数据库
.
Hadoop的安装步骤:
- 下载Hadoop
- 解压 Hadoop 至本地。
- 配置环境变量:将Hadoop的bin目录添加到系统的PATH环境变量中,在终端中可以直接运行Hadoop命令。
- 配置Hadoop:修改Hadoop的配置文件
- 格式化HDFS:在Hadoop集群中一个节点上运行hdfs namenode -format命令,格式化HDFS文件系统。
- 启动Hadoop:在Hadoop集群中一个节点上运行start-all.sh命令,启动Hadoop的各个组件。
- 验证Hadoop:在浏览器中打开Hadoop的Web界面,查看Hadoop的运行状态和资源使用情况,并提交MapReduce任务进行测试验证。
.
Eclipse下开发web项目的步骤:
- 创建动态Web项目:在Eclipse中选择File -> New -> Dynamic Web Project,输入项目名称、目标运行时环境和项目位置等信息,创建Web项目。
- 添加 Web 库:在项目中添加 Web 库,如 Servlet API、JSP API 等。
- 添加Servlet:在项目中创建Servlet类,实现Servlet接口,处理HTTP请求和响应,可以使用Eclipse的Servlet模板来快速生成代码。
- 编写JSP页面:在项目中创建JSP页面,使用HTML和Java代码来组织页面,可以使用Eclipse的JSP模板来快速生成代码。
- 配置部署描述符:在项目中配置部署描述符 web.xml,设置 Servlet/JSP 的映射关系、访问权限等。
- 配置项目:在项目的Properties中配置Web项目的相关信息,包括Servlet版本、部署描述符、Java Build Path等。
- 导出WAR包:在Eclipse中可以将Web项目导出为WAR包,以便在其他环境中部署和运行。
- 运行项目:在Eclipse中右键点击项目,选择Run As -> Run on Server,选择目标服务器和端口号,将Web项目部署到服务器上运行。
- 调试项目:在Eclipse中可以使用调试器来调试Web项目,包括设置断点、单步执行、查看变量值等操作。
.
叙述大数据分析处理的完整过程及每个过程采用的技术:
- 数据采集:在数据采集阶段,需要从各种来源(如传感器、社交媒体、日志文件等)收集大量的数据,并将其存储在数据仓库或数据湖中。常用的数据采集技术包括Kafka、Flume、Logstash等。
- 数据清洗:在数据清洗阶段,需要对采集到的数据进行去重、过滤、转换、归一化等处理,以便后续的数据分析。常用的数据清洗技术包括Hadoop MapReduce、Pig、Spark等。
- 数据存储:在数据存储阶段,需要将清洗后的数据存储在数据仓库或数据湖中,以便后续的数据处理和分析。常用的数据存储技术包括Hadoop HDFS、HBase、Cassandra、MongoDB等。
- 数据处理:在数据处理阶段,需要对存储在数据仓库或数据湖中的数据进行处理和分析,以提取有价值的信息。常用的数据处理技术包括Hadoop MapReduce、Spark、Hive、Impala等。
- 数据可视化:在数据可视化阶段,需要将处理后的数据以图表、报表等形式展示出来,以便用户进行交互式的分析和探索。常用的数据可视化技术包括Tableau、D3.js、Echarts等。
- 数据挖掘:在数据挖掘阶段,需要利用机器学习、人工智能等技术,对数据进行深度挖掘,以发现数据中隐藏的规律和趋势。常用的数据挖掘技术包括TensorFlow、Scikit-learn、Weka等。
.
程序要在hadoop集群环境下运行需要先打包再提交运行,写出提交命令:
hadoop jar ks1.jar mr.Ks1 /input/data.txt /output/result
.
利用 Hive 实现加载数据的命令:
LOAD DATA INPATH ‘/path/to/student_scores.txt’ OVERWRITE INTO TABLE student_scores;
将/student_scores.txt文件中的数据加载到student_scores表中,并覆盖原有的数据。
创建Hive表的命令:
CREATE TABLE student (
sno STRING,
sname STRING,
shuxue INT,
yuwen INT,
yingyu INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
加载数据的命令:
LOAD DATA INPATH '/input/data.txt' OVERWRITE INTO TABLE student;
实现功能的HQL命令:
SELECT sno, sname, shuxue, yuwen, yingyu, shuxue+yuwen+yingyu AS zongfen
FROM student
ORDER BY zongfen DESC, sno ASC;
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











