






更新:这篇文章是一年前的课程作业,上传本文章是想放在电子简历里面的,结果期末季翻到这的人还挺多。好多人私信我要源码,可惜我放假了才看到,正好前段时间把自己的文件整理了一下,上传一下也顺手。
部分网友反馈爬虫部分xpath比较长在文章没有展现,虽然不确定之前的xpath还能不能用,还是把爬虫代码贴到文末了。数据清洗的部分是用notebook进行的,全流程的代码都放文件夹里了。
链接: https://pan.baidu.com/s/1d38LFu-HlM5vmDfnDqBz_g?pwd=zysj 提取码: zysj
一、研究背景
随着城市化的快速发展,房地产市场扮演着越来越重要的角色。在中国,房地产市场的快速增长已经成为支撑国民经济发展的重要力量。这种迅速发展并不是一帆风顺的,房地产市场存在很多问题,例如:房屋供需关系失衡、房价波动较大、未来市场的不确定性等。因此,房地产市场的分析成为了一个重要的领域,鹤岗房价数据也由此而生。房价数据有助于我们全面理解和诊断市场状况,帮助市场参与者制定更加明智的决策,从而达到保值增值的目的。
针对这一情况,我们将通过对鹤岗房价数据的分析来深入了解该市场的变化趋势、规律和特点。这一研究旨在为购房者、开发商、政府监管机构等相关市场参与者提供更多的信息和见解,以便他们能够更好地进行决策和制定政策。
二、研究目的
本研究以安居客网鹤岗市房源数据为对象,采用数据分析和可视化相关方法,对鹤岗市的房源特征进行深入探究。通过在线房源搜索获取关于区域、房源建筑年份、房源名称、代理商、房屋特征、房屋厅室和面积等方面的相关信息,本研究旨在总结出鹤岗市房源信息的普遍特征,方便租房者进行条件调整和选择,从而提高房源信息的匹配度和租房者的满意程度。通过此研究,我们将能够更好地了解鹤岗市的房源状况,提供有针对性的租房建议,为租房市场的发展做出贡献。
三、实践内容
1. 数据采集
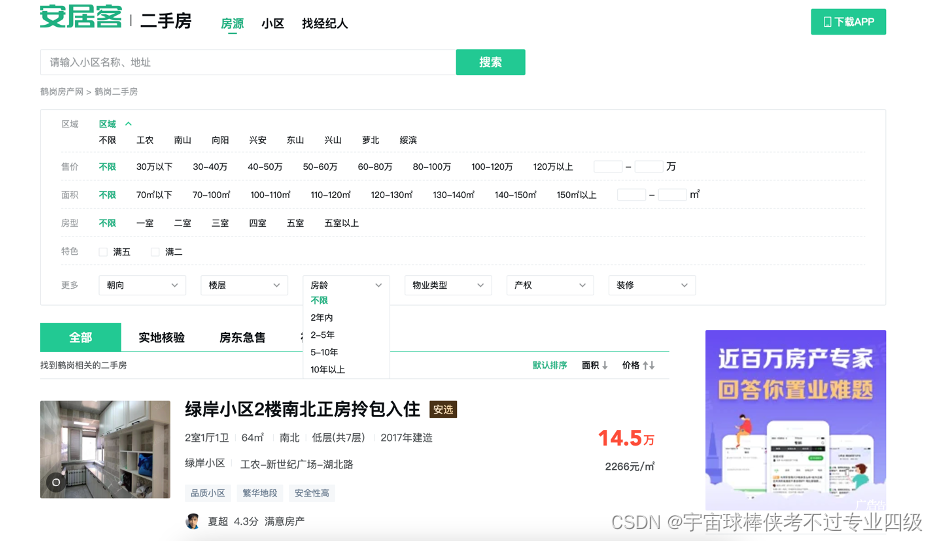
定位到安居客二手房搜索结果页面https://hegang.anjuke.com/sale/p2/
库的调用如下:

利用Request 和 lxml.etree 进行网页源代码的爬取和解析
利用time 和 random 实现基本的间断爬取
利用csv 实现数据的写入和储存
根据url的规律,通过while循环遍历搜索结果的页面(num),每张页面含有60条房源数据,当房源数据小于60条时,网页会要求验证,程序跳出循环,人工介入完成验证后,更改num参数为当前页码,继续爬虫;当没有获取到词条时,调用time库暂缓一段时间重新请求。

获取网页解析结果后,利用xpath方法获取节点内容,对于子节点不存在的例子中,遍历父节点,通过if条件句判断子节点是否有值完成数据提取
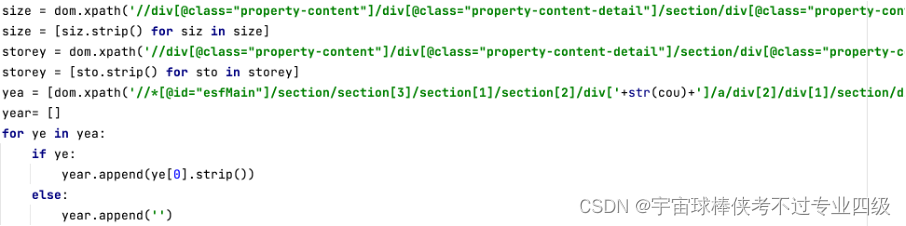
循环的末尾部分,将单页面内提取的60条信息按行写入csv文件,并为num变量加一,使得下一次循环爬取下一页数据,同时用随机数实现页间暂停

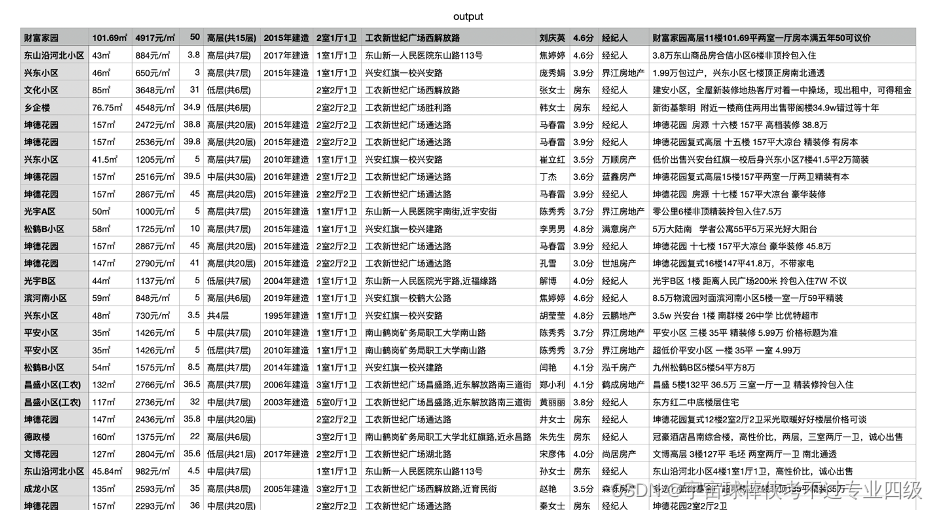
运行程序,获得output.csv如图
2. 数据清洗
调用pandas对同文件夹下的csv进行读取
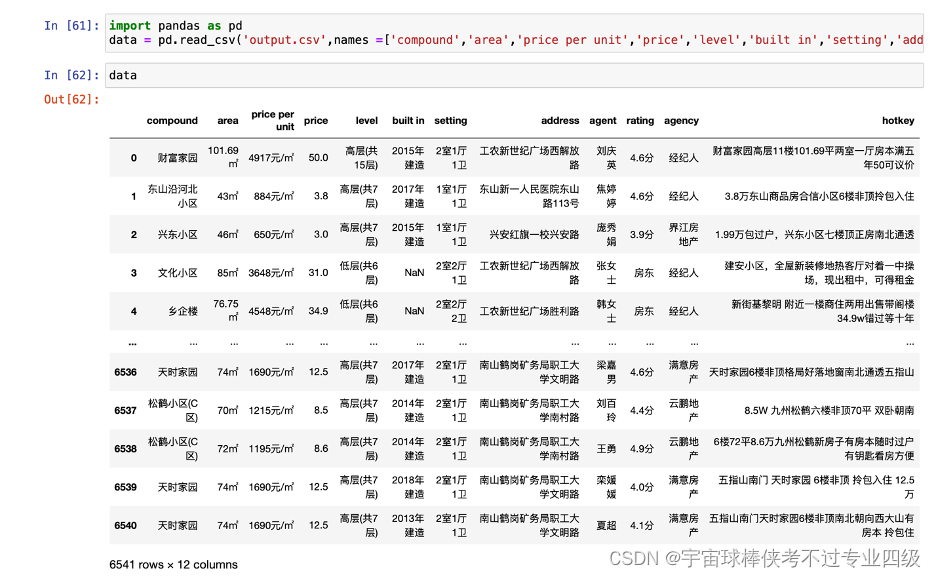
根据地址提取楼盘的地区位置信息

对面积和单价数据进行字符串的切片以及类型转换

对楼层数据进行数字的提取以及类型转换

对房屋年龄数据进行换算以及类型转换

对中介评分和中介数据进行字符串切片以及重新赋值

删除无用数据列并为地区列名重新赋值

调用pandas将DataFrame储存为csv文件

3. 数据分析
数据概览:共6541条数据,其中代理人和房屋年龄有零值
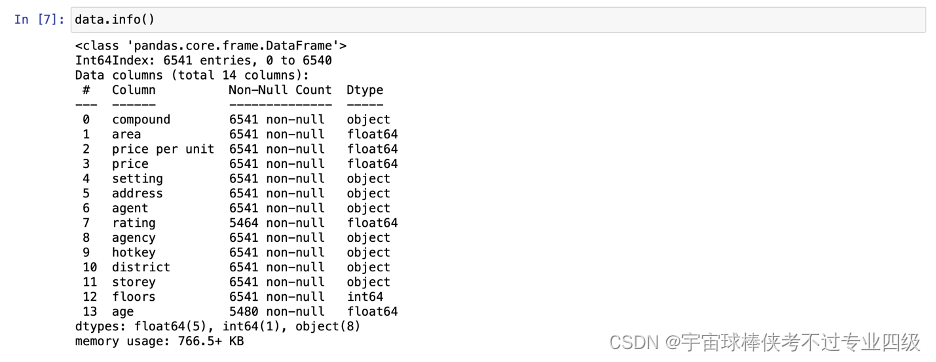
房源中面积最小为26.33平米,最大为425平米,平均面积为75.5平米,每平方米均价为1837元,最高单价为8621元,总价平均14.87万元,总层数平均为7.54层,房屋年龄平均为11.39年,经济人评分均值为4.4分
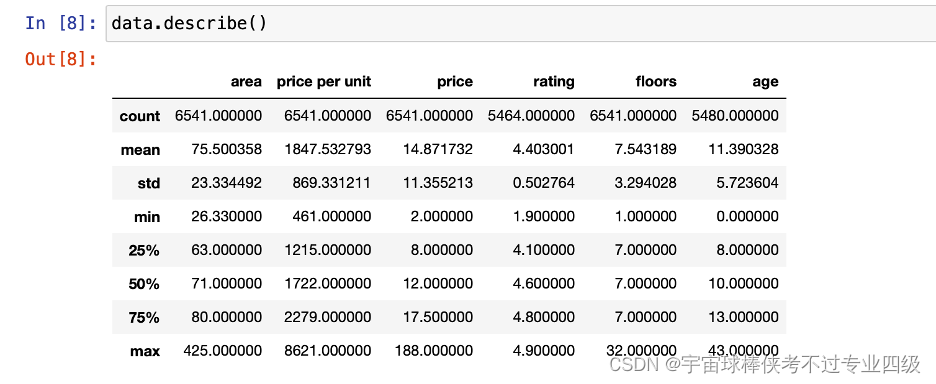
分地区查看平均单价并输出条形图
分地区查看房源平均总价
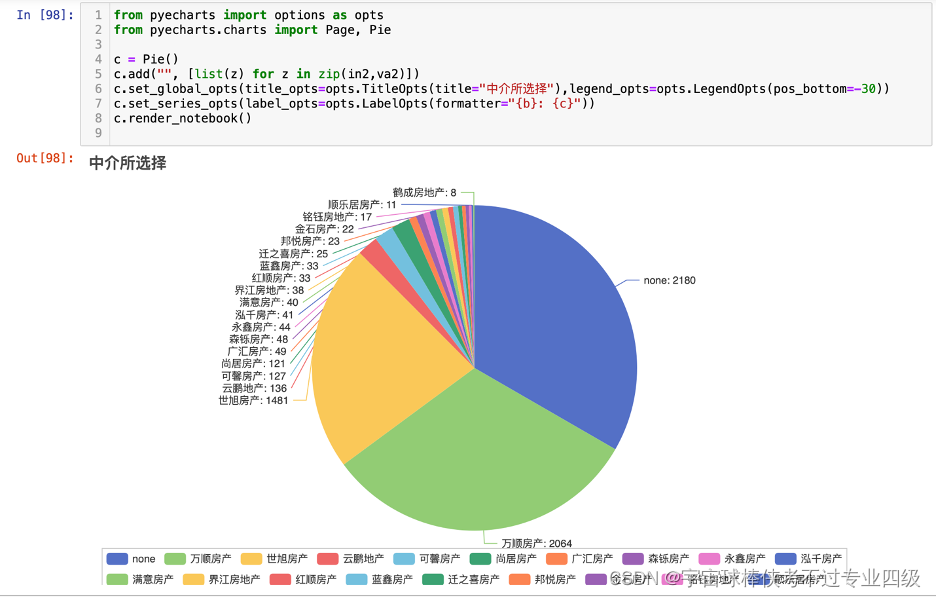
通过饼图查看中介选择
爬虫部分的代码:
import requests
from lxml import etree
import time
import random
import csv
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.3 Safari/605.1.15'}
def merge(x1,x2):
for i in x1:
x1[x1.index(i)]+=x2[x1.index(i)]
return x1
num = 1
flag = 1
while flag:
print('正在爬取第{}页'.format(num))
url = 'https://hegang.anjuke.com/sale/p{}/'.format(num)
response = requests.get(url, headers = header)
txt = response.text
dom = etree.HTML(txt)
title = dom.xpath('//div[@class="property-content-title"]/h3/text()')
if len(title)==0:
print('interrupted,current page:{}'.format(num))
time.sleep(random.randint(60,120))
continue
print('本次获得词条:{}'.format(len(title)))
if len(title)< 60:
break
size = dom.xpath('//div[@class="property-content"]/div[@class="property-content-detail"]/section/div[@class="property-content-info"]/p[2]/text()')
size = [siz.strip() for siz in size]
storey = dom.xpath('//div[@class="property-content"]/div[@class="property-content-detail"]/section/div[@class="property-content-info"]/p[4]/text()')
storey = [sto.strip() for sto in storey]
yea = [dom.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div['+str(cou)+']/a/div[2]/div[1]/section/div[1]/p[5]/text()') for cou in range(1,len(title)+1)]
year= []
for ye in yea:
if ye:
year.append(ye[0].strip())
else:
year.append('')
struc = dom.xpath('//div[@class="property-content"]/div[@class="property-content-detail"]/section/div[@class="property-content-info"]/p[1]/span/text()')
struc = [i+'卫' for i in ''.join(struc).split('卫')[:-1]]
add1 = dom.xpath('//p[@class="property-content-info-comm-address"]/span[1]/text()')
add2 = dom.xpath('//p[@class="property-content-info-comm-address"]/span[2]/text()')
add3 = dom.xpath('//p[@class="property-content-info-comm-address"]/span[3]/text()')
addre = merge(merge(add1,add2),add3)
compound = dom.xpath('//p[@class="property-content-info-comm-name"]/text()')
avg_price = dom.xpath('//p[@class="property-price-average"]/text()')
tol_price = dom.xpath('//p[@class="property-price-total"]/span[1]/text()')
agent = dom.xpath('//span[@class="property-extra-text"][1]/text()')
agent_rate = dom.xpath('//span[@class="property-extra-text"][2]/text()')t
agenc = [dom.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[' + str(cou_agenc) + ']/a/div[2]/div[1]/div[2]/div/span[3]/text()') for cou_agenc in range(1, len(title) + 1)]
agency = []
for agen in agenc:
if agen:
agency.append(agen[0])
else:
agency.append('经纪人')
data = ["This", "is", "a", "Test"]
for ind in range(1,len(title)+1):
data = [compound[ind-1],size[ind-1],avg_price[ind-1],tol_price[ind-1],storey[ind-1],year[ind-1],struc[ind-1],addre[ind-1],agent[ind-1],agent_rate[ind-1],agency[ind-1],title[ind-1]]
with open('output.csv', 'a') as file:
writer = csv.writer(file)
writer.writerow(data)
num = num+1
time.sleep(random.randint(2, 20))















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









