







-
集群容量——我们是否有足够的可用资源来运行我们的工作负载?
-
应用程序工作负载——应用程序有足够的可用资源吗?它能跟上待完成的工作吗?(像队列深度)
为了实现自动化,你通常会设置警报以获得通知,甚至使用自动伸缩。Kubernetes 是一个很好的平台,它可以帮助你实现这个即时可用的功能。
通过使用 Cluster Autoscaler 组件可以轻松地伸缩集群,该组件将监视集群,以发现由于资源短缺而无法调度的 pod,并开始相应地添加/删除节点。
因为 Cluster Autoscaler 只在 pod 调度过度时才会启动,所以你可能会有一段时间间隔,在此期间你的工作负载没有启动和运行。
Virtual Kubelet(一个 CNCF 沙箱项目)是一个巨大的帮助,它允许你向 Kubernetes 集群添加一个“虚拟节点”,pod 可以在其上调度。
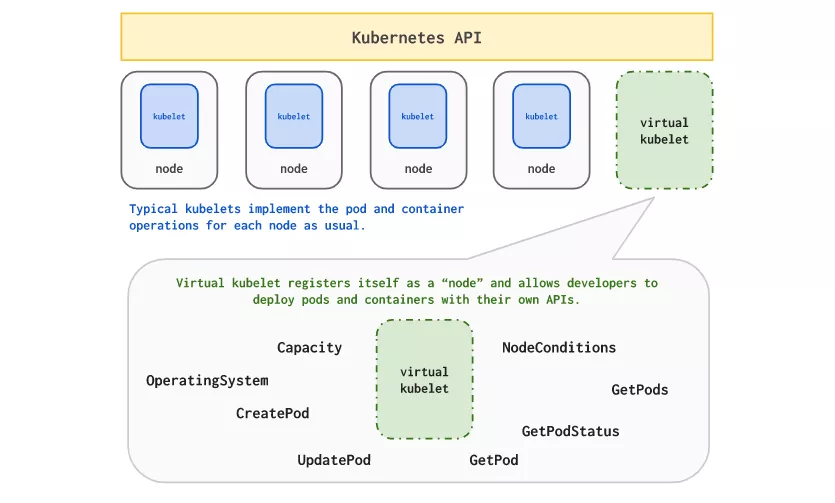
通过这样做,平台供应商(如阿里巴巴、Azure、HashiCorp 和其他)允许你将挂起的 pod 溢出到集群之
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
外,直到它提供所需的集群容量来缓解这个问题。
除了伸缩集群,Kubernetes 还允许你轻松地伸缩应用程序:
-
Horizontal Pod Autoscaler(HPA)允许你添加/删除更多的 Pod 到你的工作负载中,以 scale in/out(添加或删除副本)。
-
Vertical Pod Autoscaler(VPA)允许你添加/删除资源到你的 Pod 以 scale up/down(添加或删除 CPU 或内存)。
所有这些为你伸缩应用程序提供了一个很好的起点。
虽然 HPA 是一个很好的起点,但它主要关注 pod 本身的指标,允许你基于 CPU 和内存伸缩它。也就是说,你可以完全配置它应该如何自动缩放,这使它强大。
虽然这对于某些工作负载来说是理想的,但你通常想要基于其他地方如 Prometheus、Kafka、云供应商或其他事件上的指标进行伸缩。
多亏了外部指标支持,用户可以安装指标适配器,从外部服务中提供各种指标,并通过使用指标服务器对它们进行自动伸缩。
但是,有一点需要注意,你只能在集群中运行一个指标服务器,这意味着你必须选择自定义指标的来源。
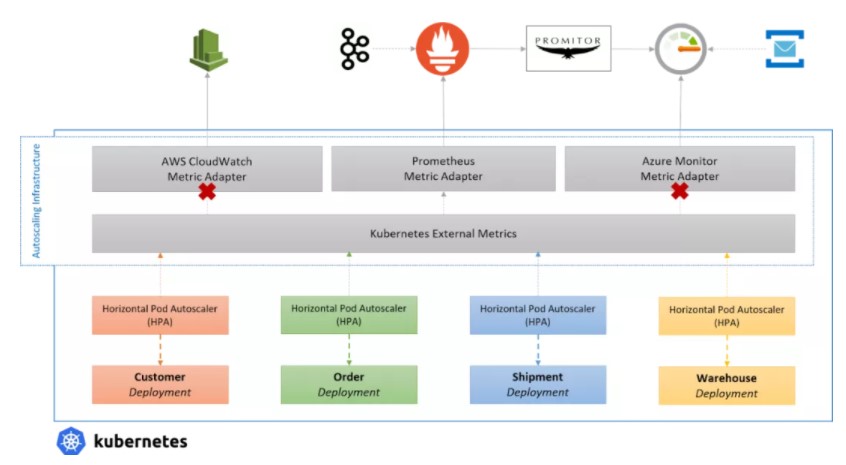
你可以使用 Prometheus 和工具,比如 Promitor,从其他提供商那里获取你的指标,并将其作为单一的真相来源来进行伸缩,但这需要大量的管道(plumbing)和工作来进行扩展。
肯定有更简单的方法……是的,使用 Kubernetes Event-Driven Autoscaling(KEDA)!
Kubernetes Event-Driven Autoscaling(KEDA)是一个用于 Kubernetes 的单用途事件驱动自动伸缩器,可以很容易地将其添加到 Kubernetes 集群中以伸缩应用程序。
它的目标是使应用程序自动扩展非常简单,并通过支持伸缩到零(scale-to-zero)来优化成本。
KEDA 去掉了所有的伸缩基础设施,并为你管理一切,允许你在 30 多个系统上进行伸缩或使用自己的伸缩器进行扩展。
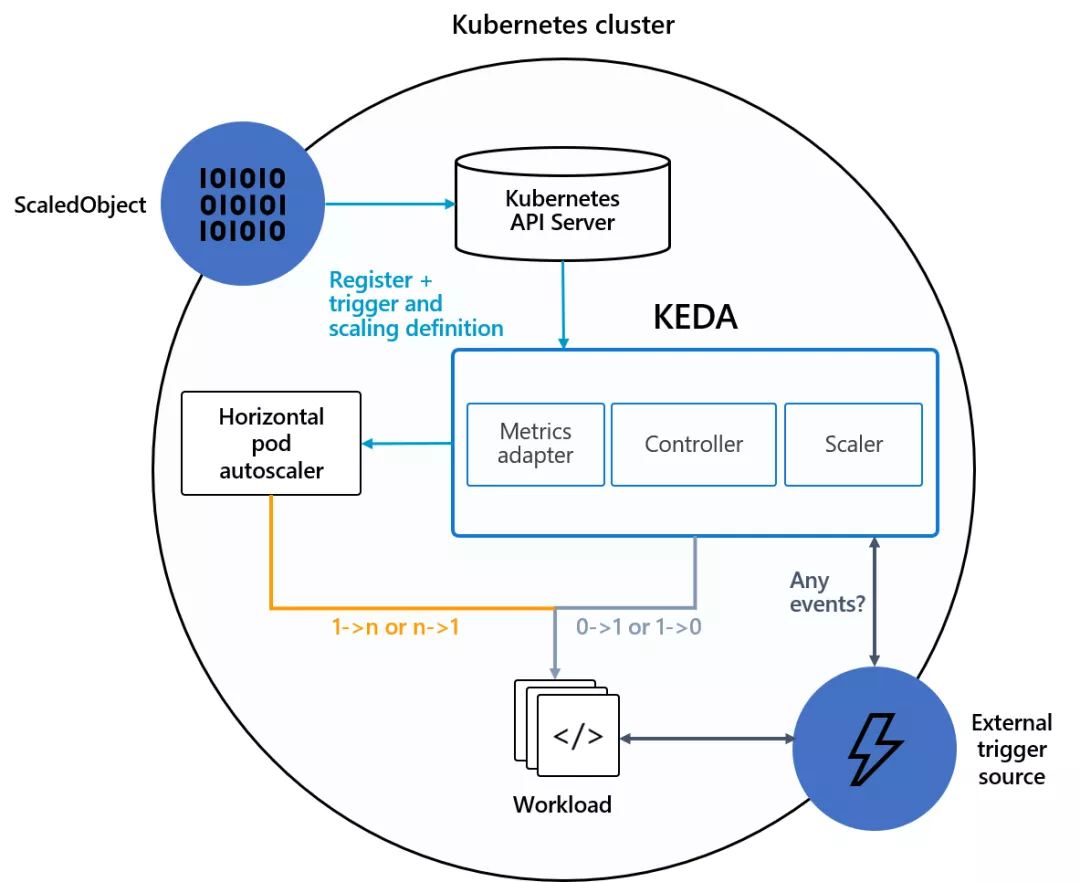
用户只需要创建 ScaledObject 或 ScaledJob 来定义你想要伸缩的对象和你想要使用的触发器;KEDA 会处理剩下的一切!
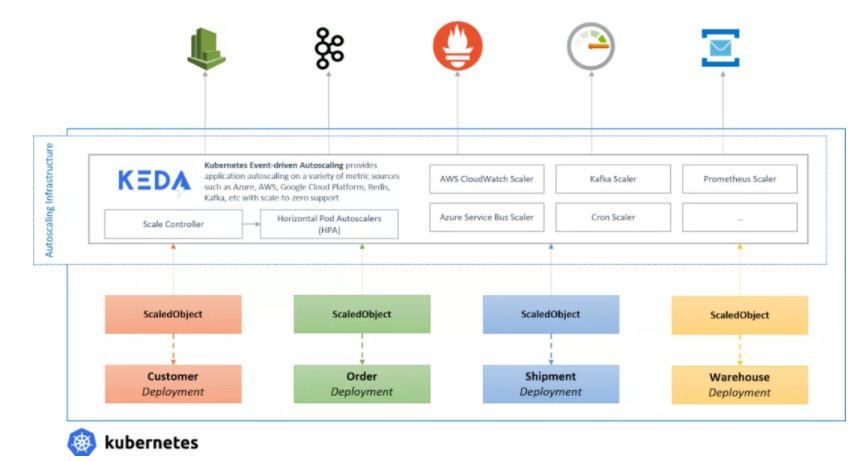
你可以伸缩任何东西;即使它是你正在使用的另一个工具的 CRD,只要它实现/scale 子资源。
那么,KEDA 重新发明轮子了吗?不!相反,它通过在底层使用 HPA 来扩展 Kubernetes,HPA 使用我们的外部指标,这些指标由我们自己的指标适配器提供,该适配器取代了所有其他适配器。
去年,KEDA 加入了 CNCF,作为 CNCF 沙箱项目,计划今年晚些时候提案升级到孵化阶段。
阿里巴巴基于 OAM/KubeVela 和 KEDA 的实践
企业分布式应用服务(EDAS)作为阿里云上的主要企业 PaaS 产品,多年来以巨大的规模服务于公有云上的无数开发者。从架构的角度来看,EDAS 是与 KubeVela 项目一起构建的。其总体架构如下图所示。
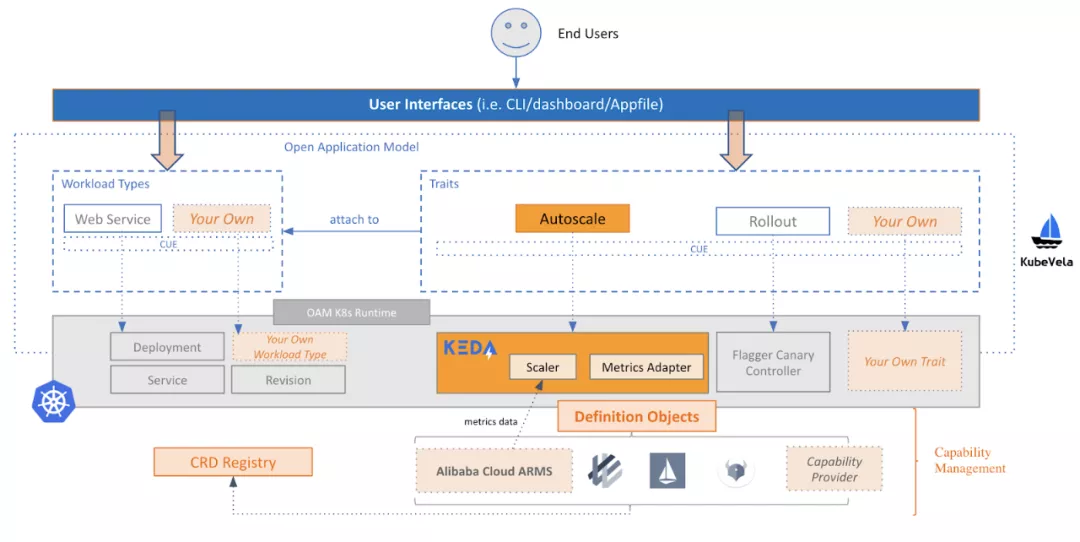
在生产上,EDAS 在阿里云上集成了 ARMS 监控服务,提供监控和应用的细粒度指标。EDAS 团队在 KEDA 项目中添加了一个 ARMS Scaler 来执行自动缩放。他们还添加了一些特性,并修复了 KEDA v1 版本中的一些 bug。包括:
-
当有多个触发器时,这些值将被求和,而不是作为单独的值留下。
-
当创建 KEDA HPA 时,名称的长度将被限制为 63 个字符,以避免触发 DNS 投诉。
-
不能禁用触发器,这可能会在生产中引起麻烦。
EDAS 团队正在积极地将这些修复程序发送给上游 KEDA,尽管其中一些已经添加到 V2 版本中。
当涉及到自动扩展特性时,EDAS 最初使用上游 Kubernetes HPA 的 CPU 和内存作为两个指标。然而,随着用户群的增长和需求的多样化,EDAS 团队很快发现了上游 HPA 的局限性:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









