







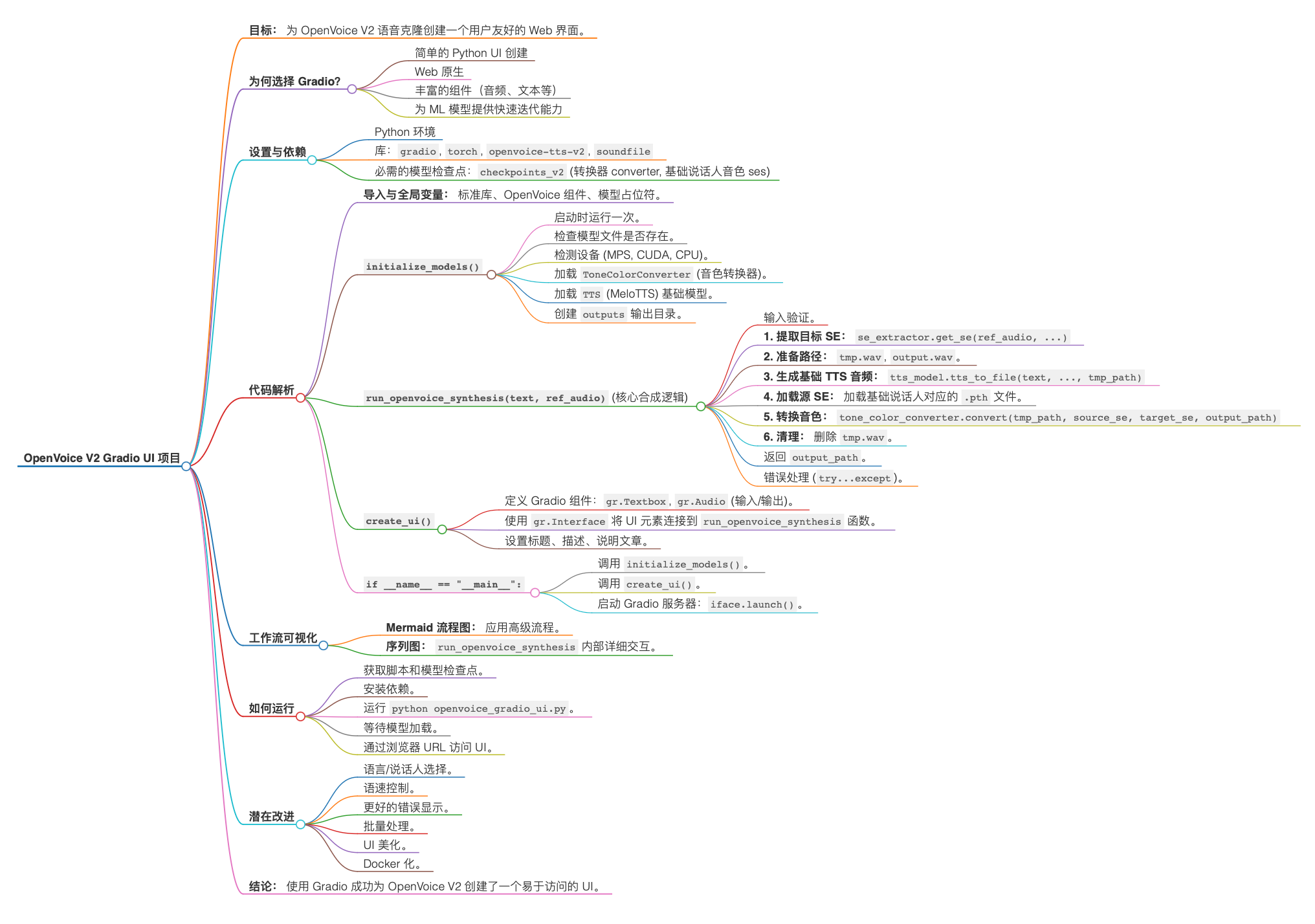
🎙️✨ DIY 语音克隆:用 Gradio 搭建一个好用的 OpenVoice V2 界面
你是否曾经摆弄过像 OpenVoice V2 这样强大的 AI 语音克隆模型,却发现自己总是在 Jupyter notebook 里来回切换?虽然 notebook 非常适合实验,但对于重复使用或分享给他人来说,它并不是最方便的选择。如果能有一个简单的网页界面,让你只需输入文本、上传参考语音,然后点击“生成”按钮,那该多酷啊?🤔
好消息!🎉 这篇博文将手把手教你如何实现这个想法:使用 Gradio 的神奇力量,为 OpenVoice V2 创建一个用户友好的 Web UI。我们将一起深入研究其背后的 Python 代码,可视化工作流程,并指导你在本地运行属于你自己的语音克隆应用程序!
为什么选择 Gradio?🤔➡️👍
Gradio 是一个非常出色的 Python 库,专为快速构建机器学习模型的 UI 而生。它在这个项目中的主要优势包括:
- 简单易用: 只需几行 Python 代码即可创建交互式演示。
- Web 原生: 自动生成可通过浏览器访问的 Web 界面。
- 组件丰富: 提供现成的文本输入、音频上传/播放、按钮等组件。
- 快速迭代: 可以轻松地将现有的 Python 函数(比如我们的 OpenVoice 逻辑)包装成 UI。
它是连接复杂 AI 模型和易用应用程序之间的完美桥梁。
项目设置与依赖 🛠️📋
在深入代码之前,请确保你准备好了以下“配料”:
- Python 环境: 一个正常工作的 Python 环境(如 Conda 或 venv)。
- 库安装: 安装所需的库:
pip install gradio torch openvoice-tts-v2 soundfile # 如果需要,添加其他依赖项 - OpenVoice V2 模型检查点: 你 必须 下载 OpenVoice V2 的模型检查点,并将它们放在相对于脚本的
checkpoints_v2目录中。脚本特别会检查以下文件:- 音色转换器模型 (
checkpoints_v2/converter/) - 至少一个基础说话人的音色嵌入 (
checkpoints_v2/base_speakers/ses/zh.pth在此示例中用于中文)
- 音色转换器模型 (
以下是脚本中使用的核心依赖项总结:
| 库 | 用途 |
|---|---|
gradio | 构建 Web UI 界面 |
torch | 核心深度学习框架(用于模型) |
openvoice-tts-v2 | OpenVoice V2 库 |
os, sys | 文件系统操作,路径管理 |
time | 测量执行时间 |
soundfile | (被 OpenVoice 隐式使用) 保存音频文件 |
代码深度解析 🧠⚙️
让我们逐段分析这个 Python 脚本 (openvoice_gradio_ui.py)。
1. 导入和设置
import os
import sys
import time
import torch
import gradio as gr
# 添加项目根目录到 Python 路径(好习惯)
current_dir = os.path.dirname(os.path.abspath(__file__))
root_dir = current_dir
sys.path.append(root_dir)
# 导入 OpenVoice 特定组件
from openvoice import se_extractor
from openvoice.api import ToneColorConverter
from melo.api import TTS # OpenVoice 使用 MeloTTS 作为基础 TTS
# 用于保存模型的全局变量
device = None
tone_color_converter = None
tts_model = None
这里包含标准的库导入,以及 OpenVoice V2 的特定组件(se_extractor, ToneColorConverter, TTS)。我们还定义了全局变量来存储加载后的模型,避免每次请求都重新加载。
2. 模型初始化 (initialize_models)
def check_model_files():
# ... (检查模型检查点文件是否存在) ...
def initialize_models():
global device, tone_color_converter, tts_model
try:
check_model_files() # 首先确保模型文件存在!
# 检测最佳可用设备 (Apple Silicon 的 MPS, CUDA, 或 CPU)
if torch.backends.mps.is_available():
device = "mps"
elif torch.cuda.is_available():
device = "cuda:0"
else:
device = "cpu"
print(f"将使用的设备 (Using device): {device}")
# 加载音色转换器 (ToneColorConverter)
ckpt_converter = 'checkpoints_v2/converter'
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
print("音色转换器加载完成")
# 加载基础 TTS 模型 (MeloTTS) - 示例使用中文
tts_model = TTS(language='ZH', device=device)
print("TTS 模型加载完成")
os.makedirs("outputs", exist_ok=True) # 创建输出目录
except Exception as e:
print(f"模型初始化失败: {str(e)}")
raise
这个函数在脚本启动时 只运行一次。
- 它检查所需的模型检查点文件是否存在。非常重要!❗
- 它智能地检测可用的最佳硬件(
mps,cuda, 或cpu)。看看对 Mac 用户的 MPS 支持!😎 - 它将
ToneColorConverter和基础TTS模型加载到全局变量中。 - 它创建一个
outputs目录用于存放生成的音频。
3. 核心逻辑 (run_openvoice_synthesis)
每次用户在 UI 中点击“提交”时,语音克隆的魔法就在这里发生。
def run_openvoice_synthesis(input_text: str, reference_audio_path: str) -> str | None: # 修改了返回类型提示
try:
# 输入验证
if not input_text or not reference_audio_path or not os.path.exists(reference_audio_path):
gr.Warning("...") # 如果输入缺失,警告用户
return None
print(f"开始合成...")
start_time = time.time()
# === OpenVoice V2 工作流程 ===
# 1. 从参考音频提取音色特征 (SE)
print("正在提取参考音频的音色特征...")
target_se, _ = se_extractor.get_se(reference_audio_path, tone_color_converter, vad=True)
# 2. 准备路径
output_dir = "outputs"
tmp_path = os.path.join(output_dir, "tmp.wav") # 用于基础语音的临时文件
output_path = os.path.join(output_dir, f"generated_audio_{int(time.time())}.wav")
# 3. 使用 MeloTTS 生成基础音频
print("正在生成基础音频...")
speaker_ids = tts_model.hps.data.spk2id
speaker_id = list(speaker_ids.values())[0] # 使用默认的基础说话人 ID
tts_model.tts_to_file(input_text, speaker_id, tmp_path, speed=1.0)
# 4. 加载基础说话人的音色特征 (SE)
print("正在加载基础说话人音色...")
speaker_key = list(speaker_ids.keys())[0].lower().replace('_', '-') # 获取对应的说话人 key
source_se = torch.load(f'checkpoints_v2/base_speakers/ses/{speaker_key}.pth', map_location=device)
# 5. 转换音色
print("正在转换音色...")
tone_color_converter.convert(
audio_src_path=tmp_path, # 基础音频路径
src_se=source_se, # 基础语音的音色
tgt_se=target_se, # 参考语音的音色
output_path=output_path, # 最终输出文件路径
message="@MyShell" # 水印/消息
)
# 6. 清理临时文件
if os.path.exists(tmp_path):
os.remove(tmp_path)
# === 工作流程结束 ===
end_time = time.time()
print(f"合成完成,耗时: {end_time - start_time:.2f} 秒")
return output_path # 返回生成音频的路径
except Exception as e:
print(f"错误:语音生成过程中发生异常: {str(e)}")
# ... (错误处理:打印 traceback, 显示 Gradio 警告) ...
return None
OpenVoice V2 流程的关键步骤清晰可见:
- 提取目标 SE: 从上传的
reference_audio_path获取独特的语音特征(音色嵌入)。 - 生成基础音频: 使用基础 TTS 模型(
MeloTTS)的标准声音,创建input_text的“中性”版本,并临时保存 (tmp.wav)。 - 加载源 SE: 加载与步骤 2 中使用的基础声音相对应的音色嵌入。
- 转换音色: 使用
ToneColorConverter将tmp.wav中的音频(具有source_se音色)转换为一个新的音频文件 (output_path),使其具有所需的target_se音色。 - 清理: 删除临时的基础音频文件。
- 返回路径: 将最终音频文件的路径发送回 Gradio 进行播放。
4. Gradio UI 创建 (create_ui)
def create_ui():
# 定义输入/输出组件
text_input = gr.Textbox(...)
audio_input = gr.Audio(type="filepath", ...) # 重要:type='filepath' 告知 Gradio 传递文件路径
audio_output = gr.Audio(type="filepath", ...)
# 使用 gr.Interface 将所有部分连接起来
iface = gr.Interface(
fn=run_openvoice_synthesis, # 点击提交时调用的函数
inputs=[text_input, audio_input], # 提供输入的 UI 组件
outputs=audio_output, # 显示输出的 UI 组件
title="OpenVoice 语音克隆系统",
description="...", # UI 描述
article="..." # 使用说明/注意事项
)
return iface
这个函数使用 Gradio 组件定义了 Web 应用的视觉元素:
gr.Textbox:用于多行文本输入。gr.Audio:一个用于上传参考音频 (type="filepath"告诉 Gradio 传递保存文件的路径),一个用于播放输出音频。gr.Interface:Gradio 的核心类,它将inputs和outputs连接到run_openvoice_synthesis函数 (fn)。它还设置了标题和描述性文本。
5. 主执行块
if __name__ == "__main__":
try:
# 在启动时 **仅一次** 初始化模型
initialize_models()
# 创建 Gradio UI 定义
iface = create_ui()
# 启动 Gradio 应用
iface.launch(
share=False, # 设置为 True 可获得临时公共链接
server_name="127.0.0.1", # 绑定到本地地址
server_port=7860,
inbrowser=True # 自动在默认浏览器中打开
)
except Exception as e:
# 捕获启动错误(例如缺少模型文件)
print(f"启动失败: {str(e)}")
import traceback
traceback.print_exc()
这个标准的 Python 入口点做了两件关键的事情:
- 在 Web 服务器启动之前调用
initialize_models()将 AI 模型加载到内存中。 - 调用
iface.launch()启动 Gradio Web 服务器,使 UI 在你的浏览器中可以访问。
可视化工作流程 📊
理解数据流和函数调用有助于更好地掌握整个过程。
Mermaid 流程图 (高级流程)
序列图 (展示 run_openvoice_synthesis 内部详细交互)
如何运行它 🚀
- 克隆/下载: 获取 Python 脚本 (
openvoice_gradio_ui.py) 和 OpenVoice V2 的checkpoints_v2目录。确保它们处于正确的相对路径结构中。 - 安装依赖: 确保你已安装 Python 和所有必需的库 (
pip install gradio torch openvoice-tts-v2 soundfile)。 - 从终端运行: 切换到包含脚本的目录,然后运行:
python openvoice_gradio_ui.py - 等待模型加载: 脚本将首先加载模型(可能需要一点时间)。你会看到类似“音色转换器加载完成”和“TTS 模型加载完成”的日志消息。
- 访问 UI: 加载完成后,它会打印一个本地 URL(例如
http://127.0.0.1:7860)。脚本配置为自动在你的默认 Web 浏览器中打开此 URL。 - 开始使用: 输入文本,上传一个
.wav或.mp3参考音频文件,然后点击“提交”!享受你克隆的声音吧。🔊
潜在的改进方向 💡
这个 UI 提供了一个坚实的基础。以下是一些可以增强功能的想法:
- 语言/说话人选择: 允许用户选择基础 TTS 模型的语言或说话人。
- 语速控制: 添加一个滑块来控制语速。
- 错误详情: 在 UI 中提供更具体的错误信息。
- 批量处理: 允许上传多个文本或一个文件进行批量合成。
- UI 美化: 自定义 Gradio 界面的外观。
- Docker 化: 将应用程序和依赖项打包到 Docker 容器中,以便于部署。
总结 🎉
我们成功地将强大的 OpenVoice V2 语音克隆功能,从以代码为中心的工作流程,转变成了一个使用 Gradio 构建的直观 Web 应用程序。这个脚本展示了如何轻松地为复杂的 AI 模型构建交互式演示,使其能够被更广泛的受众访问(或者只是让你自己的生活更轻松!)。
随意修改和增强此代码吧。祝你语音克隆愉快!
思维导图 (Markdown 格式) 🧠
希望这篇技术博客对你有帮助!



















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









