







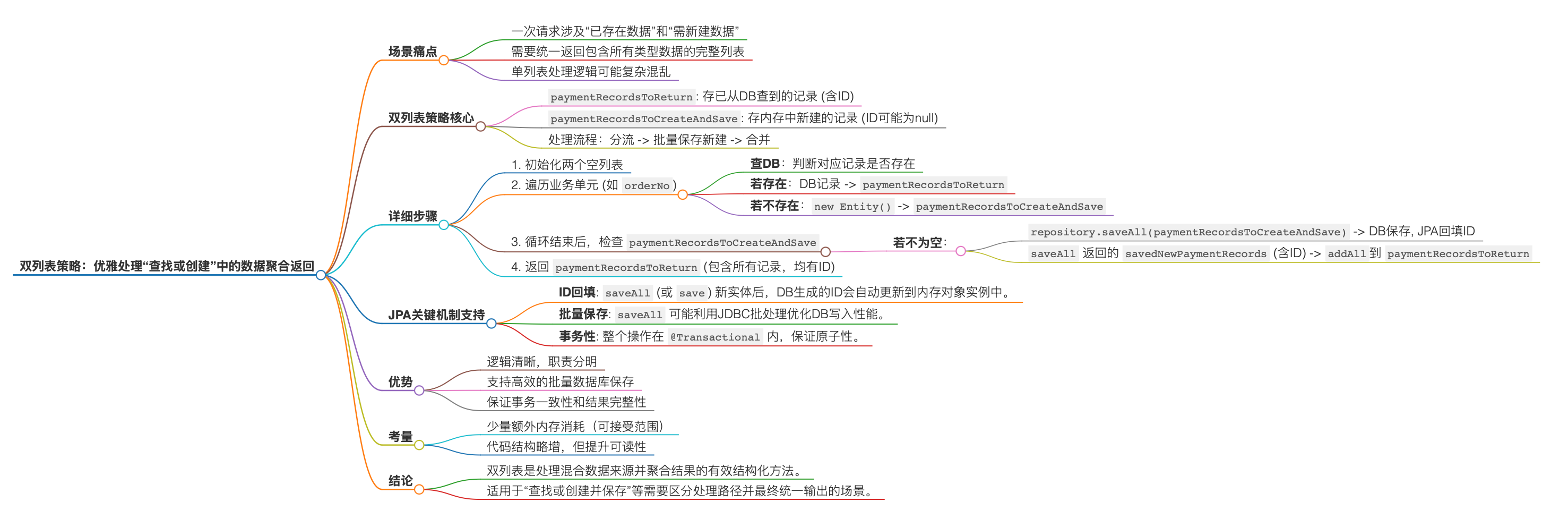
🛠️ 双列表出击:优雅处理“查找或创建”中的数据聚合返回 ✨
嗨,各位代码工匠们!👋 在我们日常的后端开发中,经常会遇到一种经典的业务场景:“查找或创建”(Find or Create)。简单来说,就是系统需要检查某个数据是否存在,如果存在就使用它,如果不存在就创建一条新的。当这个操作涉及到批量处理,并且最终需要返回一个包含所有相关数据(无论是查到的还是新建的)的完整列表时,如何优雅地组织代码就成了一个有趣的小挑战。
今天,我们就来深入探讨一种实用的策略——使用“双列表”来清晰地管理和聚合数据,特别是在结合JPA (Java Persistence API,Java持久化API) 进行数据库操作的场景下。我们将通过一个“生成并保存付款记录”的实例,看看双列表如何帮助我们条理清晰地搞定数据聚合与返回!
📝 本文概要 (Table of Contents)
| 序号 | 主题 | 简要说明 |
|---|---|---|
| 1 | 🤔 场景痛点:混合数据的聚合难题 | 当一次请求可能同时涉及“已存在数据”和“需新建数据”时,如何统一返回? |
| 2 | 💡 双列表策略:各司其职,最后汇总 | 引入两个列表:一个存放“已存在”的,一个存放“待新建”的,最终合并。 |
| 3 | ⚙️ 核心流程:分流处理,统一归集 | 详细拆解双列表策略下的数据处理步骤。 |
| 4 | 流程图:“双轨制”数据流向图 | 使用Mermaid流程图直观展示数据如何通过两个列表最终汇聚。 |
| 5 | 时序图:交互的“协奏曲”——双列表与数据库 | 使用Mermaid时序图动态描绘双列表模式下,代码与数据库的交互细节。 |
| 6 | 🧐 代码实例剖析:generateAndSavePaymentRecordsBySettlementId | 结合具体代码,看双列表如何在“付款记录生成”场景中发挥作用。 |
| 7 | ✨ 双列表的优势与考量 | 总结该策略带来的好处(如清晰性、支持批量保存)及潜在的优化点。 |
| 8 | 🌟 结论:结构化思维应对复杂聚合 | 强调良好代码结构对处理复杂逻辑的重要性。 |
| 9 | 🧠 思维导图 | 使用Markdown思维导图梳理双列表策略的关键点。 |
🤔 1. 场景痛点:混合数据的聚合难题
想象一下我们的业务需求:根据一个“结算ID”,我们要处理其下所有相关的“订单号”(orderNo),为每个订单号生成或获取一个“付款记录”(PaymentRecord)。
- 对于某些订单号,对应的
PaymentRecord可能已经存在于数据库中。 - 对于另一些订单号,
PaymentRecord不存在,需要我们根据业务规则创建一条新的,并将其保存到数据库。
最终,前端API (Application Programming Interface,应用程序编程接口) 的调用者期望收到一个完整的列表,这个列表应该包含该“结算ID”下所有订单号对应的 PaymentRecord——无论是那些从数据库直接“捞”出来的老朋友,还是那些刚刚“新鲜出炉”并存盘的新成员。
如果只用一个列表来操作,代码逻辑可能会变得复杂和混乱,尤其是在区分哪些需要保存、哪些已经包含了ID、何时合并等问题上。
💡 2. 双列表策略:各司其职,最后汇总
为了解决这个聚合难题,我们可以引入“双列表”策略:
-
paymentRecordsToReturn(返回结果聚合列表):- 这个列表的最终目标是收集所有要返回给前端的
PaymentRecord对象。 - 当发现某个订单号的
PaymentRecord已存在于数据库时,我们会将从数据库查询到的这个对象直接添加到这个列表中。
- 这个列表的最终目标是收集所有要返回给前端的
-
paymentRecordsToCreateAndSave(待新建并保存列表):- 这个列表用于临时存放那些在数据库中不存在,因此需要在内存中新创建的
PaymentRecord对象。 - 这些对象在刚创建时,如果其
id是数据库自增生成的,那么它们的id属性通常是null。
- 这个列表用于临时存放那些在数据库中不存在,因此需要在内存中新创建的
核心思想:在遍历处理所有订单号的过程中,根据记录是否存在,将它们“分流”到这两个不同的列表中。在所有订单号都处理完毕后,对 paymentRecordsToCreateAndSave 列表中的对象执行批量保存操作。JPA的 saveAll 方法在保存后会返回一个列表,其中包含了这些新保存的、并且其 id 已经被数据库生成并回填的对象。最后,将这个包含新保存对象的列表中的所有元素,也添加到 paymentRecordsToReturn 列表中。这样,paymentRecordsToReturn 就成为了我们期望的完整结果集。
⚙️ 3. 核心流程:分流处理,统一归集
采用双列表策略,数据处理流程可以概括为:
- 初始化:创建两个空的
ArrayList:paymentRecordsToReturn和paymentRecordsToCreateAndSave。 - 数据获取与分组:查询相关的基础数据(例如,从
ConsignmentSummary表获取记录),并按orderNo进行分组。 - 遍历与分流:对于每个
orderNo分组:- 检查存在性:查询数据库,看当前
orderNo的PaymentRecord是否已存在。 - 已存在路径:如果存在,将从数据库获取的
PaymentRecord对象(它已经有id)直接添加到paymentRecordsToReturn。然后处理下一个orderNo。 - 不存在路径:如果不存在,则:
- 在内存中根据业务规则创建一个新的
PaymentRecord对象。 - 将这个新创建的(此时
id可能为null)PaymentRecord对象添加到paymentRecordsToCreateAndSave。
- 在内存中根据业务规则创建一个新的
- 检查存在性:查询数据库,看当前
- 批量保存新记录:在所有
orderNo都处理完毕后,检查paymentRecordsToCreateAndSave列表是否为空。- 如果不为空,调用
paymentRecordRepository.saveAll(paymentRecordsToCreateAndSave)。此方法会将这些新对象保存到数据库,并且JPA的ID回填机制会确保返回的列表(我们称之为savedNewPaymentRecords)中的对象,其id属性已经被数据库生成的实际值填充。
- 如果不为空,调用
- 最终聚合:将
savedNewPaymentRecords中的所有元素通过paymentRecordsToReturn.addAll(savedNewPaymentRecords)添加到paymentRecordsToReturn。 - 返回结果:
paymentRecordsToReturn现在包含了所有相关的PaymentRecord对象,无论是先前已存在的还是新创建并保存的,并且它们都拥有有效的数据库id。
📊 4. 流程图:“双轨制”数据流向图
流程图解读:
此图清晰地展示了数据是如何根据其“存在状态”被导向不同的临时列表,以及新创建的数据如何经过保存和ID回填步骤后,最终与已存在的数据合并,形成统一的输出。
⏳ 5. 时序图:交互的“协奏曲”——双列表与数据库
时序图解读:
该图详细描绘了在循环中如何根据数据库查找结果将数据分别放入paymentRecordsToReturn或paymentRecordsToCreateAndSave。关键在于循环结束后的saveAll操作,以及随后将新保存的记录(此时已包含ID)合并回paymentRecordsToReturn的步骤。
🧐 6. 代码实例剖析:generateAndSavePaymentRecordsBySettlementId
让我们回顾一下PaymentRecordService中的核心代码片段:
// 初始化双列表
List<PaymentRecord> paymentRecordsToReturn = new ArrayList<>();
List<PaymentRecord> paymentRecordsToCreateAndSave = new ArrayList<>();
for (Map.Entry<String, List<ConsignmentSummary>> entry : summariesGroupedByOrderNo.entrySet()) {
String currentOrderNo = entry.getKey();
// ...
Optional<PaymentRecord> existingRecordOpt = paymentRecordRepository.findByOrderNoAndConsignmentSettlementIdAndAdminId(
currentOrderNo, consignmentSettlementId, adminId
);
if (existingRecordOpt.isPresent()) {
// 已存在:直接加入 paymentRecordsToReturn
log.info("订单号 {} ... 的付款记录已存在,直接添加到返回结果。", currentOrderNo, ...);
paymentRecordsToReturn.add(existingRecordOpt.get());
continue; // 处理下一个 orderNo
}
// 不存在:创建新对象并加入 paymentRecordsToCreateAndSave
PaymentRecord newPaymentRecord = new PaymentRecord();
// ... 设置 newPaymentRecord 的属性 ...
log.debug("订单号 {} ... 的付款记录不存在,创建新的实例。", currentOrderNo, ...);
paymentRecordsToCreateAndSave.add(newPaymentRecord);
}
// 循环结束后,批量保存新创建的记录
if (!paymentRecordsToCreateAndSave.isEmpty()) {
List<PaymentRecord> savedNewPaymentRecords = paymentRecordRepository.saveAll(paymentRecordsToCreateAndSave);
log.info("成功保存 {} 条新的付款记录。", savedNewPaymentRecords.size());
// 将新保存的、已包含ID的记录合并到最终返回列表
paymentRecordsToReturn.addAll(savedNewPaymentRecords);
}
return paymentRecordsToReturn; // 返回包含了所有情况的完整结果
这段代码完美地体现了双列表策略:
paymentRecordsToReturn负责收集那些“从数据库直接拿来就能用”的记录。paymentRecordsToCreateAndSave充当一个“暂存区”,收集所有新兵蛋子,等待统一“入伍”(保存到数据库)。- 最后通过
addAll完成大会师,确保paymentRecordsToReturn包含了沙场老将和刚刚授勋(获得ID)的新兵。
✨ 7. 双列表的优势与考量
优势:
- 逻辑清晰:代码职责分明。查找、创建、保存、合并的步骤非常清晰,易于理解和维护。
- 支持批量保存 (Batch Save):通过将所有新创建的对象收集到
paymentRecordsToCreateAndSave后再调用saveAll,可以利用JPA和数据库的批量处理能力,这通常比在循环中对每个新对象单独调用save更高效(减少数据库交互次数)。 - 事务一致性:整个方法通常在一个事务(
@Transactional)内执行。无论是查找、创建还是保存,要么全部成功,要么在出错时全部回滚,保证了数据的一致性。 - 结果完整性:确保了最终返回给调用者的列表包含了所有应该处理的记录,并且每条记录都有其在数据库中的唯一标识
id。
考量:
- 内存消耗:如果一次请求需要处理的订单号数量非常巨大,那么
paymentRecordsToCreateAndSave列表可能会在保存前占用较多内存。但在典型的Web应用场景下,这通常不是主要瓶颈。 - 代码略微冗长:相比于某些极简的单列表处理方式(可能逻辑更绕),双列表会多几行代码,但换来的是可读性和可维护性的提升。
🌟 8. 结论:结构化思维应对复杂聚合
在处理可能涉及多种数据来源(如已存在于DB vs. 需新建)并需要统一聚合返回的业务场景时,采用“双列表”策略是一种非常实用且结构清晰的方法。它使得我们能够有条不紊地处理每种情况,并最终得到一个完整、准确的结果集。
这种分而治之、先分流再汇总的思路,不仅适用于当前“查找或创建并保存”的场景,也可以推广到其他需要对数据进行分类处理和最终聚合的复杂逻辑中。用清晰的结构来驾驭复杂性,是每个优秀代码工匠的追求!💪
🧠 9. 思维导图
希望这篇博客能够帮助您更好地理解和运用“双列表”策略来构建更清晰、更健壮的后端服务!🎉



















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









