







目录
引言
- 数据处理的两个基本问题是:
- 要处理的数据有多长?
- 处理的数据在哪?
定义的描述性符号:reg和sreg
reg表示一个寄存器,sreg表示一个段寄存器。
reg的集合包括:ax、bx、cx、dx、ah、al、bh、bl、ch、cl、dh、dl、sp、bp、si、di;
sreg的集合包括:ds、ss、cs、es。
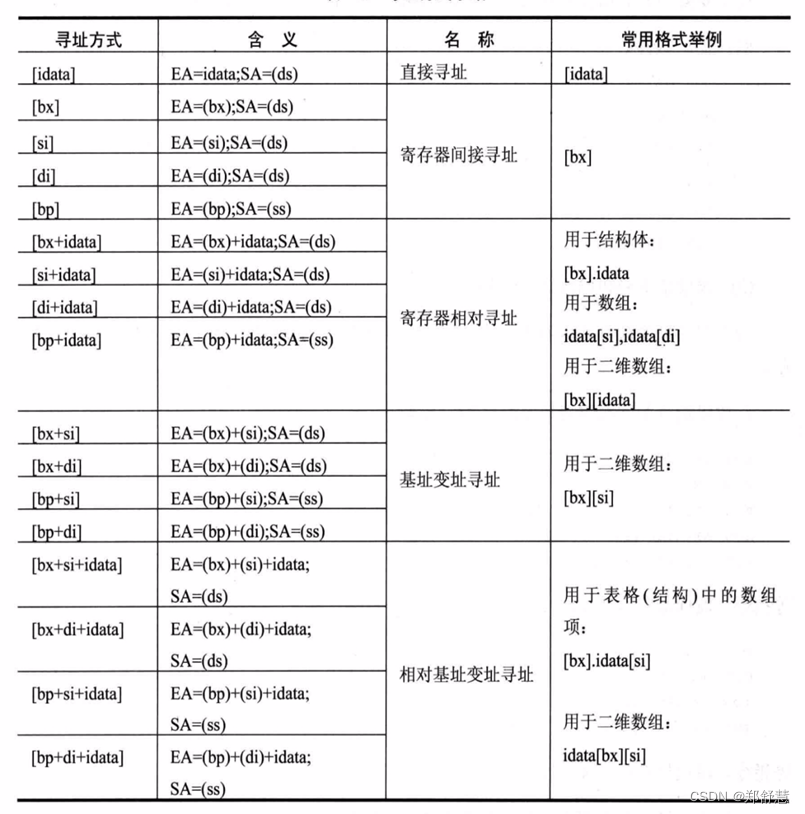
8.1 bx、si、di和bp
在8086 CPU中只有bx、si、di、bp这四个寄存器用在[ ]中进行内存单元寻址。在[...]中,这4个寄存器可以单个出现,或只能以四种组合出现:bx和si、bx和di、bp和si、bp和di。只要在[...]中使用寄存器bp,而指令中没有显性地给出段地址,段地址就默认在ss中。
正确的指令
mov ax,[bx]
mov ax,[si]
mov ax,[di]
mov ax,[bp]
mov ax,[bx+si]
mov ax,[bx+di]
mov ax,[bp+si]
mov ax,[bp+di]
mov ax,[bx+si+idata]
mov ax,[bx+di+idata]
mov ax,[bp+si+idata]
mov ax,[bp+di+idata]
以下指令是错误的
mov ax,[ax]
mov ax,[cx]
mov ax,[dx]
mov ax,[ds]
mov ax,[bx+bp]
mov ax,[si+di]
8.2 机器指令处理的数据在什么地方
绝大部分机器指令都是进行数据处理的指令,处理大致可以分为3类:读取、写入、运算。
指令在执行前,所要处理的数据可以在三个地方:CPU内部、内存、端口。
| 机器码 | 汇编指令 | 指令执行前数据的位置 |
| 8E1E0000 | mov bx,[0] | 内存,ds:0单元 |
| 89C3 | mov bx,ax | CPU内部,ax寄存器 |
| BB0100 | mov bx,1 | CPU内部,指令缓冲器 |
8.3 汇编语言中数据位置的表达
汇编语言中用三个概念来表达数据的位置。
(1)立即数(idata)
对于直接包含在机器指令中的数据(执行前在CPU的指令缓冲器中),在汇编语言中称为:立即数(idata),在汇编指令中直接给出。
(2)寄存器
指令要处理的数据在寄存器中,在汇编指令中给出相应的寄存器名。
(3)段地址(SA)和偏移地址(EA)
指令要处理的数据在内存中,在汇编指令中可用[X]的格式给出EA,SA在某个段寄存器中。
8.4 寻址方式
当数据存放在内存中的时候,我们可以用多种方式来给定这个内存单元的偏移地址,这种定位内存单元的方法一般被称为寻址方式。
8.5 指令要处理的数据有多长
8086 CPU可以处理byte和word两种尺寸的数据。因此在机器指令中要指明:指令进行的是字操作还是字节操作。
(1)通过寄存器指明要处理的数据尺寸;
- ax、bx、cx、dx等寄存器说明是字操作;而al、bl等是字节操作。
(2)若没有寄存器名存在的情况下,用操作符word ptr或者byte ptr指明内存单元的长度;
例如:下面的指令中,用word ptr指明了指令访问的内存单元是一个字单元。
mov word ptr ds:[0],1
inc word ptr [bx]
inc word ptr ds:[0]
add word ptr [bx],2
例如:下面的指令中,用byte ptr指明了指令访问的内存单元是一个字单元。
mov byte ptr ds:[0],1
inc byte ptr [bx]
inc byte ptr ds:[0]
add byte ptr [bx],2
假设内存2000:1000 FF FF FF FF FF FF ……
如果用以下指令:
mov ax,2000H
mov ds,ax
mov byte ptr [1000H],1
那么内存中的内容变为:2000:1000 01 FF FF FF FF FF ……
如果是用以下指令:
mov ax,2000H
mov ds,ax
mov word ptr [1000H],1
那么内存中的内容变为:2000:1000 01 00 FF FF FF ……
(3)有些指令默认访问的是字单元还是字节单元。
如:push指令只进行字操作。
8.6 寻址方式的综合应用

初步汇编代码
mov ax,seg
mov ds,ax
mov bx,60h ;确定记录物理地址:ds:bx
mov word ptr [bx+0ch],38 ;寄存器相对寻址 排名字段改为38
add word ptr [bx+0eh],70 ;收入字段增加70
mov si,0 ;用si来定位产品字符串中的字符
mov byte ptr [bx+10h+si],'V' ;相对基址变址寻址
inc si
mov byte ptr [bx+10h+si],'A'
inc si
mov byte ptr [bx+10h+si],'X'
c语言描述
struct company /*定义一个公司记录的结构体*/
{
char cn[3]; /*公司名称*/
char hn[9]; /*总裁姓名*/
int pm; /*排名*/
int sr; /*收入*/
char cp[3]; /*著名产品*/
};
struct compant dec={"DEC","Ken Olsen",137,40,"PDF"};
/*定义一个公司记录的变量,内存中将存有一条公司的记录*/
mian()
{
int i;
dec.pm=38;
dec.sr=dec.sr+70;
i=0;
dec.cp[i]='V';
i++;
dec.cp[i]='A';
i++;
dec.cp[i]='X';
return 0;
}
按照c语言的风格用汇编写
mov ax,seg
mov ds,ax
mov bx,60h ;记录首地址送入bx
mov word ptr [bx].0ch,38 ;排名字段改为38
add word ptr [bx].0eh,70 ;收入字段增加70
;产品名字段改为字符串'VAX'
mov si,0
mov byte ptr [bx].10h[si],'V'
inc si
mov byte ptr [bx].10h[si],'A'
inc si
mov byte ptr [bx].10h[si],'X'
多种寻址方式为结构化数据的处理提供了方便。
一般用[bx+idata+si]的方式来访问结构体中的数据。用bx定位整个结构体,用idata定位结构体中的某一数据项,用si定位数组项中的每个元素。 例如:[bx].idata、[bx].idata[si]。
8.7 div指令
div是除法指令,使用div做除
法的时候应该注意以下问题:
(1)除数:8位或16位,在寄存器或内存单元中;
(2)被除数:默认放在AX或DX和AX中。如果除数为8位,被除数则为16位,默认在AX中存放;如果除数为16位,被除数则为32位,默认在DX和AX中存放,DX存放高16位,AX存放低16位。
| 除数 | 被除数 |
| 8位 | 16为(AX) |
| 16位 | 32位(DX高16位+AX低16位) |
(3)结果:如果除数为8位,则AL存储除法操作的商,AH存储除法操作的余数;如果除数为16位,则AX存储除法操作的商,DX存储除法操作的余数。
| 运算 | 8位 | 16位 |
| 商 | AL | AX |
| 余数 | AH | DX |
格式为:
div reg(寄存器)
div 内存单元
div byte ptr ds:[0]
div byte ptr [bx+si+idata]
;al放商,ah放余数
div word ptr es:[0]
div word ptr [bx+si+idata]
;ax放商,dx放余数
利用除法指令计算100001/100编程
;被除数100001大于2^16=65535(FFFF),不能用ax来存放,要用dx和ax两个寄存器联合存放。除数小于255,可用一个8位寄存器存放,但是被除数是32位的,除数应为16位,所以要用一个16位寄存器来存放除数。
;100001的十六进制为186A1H,100001的高16位(1)存放在dx,低16位(86AH)存放在ax中。
mov dx,1
mov ax,86A1H ;(dx)*10000H+(ax)=100001
mov bx,100
div bx
;执行后ax内容等于03E8H(即1000),dx的值等于1(余数)。
利用除法指令计算1001/100编程
;被除数1001用ax来存放,除数100可用8位寄存器来存放。
mov ax,1001
mov bl,100
div bl
;执行后(al)=0AH(即10),(ah)=1(余数)。
8.8 伪指令dd
db定义字节型数据,dw定义字型数据,dd 定义 dword(double word双字型数据)
data segment
db 1
dw 1
dd 1
data ends
- 第一个数据为01h,在data:0处,占1个字节
- 第二个数据为0001h,在data:1处,占1个字
- 第三个数据为00000001h,在data:3处,占2个字
利用除法指令计算 dd 100001H 除以 dw 100,商放在 dw 0中
data segment
dd 100001 ;低16位存储在ax中,高16位存储在dx中
dw 100
dw 0
data ends
mov ax,data
mov ds,ax
mov ax,ds:[0] ;低16位存储在ax中
mov dx,ds:[2] ;高16位存储在dx中
div word ptr ds:[4]
mov ds:[6],ax
8.9 dup
和db、dw、dd等数据定义伪指令配合使用,用来进行数据的重复。
使用格式:
db 重复的次数 dup(重复的字节型数据)
dw 重复的次数 dup(重复的字型数据)
dd 重复的次数 dup(重复的双字型数据)
例如:
db 3 dup(0)
;定义了3个字节,它们的值都是0,等同于db 0,0,0。
db 3 dup(0,1,2)
;定义了9个字节,它们是0、1、2、0、1、2、0、1、2,相当于db 0、1、2、0、1、2、0、1、2
db 3 dup('abc','ABC')
;定义了18个字节,它们是'abcABCabcABCabcABC'



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











