







一、实验目的
1. 理解分治法的基本思想。
2. 掌握分治算法解决问题的步骤。
3. 掌握使用分治法解决问题的能力。
二、实验环境
1. 操作系统:Windows 10及以上。
2. 程序设计软件:Microsoft Visual C++、Microsoft Visual Studio或DEV C++等。
三、实验要求
1. 完整记录实验过程,包括算法设计思想描述、代码实现和程序测试。
2. 按照实验内容编写相应功能的程序,记录完成步骤、结果及在实验过程中所遇到的问题。
四、实验内容
1. 对于含有n个元素的数组分别使用快速排序和归并排序对其元素值按照递增排序。描述算法设计思想,编写完整的实验程序,并采用相应数据进行测试。
2. 对于递增有序的数组a,使用折半查找指定元素。描述算法设计思想,编写完整的实验程序,并采用相应数据进行测试。
3. 给定一个有n(n≥1)个整数的序列,求出其中最大连续子序列的和。 例如:序列(-2,11,-4,13,-5,-2)的最大子序列和为20,序列(-6,2,4,-7,5,3,2,-1,6,-9,10,-2)的最大子序列和为16。规定一个序列最大连续子序列和至少是0(长度为0的子序列),如果小于0,其结果为0。描述算法设计思想,编写完整的实验程序,并采用相应数据进行测试。
4. 编写一个程序查找假币问题,有n(n>3)个硬币,其中有一个是假币,且假币较轻,采用天平称重方式找到这个假币,并给出操作步骤。描述算法设计思想,编写完整的实验程序,并采用相应数据进行测试。
5. 编写程序对递增有序序列a求众数,并输出元素出现的次数(重数)。描述算法设计思想,编写完整的实验程序,并采用相应数据进行测试。
6. 设X和Y都是n(为了简单,假设n为2的幂,且X、Y均为正数)位的二进制整数,采用分治法来设计一个大整数乘积算法。描述算法设计思想,编写完整的实验程序,并采用相应数据进行测试(选做)。
1. 快速排序:
算法设计思想描述:
序列至少存在两个元素的情况,取第一个元素作为一个基准将序列分成两部分,所有小于基准的放前面,所有大于基准的放后面,基准放中间,两端交替扫描,小于基准的前移,大于基准的后移,左右子序列递归排序,即快速排序。
代码实现:
#include<stdio.h>
void disp(int a[],int n)//输出序列a所有元素
{
int i;//定义i为整型变量
for(i=0;i<n;i++)//通过for循环依次输出
printf("%d",a[i]);
printf("\n");
}
int Partition(int a[],int s,int t)//Partition划分算法标志
{
int i=s,j=t;//设s、t分别为序列前部分元素、后部分元素
int temp=a[s];//a[s]是划分的基准位置
while(i!=j)//当i不等于j时//从序列两端向中间交替扫描,直到i=j,跳出循环
{
while(j>i&&temp<=a[j])//当同时满足j大于i和基准temp小于元素a[j]时,从右到左扫描,j减1,a[j]前移到a[i]位置
j--;
a[i]=a[j];
while(i<j&&temp>=a[i])//当同时满足j大于i和基准temp大于元素a[i]时,从左到右扫描,i加1,a[i]后移到a[j]位置
i++;
a[j]=a[i];
}
a[i]=temp;//a[i]归位
return i;
}
int QuickSort(int a[],int s,int t)//QuickSort快排算法标志//对a[s...t]序列进行递增排序
{
if(s<t)//至少存在两个元素//s=t时存在一个//s>t存在0个
{
int i=Partition(a,s,t);//将整个数组分成小于基准值的左边,和大于基准值的右边
QuickSort(a,s,i-1);//对左子序列递归排序
QuickSort(a,i+1,t);//对右子序列递归排序
}
}
int main()
{
int n=10;
int a[]={6,3,9,4,2,8,7,1,10,5};
printf("排序前:");
disp(a,n);// 输出数据
QuickSort(a,0,n-1);//0到n-1次快速排序
printf("排序后:");
disp(a,n);// 输出数据
}
程序测试:
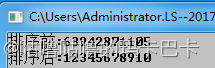
归并排序:
算法设计思想描述:
先输出序列里的元素,分配空间存储交换,使用内置函数Merge实现函数排序和合并,分奇数偶数情况去分子表的组合,将子表先两两排序成为两个有序子表,再将相邻有序子表合并成一个有序临时子表,最后剩两个子表,归并完成排序。
代码实现:
#include<stdio.h>
#include<malloc.h>
void disp(int a[],int n)//输出a中的所有元素,n为元素数量,a为序列名
{
int i;//i为a中元素值
for(i=0;i<n;i++)//通过for循环输出序列a中的元素
printf("%d",a[i]);
printf("\n");
}
void Merge(int a[],int low,int mid,int high)
//Merge函数作用是实现函数排序和合并
//将a[low..mid]和a[mid+1..high]两个相邻有序子序列合并为有序子序列a[low..high]
{
int *temp;//指针类型的临时变量,指向内存的一个地址
int i=low,j=mid+1,k=0;
//i为a[low..mid]子表的下标,j为a[mid+1..high]子表的下标,k是temp的下标
temp=(int *)malloc((high-low+1)*sizeof(int));
//表示指针变量temp申请(high-low+1)*sizeof(int)个字节的存储空间。
while(i<=mid&&j<=high)
//在a[low..mid]和a[mid+1..high]两个子表都没有被扫描完时侯循环
if(a[i]<=a[j])
//将a[low..mid]子表中的元素放入temp中
{
temp[k]=a[i];
i++;//a[low..mid]子表的下标加一记录
k++;//temp的下标加一记录
}
else//将a[mid+1..high]子表中的元素放入temp中
{
temp[k]=a[j];
j++;//a[mid+1..high]子表的下标加一记录
k++;//temp的下标加一记录
}
while(i<=mid)//将a[low..mid]余下部分复制到temp
{
temp[k]=a[i];
i++;
k++;
}
while(j<=high)//将a[mid+1..high]余下部分复制到temp
{
temp[k]=a[j];
j++;
k++;
}
for(k=0,i=low;i<=high;k++,i++)//将temp复制到序列a中
a[i]=temp[k];
free(temp);//释放临时空间
}
void MergePass(int a[],int length,int n)//一趟二路归并排序
//通过比较键值,MergePass函数可以将相同键值数据进行合并
{
int i;
for(i=0;i+2*length-1<n;i=i+2*length)
//归并length长的两个相邻子表
Merge(a,i,i+length-1,i+2*length-1);
if(i+length-1<n)//余下两个子表,后者长度小于length
Merge(a,i,i+length-1,n-1);//归并这两个子表
}
void MergeSort(int a[],int n)//二路归并算法//MergeSort函数是最终归并函数
{
int length;//定义length,length是各子表长度
for(length=1;length<n;length=2*length)
MergePass(a,length,n);
}
int main()
{
int n=10;
int a[]={7,3,2,4,6,9,8,10,1,5};
printf("排序前:\n");
disp(a,n);
MergeSort(a,n);
printf("排序后:\n");
disp(a,n);
}程序测试:
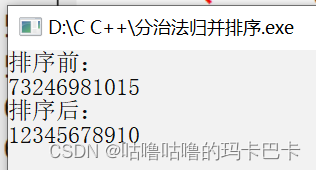
2. 折半查找指定元素:
算法设计思想描述:
首先折半查找的查找序列一定是有序的,确定中点位置,然后查找的值和中点比较,如果查找值和中点值一样,就查找到该值位置是中点位置;如果查找值大于中点值,该查找值就在序列右边部分,就在右边部分递归查找;如果查找值小于中点值,该查找值就在序列左边部分,就在左边部分递归查找;找到就返回该值位置,找不到就返回。
代码实现:
#include<stdio.h>
int BinSearch(int a[],int n,int k)
//非递归折半查找算法//定义a[]序列,n元素数量,k关键元素
{
int low=0,high=n-1,mid;
//定义第一个元素值low为0,最后一个元素值high为n-1,中间元素为mid
while(low<=high)
//当前区间存在元素时循环,当第一个元素值小于等于最后一个元素值
{
mid=(low+high)/2;//求查找区间的中间位置
if(a[mid]==k)//当中点元素等于查找的关键元素k时
return mid;//找到后返回物理下标mid
if(a[mid]>k)//当中点元素大于查找的关键元素k时
high=mid-1;//继续在前部分a[low..mid-1]中查找
else//当中点元素小于查找的关键元素k时
low=mid+1;//继续在后部分a[mid+1..high]中查找
}
return -1;//当前查找区间没有该元素时返回-1
}
int main()
{
int n=15,i,k=7;//i是查找元素k的下标
int a[]={1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};//折半查找前提是必须有序
i=BinSearch(a,n-1,k);
if(i>=0)//i大于等于0表示找到并返回下标和值
printf("a[%d]=%d\n",i,k);
else
printf("未找到%d元素\n",k);
}程序测试:

3. 求出其中最大连续子序列的和:
算法设计思想描述:
先确定n大于1,然后通过序列求中间位置,分三种情况:最大连续子序列和在左部分,在左中右部分,在右部分。通过递归求出左部分最大连续子序列和、右部分最大连续子序列和。细分左中右部分求法,是从左边开始跨越还是右边开始跨越中间,以及左边加中间的最大连续子序列和、右边加中间的最大连续子序列和,求出并比较左边跨越的最大连续子序列和左边加中间的最大连续子序列和,右边也一样,最后比较左部分最大连续子序列和、右部分最大连续子序列和、左中右最大连续子序列和三者,即可得出该序列最大连续子序列和。
代码实现:
# include <stdio.h>
long max3(long a,long b,long c)
//求出3个long长整型的最大值
{
if (a<b)//用a保存a、b中的最大值
a=b;
if (a> c)//比较返回a、c中的最大值
return a;
else
return c;
}
long maxSubSum(int a[],int l, int r)
//求a[l..r]序列中的最大连续子序列和
{
int i, j;//i是左部分元素,j是右部分的元素
long maxLSum, maxRSum;
//maxLSum是左部分最大连续子序列和,maxRSum是右部分最大连续子序列和
long maxLBSum, lBSum;
//maxLBSum是从左部分开始跨越中间,占左右部分的最大和
//LBSum是从左部分加上中间的和
long maxRBSum,rBSum;
//maxTBSum是从右部分开始跨越中间,占左右部分的最大和
//RBSum是从右部分加上中间的和
if(l==r)//当子序列只有一个元素时
{
if (a[l]>0)//该元素大于0时返回它
return a[l];
else
return 0;//该元素小于或等于0时返回0
}
int m=(l+r)/2;//求中间位置
maxLSum= maxSubSum(a,l,m);//求左边的最大连续子序列之和
maxRSum=maxSubSum(a,m+1,r);//求右边的最大连续子序列之和
maxLBSum=0,lBSum=0;
for(i=m; i>=l; i--)
//求出以左边加上a[mid]元素构成的序列的最大和
{
lBSum=lBSum+a[i];
if (lBSum> maxLBSum)
maxLBSum=lBSum;
//如果lBSum大于maxLBSum,maxLBSum等于rlBSum
maxRBSum=0,rBSum=0;
}
for (j=m+1; j<=r; j++)
//求出 a[mid]右边元素构成的序列的最大和
{
rBSum=rBSum+a[j];
if (rBSum> maxRBSum)
//如果rBSum大于maxRBSum,maxRBSum等于rBSum
maxRBSum=rBSum;
}
return max3(maxLSum,maxRSum,maxLBSum+maxRBSum);
//三者比较,找出最大的
}
int main( )
{
int a[]= {-2,11,-4,13,-5,-2},n=6;
int b[]= {-6,2,4,-7,5,3,2,-1,6,-9,10,-2},m=12;
printf("a序列的最大连续子序列的和为:\n%ld\n",maxSubSum(a,0,n-1));
printf("b序列的最大连续子序列的和为:\n%ld\n",maxSubSum(b,0,m-1));
}程序测试:

4.通过天平称重方式查找假币问题
算法设计思想描述:
将硬币组分割,分成左右两个部分,先比较左右部分的总重量,得出是哪一边比较轻,然后返回轻的部分,在轻的部分里面比较硬币重量,找到轻的硬币就返回下标位置,得到假币位置。
代码实现:
#include <iostream>
#include <vector>//模板类,可以存放任何类型的对象,必须是同一类对象
using namespace std;
int findFakeCoin(vector<int> coins, int l, int h)
//findFakeCoin表示寻找假币,用于比较两侧硬币组的重量,vector<int> coins表示容器里装着硬币,定义l左边组硬币,h是右边组硬币
{
if (l == h)//说明硬币数是偶数
return l;
int m = (l + h) / 2;
//m是判断硬币数是不是奇数的变量
if ((h - l + 1) % 2 == 1)
//说明硬币数是奇数
coins[m] += coins[h];
//将最后一个硬币放入左侧组
int left = findFakeCoin(coins, l, m);
//左边组重量
int right = findFakeCoin(coins, m+1, h);
//右边组重量
return coins[left] < coins[right] ? left : right;
// 返回较轻的一侧
}
int main() {
int n;
cout << "请输入硬币总数 n(大于3):" << endl;
cin >> n;
if(n<3)
return 0;
vector<int> coins(n);
//声明了一个int数组coins[n],大小没有指定,可以动态的向里面添加删除
cout << "请依次输入每个硬币的重量:" << endl;
for (int i = 0; i < n; i++) //for循环,找到假币下标
{
cin >> coins[i];
}
int fakeCoinIndex = findFakeCoin(coins, 0, n-1);
//0是表明已经找到,n-1表示拿出假币硬币数数量
cout << "假币位于第 " << fakeCoinIndex+1 << " 个硬币" << endl;
return 0;
}程序测试:

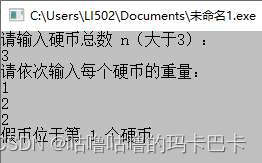
5. 对递增有序序列a求众数,并输出元素出现的次数(重数)
算法设计思想描述:
将递增有序序列从中间分开成左右两部分,分别对左右两部分进行递归调用,求众数和重数,如果两个子序列众数一样就直接得出众数和重数,重数变成左边重数加右边重数;如果两个子序列众数不一样,就比较两个子序列的重数,返回比较大的重数,即可找到众数。
代码实现:
#include <iostream>
#include <vector>//模板类,可以存放任何类型的对象,必须是同一类对象
using namespace std;
void findMode(vector<int>& array)
//findMode表示查找列表模式
//vector<int>& array,array是个引用,引用vector这个容器的变量,容器内部存着整型数据
{
int n = array.size();//目的求出数组包含的最大个数
int maxCount = 0;//最大次数
int mode = array[0];//众数
int currentCount = 1;//当前次数
for (int i = 1; i < n; i++)//for循环访问数组
{
if (array[i] == array[i - 1])//如果两个元素一样
{
currentCount++;//当前次数+1
}
else
{
if (currentCount > maxCount)//如果当前次数大于最大次数
{
maxCount = currentCount;//当前次数覆盖最大次数
mode = array[i - 1];//众数元素
}
currentCount = 1;//重置
}
}
if (currentCount > maxCount)//如果当前次数大于最大次数
{
maxCount = currentCount;//当前次数覆盖最大次数
mode = array[n - 1];//记住众数个数
}
cout << "众数为: " << mode << endl;
cout << "重数(次数)为: " << maxCount << endl;
}
int main() {
vector<int> array = {1,2,3,3,4,5,6,6,6};
//表达的是array是一个二维的int型的vector
findMode(array);
return 0;
}程序测试:

6. 大整数乘积算法
算法设计思想描述:
把输入的X和Y拆分成高位和低位两部分,其长度为n/2,运用递归计算高位与高位的乘积、低位与低位的乘积,高位加低位和高位加低位的乘积,通过二进制数的乘积计算得出结果。
代码实现:
#include<stdio.h>
#include <iostream>
using namespace std;
int multiply(int X, int Y, int n) {
//multiply辅助函数,用于计算两个n位二进制数的乘积
//位数n为2的幂,X、Y为正数,二进制整数
if (n == 1) //如果n等于1就返回X,Y的乘积
{
return X * Y;
}
int m = (1 << (n / 2)) - 1;//1的二进制数左移(n / 2)) - 1 位
//拆分输入数,划分方式为将n位数分成n/2位子数
int XHigh = X >> (n / 2); //X的高位部分,表示将X向右移动n/2位,将X除以2的n/2次方
int XLow = X & m;//X的低位部分,只有XLow的等于X和m时才都执行
int YHigh = Y >> (n / 2);//Y的高位部分
int YLow = Y & m;//Y的低位部分
// 递归计算中间结果
int A = multiply(XHigh, YHigh, n / 2);//X的高位部分与Y的高位部分的乘积
int B = multiply(XLow, YLow, n / 2);//X的低位部分与Y的低位部分的乘积
int C = multiply(XHigh+XLow, YHigh+YLow, n / 2);
//X的高低位部分与Y的高低位部分的乘积
int result = (A << n) + ((C-A-B) << (n / 2)) + B;
// 组合中间结果得到最终结果
return result;
}
int main() {
int X, Y;
int n; // 输入的位数
cout << "请输入X的位数n:";
cin >> n;
cout << "请输入X:";
cin >> X;
cout << "请输入Y:";
cin >> Y;
int result = multiply(X, Y, n);
cout << "乘积结果为:" << result << endl;
return 0;
}程序测试:


如需源文件,请私信作者,无偿。
















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









