






1.说一说ArrayList的实现原理?
ArrayList底层基于数组实现,内部封装了Object类型的数组,实现了list接口,通过默认构造器创建容器时,该数组被初始化为一个空数组,首次添加数据时再将其初始化为容量为10的数组,也可以通过有参构造器显式指定数组长度;当添加的数据超出数组长度时触发自动扩容,将旧数据拷贝到新数组中,新数组为旧数组的1.5倍,相对于同为继承list的LinkedList来说,查询快,增改删较慢,则LinkedList相反。
2.Java中有哪些集合类?
Java中的集合类分为4大类,分别由4个接口来代表,它们是Set、List、Queue、Map。其中,Set、List、Queue、都继承自Collection接口。
· Set代表无序的、元素不可重复的集合。
· List代表有序的、元素可以重复的集合。
· Queue代表先进先出(FIFO)的队列。
· Map代表具有映射关系(key-value)的集合。
Java提供了众多集合的实现类,它们都是这些接口的直接或间接的实现类,其中比较常用的有:HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。
3.如何打开一个大文件?
打开大文件的关键在于,不能直接将文件中的数据全部读取到内存中,以免引发OOM。重点要考虑内存的利用问题,就是如何使用较小的内存空间来解决问题。可以考虑的方式是,每次读取文件中的一部分内容,分多次处理这个文件,具体还要看打开文件的目的。
- 如果我们打开的是文本文件,期望读取甚至分析该文件中的内容,则可以采用java.util.Scanner来逐行读取文件的内容。在Scanner遍历文件的过程中,每处理一行之后,我们都要丢弃对该行的引用,以节约内存。
- 如果我们打开的是字节文件,期望拷贝或者搬运该文件中的内容,则可以采用缓冲流或NIO。每次利用缓冲区处理文件中的一小段数据,这样在处理过程中使用的内存空间便是很有限的,不会造成内存溢出的问题。
4.如何让UDP协议变得可靠?
UDP它不属于连接型协议,因而具有资源消耗小,处理速度快的优点,所以通常音频、视频和普通数据在传送时使用UDP较多,因为它们即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
传输层无法保证数据的可靠传输,只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
实现确认机制、重传机制、窗口确认机制。
如果你不利用linux协议栈以及上层socket机制,自己通过抓包和发包的方式去实现可靠性传输,那么必须实现如下功能:
发送:包的分片、包确认、包的重发
接收:包的调序、包的序号确认
目前有如下开源程序利用udp实现了可靠的数据传输。分别为RUDP、RTP、UDT。
(1)RUDP
RUDP 提供一组数据服务质量增强机制,如拥塞控制的改进、重发机制及淡化服务器算法等,从而在包丢失和网络拥塞的情况下, RTP 客户机(实时位置)面前呈现的就是一个高质量的 RTP 流。在不干扰协议的实时特性的同时,可靠 UDP 的拥塞控制机制允许 TCP 方式下的流控制行为。
(2)RTP
实时传输协议(RTP)为数据提供了具有实时特征的端对端传送服务,如在组播或单播网络服务下的交互式视频音频或模拟数据。应用程序通常在 UDP 上运行 RTP 以便使用其多路结点和校验服务;这两种协议都提供了传输层协议的功能。但是 RTP 可以与其它适合的底层网络或传输协议一起使用。如果底层网络提供组播方式,那么 RTP 可以使用该组播表传输数据到多个目的地。
RTP 本身并没有提供按时发送机制或其它服务质量(QoS)保证,它依赖于底层服务去实现这一过程。 RTP 并不保证传送或防止无序传送,也不确定底层网络的可靠性。 RTP 实行有序传送, RTP 中的序列号允许接收方重组发送方的包序列,同时序列号也能用于决定适当的包位置,例如:在视频解码中,就不需要顺序解码。
(3)UDT
基于UDP的数据传输协议(UDP-basedData Transfer Protocol,简称UDT)是一种互联网数据传输协议。UDT的主要目的是支持高速广域网上的海量数据传输,而互联网上的标准数据传输协议TCP在高带宽长距离网络上性能很差。顾名思义,UDT建于UDP之上,并引入新的拥塞控制和数据可靠性控制机制。UDT是面向连接的双向的应用层协议。它同时支持可靠的数据流传输和部分可靠的数据报传输。由于UDT完全在UDP上实现,它也可以应用在除了高速数据传输之外的其它应用领域,例如点到点技术(P2P),防火墙穿透,多媒体数据传输等等。
5.HTTP协议的请求方式有哪些?
| 方法 | 描述 | 是否包含主体 |
| GET | 从服务器获取一份文档 | 否 |
| HEAD | 只从服务器获取文档的首部 | 否 |
| POST | 向服务器发送带要处理的数据 | 是 |
| PUT | 将请求的主体部分存储在服务器上 | 是 |
| TRACE | 对可能经过代理服务器传送到服务器上去的报文进行追踪 | 否 |
| OPTIONS | 决定可以在服务器上执行哪些方法 | 否 |
| DELETE | 从服务器上删除一份文档 | 否 |
6.InnoDB中的行级锁是怎么实现的?
InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。
7.说一说你对Spring IoC的理解?
spring ioc是spring两大核心之一,spring为我们提供了一个ioc容器,也就是beanFactory,同时,ioc有个非常强大的功能,叫做di,也就是依赖注入,我们可以通过配置或者xml文件的方式将bean所依赖的对象通过name(名字)或者type(类别)注入进这个beanFactory中,正因为这个依赖注入,实现类与依赖类之间的解耦,如果在一个复杂的系统中,类之间的依赖关系特别复杂,首先,这非常不利于后期代码的维护,ioc就很好的帮助我们解决了这个问题,它帮助我们维护了类与类之间的依赖关系,降低了耦合性,使我们的类不需要强依赖于某个类,而且,在spring容器启动的时候,spring容器会帮助我们自动的创建好所有的bean,这样,我们程序运行的过程中就不需要花费时间去创建这些bean,速度就快了许多。
8.HTTPS协议如何保证整个传输过程安全?
HTTP 存在的问题:
1. 窃听
第三方劫持请求后可以获取通信内容。对于一些敏感数据,这是不被允许的。
2. 篡改
第三方劫持请求后可以篡改通信内容。例如银行系统中,张三本来要给李四转账,第三方劫持请求后篡改了请求数据,将收款方改为自己,导致用户资金流失。
3. 冒充
第三方可以冒充客户端发送数据。由于是明文传输,没有「加签/验签」操作,服务端无法保证请求来源的合法性。
8.1 防窃听:加密
8.1.1 对称加密
采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密。
例如 DES 就是一种对称加密算法,甲乙双方约定一个密钥「Key」,双方发送数据前都用该密钥对数据进行加密传输,收到数据后再解密成明文即可。这种方式,只要保证密钥不被泄漏,理论上也是安全的。
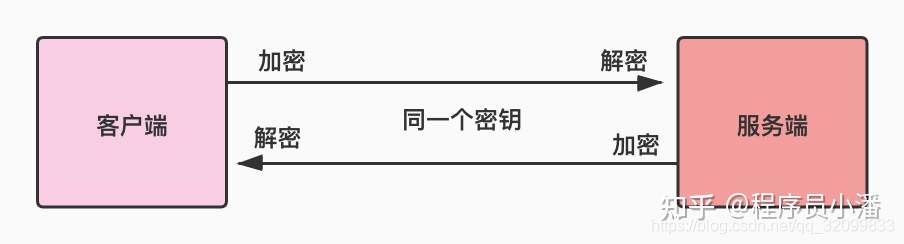
但是这会带来一个新的问题:密钥如何保存?
对于 PC 端来说,浏览器页面是明文的,肯定不能存储密钥。对于 iOS/Android 来说,即使把密钥藏在安装包的某个位置,也很容易被第三方拆包破解。
既然客户端保存不靠谱,那么密钥只在服务端保存,客户端去向服务端拿密钥是否可行?
依然不可行,服务端要怎么把密钥给你呢?明文肯定不行,如果要加密,又要用到密钥 B,密钥 B 的传输又要用到密钥 C,如此循环,无解。
8.1.2 非对称加密
非对称加密算法需要两个密钥:公开密钥(publickey:简称公钥)和私有密钥(privatekey:简称私钥)。公钥与私钥是一对,如果用公钥对数据进行加密,只有用对应的私钥才能解密。因为加密和解密使用的是两个不同的密钥,所以这种算法叫作非对称加密算法。
甲乙双方各有一套自己的密钥对,互相公开彼此的公钥,当甲方要发送数据给乙方时,用乙方公钥加密,这样密文就只有乙方自己能解开了,就算请求被劫持,第三方拿到了数据,由于没有乙方的私钥,也无法解密,这样就保证了数据被窃听。
单向非对称加密
绝大多数互联网网站对外是完全公开的,所有人都可以访问,服务端没必要验证所有客户端的合法性,只有客户端需要验证服务端的合法性。例如用户在访问电商网站时,必须确保不是钓鱼网站,以防资金损失。
这种情况下,只需要单向加密即可。服务端发送给客户端的一般不会有敏感信息,明文传输即可。但是客户端发送给服务端的就很有可能是敏感信息,例如用户修改密码,这时就必须加密传输了。

双向非对称加密
有时,服务端也需要验证客户端的合法性,例如银行系统。由于涉及到金钱,因此系统必须设计的足够安全。除了客户端发送给服务端的数据是加密的,服务端发送给客户端的数据也必须加密。
怎么做的呢?一般银行会给用户一个 U 盘,里面存储的就是一套密钥对,客户端告诉服务端自己的公钥,服务端根据公钥加密后再传输给客户端。

8.2 防篡改:加签
通过非对称加密的密文传输,可以防止数据被窃听,但是如果存在这种场景呢?
张三登陆银行系统,要给李四转一笔钱,数据通过服务端的公钥 PubB 加密传输,但是第三方劫持了这个请求,篡改了报文数据,写入的是「给王五转钱」,因为服务端的公钥是公开的,谁都能拿到,因此第三方也可以正常加密传输,服务端正常解密后进行了错误的操作,导致用户资金流失。

对于涉及到资金的操作,服务端必须要验证数据的合法性,确保数据没有被篡改,这就需要客户端对数据进行加签了。
非对称加密除了可以「公钥加密,私钥解密」外,还可以「私钥加签,公钥验签」。
银行给用户一个 U 盘,里面有一套密钥对。客户端在发送转账请求前,先对请求体加签,得到签名「sign」,然后再用服务端公钥加密,得到密文「data」,客户端将签名和密文一起发送给服务端,服务端解密后,还需要用客户端的公钥对「sign」进行验签,只有验签通过才能进行后续操作,否则就是非法请求了。
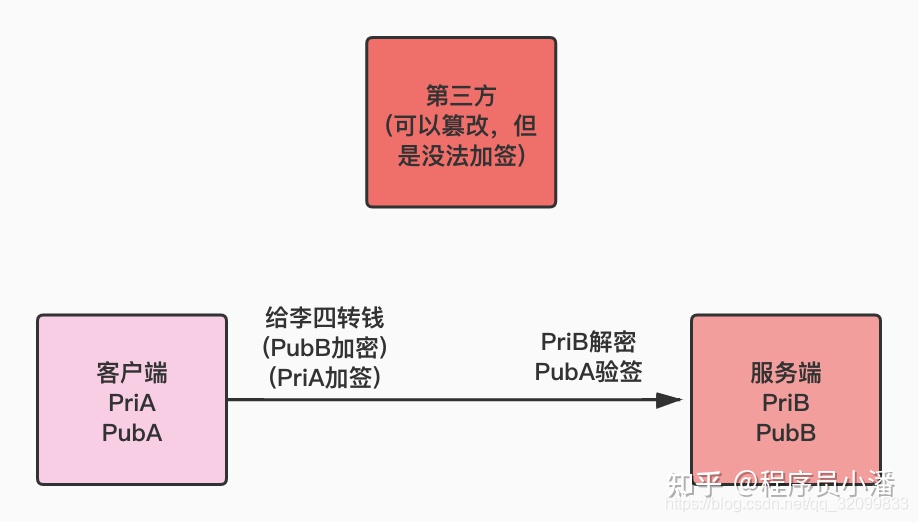
这样,即使请求被第三方劫持了,第三方可以篡改数据,但是签名它改不了,服务端解密后会发现数据和「sign」对不上,说明数据是被篡改过的。
8.3 防冒充:证书
通过加密防止数据被窃听,通过加签防止数据被篡改,现在看来好像已经很安全了,但是别忘了,有个前提是:公钥的传输是安全的。不幸的是,公钥的安全传输很难保证。
中间人攻击 假设存在这样一种场景,客户端和服务端想互换公钥,但是请求都被一个中间人劫持了,结果就是:服务端和客户端以为是和双方互换公钥了,结果是客户端和服务端都和中间人互换公钥了。
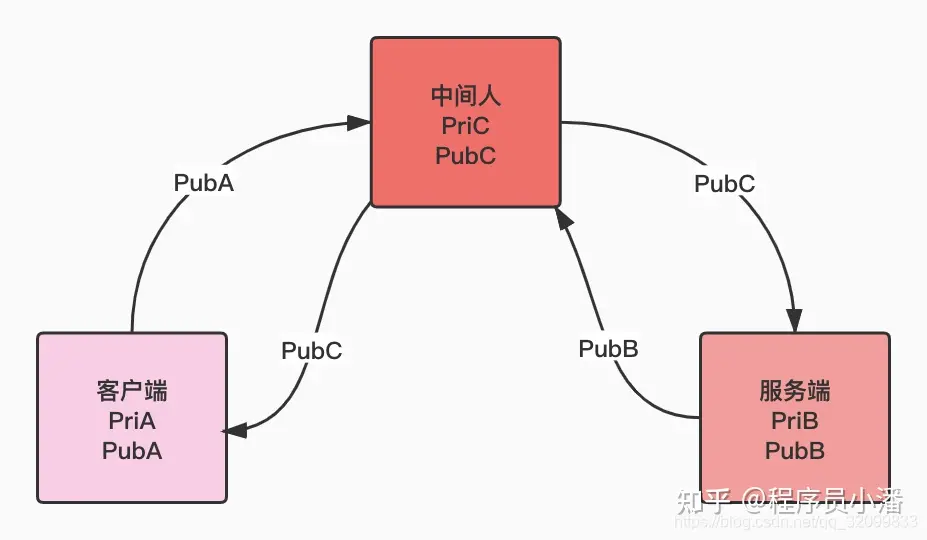
一旦出现这种问题就非常严重,前面讲到的加密解密、加签验签都失效了。客户端以为中间人就是服务端,服务端以为中间人就是客户端,双方以为是在和对方通信,其实都是在和中间人通信,中间人可以随意的窃听和篡改数据。
这个问题之所以会出现,就是因为公钥的传输是不安全的。客户端和服务端之间互换公钥时,如何确保公钥就是对方发出的,没有被篡改过呢???
8.3.1 数字证书与认证中心
在之前的基础上,引入一个中间角色:证书认证中心 CA。当服务端要把公钥发送给客户端时,不是直接发送公钥,而是先把公钥发送给 CA,CA 根据公钥生成一份「证书」给到服务端,服务端将证书给客户端。客户端拿到证书后去 CA 验证证书的合法性,确保证书是服务端下发的。
CA 就类似于「公证处」,也是一台服务器,它自己本身也有一套密钥对。它的工作就是根据服务端的公钥生成证书,然后帮助客户端来验证证书的合法性。

8.3.2 CA 被冒充怎么办?
引入 CA 可以保证公钥的传输安全,但是有一个前提,客户端和服务端是信任 CA 的,也就是说 CA 必须是安全可信任的,如果 CA 被冒充,就又会出现上面的问题。
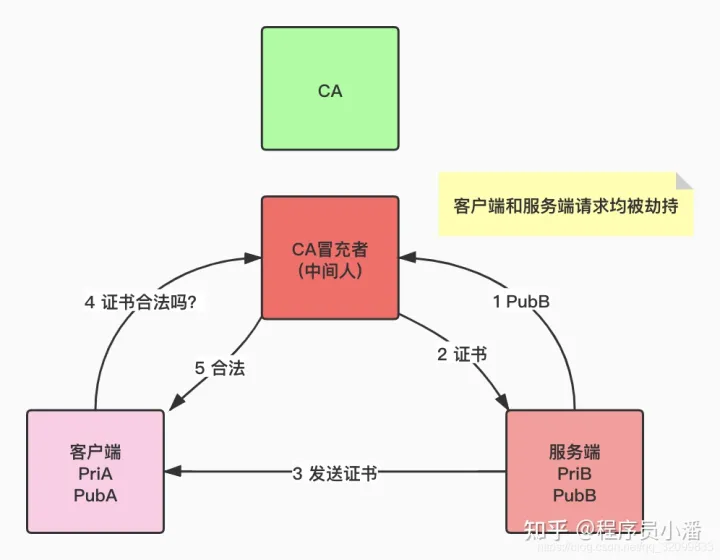
基于这个问题,就引入了「根证书」和「CA 信任链」的概念。
要让客户端和服务端信任 CA,其实 CA 也面临着同样的问题,那就是:如何保证 CA 的公钥是安全不被篡改的?答案也是一样的,就是给 CA 也颁发证书,那这个证书由谁来颁发呢?自然是 CA 的上一级 CA 了。CA 的上一级 CA 如何保证安全?那就 CA 的上一级 CA 的上一级 CA 给它办法证书了。最终就会形成一个证书信用链,如下:

客户端要想验证服务器的 C3 证书是否合法,会跑去 CA2 验证,要验证 CA2 就去 CA1 验证,以此类推。对于根证书,是没法验证的,只能无条件相信。因为 Root CA 都是国际上公认的机构,一般用户的操作系统或浏览器在发布时,就会在里面嵌入这些机构的 Root 证书。
如下是百度官网的证书,点击浏览器地址栏旁边的锁标识就能看到了。
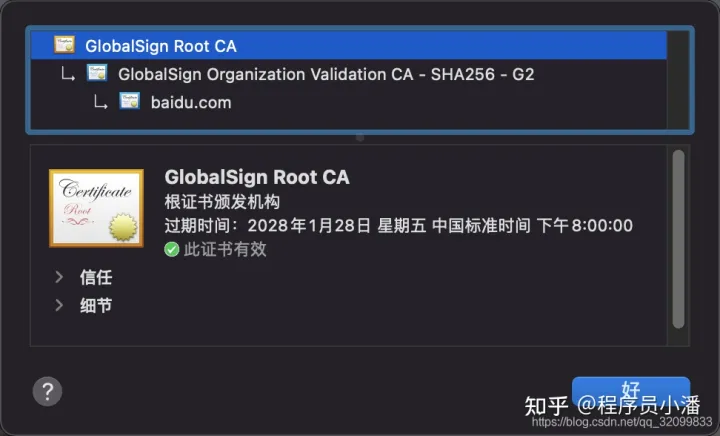
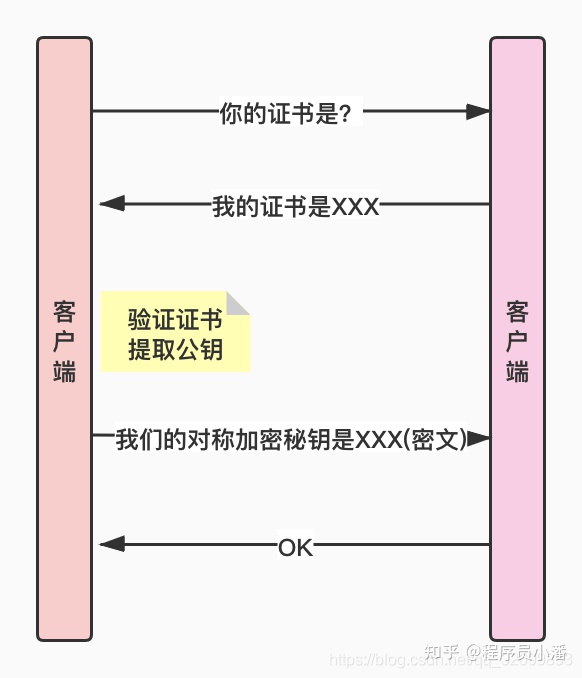
8.4 SSL/TLS 四次握手
了解了底层的实现,加密、加签、证书等概念后,再来看 SSL/TLS 协议就很容易理解了。SSL/TLS 需要四次握手的过程:
- 客户端向服务端所有证书。
- 服务端发送证书。
- 客户端验证证书,提取公钥,发送对称加密的密钥。
- 服务端收到密钥,响应 OK。
8.5 再看 HTTPS
了解 SSL/TLS,再回过头来看 HTTPS 就很简单了,HTTPS=HTTP+SSL/TLS。
使用 HTTPS 进行通信时,先是建立传输层 TCP 的连接,完成三次握手,然后再是 SSL/TLS 协议的四次握手,双方协商出对称加密的密钥,之后的通信数据会利用该密钥进行加密传输。
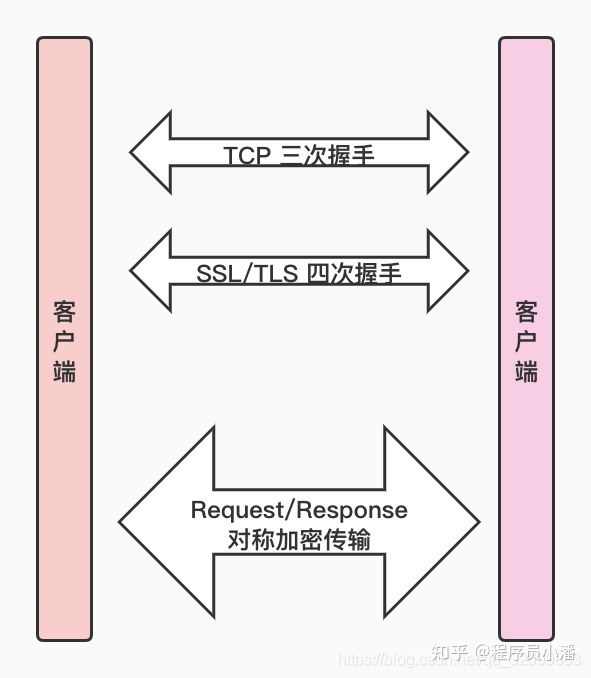
HTTP1.1 开始支持长连接了,只要连接不关闭,七次握手只需要执行一次,性能损耗不会太大,而且数据传输采用的是对称加密,相比于非对称加密,性能损耗也小得多。因此 HTTPS 相比于 HTTP,性能会有一定影响,但不会太大,相比之下,数据传输安全显得更加重要!
9.说一说HashMap的实现原理?
众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry(包括Key-Value),其中Key 和 Value 允许为null。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。另外,HashMap数组每一个元素的初始值都是Null。

值得注意的是:HashMap不能保证映射的顺序,插入后的数据顺序也不能保证一直不变(如扩容后rehash)。
要说HashMap的原理,首先要先了解它的数据结构
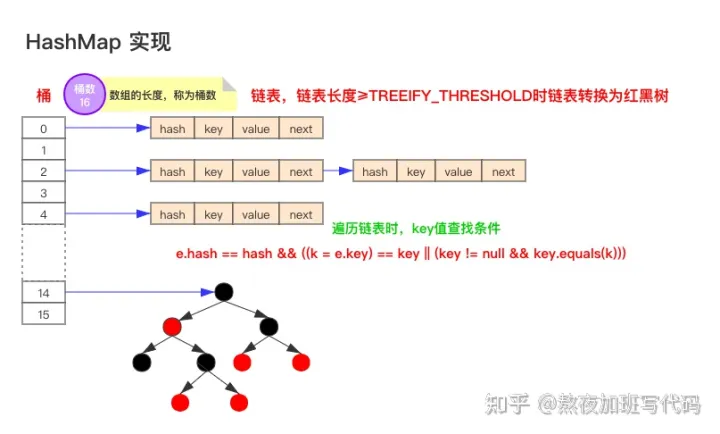
如上图为JDK1.8版本的数据结构,其实HashMap在JDK1.7及以前是一个“链表散列”的数据结构,即数组 + 链表的结合体。JDK8优化为:数组+链表+红黑树。
我们常把数组中的每一个节点称为一个桶。当向桶中添加一个键值对时,首先计算键值对中key的hash值(hash(key)),以此确定插入数组中的位置(即哪个桶),但是可能存在同一hash值的元素已经被放在数组同一位置了,这种现象称为碰撞,这时按照尾插法(jdk1.7及以前为头插法)的方式添加key-value到同一hash值的元素的最后面,链表就这样形成了。
当链表长度超过8(TREEIFY_THRESHOLD - 阈值)时,链表就自行转为红黑树。
注意:同一hash值的元素指的是key内容一样么?不是。根据hash算法的计算方式,是将key值转为一个32位的int值(近似取值),key值不同但key值相近的很可能hash值相同,如key=“a”和key=“aa”等
10.HTTP(超文本传输协议)是什么?
Http是超文本传输协议,它是应用层的面向对象的协议,它是基于TCP/IP的高级协议,默认端口号是80。它是基于请求响应模型的,即一次请求对应一次响应。它是无状态的,每次请求之间相互独立。HTTP协议请求消息的数据格式为请求行,请求头,请求空行和请求体。请求行中主要包括请求方式,请求url,请求协议和版本等。请求方式在HTTP协议中有7种,最常用的有2中,get和post。如果是get请求,则还会把请求参数拼接到url后;请求头是客户端浏览器想要告诉浏览器的一些信息,如user-Agent(浏览器信息),host(主机地址),reference(请求来源)等。请求空行是用来分割请求头和请求体的;请求体是post请求下封装请求参数的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









