






目录
2.1、newCachedThreadPool( )方法示例
2.2、newFixedThreadPool(int nThreads)方法示例
3、使用ThreadPoolExecutor类来创建线程池(自定义线程池)

1、线程池的介绍
1、线程池:是一种利用池化技术思想来实现的线程管理技术,主要是为了复用线程、便利地管理线程和任务、并将线程的创建和任务的执行解耦开来。我们可以创建线程池来复用已经创建的线程来降低频繁创建和销毁线程所带来的资源消耗。在JAVA中主要是使用ThreadPoolExecutor类来创建线程池,并且JDK中也提供了Executors工厂类来创建线程池(不推荐使用)。
主要核心原理
- 创建一个线程池子,池子中是空的
- 提交任务时,线程池子会创建新的线程对象,任务执行完毕,线程归还给池子下回再次提交任务时,不需要创建新的线程,直接复用已有的线程即可
- 但是如果提交任务时,池子中没有空闲线程,也无法创建新的线程,任务就会排队等待
2、使用线程池的原因:
以前写多线程的弊端
弊端1:用到线程的时候就创建,用完之后线程消失。每执行一个任务都需要创建新的线程来执行,创建线程对系统来说开销很高。
弊端2:不受控制风险,对于每个创建的线程没有统一管理的地方,每个线程创建后我们不知道线程的去向。
线程池的优点:
(1)降低资源消耗,复用已创建的线程来降低创建和销毁线程的消耗。
(2)提高响应速度,任务到达时,可以不需要等待线程的创建立即执行。
(3)提高线程的可管理性,使用线程池能够统一的分配、调优和监控。所以使用线程池能够提高系统的性能和可靠性,减少系统资源的浪费,提高系统的并发能力
2、使用Executors工厂类来创建线程池
Executors工厂类来创建线程池步骤:
1,创建线程池
2,提交任务
3,所有的任务全部执行完毕,关闭线程池
Executors:线程池的工具类通过调用方法返回不同类型的线程池对象。
| 方法名称 | 说明 |
| public static ExecutorService newCachedThreadPool( ) | 创建一个没有上限的线程池 |
| public static ExecutorService newFixedThreadPool(int nThreads) | 创建有上限的线程池 |
补充:
newCachedThreadPool( )方法:创建一个可缓存的无界线程池,如果线程池长度超过处理需要,可灵活回收空线程,若无可回收,则新建线程。当线程池中的线程空闲时间超过60s,则会自动回收该线程,当任务超过线程池的线程数则创建新的线程,线程池的大小上限为Integer.MAX_VALUE,可看作无限大。
newFixedThreadPool(int nThreads)方法:创建一个指定大小的线程池,可控制线程的最大并发数,超出的线程会在LinkedBlockingQueue阻塞队列中等待
使用Executors工厂类来创建线程池示例:
创建任务对象MyRunnable类
public class MyRunnable implements Runnable{
@Override
public void run() {
for (int i=1; i<=50; i++) {
System.out.println("线程" +Thread.currentThread().getName()+ "打印" +i);
}
}
}2.1、newCachedThreadPool( )方法示例
主方法
public static void main(String[] args) {
//1、获取线程池对象
ExecutorService pool1 = Executors.newCachedThreadPool();
//2.提交任务
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
//销毁线程池,但是线程池一般是不会销毁的
//pool1.shutdown();
}从结果可以看出,该方法创建的线程池,可以创建许多的线程
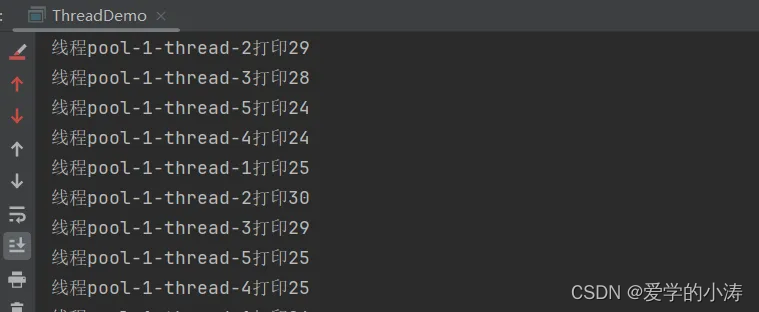
把MyRunnable类中的run方法改成下面这样,让run方法仅仅打印一次
public void run() {
//for (int i=1; i<=50; i++) {
System.out.println("线程" +Thread.currentThread().getName()+ "打印");
//}
}主方法
public static void main(String[] args) throws InterruptedException {
//获取线程池对象
ExecutorService pool1 = Executors.newCachedThreadPool();
//2.提交任务
pool1.submit(new MyRunnable());
Thread.sleep(1000);
pool1.submit(new MyRunnable());
Thread.sleep(1000);
pool1.submit(new MyRunnable());
Thread.sleep(1000);
pool1.submit(new MyRunnable());
Thread.sleep(1000);
pool1.submit(new MyRunnable());
//销毁线程池,但是线程池一般是不会销毁的
//pool1.shutdown();
}从这里的结果可以看出来线程池中线程复用的效果,一个线程是会一直存在线程池当中的
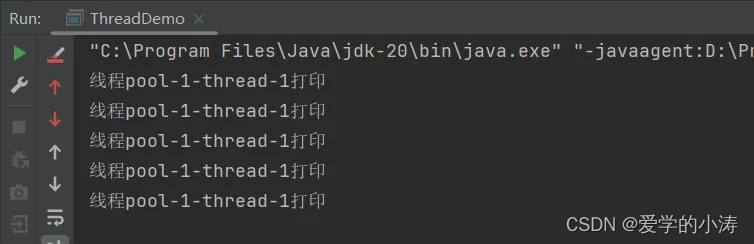
2.2、newFixedThreadPool(int nThreads)方法示例
主方法
public static void main(String[] args) throws InterruptedException {
//获取线程池对象
ExecutorService pool1 = Executors.newFixedThreadPool(3);
//2.提交任务
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
//销毁线程池,但是线程池一般是不会销毁的
//pool1.shutdown();
}从结果看出线程池中只创建了三个线程,和代码中我们给定的创建线程数是一样的
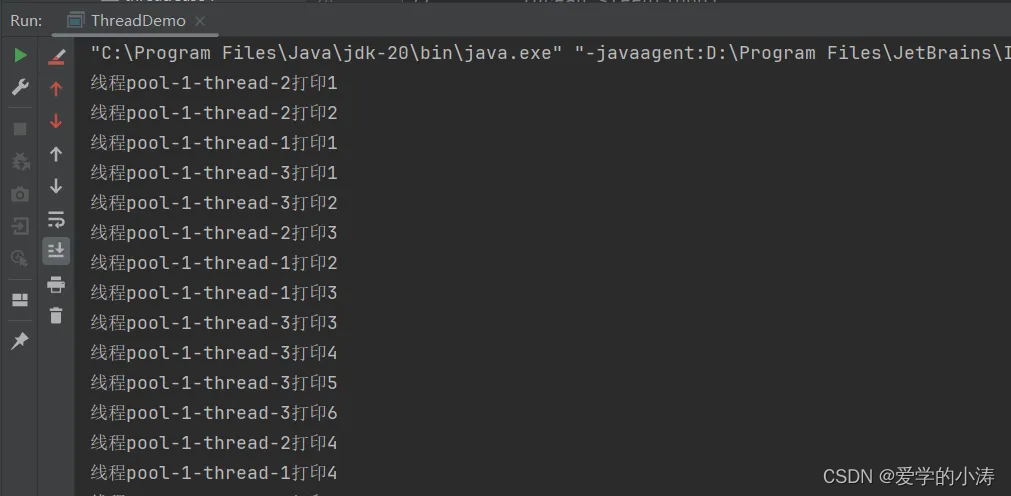
3、使用ThreadPoolExecutor类来创建线程池(自定义线程池)
ThreadPoolExecutor的全参构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}参数说明:
1、corePoolSize(线程池基本大小):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时,才会根据是否存在空闲线程,来决定是否需要创建新的线程。除了利用提交新任务来创建和启动线程(按需构造),也可以通过 prestartCoreThread() 或 prestartAllCoreThreads() 方法来提前启动线程池中的基本线程。
2、maximumPoolSize(线程池最大大小):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
3、keepAliveTime(线程存活保持时间):默认情况下,当线程池的线程个数多于corePoolSize时,线程的空闲时间超过keepAliveTime则会终止。但只要keepAliveTime大于0,allowCoreThreadTimeOut(boolean) 方法也可将此超时策略应用于核心线程。另外,也可以使用setKeepAliveTime()动态地更改参数。
4、unit(存活时间的单位):时间单位,分为7类,从细到粗顺序:NANOSECONDS(纳秒),MICROSECONDS(微妙),MILLISECONDS(毫秒),SECONDS(秒),MINUTES(分),HOURS(小时),DAYS(天);
5、workQueue(任务队列):用于传输和保存等待执行任务的阻塞队列。可以使用此队列与线程池进行交互:
- 如果运行的线程数少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。
- 如果运行的线程数等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。
- 如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
6、threadFactory(线程工厂):用于创建新线程。由同一个threadFactory创建的线程,属于同一个ThreadGroup,创建的线程优先级都为Thread.NORM_PRIORITY,以及是非守护进程状态。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号);
7、handler(线程饱和策略):当线程池和队列都满了,则表明该线程池已达饱和状态。
- ThreadPoolExecutor.AbortPolicy:处理程序遭到拒绝,则直接抛出运行时异常 RejectedExecutionException。(默认策略)
- ThreadPoolExecutor.CallerRunsPolicy:调用者所在线程来运行该任务,此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
- ThreadPoolExecutor.DiscardPolicy:无法执行的任务将被删除。
- ThreadPoolExecutor.DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重新尝试执行任务(如果再次失败,则重复此过程)。
创建线程池,在构造一个新的线程池时,必须满足下面的条件:
(1)corePoolSize(线程池基本大小)必须大于或等于0;
(2)maximumPoolSize(线程池最大大小)必须大于或等于1;
(3)maximumPoolSize必须大于或等于corePoolSize;
(4)keepAliveTime(线程存活保持时间)必须大于或等于0;
(5)workQueue(任务队列)不能为空;
(6)threadFactory(线程工厂)不能为空,默认为DefaultThreadFactory类
(7)handler(线程饱和策略)不能为空,默认策略为ThreadPoolExecutor.AbortPolicy。
说一个例子助于理解:比如线程池就是一个饭店,然后线程就是服务员,其中核心线程是正式服务员,临时线程是临时服务员,任务就是客户,而阻塞队列就是客户在排队时的等待区。当正式员工都有客户要服务且客户排队的等待区都坐满了时,再有客户来,就会去招聘临时服务员来服务这个新来的客户(注意这个被临时服务员服务的客户是新来的客户,不是等待区里的客户),直到临时服务员的数量也招聘到上限时,再有新来的客户就会被拒绝服务
| (1)corePoolSize:正式员工数量 | ——> | 核心线程数量(不能小于0) |
| (2)maximumPoolSize:餐厅最大员工数 | ——> | 线程池中最大线程的数量(最大数量 >=核心线程数量) |
| (3)keepAliveTime:临时员工空闲多长时间被辞退(值) | ——> | 空闲时间(值)(不能小于0) |
| (4)unit:临时员工空闲多长时间被辞退(单位) | ——> | 空闲时间(单位)(用TimeUnit指定) |
| (5)workQueue:排队的客户 | ——> | 阻塞队列(不能为null) |
| (6)threadFactory:从哪里招人 | ——> | 创建线程的方式(不能为null) |
| (7)handler:当排队人数过多,超出顾客请下次再来(拒绝服务) | ——> | 要执行的任务过多时的解决方案(不能为null) |
使用ThreadPoolExecutor类来创建线程池示例:
public class MyThreadPool1 {
/*
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor
(核心线程数量,最大线程数量,空闲线程最大存活时间,任务队列,创建线程工厂,任务的拒绝策略);
参数一:核心线程数量 不能小于0
参数二:最大线程数 不能小于0,最大数量>=核心线程数量
参数三:空闲线程最大存活时间 不能小于0
参数四:时间单位 用TimeUnit指定
参数五:任务队列 不能为nu11
参数六:创建线程工厂 不能为nu11
参数七:任务的拒绝策略 不能为nu11
*/
ThreadPoolExecutor pool = new ThreadPoolExecutor(
3,//核心线程数量,不能小于
6,//最大线程数,不能小于0,最大数量 >= 核心线程数量
60,//空闲线程最大存活时间
TimeUnit.SECONDS,//时间单位
new ArrayBlockingQueue<>(3),//任务队列
Executors.defaultThreadFactory(),//创建线程工厂
new ThreadPoolExecutor.AbortPolicy()//任务的拒绝策略
);自定义线程池小结
- 创建一个空的池子
- 有任务提交时,线程池会创建线程去执行任务,执行完毕归还线程
不断的提交任务,会有以下三个临界点:
- 当核心线程满时,再提交任务就会排队
- 当核心线程满,队伍满时,会创建临时线程
- 当核心线程满,队伍满,临时线程满时,会触发任务拒绝策略
4、线程池多大合适呢?
先了解一下最大并行数,比如4核8线程,最大并行数就是8
获取自己电脑最大并行数的方法之一
public class Main {
public static void main(String[] args) {
//向Java虚拟机返回可用处理器的数目
int count = Runtime.getRuntime().availableProcessors();
System.out.println("可用处理器的数目:" + count);
}
}我的电脑是12
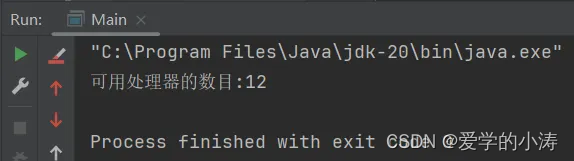
一、CPU 密集型运算时: 取最大并行数 +1
提示:+1是为了当前面的线程出问题时可以有线程可以及时补上
二、I/O 密集型运算时: 取最大并行数*期望 CPU 利用率(总时间(CPU计算时间+等待时间)/CPU 计算时间)
示例:比如要从本地文件中读取两个数据,并进行相加,这就要进行两个操作,操作一是读取两个数据,操作二是把两个数据相加,假设这两个操作都是一秒钟,但是只有相加操作是会用到CPU的,所以总时间 = 相加操作(CPU计算时间)1秒 + 读取两个数据(等待时间)1秒 为2秒,CPU计算时间为1秒,最大最大并行数我的电脑是12,我期望 CPU 利用率是100%
所以式子 = 12 * 100% * ((1 + 1)/ 1)= 24

推荐:














 2022
2022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









