






一、单项选择题
说明:题目中使用到的soup对象都来自下面的这段程序:
from bs4 import BeautifulSoup
doc='''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</body>
</html>
'''
soup=BeautifulSoup(doc,"lxml"
-
下列程序执行后a数组变成11个元素
import numpy as np
a=np.random.randint(0,3,10)
a[10]=1
print(a)
A. 正确 B. 错误

-
按一行两列左右画出y=x,y=x*x的图像,程序:
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(0,1,10)
________________
plt.plot(x,x,label="y=x")
plt.legend()
________________
plt.plot(x,x*x,label="y=x*x")
plt.legend()
plt.show()
缺少的语句是:
A.
plt.subplot(1,2,1)plt.subplot(1,2,2)
B.
plt.subplot(1,2,2)
plt.subplot(1,2,1)
C.
plt.subplot(2,1,1)
plt.subplot(2,1,2)
D.
plt.subplot(2,1,2)
plt.subplot(2,1,1)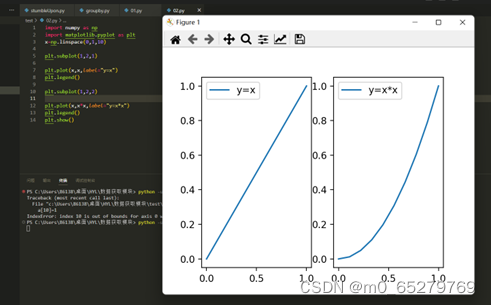
-
执行如下代码后的输出结果是( )。
import pandas as pd
aSer = pd.Series( [97, 98, 99, 100], index=["a","b","c","d"] )
aSerValues = aSer.values
print(aSerValues)
A. aSerValues
B. ["a","b","c","d"]
C. [97, 98, 99, 100]
D. [a, b, c, d]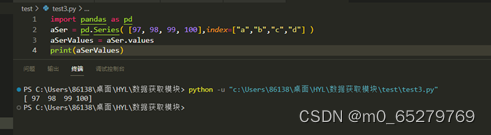
-
程序:
import numpy as np
a=np.arange(12)
a=a.reshape(3,4)
a=a[[1,2],0]
print(a)
结果是[[4],[8]]
A. 正确 B. 错误
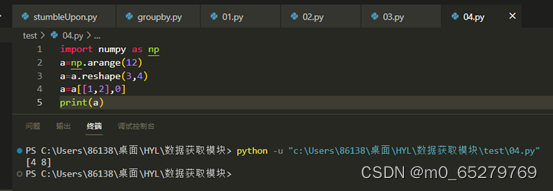
-
使用selenium+chrome可以爬取一般javaScript处理的网页数据
A. 正确
B. 错误
-
soup=BeautifulSoup(doc,"lxml")
_______________________________
print(tag)
程序结果找到class="story"的<p>元素,缺失的语句是
A. tag=soup.select_one("p[class='story']")
B. tag=soup.find("p",attr={"class":"story"})
C. tag=soup.soup.select("p[class='story']")
D. tag=soup.find("p",class="story")
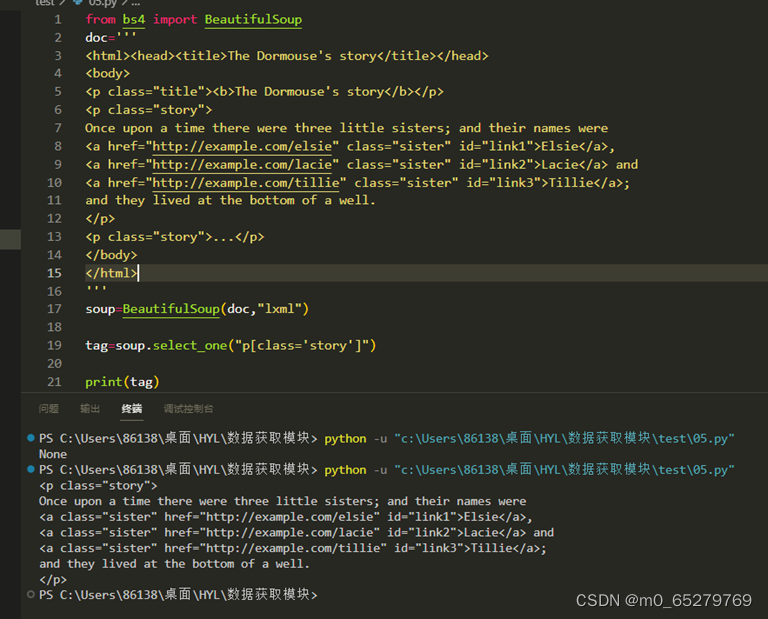
-
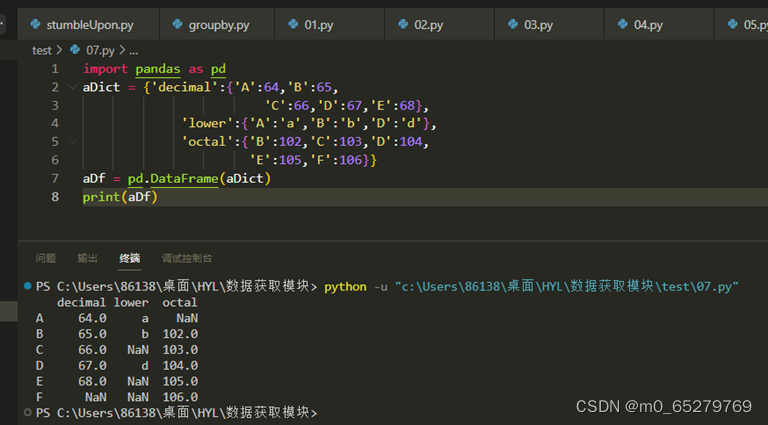
执行如下代码创建一个DataFrame对象aDf,在这里,aDf对象的列名称是( )。
import pandas as pd
aDict = {'decimal':{'A':64,'B':65,'C':66,'D':67,'E':68},'lower':{'A':'a','B':'b','D':'d'},
'octal':{'B':102,'C':103,'D':104, 'E':105,'F':106}}
aDf = pd.DataFrame(aDict)A. “decimal”、”lower”、”octal”
B. “A”、”B”、”C”
C. “A”、”B”、”C”、“D”、”E”、”F”
D. “decimal”、”lower”、”octal”、“A”、”B”、”C”
-
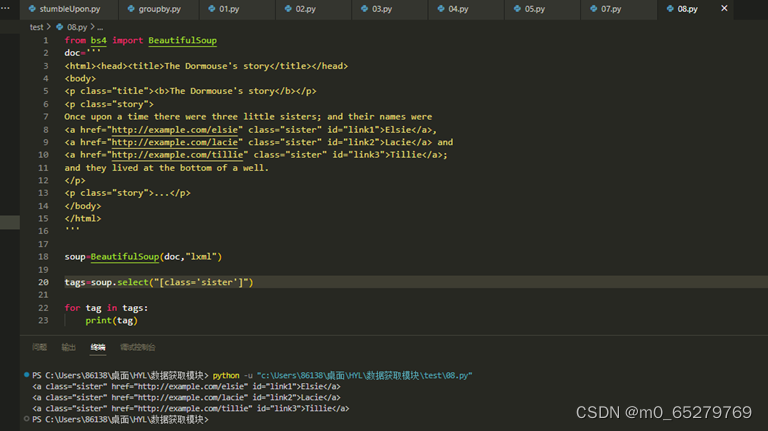
soup=BeautifulSoup(doc,"lxml")
___________________________________
for tag in tags:
print(tag)
查找文档中class="sister"的所有元素,缺失语句是:
A. tags=soup.select("[class='sister']")
B. tags=soup.select_one("[class='sister']")
C. tags=soup.select_all("[class='sister']")
D. tags=soup.find_all(attrs={"class":"sister"})
-
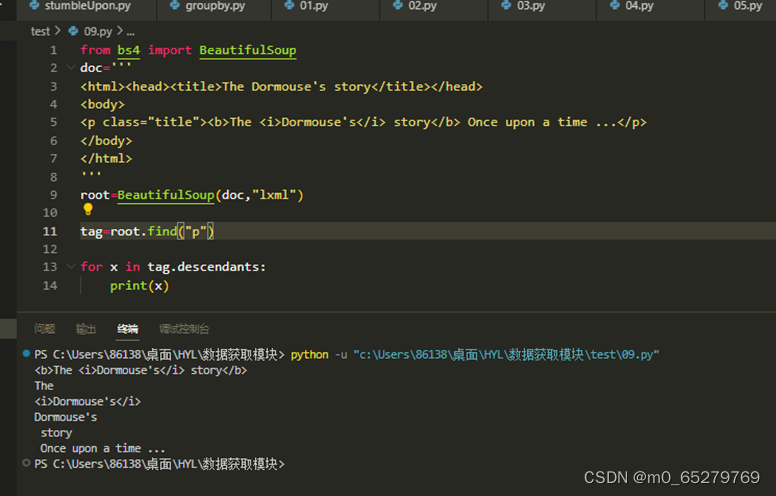
获取<p>元素的所有子孙元素节点
from bs4 import BeautifulSoup
doc='''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The <i>Dormouse's</i> story</b> Once upon a time ...</p>
</body>
</html>
'''
root=BeautifulSoup(doc,"lxml")
______________________________
for x in ________________________:
print(x)
缺失的语句是:
A. tag=soup.find("p"); tag.descendants
B. tag=soup.find("p"); tag.children
C. tag=soup.find_all("p"); tag.children
D. tag=soup.find_all("p"); tag.descendants
-
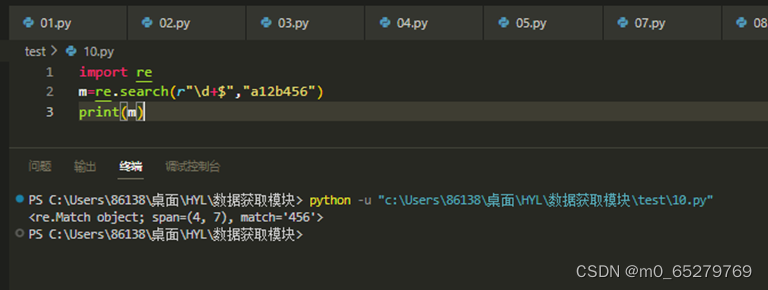
程序:
import re
m=re.search(r"\d+$","a12b456")
print(m)
匹配的结果是“456”字符串。
A. 正确
B. 错误
-
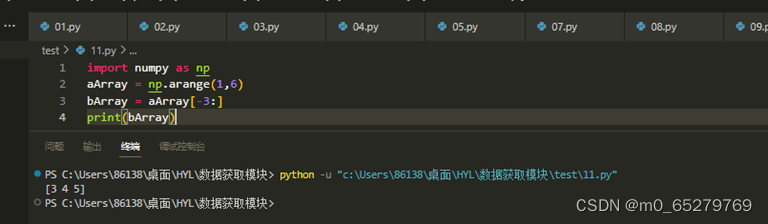
执行如下代码后,输出结果是( )。
import numpy as np
aArray = np.arange(1,6)
bArray = aArray[-3:]
print(bArray)
A. [1 2 3]
B. [2 3 4]
C. [3 4 5]
D. [4 5 6]
-
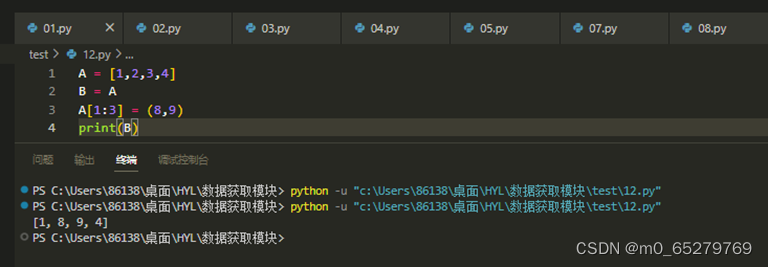
运行如下Python代码后,输出结果是( )。
A = [1,2,3,4]
B = A
A[1:3] = (8,9)
print(B)
A. [1,2,9,4]
B. [1,8,3,4]
C. [1,8,9,4]
D. [1,2,3,4]
-
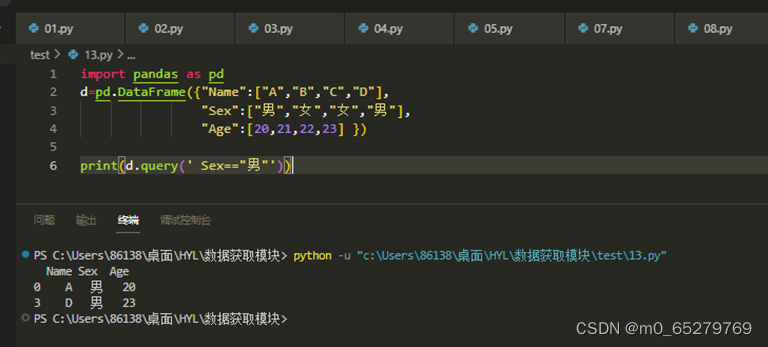
有一个学生DataFrame如下:
import pandas as pd
d=pd.DataFrame({"Name":["A","B","C","D"],
"Sex":["男","女","女","男"],
"Age":[20,21,22,23] })
找出所有男生的记录,操作是:
A. d.query(Sex=="男")
B. d.query(' Sex=="男"')
C. d.query[Sex=="男"]
D. d.query[' Sex=="男"']
-
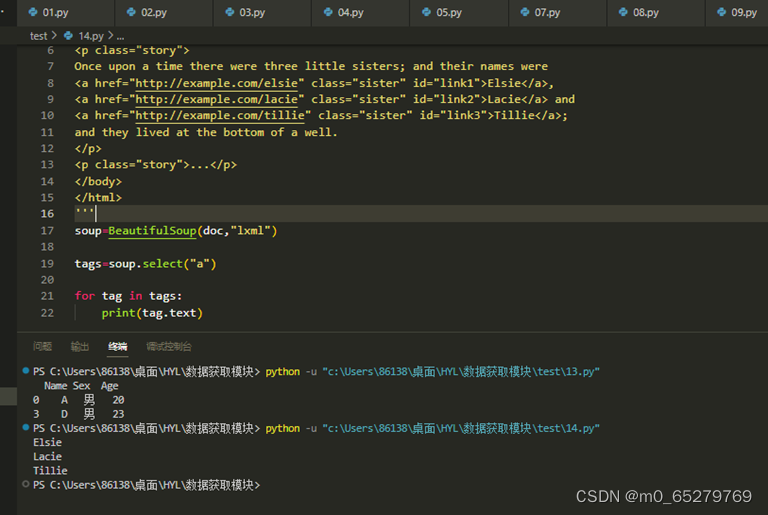
查找文档中所有<a>超级链接包含的文本值
soup=BeautifulSoup(doc,"lxml")
_____________________________
for tag in tags:
________________________
缺失的语句是:
A. tags=soup.select("a"); print(tag.text)
B.tags=soup.find("a"); print(tag["text"])
C.tags=soup.select_one("a"); print(tag.text)
D.tags=soup.find_all("a"); print(tag["text"])
-
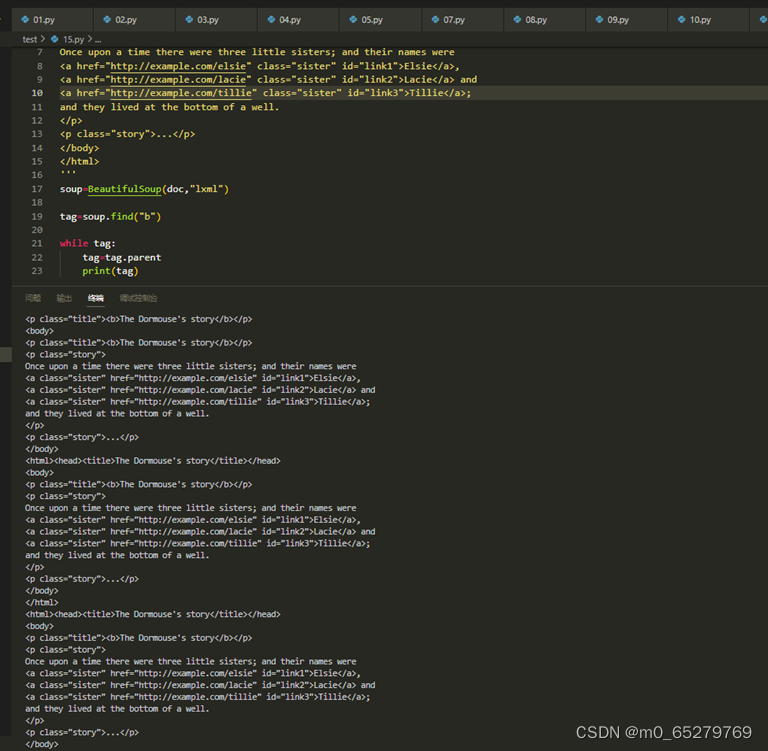
找出文档中<p class="title"><b>The Dormouse's story</b></p>的<b>元素节点的所有父节点的名称。
soup=BeautifulSoup(doc,"lxml")
print(soup.name)
________________________________
while tag:
print(tag.name)
____________________________
缺失的语句是:
A. tag=soup.find("b"); tag=tag.parent
B. tag=soup.find("b"); tag=tag["parent"]
C. tag=soup.find_all("b"); tag=tag.parent
D. tag=soup.find_all("b"); tag=tag["parent"]
-
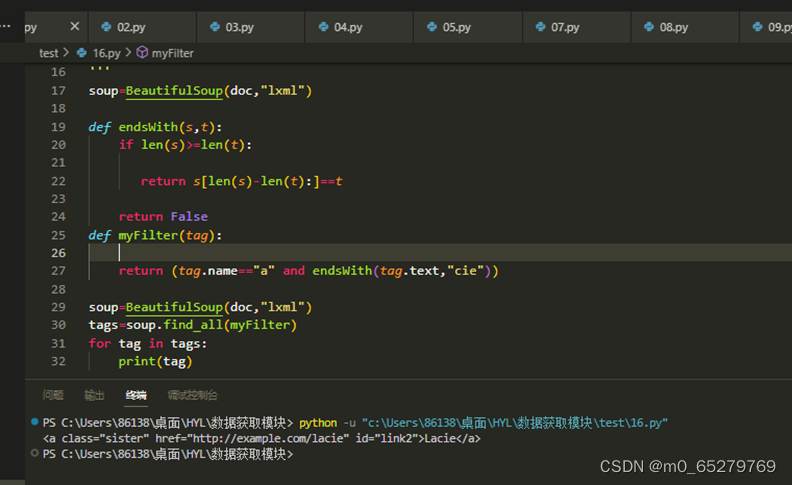
通过函数查找可以查找到一些复杂的节点元素,查找文本值以"cie"结尾所有<a>节点
def endsWith(s,t):
if len(s)>=len(t):
___________________________
return False
def myFilter(tag):
return (tag.name=="a" and _____________________________)
soup=BeautifulSoup(doc,"lxml")
tags=soup.find_all(myFilter)
for tag in tags:
print(tag)
缺失的语句是:
A. return s[len(s)-len(t):]==t; endsWith(tag.text,"cie")
B. return s[len(s)-len(t)-1:]==t; endsWith(tag.text,"cie")
C. return s[len(s)-len(t)-1:]==t; endsWith(tag["text"],"cie")
D. return s[len(s)-len(t):]==t; endsWith(tag["text"],"cie")
-
标准差越大,说明大部分数值和其平均值差异越大。(对)
-
CSV文件存储的是二进制数据。(错)
-
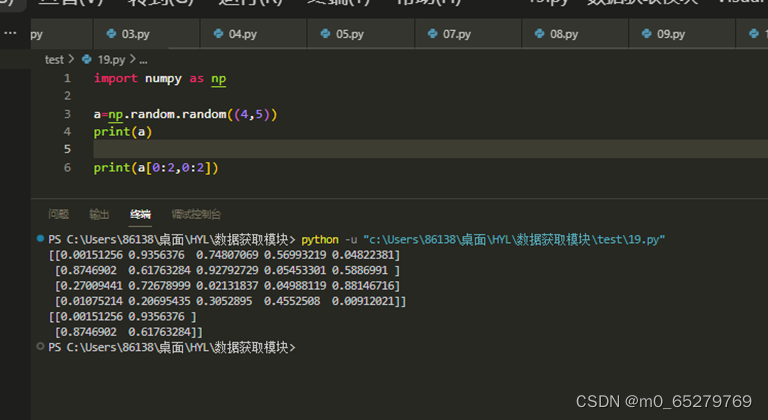
有一个随机值数组a=numpy.random.random((4,5)),截取前2行与前3列的数组,操作是
有没有可能是前2行与前2列
A. a[0:2,0:2]
B. a[0:2,:]
C. a[:,0:2]
D. a[[0,1],[0,1]]
-
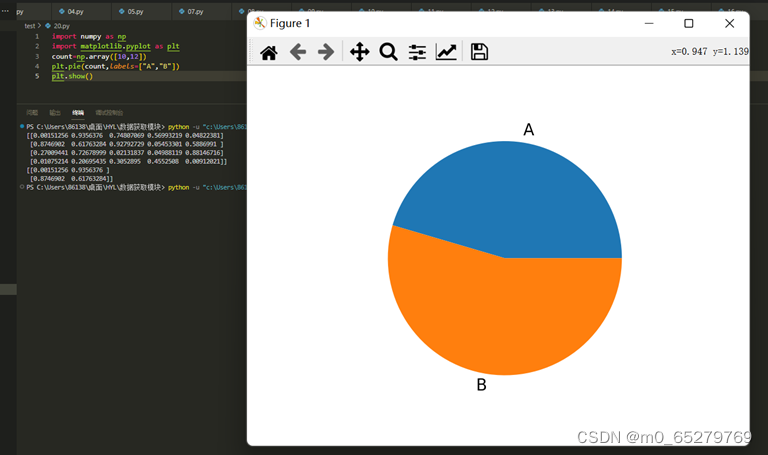
下列程序画出A,B的比例饼图,是否正确?
import numpy as np
import matplotlib.pyplot as plt
count=np.array([10,12])
plt.pie(count,labels=["A","B"])
plt.show()
A. 正确
B. 错误
-
BeautifulSoup是一个可以爬取网页数据的库。
A. 正确
B. 错误

-
可以使用索引的方式,操作Series对象的一个或一组元素。(对)
-
对序列对象进行切片操作,切片的数值不可以是负数。(错)
-
使用numpy二维数组a中np.nan的值元素替换为0
A. a[a==0]=0
B. a[np.isnan(a)]=0
C. a[isnan(a)]=0
D. a[np.isnull(a)]=0
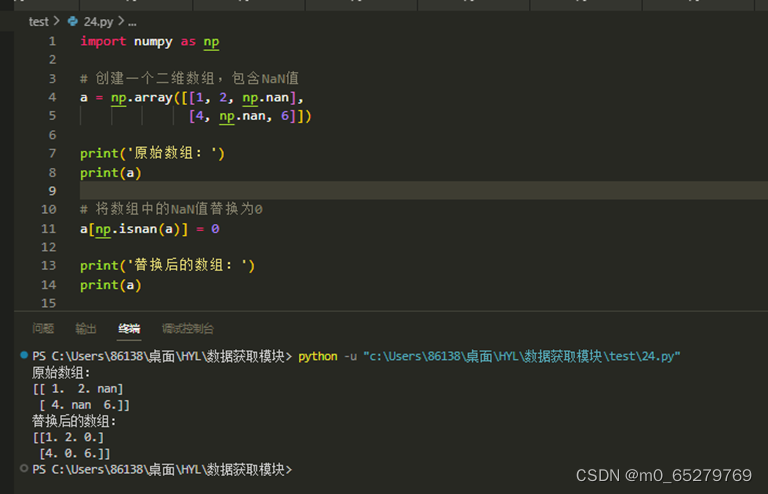
-
numpy是一个数组,只支持一维和二维的数组
A. 正确
B. 错误
-
运行如下Python代码后,输出结果是( )。
def numCompare(aNum, bNum):
if aNum > bNum:
print("%d 大于 %d" % ( aNum, bNum))
else:
print("%d 小于 %d" % ( aNum, bNum))
numCompare(5,5)
A. aNum小于bNum
B. 5 大于 5
C. 5 小于 5
D. 5 等于 5
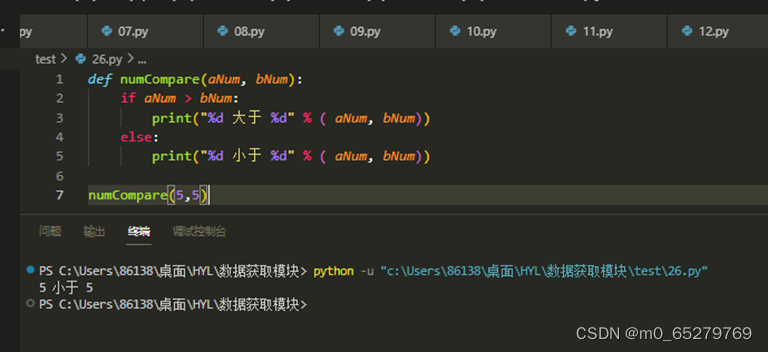
-
查找文档中所有超级链接地址
soup=BeautifulSoup(doc,"lxml")
______________________
for tag in tags:
_________________
缺失的语句是:
A. tags=soup.find_all("a");print(tag["href"]);
B. tags=soup.find("a");print(tag.href)
C. tags=soup.find_all("a");print(tag("href"))
D. tags=soup.find("a");print(tag.("href"))
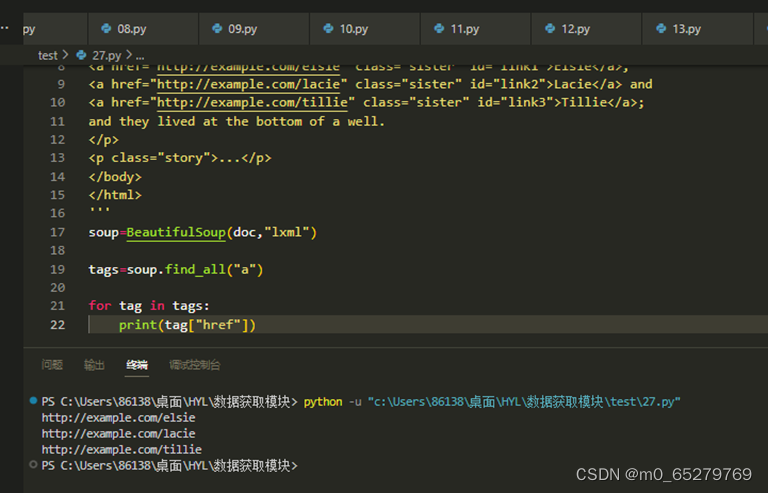
-
在主线程中启动一个子线程执行reading函数。
import threading
import time
import random
def reading():
for i in range(10):
print("reading",i)
time.sleep(random.randint(1,2))
_______________________________
r.setDaemon(False)
r.start()
print("The End")
A. r=threading.Thread(target=reading)
B. r=threading.Thread(reading)
C. r=threading.Thread(target=reading())
D. r=Thread(target=reading)
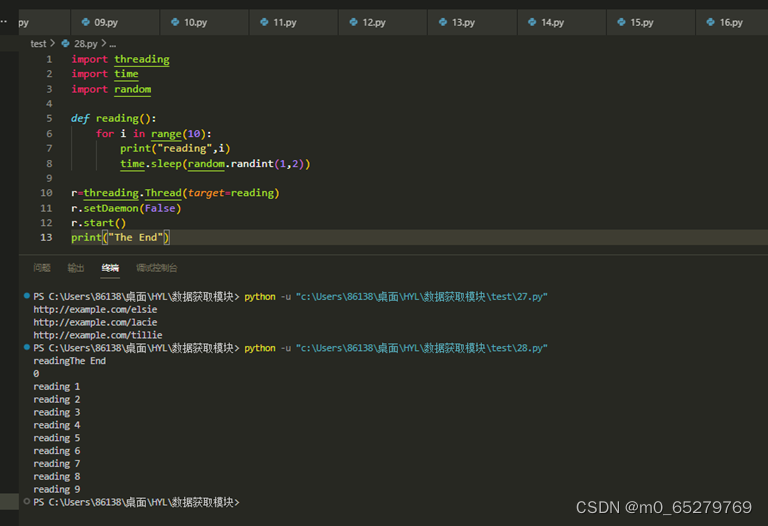
-
如果为DataFrame对象指定了索引,则不能对该对象进行切片操作,因为其默认的整数索引不存在了。(错)
-
执行如下代码后的输出结果是( )。
from numpy import array, arange, hstack, vstack, concatenate
aArray = array([arange(1,3), arange(3,5)])
bArray = array([arange(5,7), arange(7,9)])
cArray = hstack((aArray, bArray))
print(cArray)
A. [[1 2 3 4], [5 6 7 8]]
B. [[1 2], [ 3 4], [5 6],[7 8]]
C. [[1 2 5 6], [3 4 7 8]]
D. [[1 2], [ 5 6], [3 4],[7 8]]
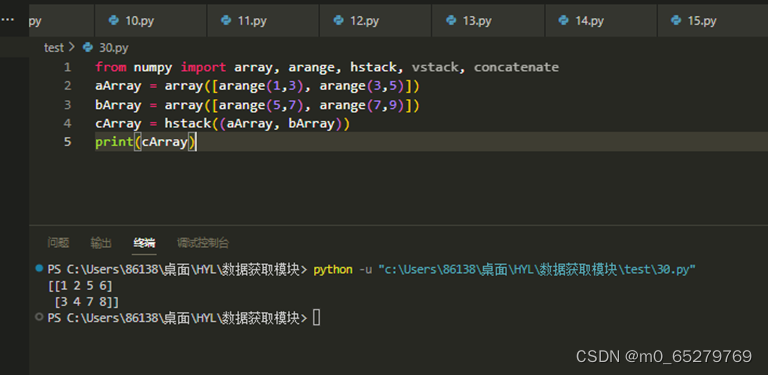
注:hstack是沿水平方向拼接
-
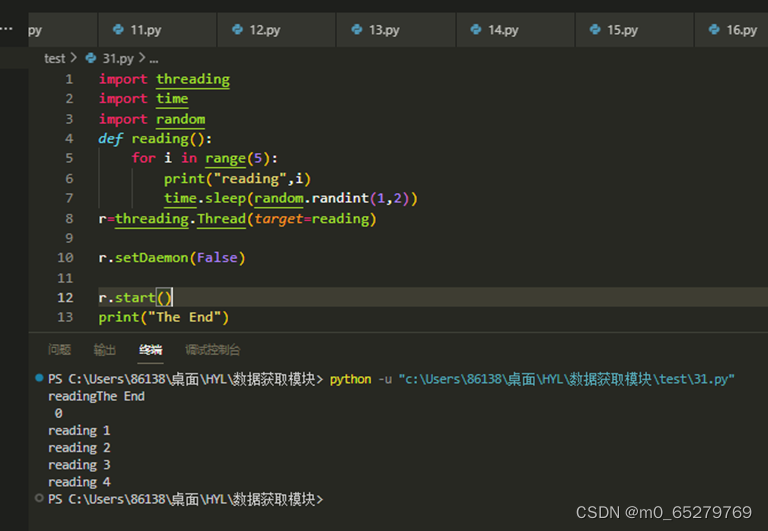
启动一个前台线程
import threading
import time
import random
def reading():
for i in range(5):
print("reading",i)
time.sleep(random.randint(1,2))
r=threading.Thread(target=reading)
__________________
r.start()
print("The End")
A. r.setDaemon(True)
B. r.setDaemon(true)
C. r.setDaemon(False)
D. r.setDaemon(false)
-
查找文档中所有<p>超级链接包含的文本值
soup=BeautifulSoup(doc,"lxml")
__________________________________
for tag in tags:
________________________
缺失的语句是:
A. tags=soup.select("p"); print(tag.text)
B.tags=soup.select_all("p"); print(tag.text)
C.tags=soup.find("p"); print(tag["text"])
D.tags=soup.find_all("p"); print(tag["text"])

-
通过使用flattern( ) 函数将二维数组aArray展平,并将结果赋值给数组bArray。此时,修改bArray元素的值,不会修改aArray的值。(对)
-
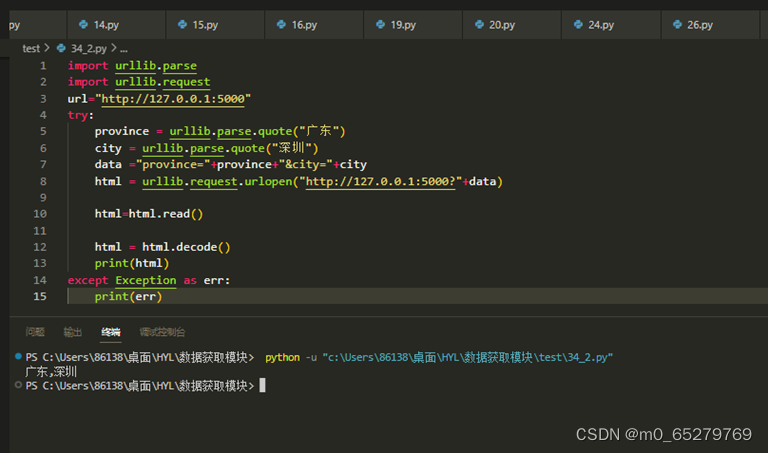
编写服务器程序server.py如下:
import flask
app=flask.Flask(__name__)
@app.route("/")
def index():
try:
province=flask.request.args.get("province")
city = flask.request.args.get("city")
return province+","+city
except Exception as err:
return str(err)
if __name__=="__main__":
app.run()
编写客户端程序client.py如下:
import urllib.parse
import urllib.request
url="http://127.0.0.1:5000"
try:
province= urllib.parse.quote("广东")
city= urllib.parse.quote("深圳")
data="province="+province+"&city="+city
html=urllib.request.urlopen("http://127.0.0.1:5000?"+data)
____________________
html = html.decode()
print(html)
except Exception as err:
print(err)
缺失的语句是
A. html=html.read()
B. html.read()
C. html=html.get()
D. html.get()
-
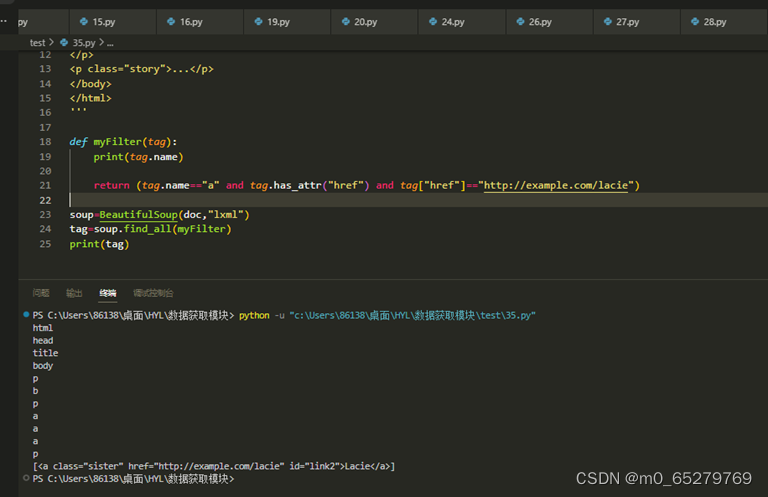
我们查找文档中的href="http://example.com/lacie"的节点元素<a>
def myFilter(tag):
print(tag.name)
__________________________________________
soup=BeautifulSoup(doc,"lxml")
tag=soup.find_all(myFilter)
print(tag)
缺失的语句是:
A. return (tag.name=="a" and tag.has_attr("href") and tag.href=="http://example.com/lacie")
B. return (tag.name=="a" and tag["href"]=="http://example.com/lacie")
C. return (tag.name=="a" and tag.has_attr("href") and tag["href"]=="http://example.com/lacie")
D. return (tag.name=="a" and tag.href=="http://example.com/lacie")
-
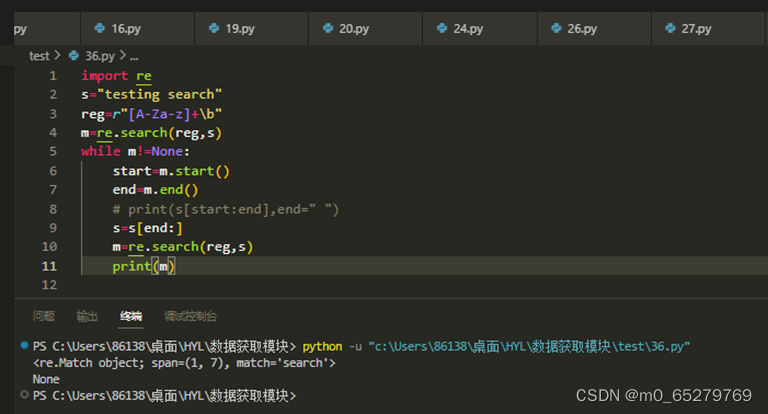
import re
s="testing search"
reg=r"[A-Za-z]+\b"
m=re.search(reg,s)
while m!=None:
start=m.start()
end=m.end()
print(s[start:end],end=" ")
s=s[end:]
m=re.search(reg,s)
结果:
A. testing search
B. testing
C. search
D. search testing
-
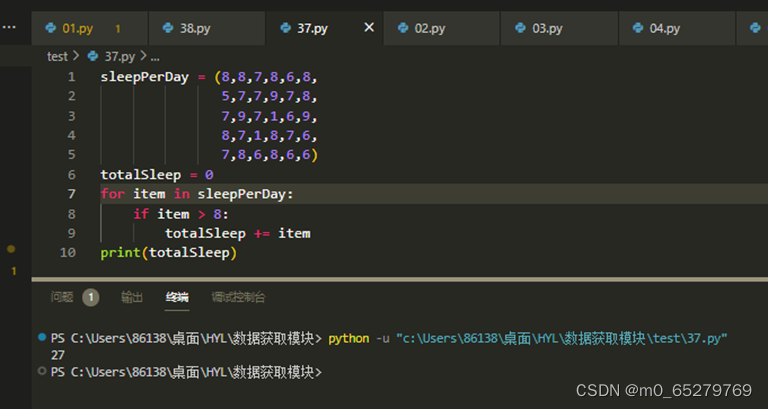
运行如下Python代码后,输出结果是( )。
sleepPerDay = (8,8,7,8,6,8,
5,7,7,9,7,8,
7,9,7,1,6,9,
8,7,1,8,7,6,
7,8,6,8,6,6)
totalSleep = 0
for item in sleepPerDay:
if item > 8:
totalSleep += item
print(totalSleep)
A. 0
B. 27
C. 35
D. 43
-
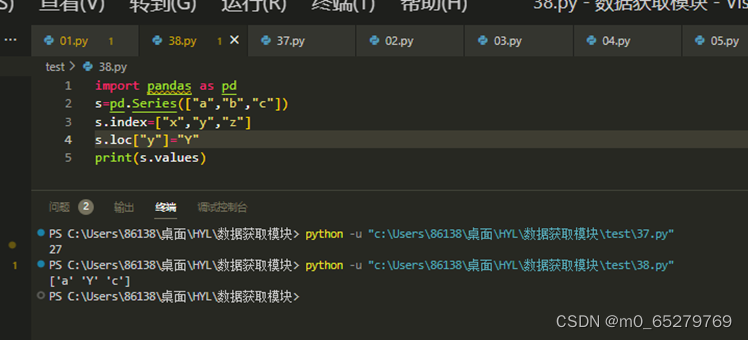
import pandas as pd
s=pd.Series(["a","b","c"])
s.index=["x","y","z"]
s.loc["y"]="Y"
print(s.values)
结果是 ["x","Y","z"]
A. 正确
B. 错误
-
只能使用python或者numpy、pandas等工具进行数据分析,其他编程语言都不能够进行数据分析工作。。(错)
-
如果数据集当中存在缺失值或异常值,那么通常需要首先处理这些缺失值或异常值,然后再对这组数据进行分析。(对)
-
相关系数是研究变量或数据之间线性相关程度的量。(对)
-
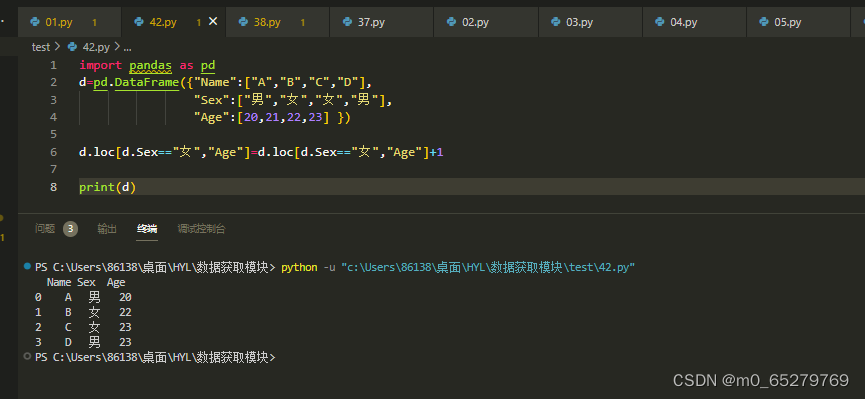
有一个学生DataFrame如下:
import pandas as pd
d=pd.DataFrame({"Name":["A","B","C","D"],
"Sex":["男","女","女","男"],
"Age":[20,21,22,23] })
把所有女生的年龄增加1,操作是:
A. d.loc[d.Sex=="女","Age"]=d.loc[d.Sex=="女","Age"]+1
B. d.loc["Age", d.Sex=="女"]=d.loc["Age", d.Sex=="女"]+1
C. d.query('Sex=="女"').Age=d.query('Sex=="女"').Age+1
D. 都不对
-
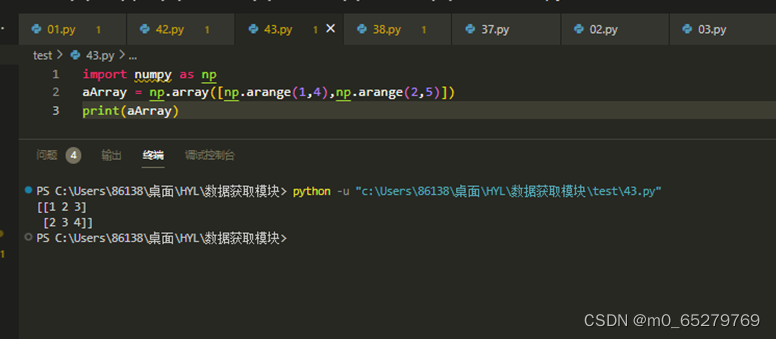
执行如下代码后, aArray的值是( )。
import numpy as np
aArray = np.array([np.arange(1,4),np.arange(2,5)])
A. [1 2 3 4; 2 3 4 5]
B. [[1 2 3 4]
[2 3 4 5]]
C. [1 2 3; 2 3 4]
D. [[1 2 3 ]
[2 3 4]]
-
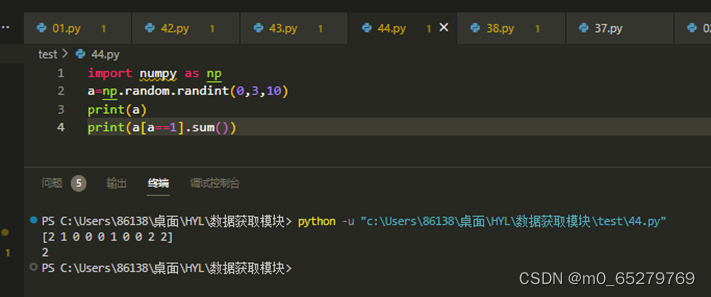
下列程序计算数组a中0的元素个数
import numpy as np
a=np.random.randint(0,3,10)
print(a)
print(a[a==1].sum())
A. 错误
B. 正确
-
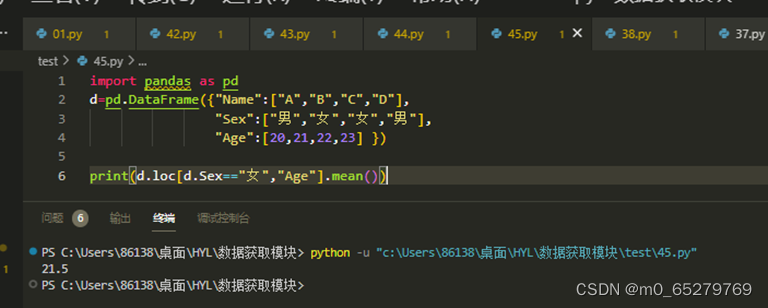
有一个学生DataFrame如下:
import pandas as pd
d=pd.DataFrame({"Name":["A","B","C","D"],
"Sex":["男","女","女","男"],
"Age":[20,21,22,23] })
把所有女生的平均年龄,操作是:
A. print(d.loc[d.Sex=="女","Age"].mean())
B. print(d.iloc[d.Sex=="女","Age"].mean())
C. print(d.query('Sex=="女"').loc["Age"].mean())
D. print(d.query('Sex=="女"').iloc["Age"].mean())
-
Python是一门解释性语言,可以对Python源代码进行编译。(错)
-
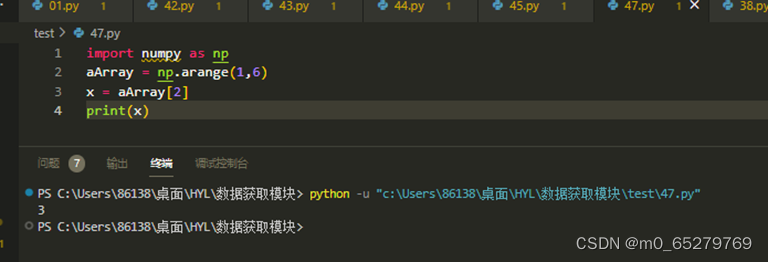
执行如下代码后,输出结果是( )。
import numpy as np
aArray = np.arange(1,6)
x = aArray[2]
print(x)
A. 1
B. 2
C. 3
D. 4
-
需要在代码中引入math包的sqrt( )函数,应该使用( )命令实现。
A. import sqrt and math
B. from math import sqrt
C. import math’s sqrt
D. import sqrt from math
-
获取<p>元素的所有直接子元素节点
from bs4 import BeautifulSoup
doc='''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The <i>Dormouse's</i> story</b> Once upon a time ...</p>
</body>
</html>
'''
root=BeautifulSoup(doc,"lxml")
________________
for x in __________________:
print(x)
缺失的语句是:
A. tag=root.find("p"); tag.children
B. tag=root.find("p"); tag.child
C. tag=root.find_all("p"); tag.children
D. tag=root.find_all("p"); tag.child
-
import numpy as np
a=np.random.randint(1,3,(2,3))
print(a)
结果a是一个2行3列的数组
A. 正确
B. 错误
-
使用numpy的函数poly1d( )创建多项式y=x^3+〖2x〗^2+3x+4,并将该对象赋值给变量aPoly,求解该多项式的一阶导数bPoly和二阶导数cPoly。通过numpy的arange( )函数创建数组X,做为直角坐标系的横轴,其取值范围是[-20,20]。在同一幅图上按列创建三个子图,分别绘制aPoly、bPoly和cPoly。
import numpy as np
import matplotlib.pyplot as plt# 创建多项式
aPoly = np.poly1d([1, 4, 3, 4])
print("多项式aPoly : ", aPoly)
# 求一阶导数和二阶导数
bPoly = aPoly.deriv()
cPoly = bPoly.deriv()
# 创建横轴数据
X = np.arange(-20, 20, 0.1)
# 绘制图形
fig, axs = plt.subplots(3, 1, figsize=(10, 10))
axs[0].plot(X, aPoly(X), label='aPoly')
axs[0].legend()
axs[1].plot(X, bPoly(X), label='bPoly')
axs[1].legend()
axs[2].plot(X, cPoly(X), label='cPoly')
axs[2].legend()
plt.show()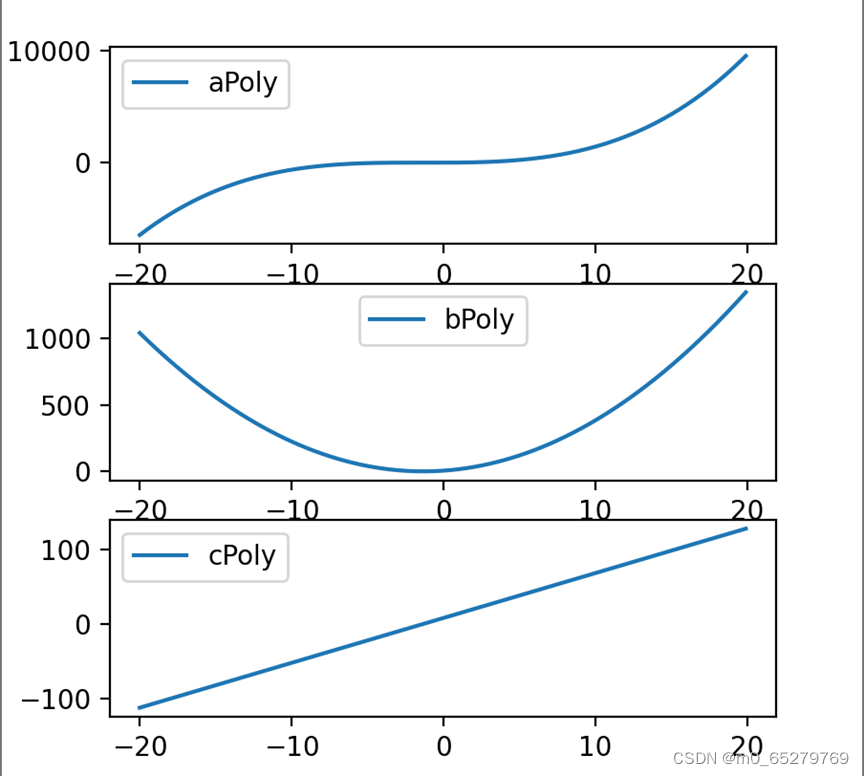
-
使用numpy包的loadtxt( )函数读取数据文件“ug_detect.csv”的第3、4、5列,分别赋值给变量humidity_str、gas_str和co_str。该数据文件的第一行是列名称,因此在读取的时候,不读取该行,从第二行开始读取。
采集时间点,温度(?C),相对湿度,瓦斯(m?/min),一氧化碳(m?/min)
1,30.22,69,2.9,3.6
2,37.68,2.86,3.64
import numpy as np
# 使用loadtxt函数读取数据文件,跳过第一行
data = np.loadtxt('C:/Users/86138/桌面/HYL/数据获取模块/test/ug_detect.csv', delimiter=',', skiprows=1, usecols=(1, 2, 3),encoding="UTF-8")
# 将第3、4、5列分别赋值给humidity_str、gas_str和co_str变量
humidity_str = data[:, 0]
gas_str = data[:, 1]
co_str = data[:, 2]
- 有一个网站有很多图片,要爬取这个网站的所有图片。
(1)你有什么办法让爬虫程序的效率高一些?
(2)写出基本的爬虫程序框架结构。
1.1、使用多线程或异步IO方式进行爬取,以尽可能地利用计算机资源。
1.2、合理设置请求头和延时,避免被反爬虫机制屏蔽。
1.3、对于大型图片文件,可以使用分片下载或断点续传等技术,提高下载效率。
1.4、合理选择爬虫框架和库,例如Scrapy等框架会自动处理并发、反爬虫等问题,能够加快开发速度。
import requests
from bs4 import BeautifulSoup
def get_image_urls(url):
# 发送HTTP请求获取页面内容
response = requests.get(url)
# 使用BeautifulSoup解析HTML文档
soup = BeautifulSoup(response.content, 'html.parser')
# 从页面中提取所有图片的URL
urls = []
for img in soup.find_all('img'):
urls.append(img['src'])
return urls
def download_images(urls):
# 遍历图片URL列表,逐一下载
for url in urls:
# 发送HTTP请求下载图片
response = requests.get(url)
# 将图片保存到本地
with open('image.jpg', 'wb') as f:
f.write(response.content)
if __name__ == '__main__':
# 爬取的网站URL
url = 'http://example.com'
# 获取所有图片的URL列表
urls = get_image_urls(url)
# 下载所有图片到本地
download_images(urls)
-
有一个班几十名同学的语文、数学、英语成绩,使用Flask创建网站如下:
import flask
App=flask.Flask(“web”)
@app.route(“/”)
def index():
S=’’’
<table border=”1”><td>学号</td><td>姓名</td><td>语文</td><td>数学</td><td>英语</td></tr>
<tr><td>1001</td><td>张三</td><td>80</td><td>78</td><td>75</td></tr>
<tr><td>1002</td><td>李四</td><td>78</td><td>88</td><td>79</td></tr>
<tr><td>...</td><td>...</td><td>...</td><td>...</td><td>...</td></tr>
</table>
‘’’
Return s
App.run()
完成下面的任务:
(1)编写爬虫程序爬取所有学生的学号、姓名、语文、数学、英语成绩,并把它们组织在一个DataFrame中。
(2)使用DataFrame编写程序计算语文、数学、英语的平均成绩。
(3)使用DataFrame统计语文成绩在[0,60)、[60,80)、[80,100]三个分数段的学生人数,并画出这三个段的人数比例拼图。
(4)保存DataFrame数据到marks.csv文件。
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 爬取学生成绩数据并组织成DataFrame
url = "http://url-to-scraped-data"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
rows = soup.find_all('tr')[1:]
data = []
for row in rows:
cols = row.find_all('td')
cols = [col.text.strip() for col in cols]
data.append(cols)
df = pd.DataFrame(data, columns=['学号', '姓名', '语文', '数学', '英语'])
# 计算语文、数学、英语平均成绩
chinese_mean = df['语文'].astype(float).mean()
math_mean = df['数学'].astype(float).mean()
english_mean = df['英语'].astype(float).mean()
# 统计分数段人数比例并画图
bins = [0, 60, 80, 100]
labels = ['[0,60)', '[60,80)', '[80,100]']
df['语文分数段'] = pd.cut(df['语文'].astype(float), bins=bins, labels=labels, include_lowest=True)
counts = df['语文分数段'].value_counts(normalize=True)
counts.plot(kind='pie')
# 保存DataFrame到csv文件
df.to_csv('marks.csv', index=False)















 7487
7487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









