









设计方案
1.1 课题概述
对课题的基本信息进行简要说明。
从英雄联盟官方网站等网站获取英雄的各方面信息,包括英雄在各种模式各种段位的英雄名、胜率、登场率、禁用率、KDA、场均击杀、场均助攻、场均时长、场均伤害、场均承伤、场均治疗、场均经济等等数据进行爬取;对原始数据进行预处理(去重、降噪、缺失值填充等),并分析英雄的不同数据(如分均伤害、分均承伤、分均治疗、分均经济、伤害转化、胜场、负场、净胜场等);利用各位置英雄数据进行分析,对KDA、分均伤害、分均经济、伤害转化、场均助攻、分均治疗、分均承伤这些数据进行最大最小归一化,然后根据不同位置进行计算加权得分,然后根据不同位置的英雄计算所有段位的得分平均值,最后按得分排序得到各位置英雄强度排名。然后利用英雄战绩对所有英雄进行分析,对胜率、BAN率、净胜场这些数据进行最大最小归一化,然后计算加权得分,然后算出各英雄在所有段位的得分平均值,从而得到所有英雄的排名。最后利用可视化将各种位置英雄强度前10名和后10名以及全部英雄强度的前10名和后10名展示出来。
1.2 详细设计
1.2.1 总体方案
本课题分四个模块:数据采集模块、数据预处理模块、数据分析模块、数据可视化模块,各模块的内容如下:
1.2.2 数据采集模块
数据采集阶段我使用selenium爬取英雄联盟官网的各分段各种模式的英雄战绩和各分段各种位置的英雄数据,英雄战绩分四个数据:英雄名、胜率、出场率、BAN率;英雄数据分九个数据:英雄名、KDA、场均击杀、场均助攻、场均时长、场均伤害、场均承伤、场均治疗、场均经济。
代码:
import openpyxl
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def aa():
url2 = "https://101.qq.com/#/hero-rank-5v5?tier=200&queue=420"
driver = webdriver.Chrome("./chromedriver.exe")
driver.get(url2)
# 等待页面元素出现
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div[3]/div/div[2]/div[1]/div[3]/div[1]/div'))
).click()
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div[3]/div/div[2]/div[1]/div[3]/div[2]/ul/li[1]'))
).click()
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div[3]/div/div[2]/div[1]/div[4]/div[1]/div/i'))
).click()
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div[3]/div/div[2]/div[1]/div[4]/div[2]/ul/li[1]'))
).click()
# 等待数据出现
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'hero-name'))
)
hero_list = ['英雄']
win_chance_list = []
onstage_times_list = []
ban_chance_list = []
yingxiongs = driver.find_elements(By.CLASS_NAME, 'hero-name')
shenglvs = driver.find_elements(By.CLASS_NAME, 'win-chance')
dengchanglvs = driver.find_elements(By.CLASS_NAME, 'onstage-times')
banlvs = driver.find_elements(By.CLASS_NAME, 'ban-chance')
for yingxiong in yingxiongs:
hero_list.append(yingxiong.text)
for shenglv in shenglvs:
win_chance_list.append(shenglv.text)
for dengchanglv in dengchanglvs:
onstage_times_list.append(dengchanglv.text)
for banlv in banlvs:
ban_chance_list.append(banlv.text)
# 将数据写入Excel文件
workbook = openpyxl.Workbook()
sheet = workbook.active
for i in range(len(hero_list)):
sheet.cell(row=i + 1, column=1, value=hero_list[i])
sheet.cell(row=i + 1, column=2, value=win_chance_list[i])
sheet.cell(row=i + 1, column=3, value=onstage_times_list[i])
sheet.cell(row=i + 1, column=4, value=ban_chance_list[i])
workbook.save(r"C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据\全部段位\英雄战绩\全部模式-英雄战绩.xlsx")
print("数据已保存到Excel文件中。")
# 关闭浏览器
driver.quit()
aa()1.2.3 数据预处理模块
数据预处理阶段我先进行了数据清洗,将出场率低于1%的元组删除,把场均时长后面的MIN字符串去掉;然后进行了数据变换,在英雄数据中构造分均伤害、分均承伤、分均治疗、分均经济、伤害转化5列数据,然后在英雄战绩数据中构造胜场、负场、净胜场3列数据
代码:
import os
import re
import pandas as pd
#数据清洗,将出场率低于1%的一列删除
def aaa():
# 获取英雄数据文件夹下指定的文件夹中的Excel文件,并进行处理
parent_path = r"C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据"
# 定义正则表达式匹配文件夹命名规则,符合要求的文件夹名前四个字为英雄战绩,后面就是四个数字
pattern = re.compile(r'^英雄战绩\d{4}$')
# pattern = re.compile(r'^英雄战绩\d{2}16$|^英雄战绩\d{3}06$')
# 获取英雄数据文件夹下所有符合要求的子文件夹及其子文件夹中的Excel文件,并进行处理
for root, dirs, files in os.walk(parent_path):
for dir_name in dirs:
# 判断文件夹名称是否符合要求
if pattern.match(dir_name):
dir_path = os.path.join(root, dir_name)
# 获取子文件夹及其子文件夹中的所有xlsx文件路径
file_list = []
for root, dirs, files in os.walk(dir_path):
for file in files:
if file.endswith(".xlsx"):
file_path = os.path.join(root, file)
file_list.append(file_path)
# 循环处理每个xlsx文件
for file_name in file_list:
print("正在处理文件: ", file_name) # 输出正在处理的Excel文件名称
# 读取Excel文件
try:
df = pd.read_excel(file_name)
# 将“登场率”列的类型转换为浮点数类型
df["登场率"] = df["登场率"].str.rstrip('%').astype(float) / 100
# 选择“登场率”小于0.01的数据
low_rate = df[df["登场率"] < 0.01]
# 删除“登场率”小于0.01的数据
df.drop(low_rate.index, inplace=True)
df["胜率"] = df["胜率"].str.rstrip('%').astype(float) / 100
df["BAN率"] = df["BAN率"].str.rstrip('%').astype(float) / 100
# 将修改后的数据保存到原文件中并覆盖原文件
df.to_excel(file_name, index=False)
except Exception as e:
print("处理文件时遇到错误: ", file_name, e) # 输出异常信息
#数据清洗,将场均时长后面的MIN字符串去掉
def bbb():
# 获取英雄数据文件夹下指定的文件夹中的Excel文件,并进行处理
parent_path = r"C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据"
# 定义正则表达式匹配文件夹命名规则,符合要求的文件夹名前四个字为英雄战绩,后面就是四个数字
pattern = re.compile(r'^英雄数据\d{4}$')
# pattern = re.compile(r'^英雄数据\d{2}16$|^英雄数据\d{3}06$')
# 获取英雄数据文件夹下所有符合要求的子文件夹及其子文件夹中的Excel文件,并进行处理
for root, dirs, files in os.walk(parent_path):
for dir_name in dirs:
# 判断文件夹名称是否符合要求
if pattern.match(dir_name):
dir_path = os.path.join(root, dir_name)
# 获取子文件夹及其子文件夹中的所有xlsx文件路径
file_list = []
for root, dirs, files in os.walk(dir_path):
for file in files:
if file.endswith(".xlsx"):
file_path = os.path.join(root, file)
file_list.append(file_path)
# 循环处理每个xlsx文件
for file_name in file_list:
print("正在处理文件: ", file_name) # 输出正在处理的Excel文件名称
# 读取Excel文件
try:
df = pd.read_excel(file_name)
df["场均时长"] = df["场均时长"].str.replace("MIN", "").astype(float)
# 将修改后的数据保存到原文件中并覆盖原文件
df.to_excel(file_name, index=False)
except Exception as e:
print("处理文件时遇到错误: ", file_name, e) # 输出异常信息
#数据变换,构造分均伤害、分均承伤、分均治疗、分均经济、伤害转化5列数据
def ccc():
# 获取英雄数据文件夹下指定的文件夹中的Excel文件,并进行处理
parent_path = r"C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据"
# pattern = re.compile(r'^英雄数据0616$')
pattern = re.compile(r'^英雄数据\d{4}$')
# 获取英雄数据文件夹下所有符合要求的子文件夹及其子文件夹中的Excel文件,并进行处理
for root, dirs, files in os.walk(parent_path):
for dir_name in dirs:
# 判断文件夹名称是否符合要求
if pattern.match(dir_name):
dir_path = os.path.join(root, dir_name)
# 获取子文件夹及其子文件夹中的所有xlsx文件路径
file_list = []
for root, dirs, files in os.walk(dir_path):
for file in files:
if file.endswith(".xlsx"):
file_path = os.path.join(root, file)
file_list.append(file_path)
# 循环处理每个xlsx文件
for file_name in file_list:
print("正在处理文件: ", file_name) # 输出正在处理的Excel文件名称
# 读取Excel文件
try:
df = pd.read_excel(file_name)
df["分均伤害"] = round(df.iloc[:, 5] / df.iloc[:, 4], 1)
df["分均承伤"] = round(df.iloc[:, 6] / df.iloc[:, 4], 1)
df["分均治疗"] = round(df.iloc[:, 7] / df.iloc[:, 4], 1)
df["分均经济"] = round(df.iloc[:, 8] / df.iloc[:, 4], 1)
df["伤害转化"] = round(df.iloc[:, 5] / df.iloc[:, 8], 3)
# 将修改后的数据保存到原文件中并覆盖原文件
df.to_excel(file_name, index=False)
except Exception as e:
print("处理文件时遇到错误: ", file_name, e) # 输出异常信息
#数据变换,构造胜场、负场、净胜场3列数据
def ddd():
# 获取英雄数据文件夹下指定的文件夹中的Excel文件,并进行处理
parent_path = r"C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据"
# pattern = re.compile(r'^英雄战绩0616$')
pattern = re.compile(r'^英雄战绩\d{4}$')
# 获取英雄数据文件夹下所有符合要求的子文件夹及其子文件夹中的Excel文件,并进行处理
for root, dirs, files in os.walk(parent_path):
for dir_name in dirs:
# 判断文件夹名称是否符合要求
if pattern.match(dir_name):
dir_path = os.path.join(root, dir_name)
# 获取子文件夹及其子文件夹中的所有xlsx文件路径
file_list = []
for root, dirs, files in os.walk(dir_path):
for file in files:
if file.endswith(".xlsx"):
file_path = os.path.join(root, file)
file_list.append(file_path)
# 循环处理每个xlsx文件
for file_name in file_list:
print("正在处理文件: ", file_name) # 输出正在处理的Excel文件名称
# 读取Excel文件
try:
df = pd.read_excel(file_name)
df["胜场"] = round(df.iloc[:, 1] * df.iloc[:, 2], 4)
df["负场"] = round((1 - df.iloc[:, 1]) * df.iloc[:, 2], 4)
df["净胜场"] = round((df.iloc[:, 1]-(1 - df.iloc[:, 1])) * df.iloc[:, 2], 4)
# 将修改后的数据保存到原文件中并覆盖原文件
df.to_excel(file_name, index=False)
except Exception as e:
print("处理文件时遇到错误: ", file_name, e) # 输出异常信息
aaa()
bbb()
ccc()
ddd()
1.2.4 数据分析模块
数据分析阶段,我先利用各位置英雄数据进行分析,对KDA、分均伤害、分均经济、伤害转化、场均助攻、分均治疗、分均承伤这些数据进行最大最小归一化,然后根据不同位置进行计算加权得分,然后根据不同位置的英雄计算所有段位的得分平均值,最后按得分排序得到各位置英雄强度排名。然后利用英雄战绩对所有英雄进行分析,对胜率、BAN率、净胜场这些数据进行最大最小归一化,然后计算加权得分,然后算出各英雄在所有段位的得分平均值,从而得到所有英雄的排名。
以下为各计算得分权重:
打野 : KDA 0.6,分均伤害0.2,分均经济0.2
下路 : KDA 0.5,分均伤害0.3,伤害转化0.2
中路 : KDA 0.6,分均伤害0.2,伤害转化0.2
辅助 : KDA 0.6,场均助攻0.2,分均治疗0.1,分均承伤0.1
上路 : KDA 0.6,分均伤害0.2,分均承伤0.2
全部英雄:胜率0.6,BAN率0.2,净胜场0.2
代码:
import os
import pandas as pd
#对各位置英雄进行强度分析,并得出得分
def jug():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“打野”开始,则进行处理
if file.endswith('.xlsx') and ("打野" in file[:2] or "打野" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,分均经济 进行最大最小归一化
df_norm = (data[['KDA', '分均伤害', '分均经济']] - data[['KDA', '分均伤害', '分均经济']].min()) / (
data[['KDA', '分均伤害', '分均经济']].max() - data[['KDA', '分均伤害', '分均经济']].min())
# 计算加权得分
df_norm['得分'] = df_norm['KDA'] * 0.6 + df_norm['分均伤害'] * 0.2 + df_norm['分均经济'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("打野英雄得分处理完成,文件路径为:", file_path)
def mid():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“中路”开始,则进行处理
if file.endswith('.xlsx') and ("中路" in file[:2] or "中路" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,分均经济 进行最大最小归一化
df_norm = (data[['KDA', '分均伤害', '伤害转化']] - data[['KDA', '分均伤害', '伤害转化']].min()) / (
data[['KDA', '分均伤害', '伤害转化']].max() - data[['KDA', '分均伤害', '伤害转化']].min())
# 计算加权得分
df_norm['得分'] = df_norm['KDA'] * 0.6 + df_norm['分均伤害'] * 0.2 + df_norm['伤害转化'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("中路英雄得分处理完成,文件路径为:", file_path)
def ad():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“下路”开始,则进行处理
if file.endswith('.xlsx') and ("下路" in file[:2] or "下路" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,伤害转化 进行最大最小归一化
df_norm = (data[['KDA', '分均伤害', '伤害转化']] - data[['KDA', '分均伤害', '伤害转化']].min()) / (
data[['KDA', '分均伤害', '伤害转化']].max() - data[['KDA', '分均伤害', '伤害转化']].min())
# 计算加权得分
df_norm['得分'] = df_norm['KDA'] * 0.5 + df_norm['分均伤害'] * 0.3 + df_norm['伤害转化'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("下路英雄得分处理完成,文件路径为:", file_path)
def top():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“下路”开始,则进行处理
if file.endswith('.xlsx') and ("上单" in file[:2] or "上单" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,伤害转化 进行最大最小归一化
df_norm = (data[['KDA', '分均伤害', '分均承伤']] - data[['KDA', '分均伤害', '分均承伤']].min()) / (
data[['KDA', '分均伤害', '分均承伤']].max() - data[['KDA', '分均伤害', '分均承伤']].min())
# 计算加权得分
df_norm['得分'] = df_norm['KDA'] * 0.6 + df_norm['分均伤害'] * 0.2 + df_norm['分均承伤'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("上单英雄得分处理完成,文件路径为:", file_path)
def sup():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“下路”开始,则进行处理
if file.endswith('.xlsx') and ("辅助" in file[:2] or "辅助" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,伤害转化 进行最大最小归一化
df_norm = (data[['KDA', '场均助攻', '分均治疗', '分均承伤']] - data[['KDA', '场均助攻', '分均治疗', '分均承伤']].min()) / (
data[['KDA', '场均助攻', '分均治疗', '分均承伤']].max() - data[['KDA', '场均助攻', '分均治疗', '分均承伤']].min())
# 计算加权得分
df_norm['得分'] = df_norm['KDA'] * 0.6 + df_norm['场均助攻'] * 0.2 + df_norm['分均治疗'] * 0.1 + df_norm['分均承伤'] * 0.1
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("辅助英雄得分处理完成,文件路径为:", file_path)
jug()
mid()
ad()
top()
sup()
#把得分数据全放入一个文件中
def jug1():
folder_path = r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据'
filepaths = []
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
if filename.startswith('打野') and filename.endswith('.xlsx'):
filepath = os.path.join(dirpath, filename)
filepaths.append(filepath)
data = []
for filepath in filepaths:
df = pd.read_excel(filepath)
data.append(df[['英雄', '得分']])
result = pd.concat(data)
result.to_excel('打野.xlsx', index=False)
def mid1():
folder_path = r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据'
filepaths = []
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
if filename.startswith('中路') and filename.endswith('.xlsx'):
filepath = os.path.join(dirpath, filename)
filepaths.append(filepath)
data = []
for filepath in filepaths:
df = pd.read_excel(filepath)
data.append(df[['英雄', '得分']])
result = pd.concat(data)
result.to_excel('中路.xlsx', index=False)
def ad1():
folder_path = r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据'
filepaths = []
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
if filename.startswith('下路') and filename.endswith('.xlsx'):
filepath = os.path.join(dirpath, filename)
filepaths.append(filepath)
data = []
for filepath in filepaths:
df = pd.read_excel(filepath)
data.append(df[['英雄', '得分']])
result = pd.concat(data)
result.to_excel('下路.xlsx', index=False)
def top1():
folder_path = r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据'
filepaths = []
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
if filename.startswith('上单') and filename.endswith('.xlsx'):
filepath = os.path.join(dirpath, filename)
filepaths.append(filepath)
data = []
for filepath in filepaths:
df = pd.read_excel(filepath)
data.append(df[['英雄', '得分']])
result = pd.concat(data)
result.to_excel('上单.xlsx', index=False)
def sup1():
folder_path = r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄数据'
filepaths = []
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
if filename.startswith('辅助') and filename.endswith('.xlsx'):
filepath = os.path.join(dirpath, filename)
filepaths.append(filepath)
data = []
for filepath in filepaths:
df = pd.read_excel(filepath)
data.append(df[['英雄', '得分']])
result = pd.concat(data)
result.to_excel('辅助.xlsx', index=False)
jug1()
mid1()
ad1()
top1()
sup1()
#整合数据求平均值
def jug2():
df = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\打野.xlsx')
# 对英雄一列进行分组并计算平均分
df_avg = df.groupby('英雄', as_index=False).agg({'得分': 'mean'})
df_avg['得分'] = round(df_avg['得分'], 4) # 保留4位小数
# 按照得分降序排列,并将结果存储到新文件
df_avg.sort_values(by='得分', ascending=False, inplace=True)
df_avg.to_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\打野_平均分降序.xlsx', index=False)
def mid2():
df = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\中路.xlsx')
# 对英雄一列进行分组并计算平均分
df_avg = df.groupby('英雄', as_index=False).agg({'得分': 'mean'})
df_avg['得分'] = round(df_avg['得分'], 4) # 保留4位小数
# 按照得分降序排列,并将结果存储到新文件
df_avg.sort_values(by='得分', ascending=False, inplace=True)
df_avg.to_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\中路_平均分降序.xlsx', index=False)
def ad2():
df = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\下路.xlsx')
# 对英雄一列进行分组并计算平均分
df_avg = df.groupby('英雄', as_index=False).agg({'得分': 'mean'})
df_avg['得分'] = round(df_avg['得分'], 4) # 保留4位小数
# 按照得分降序排列,并将结果存储到新文件
df_avg.sort_values(by='得分', ascending=False, inplace=True)
df_avg.to_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\下路_平均分降序.xlsx', index=False)
def top2():
df = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\上单.xlsx')
# 对英雄一列进行分组并计算平均分
df_avg = df.groupby('英雄', as_index=False).agg({'得分': 'mean'})
df_avg['得分'] = round(df_avg['得分'], 4) # 保留4位小数
# 按照得分降序排列,并将结果存储到新文件
df_avg.sort_values(by='得分', ascending=False, inplace=True)
df_avg.to_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\上单_平均分降序.xlsx', index=False)
def sup2():
df = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\辅助.xlsx')
# 对英雄一列进行分组并计算平均分
df_avg = df.groupby('英雄', as_index=False).agg({'得分': 'mean'})
df_avg['得分'] = round(df_avg['得分'], 4) # 保留4位小数
# 按照得分降序排列,并将结果存储到新文件
df_avg.sort_values(by='得分', ascending=False, inplace=True)
df_avg.to_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\辅助_平均分降序.xlsx', index=False)
jug2()
mid2()
ad2()
top2()
sup2()
#对全部位置英雄进行强度分析,并得出得分
def qbms():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“打野”开始,则进行处理
if file.endswith('.xlsx') and ("全部模式" in file[:2] or "全部模式" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,分均经济 进行最大最小归一化
df_norm = (data[['胜率', 'BAN率', '净胜场']] - data[['胜率', 'BAN率', '净胜场']].min()) / (
data[['胜率', 'BAN率', '净胜场']].max() - data[['胜率', 'BAN率', '净胜场']].min())
# 计算加权得分
df_norm['得分'] = df_norm['胜率'] * 0.6 + df_norm['BAN率'] * 0.2 + df_norm['净胜场'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("全部模式得分处理完成,文件路径为:", file_path)
def dsp():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“打野”开始,则进行处理
if file.endswith('.xlsx') and ("单双排" in file[:2] or "单双排" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,分均经济 进行最大最小归一化
df_norm = (data[['胜率', 'BAN率', '净胜场']] - data[['胜率', 'BAN率', '净胜场']].min()) / (
data[['胜率', 'BAN率', '净胜场']].max() - data[['胜率', 'BAN率', '净胜场']].min())
# 计算加权得分
df_norm['得分'] = df_norm['胜率'] * 0.6 + df_norm['BAN率'] * 0.2 + df_norm['净胜场'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("单双排得分处理完成,文件路径为:", file_path)
def gjbs():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“打野”开始,则进行处理
if file.endswith('.xlsx') and ("冠军杯赛" in file[:2] or "冠军杯赛" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,分均经济 进行最大最小归一化
df_norm = (data[['胜率', 'BAN率', '净胜场']] - data[['胜率', 'BAN率', '净胜场']].min()) / (
data[['胜率', 'BAN率', '净胜场']].max() - data[['胜率', 'BAN率', '净胜场']].min())
# 计算加权得分
df_norm['得分'] = df_norm['胜率'] * 0.6 + df_norm['BAN率'] * 0.2 + df_norm['净胜场'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("冠军杯赛得分处理完成,文件路径为:", file_path)
def lhzp():
# 定义操作文件夹
folder_path = "C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/"
# 遍历子文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
# 如果是 .xlsx 文件且以“打野”开始,则进行处理
if file.endswith('.xlsx') and ("灵活组排" in file[:2] or "灵活组排" in file[:-5]):
file_path = os.path.join(root, file)
# 读取数据
data = pd.read_excel(file_path)
# 对 KDA, 分均伤害,分均经济 进行最大最小归一化
df_norm = (data[['胜率', 'BAN率', '净胜场']] - data[['胜率', 'BAN率', '净胜场']].min()) / (
data[['胜率', 'BAN率', '净胜场']].max() - data[['胜率', 'BAN率', '净胜场']].min())
# 计算加权得分
df_norm['得分'] = df_norm['胜率'] * 0.6 + df_norm['BAN率'] * 0.2 + df_norm['净胜场'] * 0.2
# 将计算好的得分添加到DataFrame中,并保存到原文件中
data['得分'] = df_norm['得分'].round(4)
data.to_excel(file_path, index=False)
# 打印处理完成提示和文件路径
print("灵活组排得分处理完成,文件路径为:", file_path)
qbms()
dsp()
gjbs()
lhzp()
#把得分数据全放入一个文件中
def zhanji():
# 设置参数
source_folder = 'C:/Users/Jack/PycharmProjects/pythonProject2/英雄数据/'
output_file = '英雄强度得分.xlsx'
# 遍历文件夹,查找所需文件
files = []
for dirpath, dirnames, filenames in os.walk(source_folder):
for filename in filenames:
if (filename.startswith('单双排') and filename.endswith('.xlsx')) or \
(filename.startswith('冠军杯赛') and filename.endswith('.xlsx')) or \
(filename.startswith('全部模式') and filename.endswith('.xlsx')) or \
(filename.startswith('灵活组排') and filename.endswith('.xlsx')):
files.append(os.path.join(dirpath, filename))
# 提取数据
data = []
for file_path in files:
try:
df = pd.read_excel(file_path)
except Exception as e:
print(f'Error opening file {file_path}. Exception: {e}')
continue
data.append(df[['英雄', '得分']])
result = pd.concat(data)
# 保存文件
result.to_excel(output_file, index=False)
print(f'处理成功 {output_file}')
if __name__ == '__main__':
zhanji()
#整合数据求平均值
def zhanji1():
df = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄强度得分.xlsx')
# 对英雄一列进行分组并计算平均分
df_avg = df.groupby('英雄', as_index=False).agg({'得分': 'mean'})
df_avg['得分'] = round(df_avg['得分'], 4) # 保留4位小数
# 按照得分降序排列,并将结果存储到新文件
df_avg.sort_values(by='得分', ascending=False, inplace=True)
df_avg.to_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\英雄强度_平均分降序.xlsx', index=False)
zhanji1()
#将得分*100
import openpyxl
def sjcl():
folder_path = r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析'
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"):
file_path = os.path.join(folder_path, filename)
# 读取 Excel 文件
wb = openpyxl.load_workbook(file_path)
ws = wb.active
# 对得分一列中的所有数值乘以 100
for cell in ws['B']:
cell.value = cell.value * 100
# 保存修改
wb.save(file_path)
print(f'Successfully modified {file_path}')
1.2.5 数据可视化模块
数据可视化阶段,先将得分*100,然后使用柱状图将所有位置的英雄强度前10名和后10名以及得分展示出来。
代码:
import pandas as pd
import matplotlib.pyplot as plt
def ad():
# 读取 csv 文件
data = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析\下路_平均分降序.xlsx')
# 按得分从高到低排序
sorted_data = data.sort_values('得分', ascending=False)
# 取出前十名和后十名英雄数据
top10 = sorted_data.head(10)
bottom10 = sorted_data.tail(10)
# 绘制可视化图表
plt.rcParams['font.family'] = 'SimHei' # 修改matplotlib的默认字体
plt.subplot(1, 2, 1)
for i, score in enumerate(top10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(top10['英雄'], top10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('下路英雄强度(前十名)')
plt.subplot(1, 2, 2)
for i, score in enumerate(bottom10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(bottom10['英雄'], bottom10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('下路英雄强度(后十名)')
plt.tight_layout() # 防止图表重叠
plt.show()
def top():
# 读取 csv 文件
data = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析\上单_平均分降序.xlsx')
# 按得分从高到低排序
sorted_data = data.sort_values('得分', ascending=False)
# 取出前十名和后十名英雄数据
top10 = sorted_data.head(10)
bottom10 = sorted_data.tail(10)
# 绘制可视化图表
plt.rcParams['font.family'] = 'SimHei' # 修改matplotlib的默认字体
plt.subplot(1, 2, 1)
for i, score in enumerate(top10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(top10['英雄'], top10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('上单英雄强度(前十名)')
plt.subplot(1, 2, 2)
for i, score in enumerate(bottom10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(bottom10['英雄'], bottom10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('上单英雄强度(后十名)')
plt.tight_layout() # 防止图表重叠
plt.show()
def mid():
# 读取 csv 文件
data = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析\中路_平均分降序.xlsx')
# 按得分从高到低排序
sorted_data = data.sort_values('得分', ascending=False)
# 取出前十名和后十名英雄数据
top10 = sorted_data.head(10)
bottom10 = sorted_data.tail(10)
# 绘制可视化图表
plt.rcParams['font.family'] = 'SimHei' # 修改matplotlib的默认字体
plt.subplot(1, 2, 1)
for i, score in enumerate(top10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(top10['英雄'], top10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('中路英雄强度(前十名)')
plt.subplot(1, 2, 2)
for i, score in enumerate(bottom10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(bottom10['英雄'], bottom10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('中路英雄强度(后十名)')
plt.tight_layout() # 防止图表重叠
plt.show()
def jug():
# 读取 csv 文件
data = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析\打野_平均分降序.xlsx')
# 按得分从高到低排序
sorted_data = data.sort_values('得分', ascending=False)
# 取出前十名和后十名英雄数据
top10 = sorted_data.head(10)
bottom10 = sorted_data.tail(10)
# 绘制可视化图表
plt.rcParams['font.family'] = 'SimHei' # 修改matplotlib的默认字体
plt.subplot(1, 2, 1)
for i, score in enumerate(top10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(top10['英雄'], top10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('打野英雄强度(前十名)')
plt.subplot(1, 2, 2)
for i, score in enumerate(bottom10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(bottom10['英雄'], bottom10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('打野英雄强度(后十名)')
plt.tight_layout() # 防止图表重叠
plt.show()
def sup():
# 读取 csv 文件
data = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析\辅助_平均分降序.xlsx')
# 按得分从高到低排序
sorted_data = data.sort_values('得分', ascending=False)
# 取出前十名和后十名英雄数据
top10 = sorted_data.head(10)
bottom10 = sorted_data.tail(10)
# 绘制可视化图表
plt.rcParams['font.family'] = 'SimHei' # 修改matplotlib的默认字体
plt.subplot(1, 2, 1)
for i, score in enumerate(top10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(top10['英雄'], top10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('辅助英雄强度(前十名)')
plt.subplot(1, 2, 2)
for i, score in enumerate(bottom10['得分']):
plt.text(score + 0.5, i, str(score)) # 在柱状图每一列顶部显示分数
plt.barh(bottom10['英雄'], bottom10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('辅助英雄强度(后十名)')
plt.tight_layout() # 防止图表重叠
plt.show()
def all():
# 读取 csv 文件
data = pd.read_excel(r'C:\Users\Jack\PycharmProjects\pythonProject2\数据分析\英雄强度_平均分降序.xlsx')
# 按得分从高到低排序
sorted_data = data.sort_values('得分', ascending=False)
# 取出前十名和后十名英雄数据
top10 = sorted_data.head(10)
bottom10 = sorted_data.tail(10)
# 绘制可视化图表
plt.rcParams['font.family'] = 'SimHei' # 修改matplotlib的默认字体
plt.subplot(1, 2, 1)
for i, score in enumerate(top10['得分']):
plt.text(score + 0.5, i, str(round(score, 2))) # 在柱状图每一列顶部显示分数
plt.barh(top10['英雄'], top10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('全部英雄强度(前十名)')
plt.subplot(1, 2, 2)
for i, score in enumerate(bottom10['得分']):
plt.text(score + 0.5, i, str(round(score, 2))) # 在柱状图每一列顶部显示分数
plt.barh(bottom10['英雄'], bottom10['得分'])
plt.xlabel('得分')
plt.ylabel('英雄')
plt.title('全部英雄强度(后十名)')
plt.tight_layout() # 防止图表重叠
plt.show()
ad()
top()
mid()
jug()
sup()
all()
最终运行结果如下图所示:
下路英雄排名:
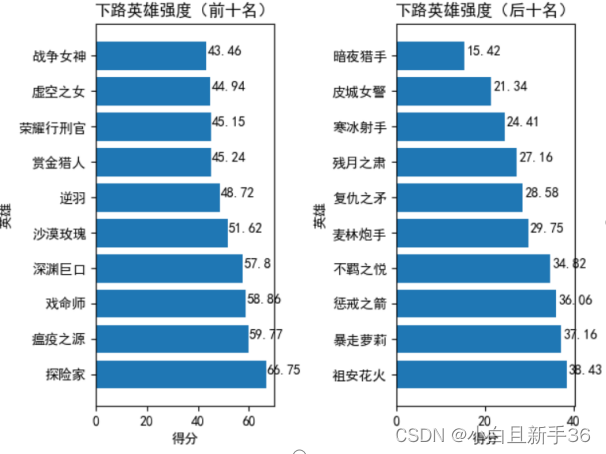
上单英雄排名:
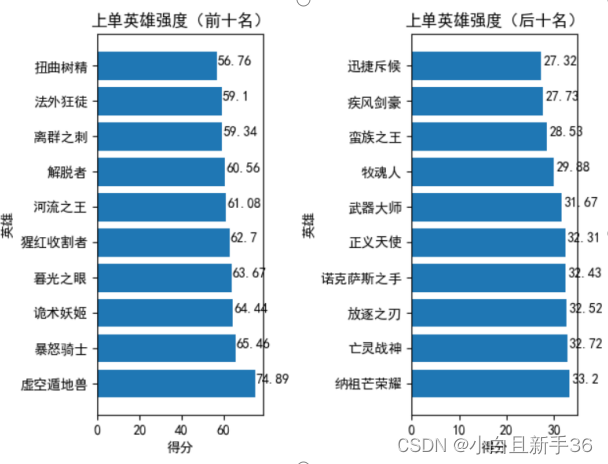
中路英雄排名:
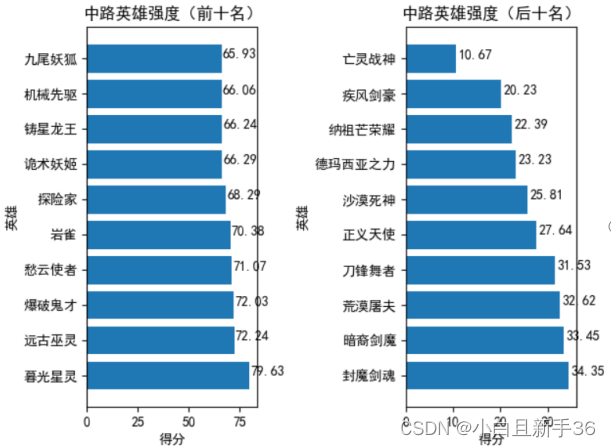
打野英雄排名:
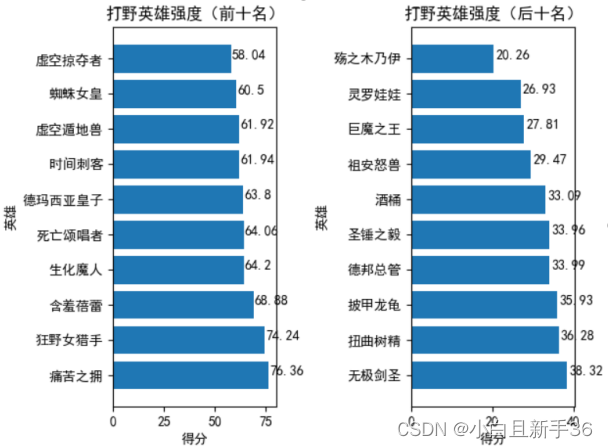
辅助英雄排名
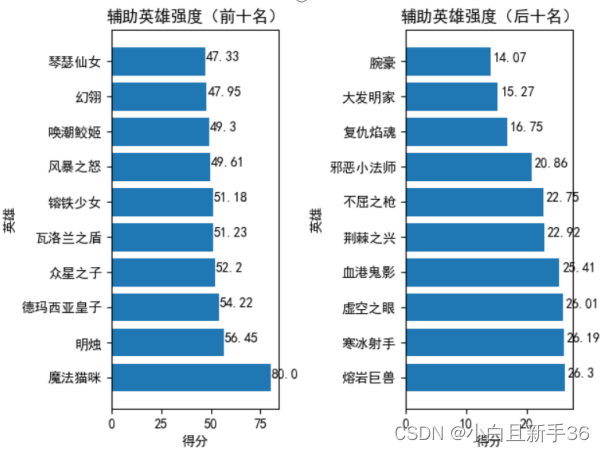
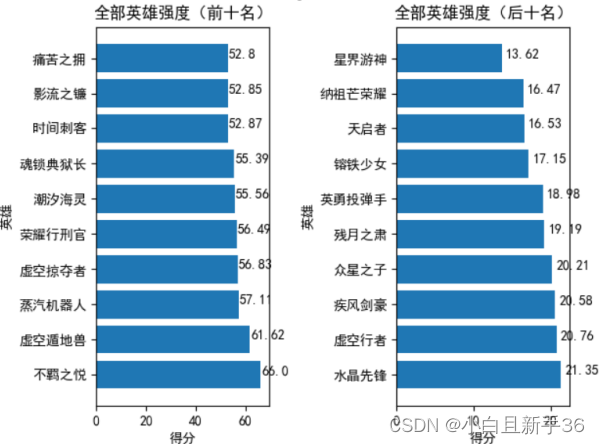
全部英雄排名:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











