







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
4.将读取到(选修课信息(1).xlsx文件)批量插入数据库
6.将读取到的数据(学生选课信息表(去重数据后).xls)批量插入数据库
五、统计每一个院系选修课为本院的情况,且对每一个院系的选修人数经行降序排序
一、题目:
1 .选修课信息(1).xlsx,信息如下:

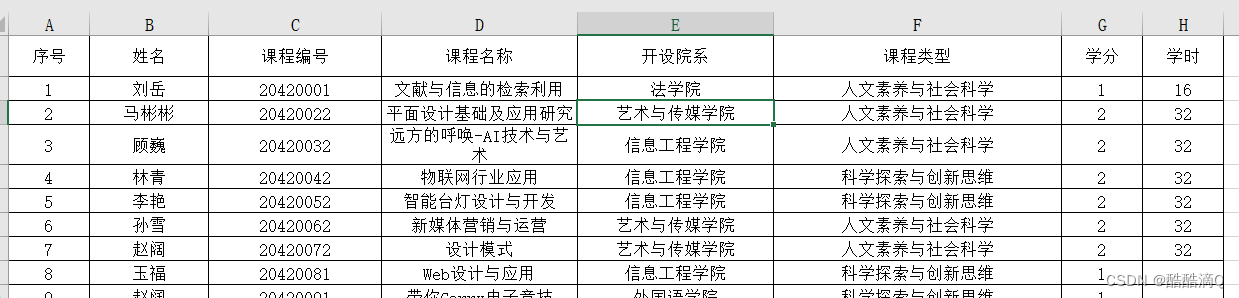
2 .学生选课信息表.xls,信息如下


3.任务
| 完成这样的一个系统,完成以下的功能: 1.请将文件中的信息导入数据库 2.统计每门公选课的选课情况,大于等于25人成班,并为每个成班的老师成一张学生花名册。 3.院里要获得选课课程统计信息,包括选课总人数,院内学生选修人数,外院学生选修人数,要包括总数据和每门课程的分数据。例如: 公选课编号 公选课名称 选修人数 本院选修人数 外院选修人数 ... ... ... ... ... - - - - - - - - - - - - 最后一行 总计- -- - - - - - - - - - - - - - - - 4.统计各个专业选修本院课程的情况,并按选修人数的多少,降序排序输出(要求按专业计算人数和百分比) 序号 专业名称 选修人数 占比 ... ... ... ..% (保留2位小数) - - - - - - - - 最后一行 总计- - - - - - - - - - 5.自己设计交互界面(非GUI界面) 项目要求 (1) 程序要添加适当的注释,程序要采用模块化编程,强调高内聚,低耦合。 (2) 程序要具在一定的健壮性,即当有错误操作时,程序也能适当地做出反应。 (3) 数据库设计合理,满足第3范式。 (4) 完成项目的基本功能 |
二、将文件中的信息导入数据库
1.实验前准备
建一个school的数据库,在建course.sql和student_scourse.sql的表;pycharm的开发环境中也下载、导入入相应的模块。
course.sql(选修课信息.xlsx)
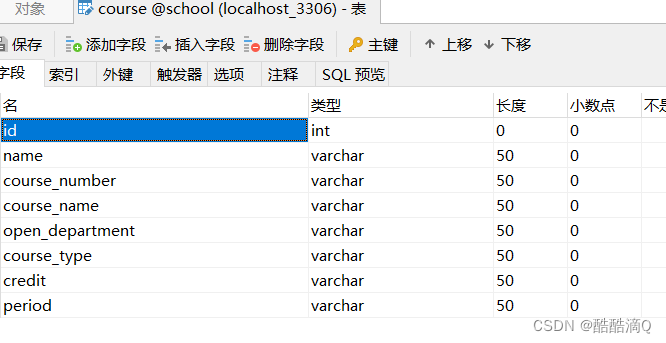
student_course.sql(学生选修课信息表.xls)
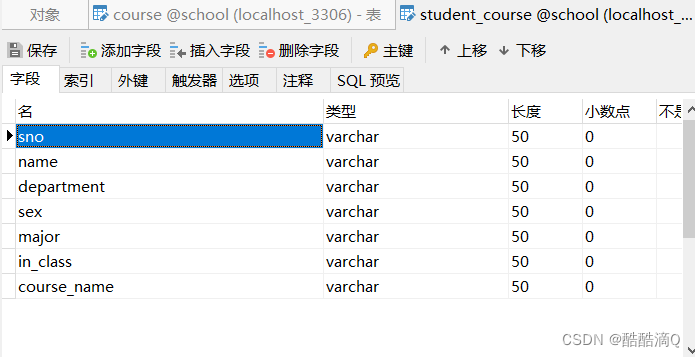
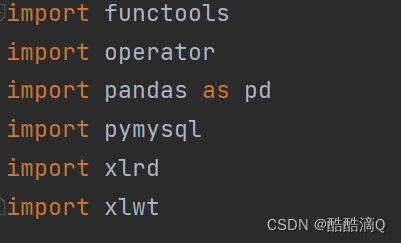
下载、导入相应的模块
2.连接mysql数据库
"""
一、连接mysql数据库
"""
def connection_database():
# 打开数据库连接
conn = pymysql.connect(
host='localhost', # MySQL服务器地址
user='root', # 用户名
password='123456', # 密码
charset='utf8', # 编码
port=3306, # MySQL服务器端口号
db='school', # 数据库名称
)
# 使用cursor()方法获取操作游标
# c = conn.cursor()
return conn
3.读取选修课信息(1).xlsx文件
"""
二、读取选修课信息(1).xlsx文件
"""
def read_course():
FilePath='选修课信息(1).xlsx'
# 1.打开excel文件
wkb = xlrd.open_workbook(FilePath)
# 2.获取sheet
sheet = wkb.sheet_by_index(0) # 获取第一个sheet表:选修课信息(1).xlsx
# 3.获取总行数
rows_number = sheet.nrows
# 4.遍历sheet表中所有行的数据,并保存至一个空列表cap[]
cap = []
for i in range(1, rows_number):
x = sheet.row_values(i) # 获取第i行的值(从0开始算起)
cap.append(x)
return cap
# print(cap) #[[1.0, '刘岳', 20420001.0, '文献与信息的检索利用', '法学院', '人文素养与社会科学', 1.0, 16.0], ...]

4.将读取到(选修课信息(1).xlsx文件)批量插入数据库
"""
三、将读取到的数据(选修课信息(1).xlsx文件)批量插入数据库
"""
def insert_course():
conn = connection_database() # 连接数据库
c = conn.cursor()
cap = read_course() # 读取选修课信息(1)到的数据
for stu in cap:
id = int(stu[0])
name = stu[1]
course_number = stu[2]
course_name = stu[3]
open_department = stu[4]
course_type = stu[5]
credit = stu[6]
period = stu[6]
# 使用f-string格式化字符串,对sql进行赋值
c.execute(
f"insert into course(id,name,course_number,course_name,open_department,course_type,credit,period) value ('{id}','{name}','{course_number}','{course_name}','{open_department}','{course_type}','{credit}','{period}')")
conn.commit()
conn.close()
print("选修课信息(1).xlsx文件,插入数据完成!")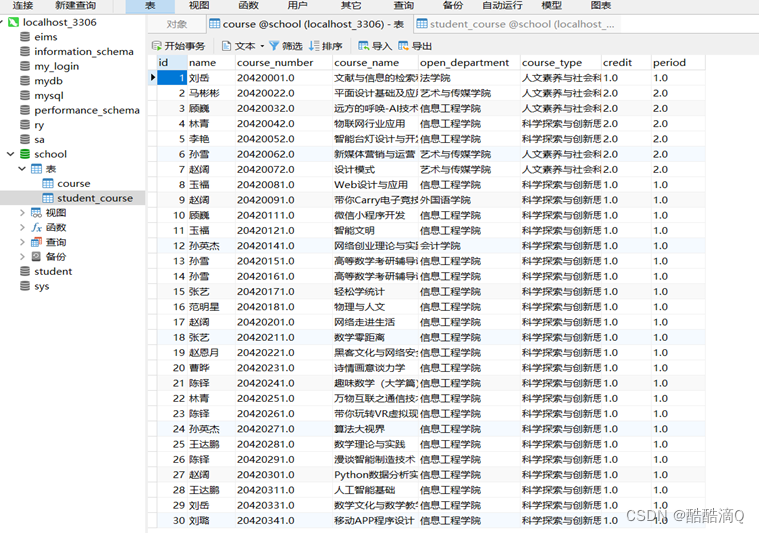
5.读取学生选课信息表.xls文件
考虑到有数据的重复,影响插入数据库,先检验是否有数据完全重复,执行删除重复行,将删除重复行的数据导入学生选课信息表(去重数据后).xls 最后,读取,学生选课信息表(去重数据后).xls
"""
四、读取学生选课信息表.xls文件
先检验是否有数据完全重复,执行删除重复行,将删除重复行的数据导入学生选课信息表(去重数据后).xls
最后,读取,学生选课信息表(去重数据后).xls
"""
def read_student_course():
data = pd.DataFrame(pd.read_excel('学生选课信息表.xls', 'Sheet1'))
# 查看读取数据内容
#print(data)
# 查看是否有重复行
re_row = data.duplicated()
# print(re_row)
# 查看去除重复行的数据
no_re_row = data.drop_duplicates()
#print(no_re_row) # 输出去重后的数据
# 将去重后的数据另建一个excle文件
# ***********已经执行过,不再执行。
# no_re_row.to_excel(r'C:\Users\覃运脉\Desktop\python期末\学生选课信息表(去重数据后).xls', index=False, engine='openpyxl')
FilePath = '学生选课信息表(去重数据后).xls'
# 1.打开excel文件
wkb1 = xlrd.open_workbook(FilePath)
# 2.获取sheet
sheet = wkb1.sheet_by_index(0) # 获取第一个sheet表:学生选课信息表.xls
# 3.获取总行数
rows_number = sheet.nrows
# 4.遍历sheet表中所有行的数据,并保存至一个空列表cap[]
cap1 = []
for i in range(1, rows_number):
x = sheet.row_values(i) # 获取第i行的值(从0开始算起)
cap1.append(x)
return cap1
# print(cap1)#[[21200101419.0, '王璇', '法学院', '男', '法学', '法学2104班', '高等数学考研辅导课(上)'], ....]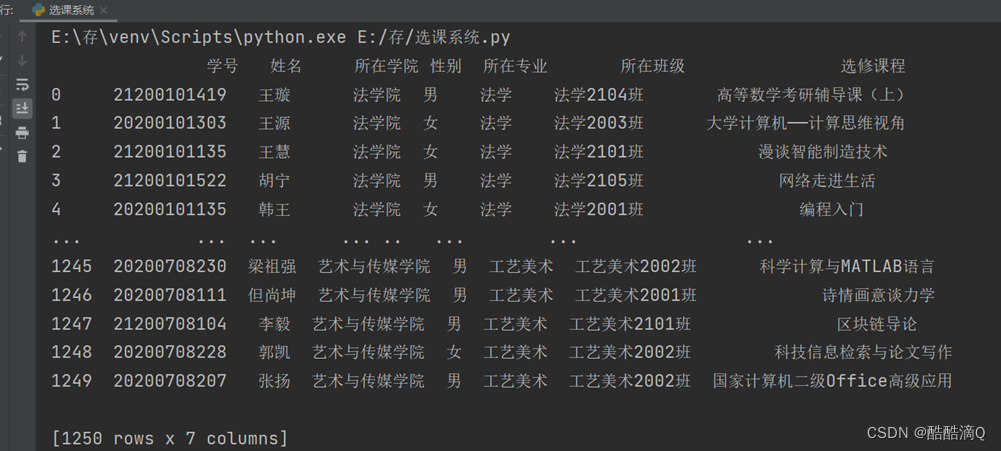
生成学生选课信息表(去重数据后).xls
6.将读取到的数据(学生选课信息表(去重数据后).xls)批量插入数据库
"""
五、将读取到的数据(学生选课信息表(去重数据后).xls)批量插入数据库
"""
def insert_student_course():
conn = connection_database() # 调用函数,连接数据库
c = conn.cursor()
cap1 = read_student_course() # 调用函数,读取‘学生选课信息表(去重数据后).xls’得到的数据
for stu in cap1:
sno = stu[0]
name = stu[1]
department = stu[2]
sex = stu[3]
major = stu[4]
in_class = stu[5]
course_name = stu[6]
# 使用f-string格式化字符串,对sql进行赋值
c.execute(
f"insert into student_course(sno,name,department,sex,major,in_class,course_name) value ('{sno}','{name}','{department}','{sex}','{major}','{in_class}','{course_name}')")
conn.commit()
conn.close()
print("学生选课信息表.xls文件,插入数据完成!")成功将数据插入数据库。

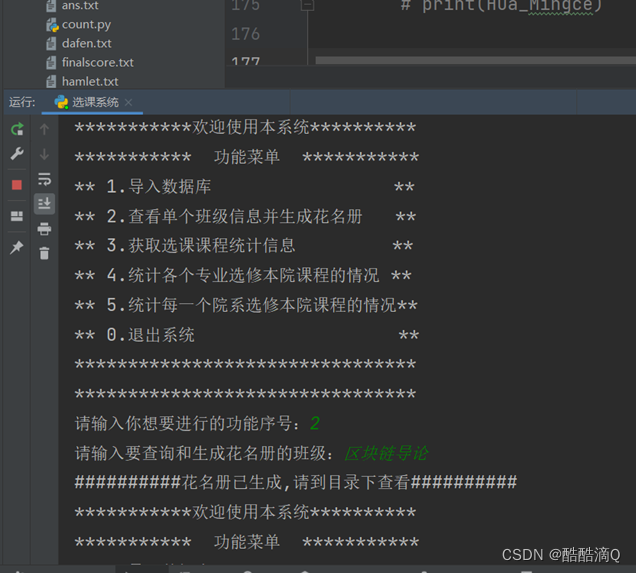
二、统计每一门的选修课情况并生成班花名册
首先,要在项目的目录下,建一个“花名册”的文件夹
'''
六、班花名册
'''
def roster(Class_name):
conn = connection_database() # 调用函数,连接数据库
c = conn.cursor()
# query = (Class_name) # 将要查询的课程转换为元组
sql = "SELECT * FROM student_course WHERE course_name ='%s'" % (Class_name)
c.execute(sql) # 调用数据库查询
course_group = c.fetchall()
# print(course_group)
Hua_Mingce = [] # 准备一个空列表用以存放数据库的查询结果
for raw in course_group:
Hua_Mingce.append(raw) # 循环使得数据库查询出的结果增加到列表里
if len(Hua_Mingce) >= 25: # 判断班级人数是否大于或等于25人
f = xlwt.Workbook('encoding = utf-8') # 设置工作簿编码
sheet1 = f.add_sheet('sheet1', cell_overwrite_ok=True) # 创建sheet工作表
try:
for i in range(len(Hua_Mingce)):
list_Huamingce = list(Hua_Mingce[i]) # 将原先查询出的数据由元组强制转换为列表
for j in range(0, 7):
sheet1.write(i, j, list_Huamingce[j]) # 写入数据参数对应 行, 列, 值
except:
print("")
fliter = "花名册/" + Class_name + ".xls"
f.save(fliter) # 保存.xls到当前工作目录
print("##########花名册已生成,请到目录下查看##########")
else:
print("!!!!!!!!!当前选修课人数小于25人,不成班!!!!!!!!!")
# print(Hua_Mingce)
效果截图:
三、院里要获得选课课程统计信息
'''
七、院里要获得选课课程统计信息
'''
def count():
conn = connection_database() # 调用函数,连接数据库
c = conn.cursor()
c.execute("select course_name from course ORDER BY course_number") # 查询所有课程语句,并且按课程编号排序
course_line = c.fetchall()
L = [] # 创建一个列表,用于储存数据库的查询结果
for row in course_line: # 创建循环
L.append(row) # 通过循环使数据库的查询结果增加到列表中
print("%-10s\t %-20s\t %-10s\t %-12s\t %-12s" % (
"公选课编号", "公选课名称", "选修人数", "本院选修人数", "外院选修人数"))
xxrs = sum_xxrs = sum_xxgc = sum_sum1 = 0 # 准备计算数据的浮点型
for t in range(len(L)): # 循环course_info传过来的课程列表
qt = xxgc = 0.0 # 准备其他学院和信息工程学院人数的计数
sum1 = 0.0 # 准备总人数的计数
query = (L[t]) # 准备将课程列表逐一插入SQL语句
sql1 = "SELECT department course_name FROM student_course WHERE course_name = '%s'" % (query)
c.execute(sql1)
cursor = c.fetchall()
# 查询当前循环下的各个学院的课程
sql2 = "SELECT course_number FROM course WHERE course_name = '%s'" % (query)
c.execute(sql2)
courseid = c.fetchall()
# 返回当前循环下的课程编号
course_id = []
for row in courseid:
course_id.append(row) # 将课程编号循环增加到准备好的列表里
# print(course_id)
Temp = []
for row in cursor:
Temp.append(row) # 将学院列表增加到准备好的列表里
for i in range(len(Temp)): # 循环各个课程的学院列表
# print(Temp[i])
str = functools.reduce(operator.add, (Temp[i])) # 将学院数据强制转换为String类型
if str == "信息工程学院": # 逐一判断是否为信息工程学院,是则信息工程学院人数+1,否则其他学院人数+1,同时总人数都+1
xxgc += 1
sum1 += 1
else:
qt += 1
sum1 += 1
xxrs = xxgc + qt # 计算选修总人数
sum_xxrs += xxrs
sum_xxgc += xxgc
sum_sum1 += qt
str_print = functools.reduce(operator.add, (L[t])) # 将当前循环的课程名称强制转换为String类型
print("%-10s\t %-20s\t %-10s\t %-12s\t %-12s" % (course_id, str_print, xxrs, xxgc, qt)) # 打印数据
print("\t\t\t\t\t\t\t\t\t\t\t %-10s\t %-12s\t %-12s" % (sum_xxrs, sum_xxgc, s
四、统计各个专业选修本院课程的情况
步骤:两表连接查询得到major_name(姓名,学院,专业名称,课程名称,课设院系);再对student_course学生选课表查询,获取到相应的专业名称,去重复的数据,将等到的结果转换为列表(手动复制,并附加上选修人数、选修外院人数且赋值为0),得到major(专业名称、选修人数、选修外院人数);算法计算,排序,输出结果。
'''
八、统计各个专业选修本院课程的情况,并按选修人数的多少
降序排序输出(要求按专业计算人数和百分比)
步骤:两表连接查询得到major_name(姓名,学院,专业名称,课程名称,课设院系);
再对student_course学生选课表查询,获取到相应的专业名称,去重复的数据,
将等到的结果转换为列表(手动复制,并附加上选修人数、选修外院人数且赋值为0),
得到major(专业名称、选修人数、选修外院人数);
算法计算,排序,输出结果。
'''
def sum_major():
conn = connection_database() # 调用函数,连接数据库
c = conn.cursor()
sql = "select student_course.`name`,student_course.department,student_course.major,student_course.course_name," \
"course.open_department from student_course join course on student_course.course_name=course.course_name; "
c.execute(sql) # 获取总共的学院列表
major_name = c.fetchall()
# print(major_name)
# (('勾晨', '法学院', '法学', '国家计算机二级Office高级应用', '通识教育课部'), ('勾晨', '法学院', '法学', '带你Carry电子竞技', '外国语学院')
'''
sql1 = "select student_course.major" \
" from student_course join course on student_course.course_name=course.course_name; "
c.execute(sql1) # 获取相应的专业名称
major1 = c.fetchall()
# print(major1)
major2 = set(major1)#除去重复的专业名称
# print(major2)
major = list(major2)#转换为列表
print(major)
#********************这部分暂时不用**************
'''
# 专业名称,选修人数,选修课为本院专业人数,相对于每一专业的数据
major = [
['物联网工程', 0, 0], ['产品设计', 0, 0], ['数据科学与大数据技术', 0, 0], ['旅游管理', 0, 0], ['人力资源管理', 0, 0], ['软件工程(中软班)', 0, 0],
['商务英语', 0, 0], ['国际贸易规则', 0, 0],
['网络工程(华为实验班)', 0, 0], ['英语', 0, 0], ['电子商务', 0, 0], ['金融学', 0, 0], ['工商管理', 0, 0], ['网络工程', 0, 0],
['审计学', 0, 0],
['法学', 0, 0], ['新闻学', 0, 0],
['工艺美术', 0, 0], ['会计学ACA', 0, 0], ['国际经济与贸易', 0, 0], ['酒店管理', 0, 0], ['会计学', 0, 0], ['数字媒体艺术', 0, 0],
['财务管理', 0, 0], ['投资学', 0, 0], ['跨境电子商务', 0, 0],
['供应链管理', 0, 0], ['财政学', 0, 0], ['工程管理', 0, 0], ['网络与新媒体', 0, 0], ['视觉传达设计', 0, 0], ['税收学', 0, 0],
['影视摄影与制作', 0, 0], ['软件工程(腾讯精英班)', 0, 0],
['环境设计', 0, 0], ['市场营销', 0, 0], ['物流管理', 0, 0], ['财务管理CIMA', 0, 0]]
for i in range(len(major_name)):
for j in range(len(major)):
# 计算各个专业的选修人数
if major_name[i][2] == major[j][0]: major[j][1] += 1
# 计算选修课为本院的人数
if (major_name[i][2] == major[j][0]) and (major_name[i][1] == major_name[i][4]):
major[j][2] += 1
# 按选修人数降序排序,对major经行排序
major.sort(key=lambda x: x[1], reverse=True)
# 输出相应的数据
print("专业名称\t\t选修人数\t\t选修课为本院专业人数\t\t占比")
for j in range(len(major)):
print("%s\t\t%d\t\t%d\t\t%.2f" % (major[j][0], major[j][1], major[j][2], (major[j][2] / major[j][1])))
# 计算总计的专业个数,各专业的选修人数,选修课为外院的人数
print('**********总计**********')
sum1 = 0
sum2 = 0
for i in range(len(major)):
sum1 += major[i][1]
sum2 += major[i][2]
print("专业数\t\t选修人数\t\t选修课为本院专业人数")
print("%d\t\t\t%d\t\t\t%d" % (len(major), sum1, sum2))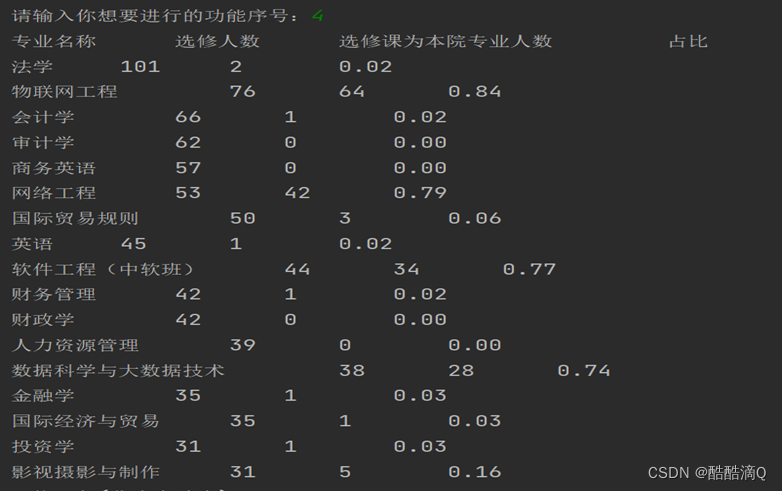
五、统计每一个院系选修课为本院的情况,且对每一个院系的选修人数经行降序排序
'''
九、统计每一个院系选修课为本院的情况,且对每一个院系的选修人数经行降序排序
'''
def count_department_major():
conn = connection_database() # 调用函数,连接数据库
c = conn.cursor()
fx = kj = jryjj = xxgc = wgy = gl = 0.0 # 准备计算中间变量
sql1 = "SELECT department FROM student_course ORDER BY department"
c.execute(sql1) # 获取总共的学院列表
major_name = c.fetchall()
sql2 = "SELECT DISTINCT department FROM student_course ORDER BY department"
c.execute(sql2) # 获取有多少个学院,不重复
judge = c.fetchall()
# [('会计学院',), ('信息工程学院',), ('外国语学院',), ('法学院',), ('管理学院',), ('艺术与传媒学院',), ('金融与经济学院',)]
major=[]#学院,每一个学院选修的人数
major1 = [['会计学院',0], ['信息工程学院', 0], ['外国语学院', 0], ['法学院', 0, ], ['管理学院', 0], ['艺术与传媒学院',0], ['金融与经济学院', 0]]
for row in major_name:
major.append(row) # 将查询的数据插入到列表
for t in range(len(major)): # 循环各个学生来自的学院
for i in range(len(major1)):
str_major = functools.reduce(operator.add, (major[t])) # 将各个学生来自的学院强制转换为String类型
if str_major==major1[i][0]:major1[i][1]+=1
#对每一个院系的选修人数进行降序排序
major1.sort(key=lambda x: x[1], reverse=True)
print("序号\t\t\t学院\t\t\t选修人数\t\t占比")
sum=0
for i in range(len(major1)):
sum+=major1[i][1]
for i in range(len(major1)):
print("%d\t\t%s\t\t%d\t\t%.2f"%(i,major1[i][0],major1[i][1],major1[i][1]/sum))
print("选修人数总计:%d" % sum) # 输出总的选修人数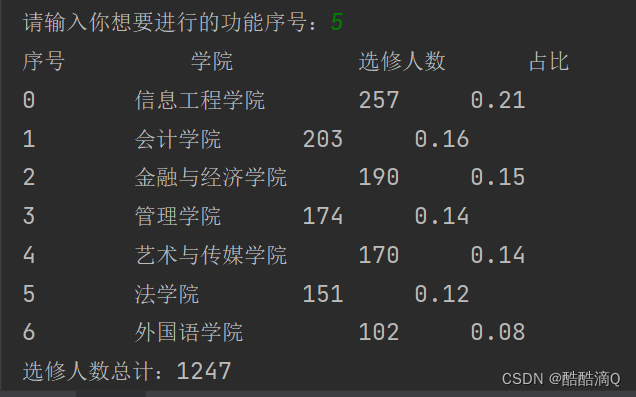
六、项目代码
七、总结
实验很有兴趣,收获很富!!!
以上就是今天要讲的内容,本文仅仅简单介绍了《Python程序开发》的实验过程和分析。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











