







用到的软件包
import os
import requests
from urllib.parse import quote正常流程

随便点击一个,选择标头拉到底部,User-Agent数据复制下来
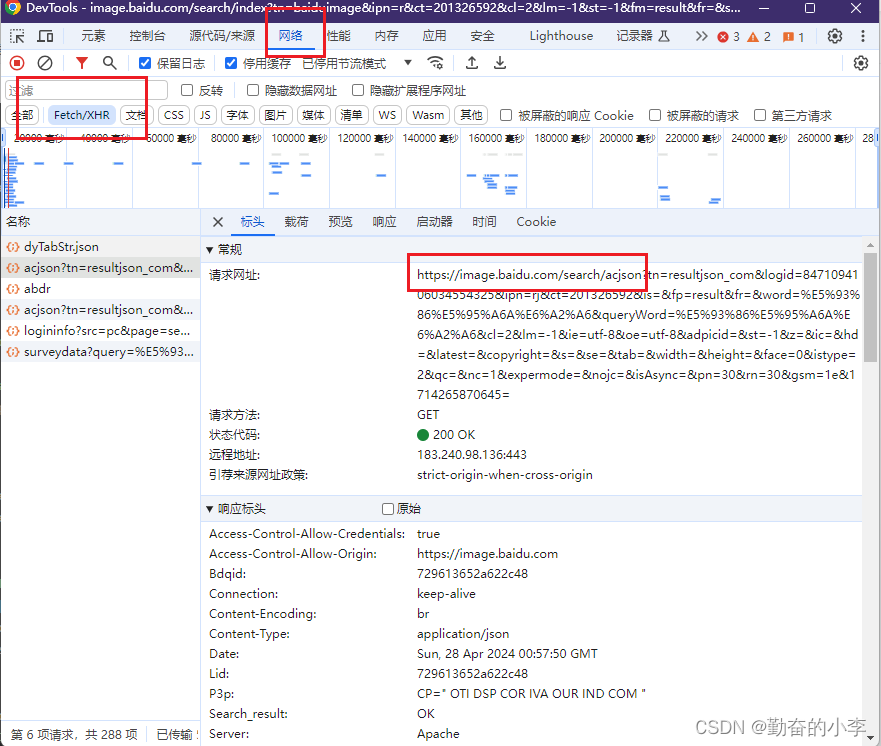
我拿的是一个接口,也可以拿别的用来获取数据
w=input('请输入要搜索的图片名:')#创建变量
encoded_text = quote(w) #将字符串进行 URL 编码
# f是格式化字符串的意思(ai说的),我的理解就是可以让字符串中存在变量
url = f"https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8639403618085309559&ipn=rj&ct=201326592&is=&fp=result&fr=&word={encoded_text}cg=wallpaper&queryWord={encoded_text}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={pn}&rn=30&gsm=1e&1713836271999="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}res = requests.get(url, headers=headers).json() #requests用于发起请求
print(res)requests可以发起不同请求,这里只用到get,携带headers这样不会被网页判定为机器人
for v in res['data']:
print(v)这次我们需要爬取的图片数据存放在data中
if v.get('thumbURL'):
image_url = v['thumbURL']
print(image_url)
image_name = os.path.basename(image_url.split('?')[0] + '.jpg')也可以那其他的链接,这里我拿的是 thumbURL中的链接
os创建图片下载链接
save_folder = "D:/图片" ##图片的保存为位置save_path = os.path.join(save_folder, image_name)图片的下载和图片名字
try:
urllib.request.urlretrieve(image_url, save_path)
print(f"成功下载图片: {image_name}")
except Exception as e:
print(f"下载图片 {image_name} 失败: {e}")确保下载过程中不被打断以及下载提示
全部代码
import os
import urllib.request
import requests
from urllib.parse import quote
pn = 30
flag = True
while flag:
w=input('请输入要搜索的图片名:')
encoded_text = quote(w)
print('下载包含输入的图片名的图片,可能会有些不同')
url = f"https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8639403618085309559&ipn=rj&ct=201326592&is=&fp=result&fr=&word={encoded_text}cg=wallpaper&queryWord={encoded_text}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={pn}&rn=30&gsm=1e&1713836271999="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
# "Referer":"https://pic.netbian.com/4k/",
}
# 创建保存图片的文件夹
save_folder = "D:/图片"
os.makedirs(save_folder, exist_ok=True)
res = requests.get(url, headers=headers).json()
if res['data']:
for v in res['data']:
if v.get('thumbURL'):
image_url = v['thumbURL']
image_name = os.path.basename(image_url.split('?')[0] + '.jpg')
save_path = os.path.join(save_folder, image_name)
try:
urllib.request.urlretrieve(image_url, save_path)
print(f"成功下载图片: {image_name}")
except Exception as e:
print(f"下载图片 {image_name} 失败: {e}")
pn += 30
else:
flag = False
print('此类图片没有了')
感觉不错的可以点一个小赞
















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











