







 本文详细解释了数据库中的索引概念,包括索引的创建、删除和内部数据结构(如B+树),以及事务的必要性、使用方法和特性,特别是隔离级别的讨论,以解决并发操作中的问题,提升数据库性能和数据一致性。
本文详细解释了数据库中的索引概念,包括索引的创建、删除和内部数据结构(如B+树),以及事务的必要性、使用方法和特性,特别是隔离级别的讨论,以解决并发操作中的问题,提升数据库性能和数据一致性。

目录
索引
数据库使用select查询的时候:
1.先遍历表
2.把当前的行给带入到条件中,看条件是否成立
3.条件成立,这样行就保留;否则,跳过。
如果表非常大,这样的遍历成本就比较高,至少是O(n),每次读取一个数据都需要读取磁盘,开销是很大的。所以,就引入了索引,索引属于是针对查询操作 引入的优化手段,可以通过索引来加快查询速度,避免针对表进行遍历。
概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
索引的相关操作
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
- 查看索引
show index from 表名;
一个索引是针对一个列来指定的,只有针对这一列进行条件查询的时候,查询速度才能被索引优化!!!
- 创建索引
create index 索引名 on 表名(字段名);
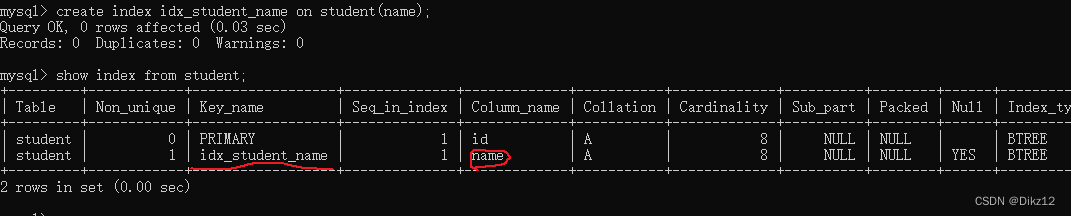
创建索引操作也是一个危险操作!
创建索引的时候,需要针对现有的数据,进行大规模的重新整理。如果这个表的本来就很大,创建索引,也很容易数据库服务器给卡住。
- 删除索引
如果自动创建的索引(主键 / 外键 / unique),是不能删除的!
drop index 索引名 on 表名;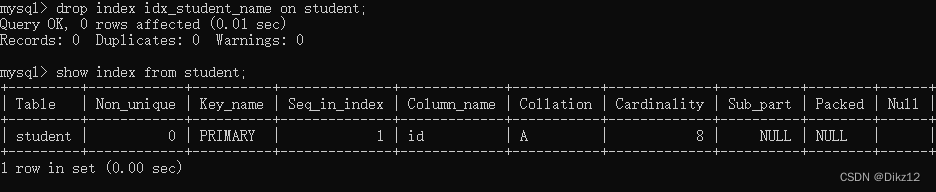
索引内部数据结构

数据库引入的索引是一个改进的树形结构B+树(N叉搜索树)。
了解B+树之前,还是要先了解下B树.
- B树
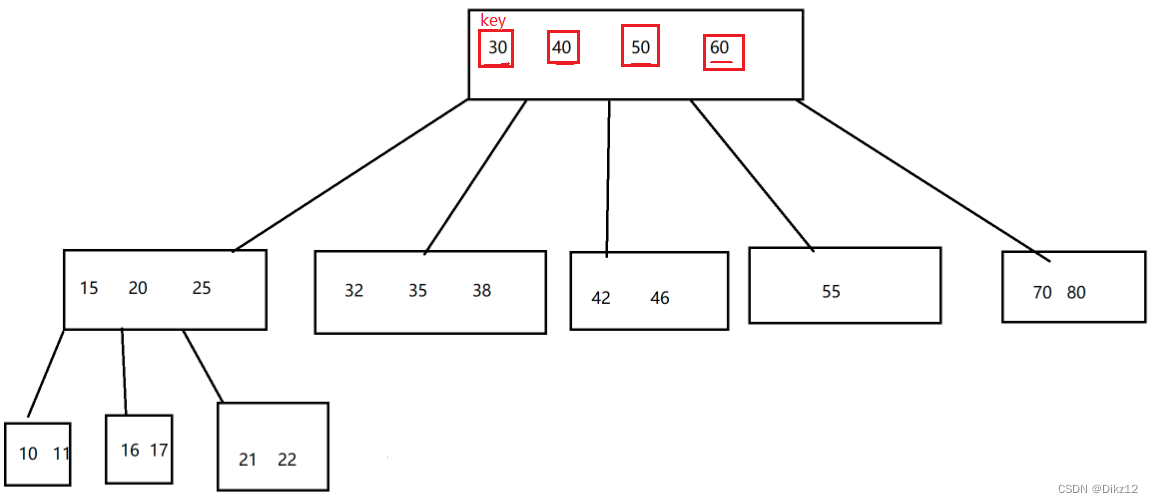
B树:也是N叉搜索树;
每个节点上有M个key,划分出M+1个区间;
进行查询的时候,就可以直接从根节点出发,判定当前要查的数据在节点上的那个区间,就决定好下一步往哪里走;
进行添加 / 删除元素就可能涉及到节点的拆分 / 节点的合并;
- B+树
B+树是堆B树的改进;可以说是针对数据库量身定做的。
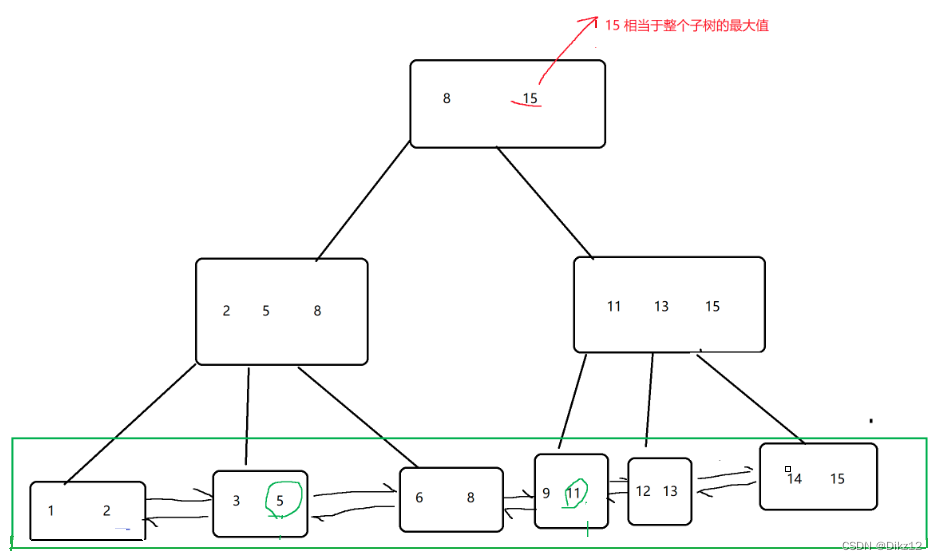
1.B+树是一个N叉搜索树.一个节点上存在N个key,划分为N个空间.
2.每个节点上的N个key, 最后一个,就相当于当前子树的最大值.
3.父节点上的每个key 都会以最大值的身份在子节点的对应区间存在.(key可能会重复出现()
(就是叶子节点这一层,包含了整个树的数据全集)
4.B+树会使用 链表 这样的结构,把叶子节点串起来。
(就非常方便的完成数据集合的遍历并且也很方便从数据集合中按照范围取出一个“子集”)
经典面试题!!!
B+树的优点(相对于B树以及哈希、红黑树):
1. N叉搜索树,树的高度有限的.降低IO的次数.
2.非常擅长范围查询.
3.所有查询最终都是要落到叶子节点.查询和查询之间的时间开销是稳定的.(不会出现这次快,下次慢)
4.由于叶子节点是全集,会把行数据只存储在叶子节点上; 非叶子节点只是存储一个用来排序的key.
事务
为什么使用事务?
开发中经常会涉及到一些场景,需要"一气呵成" 的完成一些操作.比如:转账~

引入事务就是为了避免上诉问题,事务就可以把多个sql打包成一个整体,可以保证sql要么全部执行,要么就“一个都不执行” 。(一个都不执行:不是真的一个都不执行,而是失败之后,只是看起来好像都没执行,关键操作,就是‘“翻新”,数据库称为“回滚” -> rollback)。
事务的使用
(1)开启事务: start transaction;
(2)执行各种sql
(3) 提交事务(结束):commit;
主动触发回滚: rollback => 出错,有很多中情况。
事务的使用,没什么说的,最重要的是事务背后的一些原理性质的内容!
也是经典的面试题!!!
事务的特性
1.原子性:回滚的方式,保证这一系列操作,都能执行正确,或者回复如初。
2.一致性:事务执行之前和之后,数据都不能太离谱。
3.持久性:事务做出修改,都是在硬盘上持久保存的,重启服务器,数据仍然是存在的,事务执行的修改仍然是有效的。
4.隔离性:
前三个都是好理解的,第四个隔离性涉及比较多!!也就单独拿出说。
隔离性: 数据库并发执行多个事务的时候,会涉及到一些问题.
并发执行:
并发程度越高,整体效率越高,隔离性越差,准确性越差!

在并发执行时,涉及的问题:
1.脏读问题

解决脏读问题:核心思路就是,针对写操作加锁。 只能读写完之后提交的数据
并发性降低了,隔离性提高了,效率降低了,数据准确性提高了!
2. 不可重复读 : 如果事务A在内部多次读取一个数据的时候,出现不同的情况,这种就是不可重复读.( 事务A 在两次读之间,有一个事务B 修改了数据并提交了事务)。
解决方法:刚才写的时候加锁了,写的时候不能读,没说读的时候不能写,所以,需要给读操作也加锁。(写的时候不能读,读的时候不能写)

3.幻读

解决方法:

效率 正确性 ==> 不同的需求场景 就有不同的要求
mysql服务器也提供了“隔离级别”,针对隔离级别程度进行设置,应对不同的需求场景。
上述内容就是事务的经典面试题!!
事务隔离级别
四种隔离级别,对应上面的三个问题,根据不同的业务场景,修改配置文件,设置不同的隔离级别。
















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









