






导读
在很多场景下,我们有非常多的表格或者图片,需要去识别其中表达的含义。但我们又不能使用Openai-o4的功能, 一个是国内用户使用起来不太方便,另外一个是成本比较高,同时隐私也得不到保护。例如公司的财务数据,员工的薪资数据,这个可不能让外部的大模型看到。
所以本文介绍如何私有化部署视觉大模型解决非结构化数据到格式化数据的视觉识别问题。

视觉大模型的格局
在我们深入讨论之前,了解大型视觉模型是什么,以及为什么它们胜过传统的光学字符识别(OCR)系统将会有所帮助。
与主要设计用于使用上一代算法从图像中提取文本的传统OCR系统不同,像GPT4o或Pixtral-12B或Llama 3.2–11B-Vision-Instruct这样的大型视觉模型能够完成的工作更多。
这些模型是多模态的,意味着它们可以处理文本和图像,并且是使用深度学习算法构建的,能够理解上下文,识别模式,并从复杂的非结构化输入中提取结构化数据。
传统的OCR可能在处理质量不佳的扫描、手写或混合格式时遇到困难(因为传统的ocr更多的还是基于定义的pattern去理解和识别),而大型视觉模型可以智能地解释视觉信息,以一种模仿人类理解的方式。
在过去几个月中出现了很多个视觉大模型。然而,选择合适的模型取决于需求。
例如,如果你的数据没有什么安全的控制,4o这样的GPT模型共享数据时无需担心,那么我们建议选择这种方式以节省成本, 这样既方便多用,效果一般也最好, 总体成本是最低的。
但是很多公司有严格的数据合规要求,这样就要私有化部署项目像Llama 3.2–11B-Vision或Pixtral-12B这样的模型,以确保数据的安全
同时如果平常这类数据处理的比较多,那私有化部署之后也有可能是可以降成本的。
以下是一个简单的比较:
模型多模态能力上下文理解数据隐私/合规定制化OCR准确性成本效率最佳用例
GPT-4o文本+图像, 从性能能力上来说比较强,但是隐私得不到保护,也不是很容易定制化。
Llama 3.2–11B-Vision-Instruct文本+图像, 性能效果还可以有绝对的隐私保护,因为我们可以进行私有化部署,也可以灵活的进行调整,效率也可以比较高。
每个模型适用于不同复杂性、从应用的角度也有不同性能隐私风险保护以及成本的要求。
对于处理敏感数据,例如公司那边职员的职级薪水等,这种就不太应该去让外部的大模型来处理。
像Llama 3.2–11B-Vision-Instruct或Pixtral-12B这样的模型提供了显著的优势,特别是因为它们可以托管在自己的基础设施上,确保您的数据保持安全和私密。
它们还允许高度定制,可以微调这些模型以更好地解释公司处理的特定类型的非结构化数据。
现在让我们来看看如何使用这些模型将非结构化数据解析为结构化格式的步骤。
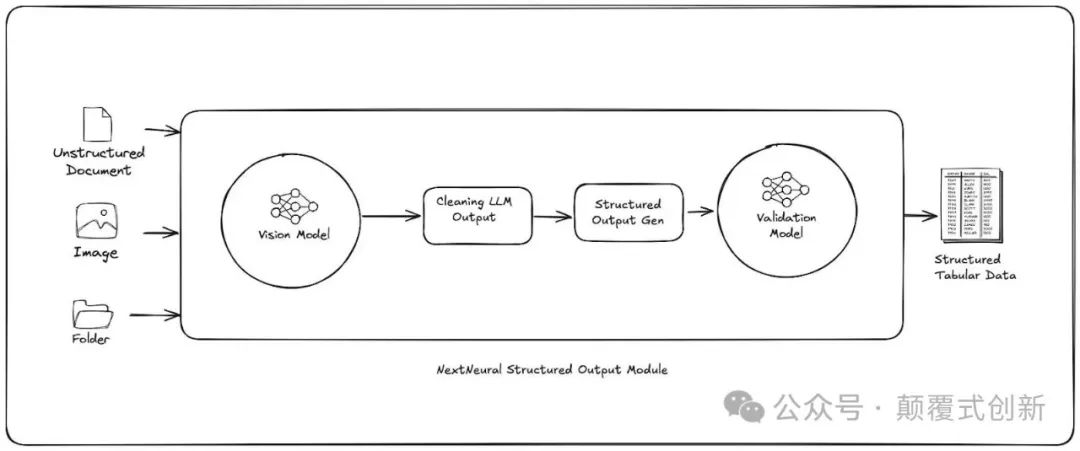
使用 Llama-3.2–11B-Vision-Instruct 步骤
首先,要先访问模型 - Llama-3.2–11B-Vision-Instruct。
登录Hugging Face,创建个帐户,Meta 的模型维护人员将开通访问权限。
还需要一台高端的云 GPU。我们在本教程中使用了 NVIDIA Tensor Core A100 GPU。一旦启动了 GPU 和相应的 Jupyter 笔记本,可以检查您的 GPU 配置:
!nvidia-smi
这个命令将显示您的 GPU 配置和内存使用情况。您还需要在 Hugging Face 上创建一个访问令牌,以便您可以下载模型。一旦您创建了访问令牌,请将其保存在环境变量中。
因此,在 .env 文件中,添加这一行:
HF_TOKEN='your_access_token_from_hugging_face'
现在我们将安装所需的库。
pip install torch requests Pillow accelerate python-dotenv
pip install git+https://github.com/huggingface/transformers
接下来,让我们导入所需的库:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from dotenv import load\_dotenv
load\_dotenv()
现在我们已经准备好了
步骤 1:下载模型
如果已经 .env 文件中保存了访问令牌,就不需要使用 huggingface_hub 登录。您现在可以下载模型。
model\_id \= "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from\_pretrained(
model\_id,
torch\_dtype=torch.bfloat16,
device\_map="auto",
)
processor = AutoProcessor.from\_pretrained(model\_id)
这将需要一些时间,因为模型相当大, 当然有时候服务器下载不了,因为被强了,这个时候你需要开启vpn下载之后上传到服务器。
步骤 2:测试模型
模型下载完成后,您可以通过使用图像来测试它。以下是如何操作:
image \= Image.open("emissions\_per\_person.png")
messages = \[
{"role": "user", "content": \[
{"type": "image"},
{"type": "text", "text": """
以表格形式捕捉每个国家的人均排放量。
提供近似的浮点数。
"""}
\]}
\]
input\_text = processor.apply\_chat\_template(messages, add\_generation\_prompt=True)
inputs = processor(
image,
input\_text,
add\_special\_tokens=False,
return\_tensors="pt"
).to(model.device)
output = model.generate(\*\*inputs, max\_new\_tokens=1000)
response = processor.decode(output\[0\])
print(response)
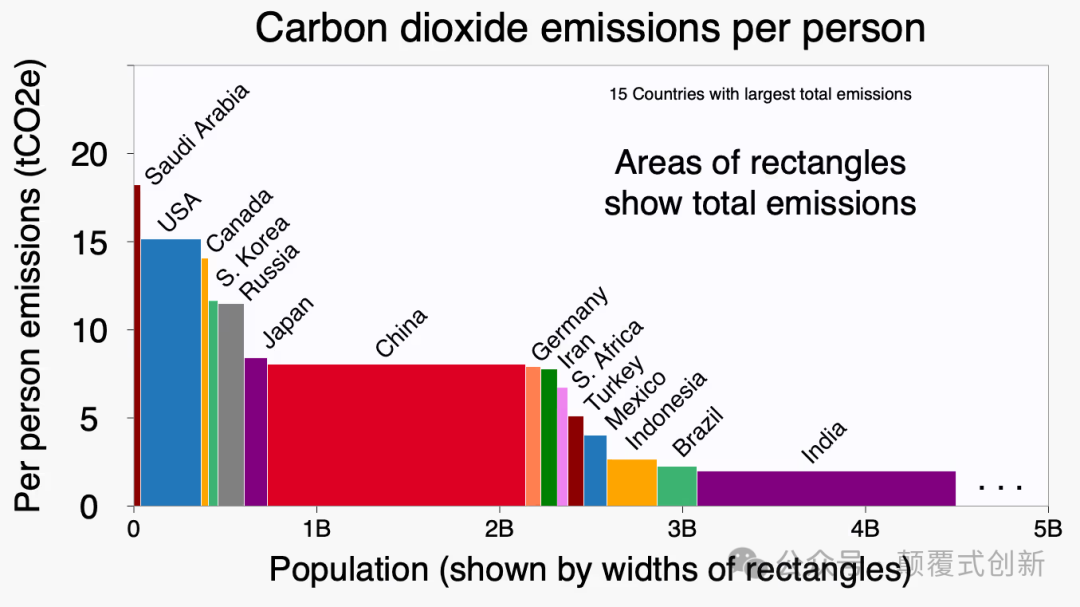
为了测试,我们使用了以下图像,显示了15个排放总量最大的国家的人均二氧化碳排放量。
这是我们得到的输出:
<|begin\_of\_text|><|start\_header\_id|>user<|end\_header\_id|>
<|image|>
以表格形式捕捉每个国家的人均排放量。
提供近似的浮点数。
<|eot\_id|><|start\_header\_id|>assistant<|end\_header\_id|>
以下表格显示了15个排放总量最大的国家的人均二氧化碳排放量,以二氧化碳当量吨为单位。数据以近似的浮点数的形式显示在表格中。
| 国家 | 人均排放量(tCO2e) |
| :--------------- | :-----------------: |
| 沙特阿拉伯 | 18.4 |
| 美国 | 16.5 |
| 加拿大 | 14.4 |
| 韩国 | 12.1 |
| 俄罗斯 | 10.4 |
| 日本 | 8.6 |
| 中国 | 7.2 |
| 德国 | 6.9 |
| 伊朗 | 5.4 |
| 南非 | 4.5 |
| 土耳其 | 4.2 |
| 墨西哥 | 3.8 |
| 印度尼西亚 | 3.4 |
| 巴西 | 3.3 |
| 印度 | 1.7 |
\*\*答案:\*\* 该表格提供了15个排放总量最大的国家的人均二氧化碳排放量的简明概述。<|eot\_id|>
这些数字大致在合理范围内。
步骤 3:使用模型进行结构化输出
我们注意到的一个因素是,该模型在生成输出时更擅长使用 markdown 格式,而不是 JSON 或 YAML。因此,我们的方法将是首先引导它生成 markdown,然后将 markdown 转换为 JSON。
看一下我们将要使用的图片文件:

这是一张相当复杂的账单,会计团队可能会收到成千上万张这样的账单。我们在这张账单上测试 AI 模型。这次我们的提示将引导 markdown:
image \= Image.open("water\_bill.png")
messages = \[
{"role": "user", "content": \[
{"type": "image"},
{"type": "text", "text": """
以 markdown 格式解析账单图像。捕获所有细节,并填写这些值:
账号:
账户名称:
地址:
账单起始日期:
账单结束日期:
账单到期日期:
账单总额:
到期日期:
到期后金额:
"""}
\]}
\]
input\_text = processor.apply\_chat\_template(messages, add\_generation\_prompt=True)
inputs = processor(
image,
input\_text,
add\_special\_tokens=False,
return\_tensors="pt"
).to(model.device)
output = model.generate(\*\*inputs, max\_new\_tokens=1000)
response = processor.decode(output\[0\])
print(response)
这将生成类似于以下的响应:
<|begin\_of\_text|><|start\_header\_id|>user<|end\_header\_id|>
<|image|>
以 markdown 格式解析账单图像。捕获所有细节,并填写这些值:
账号:
账户名称:
地址:
账单起始日期:
账单结束日期:
账单到期日期:
账单总额:
到期日期:
到期后金额:
<|eot\_id|><|start\_header\_id|>assistant<|end\_header\_id|>
\*\*水费账单详情\*\*
\* \*\*账户信息\*\*
\+ 账号:0441-12-022
\+ 账户名称:Balingit Joe
\+ 地址:Rizal
\* \*\*账单周期\*\*
\+ 账单起始日期:10/03/2022
\+ 账单结束日期:11/02/2022
\* \*\*账单到期日期\*\*:11/17/2022
\* \*\*账单总额\*\*:210.00
\* \*\*到期日期\*\*:11/17/2022
\* \*\*到期后金额\*\*:220.50<|eot\_id|>
如你所见,捕获的数据基本上是准确的。然而,模型有时会产生“幻觉”,因此需要进行手动监督。
步骤 4:生成结构化输出
使用 GPT 4o 模型,您可以轻松地生成 JSON、Zod 或 Pydantic 结构的输出。然而,目前的开源视觉模型并非如此。
为了生成结构化输出的 markdown,您需要将 markdown 转换为 JSON 格式。首先,我们将剥离 Llama-3.2 特定的标记和多余的数据:
def parse\_eot\_content(input\_string):
\# 步骤 1:找到 <|eot\_id|> 标记之间的内容
eot\_pattern \= r"<\\|eot\_id\\|>(.\*?)<\\|eot\_id\\|>"
eot\_match \= re.search(eot\_pattern, input\_string, re.DOTALL)
if eot\_match:
eot\_content \= eot\_match.group(1)
else:
return None \# 如果 <|eot\_id|> 标记之间没有内容
\# 步骤 2:移除 <|start\_header\_id|> 和 <|end\_header\_id|> 之间的部分
header\_pattern \= r"<\\|start\_header\_id\\|>.\*?<\\|end\_header\_id\\|>"
cleaned\_content \= re.sub(header\_pattern, '', eot\_content, flags\=re.DOTALL)
\# 步骤 3:返回清理后的内容
return cleaned\_content.strip()
我们还将编写一个简单的函数,将 markdown 数据解析为 JSON 格式,如下所示:
def markdown\_to\_json(markdown):
data \= {}
current\_section \= None
# 按行分割
lines = markdown.splitlines()
for line in lines:
line = line.strip()
# 如果行为空,则跳过
if not line:
continue
# 如果行是新的部分标题(加粗的文本)
section\_match = re.match(r'\\\*\\\*(.+?)\\\*\\\*', line)
if section\_match:
current\_section = section\_match.group(1).strip()
data\[current\_section\] = {}
continue
# 如果行以“\*”开头,将其处理为列表项或键值对
if line.startswith("\*"):
# 移除星号和周围的空格
line = line.lstrip("\*").strip()
key\_value\_match = re.split(r':\\s+', line, maxsplit=1)
# 处理根级别的键值对
if len(key\_value\_match) == 2:
key, value = key\_value\_match
data\[current\_section\]\[key\] = value
continue
# 如果行以“+”开头,它是部分内的键值对
if line.startswith("+"):
line = line.lstrip("+").strip()
key\_value\_match = re.split(r':\\s+', line, maxsplit=1)
# 将键值对添加到当前部分
if len(key\_value\_match) == 2:
key, value = key\_value\_match
if current\_section:
data\[current\_section\]\[key\] = value
else:
data\[key\] = value
return json.dumps(data, indent=4)
现在,我们可以使用这些函数转换 Llama-3.2 的输出。
parsed\_output = parse\_eot\_content(response)
output = markdown\_to\_json.jsonify(parsed\_output)
print(output)
这将生成以下结果:
{
"水费明细": {
"账号": "0441-12-022",
"账户名称": "Balingit Joe",
"地址": "Rizal",
"从": "2022年10月3日",
"至": "2022年11月2日",
"账单到期日": "2022年11月17日",
"当前账单金额": "210.00",
"总金额到期": "210.00",
"到期日": "2022年11月22日"
}
}
现在,可以将其插入到数据库中,并进行查询。
结尾
因为大模型是有幻觉的,所以最终使用之前最好有一个人工review,或者有对应的机制逻辑代码去对数据的正确性进行check,否则可能还是会出错这个不同的业务,最终的post check的逻辑会有比较大的差异。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











