







大家好!今天来给大家唠唠谷歌搞了个啥新玩意儿!这事儿挺有意思,跟咱们现在天天打交道的人工智能小助手有关。
要是你用过智能语音助手,或者见过那些自动帮你干活的机器人程序,那你肯定得好好看看这篇文章。
谷歌这次的新动作,说不定以后能让咱们的生活和工作变得更轻松呢!
一、为啥谷歌要搞这个新协议
先说说为啥谷歌要搞这个Agent2Agent(A2A)协议。
现在,各种各样的AI小助手(咱们就叫它们“小帮手”吧)越来越多了。有的能帮你订外卖,有的能帮你查资料,还有的能帮企业做复杂的任务,比如管理供应链、处理客户咨询啥的。这些小帮手确实挺厉害,但它们有个问题——大多数时候,它们都是“单兵作战”。
为啥说这是个问题呢?想象一下,要是你手头有个特别复杂的任务,比如要组织一场大型活动。你得分别找不同的小帮手,一个帮你订场地,一个帮你安排交通,一个帮你管理嘉宾名单……要是这些小帮手之间能互相“聊天”、互相配合,那得多省事儿啊!企业也一样,他们有很多不同的系统和应用程序,每个系统里都有自己的小帮手。要是这些小帮手能跨系统协作,那工作效率肯定能大大提升。

谷歌看到了这个问题,就联合了一大帮技术伙伴,一起搞了个A2A协议。这个协议的目的,就是让不同公司、不同框架开发出来的小帮手们能够“组团打怪”,也就是协同工作。
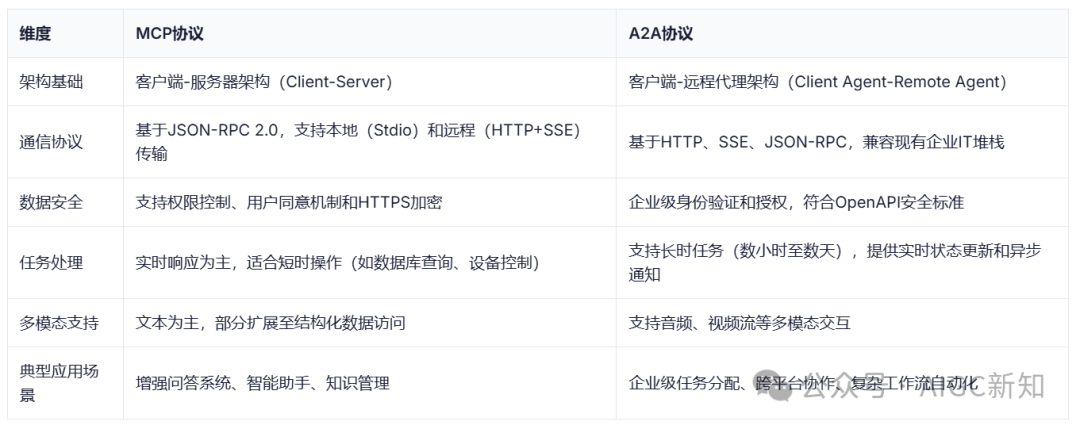
与目前非常火的MCP协议进行对比:
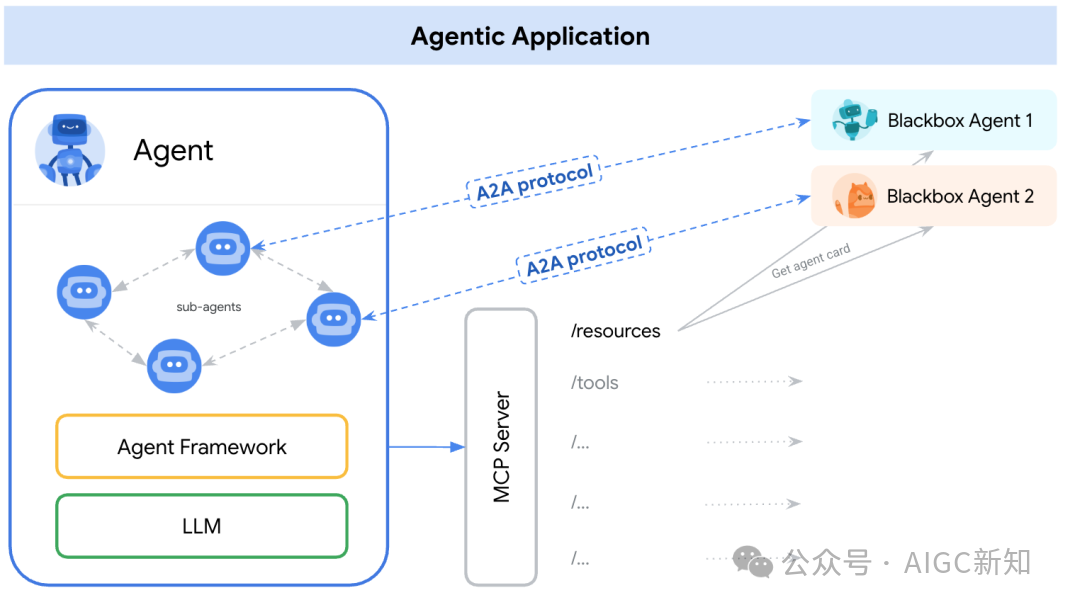
二、A2A协议是咋回事儿
(一)简单来说,A2A协议就是一套“通用语言”和“交通规则”
就好比咱们人类,不同国家的人说不同的语言,如果没有通用的交流方式,那肯定没法合作。A2A协议就是给小帮手们提供了一套大家都懂的语言,让它们能互相“说话”。
而且,它还规定了小帮手们在协作时要遵守的规则,比如谁先执行任务、谁负责反馈结果等等,就跟交通规则一样,让协作变得有条不紊。
(二)它有几个关键点
让小帮手们发挥自己的本事:
A2A协议不会限制小帮手们的能力,它们可以像在自己熟悉的环境里一样,用自己的方式去完成任务。这就像是让每个小帮手都能发挥自己的特长,而不是把它们硬塞进一个固定的框架里。
基于现有的技术标准:
谷歌没有去发明一套全新的技术,而是利用了现在大家已经广泛使用的标准,比如HTTP(就是咱们上网用的协议)、SSE(服务器发送事件)、JSON-RPC(一种数据交互格式)等等。这就像是在现有的道路上修路,而不是重新开辟一条新路,这样能大大减少成本和难度。

安全第一:
在企业里,数据安全是头等大事。A2A协议在设计的时候就特别注重安全,它采用了和OpenAPI(一个很知名的安全标准)相当的认证和授权机制。
这就像是给小帮手们的交流加了一把锁,确保只有经过授权的小帮手才能互相协作,防止数据泄露。
能处理长期任务:
有些任务可能很快就能完成,比如查个天气;但有些任务可能需要很长时间,比如做一个市场调研报告。A2A协议能够应对各种任务,不管是短平快的,还是需要好几天甚至好几周的长期任务。
而且,在任务进行过程中,它还能实时给用户反馈,让用户知道任务进行到哪一步了。
支持多种交互方式:
小帮手们和人类交流的方式可不止文字一种,还有语音、视频等等。A2A协议考虑到了这一点,它支持多种交互方式,这样就能满足不同场景下的需求。
比如,在远程会议中,小帮手可以通过视频来协助用户;在语音助手场景中,它又能通过语音和用户交流。
三、A2A协议是怎么工作的
(一)能力发现
每个小帮手都有自己的特长,比如有的擅长处理文字,有的擅长分析数据。A2A协议允许小帮手们通过一种叫做“代理卡片”的东西来展示自己的能力。
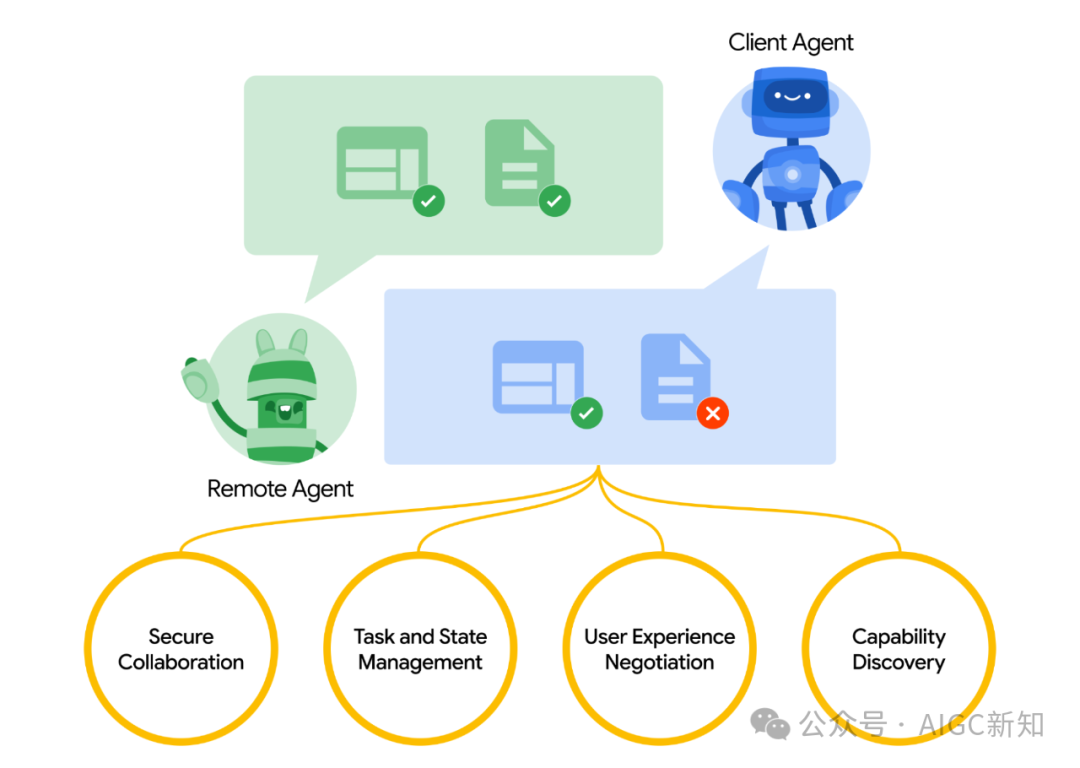
这就像是每个小帮手都有一张自己的“简历”,其他小帮手可以通过这张“简历”来了解它的特长,然后根据任务需求选择最合适的小帮手来合作。
(二)任务管理
当一个任务被分配给小帮手们的时候,它们会根据协议的规定来管理这个任务。任务有它的生命周期,从开始到结束,小帮手们会一步步推进。如果任务比较复杂,需要多个小帮手协作,它们就会互相沟通,实时同步任务的进度。最后,任务完成的结果会以“工件”的形式呈现出来,这个“工件”可以是文字报告、数据图表,甚至是一个视频,具体取决于任务的内容。
(三)协作
小帮手们之间可以通过发送消息来协作。这些消息可以包含各种信息,比如任务的上下文、执行结果、用户的要求等等。这就像是小帮手们在开一个“工作群”,大家一起讨论任务,互相协助,共同完成目标。
(四)用户体验协商
这个功能特别有意思。因为不同的用户可能使用不同的设备,或者有不同的使用习惯,所以小帮手们在和用户交流的时候,需要根据用户的情况来调整交流的方式。比如,有的用户可能更喜欢看图表,有的用户可能更喜欢听语音。A2A协议允许小帮手们和用户协商,选择最适合用户的交流方式,这样就能让用户有更好的体验。
四、A2A协议能干啥
举个例子,假设你是一家公司的招聘经理,你想招聘一名软件工程师。以前,你可能得自己去各个招聘网站找简历,然后一个个筛选,再安排面试。
现在,有了A2A协议,你可以让你的AI小帮手去完成这个任务。它会和其他专门的小帮手协作,比如有的小帮手负责在招聘网站上搜索简历,有的小帮手负责筛选符合条件的候选人,还有的小帮手负责安排面试。
最后,这些小帮手们会把筛选好的候选人名单和面试安排反馈给你,大大节省了你的时间和精力。
在应用场景方面,MCP协议和A2A协议各自有使用场景。

五、未来展望
谷歌对A2A协议的未来充满了信心。他们认为,这个协议能够开启一个全新的时代,让AI小帮手们能够无缝协作,解决更复杂的问题。而且,谷歌还打算把这个协议开源,让更多的开发者和企业能够参与进来,共同推动这个协议的发展。
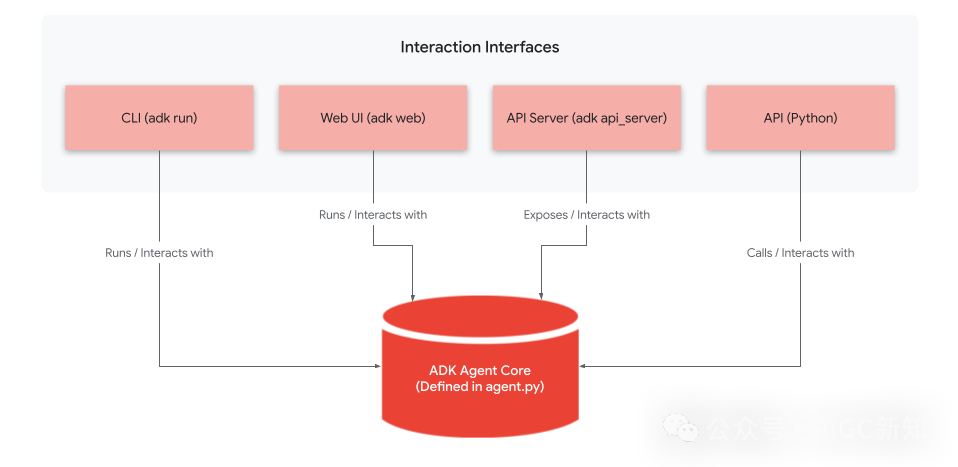
同一时间,谷歌也发布了Agent开发套件 (ADK),简化了简化Agent和Multi-agent系统的全栈端到端开发。
如果未来所有的AI小帮手都能像一个团队一样协作,那会带来多大的变化啊!比如,在医疗领域,不同的AI系统可以协作,快速诊断疾病;在教育领域,AI小帮手可以根据学生的需求,提供个性化的学习方案……总之,未来充满了无限可能!
好了,今天就聊到这里。谷歌的Agent2Agent协议听起来是不是挺有意思的?虽然现在这个协议还处于发展阶段,但它已经展现出了巨大的潜力。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











