






 我们知道数组用来存现对象的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用,而且只能存储相同数据类型的数据。现在,我们学习一个更灵活的容器---------集合。
我们知道数组用来存现对象的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用,而且只能存储相同数据类型的数据。现在,我们学习一个更灵活的容器---------集合。
前言
我们知道数组用来存现对象的一种容器,但是数组的长度固定,不适合在对象数量未知的情况下使用,而且只能存储相同数据类型的数据。现在,我们学习一个更灵活的容器---------集合。
细节参考:集合区别
提示:以下是本篇文章正文内容,下面案例可供参考
一、集合的图解?
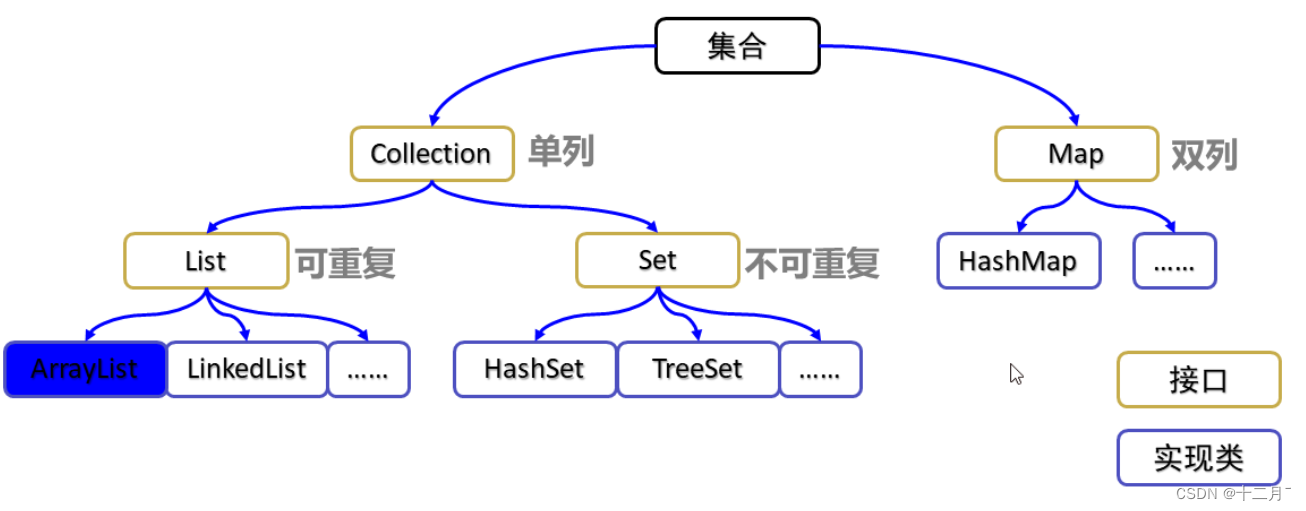
注:Collection接口,单列存储解释

Map接口,双列存储解释
二、Collection接口
Collection接口是集合类的根接口,Java中没有提供这个接口的直接的实现类。.
但是却让其被继承产生了两个接口,就是Set和List。. Set中不能包含重复的元素。.List中能包含重复元素
list具体实现类:ArrayList、LinkedList
Set具体实现类:HashSet、TreeSet
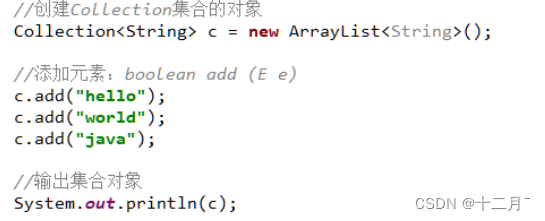
1.Collection集合
1.Collection集合使用
创建集合对象,使用对应方法
2.Collection集合遍历
使用Iterator迭代器
Iterator iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
使用下面两种方法判断及集合和获取元素:
it.next(); //获取元素
it.hasNext;//判断集合是否还存在元素

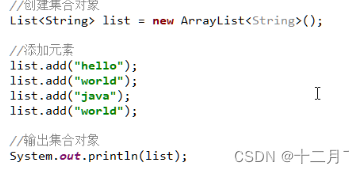
2.list集合
1.概述
(存储和取出的元素顺序一致)( 存储的元素可以重复 )
有序集合(也称为序列),用户可以精确控制列表中每个元素的插入位置。用户可以通过整数索引|访问元素,并搜索列表中的元素
2.list集合使用
3.List集合遍历
注意:并发修改异常,在list遍历时,使用迭代器Iterator进行遍历,在集合中进行了元素修改,造成迭代器获取元素中判断预期修改值和实际修改值不一致,而抛出异常。就是说在使用Iterator迭代器遍历时,不能进行修改操作,使用for循环遍历可以解决这个问题。

4.Listterator:列表迭代器
通过List集合的listlterator(方法得到,所以说它是List集合特有的迭代器
可以从任意方向遍历列表,在迭代期间修改列表,并获取列表中迭代的当前位置。

5.增强for循环
改进的for 循环,简化数组和集合的遍历(底层内部原理是Iterator迭代器)

6.数据结构(合理的数据结构能带来更高的运行或存储效率)
数据结构是计算机存储、组织数据的方式。是指相互之间存在一种或多种特定关系的数据元素的集合
1、栈(数据先进后出)
2、队列(数据先进先出)
3、数组(查询快,增删慢)
查询数据通过索引定位,查询任意数据耗时相同,查询效率高
删除数据时,要将原始数据删除,同时后面每个数据前移,删除效率低
添加数据时,添加位置后的每个数据后移,再添加元素,添加效率极低
4、链表(查询慢,增删快)
增删
直接改变地址指向
查询
查询一个数据从头开始
7.List集合子类特点
1、ArrayList:底层数据结构是数组,查询快,增删慢
2、LinkedList:底层数据结构是链表,查询慢,增删快
3.Set集合
1.Set集合概述
Set集合特点(不重复元素,没有带索引方法)
--------不包含重复元素的集合
--------没有带索引的方法,所以不能使用普通for循环遍历
2.HashSet(对集合迭代顺序不作保证)
获取对象哈希值:
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的
- 默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
HashSet集合特点 -
- 底层数据结构是哈希表
- 对集合的迭代顺序不作任何保证,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以是不包含重复元素的集合
HashSet集合实现变量相同,就是同一个对象不存储,就需要重写equals()方法和hashCold方法。(可以自动生成)
3.LinkedHashSet集合使用
-
- 哈希表和链表实现的Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素唯一,也就是说没有重复的元素
public class LinkedHashSetDemo {
public static void main(String[] args) {
//创建集合对象
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<String>();
//添加元素
linkedHashSet.add("hello");
linkedHashSet.add("world");
linkedHashSet.add("java");
linkedHashSet.add("world");
//遍历集合
for(String s : linkedHashSet) {
System.out.println(s);
}
}
}
4.TreeSet集合使用
- 元素有序,可以按照一定的规则进行排序,具体排序方式取决于构造方法
- TreeSet():根据其元素的自然排序进行排序
- TreeSet(Comparator comparator) :根据指定的比较器进行排序
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以不包含重复元素的集合
public class TreeSetDemo01 {
public static void main(String[] args) {
//创建集合对象
TreeSet<Integer> ts = new TreeSet<Integer>();
//添加元素
ts.add(10);
ts.add(40);
ts.add(30);
ts.add(50);
ts.add(20);
ts.add(30);
//遍历集合
for(Integer i : ts) {
System.out.println(i);
}
}
}
5.Set集合排序
需求:
- 存储学生对象并遍历,创建TreeSet集合使用无参构造方法
- 要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
1.自然排序Comparable
- 用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
//学生类
//public class Student implements Comparable<Student>
@Override
public int compareTo(Student s) {
// return 0;
// return 1;
// return -1;
//按照年龄从小到大排序
int num = this.age - s.age;
// int num = s.age - this.age;
//年龄相同时,按照姓名的字母顺序排序
int num2 = num==0?this.name.compareTo(s.name):num;
return num2;
}
2.比较器排序Comparator
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
//测试类
//创建集合对象
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
//this.age - s.age
//s1,s2
int num = s1.getAge() - s2.getAge();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
return num2;
}
});
6.泛型(参数化类型)
将类型由原来的具体的类型参数化,然后在使用/调用时传入具体的类型。
- <类型>:指定一种类型的格式。这里的类型可以看成是形参
- <类型1,类型2…>:指定多种类型的格式,多种类型之间用逗号隔开。这里的类型可以看成是形参
- 将来具体调用时候给定的类型可以看成是实参,并且实参的类型只能是引用数据类型
概念: -
- 把运行时期的问题提前到了编译期间
- -避免了强制类型转换
1.泛型类
修饰符 class 类名<类型> { }
//泛型类
public class Generic<T> {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
//测试类
public class GenericDemo {
public static void main(String[] args) {
Generic<String> g1 = new Generic<String>();
g1.setT("林青霞");
System.out.println(g1.getT());
Generic<Integer> g2 = new Generic<Integer>();
g2.setT(30);
System.out.println(g2.getT());
Generic<Boolean> g3 = new Generic<Boolean>();
g3.setT(true);
System.out.println(g3.getT());
}
}
2.泛型方法
修饰符 <类型> 返回值类型 方法名(类型 变量名) { }
//泛型接口
public interface Generic<T> {
void show(T t);
}
//泛型接口实现类
public class GenericImpl<T> implements Generic<T> {
@Override
public void show(T t) {
System.out.println(t);
}
}
//测试类
public class GenericDemo {
public static void main(String[] args) {
Generic<String> g1 = new GenericImpl<String>();
g1.show("林青霞");
Generic<Integer> g2 = new GenericImpl<Integer>();
g2.show(30);
}
}
3.泛型接口
修饰符 interface 接口名<类型> { }
//带有泛型方法的类
public class Generic {
public <T> void show(T t) {
System.out.println(t);
}
}
//测试类
public class GenericDemo {
public static void main(String[] args) {
Generic g = new Generic();
g.show("林青霞");
g.show(30);
g.show(true);
g.show(12.34);
}
}
7.类型通配符
为了表示各种泛型List的父类,可以使用类型通配符

//类型通配符:<?>
List<?> list1 = new ArrayList<Object>();
List<?> list2 = new ArrayList<Number>();
List<?> list3 = new ArrayList<Integer>();
System.out.println("--------");
//类型通配符上限:<? extends 类型>
// List<? extends Number> list4 = new ArrayList<Object>();
List<? extends Number> list5 = new ArrayList<Number>();
List<? extends Number> list6 = new ArrayList<Integer>();
System.out.println("--------");
//类型通配符下限:<? super 类型>
List<? super Number> list7 = new ArrayList<Object>();
List<? super Number> list8 = new ArrayList<Number>();
// List<? super Number> list9 = new ArrayList<Integer>();
8.可变参数
可变参数又称参数个数可变,用作方法的形参出现,那么方法参数个数就是可变的了
修饰符 返回值类型 方法名(数据类型… 变量名) { }
public static int sum(int...a){ }
- 这里的变量其实是一个数组
- 如果一个方法有多个参数,包含可变参数,可变参数要放在最后
public class ArgsDemo01 {
public static void main(String[] args) {
System.out.println(sum(10, 20));
System.out.println(sum(10, 20, 30));
System.out.println(sum(10, 20, 30, 40));
System.out.println(sum(10,20,30,40,50));
System.out.println(sum(10,20,30,40,50,60));
System.out.println(sum(10,20,30,40,50,60,70));
System.out.println(sum(10,20,30,40,50,60,70,80,90,100));
}
// public static int sum(int b,int... a) {
// return 0;
// }
public static int sum(int... a) {
int sum = 0;
for(int i : a) {
sum += i;
}
return sum;
}
}
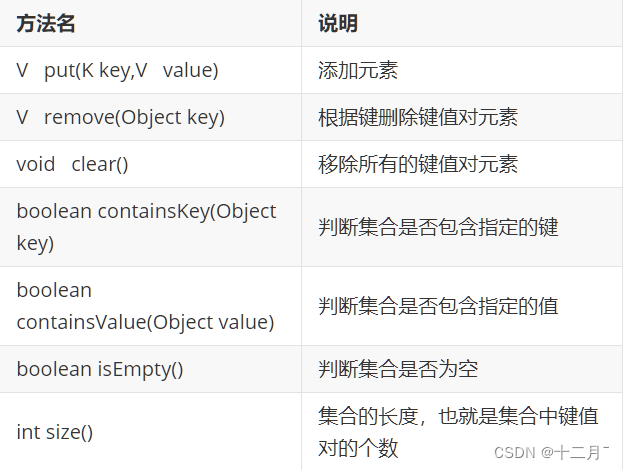
4.Map集合
interface Map<K,V> K:键的类型;V:值的类型
将键映射到值的对象;不能包含重复的键;每个键可以映射到最多一个值
特点
- 键值对映射关系
- 一个键对应一个值
- 键不能重复,值可以重复
- 元素存取无序

1.Map集合使用
2.Map集合的遍历
1.方式一
- 获取所有键的集合。用keySet()方法实现
- 遍历键的集合,获取到每一个键。用增强for实现
- 根据键去找值。用get(Object key)方法实现
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (String key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = map.get(key);
System.out.println(key + "," + value);
}
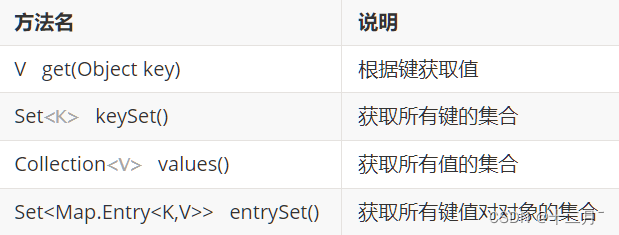
2.方式二
- 获取所有键值对对象的集合
- Set<Map.Entry<K,V>> entrySet():获取所有键值对对象的集合
- 遍历键值对对象的集合,得到每一个键值对对象
- 用增强for实现,得到每一个Map.Entry
- 根据键值对对象获取键和值
- 用getKey()得到键
- 用getValue()得到值
//获取所有键值对对象的集合
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : entrySet) {
//根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "," + value);
}
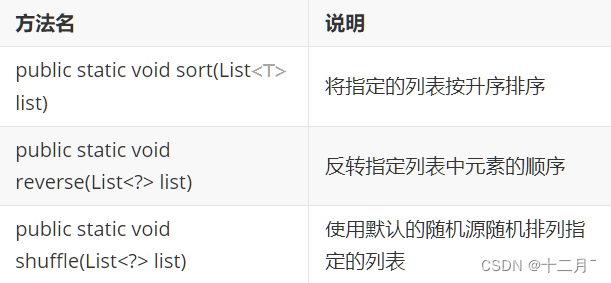
5.Collections集合工具类
是针对集合操作的工具类
6.集合总结
1、Collection集合:具体实现类ArrayList,创建集合对象后可使用。使用的Iterator迭代器遍历,条件由方法hasNext()判断集合是否存在元素,存在用next()方法获取元素。
2、list集合(有序,可以有重复元素的集合)
包含两个子类
ArrayList(底层数据结构是数组,查询快,增删慢)
LinkedList(底层数据结构是链表,查询慢,增删快)
遍历使用for循环、增强for循环、Iterator迭代器以及ListIterator列表迭代器
其中,Iterator迭代器在遍历时,不能进行对列表的改变,否则会抛出并发修改异常
ListIterator列表迭代器,可以允许沿任意方向遍历,遍历期间修改列表,获得列表中迭代器的当前位置。
3、set集合(不能有重复元素的集合,没有带索引的方法)
HashSet(对集合迭代顺序不作保证)
排序
----自然排序Comparable:自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
----比较器排序Comparator:比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
遍历对,对象的成员变量值相同,我们就认为是同一个对象(注意对equals()方法和hashCode()方法的重写)
可以使用迭代器和增强for循环遍历
LinkedHashSet集合(有序,存储顺序和输出顺序一致)
-
- 哈希表和链表实现的Set接口,具有可预测的迭代次序
- 由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
- 由哈希表保证元素唯一,也就是说没有重复的元素
TreeSet集合(有序,规定的顺序)
- 元素有序,可以按照一定的规则进行排序,具体排序方式取决于构造方法
- TreeSet():根据其元素的自然排序进行排序
- TreeSet(Comparator comparator) :根据指定的比较器进行排序
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以不包含重复元素的集合
4、map集合(无序,键值对应,一键值可以对应一个或多个值,但是键值只能一个不能重复)
遍历有两种方式:
方式一:
找到键值,再用键值找到对应的值
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (String key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = map.get(key);
System.out.println(key + "," + value);
}
方式二:
找到键值对象,再得到键值对对象,根据键值对对象获取键和值
//获取所有键值对对象的集合
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : entrySet) {
//根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "," + value);
}















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









