







引入group by 可以针对不同的组来分别进行聚合
//数据
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66),
('小马','服务员', 1200.20),
('kiki','游戏陪玩', 2000.20),
('马斯克','董事长', 12000000.20);不用group by 分组的时候,相当于就只有一组,把所有的行进行聚合。
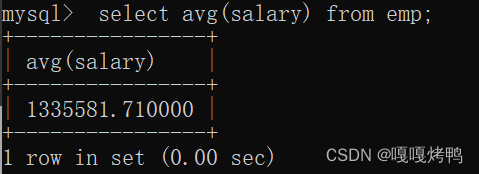
根据角色role这个类来进行分组,统计平均工资salary
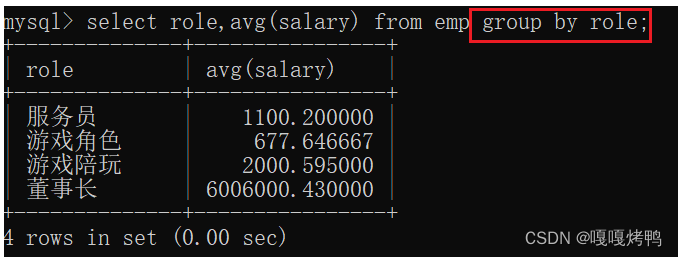
把role这一列值相同的行分成了一组,然后计算平均值也是针对单个分组而言的。
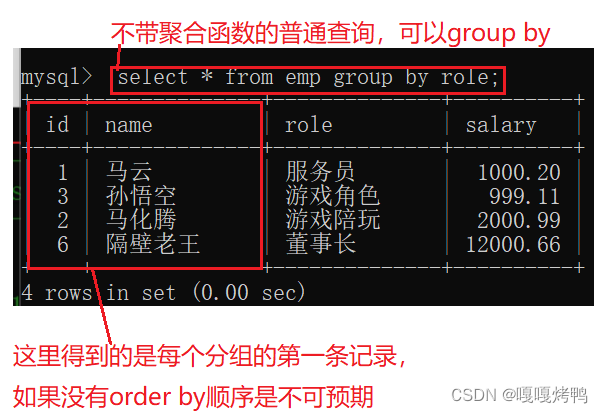
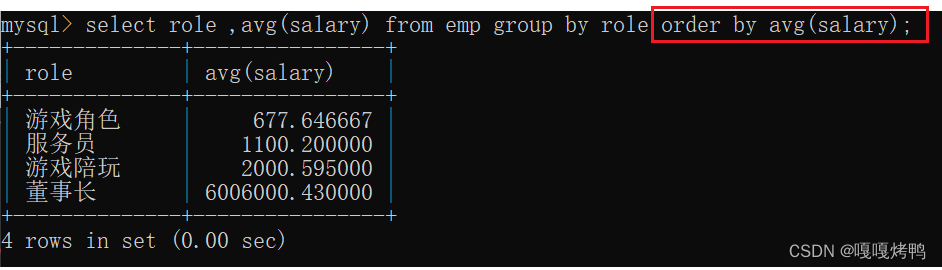
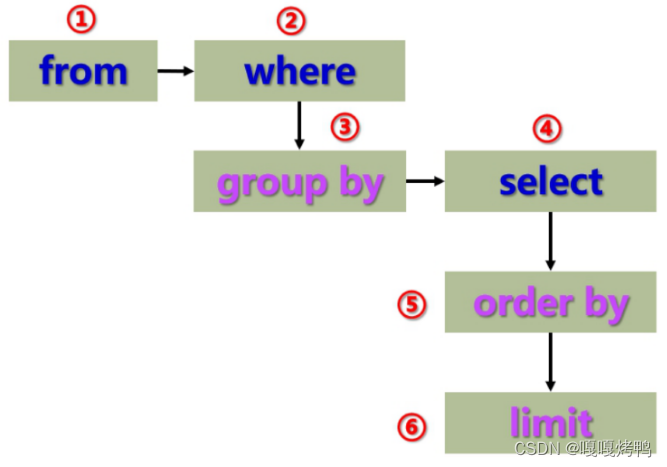
分组查询指定条件,分为
- 分组前指定条件(先筛选,再分组)where
- 分组后指定条件(先分组,再筛选)having
- 分组前后都指定条件where having
1、分组前指定条件
统计每个岗位的平均薪资,但是刨除某个人的数据
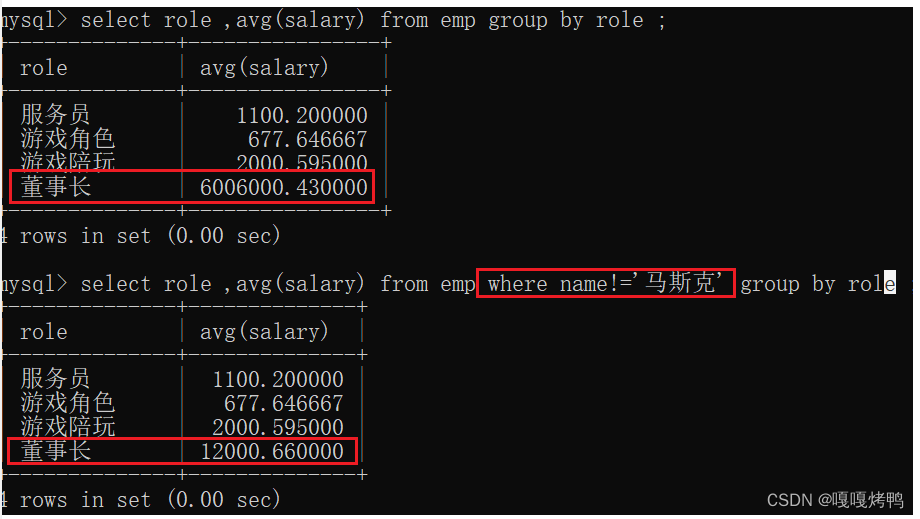
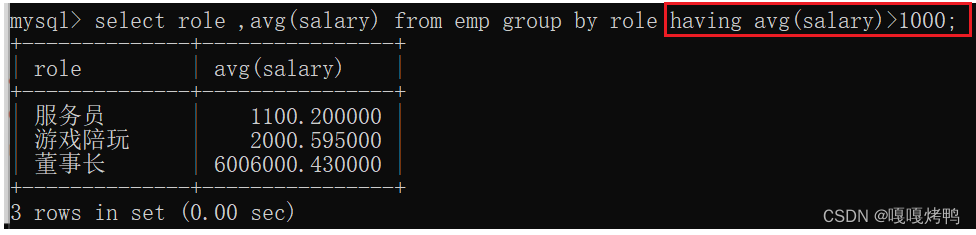
2、分组后指定条件
查询每个岗位的平均工资,但是刨除平均薪资在1000一下的

3、分组前后都指定条件
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









