







目录
一、对于表的介绍、基本概念与操作
MySQL对于表的介绍、基本概念与操作_嘎嘎烤鸭的博客-CSDN博客
数据库里的表,每一个列都是带有类型的。所有行的对应列存的数据必须是同一类。
1.1MySQL的数据类型
数值类型:分为整型和浮点型:
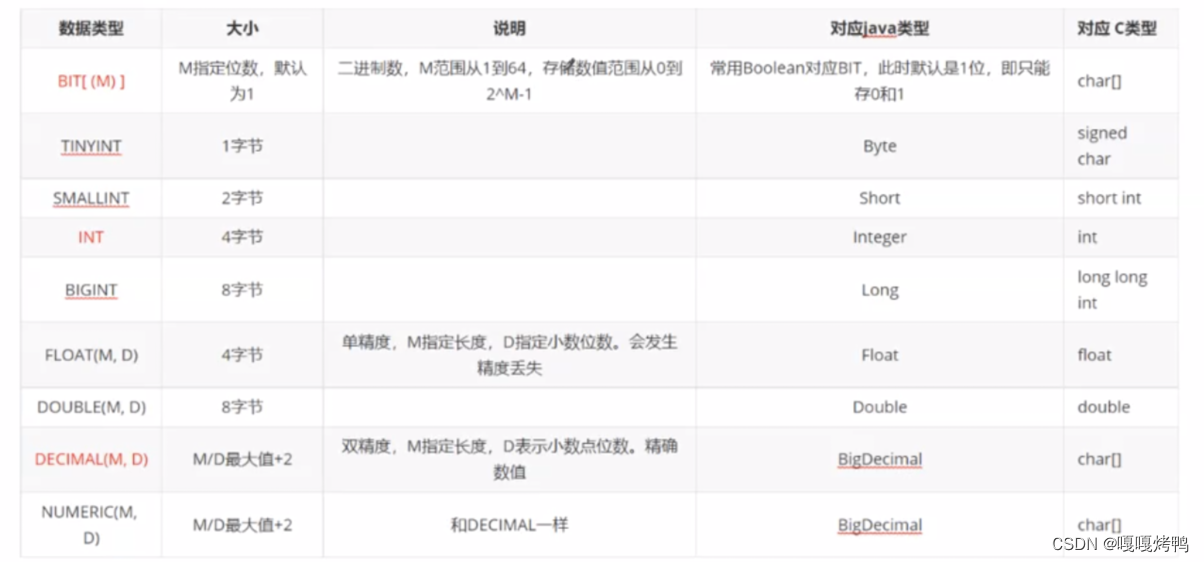
字符串类型

日期类型

1.2表操作
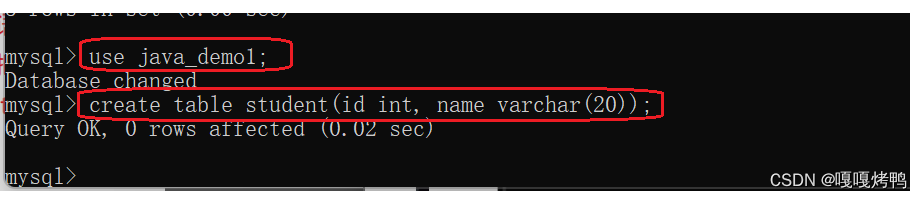
1.2.1创建表
要想操作表,必须先选中数据库( use 数据库 )
create table 表名(列名 类型,列名 类型.....)
注意: varchar(20)后面括号中的20是20个字符不是字节
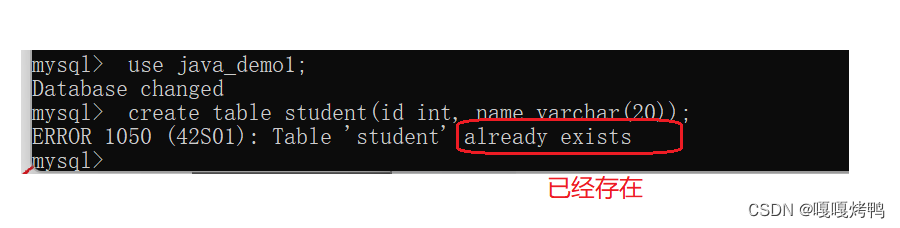
注意:
a、同一个数据库中不能有名字相同的两个表
b、列名和表名不能和SQL关键字重复
如果非要这么搞,可以给类名/表名加上反引号引起来

1.2.2 查看表
show tables;

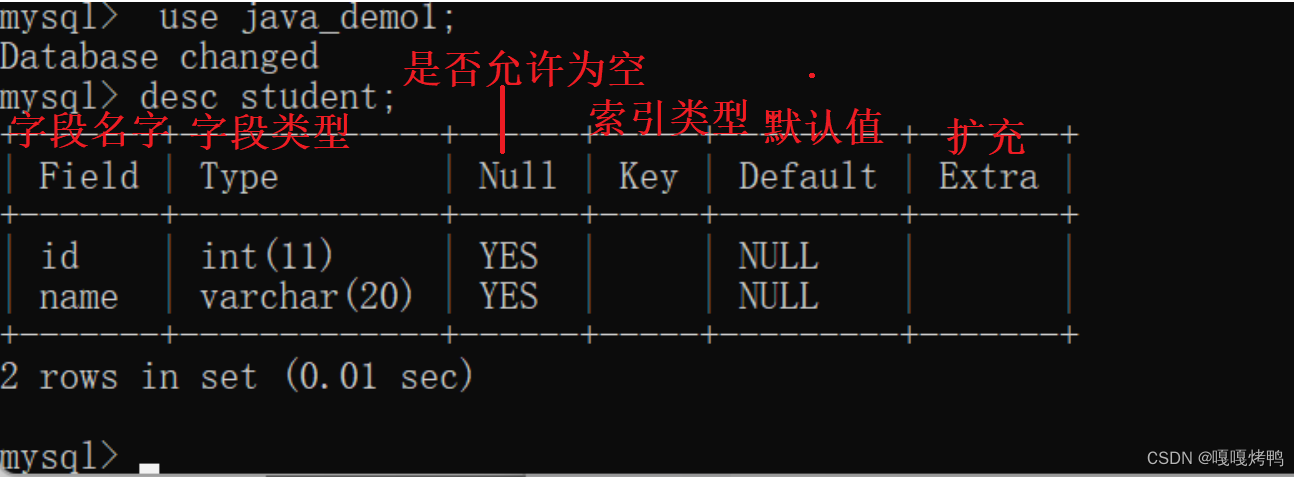
1.2.3 查看表结构
desc 表名;
1.2.4 删除表
drop table 表名;
注释:可以使用"comment"或"--"增加字段说明。
实操题:
有一个商店的数据,记录客户及购物情况,有以下三个表组成:
商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供应商provider)
客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证 card_id)
购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
SQL建库

二、 insert插入
mysql数据库中的插入数据insert,中文字符集配置_嘎嘎烤鸭的博客-CSDN博客
- C:create 新增
- D:update 修改
- R:retrieve 查询
- D:delete 删除
进行增删查改,必须先选中数据库
2.1 新增关键字 insert
SQL 使用 insert 关键字来表示新增数据
每次新增都是直接新增一行(一条记录)
insert into 表名 value(列,列.....);
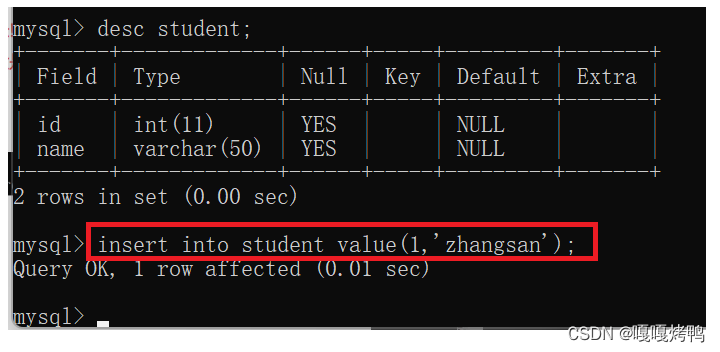
注意:
- value后面的()中的内容个数、类型必须和表的结构匹配
- 在SQL中,‘’(单引号)和“”(双引号)都可以表示字符串,因为SQL没有字符类型,只有字符串类型,这种编程语言对单双引号要求不高
2.1.1 常见错误类型
1、列数不匹配
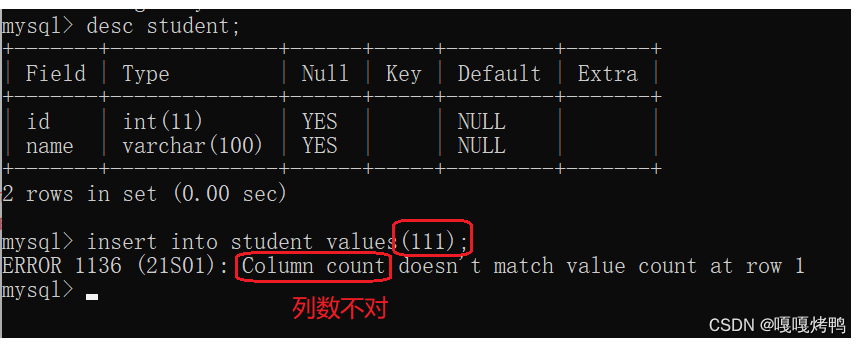
2、列的类型不匹配

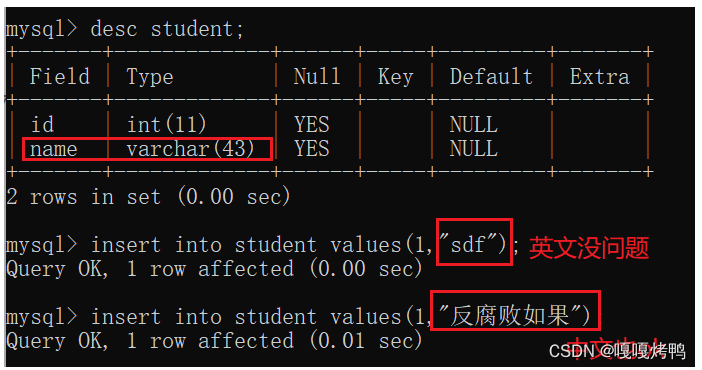
可以存中文字符的数据吗?

insert除了可以插入完整的一行数据之外。还可以指定哪列插入
此时,未被指定的列,则是默认值来进行填充
2.2 指定列插入数据
insert除了可以插入完整的一行数据之外。还可以指定哪列插入
此时,未被指定的列,则是默认值来进行填充

2.2.1 指定一个列:(列名)

2.2.2指定多个列(用逗号,分隔)

2.2.3多列同时插入
一次性插入多个行——一个sql插入多条数据
实现方法:insert 语句values后面跟多个()
每一组括号对应一行(一条记录)

insert插入效率问题:
在mysql中,一次插入1条数据,插10次比一次性插入10条效率低,因为insert是通过网络访问的,发送请求返回网络响应都是要时间的,数据库服务器是把数据保存在硬盘上的(硬盘读取要时间)
mysql关系型数据库每次进行sql操作,内部都会开启一个事务(开启事务也是要时间开销的)
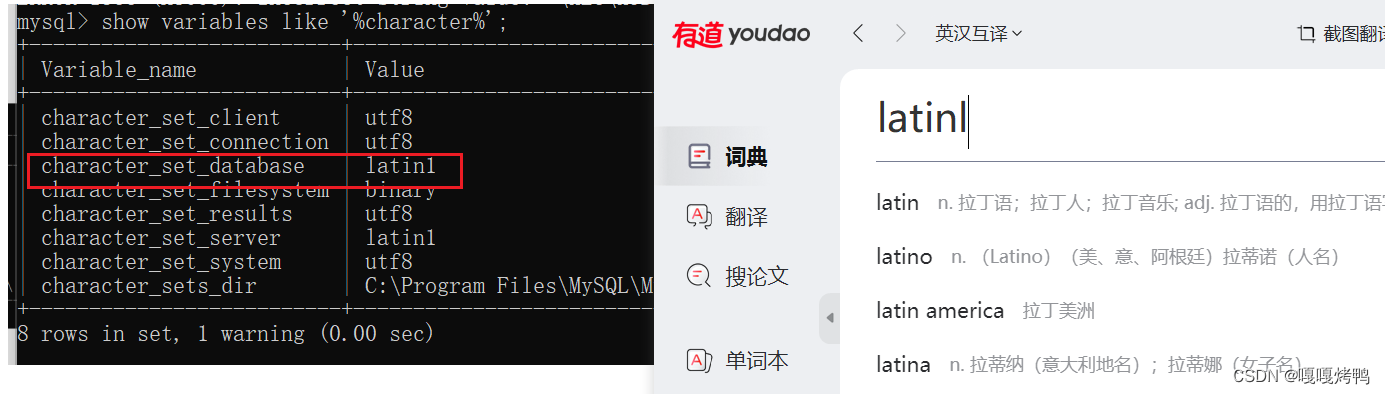
一、查看数据库字符集类型
show variables like '%character%';
创建数据库时,如果手动指定过字符集,就以手动的为准,没有手动指定,就会读取mysql的配置文件my.ini里的默认字符集。默认字符集是拉丁文,不支持中文。
二、更改数据库字符集
1、删除之前的库,重新建一个指定utf-8字符集的数据库。(一定要删除数据库,妄想中途改变字符集,继续使用)
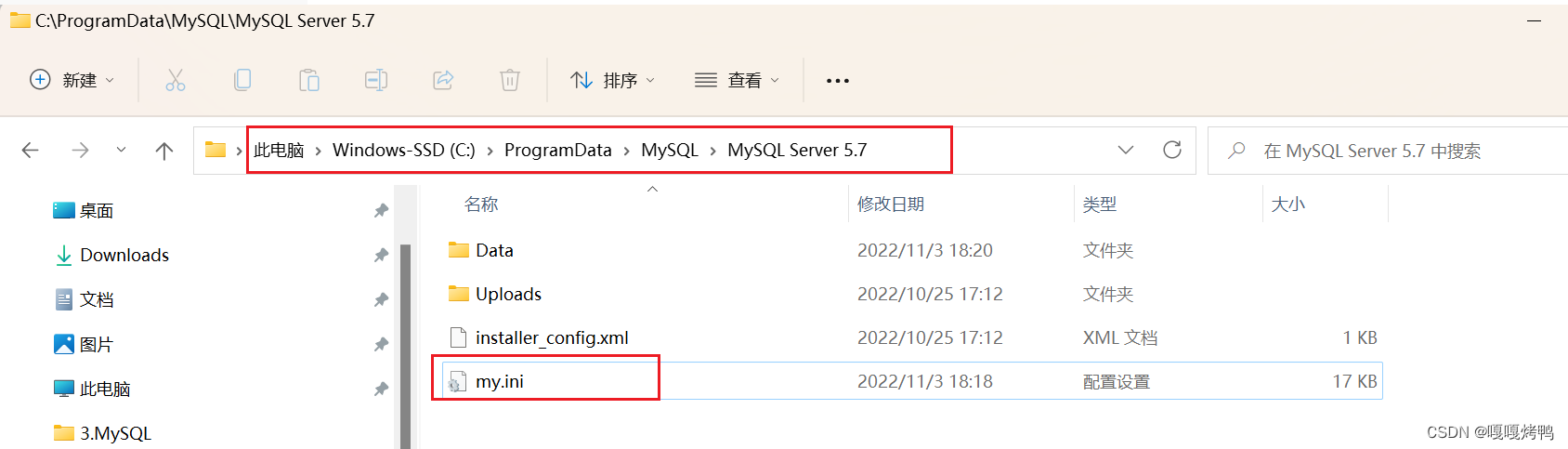
2、找到自己文件目录下mysql中的my.ini
3、打开my.ini记事本,找到[mysql]节点,
找到default-character-set,改成default-character-set=utf8
如果是#default-character-set=utf8,把#删除(前面有#号表示注释,需要删除#)
最后保证下面的样子:
4、ctrl+s保存
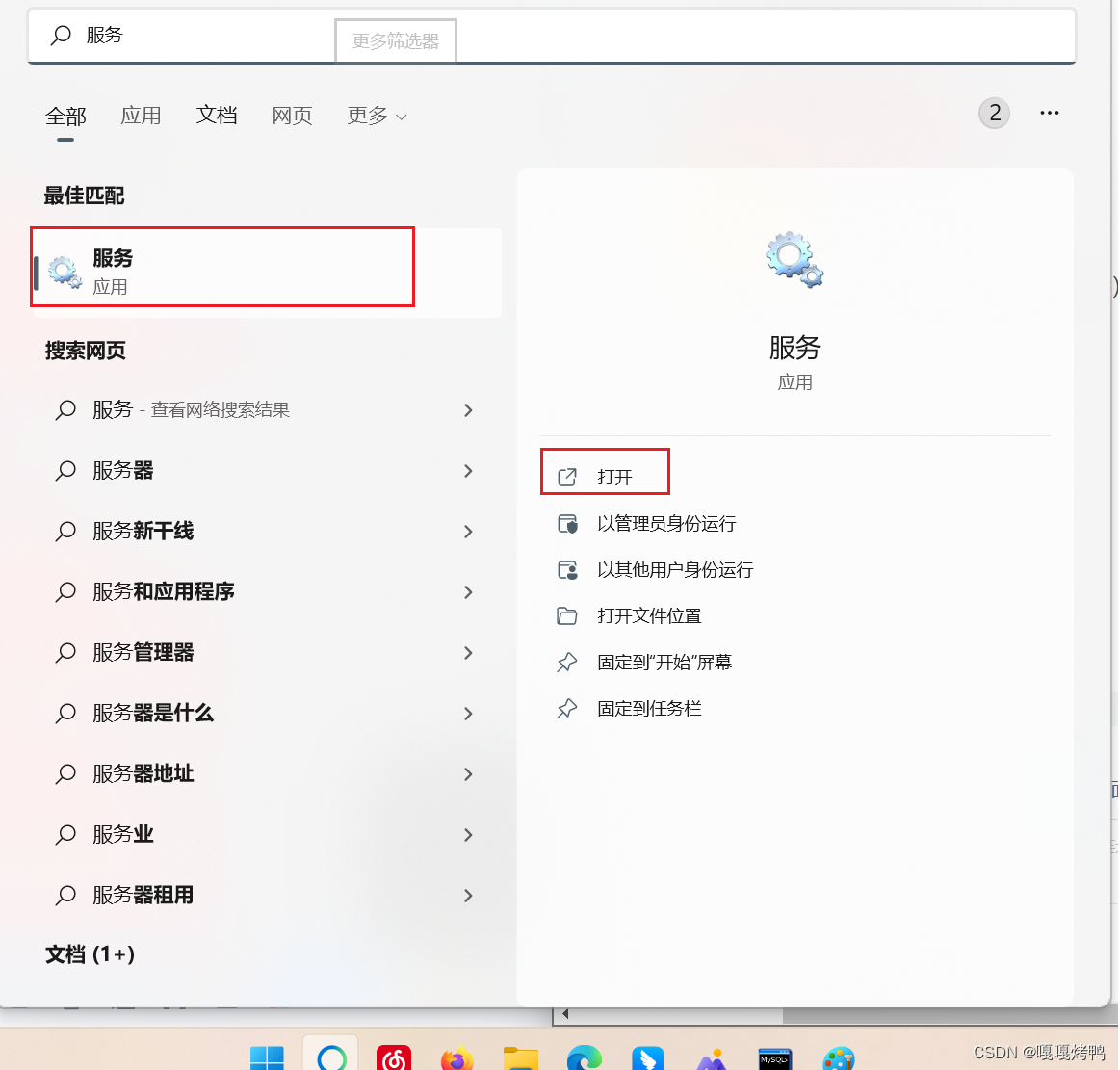
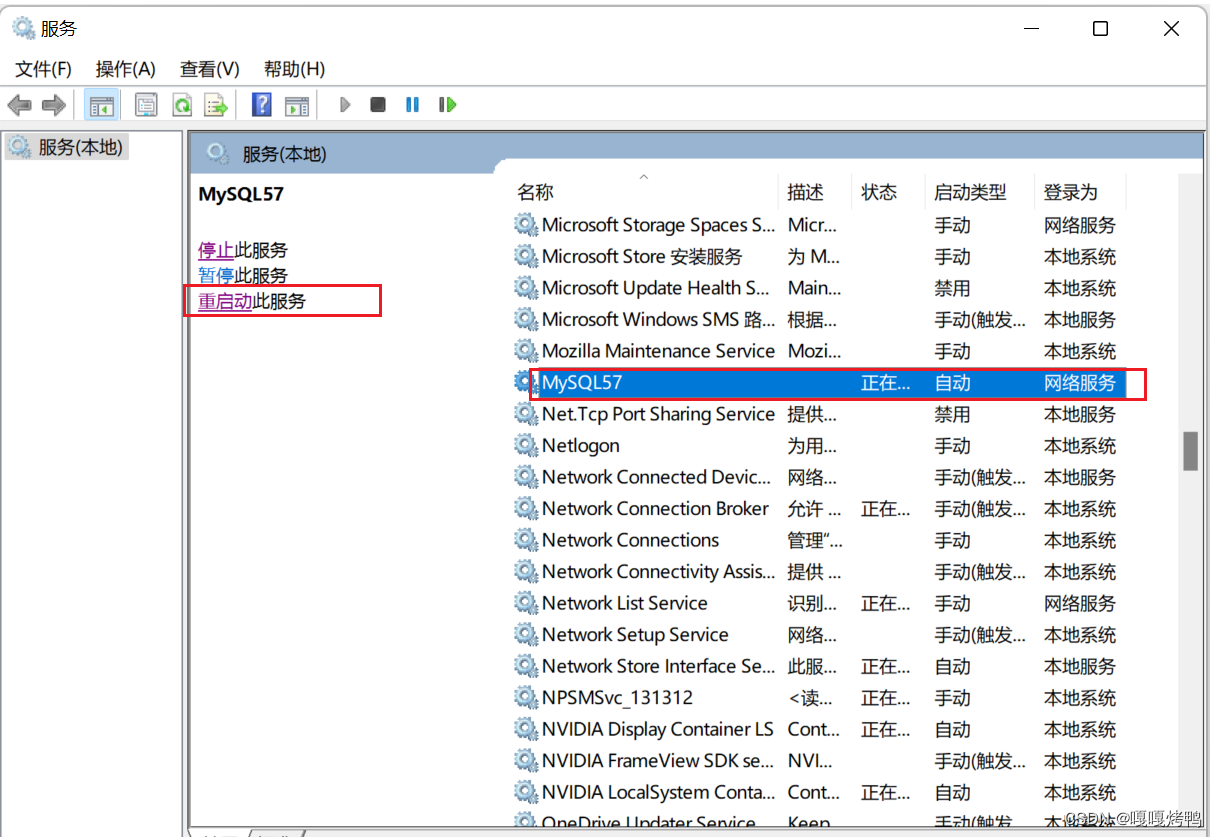
5、重启mysql(让服务器重新加载配置文件)
6、查看
7、使用



三、select查询
mysql数据库基本操作中select查询_嘎嘎烤鸭的博客-CSDN博客
3.1全列查询
select * from 表名;

3.2 单列查询
select 列名 from 表名;

3.3 查询的列为“表达式”
查询列为“表达式”,在查询过程中会进行一个简单的计算(列和列之间,行和行之间不行)
给所有同学的年龄加10
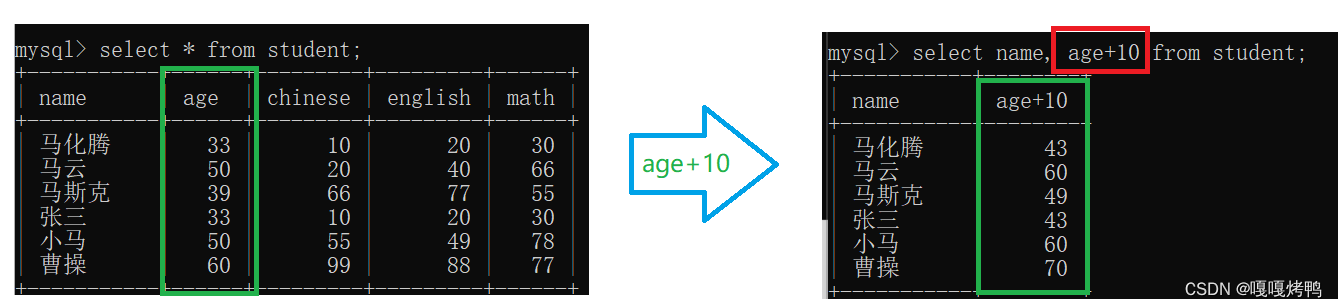
注意:进行表达式查询的时候,查询结构是一个临时表,并不会写入硬盘,(临时表的类型也不是和原始表的类型完全一致,会尽可能把数据表示进去),select只是查询,无论如何操作select都不会修改硬盘上的数据!!
查询所有同学的三门课总分

查询临时表的列名就是写的表达式

3.4 给查询结果指定别名

 3.5 去重distinct
3.5 去重distinct
查询的时候,针对列来进行去重(把有重复的记录合并成一个)
指定几个列就要求一定要这几个列重复才可以


3.6 针对查询结果进行排序order by

默认从小到大排序 asc
从大到小手动改成desc(descend)
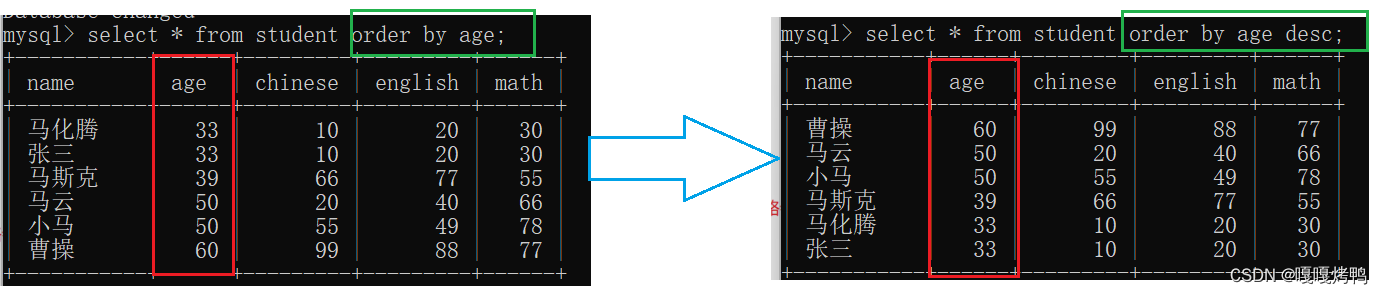
关于排序的注意事项:
- 如果sql中没有显式的写order by ,认为查询结果的顺序是不可预期的(mysql没有承诺默认顺序是按照插入顺序依次排列的)
- 如果要排序的列中有NULL,则视NULL为最小值
- 要是多个记录,排序的列值相同,此时先后顺序也是不确定的
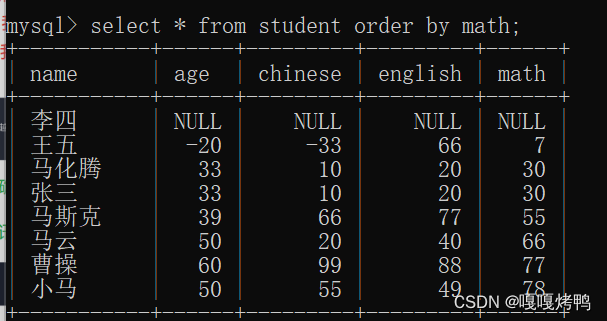
3.7 对别名/表达式来进行排序
按照同学的总成绩进行排序

在sql中,null和任何值进行计算,结果还是null
3.8 指定多个列进行排序
优先级问题:
先以第一列为标准排序,当第一列重复时,再按照第二个列的标准排序........
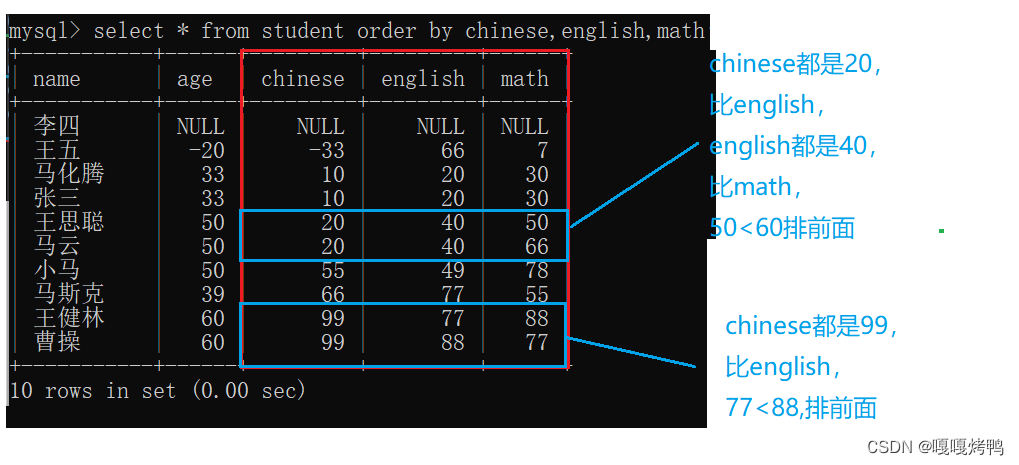
可以为每一列指定从小到大或者从大到小排序,在每一列后加asc或者desc

四、where条件查询
mysql数据库基本操作中where条件查询_嘎嘎烤鸭的博客-CSDN博客
4.1 条件查询where
针对查询结果,按照一定的条件进行筛选!!!
通过where指定一个条件,把查询到的每一行都带入到条件中,
- 看条件是真还是假,真->保留到临时表,假->舍弃
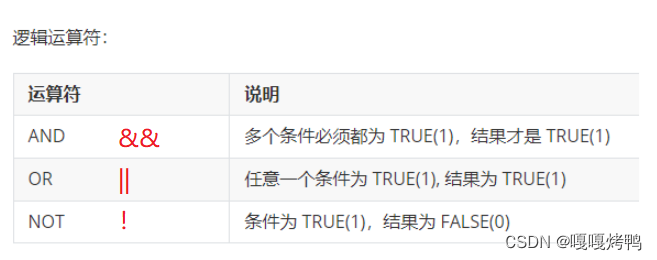
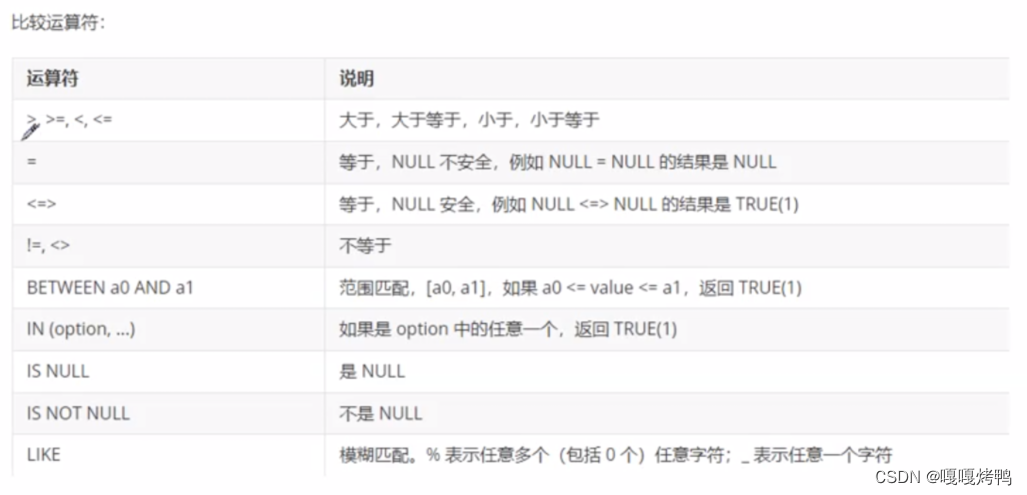
- 在SQL中 = 又变回“比较相等”(只在where子句中)
- 使用 = 来比较某个值和NULL的相等关系,结果还是NULL,NULL又会被当成false
- 所以就有了 <=> 针对NULL特殊处理
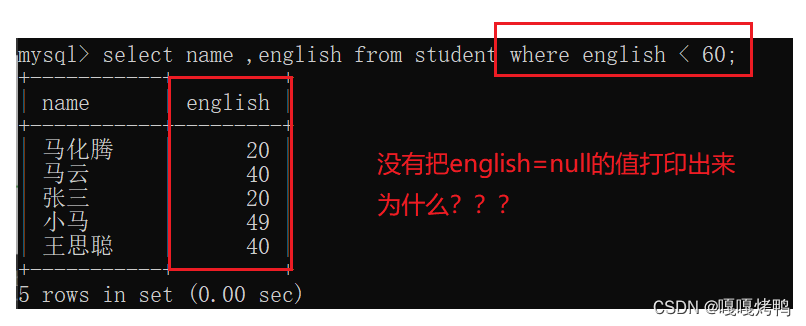
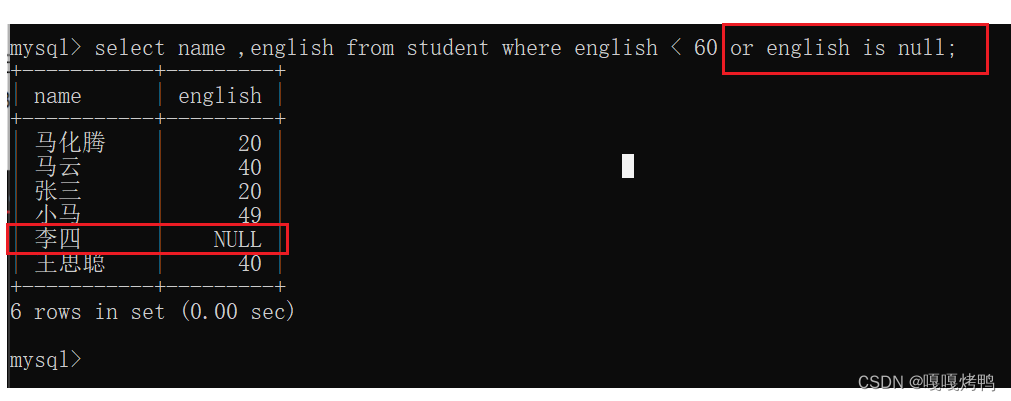
因为NULL和任何数据进行运算都是NULL,这里NULL<60结果还是NULL,当成了false,不打印。解决方法:加个条件or,带上NULL。
4.2 同一行的两个列进行比较

注意:where字句不能使用列的别名来比较
 内部原理解释:mysql里执行查询操作时,先针对每行记录计算条件,并按条件筛选,满足条件的记录才会取出对应的列,并且计算里面的表达式(生成别名)——先where条件筛选再as total起别名 。
内部原理解释:mysql里执行查询操作时,先针对每行记录计算条件,并按条件筛选,满足条件的记录才会取出对应的列,并且计算里面的表达式(生成别名)——先where条件筛选再as total起别名 。
所以先开始where的时候还没有生成total,这个条件都不认识,那么计算机自然会报错
逻辑运算符AND
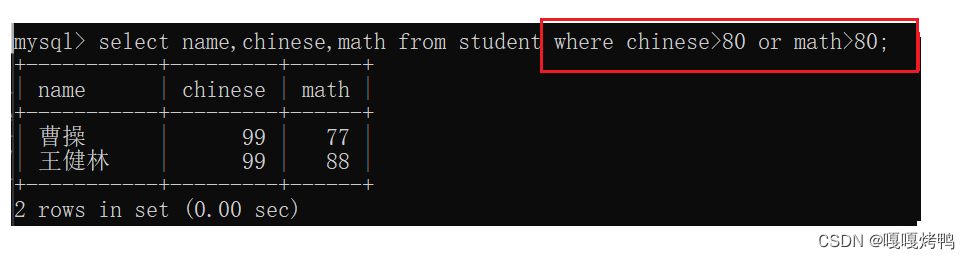
查询语文成绩大于80且数学成绩大于80的同学 
逻辑运算符OR
查询语文成绩大于80或者数学成绩大于80的同学
技巧:条件中有and和or,先计算and再算or。但是一般不建议记优先级,最好的办法是加括号()
between...and...
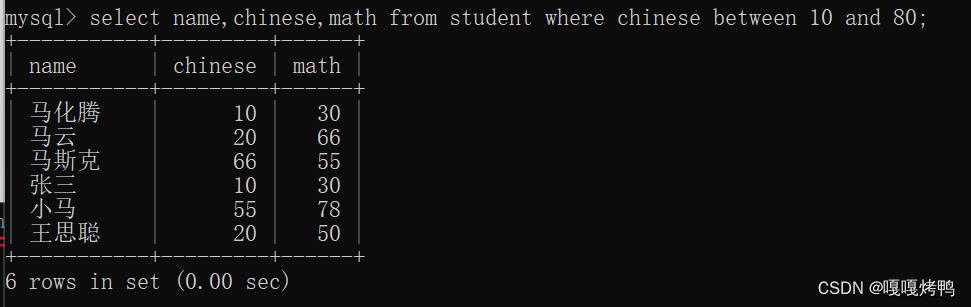
between A and B ——> [A,B] 左右都是闭区间
查询数学成绩是30或者55或者66的同学 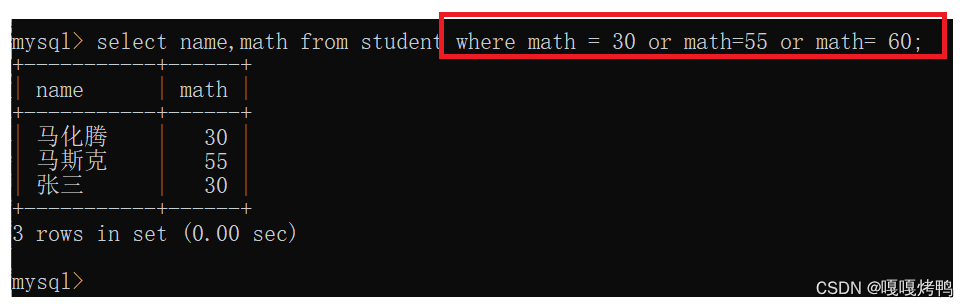
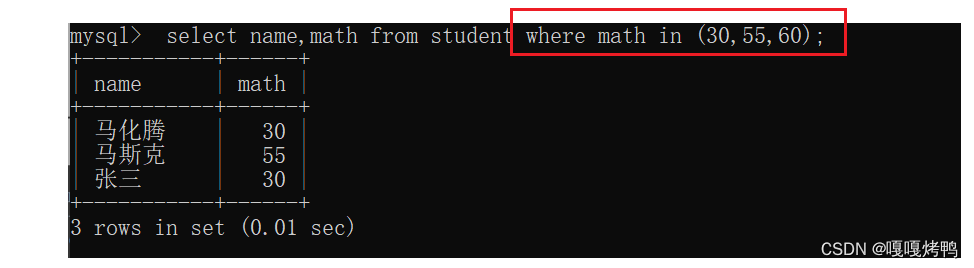
4.3 in
用in更方便
4.4 %
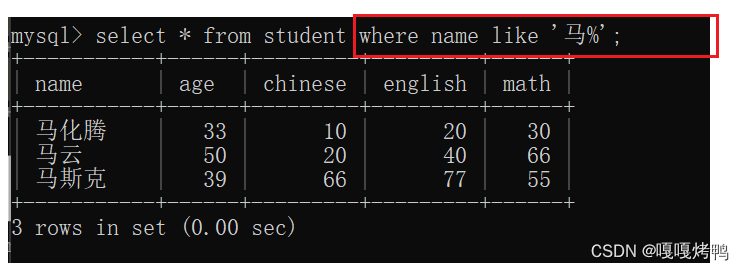
查询姓马的同学的成绩(开头第一个字是马)
%可以表示任意字符(0个也是),以马开头的name都可以被查出来
- 马%:以马开头的
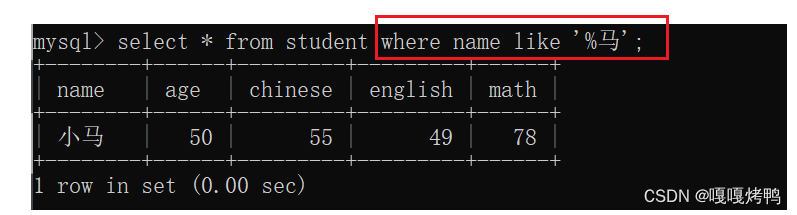
- %马:以马结尾的
- %马%:无论开头还是结尾,有马就行

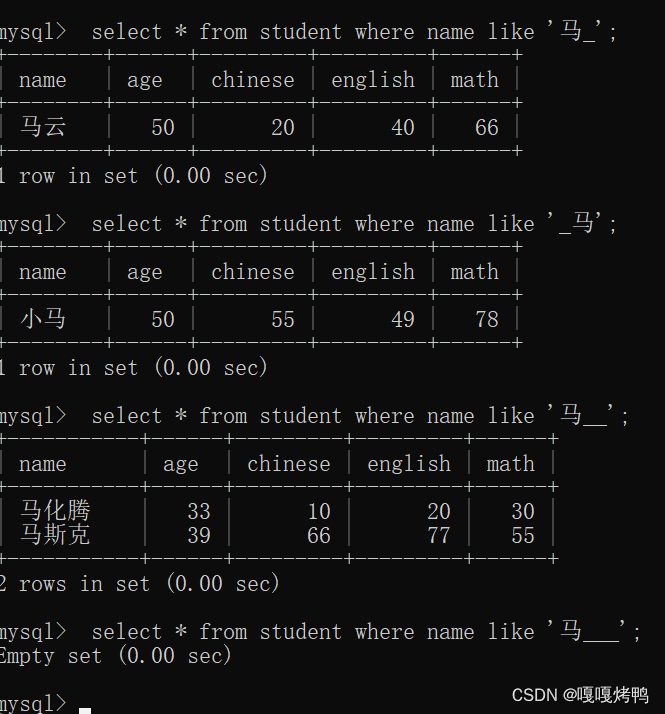
4.5 _下划线
_下划线,匹配任意一个字符
一个下划线就是一个字符
注意:模糊查询like对数据库来说开销还是比较大的
mysql支持的模糊匹配功能非常有限
实际开发中,可能会遇到更复杂的模糊匹配
可能会描述一些更复杂的规则,某某字符出现在什么位置范围,重复出现的次数。。。。
这就需要正则表达式来描述这种字符串的规则
正则表达式:使用一些特殊的规则,来描述一个字符串长啥样,那么查询或进行其他操作时,就可以按照这套规则来进行匹配。

解决方法:使用<=>和NULL比较;
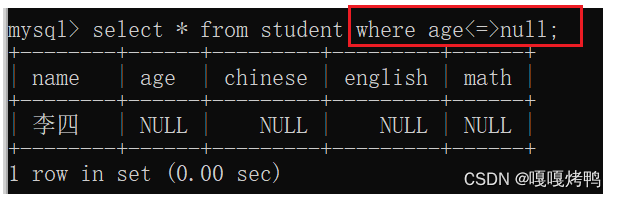
is null 要求只能比较一个列是否为空,而<=>可以直接比较两个列,一行里有两列都是null也可以查询出来。

- 条件查询不仅仅是搭配select使用,update/delete也会搭配where子句,对应的条件用法也是完全相同的。
- 通过条件来对结果集合进行限制,以防止select * 的卡死
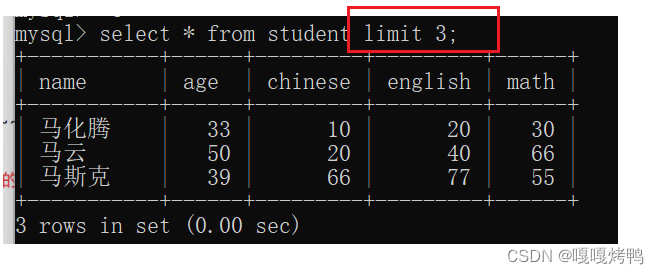
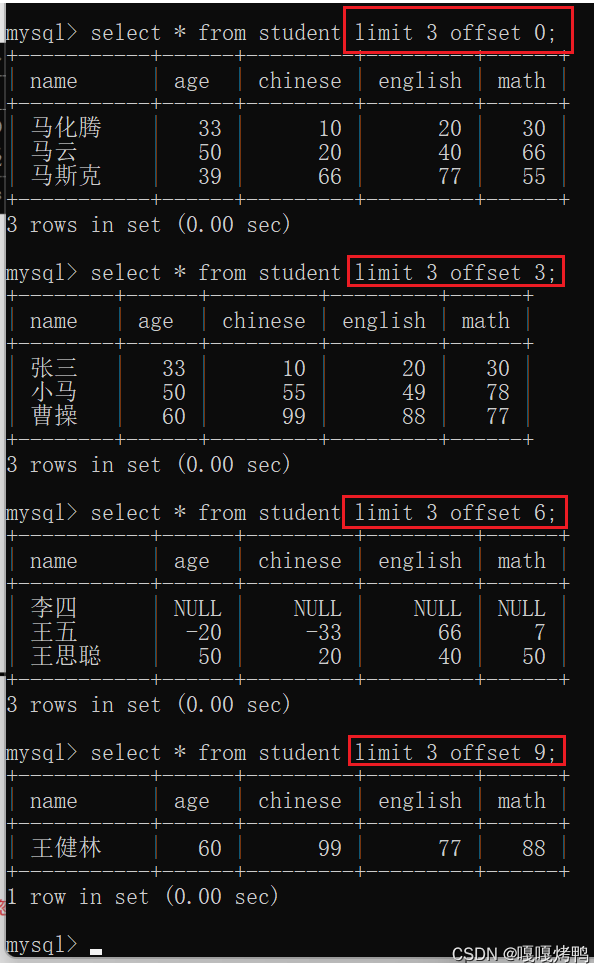
4.6 limit
限制查询结果的数量limit
直接在查询语句的末尾加上limit指定数字N,N表示这次查询最大结果的数量。
在数据库中,分页查询主要就是通过limit来实现的。
搭配offset就可以指定从第几条开始筛选了,(offset的值从0开始计算)
五、update修改、delete删除
mysql数据库基本操作中update修改、delete删除基本操作_嘎嘎烤鸭的博客-CSDN博客
5.1 update修改
update 表名 set 列名=值 where 条件;
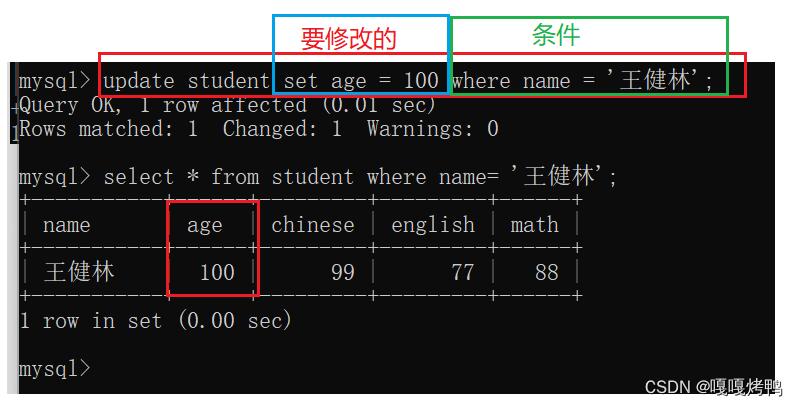
注意:修改操作是在改服务器里的硬盘数据了,修改后会持续生效。故update操作是很危险的。
修改操作还可以使用表达式来进行修改
没写where子句,就是匹配所有行
语法细节:不可以使用-=或+=
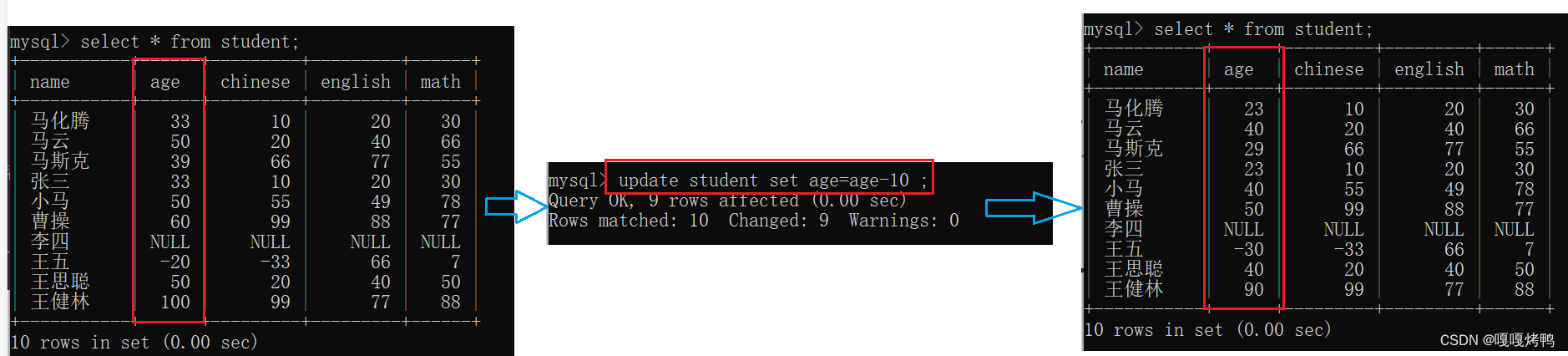
同时修改多个列,列与列之间用逗号,分隔

update搭配order by 和limit等子句来进行使用
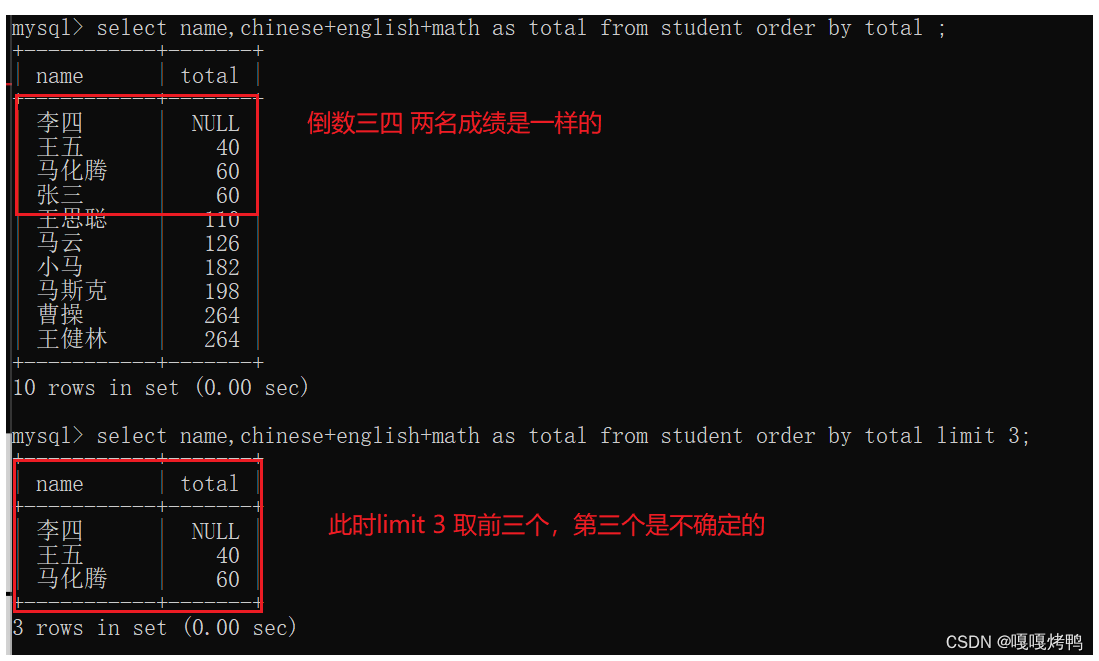
给总成绩倒数第四名的同学,数学成绩设置成10分
- 先加和得到总分
- 按照总分进行排序
- 取结果的前三个

 5.2 delete删除
5.2 delete删除
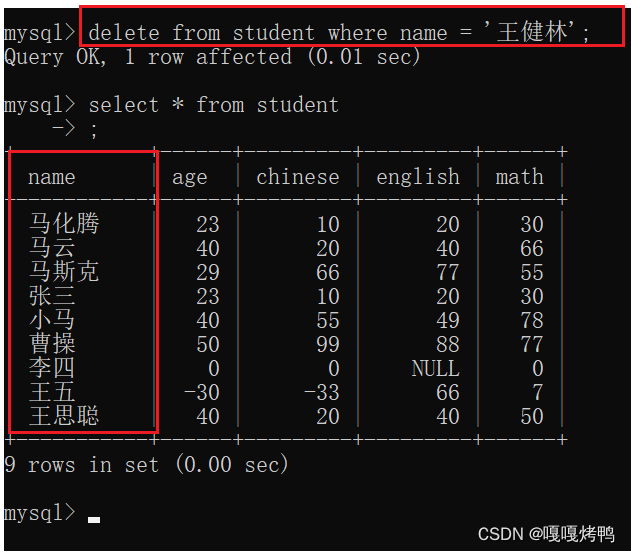
delete from 表名 where 条件;
delete也是在修改数据库服务器的硬盘,持久化删除
后面的条件也是和update一样,可以支持where 、order by 、limit
如果没写条件,就会把表里所有的记录都删除,非常危险

这种删除,只是删了表里的数据,表还是存在只是空了
drop是把整个表全部都删除了
六、数据库约束
约束就是让数据库帮助程序员更好的检查数据是否正确!

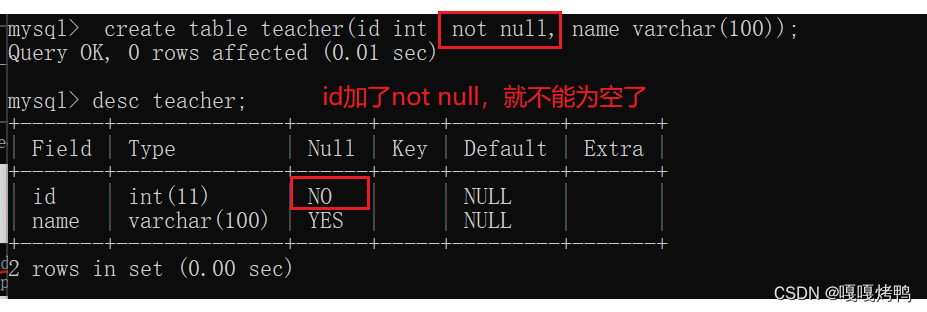
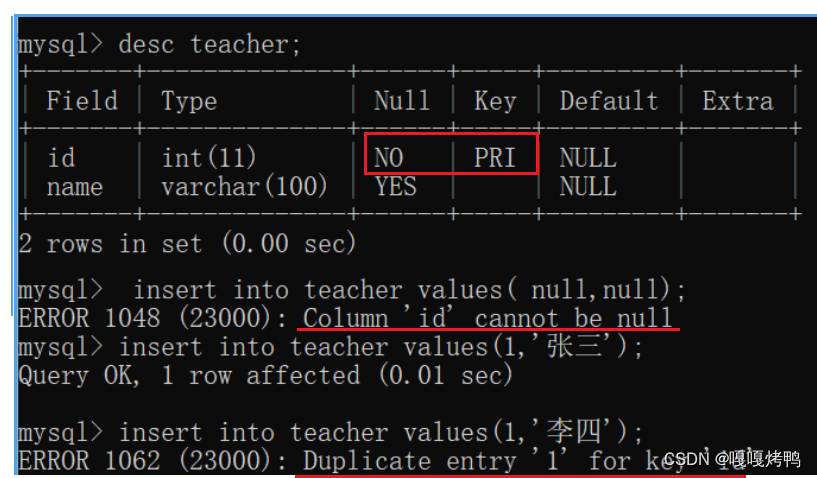
6.1 not null
NOT NULL指定某列不能存储NULL值


6.2 unique
UNI保证某列的每行必须有唯一的值
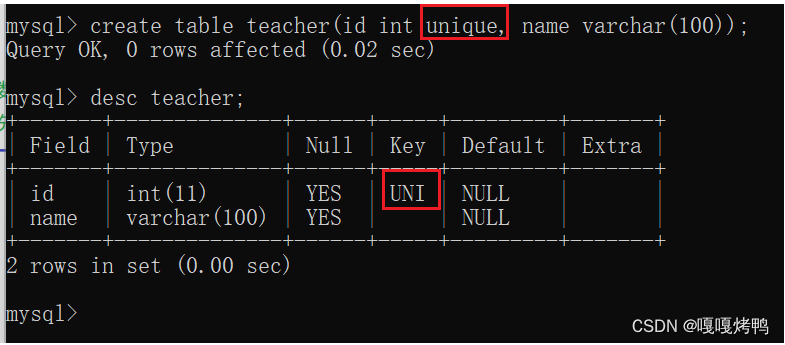

数据库是如何判断这条记录是重复的,先查找再插入,如果没有重复的就插入,重复了不允许插入。
约束是可以组合在一起使用的,同时加上not null和unique
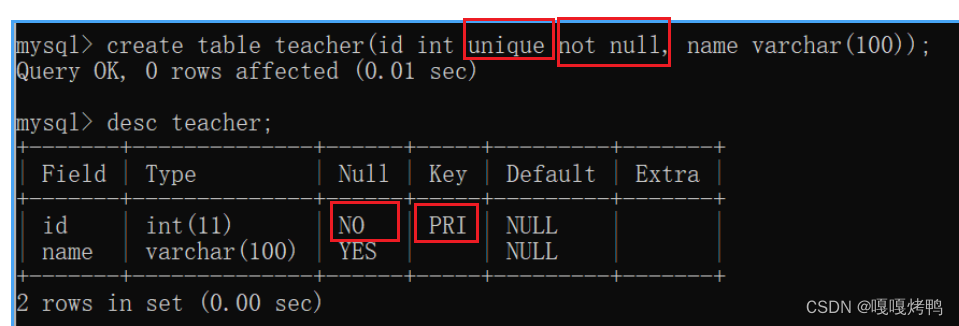
PRI = primary key4
主键约束就是not null和unique
主键也同样是在插入记录的时候先查找再插入的
正因为主键和unique都有先查询的过程,mysql就会默认给primary key 和 unique 这样的列,自动添加索引来提高查询的速度
- 实际开发中,大部分的表一般都会带一个主键,主键往往是一个整数表示的id
- 在mysql中,一个表里只能有一个主键,不能有多个
- 虽然主键不能有多个,mysql允许把多个列放到一起共同作为一个主键(联合主键)
- 主键另外一个非常常用的方法,就是使用mysql自带的"自增主键"作为主键的值,
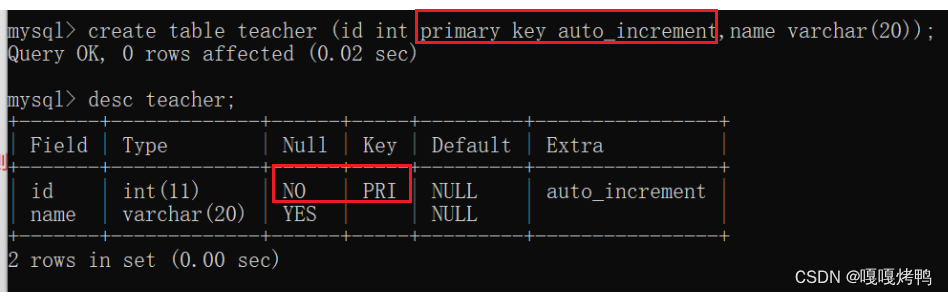
插入id的时候,可以手动指定,也可以不动手指定(null),则会有mysql自动生成。

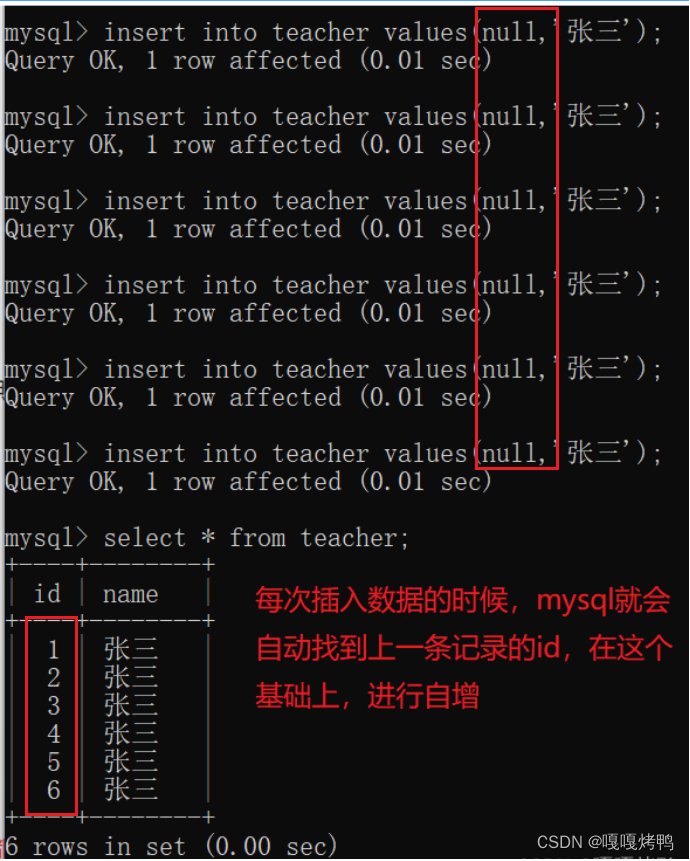
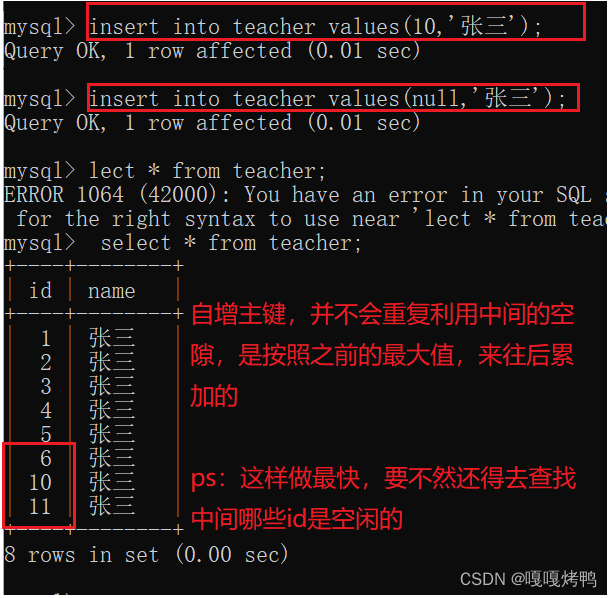
当mysql的数据量比较小,所有的数据都在一个mysql服务器上时,自增主键是可以很好工作的。
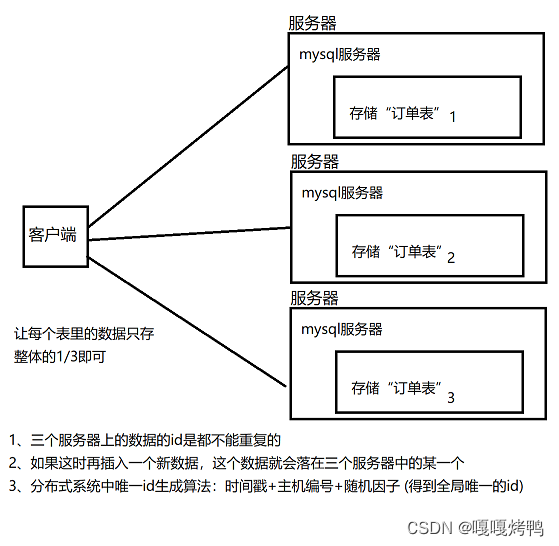
如果mysql的数据量很大,一台主机放不下,就需要进行分库分表,使用多个主机来进行存储了。本质上就是把一张大表分成多个小表,每个数据库服务器分别只存储一部分数据。
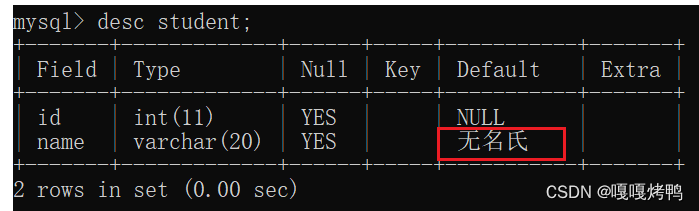
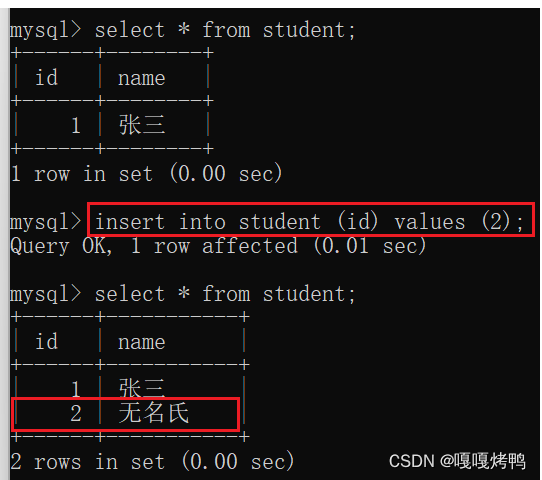
6.3 default
default 规定没有给列赋值时的默认值

6.4 foreign key
foreign key 外键约束,针对两个表之间产生的约束

此处外键约束的含义就是要求student里的classId务必要在class表的id列中存在。
学生表中的数据要依赖班级表的数据,班级表的数据要对学生表产生约束力(父亲对孩子有约束力),此处起到约束作用的班级表就叫做父表,被约束的表叫做子表
外键约束是父表约束子表,但实际上子表也在约束父表。

我们试图删除class表中id为1的记录,发现删除失败,因为id为1的被子表引用了。
id为3的没有被子表引用,可以删除
如果想删除,那就需要先删除子表,再删除父表
创建外键约束时,一定是先创建父表再创建子表
6.5 数据库实体的关系:
6.5.1 一对一
教务系统中,一个学生对应一个账号
- 把学生和账号放到同一个表里
- 学生和账号放在不同的表里,相互关联
6.5.2 一对多
教务系统中,班级和学生的关系
学生和班级放在不同的表里,相互关联
6.5.3 多对多
教务系统中,课程和学生的关系
三张表:

6.5.4 没关系
如果两个实体往上述三个关系中都套不进去,就是没关系
如何通过关系建表:
- 找实体,给每个实体都安排个表(需求中的关键字)
- 明确实体的关系(往固定造句格式中套)
- 根据这些关系使用固定的方法来建表
七、 聚合查询
聚合查询、联合查询【mysql数据库】_嘎嘎烤鸭的博客-CSDN博客
把查询结果插入到另一个表中(相当于复制表)

要求查询结果临时表的列数和列的类型,要和student2这里匹配
聚合查询需要搭配聚合函数

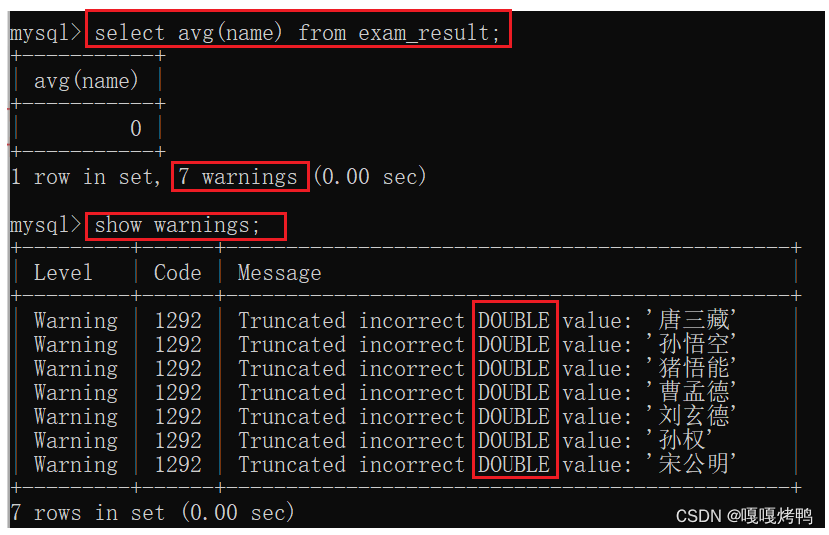
7.1 count

不一定非要写星号(*),还可以写成任意的 列名/表达式

虽然有一行是全NULL,count计算会把全为NULL的行也给计算进去

7.2 sum
sum求和,把这一列的所有行进行加和,要求这个列得是数字(不能是字符串/日期)

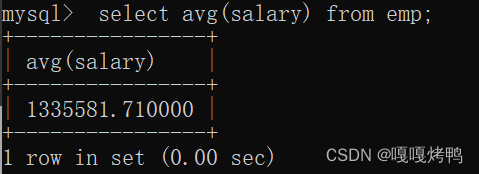
7.3 AVG
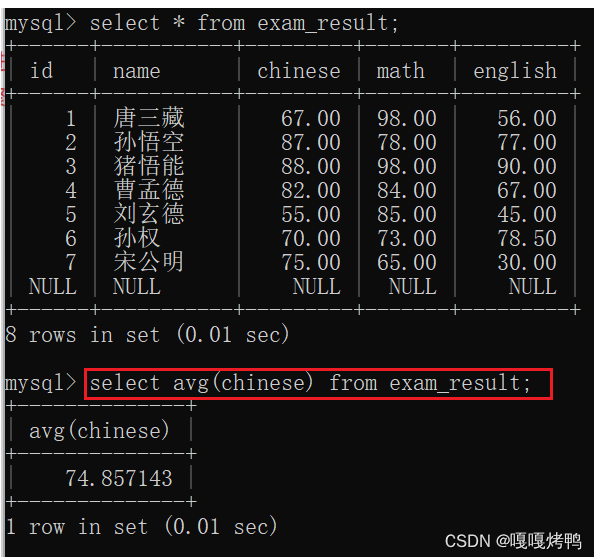
7.4 MAX&&MIN

求和,平均,最大,最小这些操作都是针对数字类型的列进行的。
表达式的聚合计算


八、联合查询
聚合查询、联合查询【mysql数据库】_嘎嘎烤鸭的博客-CSDN博客
包括:内连接,外连接,子查询,合并查询
多表查询的基本执行过程:笛卡尔积
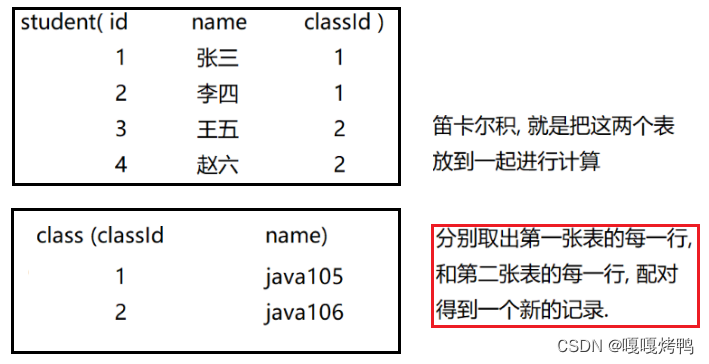
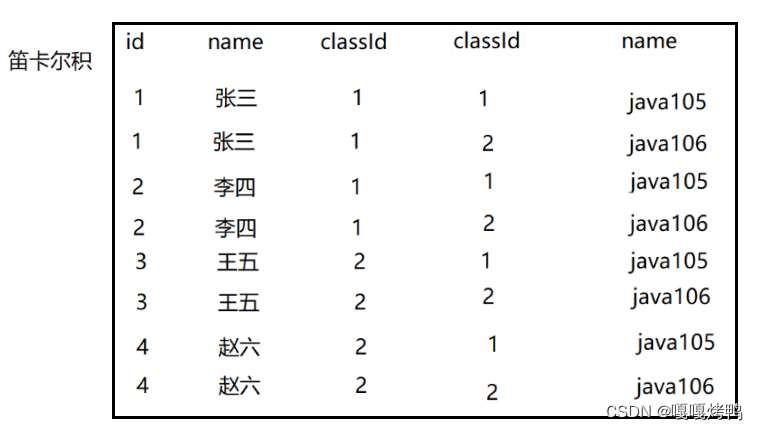
笛卡尔积通过排列组合:列数是两个表列数的和,行数是两个表行数的积
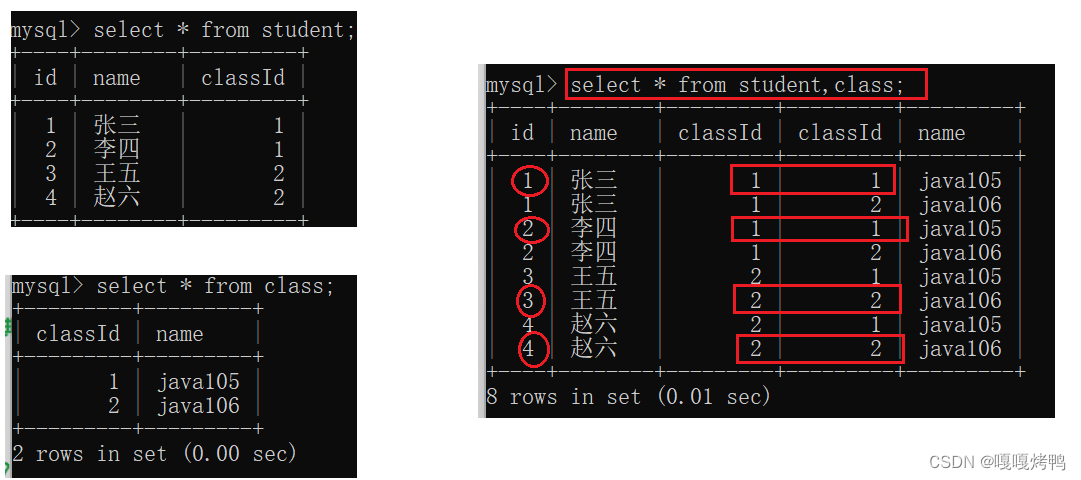
通过条件,排除无意义的数据。
练习:
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
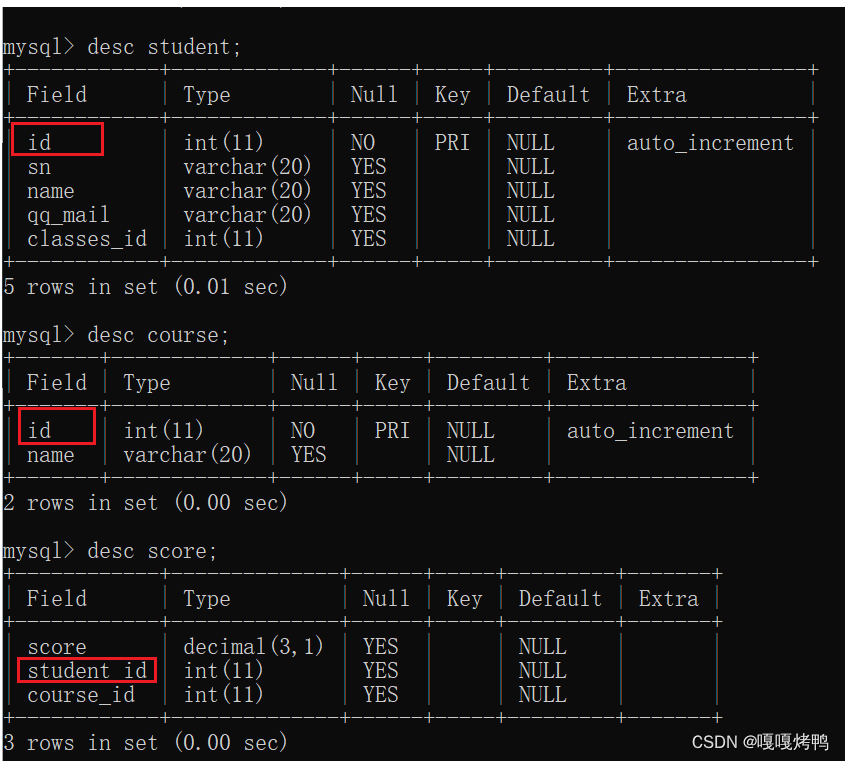
create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20) , classes_id int);
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3, 1), student_id int, course_id int);
insert into classes(name, `desc`) values
('class1', 'desc1'),
('class2','desc2'),
('class3','desc3');
insert into student(sn, name, qq_mail, classes_id) values
('09982','likui','xuanfeng@qq.com',1),
('00835','puti',null,1),
('00391','baisuzhen',null,1),
('00031','xuxian','xuxian@qq.com',1),
('00054','buxiangbiye',null,1),
('51234','haohaoshuohua','say@qq.com',2),
('83223','tellme',null,2),
('09527','laowai','foreigner@qq.com',2);
insert into course(name) values
('Java'),('wenhua'),('yuanli'),('chinese'),('math'),('english');
insert into score(score, student_id, course_id) values
-- likui
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- puti
(60, 2, 1),(59.5, 2, 5),
-- baisuzhen
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- xuxian
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- buxiangbiye
(81, 5, 1),(37, 5, 5),
-- haohaoshuohua
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);4个表:student 学生表 、 classes 班级表 、 course 课程表 、 score 分数表
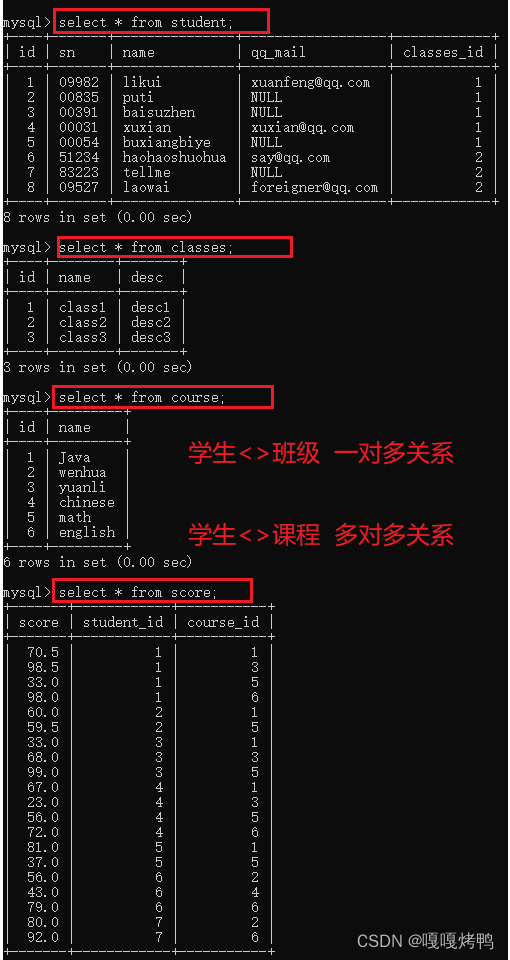
查询许仙同学的成绩
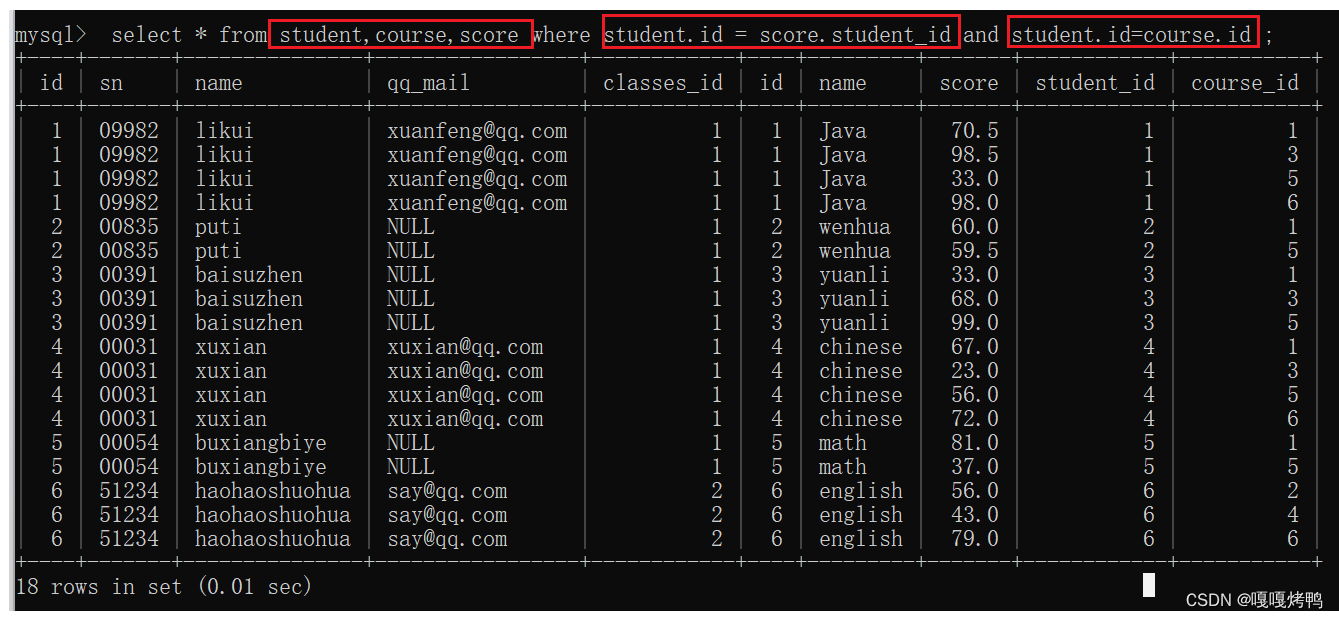
写法1:from多个表
1、先笛卡尔积
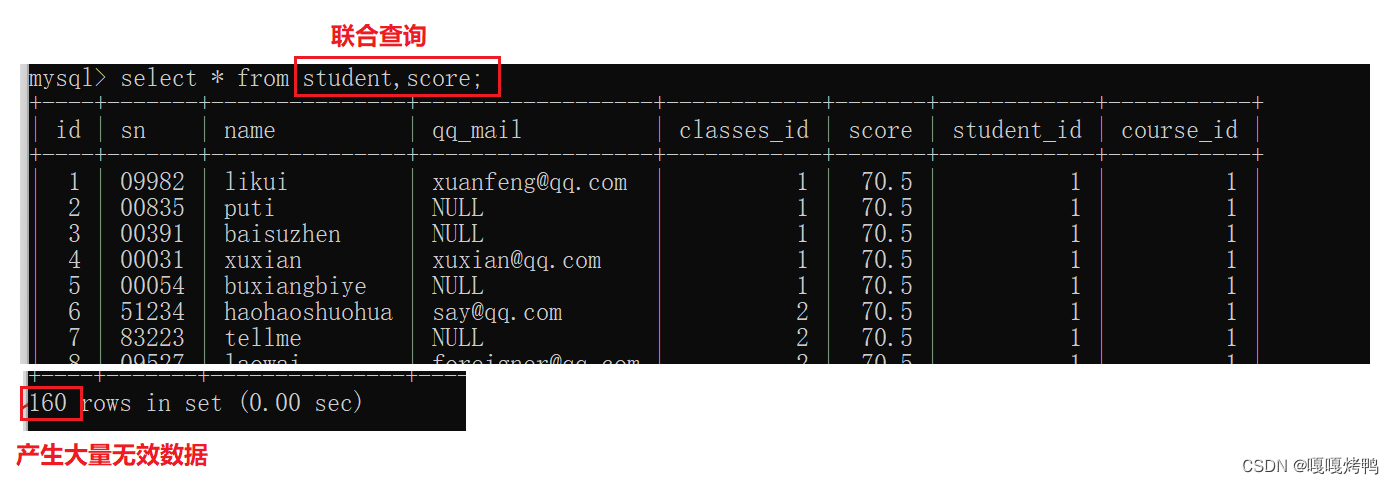
2、引入连接条件
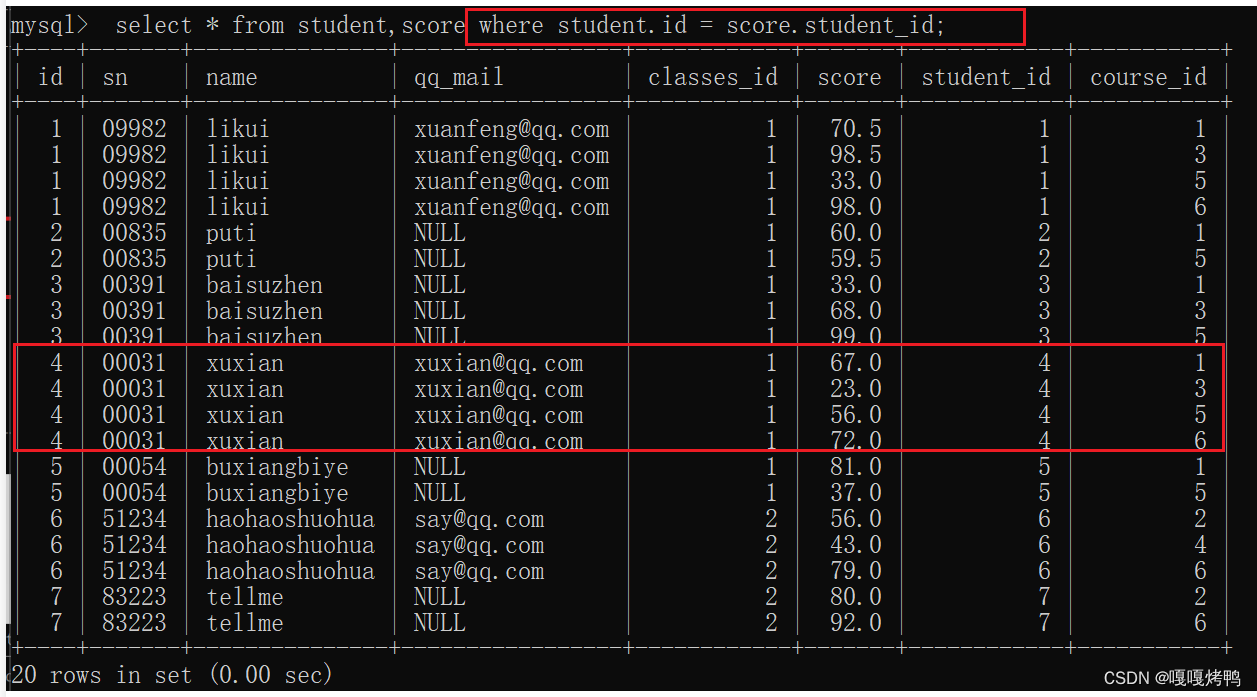 3、根据必要需求,加入必要的条件即可
3、根据必要需求,加入必要的条件即可
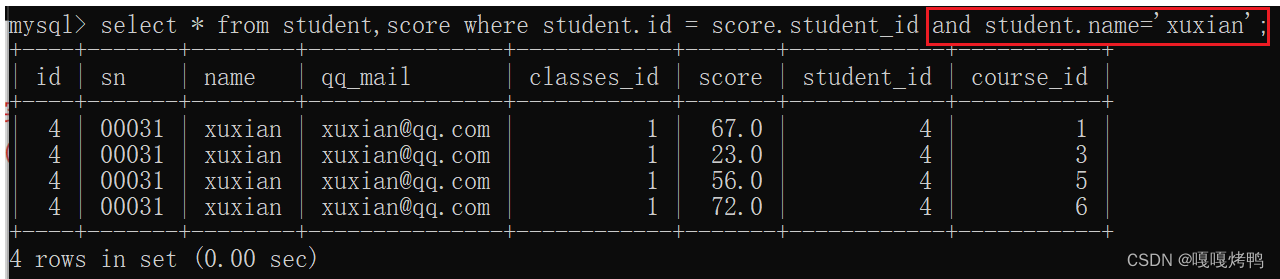
4、把不必要的列去掉,保留想关注的列

写法二:join on

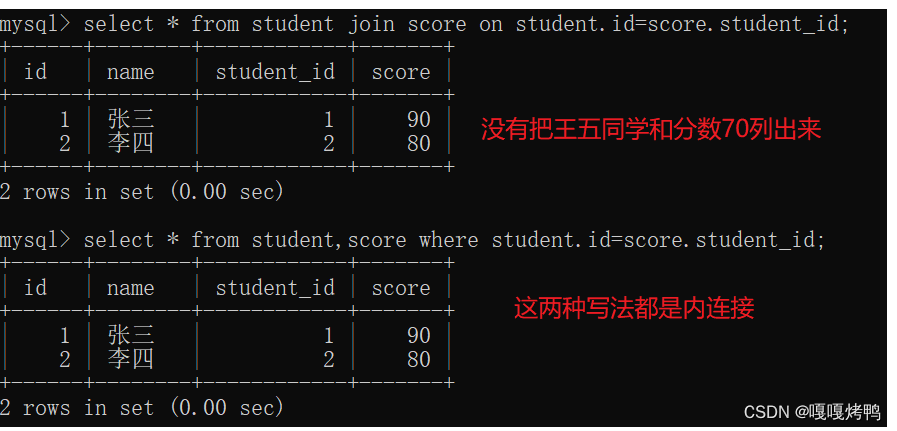
写法三:inner join
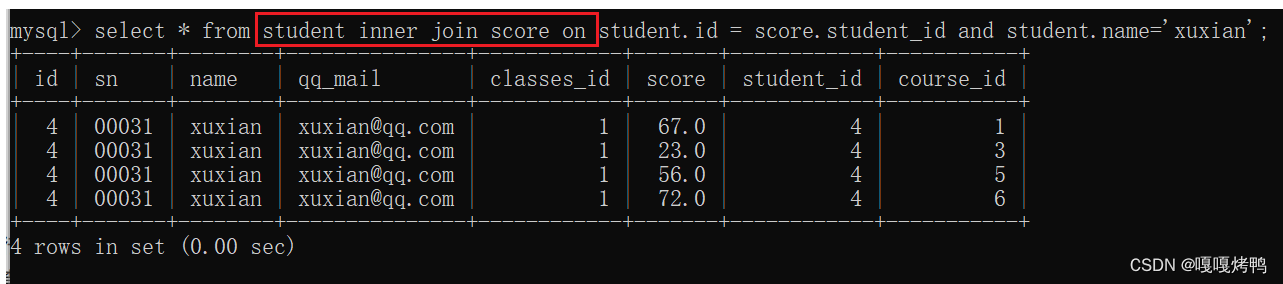
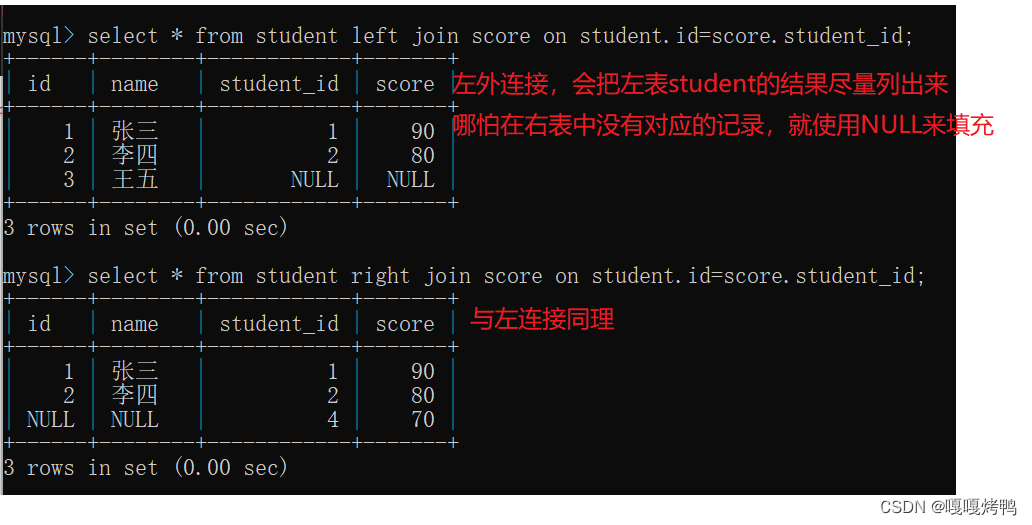
注意: from多个表只能够实现内连接,而join on既可以实现内连接也可以使用外连接。
查询所有同学的总成绩及个人信息

第一步:笛卡尔积

第二步:加上连接条件

第三步:加上聚合查询,把同一个学生的行合并到一个组里,同时计算总分
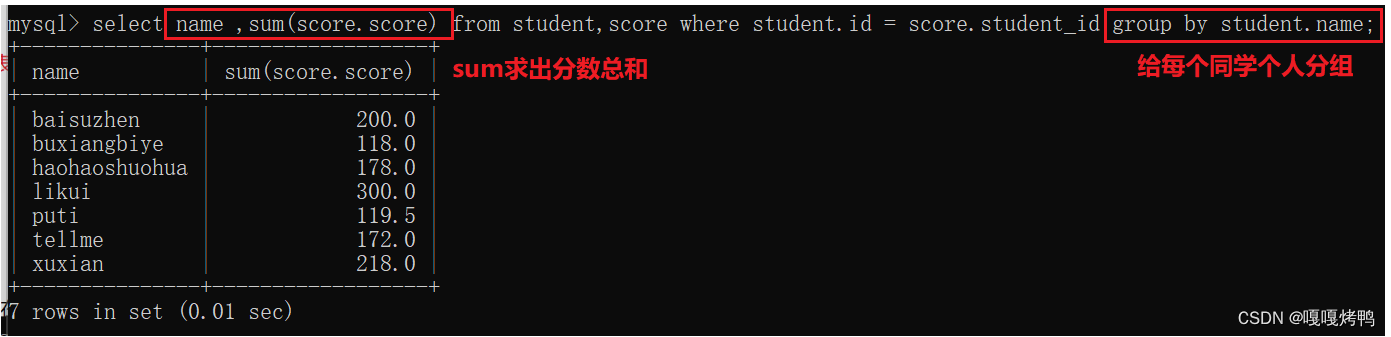
第一步:笛卡尔积

第二步:引入连接条件:三张表需要两个连接条件
第三步:精简一些不必要的列
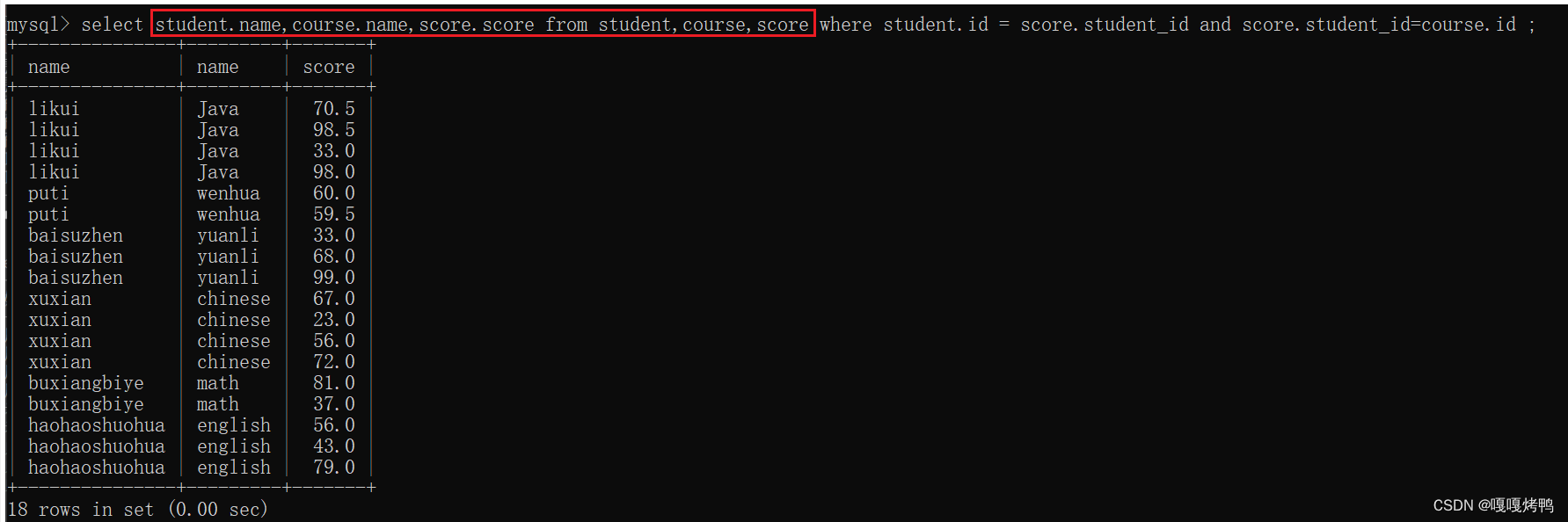
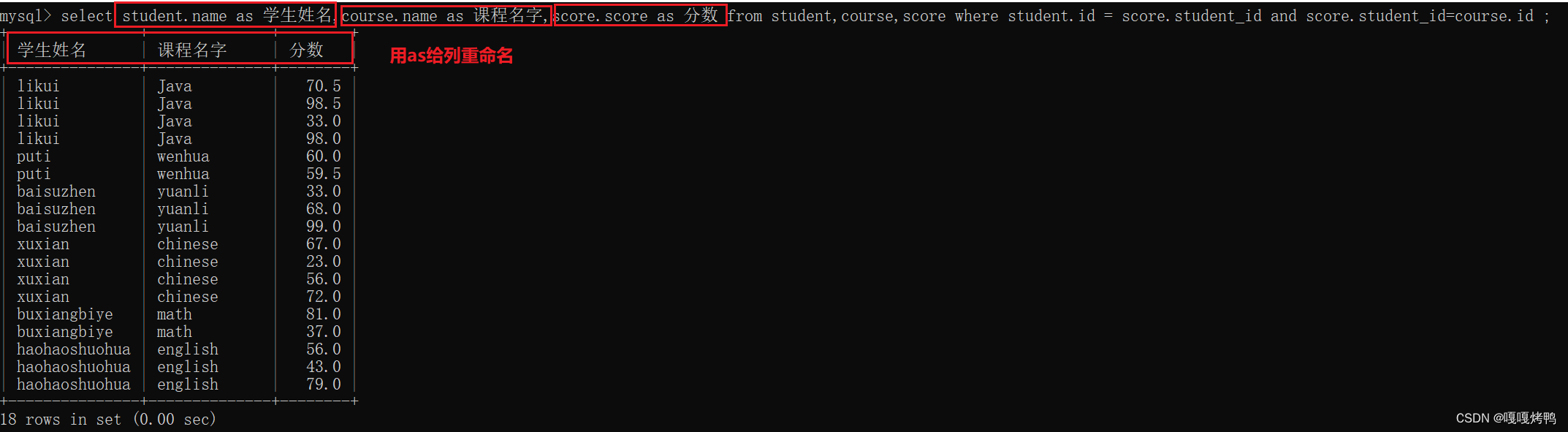
用join on也是没问题的
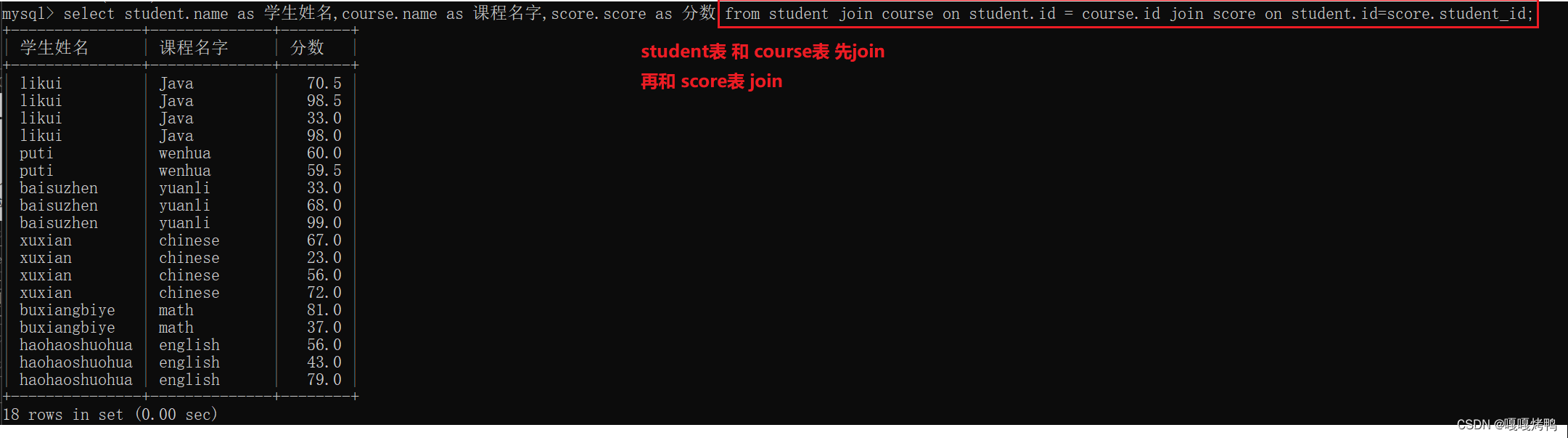
内连接和外连接在大多数情况下是没有区别的,比如要连接的两个表里面的数据都是一一对应的,这时是没有区别的,如果不是一一对应,内连接和外连接就有区别了。
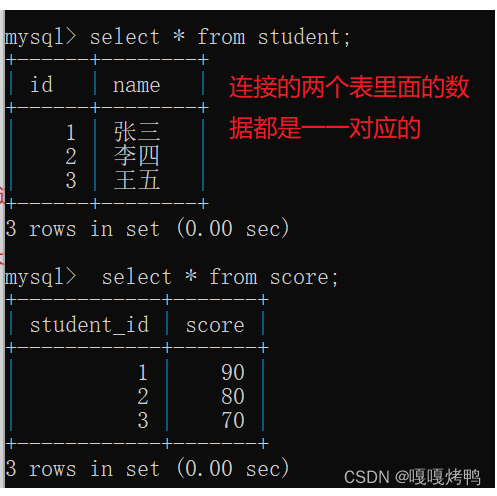
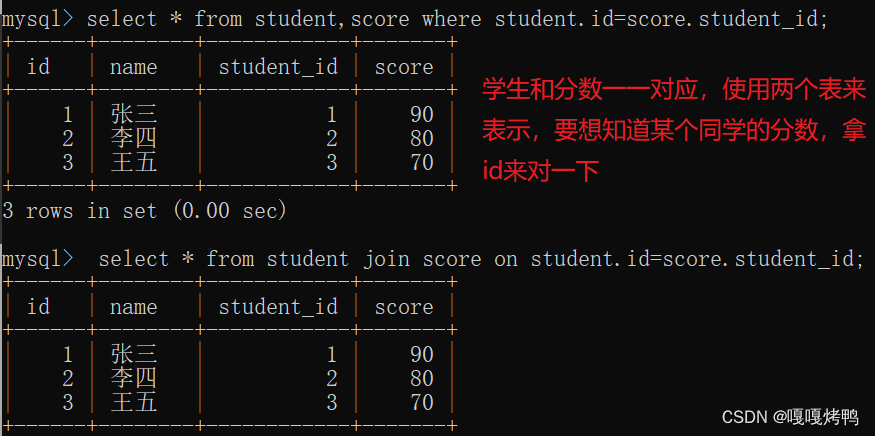
如果不是一一对应

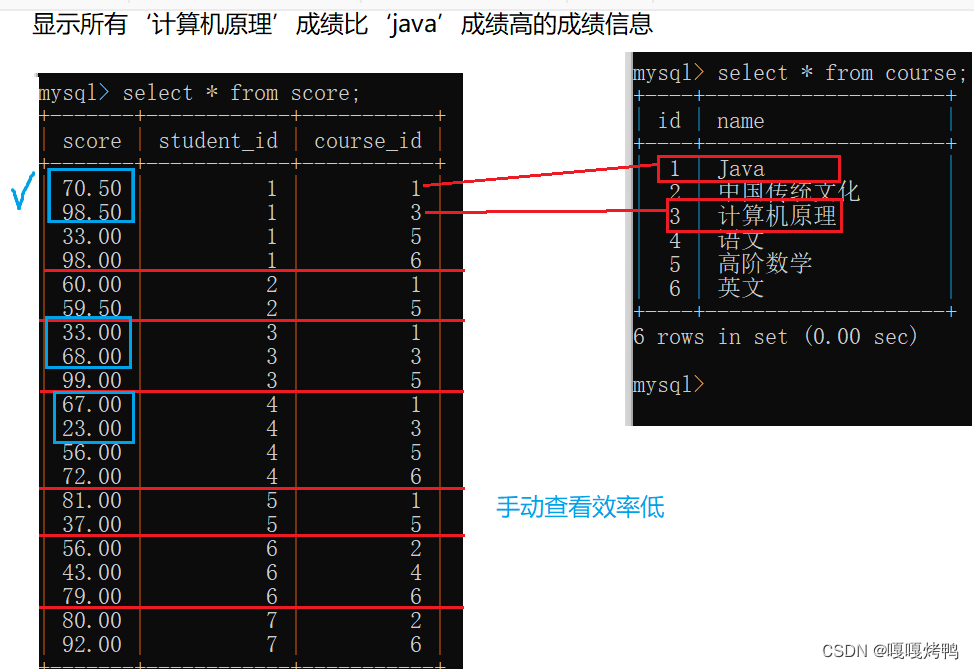
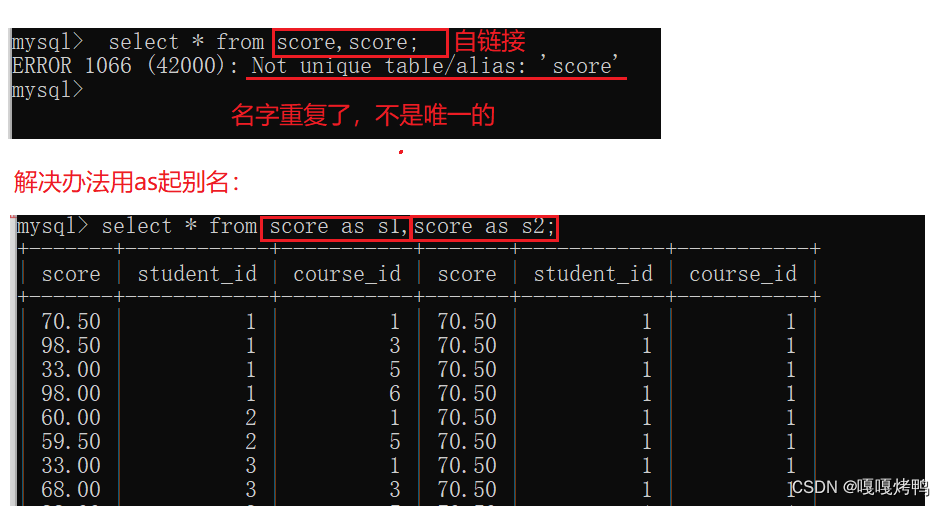
 自连接:自己和自己进行笛卡尔积
自连接:自己和自己进行笛卡尔积
SQL中无法针对行和行之间的条件比较,需要使用自连接,把行转成列
显示所有‘计算机原理’成绩比‘java’成绩高的成绩信息

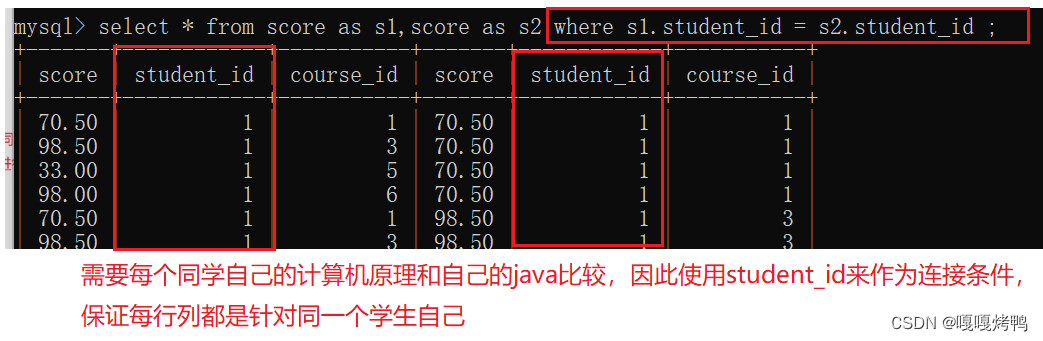
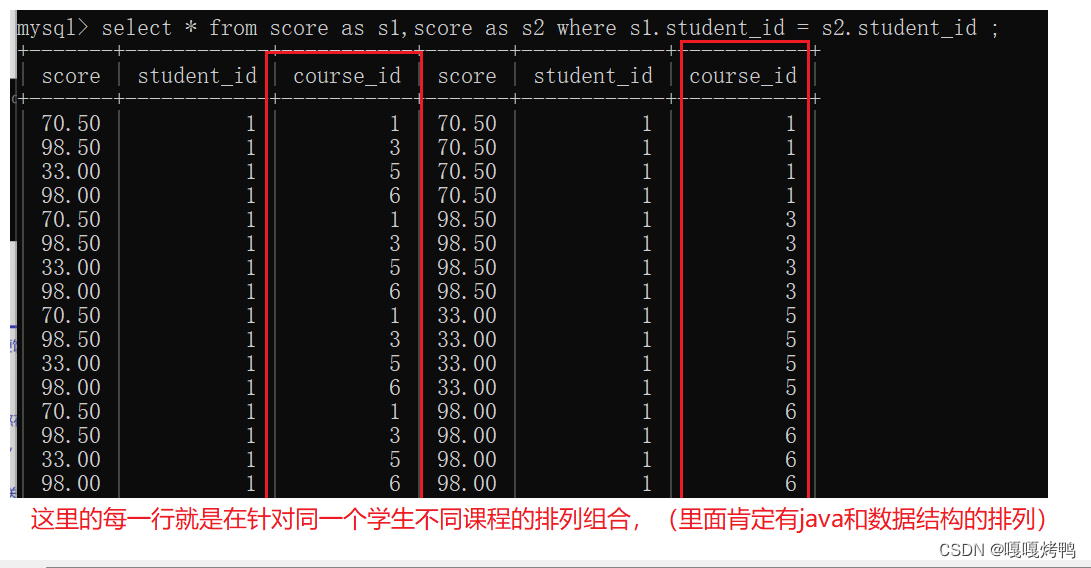

 子查询:把多个SQL组合成一个,把一个查询作为另一个查询的一部分条件(套娃),代码可读性非常差,执行效率也非常差(慎用)
子查询:把多个SQL组合成一个,把一个查询作为另一个查询的一部分条件(套娃),代码可读性非常差,执行效率也非常差(慎用)
单行子查询:返回一行记录的子查询
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
4.2.1 内连接
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
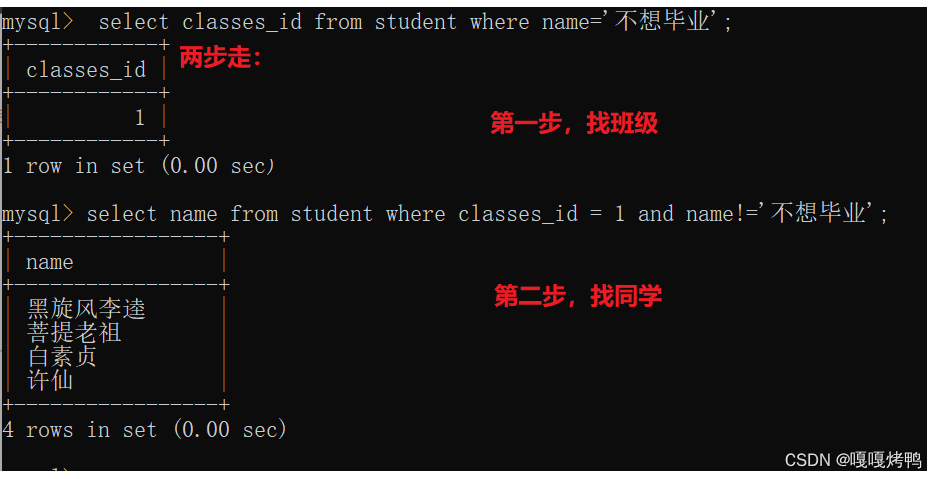

多行子查询:返回多行记录的子查询
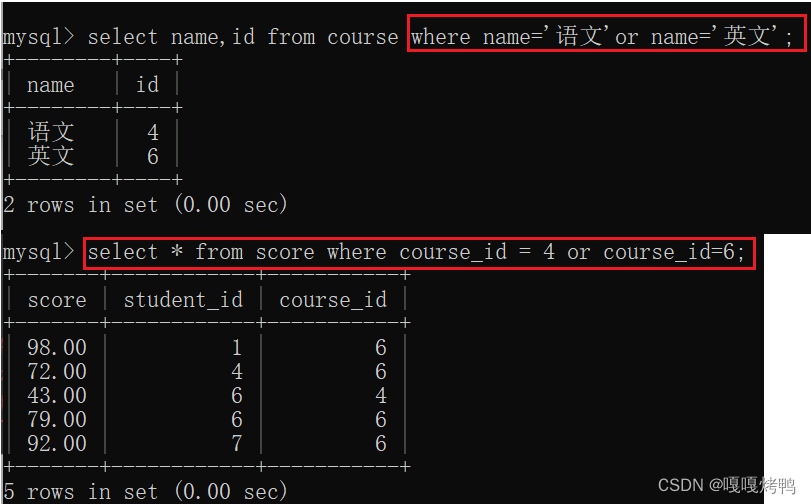
查询“语文”或“英语”课程的成绩信息
- 先根据课程名字查询出课程id
- 再根据课程id查询出课程分数

注意:查询结果放在内存中,如果查询结果太大了,内存放不下,in就用不了了,可以使用exists代替,exists本质上就是让数据库执行很多个查询操作, 但是exists可读性比较差,执行效率也大大低于in(适合解决特殊场景)
合并查询:本质上是把两个查询的结果集合成一个,union、union all
查询id小于3,或者名字为“英文”的课程:

or和union的区别:
or查询只能来自同一张表,union查询可以是来自不同的表,只要查询的结果的列匹配即可。
union和union all的区别:
union 会进行去重(把重复的行只保留一行),union all可以保留多份,不会去重。
九、group by 分组
group by 分组【mysql数据库】_嘎嘎烤鸭的博客-CSDN博客
引入group by 可以针对不同的组来分别进行聚合
//数据
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66),
('小马','服务员', 1200.20),
('kiki','游戏陪玩', 2000.20),
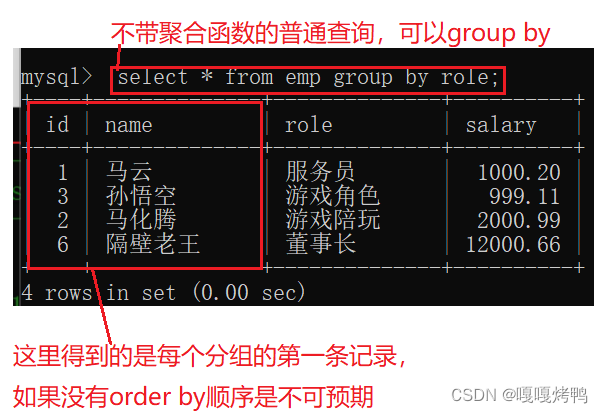
('马斯克','董事长', 12000000.20);不用group by 分组的时候,相当于就只有一组,把所有的行进行聚合。
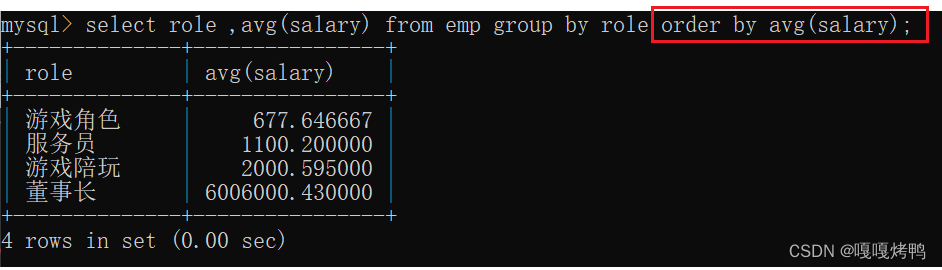
根据角色role这个类来进行分组,统计平均工资salary

把role这一列值相同的行分成了一组,然后计算平均值也是针对单个分组而言的。
分组查询指定条件,分为
- 分组前指定条件(先筛选,再分组)where
- 分组后指定条件(先分组,再筛选)having
- 分组前后都指定条件where having
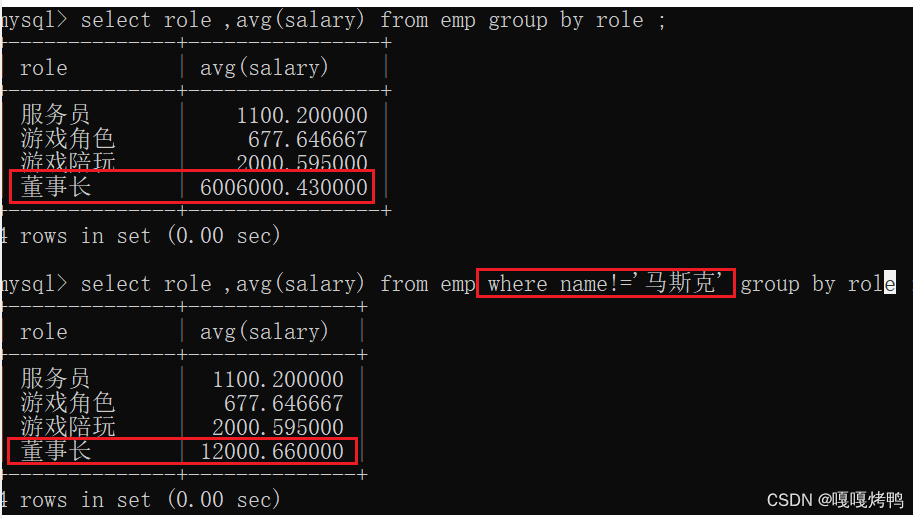
9.1 分组前指定条件
统计每个岗位的平均薪资,但是刨除某个人的数据
9.2 分组后指定条件
查询每个岗位的平均工资,但是刨除平均薪资在1000一下的
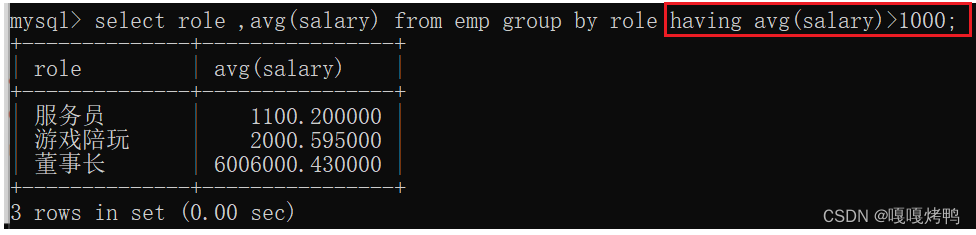

9.3 分组前后都指定条件

十、索引
10.1 概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引, 并指定索引的类型,各类索引有各自的数据结构实现。
10.2 作用
数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。 索引所起的作用类似书籍目录,可用于快速定位、检索数据。 索引对于提高数据库的性能有很大的帮助。
10.3 使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
数据量较大,且经常对这些列进行条件查询。
该数据库表的插入操作,及对这些列的修改操作频率较低。
索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。 反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
举一个形象的例子,索引本质上相当于“书的目录”,通过目录就可以快速的找到章节对应的位置,索引的效果就是加快了查找的速度。
数据库操作查的概率比增删改的概率要大得多,因此大多数情况下,引入索引还是比较好的选择,但是注意,索引也会增加增删改的时间开销(增删改需要调整已经创建好的索引目录),还会增加空间的开销(构造索引,也需要额外的硬盘空间来保存)。
10.4 使用
mysql数据库创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
查看索引——show index from 表名;
创建索引:对于非主键、非唯一约束、非外键的字段,可以创建普通索引——create index 索引名 on 表名(字段名);
删除索引——drop index 索引名 on 表名;
创建索引最好是在表创建之初就把索引给搞好,否则在数据很多的情况下是很危险的操作。
- 吃掉大量的磁盘IO,这段时间内数据库是无法被正常运行的(删除索引也是如此)
- 针对性别这样的列添加索引是无法提高查找数据的
- 要是已经有大量数据了,再进行操作就要慎重了


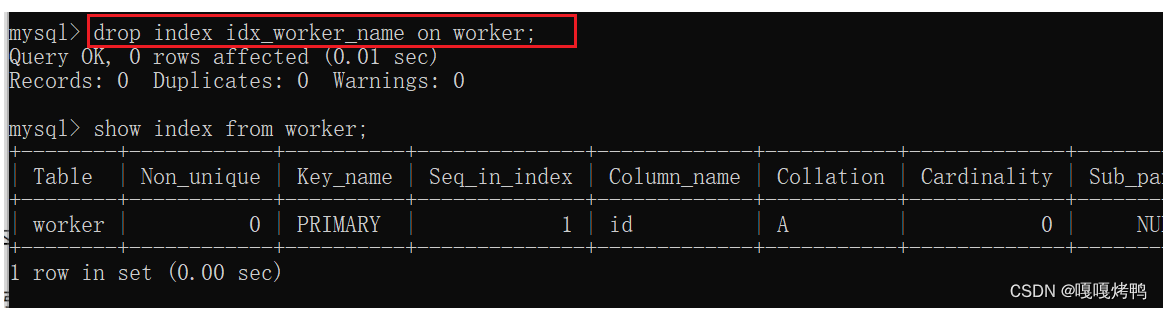
索引创建好之后不需要手动使用,直接查询的时候数据库会自动的来走索引,SQL是通过数据库的执行引擎来执行的,执行引擎内部会有优化操作(自动评估,选择成本最低,速度最快的方法),查询是否在走索引或者怎么走的是不好预测的,可以使用explain这个关键词来显示查询过程中具体的使用索引的情况。
10.5 索引在mysql中的数据结构
是哈希表吗? 不是
哈希表只能比较相等,无法进行范围查询(显然mysql经常要范围查询)
是二叉搜索树吗? 不是
二叉可以范围查询,但元素个数多了树的高度会很高,元素的比较次数就会比较多
是N叉搜索树(B树)吗? 不是
虽然比较次数较二叉没怎么减少,但是读写硬盘的次数减少了
是B+树吗? 是滴~
为数据库量身定做的数据结构

B+树也是一个N叉搜索树,每个节点上可能包含N个key,N个key划分出N个区间,最后一个key相当于是最大值。
父元素的key会在子元素中重复出现,并且是子元素中的最大值(这样重复出现导致叶子节点包含了所有数据的全集,非叶子节点中的所有值都会在叶子节点中体现出来)
叶子节点用类似链表的方式首尾相连
B+树的优点:
作为一个N叉树,高度降低了,比较的时候硬盘IO次数减少了
更适合进行范围搜索
所有的查询都是要落在叶子节点上的,所以无论查询哪个元素,中间比较的次数差不多,查询操作比较均衡
由于所有的key都会在叶子节点中体现,因此非叶子节点不必存表的真实数据(数据行),只需要把所有的数据行给放到叶子节点上即可(非叶子节点只需要存索引列的值)

非叶子节点中只存了简单的id,所以空间成本大大降低,可以在内存中缓存,提高查询速度,减少硬盘IO次数。
B+树这个结构只是针对mysql的InnoDB这个数据库引擎里面所典型使用的数据结构。(不同的数据库所使用的数据结构也是不同的)
十一、事务
11. 1事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。 在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
把多个操作打包成一个整体,要么全部都执行完,要么一个都不执行(原子性),这是事务最核心的特性。
执行出错,自动恢复成执行前的样子,这样的逆操作叫做 “回滚”(rollback)
回滚就是把执行过的操作逆向恢复回去,(数据库会记录每个操作,如果某个操作出错就会回滚)
11.2 使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
开启事务后,中间的sql不会立即就执行,而是先攒着,等commit再统一执行(保证原子性)
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;11.3 事务核心特性
- 原子性 (事务的初心)
- 一致性 事务执行前执行后都得是数据合法的状态
- 持久性(硬盘) 事务产生的修改都是会写入硬盘的,即使程序重启,事务也可以正常工作
- 隔离性 一个数据库服务器同时执行多个事务时,事务之间的“相互影响程度”
关于隔离性:
mysql服务器要同时给多个客户提供服务,此时多个客户端之间可能会同时发起事务,尤其是这多个事务在操作同一个数据库的同一张表,这个时候就会出问题。
隔离性越高,事务之间并发程度越低,执行效率越慢,数据准确性越高(算钱)
隔离性越低,事务之间并发程度越高,执行效率越快,数据准确性越低(点赞数)
11.4 脏读问题(dirty data)
事务之间完全并发,没有任何限制,就会出现脏读问题
解决办法:降低事务的并发性,提高隔离性(俗称“加锁”)
加锁:事务B写数据的时候,事务A停止读数据;事务A读数据的时候,事务B停止写数据

11.5 幻读问题
在同一个事务中两次读到的结果集不同,
解决办法:串行化,彻底舍弃并发
事务B写数据的时候,事务A停止任何操作
11.6 隔离级别
- read uncommitted:不做任何限制,事物之间随意并发执行,并发程度最高,隔离性最低,会产生脏读+幻读+不可重复读问题
- read committed:对写操作加锁,并发程度降低,隔离性提高,解决脏读问题,依旧存在幻读+不可重复读的问题
- repeatable read(默认):对写操作和读操作都加了锁,并发程度再次降低,隔离性又提高,解决脏读+不可重复读问题,可能存在幻读的问题
- serializable:严格串行化,并发程度最低,隔离性最高,可以解决脏读+幻读+不可重复读的问题















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









