






 文章介绍了如何利用Python的requests、正则表达式和多进程技术,结合开发者工具分析,实现对Scrape|Movie网站的电影信息爬取,包括列表页的HTML结构解析和详情页链接获取,以及数据的存储。
文章介绍了如何利用Python的requests、正则表达式和多进程技术,结合开发者工具分析,实现对Scrape|Movie网站的电影信息爬取,包括列表页的HTML结构解析和详情页链接获取,以及数据的存储。
1.准备工作
运行环境:
windows11操作系统
conda==4.9.2
python==3.7
依赖库版本:
requests==2.28.0
urllib3==1.26.18(安装requests时自动安装)
本案例将多进程、requests、正则表达式的基本用法串联起来,实现一个完整的网站爬虫
2.爬取目标
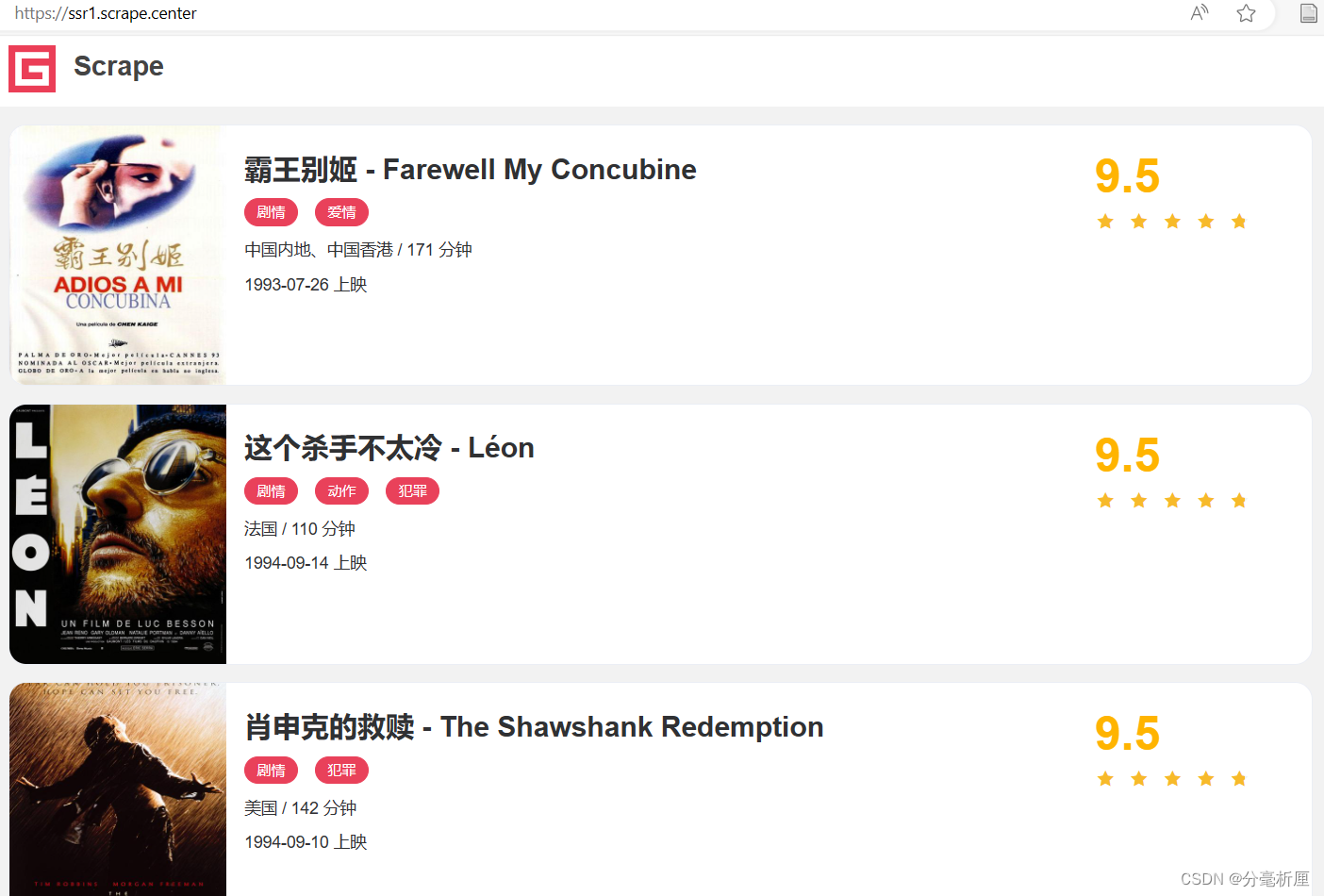
我们以一个基本的静态网站作为案例进行爬取,网站链接为Scrape | Movie,这个网站里面包含一些电影信息。如图所示
3.爬取列表页
我们首先观察一下列表页的结构和翻页规则。在浏览器中访问Scrape | Movie,然后打开浏览器开发者工具(通常情况下按F12就打开了)
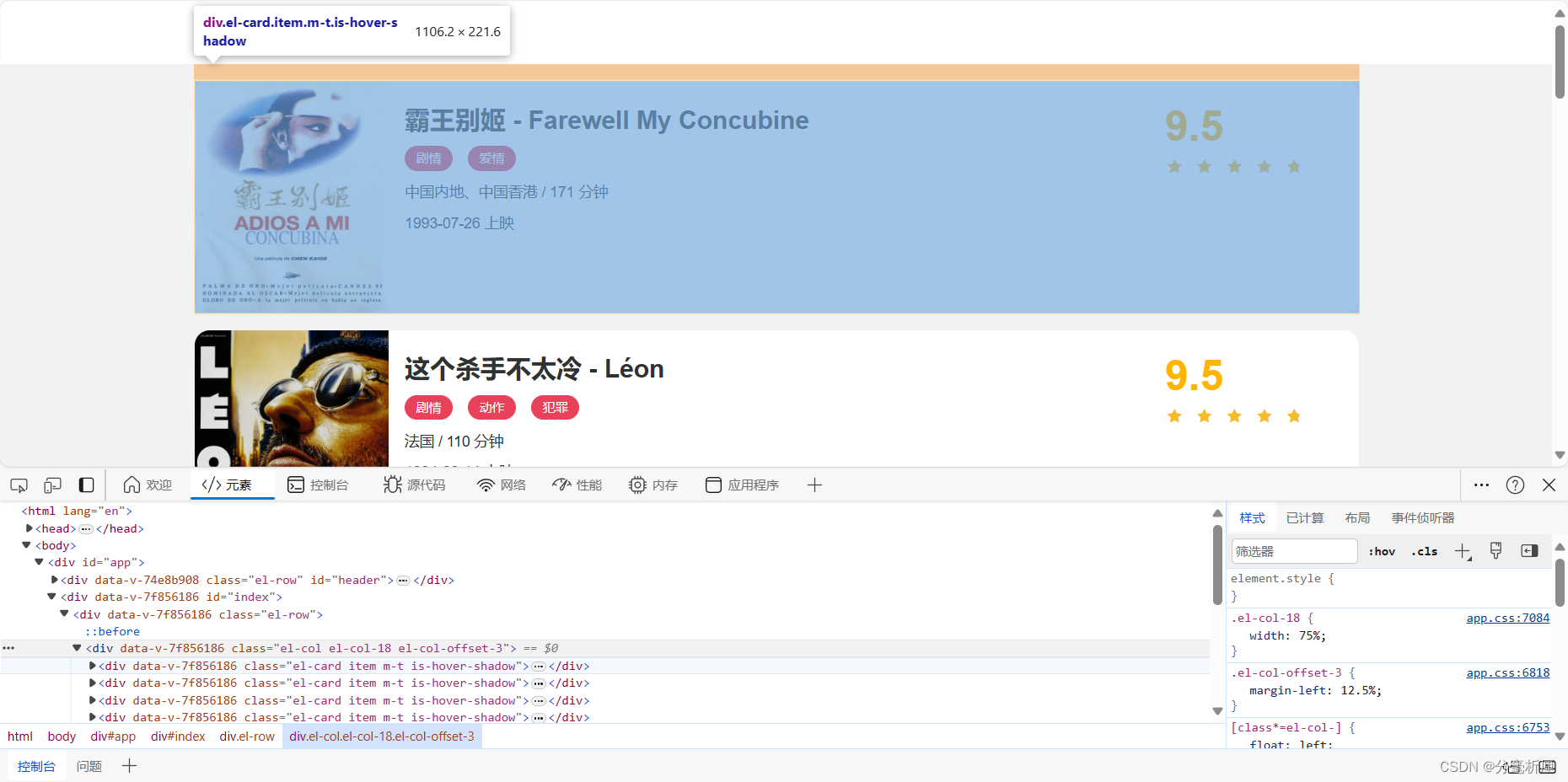
我们刊每一个电影信息区块对应的HTML以及进入到详情页的URL,可以看到每部电影对应着一个div节点,这些节点的class属性中都有el-card这个值。每个列表页有10个这样的div节点,也就对应着10部电影的信息。
接下来观察一下,如何从列表页进入详情页,当我们选中第一个电影的名称,可以看到下图。
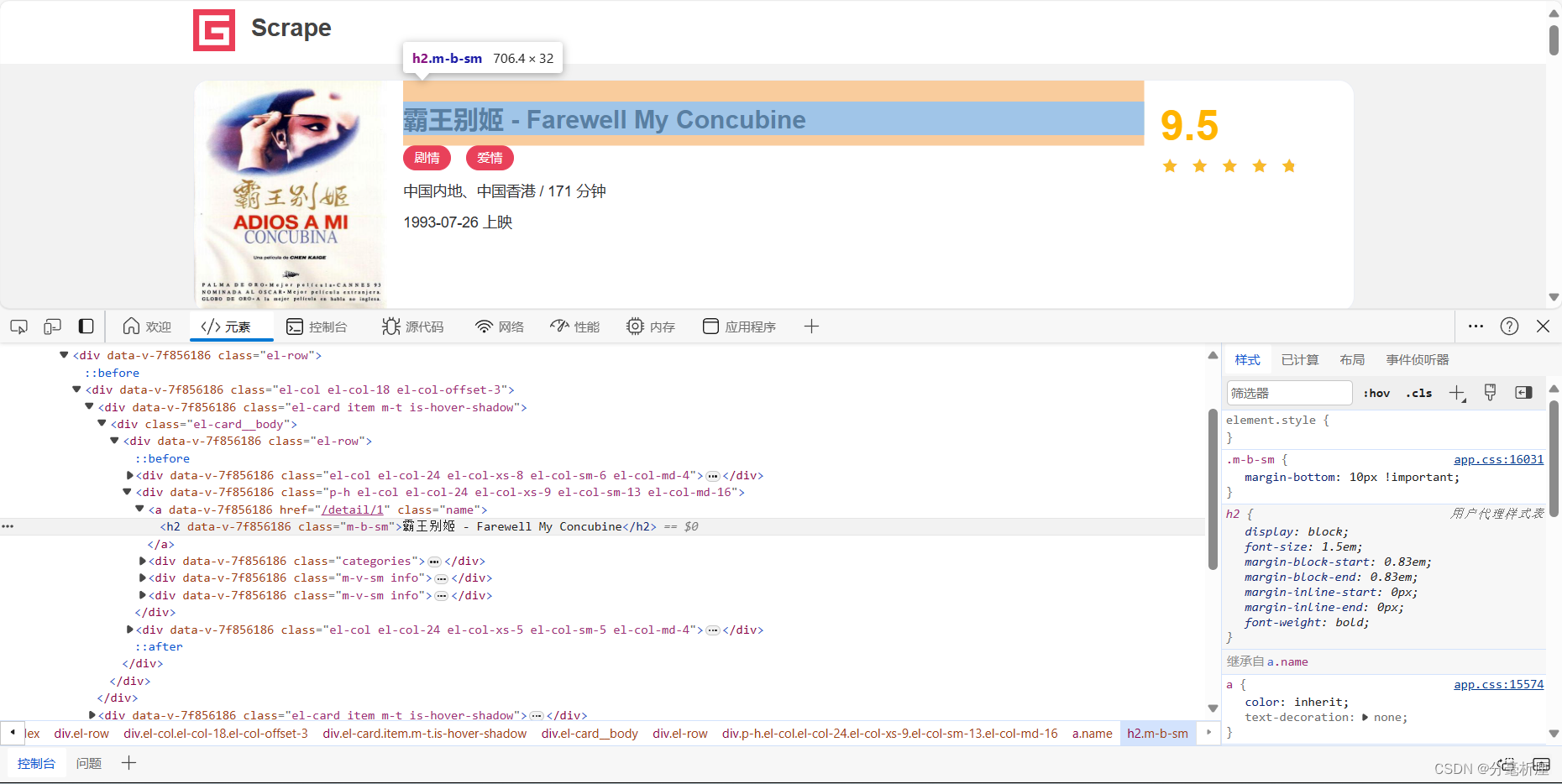
提示一下,这里在找的时候,看好蓝色区块对应的位置,然后一级一级往下展开div节点,就找到了霸王别姬-Farewell My Concubine。我们看到这个名称是一个h2节点,其内部的文字就是电影标题。h2节点的外面包含一个a节点,这个节点带有href属性,其实就是一个超链接,href的值为/detail/1,这是一个相对于网站的根URL hhtps://ss1.scrape.center/的路径,加上网站的根URL就构成了电影详情页的URL,即hhtps://ss1.scrape.center/detail/1。这样我们只需要提取这个href属性就能构造出详情页的URL并接着爬取了。
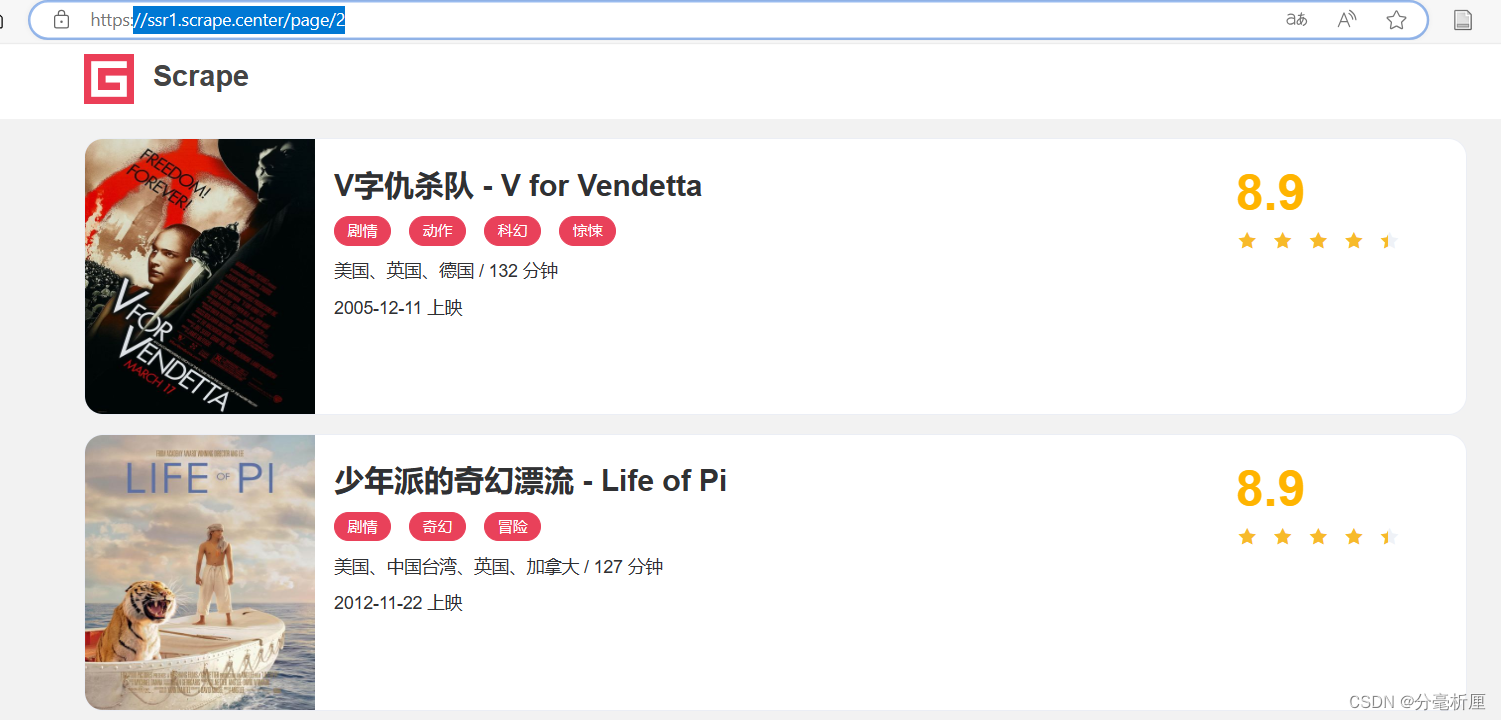
接下来分析一下翻页的逻辑,当点击最下方的第2页时,可以看到网页的URL变成了hhtps://ssr1.scrape.center/page/2,以此类推,第3页,第4页等等。
那么到这里,逻辑基本清晰了。来写代码实现一下吧。
import requests
import logging
import re
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
BASE_URL = 'https://ssr1.scrape.center'
TOTAL_PAGE = 10这里requests库用来爬取页面、loggin库用来输出信息、re库用来实现正则表达式解析、urljoin模块用来做URL的拼接。然后我们定义了日志输出级别和输出格式,以及BASE_URL为当前站点的根URL,TOTAL_PAGE为需要爬取的总页码量。
下面实现一个爬取方法
def main():
for page in range(1, TOTAL_PAGE+1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
logging.info('deta urls %s', list(detail_urls))
if __name__ == '__main__':
main()运行结果如下:
2020-03-08 22:39:50,505-INFO: get detail url https://ssr1.scrape.center/detail/1
2020-03-08 22:39:51,949。INFO: get detail url https://ssr1.scrape.center/detail/2
2020-03-08 22:39:51,950-INFO: get detail url https://ssr1.scrape;center/detail/3
2020-03-08 22:39:51,950-INFO: get detail ur1 https://ssr1.scrape.center/detail/4
2020-03-08 22:39:51,950-INFO: get detail url https://ssr1.scrape,center/detail/5
2020-03-08 22:39:51,950-INFO: get detail url https://ssr1.scrape.center/detail/6
2020-03-08 22:39:51,950.INFO: get detail url https://ssr1.scrape.center/detail/7
2020-03-08 22:39:51,950.INFO: get detail url https://ssr1.scrape.center/detail/8
2020-03-08 22:39:51,950-INFO: get detail url https://ssr1.scrape.center/detail/g
2020-03-08 22:39:51,950-INFO: get detail url https://ssr1.scrape.center/detail/10
2020-03-08 22:39:51,951-INFO: detail urls ['https://ssr1.scrape.center/detail/1',
'https://ssr1.scrape.center/detail/2',
'https://ssr1.scrape.center/detail/3',
'https://ssr1.scrape,center/detail/4',
'https://ssr1.scrape.center/detail/5',
'https://ssr1.scrape.center/detail/6',
'https://ssr1.scrape.center/detail/7',
'https://ssr1.scrape.center/detail/8',
'https://ssr1.scrape.center/detail/9',
'https://ssr1.scrape.center/detail/10']
2020-03-08 22:39:51,951-INFO: scraping https://ssr1.scrape.center/page/2...
2020-03-08 22:39:52,842-INFO: get detail url https://ssr1.scrape.center/detail/11
2020-03-08 22:39:52,842-INFO: get detail url https://ssr1.scrape.center/detail/12 4.爬取详情页
def parse_detail(html):
cover_pattern = re.compile('class="item.*?<img.*?src="(.*?)".*?'
'class="cover">',re.S)
name_pattern = re.compile('<h2.*?>(.*?)</h2>')
categories_pattern = re.compile('button.*?category.*?<span>(.*?)'
'</span>.*?</button>',re.S)
published_at_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>',
re.S)
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>',re.S)
cover = re.search(cover_pattern, html).group(1).strip() if re.\
search(cover_pattern, html) else None
name = re.search(name_pattern, html).group(1).strip() if re.\
search(name_pattern, html) else None
categories = re.findall(categories_pattern, html) if re.\
findall(categories_pattern, html) else []
published_at = re.search(published_at_pattern, html).group(1) if re. \
search(published_at_pattern, html) else None
drama = re.search(drama_pattern, html).group(1).strip() if re.\
search(drama_pattern, html) else None
score = float(re.search(score_pattern,html).group(1).strip()) if re.\
search(score_pattern, html) else None
return {
'cover': cover,
'name': name,
'categories': categories,
'published_at': published_at,
'drama': drama,
'score': score
}5.保存数据
import json
from os import makedirs
from os.path import exists
RESULT_DIR = 'results'
exists(RESULT_DIR) or makedirs(RESULT_DIR)
def save_data(data):
name = data.get('name')
data_path = f'{RESULT_DIR}/{name}.json'
json.dump(data,open(data_path,'w',encoding='utf-8'),
ensure_ascii=False,indent=2)接下来把main方法修改一下就好了,改写如下:
def main():
for page in range(1, TOTAL_PAGE+1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s', data)
logging.info('saving data to json file')
save_data(data)
logging.info('deta saved successfully')
if __name__ == '__main__':
main()然后就可以得到结果啦

喜欢的可以点个关注哦,近期会一直分享爬虫相关知识。
参考资料:《网络爬虫开发实战》

















 3441
3441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









