






问题 A: 国家排序
题目描述
有N个国家的名称,请把这些名称按照字典序从小到大排序输出。
输入
第1行一个整数n;
下面第2行到n+1行,每行一个国家名称。注意国家名称可能包括空格,比如United States
输出
n行,每行一个名称。
样例输入
2
England
China
样例输出
China
England
思路:直接用sort排好了(/懒
#include<bits/stdc++.h>
using namespace std;
const int N = 1000010;
string s[N];
int main()
{
int n;
cin >> n;
getchar();//必须回吃一个字符,否则空格会占掉s[0]
for(int i = 0; i < n; i ++ ) getline(cin, s[i]);
sort(s, s + n);
for(int i = 0; i < n; i ++ ) cout << s[i] << endl;
return 0;
}
问题 B: 进阶杨辉三角
题目描述
杨辉三角在中国南宋数学家杨辉1261年所著的《详解九章算法》一书中出现。 在欧洲,帕斯卡(1623—-1662)在1654年发现这一规律,所以这个表又叫做帕斯卡三角形。 帕斯卡的发现比杨辉要迟393年,比贾宪迟600年。
如你所知,杨辉三角是这样一个三角形,下层的每一个数都是上层相邻两个数之和。然而,粗心的小F不小心把杨辉三角打翻了,于是它变成了这样一个数组:
1 1 1 1 2 1 1 3 3 1 1 4 6 4 1 ……
小F不知道怎么恢复杨辉三角,于是来求助你,请聪明的你编写程序,求出这个数组的第k个数是多少(mod 1e9+7),数组下标从 1 开始。
输入
第一行为 t,代表有t组测试数据,t <= 10000
之后 t 行,每行一个数k,表示你要求的杨辉三角数组中第k个数,1 <= k <= 50000
输出
输出共 t 行,每行一个数,表示 杨辉三角数组中第k个数( mod 1e9+7 )
样例输入
5
1
2
3
4
5
样例输出
1
1
1
1
2
思路:将杨辉三角形用最古朴的方法算出来,然后对于每一个查询判断它在第几行第几列,直接输出,N 设置成1000,1000行总共有(1 + 1000)× 1000 / 2个数,远超k的范围,肯定够用
#include<bits/stdc++.h>
using namespace std;
const int N = 1010, mod = 1e9 + 7;
int f[N][N];
int main()
{
int t;
cin >> t;
for(int i = 0; i < N; i ++ ) f[i][0] = f[i][i] = 1;
for(int i = 2; i < N; i ++ )
for(int j = 1; j < i; j ++ )
f[i][j] = (f[i - 1][j - 1] + f[i - 1][j]) % mod;
while(t -- ){
int n;
cin >> n;
n --;
int x = 0, y = 0;
while(n > 0){
n -= (x + 1);
x ++;
}
if(n < 0){
y = x + n;
x --;
}
cout << f[x][y] << endl;
}
return 0;
}
问题 C: 年号字号
题目描述
小明用字母A对应数字1、B对应2,以此类推,用Z对应26。对于27以上的数字,小明用两位或更长位的字符串来对应。例如,AA对应27、AB对应28、AZ对应52、LQ对应329。
输入
输入一个数字N
输出
输出对应字符串。
样例输入
27
样例输出
AA
思路:就像转换成2进制数一样,转化成26进制数,再输出
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
int main()
{
LL n;
cin >> n;
stack<char> s;
while(n >= 1){
if(n % 26 == 0){
s.push('Z');
n --;
}
else{
char c = (char)('A' + n % 26 - 1);
s.push(c);
}
n /= 26;
}
while(s.size()){
cout << s.top();
s.pop();
}
return 0;
}
问题 D: 【蓝桥杯2020初赛】跑步锻炼
题目描述
小蓝每天都锻炼身体。
正常情况下,小蓝每天跑1 千米。如果某天是周一或者月初(1 日),为了激励自己,小蓝要跑2 千米。如果同时是周一或月初,小蓝也是跑2 千米。
小蓝跑步已经坚持了很长时间,从2000 年1 月1 日周六(含)到2020 年10 月1 日周四(含)。
请问这段时间小蓝总共跑步多少千米?
思路:直接模拟
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
bool runnian(int n){
if(n % 400 == 0) return true;
if(n % 100 == 0) return false;
if(n % 4 == 0) return true;
return false;
}
//1 3 5 7 8 10 12
int main()
{
int res = 0;
int y = 2000, m = 1, d = 1, zhou = 6;
while(!(y == 2020 && m == 10 && d == 1)){
if(zhou == 1 || d == 1) res += 2;
else res ++;
d ++;
zhou ++;
if(zhou > 7) zhou = 1;
if(m == 2 && d == 30 && runnian(y)){
m ++;
d = 1;
}else if(m == 2 && d == 29 && !runnian(y)){
m ++;
d = 1;
}else if((m==1 || m==3 || m==5 || m==7 || m==8 || m==10 || m==12) && d == 32){
m ++;
d = 1;
}else if((m==4 || m==6 || m==9 || m==11) && d == 31){
m ++;
d = 1;
}
if(m == 13){
y ++;
m = 1;
}
}
res += 2;//加上最后一天的
cout << res << endl;
return 0;
}
问题 F: 【蓝桥杯2020初赛】蛇形填数
题目描述
如下图所示,小明用从1 开始的正整数“蛇形”填充无限大的矩阵。

容易看出矩阵第二行第二列中的数是5。请你计算矩阵中第20 行第20 列的数是多少?
思路:别人写的基本上都是直接生成这个矩阵,然后输出f[20][20],其实没那么复杂啦。(假设斜着的为行),第i行就有i个数,前n行就有(n+1)×n/2个数,f[n][n]前面有2*n - 2 行,最后再加上n,就是f[n][n]中的值
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
int main()
{
int n = 20 + (20 - 2);
int cur = (n + 1) * n / 2;
cout << cur + 20 << endl;
return 0;
}
问题 G: 不容易系列2
题目描述
大家常常感慨,要做好一件事情真的不容易,确实,失败比成功容易多了!
做好“一件”事情尚且不易,若想永远成功而总从不失败,那更是难上加难了,就像花钱总是比挣钱容易的道理一样。
话虽这样说,我还是要告诉大家,要想失败到一定程度也是不容易的。比如,我高中的时候,就有一个神奇的女生,在英语考试的时候,竟然把40个单项选择题全部做错了!大家都学过概率论,应该知道出现这种情况的概率,所以至今我都觉得这是一件神奇的事情。如果套用一句经典的评语,我们可以这样总结:一个人做错一道选择题并不难,难的是全部做错,一个不对。
不幸的是,这种小概率事件又发生了,而且就在我们身边:
事情是这样的――HDU有个网名叫做8006的男性同学,结交网友无数,最近该同学玩起了浪漫,同时给n个网友每人写了一封信,这都没什么,要命的是,他竟然把所有的信都装错了信封!注意了,是全部装错哟!
现在的问题是:请大家帮可怜的8006同学计算一下,一共有多少种可能的错误方式呢?
输入
输入数据包含多个多个测试实例,每个测试实例占用一行,每行包含一个正整数n(2<n<=20),n表示8006的网友的人数。
输出
对于每行输入请输出可能的错误方式的数量,每个实例的输出占用一行。
样例输入
2
3
样例输出
1
2
提示
装错信封问题
这个问题是由 18 世纪初的法国数学家蒙摩提出来的。
某人给五个朋友写信,邀请他们来家中聚会。请柬和信封交由助手去处理。粗心的助手却把请柬全装错了信封。请问:助手会有多少种装错的可能呢?
瑞士数学家欧拉按一般情况给出了一个递推公式:
用A、B、C……表示写着n位友人名字的信封,a、b、c……表示n份相应的写好的信纸。把错装的总数为记作 f(n) 。假设把a错装进B里了,包含着这个错误的一切错装法分两类:
(1)b装入A里,这时每种错装的其余部分都与A、B、a、b无关,应有 f(n-2) 种错装法。
(2)b装入A、B之外的一个信封,这时的装信工作实际是把(除a之外的) 份信纸b、c……装入(除B以外的)n-1个信封A、C……,显然这时装错的方法有 f(n-1) 种。
总之在a装入B的错误之下,共有错装法 f(n-2)+f(n-1) 种。a装入C,装入D……的n-2种错误之下,同样都有 f(n-2)+f(n-1) 种错装法,因此 :
f(n)=(n-1) {f(n-1)+f(n-2)}
这是递推公式,令n=1、2、3、4、5逐个推算就能解答蒙摩的问题。
f(1)= 0, f (2)= 1, f (3)= 2, f (4)= 9, f (5)=44。
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 25;
LL f[N];
int n;
int main()
{
f[1] = 0;
f[2] = 1;
for(int i = 3; i <= 20; i ++ )
f[i] = (i - 1) * (f[i - 1] + f[i - 2]);
while(cin >> n){
cout << f[n] << endl;
}
return 0;
}
问题 H: 13-4 矩阵快速幂
题目描述
给定n*n的矩阵A,求A^k。
矩阵每个元素对1e9+7取模。
输入
第一行两个整数n,k,接下来n行,每行n个整数,第i行第j列的数表示A(i,j)。
输出
Ak,共n行,每行n个数,第i行第j列的数表示(Ak)(i,j)。
矩阵每个元素对1e9+7取模。数据考虑使用long long 类型。
样例输入
2 2
5 8
4 6
样例输出
57 88
44 68
思路:血与泪的教训,不开long long见祖宗!!
思路跟快速幂完全一样,就是把数的乘换成了矩阵的乘,快速幂参考代码:
LL qpow(int a, int b, int p){
LL res = 1 % p;
while(b){
if(b & 1) res = res * a % p;
a = (LL)a * a % p;
b >>= 1;
}
return res;
}
下面是这个题目的:
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int mod = 1e9 + 7, N = 1010;
LL A[N][N], res[N][N];
LL tmp[N][N];
LL n, b;
void MXM(LL a[][N], LL b[][N]){
memset(tmp, 0, sizeof tmp);
for(int i = 1; i <= n; i ++ )
for(int j = 1; j <= n; j ++ )
for(int k = 1; k <= n; k ++ )
tmp[i][j] = (tmp[i][j] + a[i][k] * b[k][j] % mod) % mod;
for(int i = 1; i <= n; i ++ )
for(int j = 1; j <= n; j ++ ) a[i][j] = tmp[i][j];
}
void q_M_pow(){
for(int i = 1; i <= n; i ++ ) res[i][i] = 1;
while(b){
if(b & 1) MXM(res, A);
MXM(A, A);
b >>= 1;
}
for(int i = 1; i <= n; i ++ ){
for(int j = 1; j <= n; j ++ ) printf("%lld ", res[i][j]);
printf("\n");
}
}
int main()
{
cin >> n >> b;
for(int i = 1; i <= n; i ++ )
for(int j = 1; j <= n; j ++ ) scanf("%lld", &A[i][j]);
q_M_pow();
return 0;
}
问题 I: 【蓝桥杯2020初赛】七段码
之前写过(问题E),答案就是80,时隔几个月我仍然觉得直接肉眼数更容易
问题 J: 【蓝桥杯2020初赛】平面切分
问题 K: 【蓝桥杯2020初赛】字串排序
题目描述
小蓝最近学习了一些排序算法,其中冒泡排序让他印象深刻。
在冒泡排序中,每次只能交换相邻的两个元素。
小蓝发现,如果对一个字符串中的字符排序,只允许交换相邻的两个字符,则在所有可能的排序方案中,冒泡排序的总交换次数是最少的。
例如,对于字符串lan 排序,只需要1 次交换。对于字符串qiao 排序,总共需要4 次交换。
小蓝的幸运数字是V,他想找到一个只包含小写英文字母的字符串,对这个串中的字符进行冒泡排序,正好需要V 次交换。请帮助小蓝找一个这样的字符串。
如果可能找到多个,请告诉小蓝最短的那个。
如果最短的仍然有多个,请告诉小蓝字典序最小的那个。
请注意字符串中可以包含相同的字符。
输入
输入一行包含一个整数V,为小蓝的幸运数字。
对于所有评测用例,1 ≤ V ≤ 10000。
输出
每组测试数据,输出一个字符串,为所求的答案。
样例输入
100
样例输出
jihgfeeddccbbaa
思路:每交换一次会减少一个逆序对,逆序对的数量就是总共需要的交换次数。(逆序对:直接看当前字母后面有几个比它自己小的字母)。比如ecdba需要交换的次数就是4+3+2+1=10.只有26个字母,必然有字母会重复使用,还有一个结论是字母的使用越平均越好,我也想不出什么证明来,比对一下ccbbaa,cbbbaa,ccbaaa,cccbba可知,如果不能平均分的话,多出来的添加给较小的字母。
我们反向去求每个长度的字符串最大的逆序对是多少,第一个大于等于所输入V的即为我们需要的字符串长度.长度应该不会太大,那从右到左遍历字符串,每个位置每个字母都试一下,复杂度是26len
问题 L: 【蓝桥杯2020初赛】子串分值和
题目描述
请注意:Python选手请把input()改成input().strip()
对于一个字符串S ,我们定义S 的分值f (S ) 为S 中出现的不同的字符个数。
例如f (”aba”) = 2, f (”abc”) = 3, f (”aaa”) = 1。
现在给定一个字符串S [0 : n - 1](长度为n),请你计算对于所有S 的非空子串S [i : j](0 ≤ i ≤ j < n), f (S [i:: j]) 的和是多少。
输入
输入一行包含一个由小写字母组成的字符串S 。
对于所有评测用例,1 ≤ n ≤ 100000。
输出
输出一个整数表示答案。
样例输入
ababc
样例输出
28
思路:样例模拟:
a 1
ab 2
aba 2
abab 2
ababc 3
b 1
ba 2
bab 2
babc 3
a 1
ab 2
abc 3
b 1
bc 2
c 1
按每个字母为头的不同长度子串暴力枚举会超时,但应该也是能过大部分测试点的。
计算每一个字母对于字符串的贡献值,如果这个字母没有出现过,就加上这个字母在字符串是第几个乘上所剩字符串的长度。那样例距离第一个字母a的贡献值是15=5,第二个字母b的贡献值是24=8.如果这个字母出现过,那它只对上一次出现之后的字符串有贡献,这个字母的贡献值是 上一次这个字母出现到i的长度*所剩字符串长度。比如样例的第三个字母a贡献值是
(
3
−
1
)
∗
3
=
6
(3-1) * 3=6
(3−1)∗3=6
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 100010;
LL f[30];
LL sum;
int main()
{
char s[N];
cin >> s + 1;
int n = strlen(s + 1);
for(int i = 1; i <= n; i ++ ){
sum += (i - f[s[i] - 'a']) * (n - i + 1);
f[s[i] - 'a'] = i;
}
cout << sum << endl;
return 0;
}
问题 M: 植物大战僵尸
相信你一定玩过植物大战僵尸

对,没有错,就是这款经典游戏。今天,小L重新玩了这个游戏,但是在玩的过程中突然想出一些问题想去解决。
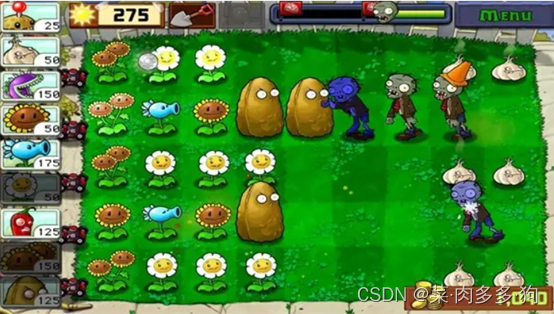
我们假设题目中的游戏跟上图一样 所有的草地大小都是5*N的尺寸
小L想知道的是在僵尸攻过来之前这些植物两两之间最大的曼哈顿距离为多少。
曼哈顿距离:两个点在标准坐标系上的绝对轴距总和。即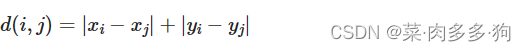
其实小T知道这个答案,便在QQ上给小L发送了总共无数遍,可是小L居然把小T开了免打扰模式,所以并没有看到问题的答案,于是请你告诉他好吗?
输入
第一行 两个数 n, m (10<=n <= 1e6,2<=m<=1e7)
接下来m行 每行两个数x,y,即这些植物所在的坐标(1<=x<=5)(1<=y<=n)
注意:虽然不会出现同一个草地方格中出现两个植物的情况,但是可能出现给出的坐标相同的情况,只需要把原来那个位置的植物铲去再种上新的即可。行列皆从1开始
输出
一个整数
最大的曼哈顿距离
样例输入
10 2
1 1
5 10
样例输出
13
思路:这个题目x只有1~5,我要找整个图上距离最远的两个点,转换成固定一个x找出最靠上和最靠下的点,距离最远的两个点一定在这10个点里(有可能不足十个)
#include<bits/stdc++.h>
using namespace std;
int up[6], down[6]; //x 1~5 对应的最大y和最小y
int main()
{
int n, m;
cin >> n >> m;
memset(down, 0x3f, sizeof down);
while(m -- ){
int x, y;
scanf("%d%d", &x, &y);
up[x] = max(up[x], y);
down[x] = min(down[x], y);
}
int ma = 0;
for(int i = 1; i <= 5; i ++ ){
if(up[i] == 0) continue;
for(int j = 1; j <= 5; j ++ ){
if(down[j] == 0x3f3f3f3f) continue;
ma = max(abs(i - j) + abs(up[i] - down[j]), ma);
}
}
cout << ma << endl;
return 0;
}
问题 N: Mondriaan’s Dream
题目描述
正方形和矩形让著名的荷兰画家皮特·蒙德里安着迷。一天晚上,在完成他的“厕所系列”中的图纸后(他必须用卫生纸画画,因为他所有的纸都充满了正方形和矩形),他梦想着用宽度为2和高度为1的小矩形填充一个大矩形以不同的方式。

作为这种材料的专家,他一眼就看到他需要一台计算机来计算填充尺寸为整数值的大矩形的方法的数量。帮助他,让他的梦想不会变成噩梦!
输入
输入包含多个测试用例。每个测试用例由两个整数组成:大矩形的高度 h 和宽度 w。输入由 h=w=0 终止。否则,1<=h,w<=11。
输出
对于每个测试用例,输出给定矩形可以用大小为 2 乘以 1 的小矩形填充的不同方式的数量。假设给定的大矩形是定向的,即多次计算对称平铺。
样例输入
1 2
1 3
1 4
2 2
2 3
2 4
2 11
4 11
0 0
样例输出
1
0
1
2
3
5
144
51205
思路:很重要的思想就是,把一个方向的方格怎么摆确定了,另一个方向也就跟着确定了。假设我们枚举的是横着放的方格。每一列一共有n行,也就是2^n的方案数,我们用二进制数去枚举,1表示放,0表示不放。f(i,j)表示摆放第i列,i-1列伸出来横着的方格状态为j的方案数。需要保证前面一列伸过来的和这一列伸出去的不能有重叠的,也就是不能在同一行连续放两个横着的方格,其次要保证我留出来的空格一定要能被竖着的方格放(连续的空格必须是偶数的)

#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 12, M = 1 << N;
int n, m;
LL f[N][M];
vector<int> state[M];
bool st[M];
int main()
{
while(cin >> n >> m, n || m){
memset(f, 0, sizeof f);
//先筛一遍把本身这个方案一定不合法的删去
//没有连续的偶数空位
for(int i = 0; i < 1 << n; i ++ ){
int cnt = 0;//计录连续 0的个数
bool valid = true;
for(int j = 0; j < n; j ++ )
if(i >> j & 1){//如果这一位上是1
if(cnt & 1){//如果这个1前面有连续个奇数0
valid = false;
break;
}
cnt = 0;
}else cnt ++;
//最后判断一下尾部是否有连续个奇数 0
if(cnt & 1) valid = false;
st[i] = valid;
}
for(int i = 0; i < 1 << n; i ++ ){
state[i].clear();
for(int j = 0; j < 1 << n; j ++ )
if(!(i & j) && st[i | j]) state[i].push_back(j);
//i & j等于0,保证我这列伸出的方块和上一列伸出的方块不能有重叠的
//st咱上一个循环算的,保证有连续个偶数个空位能够让竖着的方块放
//i | j,则表示我上一列伸出的方块在这一列也占位置,只有这两列都没有横着小方块的情况的st
}
f[0][0] = 1;
for(int i = 1; i <= m; i ++ )
for(int j = 0; j < 1 << n; j ++ )
//f(i,j):摆放第i列,i-1列伸出来横着的方格状态为j的方案数,j为一个二进制数,范围是0~行数位数的二进制范围
for(auto k : state[j]) f[i][j] += f[i - 1][k];
cout << f[m][0] << endl;
}
return 0;
}
问题 P: 没有上司的舞会
Ural 大学有 N名职员,编号为 1∼N。
他们的关系就像一棵以校长为根的树,父节点就是子节点的直接上司。
每个职员有一个快乐指数,用整数 Hi给出,其中 1≤i≤N。
现在要召开一场周年庆宴会,不过,没有职员愿意和直接上司一起参会。
在满足这个条件的前提下,主办方希望邀请一部分职员参会,使得所有参会职员的快乐指数总和最大,求这个最大值。
输入格式
第一行一个整数 N。
接下来 N行,第 i行表示 i号职员的快乐指数 Hi。
接下来 N−1行,每行输入一对整数 L,K,表示 K是 L 的直接上司。
输出格式
输出最大的快乐指数。
输入样例:
7
1
1
1
1
1
1
1
1 3
2 3
6 4
7 4
4 5
3 5
输出样例:
5
思路:树形dp最经典的一道题了,懒得写了,应该随便搜一下叙述的都比我清楚。
#include <bits/stdc++.h>
using namespace std;
const int N = 6010;
bool has_father[N];
int e[N], ne[N], h[N], idx;
int n, f[N][2];
int happy[N];
void add(int a, int b ){
e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}
void dfs(int u)
{
f[u][1] += happy[u];
for(int i = h[u]; ~i; i = ne[i]){
int v = e[i];
dfs(v);
f[u][1] += f[v][0];
f[u][0] += max(f[v][0], f[v][1]);
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i ++ ) cin >> happy[i];
memset(h, -1, sizeof h);
for(int i = 0; i < n - 1; i ++ ){
int a, b;
scanf("%d%d", &a, &b);
has_father[a] = true;
add(b, a);
}
int root = 1;
while(has_father[root]) root ++;
dfs(root);
cout << max(f[root][0], f[root][1]) << endl;
system("pause");
return 0;
}
问题 Q: 走廊泼水节
题目描述
给定一棵N个节点的树,要求增加若干条边,把这棵树扩充为完全图,并满足图的唯一最小生成树仍然是这棵树。
求增加的边的权值总和最小是多少。
输入
第一行包含整数t,表示共有t组测试数据。
对于每组测试数据,第一行包含整数N。
接下来N-1行,每行三个整数X,Y,Z,表示X节点与Y节点之间存在一条边,长度为Z。
输出
每组数据输出一个整数,表示权值总和最小值。
每个结果占一行。
样例输入
2
3
1 2 2
1 3 3
4
1 2 3
2 3 4
3 4 5
样例输出
4
17
提示
N≤6000,Z≤100
思路:其实刚那道题还挺懵的,怎么不给我权让我算最小权hhh。这道题主要考的是并查集的操作和对最小生成树概念的理解。题意是给你一个唯一的最小生成树,由于是唯一的,那我在生成最小生成树的时候(也就是不断合并两个集合的时候),每次都只有唯一的最小的一条边可选,也就是说我现在要加的边的长度 最小也得是他给的最小生成树的长度+1才可以。那为了保证我所加的边最小,我先从最小生成树边最小的开始合并集合(每次合并集合相当于把两个集合的每个边相互连线,要连xy条,再减去自己最小生成树已有的,就是xy - 1条)。
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 6010;
//p记录的是当前节点的父亲节点
int p[N], sz[N]; //size,用于记录集合包含的点数,用size会有重名
int n;
struct edge{
int a, b, w;
bool operator< (const edge &t) const{
return w < t.w;
}
}e[N];
//寻找祖宗节点
int find(int x){
if(p[x] != x) p[x] = find(p[x]); //找的同时路径压缩了,很妙的代码
return p[x];
}
int main()
{
int t;
cin >> t;
while(t -- ){
int n;
cin >> n;
for(int i = 0; i < n - 1; i ++ ){
int a, b, w;
cin >> a >> b >> w;
e[i] = {a, b, w};
}
sort(e, e + n - 1);
//初始化每个点自己为一个集合,每个集合大小都是1
for(int i = 1; i <= n; i ++ ) p[i] = i, sz[i] = 1;
LL res = 0;
for(int i = 0; i < n - 1; i ++ ){
int a = find(e[i].a), b = find(e[i].b);
if(a != b){
res += (sz[a] * sz[b] - 1) * (e[i].w + 1);
p[a] = b; //讲a集合插入b集合,b为根
sz[b] += sz[a];//b集合的大小再加上原先a的
}
}
cout << res << endl;
}
return 0;
}
















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











