







目录
📢数据库基础操作命令📢
✍显示数据库
show databases;
注意这里的 database 是复数形式,需要 + s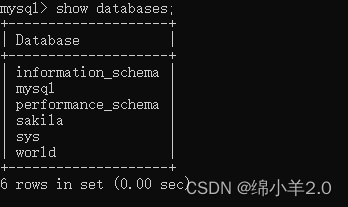
✍创建数据库
create database if not exists da_name 数据库名称
(可选) character set charset_name 字符集名称
(可选) collate collation_name; 排序规则名称
if not exists - 如果不存在
此命令代表着如果不存在这个名称的数据库就会执行创建此库
当然后面俩行指定字符集和指定排序规则可以不用写, 如果在 MySQL 中创建数据库时不指定字符集和排序规则,MySQL 将使用默认的字符集和排序规则。在 MySQL 8.0 中,默认字符集为 utf8mb4,默认排序规则为 utf8mb4_0900_ai_ci。
字符集为何物?
排序规则又为何物?
在 MySQL 中,字符集是一组字符编码和排序规则,用于确定如何存储和比较字符串数据
可能有人听说过 utf8 这个字符集,相对于 utf8mb4 字符集来说utf8 字符集只支持最多 3 个字节的 Unicode 字符,而 utf8mb4 字符集支持最多 4 个字节的 Unicode 字符。也就意味着 utf8mb4 字符集可以更好地支持 Emoji 和其他特殊字符 .
排序规则是指用于比较和排序字符串的规则。它们通常与字符集相关联,因为不同的字符集可能具有不同的排序规则。例如上方的的 utf8mb4_general_c 表示不区分大小写的通用排序规则,意味着大小写是一样的字符.
✍删除数据库
drop database if exists db_name;
- if exists: 如果存在 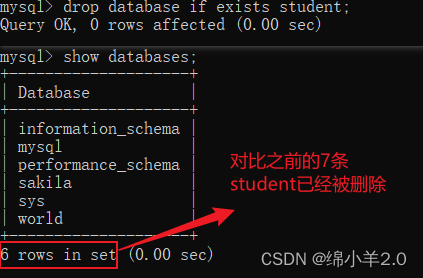
✍使用数据库
use db_name;

📢表的基础操作命令📢
✍创建表
create table tb_name (
field1 datatype comment '注释',
field2 datatype,
field3 datatype
);
- tb_name: 表名
- field: 表结构中定义的字段
- datatype: 数据类型
comment 这个可以不加,这只是 sql 用来注释的意思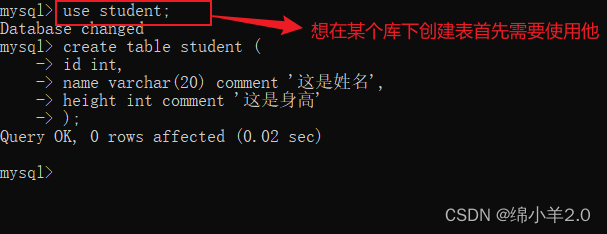
✍查看表
desc tb_name; 
show full columns from student;
✍删除表
drop [temporary] table[if exists] tbl_name [, tbl_name]...
- temporary:指定要删除的表是临时表。
- if exists:指定如果表不存在,则不会引发错误。删除一个表或多个表
单个表时
drop table tb_name;
多个表时
drop table tb1_name, tb2_name, tb3_name;删除一个临时表时
drop temporary table tb_name;📢表的增删查改📢
✍新增
insert into tb_name (column,column,column...) values
(value_list),
(value_list);
- column: 列名
- value_list: 插入的数据集单行数据 + 全列插入

多行数据 + 指定列插入
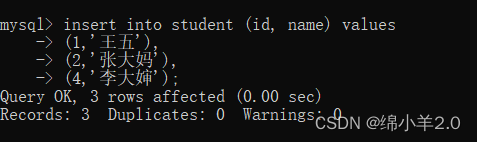

✍查询
select
[distinct] { * | {column [, column] ...}
[from table_name]
[where...]
[order by column [ASC | DESC], ...]
limit ...
- distinct: 去重
- order by: 排序
- where: 条件查询
- limit: 分页查询全列查询
select * from tb_name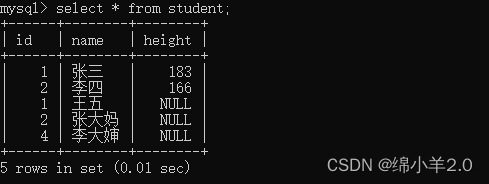
指定列查询
select column1, column2, column3... from tb_name;
查询字段为表达式
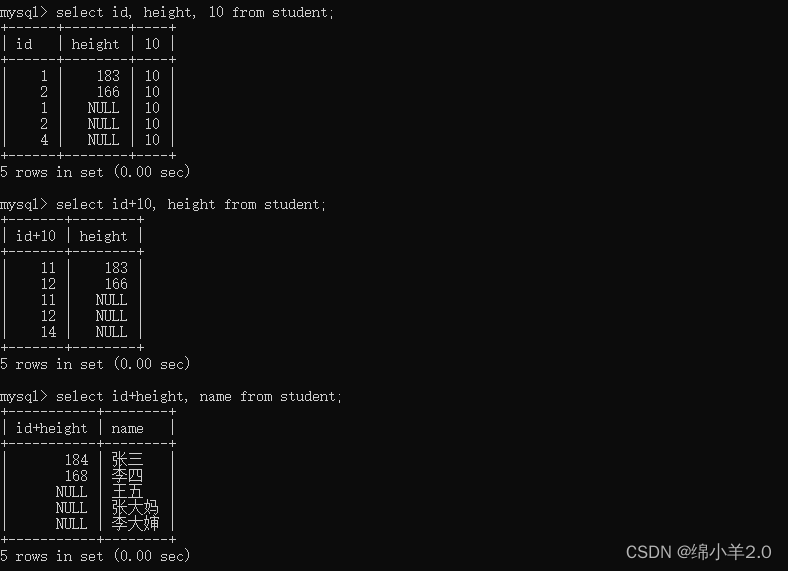
注意这里的查询字段表达式并不会修改表中原本的数值
别名 as
有时候我们的表达式比较复杂,查询的结果看起来也很复杂,我们就可以用 as 别名的方式重命名

去重 distinct
先将表中数值修改一下
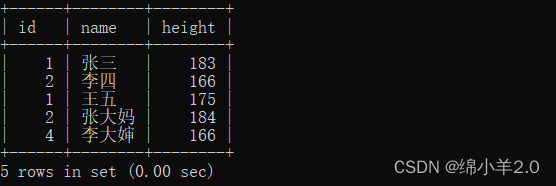
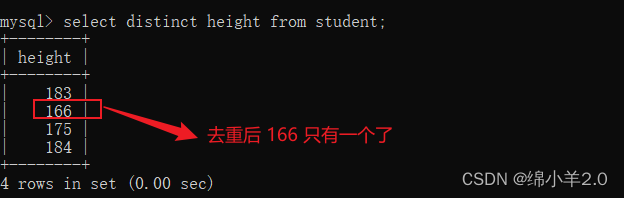
排序 order by
select column1,column2... from tb_name
order by colmun [asc | desc];
- asc: 升序
- desc: 降序
- 默认为 asc 升序 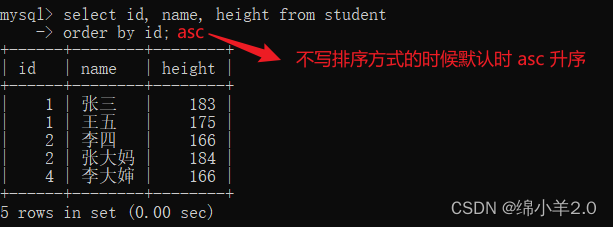
注意一下, 这里的 desc 和之前的查看表结构的 desc 是俩种意思
在 SQL 中 DESC 在 DESC 排序中的含义。在 SQL 中,DESC 是 DESCENDING 的缩写,表示按降序排序。
另一方面,DESC 在 DESC table_name 命令中的含义是 DESCRIBE,用于显示表的结构信息,包括列名、数据类型、键信息和注释。

排序也可以使用表达式以及别名排序
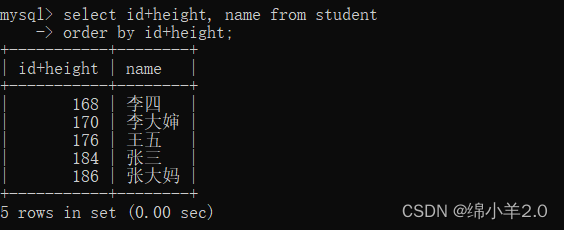
注意使用别名排序时,在order by 的后面需要写上原始的列名或者表达式, 因为该子句在查询处理期间执行,而别名在查询结果生成后才可用。因此,需要在 ORDER BY 子句中使用原始列名或表达式。

条件查询 where
这里的 where 和我们用的 java c 里面的是一样的用法,简单介绍几个特殊的.
- where between a0 and a1: 在 [a0,a1] 这个区间内返回 true(1),注意这里是左闭右闭区间
- where in(): 这里和上述差不多,如果是 () 中的任意一个即返回 true(1),也可以使用子查询作为 IN() 函数的参数。
例如,以下查询将选择 my_table 表中 id 列的值在 other_table 表中出现的所有行:
select * from my_table where id in (select id from other_table);- like: like运算符用于在查询中匹配模式。该运算符接受两个参数:一个是要匹配的字符串,另一个是包含模式的字符串。模式可以包含通配符,例如 % 表示任意字符序列,_ 表示任意单个字符
选择 my_table 表中 name 列以字母 J 开头的所有行
select * from my_table where name like 'J%';选择 my_table 表中 name 列以字母 J 开头和以字母 n 结尾的所有行
select * from my_table where name like 'J%n';选择 my_table 表中 name 列包含字母 ohn 的所有行
select * from my_table where name like '%ohn%'选择 my_table 表中 name 列以字母 J 开头和以字母 n 结尾,中间只有一个字符的所有行
select * from my_table where name like 'J_n';- and: 与 java 中 && 同理 (与)
- or: 与 java 中 || 同理 (或)
分页查询 limit
- 从 0 行开始筛选 n 条结果
select ... from tb_name [where...] [order by...] limit n;
- 从 s 行开始筛选 n 条结果
select ... from tb_name [where...] [order by...] limit s,n;
- 从 s 行开始筛选 n 条结果: 此种用法最好,更直观
select ... from tb_name [where...] [order by...] limit n, offset s;- 以身高排序,将表分成三页,每页俩条数据,数据不足不影响结果
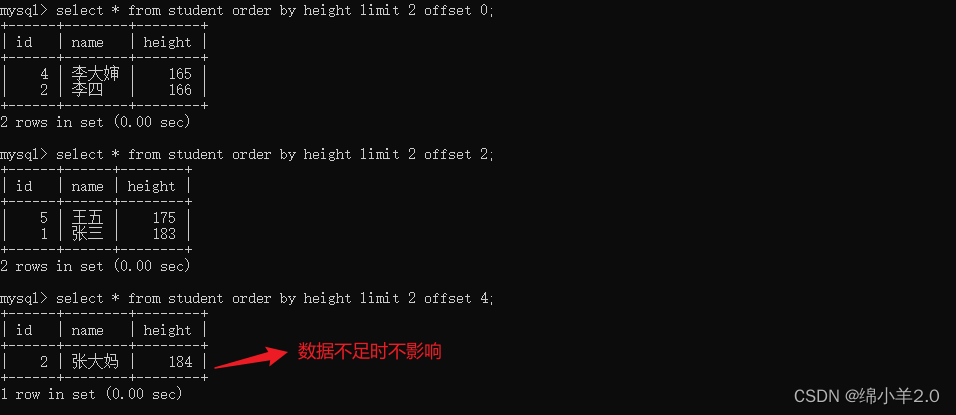
✍ 聚合查询
聚合查询是一种用于计算和汇总数据的查询。它们通常使用聚合函数(如 SUM、AVG、COUNT 等)来计算数据的总和、平均值、计数等。聚合查询通常与 GROUP BY 子句一起使用,以便按照特定的列对数据进行分组。
常见函数有:
| count() | 返回查询到的数据的数量 |
| sum() | 返回查询到的数据的总和, 不是数字没有意义 |
| avg() | 返回查询到的数据的平均值, 不是数字没有意义 |
| max() | 返回查询到的数据的最大值, 不是数字没有意义 |
| min() | 返回查询到的数据的最小值, 不是数字没有意义 |
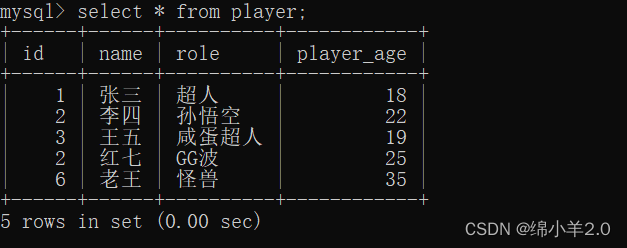
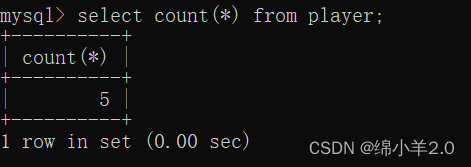
- count() : 查询有几个玩家
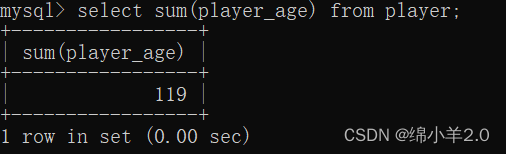
- sum() : 查询所有玩家的年龄总和
group by
GROUP BY 子句可以对指定列进行分组查询.
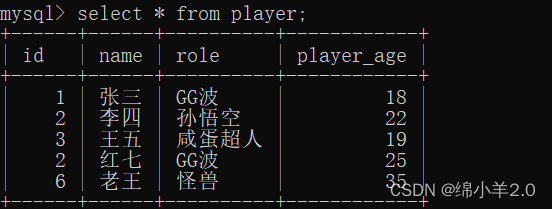
我们将表中数据修改一下
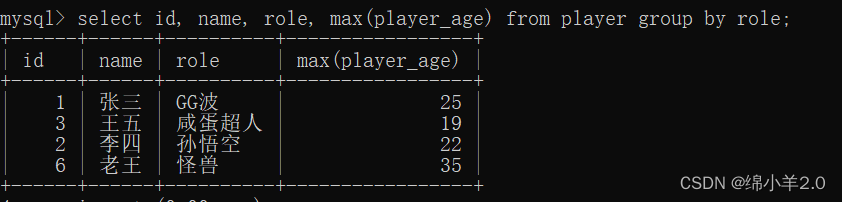
- 求出相同角色下年龄最大的玩家 (对 role 列进行分组)
- 如果此时你还想在进行一次筛选过滤时,不能使用 where 语句, 需要使用 having : 上述条件中在筛选出年龄大于20的角色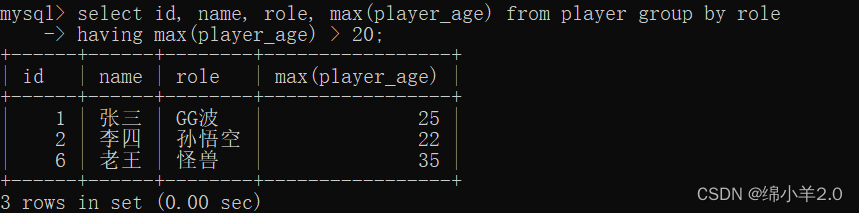
✍联合查询
- 语法1:
select column1, column2... from table1
(inner, left, right)join table2 on 条件表达式1 and 条件表达式2
- 语法2: 不可使用与外连接
select column1, column2... from table1, table2, where 条件表达式1 and 条件表达式2
- inner: 内链接
- left,right: 外连接(左右)实际开发中数据来自不同的表,而对多表进行查询就需要使用到联合查询,联合查询是一种将两个或多个 SELECT 语句的结果组合成一个结果集的方法。如果你需要从多个表中检索数据,并且这些表之间没有直接的关联关系,那么使用联合查询是一个不错的选择。
联合查询的原理是对多张表取 笛卡尔积.
- 笛卡尔积: 笛卡尔积是指两个集合中的每个元素都与另一个集合中的每个元素组合成一个有序对的集合。换句话说,如果集合A有m个元素,集合B有n个元素,则它们的笛卡尔积就是一个包含mn个有序对的集合。
例如: 现有一个集合 A(1, 2, 3), 集合B(a, b, c),它们俩的笛卡尔积就是 [(1, a), (1, b), (1, c), (2, a), (2, b), (2, c), (3, a), (3, b), (3, c)]
内连接
表1:
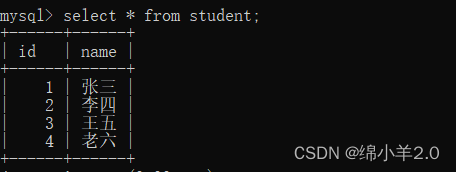
表二:
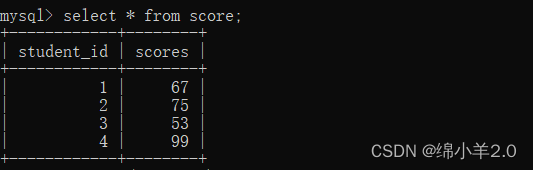
它们的笛卡尔积就是:
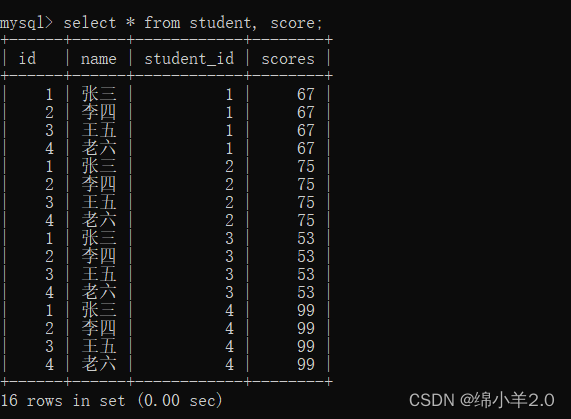
我们筛选出 id 和 student_id 一样的得出学生的成绩表

在内连接中,inner 是可以省略掉的, 如果没有指定 join 类型,MySQL 将默认使用 inner join, 这种行为可能会因 MySQL 版本而异,因此最好在使用 JOIN 时始终指定 JOIN 类型,以避免出现意外行为。
外连接
外连接分左右连接
左外连接返回左表中的所有行以及右表中匹配行的交集,同时还包括左表中没有匹配的行。
右外连接返回右表中的所有行以及左表中匹配行的交集,同时还包括右表中没有匹配的行。
例如我修改老六的 id 为5后进行内连接和外连接


自连接
自连接就是将自己和自己做笛卡尔积, 目的是为了对相同行之间做条件比较
例如下表:
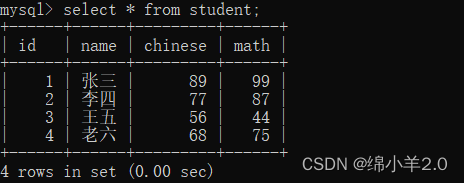
如果我想要筛选出数学分数比语文分数高的同学会发现如果不使用自连接将无法进行比较,因为 mysql 不支持同一行操作,这时候就需要用到自连接.
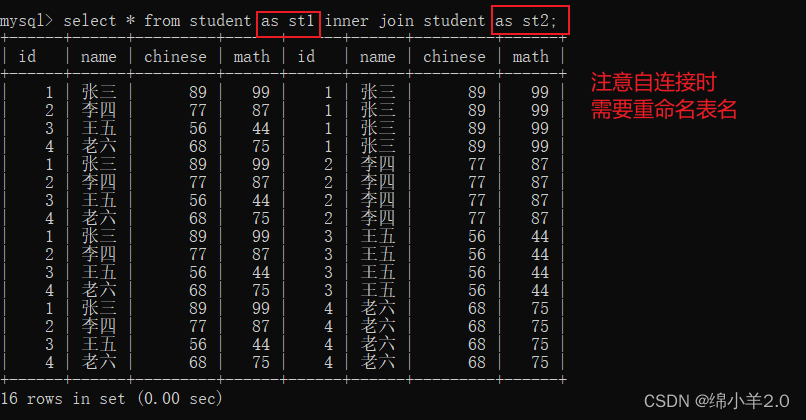
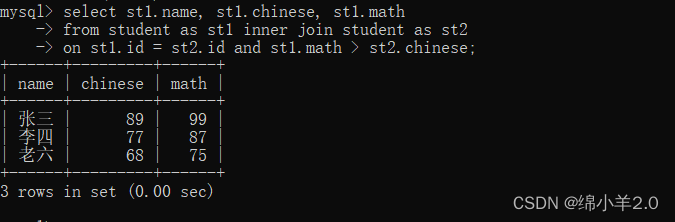
再进行条件判断
✍子查询
子查询是一个查询语句,它嵌套在另一个查询语句中。子查询可以用于从一个表中选择数据,并将其作为另一个查询的条件或结果。
例如
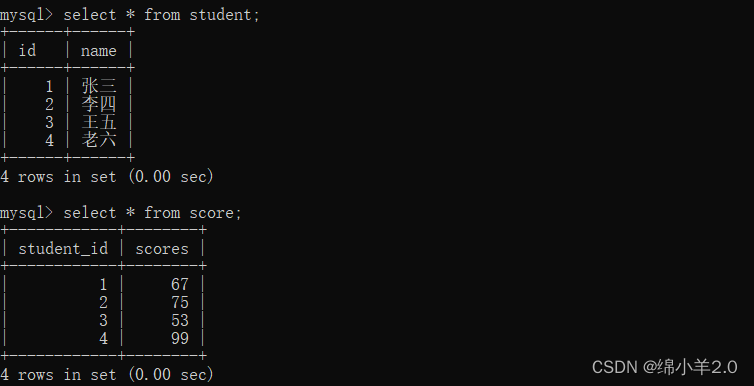
上图中我们想要查询到李四的成绩需要俩步: 1.查找到张三的id 2.查找到对应 id 的成绩

子查询可以在第二条语句中进行嵌套一条语句从而一步实现: 缺点是嵌套一旦过多代码不易阅读

✍合并查询
合并查询是指使用 union 或者 unionall 运算符进行合并多个 select 语句的结果集,他和 or 相似, 但是 union 可以对多表的语句进行操作, 而 or 只能对单表的语句进行操作.
例如我想要查询 student 表中 id 为1或者 score表中 student_id 为 2的结果
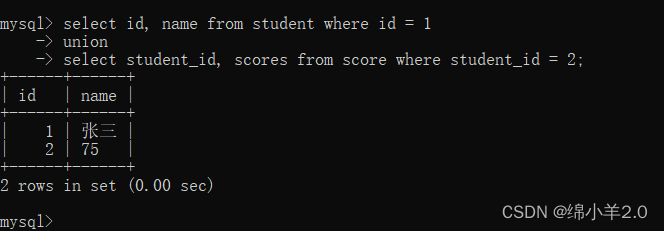
union all 和 union 的区别是 union 会对结果进行去重, 而 union all 不会对结果进行去重
✍修改
update tb_name set column = new value [,column2 = new value]
[where...] [order by...] [limit]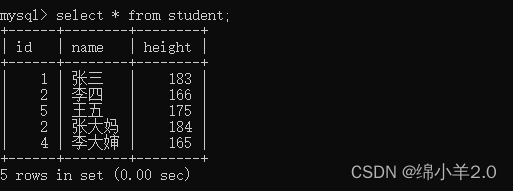
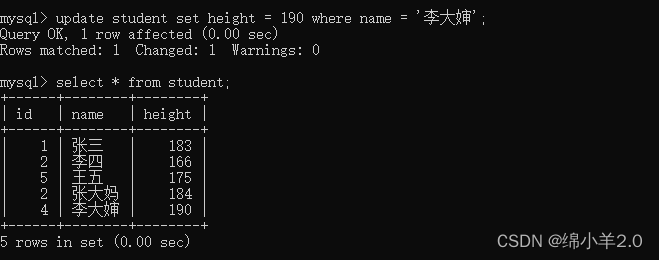
- 单列修改: 将李大婶的身高修改为190
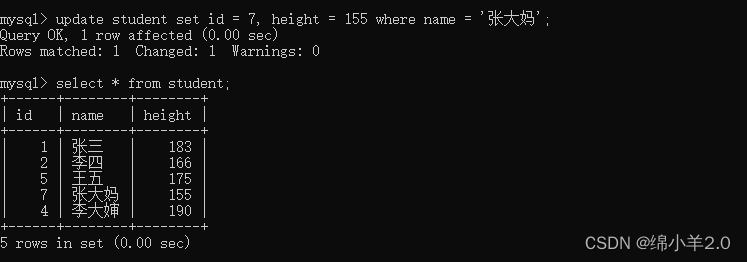
- 多列修改: 将张大妈的身高修改为 155 并且 id 为 7
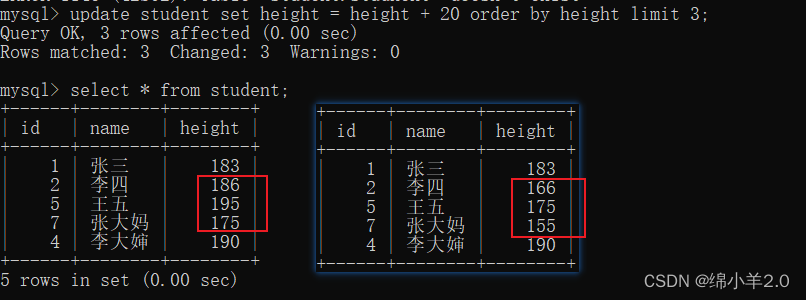
- 将身高倒数前三名的身高 + 20
✍alter 修改表结构
- 修改列
alter table table_name
change column old_column_name new_column_name column_definiton
- 添加列
alter table table_name
add column column_name column_definition;
- table_name: 表名
- column_name: 列名
- old_column_name: 旧的列名
- new_column_name: 新的列名
- column_definition: 列定义
在下列表中添加新列 age


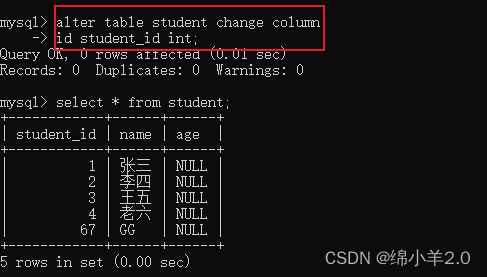
修改 id 列为 student_id
✍删除
delete from tb_name
[where ...]
[order by ...]
[limit ...];- 单条数据删除: 删除王五的数据

- 全部删除
delete from student;本文就到这里了,如有不足请指出
















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









