







一、题目描述

二、题解
方法一
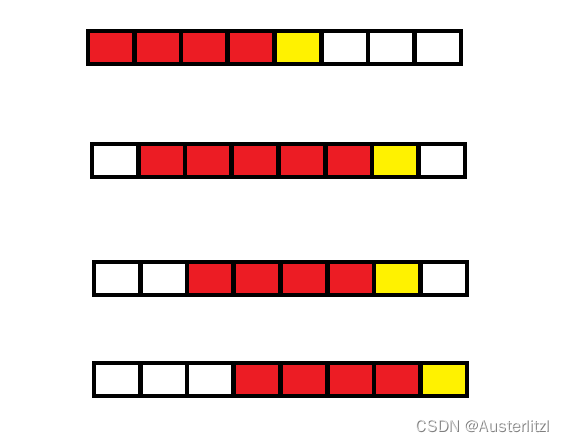
最常规的办法,无疑就是按顺序 把每一个字符作为子串的首字符,比过去看当前子串有没有重复的字符。如下图,一个空格代表一个字符,红色部分代表无重复子串,黄色空格代表该字符和前面红色无重复子串中的某个字符相同(不一定是首字符)。
但是,这样是否太麻烦了呢?每次都要一个一个比过去,算法复杂度太高。这时我不禁想到,这里的找无重复子串和模式串匹配有类似之处。上文的思路就类似于BF算法,暴力破解,那么在这里能不能想到一个类似于KMP算法的较优解呢?
方法二
核心思路
我们知道,KMP算法主要涉及到指针回溯的问题,模式串指针并不是每次都回到最开始的位置。如下图,以重复的两个 'd' 之前 的字符为无重复子串首字符的时候,每次的无重复子串长度都递减,直到无重复子串的首字符为第一个 'd' 后面的字符时,才有可能不递减。那么,无重复子串逐次递减的过程,毫无疑问是浪费时间的,所以这里不如把指针直接回溯到 无重复子串内部 (红色背景) 和 正在比较的字符 (黄色背景) 相同的字符的后一位。
在下图中形象地表现为:step1找到重复的字符之后,直接跳到step5,从 'i' 位置开始寻找新的无重复子串。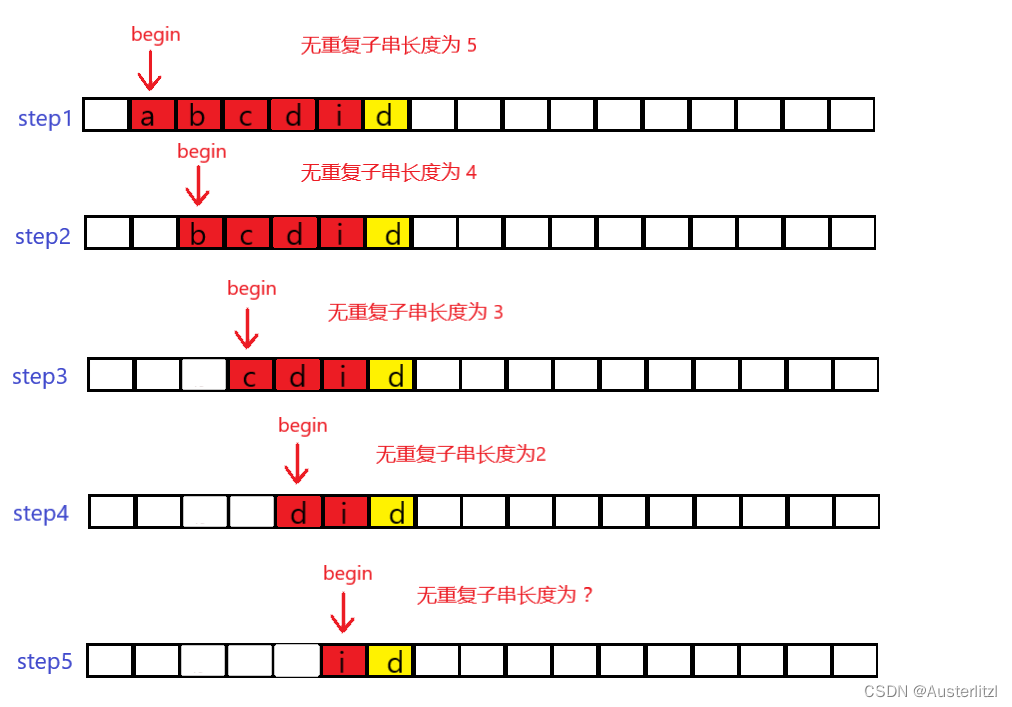
具体实现
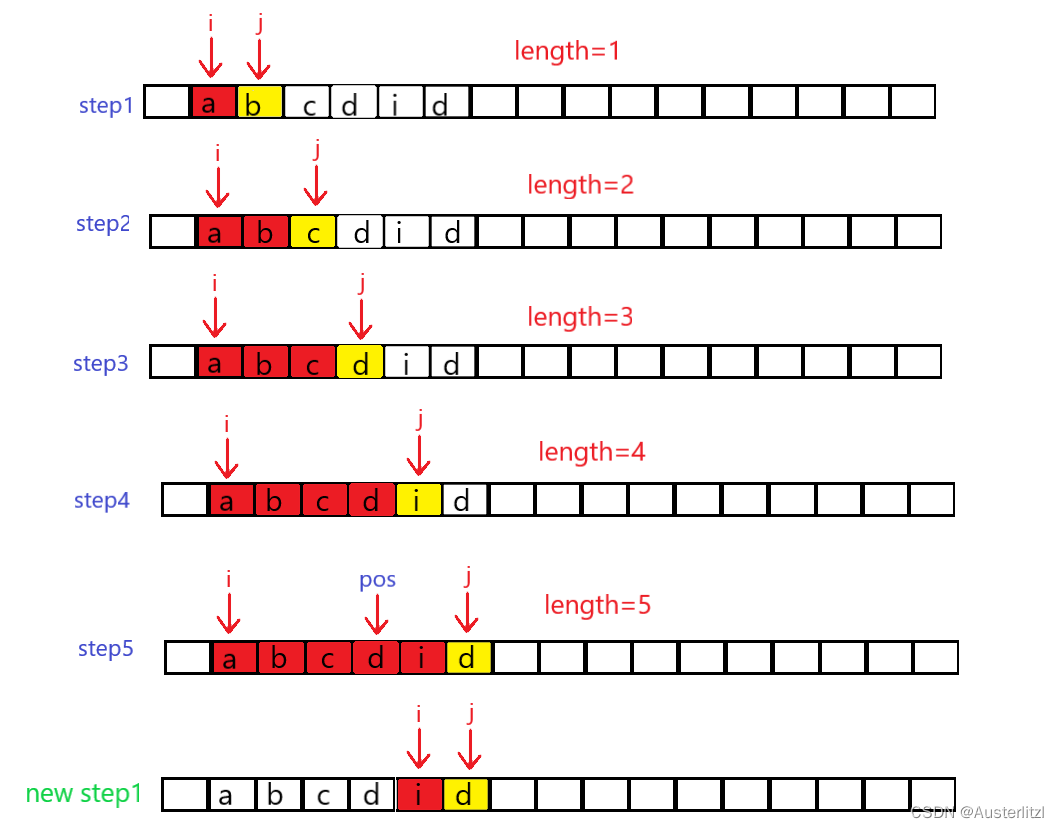
寻找一个无重复子串的过程大体如下:
length表示当前无重复子串的长度。i 表示当前的无重复子串起始字符的位置,j 表示正在比较的字符的位置,如果在当前无重复子串内部没有和 j 位置的字符相等的,那么 j 位置的字符也算进当前无重复子串内部,length+1。然后 j+1,重复上述过程。直到如step5中,在无重复子串中发现了和 j 位置的字符相同的字符,那么用pos 标记无重复子串中该字符的位置。然后开始新一轮的查找无重复子串。
同时,如果 当前无重复子串起始字符 到 整个字符串末尾的长度,小于已经得到的无重复子串最大长度lengthMax,那么再寻找也找不出长度大于lengthMax的无重复子串,直接跳出查找过程即可。
代码
int lengthOfLongestSubstring(char * s){
int len=strlen(s);
int lengthMax=0;//最长长度
for(int i=0;i<len;i++)//从第i个开始往后寻找子串
{
int length=1;//当前长度
int flag=0;//判断有无重复,假设无
int pos=0;//存储 无重复子串 中,和 当前比较字符 重复的字符 的位置
for(int j=i+1;j<len;j++) // 当前比较的字符
{
for(int k=i;k<j;k++) // 无重复子串内的字符 和 当前字符 比较的过程
{
if(s[j] == s[k])
{
flag=1;//有重复,k下标和j下标的两个字符重复了
pos=k;
break;
}
}
if(flag == 0 )
{
length++;
}
else{
i=pos;//因为i=pos之后,循环还会+1,所以实际上是i=pos+1
break;
}
}
if(lengthMax<length)
{
lengthMax=length;
}
//再次开始的位置到最后位置如果比目前读出的最长字串短,没必要继续
if(len-i <lengthMax)
break;
}
return lengthMax;
}















 4939
4939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











