







一、Redis的持久化
1.1 RDB
RDB全称Redis Database Backup file (Redis数据备份文件), 也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
-
快照文件称为RDB文件,默认是保存在当前运行目录。
- 执行命令:
# 先连接redis redis-cli # 保存(方式1) save # 保存(方式2) bgsave- 方式1:我们知道redis是单线程的,并且磁盘的IO是很慢的,由Redis主进程来执行RDB,会阻塞所有命令。
- 方式2:所以我们推荐
bgsave,开启子进程执行RDB,避免主进程受到影响
-
redis默认会在关闭之前对数据做一次持久化,在运行的目录下。如果在备份的时候redis突然宕机,那么数据就丢失了,这显然不是我们想要的,我们希望隔一段时间备份一次
- Redis内部有触发RDB的机制,可以在redis.conf文件中找到, 格式如下:
# 900秒内,如果至少有1个key被修改,则执行bgsave,如果是save ""则表示禁用RDB save 900 1 save 300 10 save 60 10000- RDB的其它配置也可以在redis.conf文件中设置:
# 是否压缩, 建议不开启,压缩也会消耗cpu,磁盘的话不值钱 rdbcompression yes # RDB文件名称 dbfilename dump.rdb #文件保存的路径目录 dir ./ -
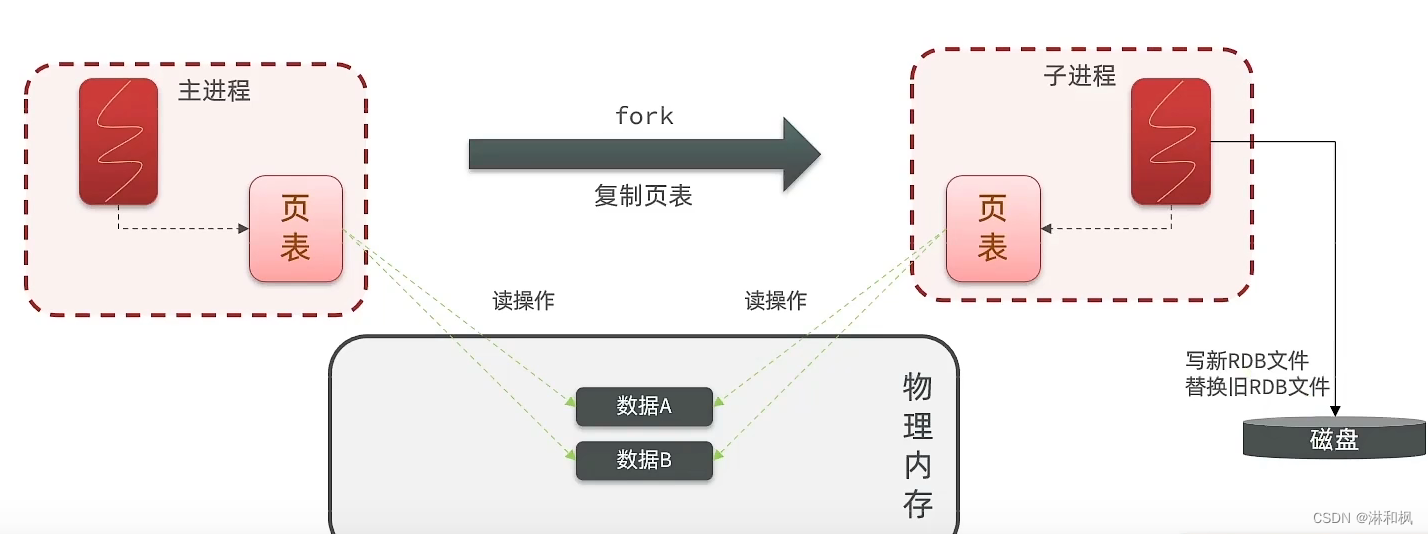
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。执行流程如下:
- 进程是无法直接操作内存的,都是由操作系统给每个进程分配一个虚拟内存。操作系统会维护虚拟内存和物理内存之间的映射关系,就是图中的页表。
- 所以我们执行fork,不是将内存数据做拷贝,而是拷贝一个页表。因为页表一样,所以会映射到一样的物理内存区域。所以我们无需拷贝所以数据,速度就会更快
- 但是,因为这个过程是异步的,子进程在写入磁盘的过程中,主进程仍然可以接收用户请求去写数据。这时候就会导致脏数据,那怎么解决这个问题呢?
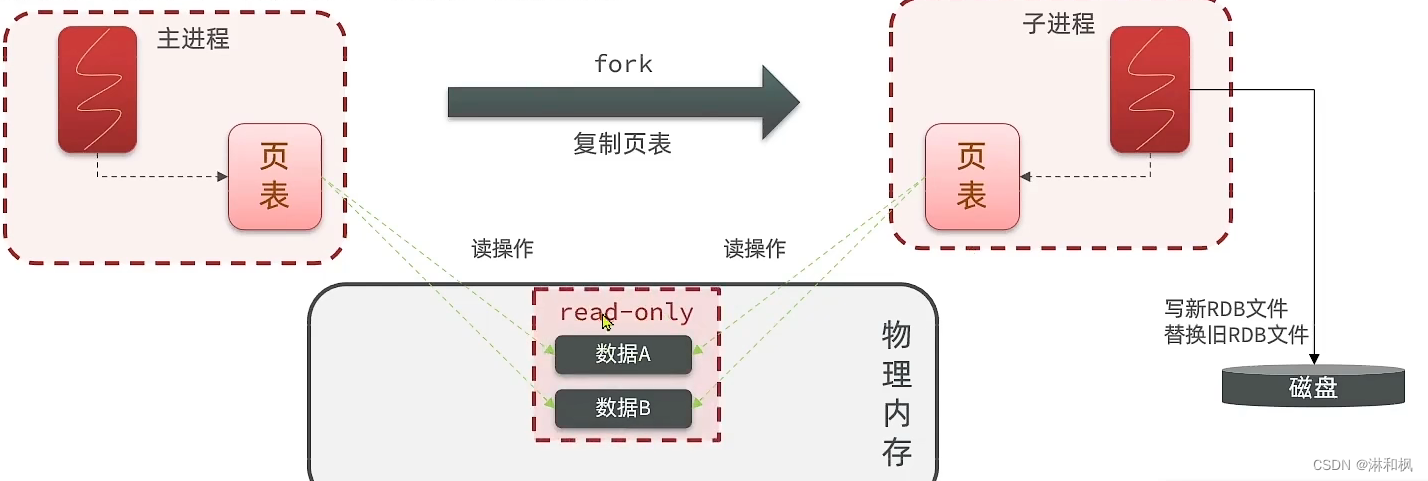
- fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存
- 当主进程执行写操作时,则会拷贝-份数据,执行写操作。
- 此时这个共享内存被标记为只读模式
- fork采用的是copy-on-write技术:
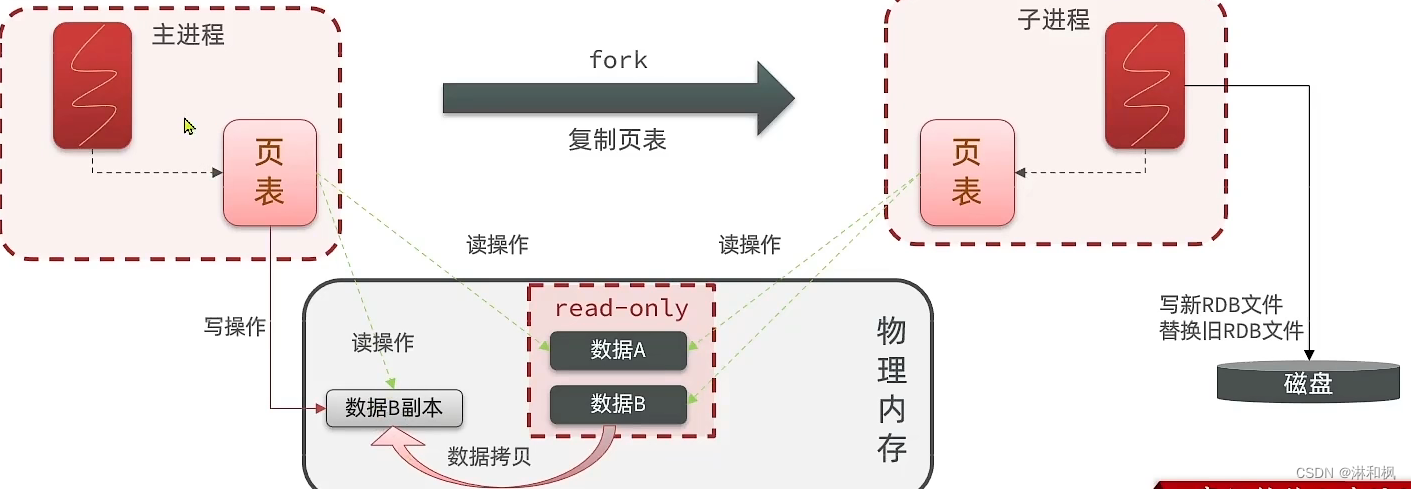
- 那如果用户真的发了一个写的请求怎么办呢?
- 那么read-only部分就会拷贝一份数据,主进程负责在这个副本里面进行读写操作,如下图:
1.2 AOF
AOF全称为Append Only File (追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。默认
关闭
- AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes
#AOF文件的名称
appendfilename "appendonly.aof"
- AOF的命令记录的频率也可以通过redis.conf文件来配:
#表示每执行一次写命令,立即记录到AOF文件
appendfsync always
#写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
#写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
- 启用AOF之前要禁用RDB:
# 在这个地方写入 save ""
# save 900 1
# save 300 10
# save 60 10000
save ""
- 因为是记录命令, AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
set num 123
set name jack ----------bgrewriteaof--------> mset name jack num 666
set num 666
- Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
1.3 RDB与AOF对比
- RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定时对整个内存做快照 | 记录每一次执行的命令 |
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
二、Redis主从
2.1 搭建主从架构
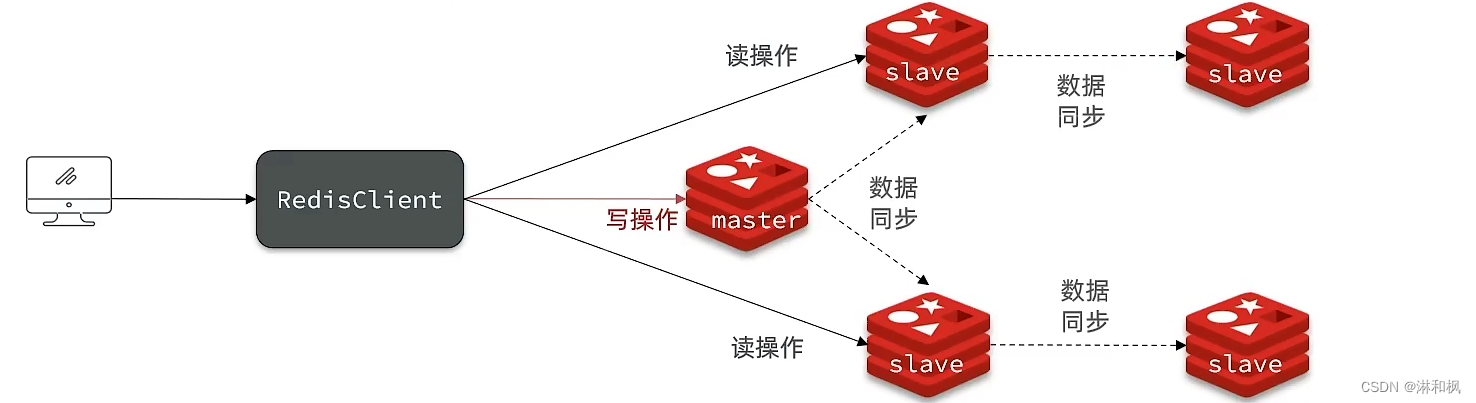
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
-
为什么redis要采用主从集群呢,而不是传统的负载均衡集群?
- 因为redis大部分场景都是读多写少,主节点主要复制写操作,而从节点就负责读操作。
-
下面就开始实操吧!
# 首先我们先建立三个目录
mkdir 7001 7002 7003
- 然后我们需要三个配置文件,我们先把redis的配置文件恢复到原来的状态,就是手动改回来,修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式, AOF保持关闭状态。
- 然后将redis- 6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目 录执行下列命令):
#方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
#方式二:管道组合命令,一键拷贝
echo 7001 7002 7003| xargs -t -n 1 cp redis-6.2.4/redis.conf
- 修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003, 将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
# sed 修改7001/redis.conf,s代表替换,将6379替换为7001,/g代表全局;后面也一样,将dir .替换为: dir /tem/7001
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/ 7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/ 7002\//g' 7001/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/ 7003\//g' 7001/redis.conf
- 虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
# redis 实例的声明IP
replica-announce-ip 192.168.150.101
- 每个目录都要改,我们一键完成修改(在/tmp目 录执行下列命令) :
# 1a表示在第一行后面追加一行
sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf
# 或者一键修改
printf '%s\n' 7001 7002 7003| xargs -I{} -t sed -i '1a replica-announce-ip
192. 168.150.101' {}/redis.conf
- 然后我们就可以开启多个窗口去分别启动这三个redis了
# 首先切换到tmp目录,或者写全路径也行,然后分别启动
redis-server 7001/redis.conf
-
但是目前他们是独立的redis,并没有主从联系,要配置主从可以使用replicaof或者slaveof (5.0以前) 命令。
-
有临时和永久两种模式:
-
修改配置文件(永久生效):
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服務,执行slaveof命令 (重启后失效):
-
# slaveof <masterip> <masterport> 如下 SLAVEOF 192.168.150.101 7001 # 如果的当前客户端连接的是7002,表示7002要成为7001的slave # 要指定客户端启动可以使用命令 redis-cli -p 7002
-
-
-
注意:在5.0以后新增命令replicaof,与salveof效果一致。
-
怎么查看集群信息呢?
INFO replication
- 此时在7001上set,在其从节点上可以get到,而且从节点不能set操作,天然实现了读写分离。
2.2 数据同步原理
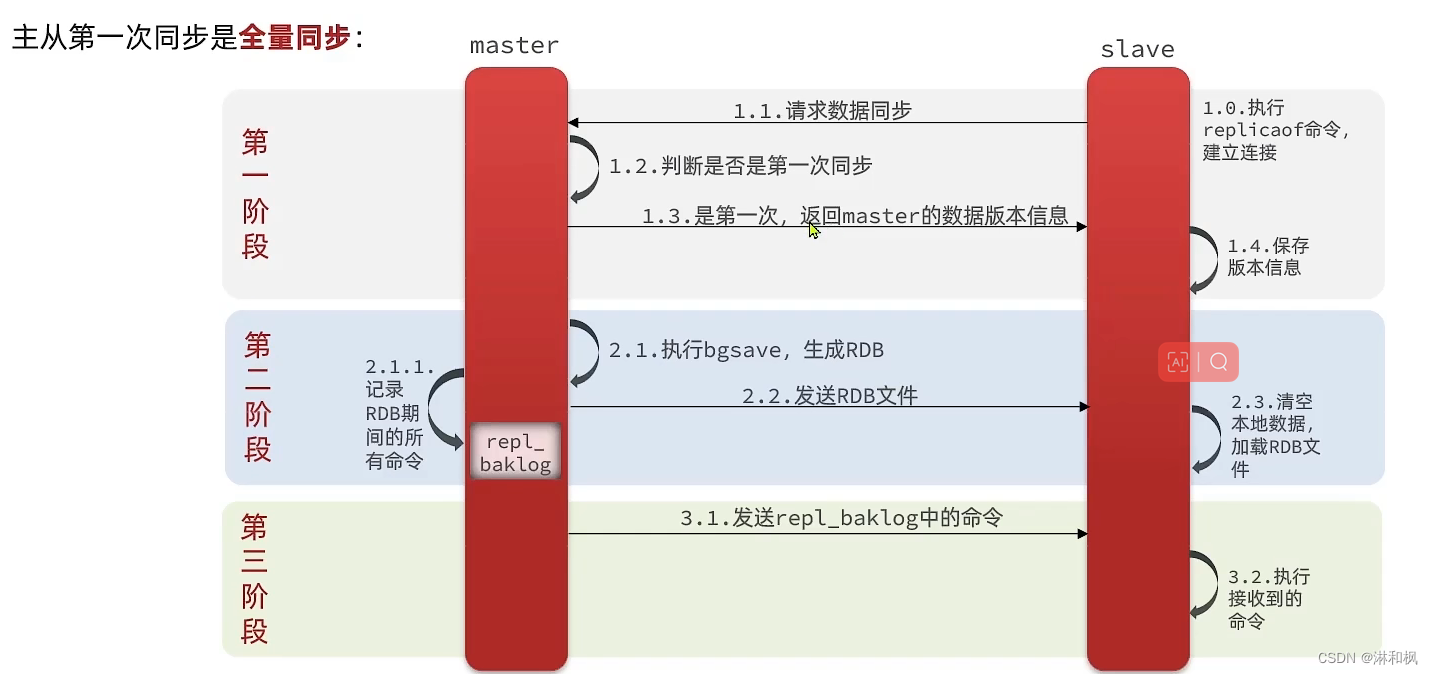
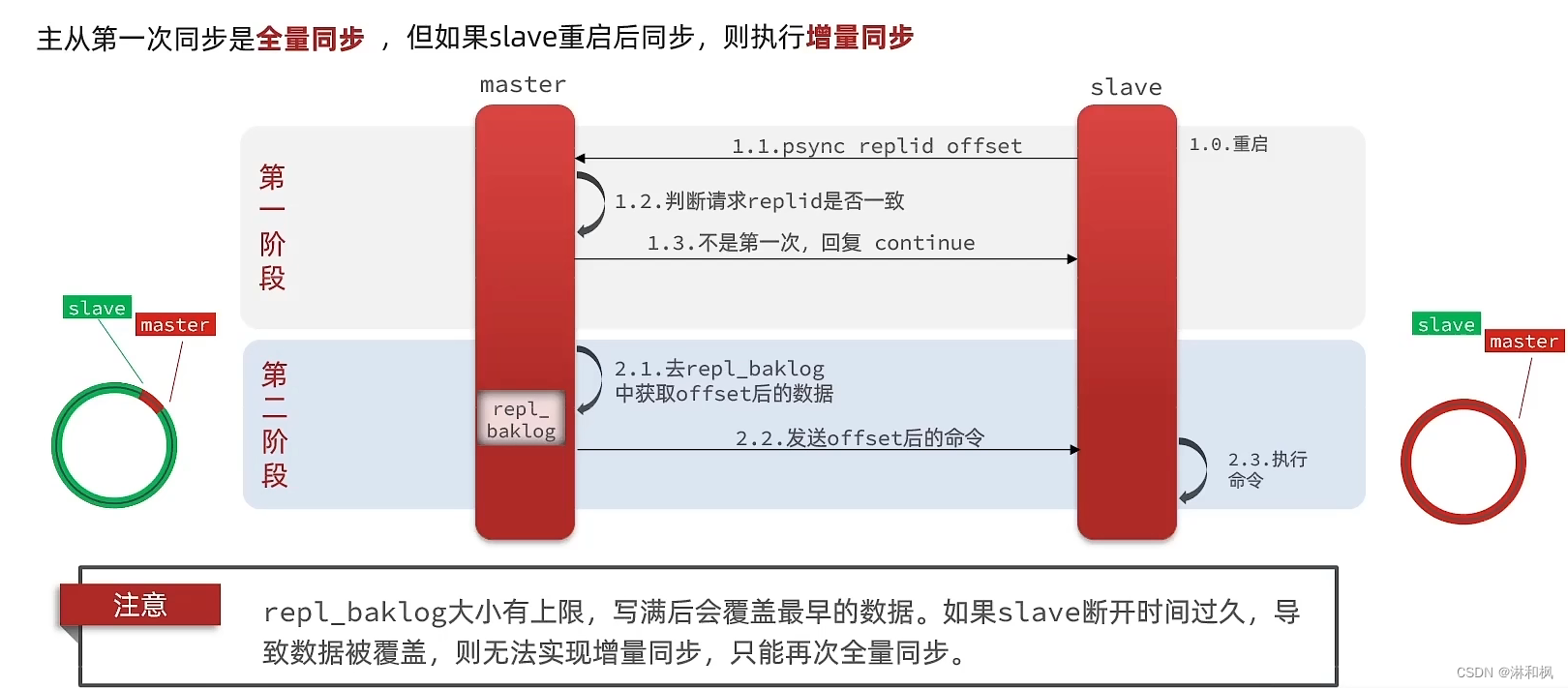
- 主从第一次同步是全量同步:
-
master如何判断slave是不是第一 次来同步数据?这里会用到两个很重要的概念:
- Replication Id:简称replid, 是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl baklog中 的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
-
因此slave做数据同步,必须向master声明自己的replication id和offset, master才可以判断到底需要同步哪些数据
-
后面就是增量同步:
-
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl baklog的大小, 发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master.上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力,如下图:
三、Redis哨兵
3.1 哨兵的作用和原理
slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?
3.1.1 哨兵的作用
-
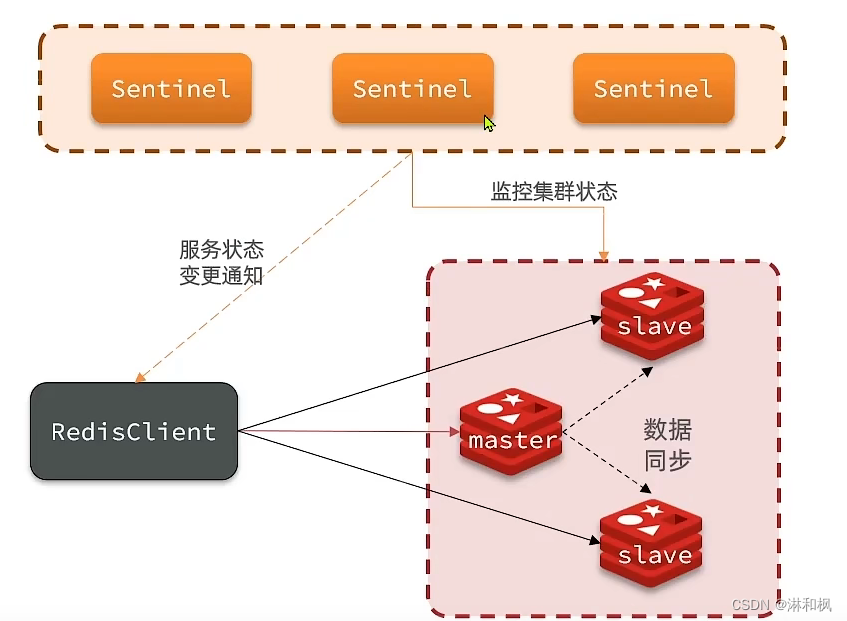
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下:
-
监控: Sentinel 会不断检查您的master和slave是否按预期工作
-
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也
以新的master为主. -
通知: Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送
给Redis的客户端
-
- 那么哨兵是怎么得知集群中每个节点的状态呢?
3.1.2 服务状态监控
- Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
3.1.3 选举新的master
- 一旦发 现master故障, sentinel需 要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
3.1.4 如何实现故障转移
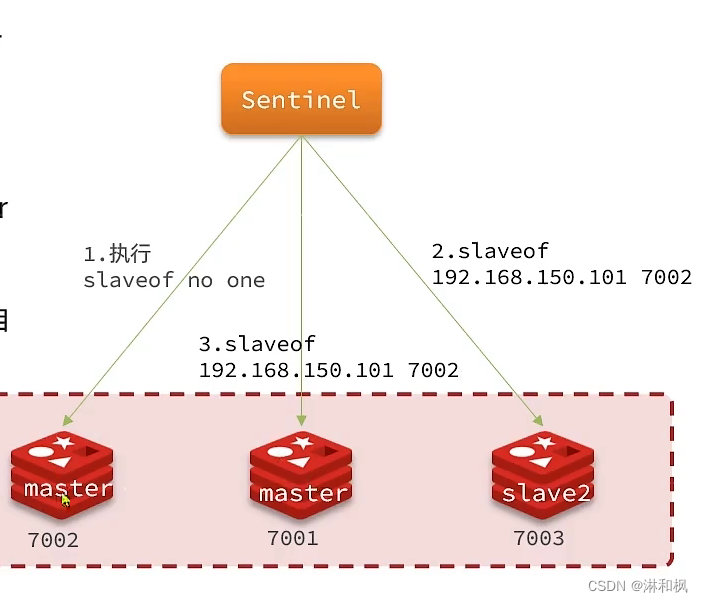
- 当选中了其中一个slave为新的master后(例如slave1),故障的转移的步骤如下:
- sentinel给备选的slave 1节点发送slaveof no one命令,让该节点成为master
- sentinel给所有其它slave发送slaveof 192.168.150.101 7002命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
3.2 搭建哨兵集群
- 要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
- 我们创建三个文件夹,名字分别叫s1、s2、s3:
mkdir s1 s2 s3
- 然后我们在s1目录创建一个sentinel.conf文件, 添加下面的内容:
# 端口,s2要改成27002,s3为27003
port 27001
# 声明ip
sentinel announce-ip 192.168.150.101
# 声明监控 mymaster为集群/主节点名称,2为选举master的quorum
sentinel monitor mymaster 192.168.150.101:7001 2
# 超时时间
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
# 工作目录
dir "/tmp/s1'
- 然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目 录执行下列命令)
#方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
#方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
- 修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e' "s/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e' "s/s1/s3/g' s3/sentinel.conf
- 然后分别启动
redis-sentinel s1/sentinel.conf
redis-sentinel s2/sentinel.conf
redis-sentinel s3/sentinel.conf
3.3 RedisTemplate的哨兵模式
-
在Sentinel集群监管下的Redis主从集群, 其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
-
在pom文件中引入redis的starter依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 然后在配置文件application.yml中指定sentinel相关信息:
spring:
redis:
sentinel :
master: mymaster #指定master名称
nodes: #指定redis-sentinel集群信息
-192.168.150.101 :27001
-192.168.150.101 :27002
-192.168.150.101 :27003
- 配置主从读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer(){
return configBuilder -> configBuilder.readFrom(ReadFrom. REPLICA_PREFERRED);
}
- 这里的ReadFrom是配置Redis的读取策略,是一-个枚举,包括:下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED: 优先从master节点读取,master不可用才读取replica
- REPLICA:从slave (replica) 节点读取
- REPLICA_PREFERRED: 优先从slave (replica) 节点读取,所有的slave都不可用才读取master
四、Redis分片集群
4.1 搭建分片集群
4.1.1 分片集群结构
-
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
-
使用分片集群可以解决.上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
-
开始搭建,删除之前的7001、7002、 7003这几个目录,重新创建出7001、7002、 7003、 8001、 8002、 8003目录:
#进入/tmp目录
cd /tmp
#删除旧的,避免配置干扰
rm -rf 7001 7002 7003
#创建目录
mkdir 7001 7002 7003 8001 8002 8003
- 在/tmp下准备一个新的redis.eonf文件,内容如下:
port 6379
#开启集群功能
cluster-enabled yes
#集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
#点心跳失败的超时时间
cluster-node-timeout 5000
#持款化文件存放目录
dir /tmp/6379
#绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
#注册的实例ip
replica-announce-ip 192.168.150.101
#保护模式
protected-mode no
#数据库数量
databases 1
#日志
logfile /tmp/6379/run.log
- 将这个文件拷贝到每个目录下:
#进入/tmp目录
cd /tmp
#执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
- 修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
# 进入tmp目录
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
- 因为已经配置了后台启动模式,所以可以直接启动服务:
# -键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
# 通过ps查看状态
ps -ef | grep redis
- 如果要关闭所有进程,可以执行命令:
ps -ef | grep redis awk '{print $2}' | xargs kill
# 或者(推荐这种方式)
printf '%s\n' 7001 7002 7003 8001 8002 8003| xargs -I{} -t redis-cli-p {} shutdown
4.1.2 创建集群
- Redis5.0以后,集群管理以及集成到了redis-cli中,格式如下:
# redis-cli --cluste create创建集群
# --cluster-replicas 集群副本数量
# 1 代表主从比例1:1,所以前三个为主,后三个为从
redis-cli --cluste create --cluster-replicas 1 192.168.150.101:7001
192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002
192.168.150.101:8003
- 通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes
4.2 散列插槽
-
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上, 查看集群信息时就能看到
-
数据key不是与节点绑定,而是与插槽绑定。redis会 根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}“, 且”{}"中至少包含1个字符, "{}"中的部分是有效部分
- key中不包含"{}",整个key都是有效部分
-
例如: key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。 计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是siot值。
# 这个集群模式下连接要加-c
redis-cli -c -p 7001
4.3 集群伸缩
- redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:
redis-cli --cluster --help
- 向集群中添加一个新的master节点,并向其中存储num = 10:
- 启动一个新的redis实例,端口为7004
- 添加7004到之前的集群,并作为一个master节点
- 给7004节点分配插槽,使得num这个key可以存储到7004实例
# 创建7004目录
mkdir 7004
# 将redis.conf拷贝到该目录
cp redis.conf 7004
# 批量修改文件中的内容
sed -i s/6379/7004/g 7004/redis.conf
# 添加集群中的节点,后面这个ip和端口是用来通知集群添加了新节点的
redis-cli --cluster add-node 192.168.150.101:7004 192.168.150.101:7001
# 开始重新分片
redis-cli --cluster reshard 192.168.150.101:7001
# 弹出多少个插槽你想从集群移动过去
# 然后弹出谁接收这个插槽,填写ID
# 然后弹出从哪里开始拷贝,填写ID,填写done结束
4.4 故障转移
-
同上面的故障转移差不多,这个就不多说
-
手动故障转移:故障迁移
- 利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
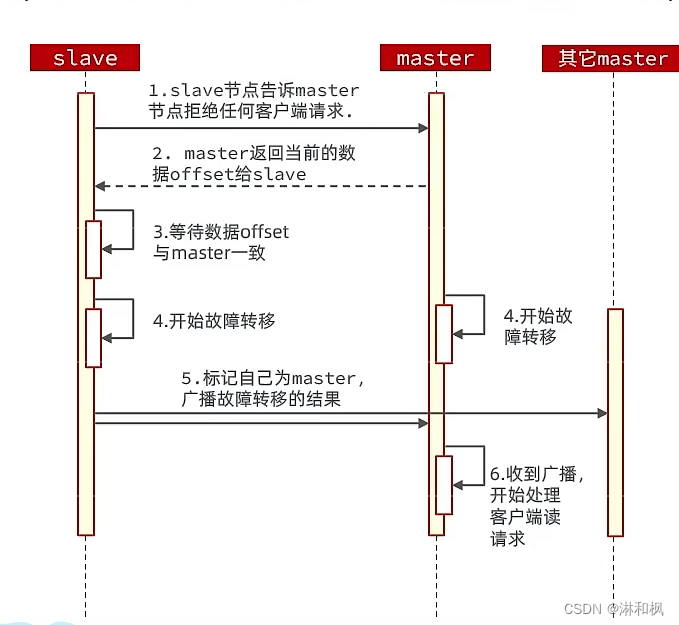
- 手动的Failover支持三种不同模式:
- 缺省:默认的流程,如图1~6步
- force:省略了对offset的一致性校验
- takeover:直接执行第5步,忽略数据一致性、忽略master状态和其它master的意见
4.5 RedisTemplate访问分片集群
- RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
- 引入redis的starter依赖
- 配置分片集群地址
- 配置读写分离
- 与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:
redis:
cluster:
nodes: #指定分片集群的每一个节点信息
192.168.150.101:7001
192.168.150.101:7002
192.168.150.101:7003
192.168.150.101:8001
192.168.150.101:8002
192.168.150.101:8003
五、多级缓存
-
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题:
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击
-
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
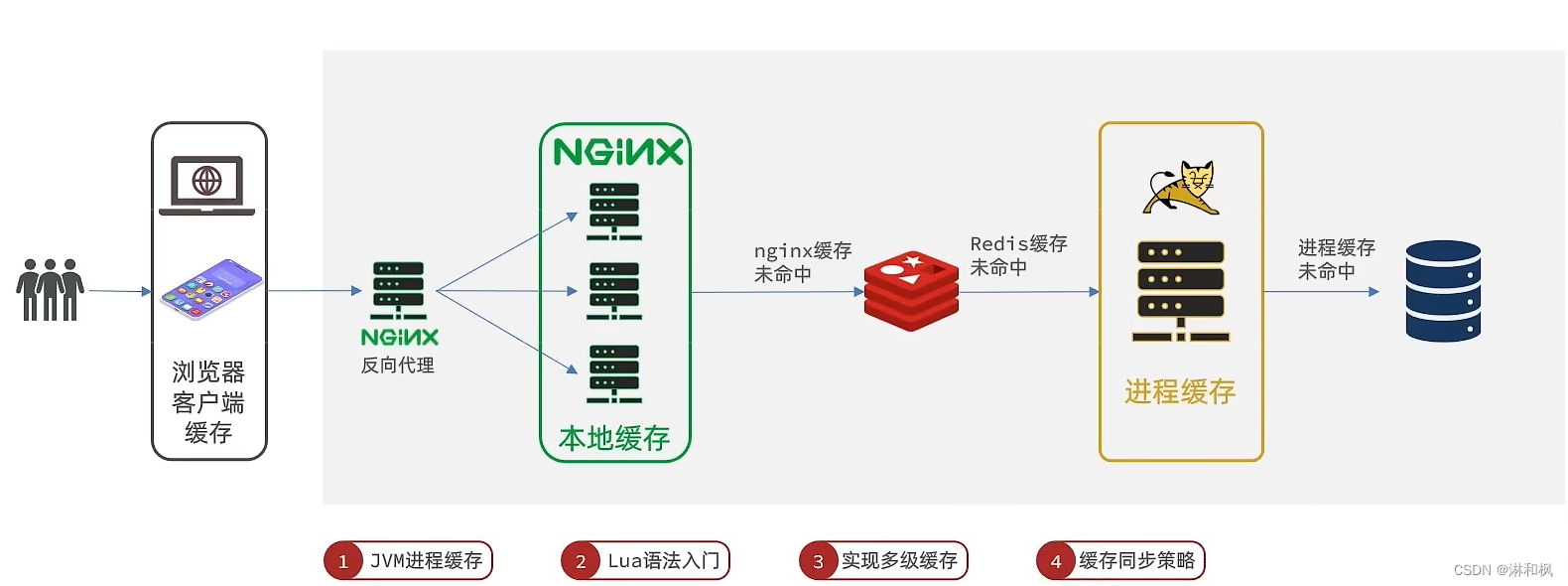
5.1 进程缓存
5.1.1 准备工作
- 为了方便后期配置MySQL,我们先准备两个目录,用于挂载容器的数据和配置文件目录:
#进入/tmp目录
cd /tmp
#创建文件夹
# mkdir mysql
# 进入mysql目录
cd mysql
- 进入mysql目录后,执行下面的Docker命令:
docker run \
-p 3306:3306 \
--name mysql \
-V $PWD/conf:/etc/mysql/conf.d \
-V $PWD/logs:/logs \
-V $PWD/data: /var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123 \
--privileged \
-d \
mysql:5.7.25
- 在/tmp/mysql/conf目录添加一个my.cnf文件,作为mysql的配置文件:
#创建文件
touch /tmp/mysql/conf/my.cnf
- 文件内容如下:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
-
接下来就可以导入数据了
-
运行nginx服务器
5.1.2 初识Caffeine
-
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
- 分布式缓存,例如Redis:
-
Caffeine是一个基于Java8开发的, 提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址: https://github.com/ben-manes/caffeine
-
可以通过item-service项目中的单元测试来学习Caffeine的使用:
@Test
void testBasicOps() {
//创建缓存对象
Cache<String,String> cache = Caffeine.newBuilder().build() ;
//存数据
cache.put("gf","迪丽热巴");
//取数据,不存在则返回null
String gf = cache.getIfPresent("gf") ;
System.out.println("gf="+ gf);
//取数据,不存在则去数据库查询
String defaultGF = cache. get("defaultGF",key -> {
//这里可以去数据库根据key 查询value
return "柳岩";
});
System.out.println("defaultGF="+defaultGF) ;
}
-
缓存不能无限制增加,要么设置过期时间或者其他方法
-
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量.上限
//创建缓存对象 Cache<String,String> cache = Caffeine.newBuilder() .maximumSize(1) //设置缓存大小上限为 1 .build() ;- 基于时间:设置缓存的有效时间
//创建缓存对象 Cache<String,String> cache =Caffeine.newBuilder() .expireAfterWrite(Duration.ofSeconds(10)) //设置缓存有效期为10秒,从最后一-次写入开始计时 .build() ;- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
-
在默认情况下,当一个缓存元素过期的时候,Caffeine不会 自动立即将其清理和驱逐。而是在一次读 或写操作后,或者在空闲时间完成对失效数据的驱逐。
5.1.3 实现进程缓存
-
利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库.
- 缓存初始大小为100
- 缓存上限为10000
-
首先先写一个配置类
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long,Item> itemCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long,ItemStock> stockCache() {
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}
- 现在就可以开始使用
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id,key -> itemService.query()
.ne(column:"status",val:3).eq(column:"id",key)
.one()
);
}
5.2 Lua语法入门
5.2.1 初识Lua
- Lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。官网: https://www.lua.org/
- 首先需要安装Lua运行的环境,官网有教程
- 在Linux虚拟机的任意目录下,新建一个hello.lua文件
touch hello.lua
- 添加下面的内容
print("hello World")
- 运行
lua hello.lua
5.2.2 变量和循环
- 数据类型
| 数据类型 | 描述 |
|---|---|
| nil | 这个最简单,只有值nil属于该类,表示一个无效值(在条件表达式中相当于false) |
| boolean | 包含两个值: false和true |
| number | 表示双精度类型的实浮点数 |
| string | 字符串由一对双引号或单引号来表示 |
| function | 由C或Lua编写的函数 |
| table | Lua中的表(table)其实是一个"关联数组" (associative arrays) ,数组的索引可以是数字、字符串或表类型。在Lua 里,table的创建是通过"构造表达式"来完成,最简单构造表达式是{},用来创建一个空表。 |
- 可以使用type来查看数据类型
print(type("hello,world"))
- Lua声明变量的时候,并不需要指定数据类型:
-- 声明字符串
local str = 'hello'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
-- 声明数组key为索引的table
local arr = {'java','python','lua'}
-- 声明table,类似java的map
local map = {name='Jack', age=21}
- 访问table:
-- 访问数组,lua数组的角标从1开始
print(arr[1])
-- 访问table
print(map['name'])
print (map.name)
-
数组、table都可以利用for循环来遍历:
- 遍历数组:
-- 声明数组key为索引的table local arr = {'java','python', 'lua'} -- 遍历数组 for index,value in ipairs(arr) do print(index,value) end- 遍历table
-- 声明map,也就是table local map = {name='Jack',age=21} -- 遍历table for key,value in pairs(map) do print(key, value) end5.2.3 条件控制,函数
-
定义函数的语法:
function函数名(argument1, argument2...,argumentn) -- 函数体 return 返回值 end -
例如,定义一个函数,用来打印数组:
function printArr(arr) for index,value in ipairs(arr) do print(value ) end end -
类似Java的条件控制,例如if、else语法 :
if(布尔表达式) then --[布尔表达式为true时执行该语句块--] else --[布尔表达式为false 时执行该语句块--] end -
与java不同,布尔表达式中的逻辑运算是基于英文单词:and,or,not
5.3 OpenResty实现多级缓存
5.3.1 安装OpenResty
-
OpenResty是一个基于Nginx的高性能Web平台,用于方便地搭建能够处理超高并发、 扩展性极高的动态Web应用、Web服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的Lua库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
- 官方网站:https://openresty.org/cn/
-
首先要安装OpenResty的依赖开发库,执行命令:
yum install -y pcre-devel openssl--devel gcc --skip-broken
- 你可以在你的CentOS系统中添加openresty仓库,这样就可以便于未来安装或更新我们的软件包(通过yum check-update命令)。运行下面的命令就可以添加我们的仓库:
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
- 如果提示说命令不存在,则运行:
yum install -y yum-utils
- 然后就可以像下面这样安装软件包,比如openresty
yum install -y openresty
- opm是OpenResty的一个管理工具,可以帮助我们安装一个第 三方的Lua模块。
- 如果你想安装命令行工具opm那么可以像下面这样安装openresty-opm包:
yum install -y openresty-opm
-
默认情况下,OpenResty安装的目录是: /usr/local/openresty
-
然后配置nginx的环境变量
vi /etc/profile
- 在最下面加入两行:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH
- NGINX_HOME: 后面是OpenResty安装目录下的nginx的目录然后让配置生效:
source /etc/profile
- OpenResty底层是基于Nginx的,查看OpenResty目录的nginx目录,结构与windows中安装的nginx基本一致,所以运行方式与nginx基本一致:
#启动nginx
nginx
#重新加载配置
nginx -s reload
#停止
nginx -s stop
- nginx的默认配置文件注释太多,影响后续我们的编辑,这里将nginx.conf中的注释部分删除,保留有效部分。修改/usr/local/openresty/nginx/conf/nginx.conf文件,内容如下:
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
- 现在就可以让OpenResty接收请求了
- 在nginx.conf的http’下面,添加对OpenResty的Lua模块的加载:
#加载lua模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
- 在nginx.conf的server’下面,添加对/api/item这个路径的监听:
location /api/item {
#响应类型,这里返回json
default_type application/json;
#响应数据由lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}
- 但是我们没有这个lua/item.lua文件,我们就新建一个
# 去nginx目录创建
mkdir lua
touch lua/item.lua
- 内容如下
--返回假数据,这里的ngx. say()函数,就是写数据到Response中,这个假数据就自己改
ngx.say('{"id":10001,"name":"SALSA AIR}')
- 重新加载配置
nginx -s reload
- 再访问路径就行了
5.3.2 请求参数处理
- OpenResty提供了各种API用来获取不同类型的请求参数:
| 参数格式 | 参数示例 | 参数解析代码示例 |
|---|---|---|
| 路径占位符 | /item/1001 | # 1.正则表达式匹配: location ~ /item/(\d+) { content_by_lua_file lua/item.lua; } 2.匹配到的参数会存入ngx.var数组中可以用角标获取 local id=ngx.var[1] |
| 请求头 | id: 1001 | –获取请求头,返回值是table类型 local headers =ngx.req.get_headers() |
| get请求参数 | ?id=1001 | –获取GET请求参数,返回值是table类型 local getParams=ngx.req.get_uri_args() |
| Post表单参数 | id=1001 | –读取请求体 ngx.req.read_body() 获取POST表单参数,返回值是table类型 local postParams = ngx.req.get_post_args() |
| JSON参数 | {“id”,1001} | –读取请求体 ngx.req.read_body() –获取body中的json参数,返回值是string类型 local jsonBody = ngx.req.get_body_data() |
5.3.3 查询Tomcat
-
案例:获取请求路径中的商品id信息,根据id向Tomcat查询商品信息
- 这里要修改item.lua,满足下面的需求:
- 获取请求参数中的id
- 根据id向Tomcat服务 发送请求,查询商品信息
- 根据id向Tomcat服务发送请求,查询库存信息
- 组装商品信息、库存信息,序列化为JSON格式并返回
- 这里要修改item.lua,满足下面的需求:
-
nginx提供了内部API用以发送http请求:
local resp = ngx.location.capture("/path", {
method = ngx.HTTP_GET, --请求方式
args = {a=1,b=2}, -- Get请求
body = "c=3&d=4" -- Post请求
})
- 返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
- 注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。
- 但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这 个路径做反向代理:
location /path{
# 这里是wi ndows电脑的i p和Java服务端口,需要确保wi ndows防火墙处于关闭状态
proxy_pass http://192.168.150.101:8081;
}
- 我们可以把http查询的请求封装为一个函数,放到OpenResty函数库中,方便后期使用。
- 在/usr/local/openresty/lualib目录下创建common.lua文件:
vi /usr/local/openresty/lualib.common.lua
- 在common.lua中封装http查询的函数
--封装函数,发送http请求,并解析响应
local function read_http(path,params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
--记录错误信息,返回404
ngx.log(ngx.ERR,"http not found, path: ",path,",args: ",args)
ngx.exit(404)
end
return resp.body
end
--将方法导出
local _M={
read_http = read_http
}
return _M
- 现在我们就可以开始使用了
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
--导入cjson库
local cjson = require "cjson"
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_http("/item" .. id, nil)
-- 查询库存信息
local stockJSON = read_http("/item/stock" ..id, nil)
--JSON转为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
--组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 返回结果
ngx.say(cjson.encode(item))
- OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
local cjson = require "cjson"
5.3.4 Tomcat负载均衡
- 由于tomcat进程不会共享数据,nginx查询另一个tomcat时会查询不到
- 我们可以用hash算法固定某个查询到固定的tomcat
upstream tomcat-cluster {
hash $require_uri;
server 192.168.150.101:8081;
server 192.168.150.101:8082;
}
# proxy_pass 要改为 http://tomcat-cluster
5.3.5 添加redis缓存
-
我们在实际开发中应该先查询redis,再去查询tomcat
-
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第-次查询时添加缓存,可能会给数据库带来较大压力
-
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
-
我们数据量较少,可以在启动时将所有数据都放入缓存中。
-
利用Docker安装Redis
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes
- 在item-service服务中引入Redis依赖
<dependency>
<group>org.springframework.boot</group>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 配置Redis地址
spring:
redis:
host: 192.168.150.101:8081
- 编写初始化类
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public void afterPropertiesSet() throws Exception { //初始化缓存... }
}
5.3.6 查询redis缓存
-
OpenResty提供了操作Redis的模块,我们只要引入该模块就能直接使用:
-
引入Redis模块,并初始化Redis对象
--引入redis模块
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new( )
--设置Redis超时时间
red:set_timeouts(1000,1000,1000)
- 封装函数,用来释放Redis连接,其实是放入连接池
--关闭redi s连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 --连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok,err = red:set_keepalive(pool_max_idle_time,pool_size)
if not ok then
ngx.log(ngx.ERR,"放入Redis连接池失败: ",err)
end
end
- 封装函数,从Redis读数据并返回
--查询redis的方法ip和port是redis地址, key 是查询的key
local function read_redis(ip, port, key)
--获取一个连接
local ok,err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR,"连接redis失败:",err)
return nil
end
--查询redis
local resp, err = red:get(key)
--查询失败处理
if not resp then
ngx.log(ngx.ERR,"查询Redis失败: ",err, ",key = ",key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR,"查询Redis数据为空,key = ",key)
end
close_redis(red)
return resp
end
- 封装查询函数
--封装查询函数
function read_data(key,path,params)
--查询redis
local resp = read_redis("127.0.0.1",6379,key)
--判断查询结果
if not resp then
ngx.log("redis查询失败,尝试查询http,key: ",key)
-- redis查询失败,去查询http
resp = read_http(path, params)
end
return resp
end
-- 然后将下面调用read_http改成read_data
5.3.7 nginx本地缓存
- OpenResty为Nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
- 开启共享字典,在nginx.conf的http 下添加配置:
#共享字典,也就是本地缓存,名称叫做: item_cache, 大小150m
lua_shared_dict item_cache 150m;
- 操作共享字典:
--获取本地缓存对象
local item_cache =ngx.shared.item_cache
--存储,指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set(' key','value',1000)
--读取
local val = item_cache:get('key')
- 需求
- 修改item.lua中的read_data函数,优先查询本地缓存,未命中时再查询Redis、Tomcat
- 查询Redis或Tomcat成功后,将数据写入本地缓存,并设置有效期
- 商品基本信息,有效期30分钟
- 库存信息,有效期1分钟
--封装查询函数
function read_data(key,expire,path,params)
--查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR,"本地缓存查询失败,尝试查询http,key: ",key)
--查询redis
val = read_redis("127.0.0.1",6379,key)
--判断查询结果
if not val then
ngx.log(ngx.ERR,"查询失败,尝试查询http,key: ",key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
end
--查询成功,写入本地缓存
item_cache:set(key,val, expire)
-- 返回数据
return val
end
--然后将下面的查询添加过期时间参数
六、缓存同步
6.1 数据同步策略
- 缓存数据同步的常见方式有三种:
- 设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
- 同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
- 异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
- 设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
6.2 安装Canal
-
Canal,译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。GitHub的地址: https://github.com/alibaba/canal
-
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:
- MySQL master将数据变更写入二进制日志(binary log)其中记录的数据叫做binary log events
- MySQL slave将master的binary log events拷贝到它的中继日志(relay log)
- MySQL slave重放relay log中事件,将数据变更反映它自己的数据
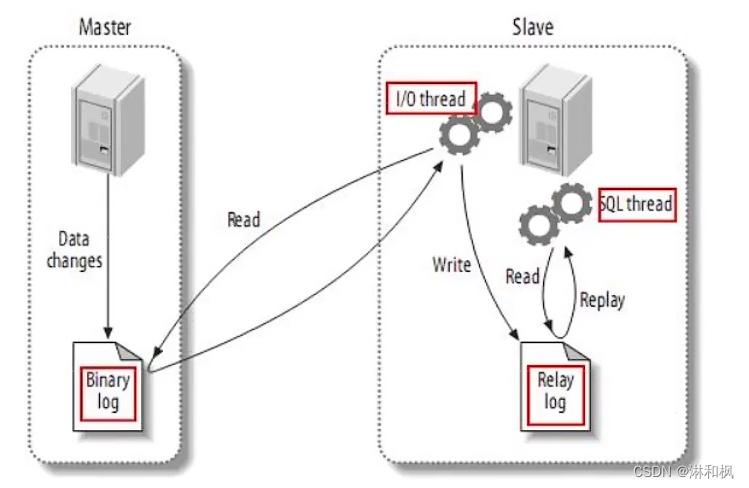
-
Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
-
下面我们就开启mysql的主从同步机制,让Canal来模拟salve
-
修改文件:
vi /tem/mysql/conf/my.cnf
- 添加内容:
# binlog存放的地址和名称
log-bin=/var/lib/mysql/mysql-bin
# 数据库名称
binlog-do-db=test
- 接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对这个库的操作权限。
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT,REPLICATION SLAVE,REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%'
identified by 'canal';
FLUSH PRIVILEGES;
- 重启mysq|容器即可
docker restart mysql
- 测试设置是否成功:在mysq|控制台, 或者Navicat中, 输入命令:
show master status;
- 开始安装Canal
- 我们需要创建一个网络, 将MySQL、 Canal、 MQ放到同一个Docker网络中:
# 创建一个名为test的网络
docker network create test
# 让mysql加入这个网络
docker network connect test mysql
- 将canal镜像压缩包上传到虚拟机,然后通过命令导入:
dockersload -i canal.tar
- 然后运行canal容器
# -e canal.destinations=test 集群名称为test
# -e canal.instance.master.address=mysql:3306 这个是mysql的地址
# dbUsername,dbPassword,connectionCharset对应用户名和密码和编码
# -e canal.instance.filter.regex=test\\..* 只监听test这个库
docker run -p 11111:11111 --name canal \
-e canal.destinations=test \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=test\\..* \
--network test \
-d canal/canal-server:v1.1.5
- 启动后怎么知道canal与mysql建立连接呢?
# 进入容器内部
docker exec -it canal bash
# 查看canal运行日志
tail -f canal-server/logs/canal/canal.log
# 也可以看数据库运行日志
tail -f canal-server/logs/test/test.log
6.3 监听Canal
- Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。不过这里我们会使用GitHub上的第三方开源的canal-starter。地址: https://github.com/NormanGyllenhaal/canal-client
- 引入依赖:
<!--canal -->
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
- 编写配置
canal :
destination: test #canal实例名称,要跟canal-server运行时设置的destination一致
server: 192.168.150.101:11111 # canal地址
- 编写监听器,监听Canal消息:
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {
@Override
public void insert(Item item) {
//新增数据到redis
}
@Override
public void update(Item before, Item after) {
//更新redis数据
//更新本地缓存
}
@Override
public void delete (Item item) {
//删除redis数据
//清理本地缓存
}
}
- canal怎么知道要把哪些表字段映射成实体类哪个字段呢?
- 这个过程中需要知道数据库与实体的映射关系,要用到JPA的几个注解:
- @Id:标记表中的id字段
- @Column(name=“name”):标记表中与属性名不一致的字段
- @Transient:标记不属于表中的字段
七、Redis最佳实战
7.1 Redis键值设计
7.1.1 优雅的key设计
-
Redis的Key虽然可以自定义,但最好遵循下面的几个最佳实践约定:
- 遵循基本格式: [业务名称]:[数据名]:[id]
- 长度不超过44字节
- 不包含特殊字符
-
例如:我们的登录业务,保存用户信息,其key是这样的:login:user:10
- 可读性强
- 避免key冲突
- 方便管理
- 更节省内存: key是string类型,底层编码包含int、embstr和raw三种。embstr在小于44字节使用,采用连续内存空间,内存占用更小
-
BigKey通常以Key的大小和Key中成员的数量来综合判定,例如:
- Key本身的数据量过大: 一个String类型的Key,它的值为5 MB。
- Key中的成员数过多: 一个ZSET类型的Key,它的成员数量为10000个。
- Key中成员的数据量过大: 一个Hash类型的Key,它的成员数量虽然只有1000个但这些成员的Value (值)总大小为100 MB。
7.1.2 拒绝BigKey
-
BigKey的危害:
- 网络阻塞:对Big.Key执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢
- 数据倾斜:BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- Redis阻塞:对元素较多的hash、list、 zset等 做运算会耗时较旧,使主线程被阻塞
- CPU压力:对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用.
-
如何发现BigKey
- redis-cli --bigkeys:利用redis-cli提供的–bigkeys参数,可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的big key
- scan扫描:自己编程,利用scan扫描Redis中 的所有key,利用strlen、 hlen等 命令判断key的长度( 此处不建议使用MEMORY USAGE)
- 第三方工具:利用第三方工具,如Redis-Rdb-Tools分析RDB快照文件,全面分析内存使用情况
- 网络监控:自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
-
如何删除BigKey
- redis 3.0及以下版本
- 如果是集合类型,则遍历BigKey的元素 ,先逐个删除子元素,最后删除BigKey
- Redis 4.0以后
- Redis在4.0后提供了异步删除的命令: unlink
- redis 3.0及以下版本
7.1.3 恰当的数据类型
-
比如存储一个User对象,我们有三种存储方式:
- json字符串
- 优点:实现简单粗暴
- 缺点:数据耦合,不够灵活
- 字段打散
- 优点:可以灵活访问对象任意字段
- 缺点:占用空间大、没办法做统一控制
- hash(推荐)
- 优点:底层使用ziplist,空间占用小,可以灵活访问对象的任意字段
- 缺点:代码相对复杂
- json字符串
-
假如有hash类型的key,其中有100万对field和value, field是 自增id,这个key存在什么问题?如何优化?
-
存在的问题:
- hash的entry数量 超过500时,会使用哈希表而不是ZipList,内存占用较多。
- 可以通过hash-max-ziplist-entries配置entry上限。但是如果entry过多就会导致BigKey问题
-
方案2:拆分为string类型:
- string结构 底层没有太多内存优化,内存占用较多。
- 想要批量获取这些数据比较麻烦
-
方案三:拆分为小的hash,将id / 100作为key,将id % 100作为field,这样每100个元素为一个Hash
-
7.2 批处理优化
7.2.1 Pipeline
-
单个命令执行
- 一次命令的响应时间= 1次往返的网络传输耗时+ 1次Redis执行命令耗时
-
n条命令批量执行
- N次命令的响应时间= 1次往返的网络传输耗时+ N次Redis执行命令耗时
- Redis提供了很多Mxxx这样的命令,可以实现批量插入数据,例如:
- mset
- hmset
- Redis提供了很多Mxxx这样的命令,可以实现批量插入数据,例如:
- N次命令的响应时间= 1次往返的网络传输耗时+ N次Redis执行命令耗时
-
MSET虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用Pipeline功能:
@Test
void testPipeline() {
//创建管道
Pipeline pipeline = jedis.pipelined() ;
for(int i=1;i<=100000;i++){
//放入命令到管道
pipeline.set("test:key_" + i,"value_”+ i) ;
if(i%1000==0){
//每放入1000条命令, 批量执行
pipeline.sync() ;
}
}
}
7.2.2 集群下的批处理
- 如MSET或Pipeline这样的批处理需要在- -次 请求中携带多条命令,而此时如果Redis是一-个集群,那批处理命令的多个key必须落在一个插槽中, 否则就会导致执行失败。
| 串行命令 | 串行slot | 并行slot | hash_tag | |
|---|---|---|---|---|
| 实现思路 | for循环遍历,依次 执行每个命令 | 在客户端计算每个key的 slot,将slot一致分为一组,每组都利用Pipeline 批处理。 串行执行各组命令 | 在客户端计算每个key的 slot,将slot一致分为一组,每组都利用Pipeline 批处理。 并行执行各组命令 | 将所有key设置相同的hash_tag,则所有key的slot一定相同 |
| 耗时 | N次网络耗时+ N次 命令耗时 | m次网络耗时+N次命令耗 时m=key的slot个数 | 1次网络耗时+N次命令耗时 | 1次网络耗时+N次命令耗时 |
| 优点 | 实现简单 | 耗时较短 | 耗时非常短 | 耗时非常短、实现简单 |
| 缺点 | 耗时非常久 | 实现稍复杂 slot越多, 耗时越久 | 实现复杂 | 容易出现数据倾斜 |
7.3 服务端优化
7.3.1 持久化配置
-
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- 用来做缓存的Redis实例尽量不要开启持久化功能
- 建议关闭RDB持久化功能,使用AOF持久化
- 利用脚本定期在slave节点做RDB,实现数据备份
- 设置合理的rewrite阈值,避免频繁的bgrewrite
- 配置no-appendfsync-on-rewrite=yes,禁止在rewrite期间做aof,避免因AOF引起的阻塞
-
部署有关建议:
- Redis实例的物理机要预留足够内存,应对fork和rewrite
- 单个Redis实例内存上限不要太大,例如4G或8G。可以加快fork的速度、减少主从同步、数据迁移压力
- 不要与CPU密集型应用部署在一起
- 不要与高硬盘负载应用一起部署。例如:数据库、消息队列
7.3.2 慢查询
-
慢查询:在Redis执行时耗时超过某个阈值的命令,称为慢查询。
-
慢查询的阈值可以通过配置指定:
- slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000,建议1000
-
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
- slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是128,建议1000
-
修改这两个配置可以使用: config set命令:
config set slowlog-log-slower-than 1000
config set slowlog-max-len 1000
- 查看慢查询日志列表:
- slowlog len:查询慢查询日志长度
- slowlog get[n]:读取n条慢查询日志
- slowlog reset:清空慢查询列表
7.3.3 命令及安全配置
-
Redis会绑定在0.0.0.0:6379,这样将会将Redis服务暴露到公网上,而Redis如果没有做身份认证,会出现严重的安全漏洞,漏洞重现方式: https://cloud.tencent.com/developer/article/1039000
-
漏洞出现的核心的原因有以下几点:
- Redis未设置密码
- 利用了Redis的config set命令动态修改Redis配置
- 使用了Root账号权限启动Redis
-
为了避免这样的漏洞,这里给出一些建议:
- Redis- 定要设置密码
- 禁止线上使用下面命令: keys、 flushall、flushdb、 config set等命令。可以利用rename-command禁用。
- bind: 限制网卡,禁止外网网卡访问
- 启防火墙
- 不要使用Root账户启动Redis
- 尽量不是有默认的端口
7.3.4 内存配置
- 当Redis内存不足时,可能导致Key频繁被删除、响应时间变长、QPS不稳定等问题。当内存使用率达到90%以上时就需要我们警惕,并快速定位到内存占用的原因。
| 内存占用 | 说明 |
|---|---|
| 数据内存 | 是Redis最主要的部分,存储Redi s的键值信息。主要问题是Bi gKey问题、内存碎片问题 |
| 进程内存 | Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redi s数据占用的内存相比可以忽略。 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用BigKey,可能导致内存溢出。 |
-
Redis提供了一些命令,可以查看到Redis目前的内存分配状态:
- info memory
- memory xxx
-
内存缓冲区常见的有三种:
- 复制缓冲区:主从复制的repl_backlog_buf, 如果太小可能导致频繁的全量复制,影响性能。通过repl-backlog-size来设置,默认1mb
- AOF缓冲区: AOF刷盘之前的缓存区域, AOF执行rewrite的缓冲区。无法设置容量上限
- 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大1G且不能设置。输出缓冲区可以设置
Redis执行时耗时超过某个阈值的命令,称为慢查询。
-
慢查询的阈值可以通过配置指定:
- slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000,建议1000
-
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
- slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是128,建议1000
-
修改这两个配置可以使用: config set命令:
config set slowlog-log-slower-than 1000
config set slowlog-max-len 1000
- 查看慢查询日志列表:
- slowlog len:查询慢查询日志长度
- slowlog get[n]:读取n条慢查询日志
- slowlog reset:清空慢查询列表
7.3.3 命令及安全配置
-
Redis会绑定在0.0.0.0:6379,这样将会将Redis服务暴露到公网上,而Redis如果没有做身份认证,会出现严重的安全漏洞,漏洞重现方式: https://cloud.tencent.com/developer/article/1039000
-
漏洞出现的核心的原因有以下几点:
- Redis未设置密码
- 利用了Redis的config set命令动态修改Redis配置
- 使用了Root账号权限启动Redis
-
为了避免这样的漏洞,这里给出一些建议:
- Redis- 定要设置密码
- 禁止线上使用下面命令: keys、 flushall、flushdb、 config set等命令。可以利用rename-command禁用。
- bind: 限制网卡,禁止外网网卡访问
- 启防火墙
- 不要使用Root账户启动Redis
- 尽量不是有默认的端口
7.3.4 内存配置
- 当Redis内存不足时,可能导致Key频繁被删除、响应时间变长、QPS不稳定等问题。当内存使用率达到90%以上时就需要我们警惕,并快速定位到内存占用的原因。
| 内存占用 | 说明 |
|---|---|
| 数据内存 | 是Redis最主要的部分,存储Redi s的键值信息。主要问题是Bi gKey问题、内存碎片问题 |
| 进程内存 | Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redi s数据占用的内存相比可以忽略。 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用BigKey,可能导致内存溢出。 |
- Redis提供了一些命令,可以查看到Redis目前的内存分配状态:
- info memory
- memory xxx
- 内存缓冲区常见的有三种:
- 复制缓冲区:主从复制的repl_backlog_buf, 如果太小可能导致频繁的全量复制,影响性能。通过repl-backlog-size来设置,默认1mb
- AOF缓冲区: AOF刷盘之前的缓存区域, AOF执行rewrite的缓冲区。无法设置容量上限
- 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大1G且不能设置。输出缓冲区可以设置















 7245
7245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









