







实验5:自然语言处理实践(情感分类)
一:实验目的与要求
1:掌握RNN、LSTM、GRU的原理。
2:学习用RNN、LSTM、GRU网络建立训练模型,并对模型进行评估。
3:学习用RNN、LSTM、GRU网络做预测。
二:实验内容
选择公开数据集,用LSTM、GRU或相应的改进模型实现情感分类。
如:IMDB电影评论数据集,IMDB是一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。百度平台该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
三:实验环境
本实验所使用的环境条件如下表所示。
| 操作系统 | Ubuntu(Linux) |
| 程序语言 | Python(3.8.10) |
| 第三方依赖 | numpy, matplotlib,keras等 |
四:方法流程
1:使用imdb.load_data编写数据加载代码,设置相关参数,例如max_features、maxlen、batch_size等。
2:编写LSTM和GRU模型的网络代码,并打印网络结构进行分析。
3:编写上述RNN模型编译、训练和测试的代码。
4:根据训练结果进行可视化绘图,例如损失值和准确率。
5:根据实验结果,对比上述RNN模型。
五:实验展示(训练过程的数据打印和可视化、测试和应用的结果展示)
1:GRU模型的实现
GRU模型的代码搭建如下表所示。
| model = models.Sequential() model.add(layers.Embedding(max_features, 32, input_length = maxlen)) model.add(layers.Conv1D(32, 5, activation = 'relu')) model.add(layers.MaxPooling1D(3)) model.add(layers.Conv1D(32, 5, activation = 'relu')) model.add(layers.MaxPooling1D(3)) model.add(layers.Dropout(0.2)) model.add(layers.CuDNNGRU(32)) # return_sequences = False model.add(layers.Dense(1, activation = 'sigmoid')) |
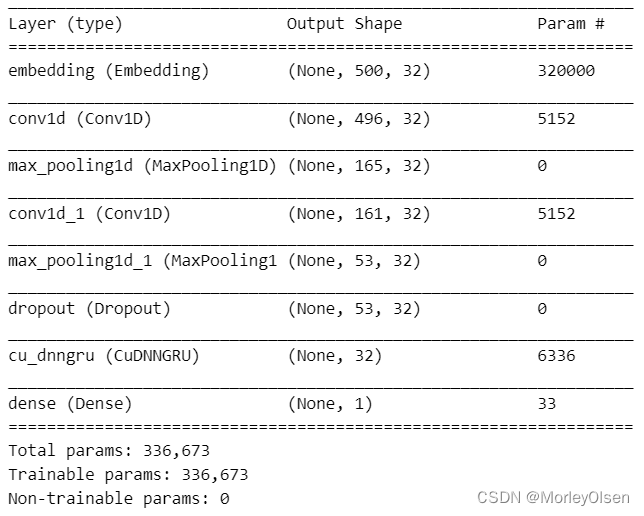
通过【model.summary()】打印GRU模型的网络结构,如下图所示。由下图可知,GRU模型的训练参数量为336673。
在模型编译环节,由于情感分析只需要分类为正向情绪positive(符号化为1)和负向情绪negative(符号化为0),因此GRU模型采用二分类交叉熵(binary_crossentropy)作为损失函数。同时,优化器选用rmsprop,评价指标选用准确率。
在模型训练环节,批次大小选为32,迭代次数选为15,验证集在输入训练集中的占比为20%。GRU模型的训练过程如下表所示。
| Epoch 1/15 625/625 [==============================] - 31s 10ms/step - loss: 0.5597 - acc: 0.6617 - val_loss: 0.2946 - val_acc: 0.8784 Epoch 2/15 625/625 [==============================] - 6s 10ms/step - loss: 0.2560 - acc: 0.8980 - val_loss: 0.2974 - val_acc: 0.8778 Epoch 3/15 625/625 [==============================] - 6s 9ms/step - loss: 0.1908 - acc: 0.9268 - val_loss: 0.2786 - val_acc: 0.8842 Epoch 4/15 625/625 [==============================] - 6s 9ms/step - loss: 0.1511 - acc: 0.9433 - val_loss: 0.3029 - val_acc: 0.8822 Epoch 5/15 625/625 [==============================] - 6s 10ms/step - loss: 0.1237 - acc: 0.9564 - val_loss: 0.2970 - val_acc: 0.8898 Epoch 6/15 625/625 [==============================] - 6s 10ms/step - loss: 0.0941 - acc: 0.9675 - val_loss: 0.3680 - val_acc: 0.8750 Epoch 7/15 625/625 [==============================] - 8s 12ms/step - loss: 0.0716 - acc: 0.9766 - val_loss: 0.3606 - val_acc: 0.8806 Epoch 8/15 625/625 [==============================] - 6s 10ms/step - loss: 0.0428 - acc: 0.9870 - val_loss: 0.4644 - val_acc: 0.8740 Epoch 9/15 625/625 [==============================] - 6s 9ms/step - loss: 0.0266 - acc: 0.9916 - val_loss: 0.4629 - val_acc: 0.8736 Epoch 10/15 625/625 [==============================] - 7s 10ms/step - loss: 0.0154 - acc: 0.9954 - val_loss: 0.5867 - val_acc: 0.8754 Epoch 11/15 625/625 [==============================] - 7s 12ms/step - loss: 0.0087 - acc: 0.9976 - val_loss: 0.6492 - val_acc: 0.8770 Epoch 12/15 625/625 [==============================] - 8s 12ms/step - loss: 0.0076 - acc: 0.9984 - val_loss: 0.8017 - val_acc: 0.8686 Epoch 13/15 625/625 [==============================] - 8s 12ms/step - loss: 0.0057 - acc: 0.9988 - val_loss: 0.9574 - val_acc: 0.8700 Epoch 14/15 625/625 [==============================] - 8s 12ms/step - loss: 0.0043 - acc: 0.9989 - val_loss: 0.9877 - val_acc: 0.8722 Epoch 15/15 625/625 [==============================] - 7s 11ms/step - loss: 0.0019 - acc: 0.9996 - val_loss: 1.0454 - val_acc: 0.8652 |
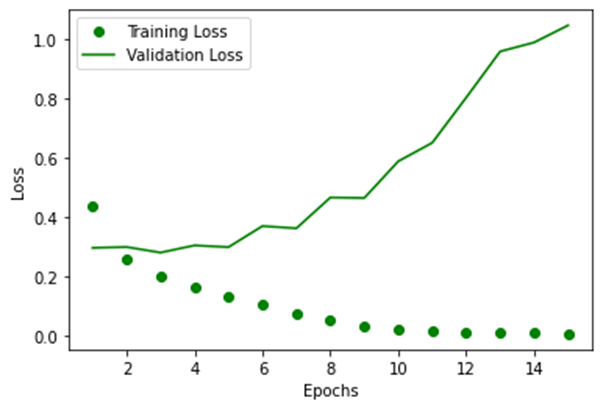
针对上述训练结果,利用plt绘制曲线变化图。
GRU模型的训练损失值和验证损失值,如下图所示。
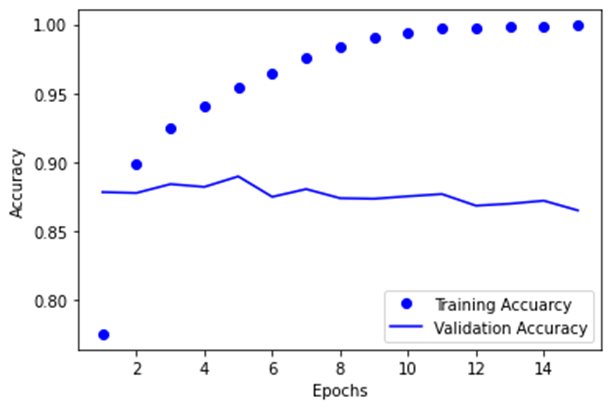
GRU模型的训练准确率和验证准确率,如下图所示。
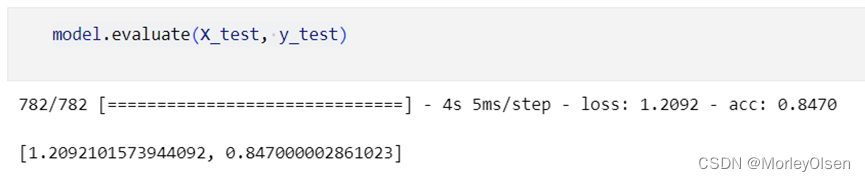
基于利用数据集训练过后的模型,在测试集上进行测试,结果如下图所示。最终的测试准确率为:84.70%。
2:LSTM模型的实现
LSTM模型的代码搭建如下表所示。
| model = models.Sequential() model.add(layers.Embedding(max_features, 32, input_length = maxlen)) model.add(layers.Dropout(0.2)) model.add(layers.CuDNNLSTM(32)) # return_sequences = False model.add(layers.Dense(1, activation = 'sigmoid')) |
通过【model.summary()】打印GRU模型的网络结构,如下图所示。由下图可知,LSTM模型的训练参数量为328481。

在模型编译环节,由于情感分析只需要分类为正向情绪positive(符号化为1)和负向情绪negative(符号化为0),因此GRU模型采用二分类交叉熵(binary_crossentropy)作为损失函数。同时,优化器选用rmsprop,评价指标选用准确率。
在模型训练环节,批次大小选为32,迭代次数选为15,验证集在输入训练集中的占比为20%。GRU模型的训练过程如下表所示。
| Epoch 1/15 625/625 [==============================] - 18s 27ms/step - loss: 0.5685 - acc: 0.6912 - val_loss: 0.3342 - val_acc: 0.8610 Epoch 2/15 625/625 [==============================] - 17s 27ms/step - loss: 0.2768 - acc: 0.8936 - val_loss: 0.2835 - val_acc: 0.8870 Epoch 3/15 625/625 [==============================] - 16s 26ms/step - loss: 0.2250 - acc: 0.9143 - val_loss: 0.3460 - val_acc: 0.8634 Epoch 4/15 625/625 [==============================] - 15s 24ms/step - loss: 0.2012 - acc: 0.9244 - val_loss: 0.3467 - val_acc: 0.8796 Epoch 5/15 625/625 [==============================] - 16s 26ms/step - loss: 0.1847 - acc: 0.9314 - val_loss: 0.2746 - val_acc: 0.8916 Epoch 6/15 625/625 [==============================] - 16s 25ms/step - loss: 0.1696 - acc: 0.9402 - val_loss: 0.3191 - val_acc: 0.8808 Epoch 7/15 625/625 [==============================] - 15s 25ms/step - loss: 0.1641 - acc: 0.9403 - val_loss: 0.2730 - val_acc: 0.8960 Epoch 8/15 625/625 [==============================] - 15s 25ms/step - loss: 0.1609 - acc: 0.9429 - val_loss: 0.2994 - val_acc: 0.8942 Epoch 9/15 625/625 [==============================] - 16s 25ms/step - loss: 0.1518 - acc: 0.9450 - val_loss: 0.2790 - val_acc: 0.8924 Epoch 10/15 625/625 [==============================] - 16s 26ms/step - loss: 0.1315 - acc: 0.9551 - val_loss: 0.3164 - val_acc: 0.8740 Epoch 11/15 625/625 [==============================] - 15s 25ms/step - loss: 0.1341 - acc: 0.9521 - val_loss: 0.2852 - val_acc: 0.8972 Epoch 12/15 625/625 [==============================] - 16s 25ms/step - loss: 0.1223 - acc: 0.9568 - val_loss: 0.3203 - val_acc: 0.8924 Epoch 13/15 625/625 [==============================] - 16s 26ms/step - loss: 0.1170 - acc: 0.9599 - val_loss: 0.2889 - val_acc: 0.8920 Epoch 14/15 625/625 [==============================] - 16s 26ms/step - loss: 0.1029 - acc: 0.9637 - val_loss: 0.3150 - val_acc: 0.8872 Epoch 15/15 625/625 [==============================] - 16s 25ms/step - loss: 0.1008 - acc: 0.9662 - val_loss: 0.3256 - val_acc: 0.8942 |
针对上述训练结果,利用plt绘制曲线变化图。
GRU模型的训练损失值和验证损失值,如下图所示。
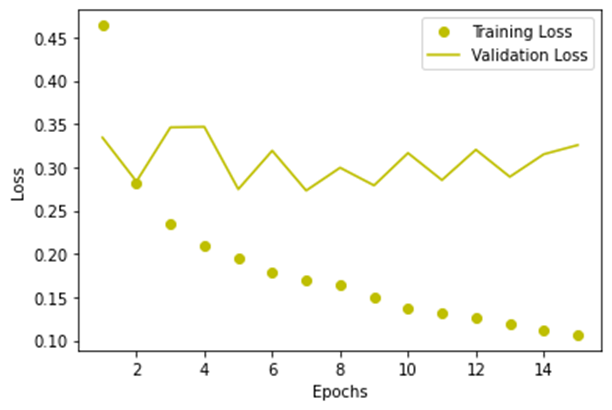
GRU模型的训练准确率和验证准确率,如下图所示。
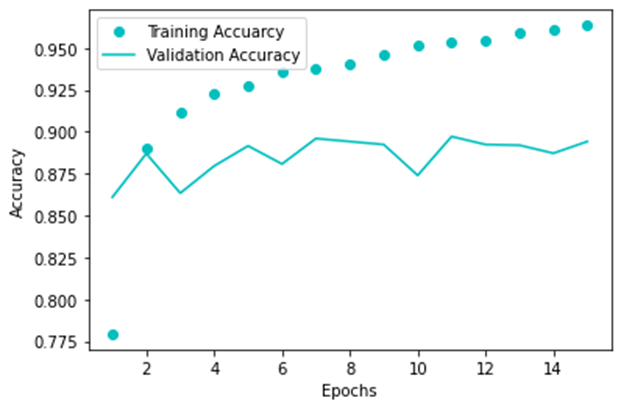
基于利用数据集训练过后的模型,在测试集上进行测试,结果如下图所示。最终的测试准确率为:87.72%。

3:GRU模型和LSTM模型的对比
基于本实验第1节和第2节部分的内容,可以得到:
(1)GRU模型的训练参数量为336673,而LSTM模型的训练参数量为328481。因此,GRU模型的训练参数量略多于LSTM模型。
(2)GRU模型在训练过程中的验证集上的最高准确率为88.98%,而LSTM模型在训练过程中的验证集上的最高准确率为89.72%。因此,GRU模型的验证准确率略低于LSTM模型。
(3)GRU模型最终的测试准确率为84.70%,而L,STM模型最终的测试准确率为87.72%。因此,GRU模型的测试准确率略低于LSTM模型。
综上所述,GRU模型的效果比LSTM模型略差。
六:实验结论
1:斯坦福官方平台的IMDB电影评论数据集Large Movie Review Dataset v1.0(Sentiment Analysis)。
2:添加正则化项(如:dropout)可以有效防止模型过拟合,提高泛化能力。同时,选择合适的优化器(如:adam、rmsprop)可以加速模型的训练过程。
3:隐藏层单元数、学习率、批次大小等超参数的调整对于LSTM和GRU模型的表现性能具有显著影响。通过合理的超参数调整,可以进一步提高模型的性能。
4:GRU模型可以解决RNN中不能长期记忆和反向传播中的梯度等问题,但是比LSTM简单,容易进行训练。
5:在LSTM模型中,信息的添加和移除通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息。其中,LSTM模型具有三个门,遗忘门,输入门,输出门。
6:循环神经网络是时间上的展开,处理的是序列结构的信息。而递归神经网络是是空间上的展开,处理的是树状结构的信息。
7:电影评论情感分析的实践流程示意图,如下图所示。

七:遇到的问题和解决方法
暂无。
八:程序源代码
以下代码为GRN示例,LSTM可同理实现。完整代码可见ipynb附件。
| import numpy as np import matplotlib.pyplot as plt from keras.datasets import imdb from keras import models from keras import layers from keras.preprocessing.sequence import pad_sequences max_features = 10000 # Only include top 10,000 words in the vocabulary maxlen = 500 # Cut off each review after 500 words batch_size = 32 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words = max_features) X_train.shape, X_test.shape X_train = pad_sequences(X_train, maxlen = maxlen) X_test = pad_sequences(X_test, maxlen = maxlen) X_train.shape, X_test.shape model = models.Sequential() model.add(layers.Embedding(max_features, 32, input_length = maxlen)) model.add(layers.Conv1D(32, 5, activation = 'relu')) model.add(layers.MaxPooling1D(3)) model.add(layers.Conv1D(32, 5, activation = 'relu')) model.add(layers.MaxPooling1D(3)) model.add(layers.Dropout(0.2)) model.add(layers.CuDNNGRU(32)) # return_sequences = False model.add(layers.Dense(1, activation = 'sigmoid')) model.summary() model.compile(loss = 'binary_crossentropy', optimizer = 'rmsprop', metrics = ['acc']) history = model.fit(X_train, y_train, batch_size = batch_size, epochs = 15, validation_split = 0.2) loss = history.history['loss'] val_loss = history.history['val_loss'] acc = history.history['acc'] val_acc = history.history['val_acc'] epochs = range(1, 16) plt.plot(epochs, loss, 'go', label = 'Training Loss') plt.plot(epochs, val_loss, 'g', label = 'Validation Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show() plt.plot(epochs, acc, 'bo', label = 'Training Accuarcy') plt.plot(epochs, val_acc, 'b', label = 'Validation Accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show() model.evaluate(X_test, y_test) |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











