







 本文教你如何利用豌豆IP代理软件替换IP进行个人或爬虫上网,包括注册、获取API、多线程访问示例。
本文教你如何利用豌豆IP代理软件替换IP进行个人或爬虫上网,包括注册、获取API、多线程访问示例。
接着上篇理论篇的理论知识学习完后,理论存在,实践开始,如果理论还没看的点击下方链接
像个黑客一样在网络上来无影去无踪之IP代理理论篇 https://blog.csdn.net/m0_65831893/article/details/123035701
https://blog.csdn.net/m0_65831893/article/details/123035701
我们知道IP代理是什么后,那要如何替换自己的IP进行上网呢?最简单的方法就是下载一个IP代理软件,众所周知,免费的不一定好用,好用的都要钱,但是今天给你推荐个好用又免费的
(事先声明,我只是个小博主,没有收取任何广告费用,良心推荐而已)
豌豆IP代理https://h.wandouip.com/?pr=89ZK4T
点击进去之后,点击注册然后实名认证后联系客服就会送你10000个IP账户给你使用
注意这个是有时限的,每人只能白嫖一次
个人上网使用
在上面那个页面注册完之后,点击到下面链接进行登录,千万不能在下方链接注册,这个网站有个Bug就是在这个首页注册完,在别的地方不能登录,所以一定严格按照步骤来注册
豌豆IP代理首页https://www.wandouip.com/ 点击进首页后点击下载就能直接使用个人IP代理切换上网了
爬虫上网使用
在上面那个页面注册完后,我们可以点击工具提取API如下图
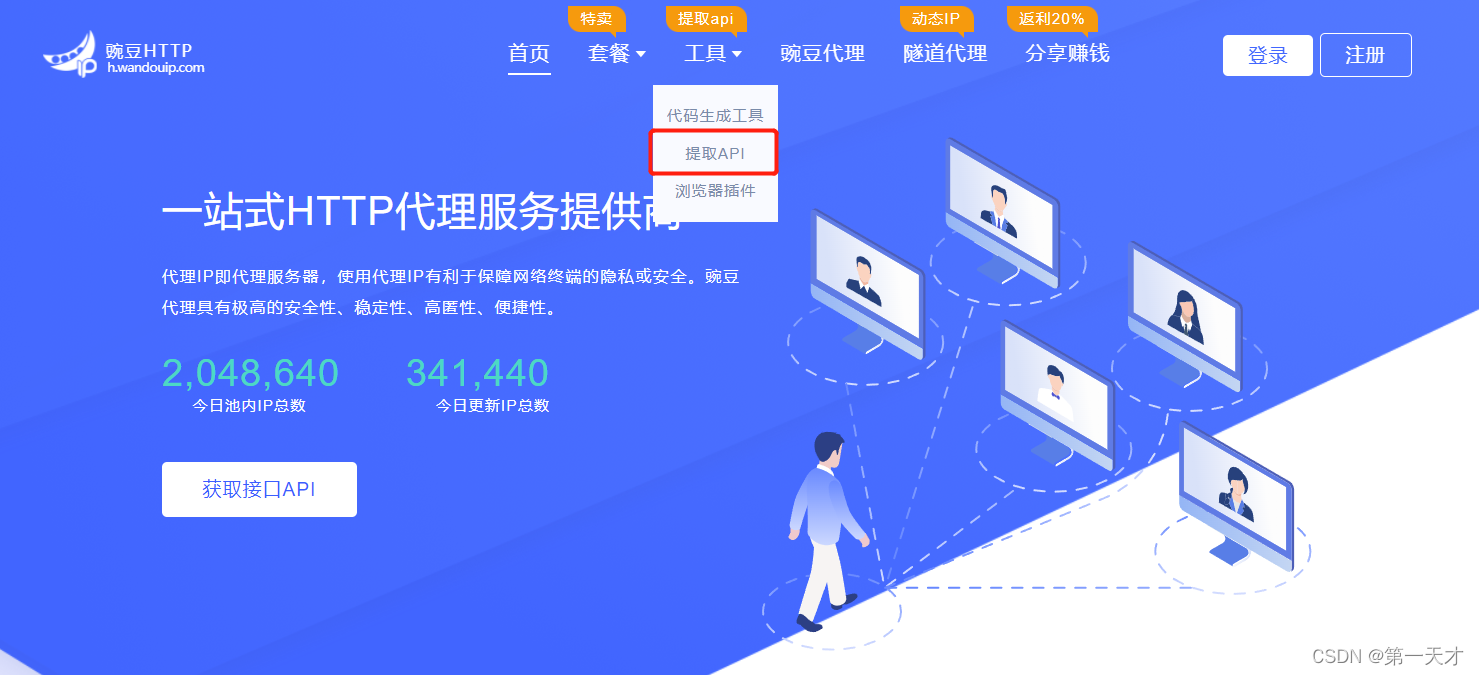
然后进入到一个界面什么都不用动,提取数量可以看你需要,点击生成API链接,复制链接
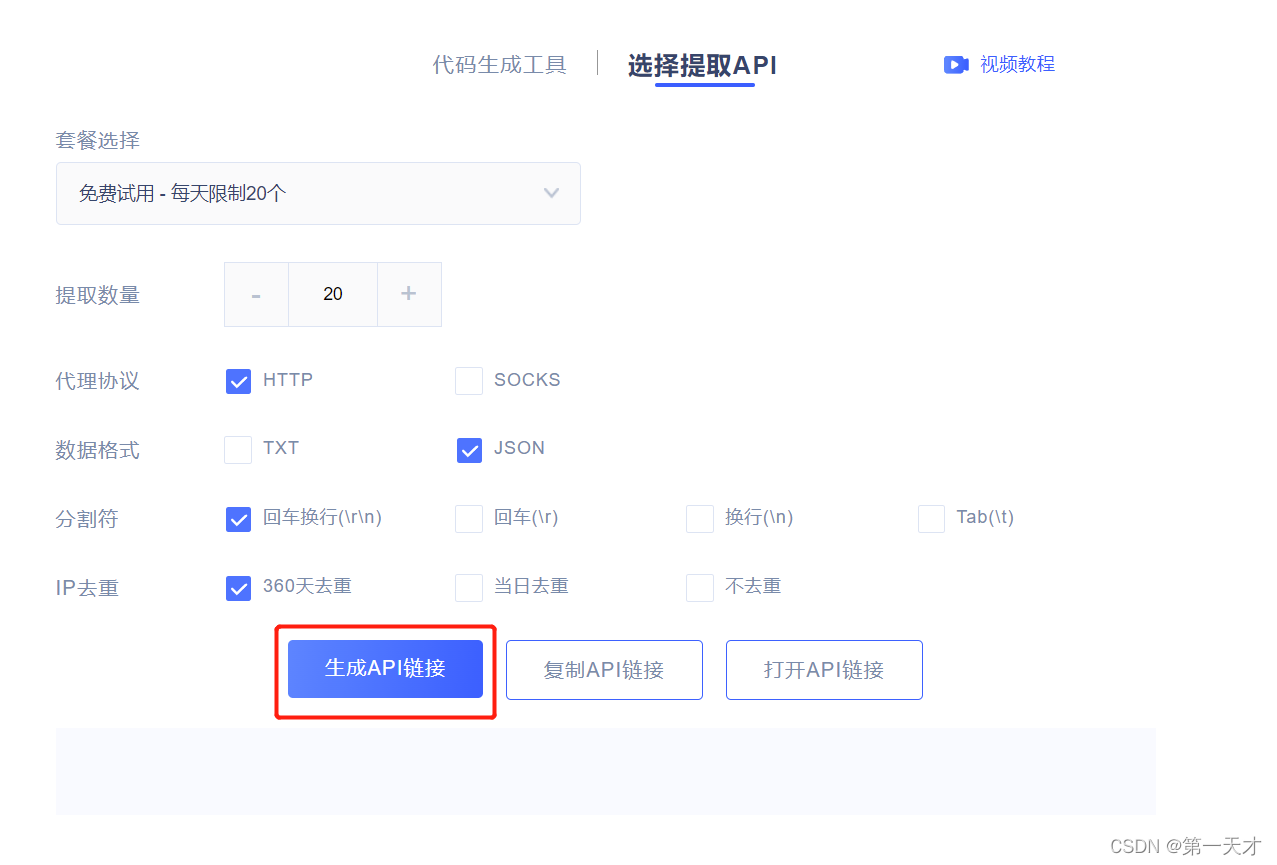
拿到链接后我们拿到的值是一个json格式的,我们拿到后进行转码提取
(以下示范均是python代码)
def get_ip_list():
url = '你的API获取链接'
resp = requests.get(url) #这里是通过request库访问你的API获取链接
resp_json = resp.text #获取到你访问链接后返回的数据
resp_dict = json.loads(resp_json) #将获取到数据进行转码
ip_dict_list = resp_dict.get('data') #将转码过后的有关于ip号端口号的数据提取
return ip_dict_list在获取到IP和端口后,我们就可以进行一个代理,往下是一个多线程访问一个网站的简单函数
def spider_ip(ip,port,targetUrl):
# 非账号密码验证
proxyMeta = "http://%(host)s:%(port)s" % {
"host": ip,
"port": port,
}
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
# 记录开始时间
start = int(round(time.time() * 1000))
resp = requests.get(targetUrl, proxies=proxies, timeout=10)
#
# 这里可以进行对resp的爬取清洗数据相关操作
#
# 记录访问时间
costTime = int(round(time.time() * 1000)) - start
try:
result = '访问成功! ' + "耗时:" + str(costTime) + "ms"
except:
result = '此代理失效'
print('当前线程:', threading.current_thread(), '\n' + result)在看懂以上函数后,我们就可以进行一个IP代理多线程访问了,需要爬取数据的操作你就自己添加到中间去吧,总的代码如下
# coding=utf-8
import requests
import time
import json
import threading
def get_ip_list():
url = '你的API获取链接'
resp = requests.get(url) #这里是通过request库访问你的API获取链接
resp_json = resp.text #获取到你访问链接后返回的数据
resp_dict = json.loads(resp_json) #将获取到数据进行转码
ip_dict_list = resp_dict.get('data') #将转码过后的有关于ip号端口号的数据提取
return ip_dict_list
def spider_ip(ip, port, targetUrl):
# 非账号密码验证
proxyMeta = "http://%(host)s:%(port)s" % {
"host": ip,
"port": port,
}
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
# 记录开始时间
start = int(round(time.time() * 1000))
resp = requests.get(targetUrl, proxies=proxies, timeout=10)
#
# 这里可以进行对resp的爬取清洗数据相关操作
#
# 记录访问时间
costTime = int(round(time.time() * 1000)) - start
try:
result = '访问成功! ' + "耗时:" + str(costTime) + "ms"
except:
result = '此代理失效'
print('当前线程:', threading.current_thread(), '\n' + result)
if __name__ == '__main__':
# 获取IP代理池
ip_dict_list = get_ip_list()
# 请求地址
targetUrl = "https://www.itmsf.com/?fromuid=16523"
i = 1
for ip_dict in ip_dict_list:
ip = ip_dict.get('ip')
port = ip_dict.get('port')
ip_threading = threading.Thread(target=spider_ip, args=(ip, port, targetUrl))
ip_threading.name = '线程%d' % i
ip_threading.start()
i += 1
通过以上方法就能进行一个IP代理访问啦!
(以上内容仅供学习参考,若有错误之处欢迎指正交流)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











