






 文章探讨了训练神经网络模型时的几个关键概念:批量操作,动量和自动学习率调整。批量大小影响训练速度和稳定性,小批次能提供更好的泛化能力,而大批次可能加速训练但可能导致过拟合。动量利用历史梯度信息帮助越过局部极小值。自动学习率调整如RMSProp通过考虑梯度平方的均值动态改变学习率,防止训练停滞或过快。学习率调度策略如衰减和预热进一步优化训练过程。
文章探讨了训练神经网络模型时的几个关键概念:批量操作,动量和自动学习率调整。批量大小影响训练速度和稳定性,小批次能提供更好的泛化能力,而大批次可能加速训练但可能导致过拟合。动量利用历史梯度信息帮助越过局部极小值。自动学习率调整如RMSProp通过考虑梯度平方的均值动态改变学习率,防止训练停滞或过快。学习率调度策略如衰减和预热进一步优化训练过程。
目录
1.2 Small Batch v.s. Large Batch
2.1Training stuck Samll Gradient
摘要
这周学习了批次、动量以及自动调整学习速率,是在训练模型时用到的方法。学习了批次的概念以及大批次和小批次在各方面各自的优缺点,以及在原来gradient的方法上加上动量这个方法,更好的解决遇到critical point的情况。最后学习了训练过程中自动调整学习速率的计算方法,以及同一参数在不同时间学习速率的动态调整方法。
Abstract
This week, I learned about batch, momentum, and automatic adjustment of learning rate, which are the methods used in training the model. I have learned the concept of batches and the advantages and disadvantages of large and small batches in various aspects, as well as the addition of momentum to the original gradient method to better solve critical point situations. Finally, I learned the calculation method for automatically adjusting the learning rate during the training process, as well as the dynamic adjustment method for the learning rate of the same parameter at different times.
1. 批次(batch)与动量(momentum)
1.1 回顾批量操作

在实际训练的时候,不是将整个data集进行训练,而是采用btach的方法,将data集分成若干份batch进行训练,挨个进行梯度下降优化参数,每一次计算梯度都是在上一个batch进行梯度下降的基础上进行的。
将所有的batch都用过一遍就叫做 1 epoch。在进行training的时候会有多次epoch,在每次epoch之前会重新再分一次batch,并且每一个epoch分的batch都不一样,这件事情就叫做改组(Shuffle)。
1.2 Small Batch v.s. Large Batch

假设有20个examples,有最极端的两种情况:
一、Batch size = N(Large Batch),即20个examples作为一个batch。Large Batch冷却时间比较长,需要将所有的资料都看过一边之后再update,走得很稳。
二、Batch size = 1(Small Batch),即每一个example作为一个batch。Small Batch的冷却时间很短,每次都是看一个参数,每看过一个资料就会更新一次,如果有20个参数,那么一个epoch就要更新20次。更新的方向就是曲曲折折的,走的不稳。
之所以看起来左边冷却时间长右边冷却时间长,是因为没有考虑平行运算,Large Batch冷却时间并不一定会很长。
从折线图可以看出,batch size为10和100所用的时间是一样的,假设有1000笔资料,因为平行运算的原因,这1000笔资料是平行处理的,并不是一笔资料时间的1000倍,但是平行运算的数量是有上限的,当batch size非常巨大的时候,GPU在跑完一个batch计算出gradient花费的时候会随着size的增加而增加。

左边是拿一个batch出来,算一次gradient更新一次参数的时间随着batch size的变化,右边是跑完一个完整的epoch需要的花的时间随着batch size的变化。明显两边的趋势是完全相反的,因此可以发现在不考虑平行运算的时候,会觉得large batch是需要更长时间的,但是考虑平行运算的话,large batch需要的时间反而更短。这是因为由于batch size 较小时,虽然更新一次的时间较短,但是更新的次数很多,所以训练一次epoch的时间会很长。
当单次训练的数据量达到GPU能够进行平行运算的最大极限值时,一次epoch的时间就达到最小值。
神奇的是反而Small Batch 产生的noisy的gradient可以帮助training,拿不同的batch来训练同一个模型,会得到如下的结果。

可以发现batch size越大,validation上的结果越差,这个是overfitting的问题吗?不是,因为train上的结果也是越差的,这两个用的是同一个model,可以表示的function是一样的,因此不是model bias的问题,是optimization的问题。
为什么Small batch的测试结果会表现得更好呢?

对于full batch来说,在做gradient descend 的时候,进行update是沿着一个loss function,在update的时候走到梯度为零的地方就会停下来了。而对于small batch,每次是挑一个batch出来,因此每次update的loss function是不一样的,比如第一次是L1,第二次L2,如果L1卡住了,L2不一定会卡住,因此一个loss卡住了,可以换另一个loss继续走。
事实上,small batch在testing data上的表现也是更好的。

这是为什么呢?用一个例子解释如下:

实际训练的时候,train和test的结果是不会一致的,现在假设Testing Loss的图像就如同是training loss进行右移得到的,使用small batch的话minima一般落在“平原”地区,可以发现train与test的误差比较小,而使用large batch的地方,minima一般落在“峡谷”处,这时图像稍微偏差一些,造成的误差就会非常大,因此testing data的结果就会很差。
1.3 momentum
 虽然是叫动量,但是它实际上更像是物理上的惯性,在Loss在达到critical point点的时候,可以借助惯性的冲力仍然有继续前进的趋势,甚至可以翻越“小山丘”继续下降。
虽然是叫动量,但是它实际上更像是物理上的惯性,在Loss在达到critical point点的时候,可以借助惯性的冲力仍然有继续前进的趋势,甚至可以翻越“小山丘”继续下降。
一般的gradient可能无法解决minima的问题,因此需要新的gradient方法,在一般的gradient基础上加上momentum.

参数的更新方向不再由gradient单独决定,而是由gradient和上一步的movement共同决定。
参数更新的方向=上一步的movement - gradient

movement = 所有之前的gradient之和
momentum的好处

在local minima处,当梯度为0时,因为上一次的momentum不为0,所以此时的momentum并不为0,所以会继续往右走,并不会卡在local minima。对于翻越“小山坡”的点来说,计算出来的update方向是往回走的,但当last momentum大于梯度值时,在last momentum的助力下,可以成功翻越“小山坡”,找到loss更小的点。
2、自动调整学习速率
2.1Training stuck 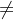 Samll Gradient
Samll Gradient
critical point 不一定是训练过程最大的阻碍,多数时候会以为走到了critical point,因为梯度为零,不能再更新参数,当loss不再下降,此时的gradient真的很小吗?

在上图的例子中,当loss几乎不再下降的时候,gradient的大小并没有为0,这是为什么呢?
因为可能遇到的是图中左边的情况,遇到了一个“峡谷”,在梯度相同的地方来回跳动,此时loss值不再变化,但是gradient的大小并不为0。
很多时候train还没有走到critical point的时候就已经停止了
以黑点为起点做training,当调整到10-7时,走向不是震荡的了,但是这样是永远走不到终点,因为learning rate太小了,当坡度很平滑的时候根本不可能前进。
传统的gradient中对所有的参数都是设置的同样的learning rate,但这种gradient连error surface都解决不了,那么遇到更加复杂的error surface就更不可能解决,因此需要更好的gradient,这种gradient需要为没一个参数“定制”一个learning rate。

如果在某一方向上非常平坦,那么就希望这个learning rate大一些,如果比较陡峭,波动很大,就希望learning rate小一点,那么怎么根据gradient调整learning rate呢?
parameter dependent的learning rate的常见计算方式:Root Mean Square
那么同一参数在不同时间的learning rate调整方法是什么呢?RMSProp
2.2 Root Mean Squar和RMSProp

当很小趋近于0,说明
相对于之前算出来的gradient更加重要,如果
很大趋近于1,说明现在算出来的
比较不重要,之前的比较重要。因此通过
这一项,可以决定当前算出来的
与之前所有的g哪个更加重要,通过RMSProp可以动态调整
的值。

为什么Rooot Mean Square可以根据坡度大小调整learning rate呢?
假设有两个参数1和
2,
1因为坡度小的原因,因此算出来的gradient 大小都比较小,由公式可知
小(
大小由g决定),所以learning rate比较大,
2坡度大,因此算出来的gradient比较大,因此
大,所以learning rate比较小。因此有了
,就可以随着参数的gradient的不同,自动的调整learning rate的大小。
但是同一方向、同一个参数的learning rate并不是一成不变的,也会随着时间而动态调整。

在比较平缓的地方,learning rate会变大,在比较陡峭的地方,learning rate会变小。
那么用新的gradient方法进行training,结果会怎样呢?

可以走到终点,但是容易突然就“爆炸”了,因为在纵轴的方向,刚开始gradient比较大learning rate比较小,因此在纵轴方向积累了很多很小的D,累计到一定量之后,D就会变很大,这时就会走到gradient比较大的地方,D又会慢慢变大,updata的步伐又会变小,慢慢的又回到横轴位置。
怎么避免这种“爆炸”的出现呢?使用Learning Rate Scheduling
2.3 Learning Rate Scheduling

把N当做一个跟时间有关的常数,
①Learning Rate Decay
刚开始比较大,当我们慢慢接近终点的时候,需要把
降下来,当
突然变得很大,但是乘上非常小的
时候就停下来了,就能一直保持平稳的走了。
②Warm Up(先增后减)
刚开始非常小是为了让先统计一下
的数据,比较精准以后再慢慢增加
的大小。

新的gradient并不是完全顺着这一个时间点算出来的gradient来更新参数,而是要考虑过去所有的gradient。
不考虑gradient的方向,因为计算的都是平方项,而Momentum是之前所有gradient之和,是会考虑gradient的方向的,因此momentum和
是不会相互抵消掉的。再加上learning rate scheduling就成为了新的gradient版本。
总结

在没有平行运算的情况下,小的batch比大的batch更新速度快,但是在小的情况下,两者并无差异除非当大的batch非常大的时候。对于一个epoch所需要的时间来说,大的batch比小的batch所需要的时间更短。小的batch进行gradient时比较曲折,而大的batch比较平稳,但是反而时小的batch这种曲折的gradient在进行Optimization和Generalization时可以表现得更好。大的batch和小的batch都有各自擅长的地方,也有“鱼和熊掌兼得”的方法。















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









