






Jsoup网络爬虫案例(爬取京东商品数据)
一. 依赖安装
更多版本可以去Maven仓库查看,这里使用较新的1.15.3版本
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
二. 进入京东官网,查看分析前端对象数据
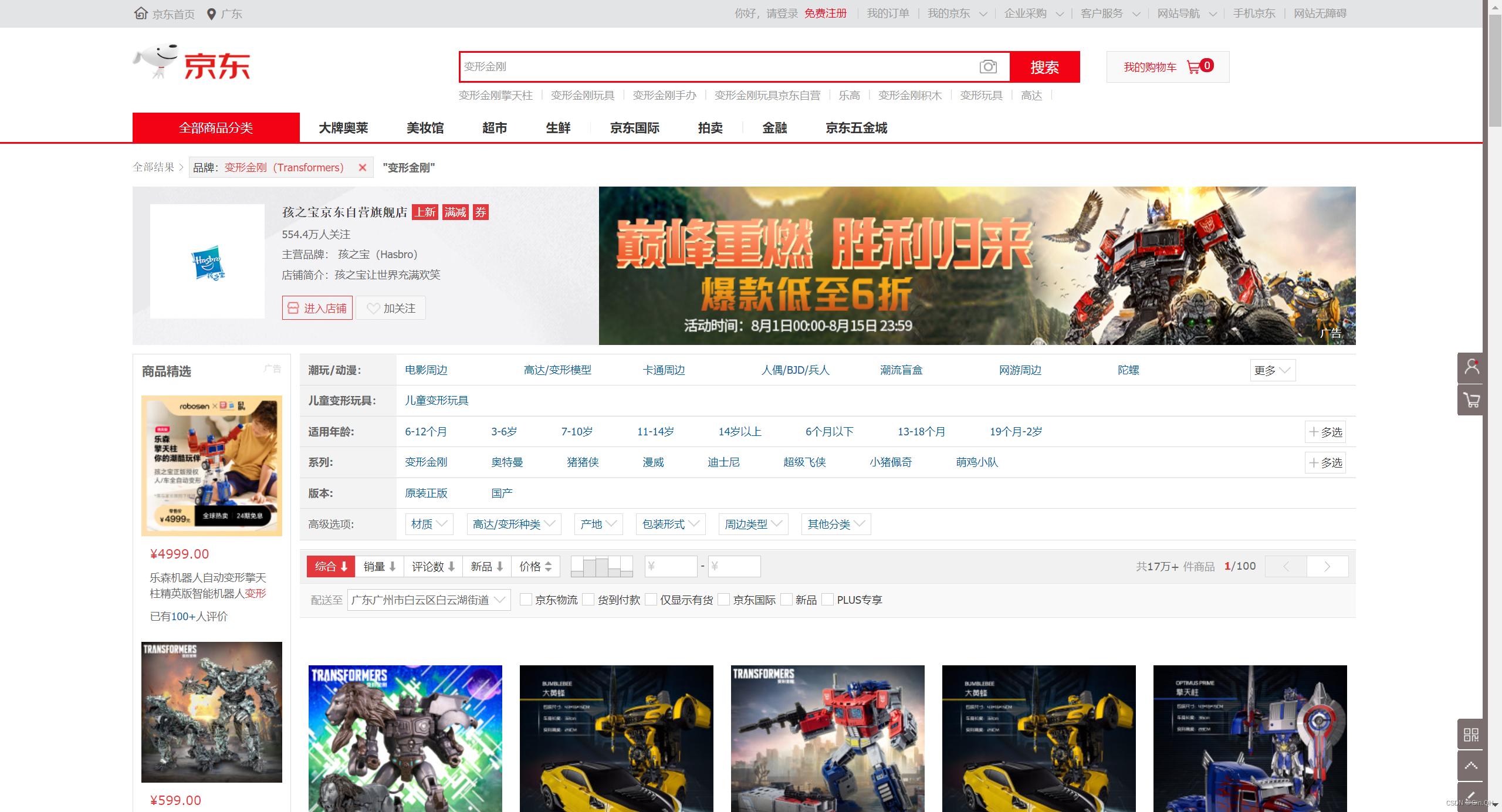
打开F12,使用前端选择按钮
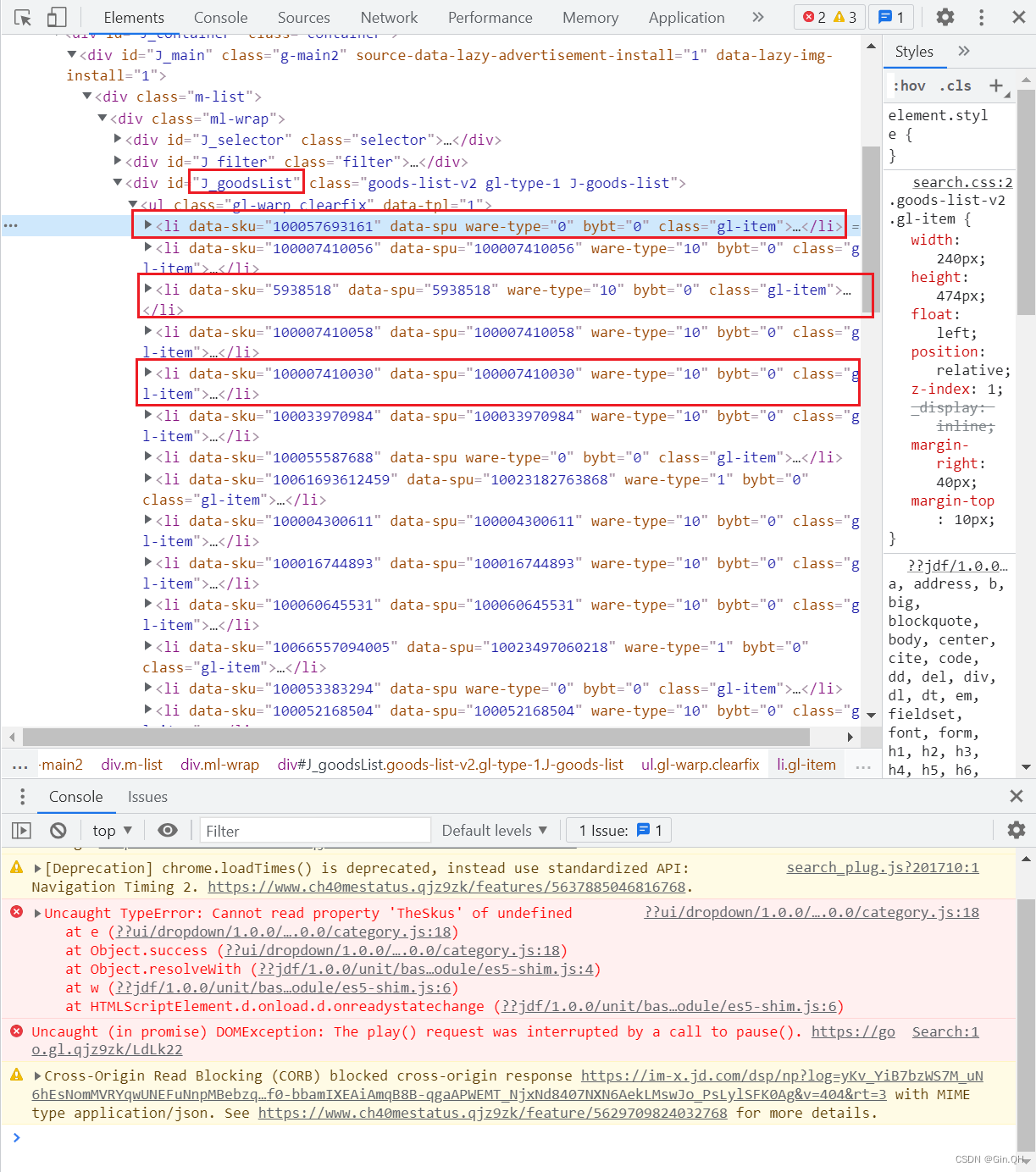
选择指定图片位置,进行获取,发现id为 J_goodsList 的div标签下的li标签,每个li标签对应一条商品数据,
三. 写代码,开始爬虫
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Scanner;
import java.util.SimpleTimeZone;
public class Jsoup {
static int i = 0;
public static void main(String[] args) {
//输入搜索内容
Scanner sc = new Scanner(System.in);
String item = sc.next();
//拼接搜索路径
String url = "https://search.jd.com/Search?keyword=" + item;
//设置空参
Document document = null;
Element element = null;
Elements elementsByClass = null;
Elements li = null;
InputStream is=null;
FileOutputStream os =null;
try {
//获取doc对象
document = org.jsoup.Jsoup.connect(url).get();
//根据id和标签获取内容
element=document.getElementById("J_goodsList");
elementsByClass = element.getElementsByClass("gl-warp clearfix");
li = element.getElementsByTag("li");
URLConnection con = null;
//遍历开始下载
for (Element ei : li) {
i++;
//获取图片路径
String img = ei.getElementsByTag("img").eq(0).attr("data-lazy-img");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy年MM月dd日HH时mm分ss秒");
//设置文件名
String text = item + dateFormat.format(new Date()) + "第" + i + "张图片".replaceAll(" ", "");
//设置图片下载路径
URL picture = new URL("https:" + img);
con = picture.openConnection();
// 输入流
is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
//下载路径及下载图片名称
String filename = "D:\\图片下载/ " + text + ".jpg";
File file = new File(filename);
// 输出的文件流
os = new FileOutputStream(file, true);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
System.out.println("正在下载--->" + picture);
}
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
try {
//关闭资源
if(os!=null) os.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
try {
//关闭资源
if(is!=null) is.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
执行过程如下:
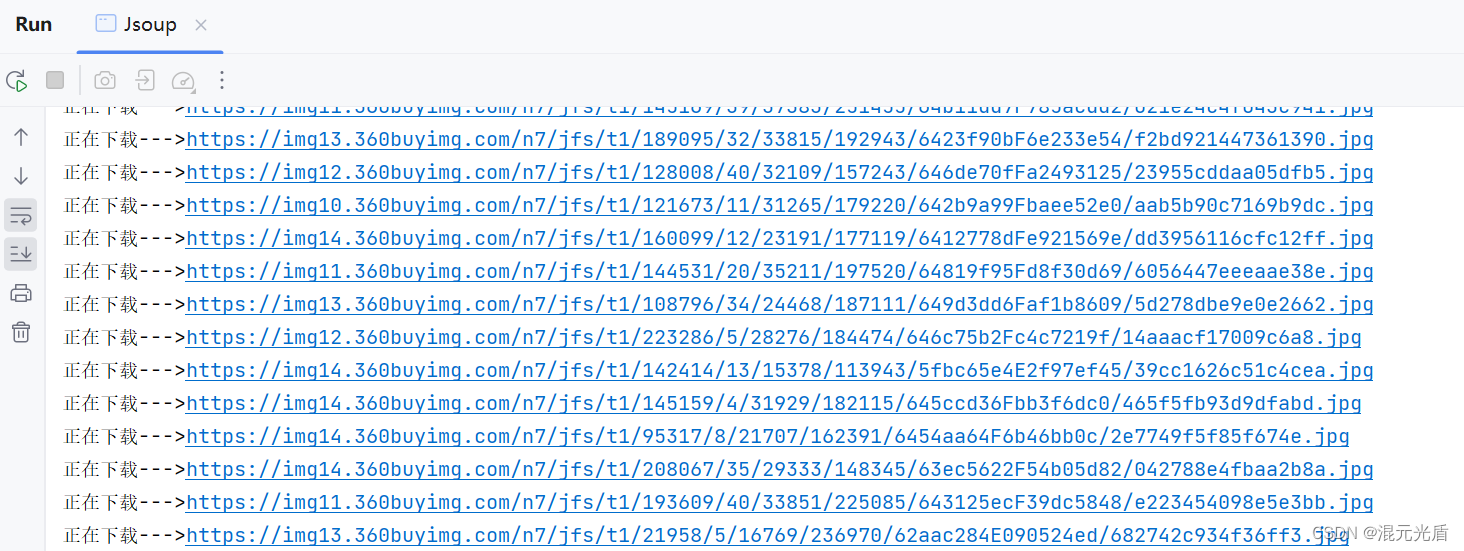
数据爬取成功!
最后,关于Jsoup的一些其他API或者方法,可以去查看官方文档,也可以去查看这位博主的一篇博客,个人觉得挺不错的。
















 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











