







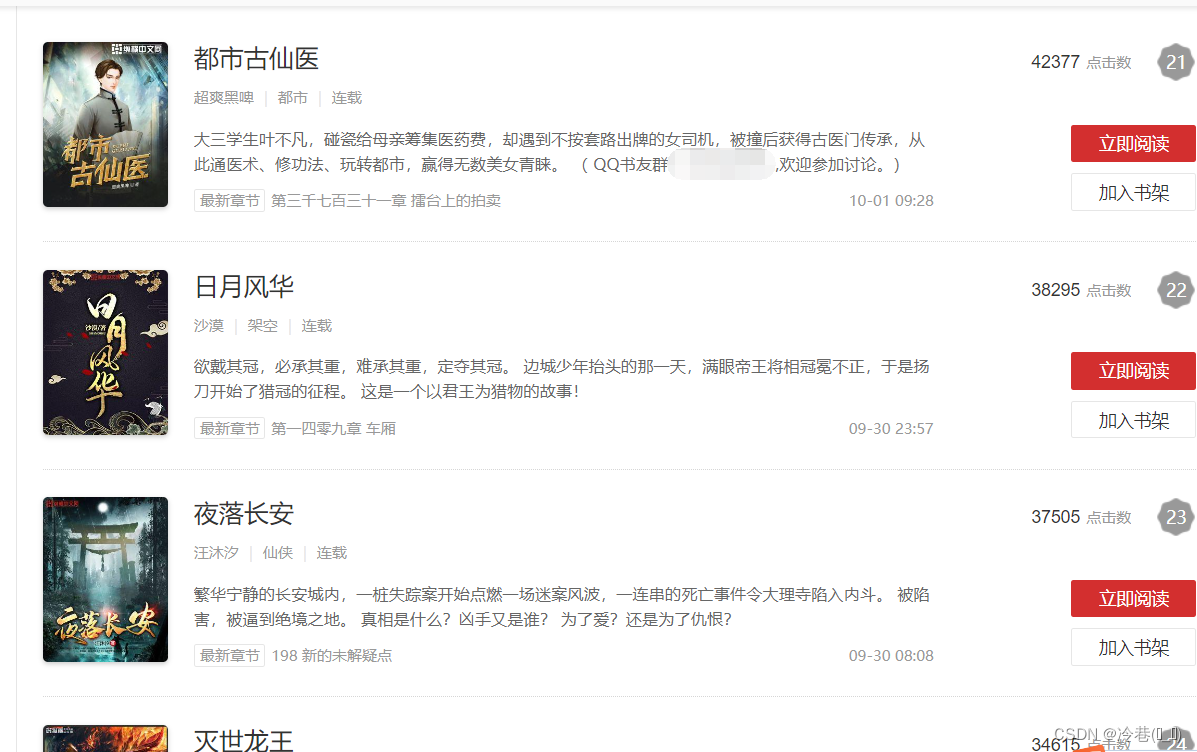
目标
aHR0cHMlM0EvL3d3dy56b25naGVuZy5jb20vcmFuay9kZXRhaWxzLmh0bWwlM0ZydCUzRDUlMjZkJTNEMSUyNnAlM0Qy
来到页面
先请求再说
import requests
def dowmload_one_page(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
resp = requests.get(url=url,headers=header)
print(resp.text)
if __name__ == '__main__':
dowmload_one_page('https://www.xxxxxxxx.com/rank/details.html?rt=5&d=1&p=2')
没有乱码,然后到页面分析去
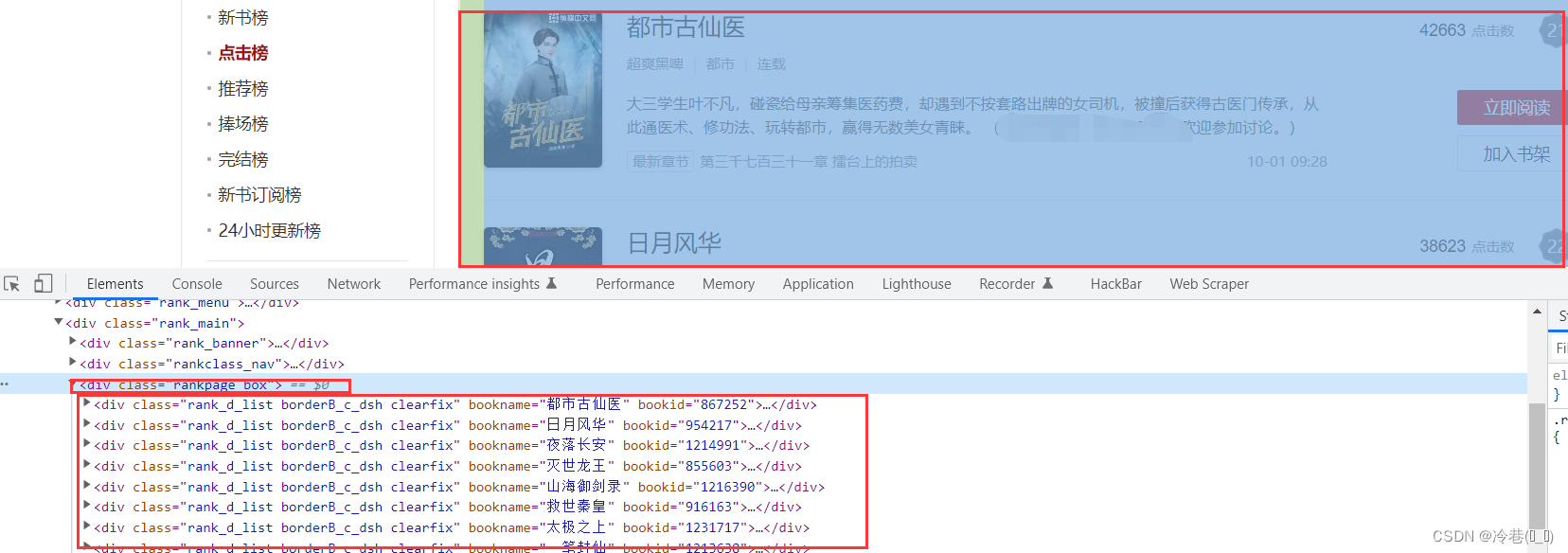
所有的学习都在这个大的div里面
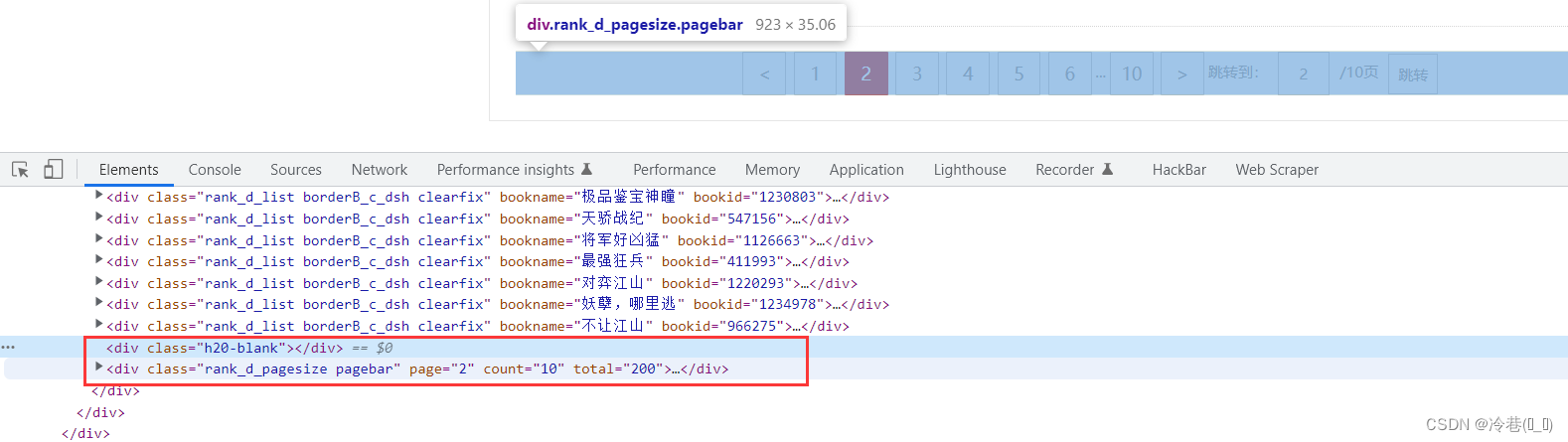
拉到最后面会看到俩个没有用的div,可以去掉
导入库
from lxml import etree定位到列表
html = etree.HTML(resp.text)
div_list = html.xpath('/html/body/div[2]/div[4]/div[2]/div[3]')[0] # 加个0给它整成列表
divs = div_list.xpath('./div')[:-2] # 后面多了来个列表,不是需要的
print(len(divs))
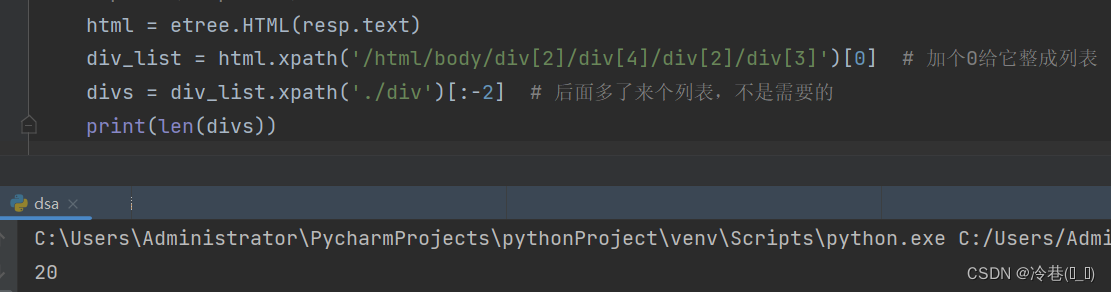
一共有20个
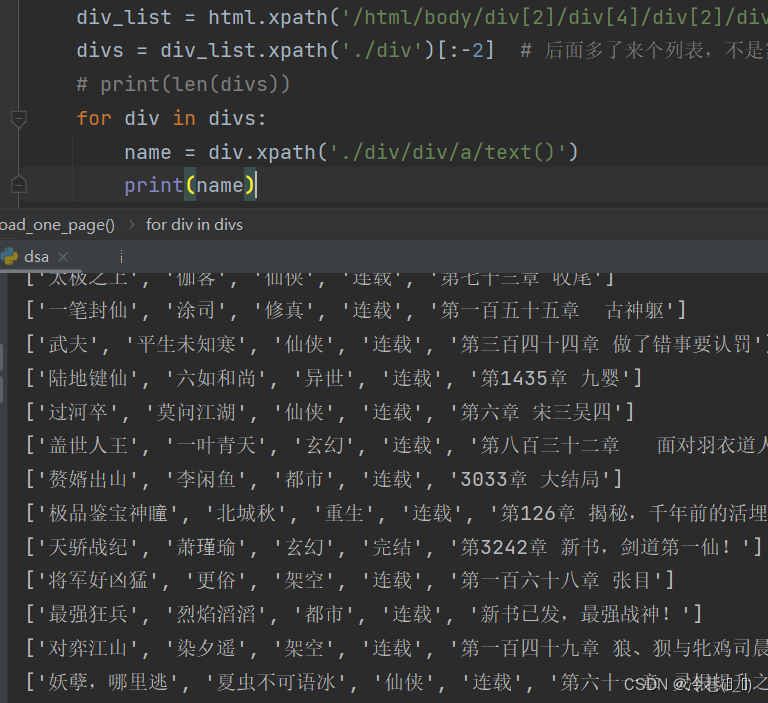
全部提取出来
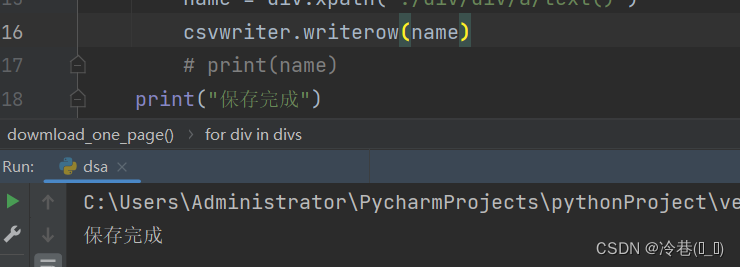
保存一下
import requests,csv
from lxml import etree
f = open("da.csv",mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
def dowmload_one_page(url):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
resp = requests.get(url=url,headers=header)
# print(resp.text)
html = etree.HTML(resp.text)
div_list = html.xpath('/html/body/div[2]/div[4]/div[2]/div[3]')[0] # 加个0给它整成列表
divs = div_list.xpath('./div')[:-2] # 后面多了来个列表,不是需要的
# print(len(divs))
for div in divs:
name = div.xpath('./div/div/a/text()')
csvwriter.writerow(name)
# print(name)
print("保存完成")
if __name__ == '__main__':
dowmload_one_page('https://www.xxxx.com/rank/details.html?rt=5&d=1&p=2')
回到页面,可以看到一共是10页,如果是这样改代码
if __name__ == '__main__':
for i in range(1,11):
dowmload_one_page ('https://www.xxx.com/rank/details.html?rt=5&d=1&p={i}')
的话,会发现效率很低,贼慢,如果需要爬的页面很多的那种的话,可以挂电脑去看电视了,还有可能会出错,这时候我们就需要线程池了
导入库
from concurrent.futures import ThreadPoolExecutor修改代码如下
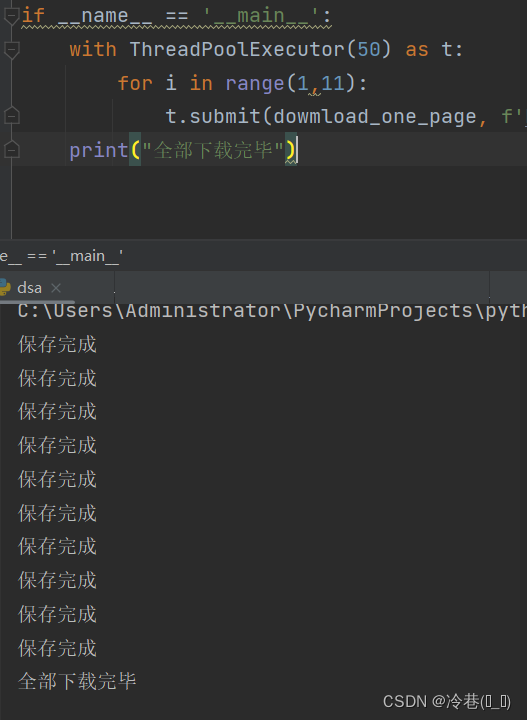
if __name__ == '__main__':
with ThreadPoolExecutor(50) as t:
for i in range(1,11):
t.submit(dowmload_one_page, f'https://www.xxxx.com/rank/details.html?rt=5&d=1&p={i}')
print("全部下载完毕")ThreadPoolExecutor(50)的意思是创建50个线程池,t.submit呢是把任务交给线程池
运行后瞬间完成,如果是单独的for循环估计要好几秒















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









