






1)使用的虚拟机为VMware Workstation Pro
1.2使用MobaXterm_Personal_22.1管理linux系统
1)MobaXterm主要用于操作linux系统,可以同时登录多态linux服务器进行操作。
(3) 安装jdk,解压缩 jdk-8u291-linux-x64.tar.gz到opt目录下
1)上传hadoop安装包hadoop-3.2.2.tar.gz到centeos的/opt目录下
3) 配置hadoop的环境变量将hadoop环境变量设置到/etc/profile文件中
- 配置安装hadoop环境
- 在虚拟机安装linux操作系统
1)使用的虚拟机为VMware Workstation Pro
- 新建虚拟机
(1)点击文件---新建虚拟机;点下一步

(2)点下一步

(3)点下一步

(4)客户机操作系统选:linux(L) ,版本选:centos 7 64位

(5)命名并选好位置后点下一步

(6)处理器数量选:2;内核数量选:2;点下一步

(7)使用8GB内存

(8)使用网络地址转换;点下一步

(9)点下一步
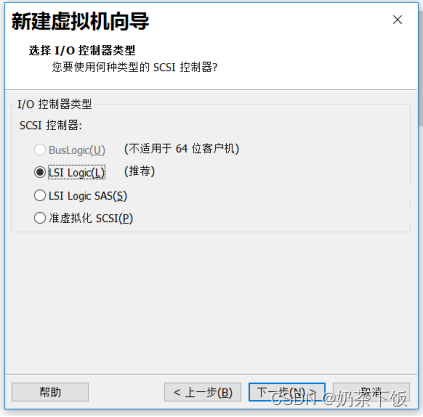
(10)点下一步
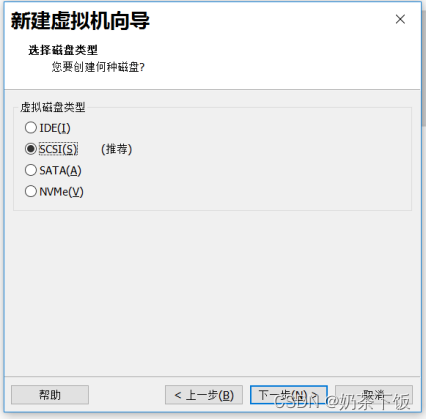
(11)点下一步

(12)将最大磁盘大小改成60;点下一步
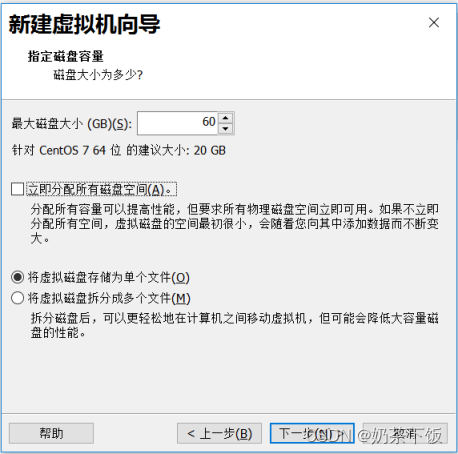
(13)点下一步,点完成

(14)点击编辑虚拟机,加载centeos操作系统的镜像安装文件,点击确定结束
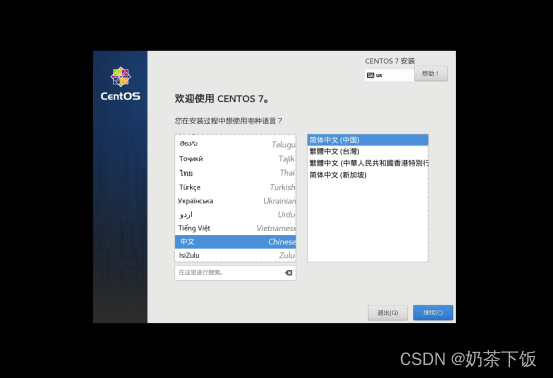
(15)点击开启此虚拟机,运行安装;等一会儿,出现此界面,选中文
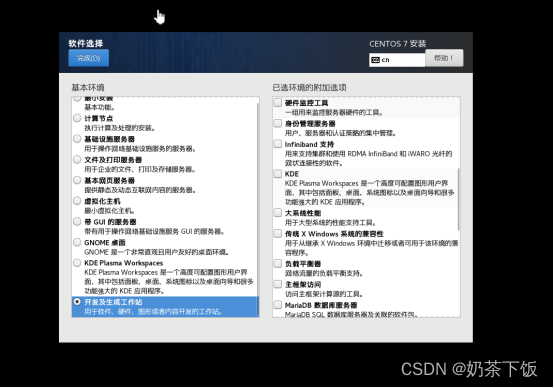
(16)软件选择:开发及生成工作站
(17)网络和主机名选已连接;点完成
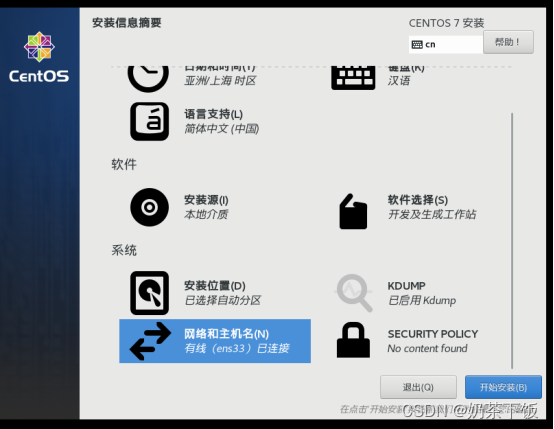
(18)设置 ROOT密码
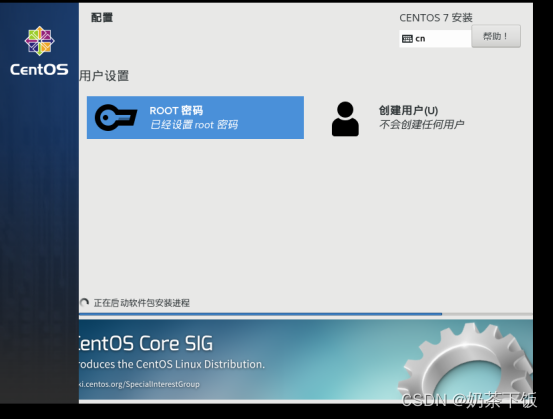
(19) 安装完后点重启,开启虚拟机
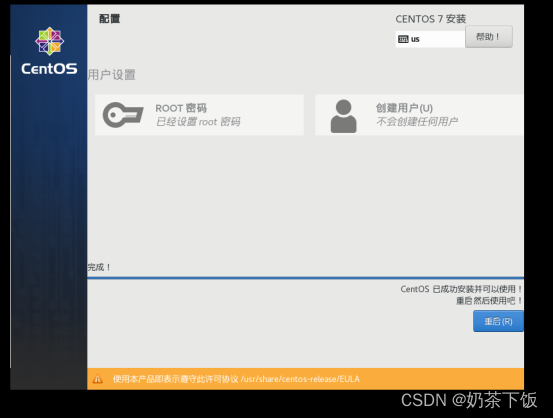

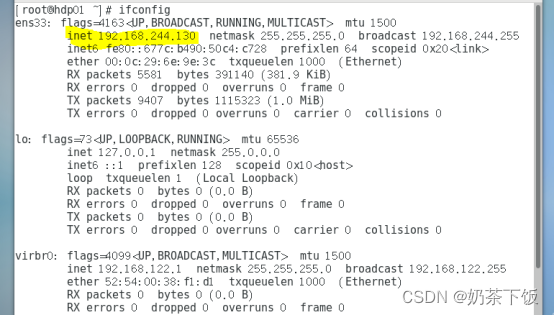
(20)查看ip地址(鼠标右键单击,点打开终端,输入:ifconfig)
1.2使用MobaXterm_Personal_22.1管理linux系统
1)MobaXterm主要用于操作linux系统,可以同时登录多态linux服务器进行操作。
2)使用MobaXterm登录linux系统
(1)在虚拟机查看ip和ssh服务是否启动
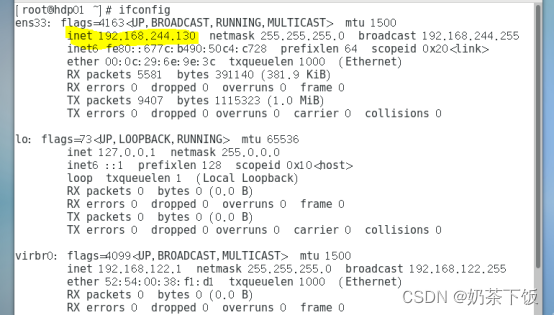
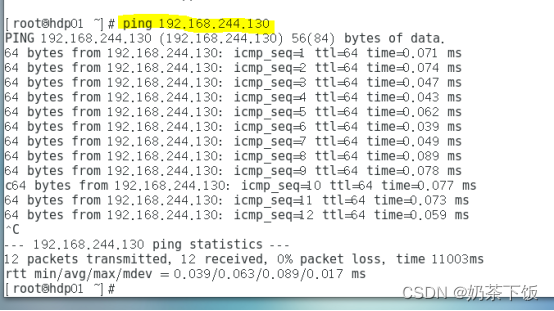
(2)使用ping命令查看外网是否能够访问:

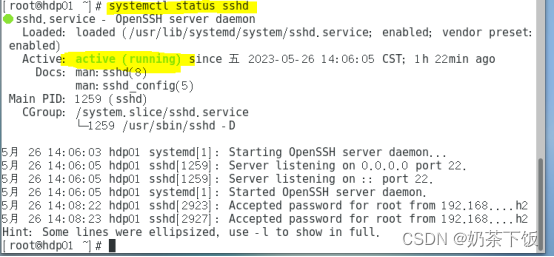
(3)使用systemctl status sshd查看会话服务是否启动
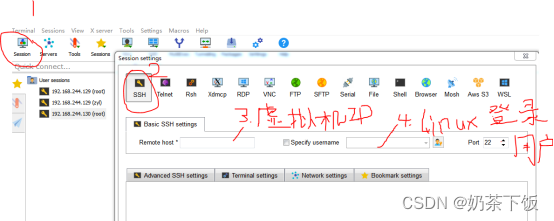
(4)双击MobaXterm进入MobaXterm系统

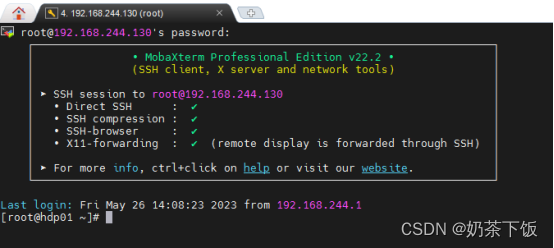
(5)使 用MobaXterm登录linux系统

(6)输入密码,登录成功:
1.3 jdk的安装步骤
1)卸载原有的jdk
(1)查看当前环境下已安装的jdk
rpm -qa | grep 安装包名称 (查看安装包的指令)
rpm -qa | grep java

(2)卸载已经安装的jdk
rpm -e --nodeps 要卸载的安装包名称
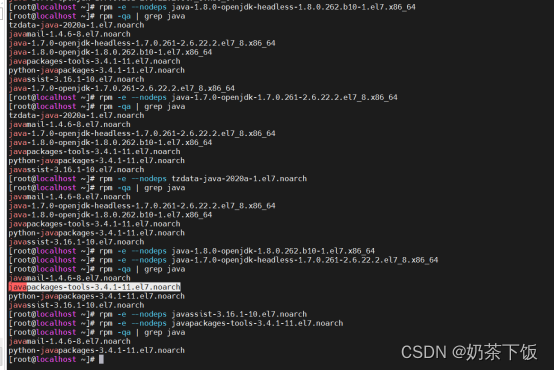
输入java看到未找到命令的提示,表示卸载完成

(3) 安装jdk,解压缩 jdk-8u291-linux-x64.tar.gz到opt目录下
tar -zxvf jdk-8u291-linux-x64.tar.gz

(4) 配置jdk的环境变量
vi /etc/profile
加入以下内容:
export JAVA_HOME=jdk的安装路径
export PATH=$PATH:$JAVA_HOME/bin
当前jdk的安装路径为:/opt/jdk1.8.0_291
export JAVA_HOME=/opt/jdk1.8.0_291
export CLASSPATH=.:$JAVA_HOME
export PATH=$PATH:$JAVA_HOME/bin

按下esc,输入:wq存盘退出
(5) 配置文件生效
source /etc/profile
输入java -version

环境变量配置完成
Javac MyClass.java
Java MyClass

1.4大数据Hadoop环境的安装配置
1)上传hadoop安装包hadoop-3.2.2.tar.gz到centeos的/opt目录下

(1)tar -zxvf hadoop-3.2.2.tar.gz

- 解压缩以后的目录

- 加压缩后进入hadoop-3.2.2/bin目录下,运行查看hadoop版本的命令
./hadoop version

- vi /etc/profile
内容如下:
# 增加hadoop环境变量
export HADOOP_HOME=/opt/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存后刷新下环境变量
source /etc/profile

- 验证,使用hadoop自带的词频统计组件,实现统计功能
使用news.txt文件作为词频统计的输入文件(数据源),放置到/opt/input目录下

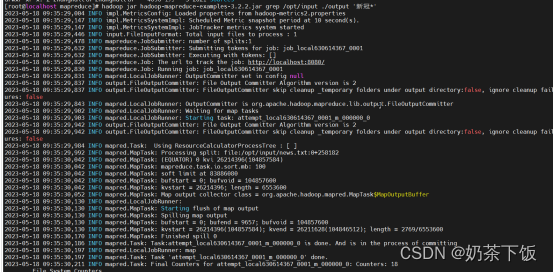
进入/opt/hadoop-3.2.2/share/hadoop/mapreduce文件夹运行词频统计命令
hadoop jar hadoop-mapreduce-examples-3.2.2.jar grep /opt/input ./output '新冠*'
(此命令用于统计/input/news.txt文件中统计’新冠’词组出现的次数。)

- 独立(本地)运行模式:
无需任何守护进程,所有的程序都运行在同一个JVM上执行。在独立模式下调试MR程序非常高效方便。所以一般该模式主要是在学习或者开发阶段调试使用 。
- 伪分布式模式:
Hadoop守护进程运行在本地机器上,模拟一个小规模的集群,换句话说,可以配置一台机器的Hadoop集群,伪分布式是完全分布式的一个特例。
- 完全分布式模式:
Hadoop守护进程运行在一个集群上
- 修改配置文件 core-site.xml
vi core-site.xml
内容如下:
| <configuration> <!--指定Hadoop运行时产生文件的存储目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop/tmp</value> </property> <!--指定HDFS中NameNode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop2:9000</value> </property> </configuration> |
vi hdfs-site.xml
| #搭建集群后,hadoop本身自带了一个webUI访问页面 <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
hdfs namenode -format
出现successfully表示格式化成功

进入/opt/hadoop-3.2.2/sbin目录

运行
./start-dfs.sh
出现以下错误
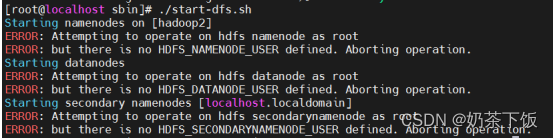
表示执行用户身份错误,修改/etc/profile文件,增加以下配置
vi /etc/profile
| export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
再次运行,出现以下错误,需要修改主机名称
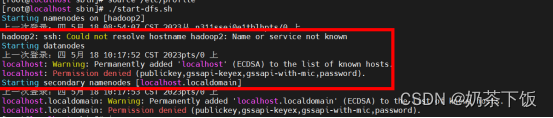
修改主机名
| vi /etc/sysconfig/network
|
修改/etc/hosts文件
vi /etc/hosts

重新启动服务器
SSH安装免密登陆
设置无密码登录
| #~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/” cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权 chmod 600 ./authorized_keys # 修改文件权限 |

修改core-site.xml文件,变更为以下内容
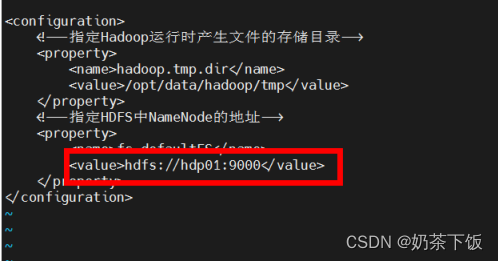
运行时出现jdk路径没有找到的错误,
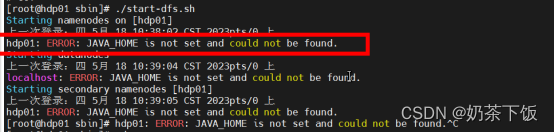
则修改/opt/hadoop-3.2.2/etc/hadoop/ hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_291
./start-dfs.sh
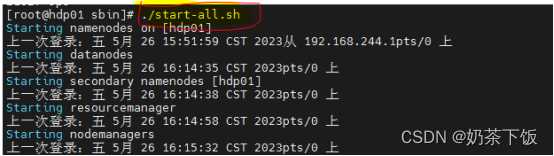
使用jps命令查看进程
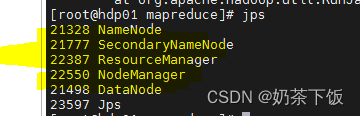

3)测试Hdfs文件系统
Hdfs---hadoop分布式文件系统
在hdfs上创建目录,使用以下命令创建目录
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/zrgj
hdfs dfs -mkdir /user/zrgj/input

- 配置yarn的jdk路径(jdk路径:/opt/jdk1.8.0_291)
进入/opt/hadoop-3.2.2/etc/hadoop目录,编辑yarn-env.sh
d /opt/hadoop-3.2.2/etc/hadoop
vi yarn-env.sh

- 配置yarn-site.xml(位于/opt/hadoop-3.2.2/etc/hadoop目录)
vi yarn-site.xml
| <configuration> <!--Reducer获取数据的方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- yarn的resourcemanager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hdp01</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration> |
- 配置 mapred-env.sh(/opt/hadoop-3.2.2/etc/hadoop目录)的jdk运行环境(jdk路径:/opt/jdk1.8.0_291)
vi mapred-env.sh

- .配置mapred-site.xml(/opt/hadoop-3.2.2/etc/hadoop目录)
vi mapred-site.xml
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hdp01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hdp01:19888</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration> |
- 启动yarn集群(进入/opt/hadoop-3.2.2/sbin目录)
启动resourcemanager(资源管理进程):
./yarn-daemon.sh start resourcemanager
启动nodemanager(服务器节点管理进程):
./yarn-daemon.sh start nodemanager
使用jps查看进程
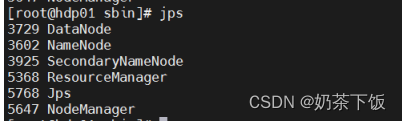
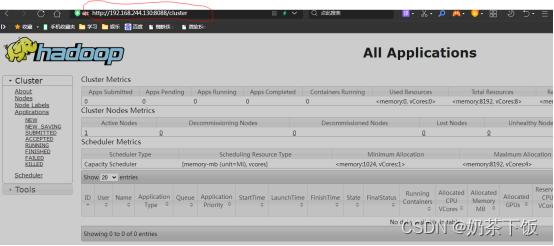
使用浏览器查看
例如:http://192.168.244.130:8088/
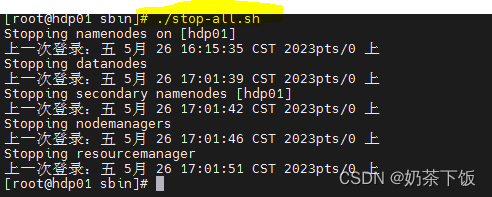
- 停止所有的服务
./stop-all.sh
启动所有的节点
./start-all.sh

- 配置历史服务器
配置mapred-site.xml
vi mapred-site.xml
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置历史服务器 --> <property> <name>mapreduce.jobhistory.address</name> <value>hdp01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hdp01:19888</value> </property> </configuration> |
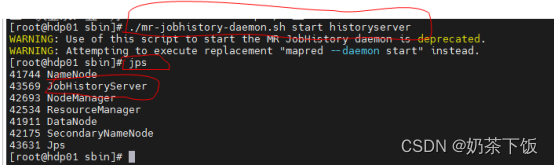
- 启动历史服务器(进入/opt/hadoop-3.2.2/sbin目录)
./mr-jobhistory-daemon.sh start historyserver
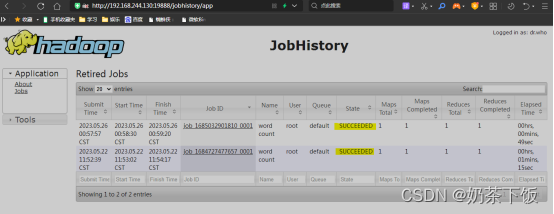
- 浏览查看历史服务器
http://自己centeos的ip地址:19888/
例如:
http://192.168.244.130:19888/

(1) 上传数据文件到hdfs文件系统中
hdfs dfs -put 本地目录的文件 hdfs://hdp01:9000/user/zrgj/input
例如:
hdfs dfs -put /opt/input/news.txt hdfs://hdp01:9000/user/zrgj/input

- 使用hadoop自带的词频统计组件hadoop-mapreduce-examples-3.2.2.jar执行词频统计
上传所有xml文件到hdfs系统
hdfs dfs -put /opt/input/news.txt /user/zrgj/input
执行词频统计:
hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /user/zrgj/input/news.txt /user/zrgj/output/

查看统计的结果:
hdfs dfs -tail /user/output/part-r-00000















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









