







目录
3.编写Spark Streaming程序使用Kafka数据源
1.下载依赖包
(1)下载spark-streaming-kafka-0-10_2.12-3.2.0.jar并拷贝到spark/jars/下:https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10_2.12/3.1.1
(2)下载spark-token-provider-kafka-0-10_2.12-3.2.0.jar并拷贝到spark/jars/下:
https://mvnrepository.com/artifact/org.apache.spark/spark-token-provider-kafka-0-10_2.12/3.1.1
(3)/home/Group10/kafka/kafka_2.12-3.0.0/libs/下的kafka-clients-3.0.0.jar拷贝到/home/Group10/spark/jars/下
cp /home/Group10/kafka/kafka_2.12-3.0.0/libs/kafka-clients-3.0.0.jar /home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/jars
2.启动zk和kafka
(1)启动zookeeper
zkServer.sh start(2)启动kafka
cd /home/Group10/kafka/kafka_2.12-3.0.0./bin/kafka-server-start.sh -daemon config/server.properties3.编写Spark Streaming程序使用Kafka数据源
(1)编写生产者(Producer)程序
请新打开一个终端,然后,执行如下命令创建代码目录和代码文件:
cd /home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/mycode
mkdir kafka
cd kafka
mkdir -p src/main/scala
cd src/main/scala
vim KafkaWordProducer.scala
代码如下:
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object KafkaWordProducer {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordProducer <metadataBrokerList> <topic> " +
"<messagesPerSec> <wordsPerMessage>")
System.exit(1)
}
val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args
// Zookeeper connection properties
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
// Send some messages
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).
toString)
.mkString(" ")
print(str)
println()
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
}
Thread.sleep(1000)
}
}
}
(2)编写消费者(Consumer)程序(vim KafkaWordCount.scala)
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object KafkaWordCount{
def main(args:Array[String]){
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
sc.setLogLevel("ERROR")
val ssc = new StreamingContext(sc,Seconds(10))
ssc.checkpoint("file:///home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/mycode/kafka/checkpoint") //设置检查点,如果存放在HDFS上面,则>写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动Hadoop
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "10.103.105.94:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("wordsender")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd => {
val offsetRange = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value))
val lines = maped.map(_._2)
val words = lines.flatMap(_.split(" "))
val pair = words.map(x => (x,1))
val wordCounts = pair.reduceByKey(_+_)
wordCounts.foreach(println)
})
ssc.start
ssc.awaitTermination
}
}
(3)编译打包
cd /home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/mycode/kafka
vim simple.sbt
内容如下:
name := "Simple Project"
version := "1.6.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.1.1"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.1.1" % "provided" libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.1.1"
libraryDependencies += "org.apache.kafka" % "kafka-clients" % "3.0.0"
在该目录下编译打包:
/home/Group10/sbt/sbt/sbt package(4)运行
新开一个终端运行生产者程序,在/home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/mycode/kafka目录执行如下命令:
/home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/bin/spark-submit --class "KafkaWordProducer" ./target/scala-2.12/simple-project_2.12-1.6.1.jar 10.103.105.94:9092 wordsender 3 5在打开一个终端运行消费者程序,执行如下命令;
/home/Group10/spark-3.1.1/spark-3.1.1-bin-hadoop2.7/bin/spark-submit --class "KafkaWordCount" ./target/scala-2.12/simple-project_2.12-1.6.1.ja消费的结果:
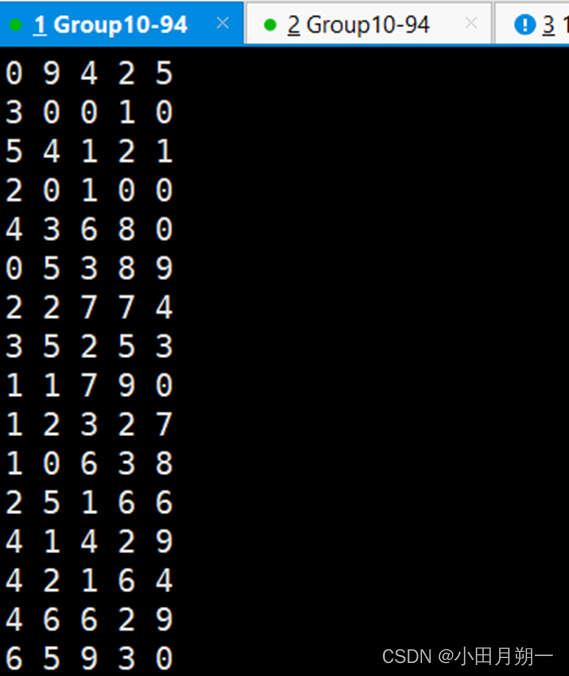















 7406
7406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









