







【1】案例背景
随着推特和微信等社交网络平台的流行,越来越多的青少年用户会在这些平台发布信息。这些数据能够反映青少年的行为兴趣,结合平台上用户的性别、年龄等信息,对于挖掘青少年细分市场具有很大价值。
【2】方法陈述
K-Means是一种基于欧式距离的聚类算法,它的基本思想是,通过迭代寻找K个簇(Cluster)的一种划分方案,使得聚类结果对应的损失函数最小。它的优点是:高效可伸缩,计算复杂度为接近于线性(N是数据量,K是聚类总数,t是迭代轮数);收敛速度快,原理相对通俗易懂,可解释性强。在此,采用K-means聚类实现青少年市场细分。
【3】实验代码
步骤一
#读取数据查看数据特征
teenager_sns <- read.csv("C:/Users/17909/Desktop/teenager_sns.csv")
summary(teenager_sns)
sum(is.na(teenager_sns$gender))
sum(is.na(teenager_sns$age))
步骤二
#数据预处理
#处理异常值和缺失值
teenager_sns$age <- ifelse(teenager_sns$age >= 13 & teenager_sns$age < 20,
teenager_sns$age, NA)
summary(teenager_sns$age)
#进行虚拟编码
teenager_sns$female <- ifelse(teenager_sns$gender == "F" &
!is.na(teenager_sns$gender), 1, 0)
teenager_sns$no_gender <- ifelse(is.na(teenager_sns$gender), 1, 0)
table(teenager_sns$gender, useNA = "ifany")
table(teenager_sns$female, useNA = "ifany")
table(teenager_sns$no_gender, useNA = "ifany")
#均值插补
mean(teenager_sns$age, na.rm = TRUE) # works
aggregate(data = teenager_sns, age ~ gradyear, mean, na.rm = TRUE)
ave_age <- ave(teenager_sns$age, teenager_sns$gradyear,
FUN = function(x) mean(x, na.rm = TRUE))
teenager_sns$age <- ifelse(is.na(teenager_sns$age), ave_age, teenager_sns$age)
summary(teenager_sns$age)
步骤三
#训练模型
interests <- teenager_sns[3:40]
interests_z <- as.data.frame(lapply(interests, scale))
set.seed(2345)
teen_clusters <- kmeans(interests_z, 5)
teen_clusters$size
步骤四
#结果分析
teen_clusters$centers
hist(teen_clusters$centers)
【4】结果分析
读取数据查看数据特征,发现age和gender有缺失值,如图1所示,查看缺失值个数,发现gender缺失2724个,age缺失5086个。
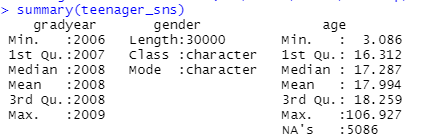
|
图1 数据特征 |
同时发现age最小值为3.086,最大值为106..927,显然不符合实际,因此将age>20或age<13的值视为异常值,将异常值赋值为NA。接着对age使用均值插补,age新的特征结果如图2所示。

|
图2 均值插补后age的数据特征 |
由于gender数据类型为character,所以对其进行虚拟编码,如图3所示。
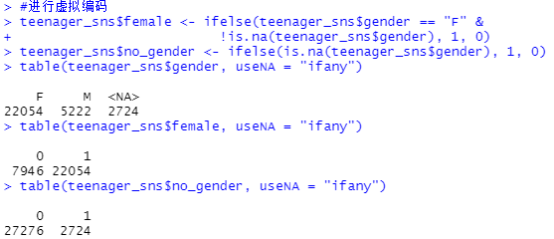
|
图3 对gender进行虚拟编码 |
对数据预处理结束后,进行模型的训练,在此,将细分市场的个数设置为5,每一个类中样本的数目如图4所示。

|
图4 K-means中每一类样本的数目 |
观察每一类的聚类中心,如图5所示, 如果聚类中心在某一个变量取值大于0,代表该聚类所代表的群体在该变量取值大于群体平均水平,由此,可分析聚类所代表的群体。

|
图5 每一类的聚类中心 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











