







引言
在前一博客中我大致完成了对archive概述的学习。接下来我将在本篇博客中开始对cbtree文件夹内容的学习和解读。 文件路径 opengauss-server\src\gausskernel\storage\access\cbtree
本篇为cbtree文件夹下cbtreee.cpp内容。
主要对cbtreecanreturn、cbtreeoptions、cbtreegettuple、InsertToBtree四个函数做代码注释,以及相关知识点做延拓介绍。
B-tree
B-tree,全名为平衡多路查找树(Balanced Tree),是数据库索引的一种常见类型,可以为各种查询类型提供高效的数据访问。它们在处理大量数据时特别有用,并提供对数搜索时间。通过一次处理多个元组,可以提供显著的性能优势。例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2)logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
openGauss的前身PostgreSQL使用的也是B-tree索引。B-tree索引适合比较查询和范围查询,当查询条件使用 (>,=,<,>=,<=)时,可以使用B-tree索引。B-tree索引是PostgreSQL和openGauss的默认索引方式。总的来说,B-tree索引提供了一种在硬盘和分区之上的薄软件层,创建了连续性和易用性的抽象,使得管理硬盘替换、重新分区和备份变得更加容易。
B树的主要特点包括:
- 所有叶子节点都在同一层。
- B树由最小度数’t’定义。’t’的值取决于磁盘块大小。
- 除根节点外,每个节点必须至少包含t-1个键。根节点至少包含1个键。
- 所有节点(包括根)最多可以包含(2*t - 1)个键。
- 节点的子节点数等于其键数加1。
- 所有节点的键都按升序排序。
- 两个键k1和k2之间的子节点包含所有在k1和k2范围内的键 如下图所示是一个B树
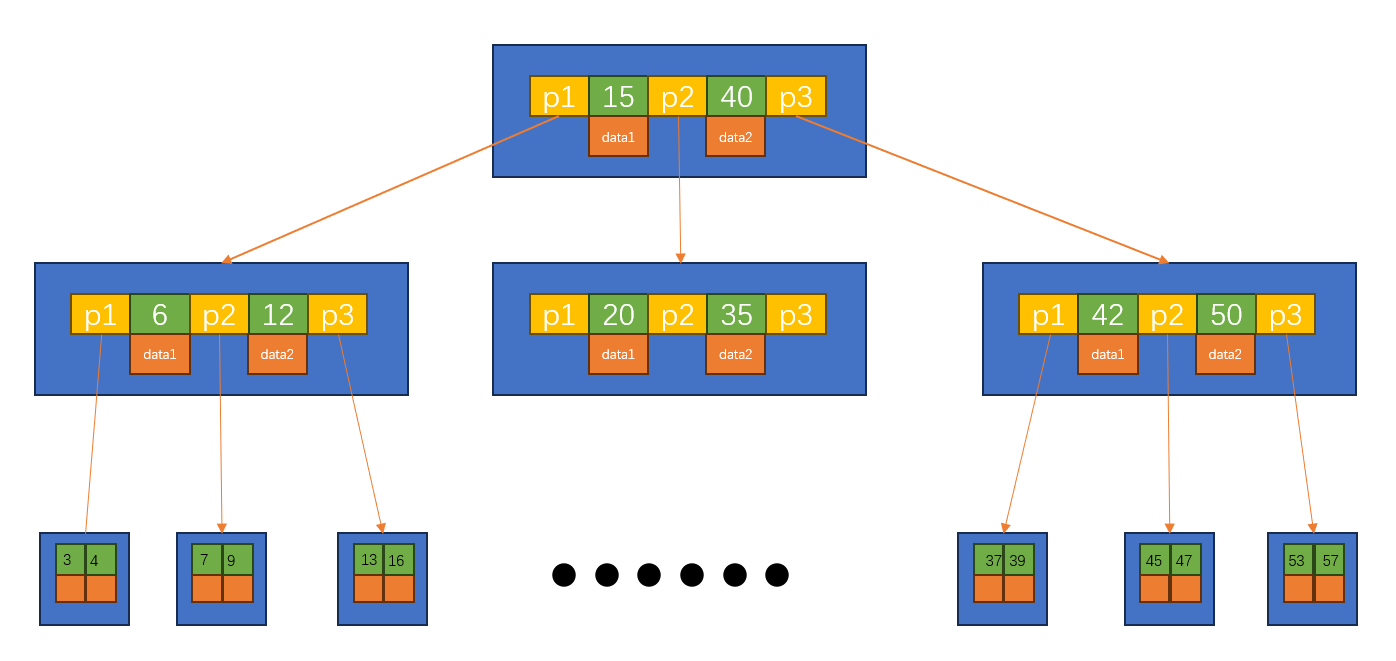
参考链接:https://en.wikipedia.org/wiki/B-tree,可以获得B-tree更多理论知识。 参考链接:B-Tree Visualization,可以手动逐个添加结点,体会B-tree的建立过程。
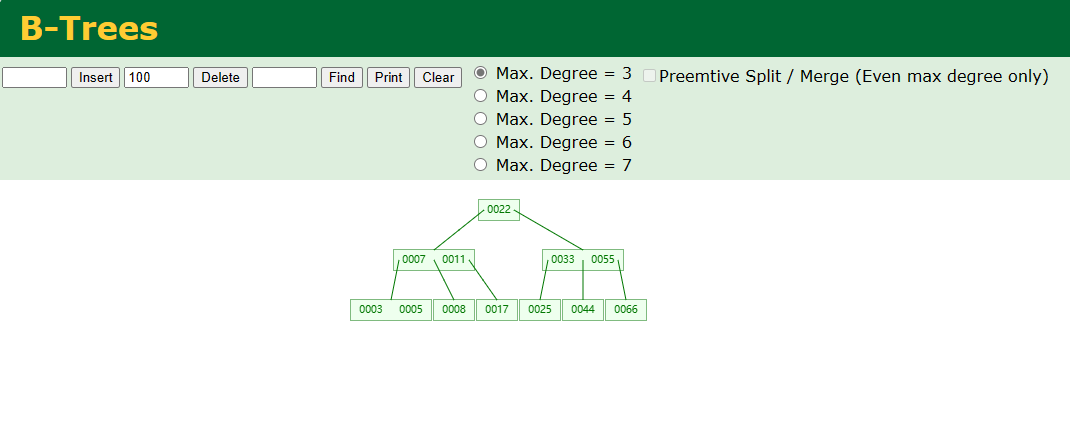
以下是相关函数源码以及代码注释
FunctionName:cbtreecanreturn 这是一个名cbtreecanreturn的C函数。传入一个结构体指针,通过多次宏展开,宏函数调用,以返回了指定类型值。以下为完整源码和注释内容:
Datum cbtreecanreturn(PG_FUNCTION_ARGS){PG_RETURN_BOOL(true);}
FunctionName:cbtreeoptions 这是一个名cbtreeoptions的C函数。函数的作用是获取B-tree索引的选项,并根据需要进行验证。如果选项有效,则返回这些选项;否则,返回NULL。以下为完整源码和注释内容:
/*function name:cbtreeoptionsdescription:This function is part of handling the CBTree index.Note: The main process is as follows:STEP1:To get the default relationship options, if the `validate` parameter is true, then the `default_reloptions` function will validate the validity of the options.STEP2:If filledOption is null,return Datum(0),else return Datum(filledOption)date: 2023/9/17*/Datum cbtreeoptions(PG_FUNCTION_ARGS){Datum indexRelOptions = PG_GETARG_DATUM(0);bool validate = PG_GETARG_BOOL(1);bytea *filledOption = default_reloptions(indexRelOptions, validate, RELOPT_KIND_CBTREE);//To get the default relationship options, if the `validate` parameter is true, then the `default_reloptions` function will validate the validity of the options.if (filledOption != NULL)PG_RETURN_BYTEA_P(filledOption);PG_RETURN_NULL();}
FunctionName:cbtreegettuple 这是一个名cbtreegettuple的C函数。这个函数的作用是获取B-tree索引的元组,并根据扫描方向进行处理。如果扫描描述符为NULL,或者获取元组时出现错误则返回错误信息。以下为完整源码和注释内容:
/*function name:cbtreegettupledescription:This function is part of handling the CBTree index.Note: The main process is as follows:STEP1:The function first checks whether the scan parameter is NULL. If it is, it will report an error and exit.STEP2:The function calls the _bt_gettuple_internal function to get the tuple.And returns a boolean value indicating whether the tuple was successfully obtained.STEP3:The cbtreegettuple function returns the result of the _bt_gettuple_internal functiondate: 2023/9/17*/Datum cbtreegettuple(PG_FUNCTION_ARGS){IndexScanDesc scan = (IndexScanDesc)PG_GETARG_POINTER(0);ScanDirection dir = (ScanDirection)PG_GETARG_INT32(1);if (scan == NULL)ereport(ERROR,(errcode(ERRCODE_INVALID_PARAMETER_VALUE), errmsg("Invalid arguments for function cbtreegettuple")));bool res = _bt_gettuple_internal(scan, dir);PG_RETURN_BOOL(res);}
FunctionName:InsertToBtree 这是一个名InsertToBtree的C函数。他的作用时将数据插入到B-tree中。首先他从向量批处理中获取数据,然后对每一行进行处理,最后将每个元组插入到B-tree。以下为完整源码和注释内容:
/** Insert the vector batch into btree pool.* @IN param vecScanBatch: the prepared vector batch* @OUT param buildstate: include the btree pool to be insert* @IN param indexInfo: the index information* @OUT param reltuples: the number of tuples which have been inserted into btree* @IN param values: the container to use temprarily* @IN param isnulls: the container to use temprarily* @IN param transferFuncs: the transfer functions array*//*function name:InsertToBtreedescription:This function is part of handling the CBTree index.Note: The main process is as follows:STEP1:It gets the number of rows in the batch and adds this to reltuples.STEP2:For each row in the batch, it does the following:checking if the value is null. If it is, it sets the corresponding entry in isnulls to true. Otherwise, it sets it to false and converts the scalar value to a datum using the corresponding transfer function.And it gets the item pointer (tid) for the row.STEP3:It calls _bt_spool to add the tid and values to the B-tree spool.STEP4:add buildstate.indtuples.date: 2023/9/17*/static void InsertToBtree(VectorBatch *vecScanBatch, BTBuildState &buildstate, IndexInfo *indexInfo, double &reltuples,Datum *values, bool *isnulls, ScalarToDatum *transferFuncs){int rows = vecScanBatch->m_rows;ScalarVector *vec = vecScanBatch->m_arr;ScalarVector *sysVec = vecScanBatch->GetSysVector(SelfItemPointerAttributeNumber);reltuples += rows;for (int rowIdx = 0; rowIdx < rows; rowIdx++) {int i;ItemPointer tid;for (i = 0; i < indexInfo->ii_NumIndexAttrs; i++) {int32 colIdx = indexInfo->ii_KeyAttrNumbers[i] - 1;if (vec[colIdx].IsNull(rowIdx)) {isnulls[i] = true;} else {isnulls[i] = false;values[i] = transferFuncs[i](vec[colIdx].m_vals[rowIdx]);}}tid = (ItemPointer)(&sysVec->m_vals[rowIdx]);/* Fill btree spool */_bt_spool(buildstate.spool, tid, values, isnulls);buildstate.indtuples += 1;}}
Datum类型
opengauss中系统函数大量引用Datum类型进行传参,而这个作为对数据库修改最为基础的一部分。这里简单做一下介绍。Datum类型的主要优点是它提供了一种灵活的方式来处理各种不同的数据类型。例如,你可以使用Datum类型来表示整数、浮点数、字符串、日期时间等等。这使得你可以编写通用的函数和操作,而不需要为每一种可能的数据类型编写特定的代码。 Datum类型是opengauss系统函数大量引用的类型,其定义为:
typedef uintptr_t Datum;typedef unsigned long long uintptr;
可以在opengauss-server\src\include\postgre.h,中找的其定义
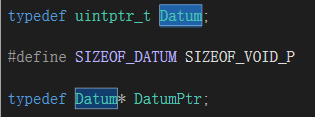
这里是将字符指针类型转换为无符号长整形。所以opengauss内部进行传参实际上并没有对指针进行传递,而是将指针转化为整形,然后进行传递。 对本篇博客涉及到的第一个函数cbtreecanreturn,我们通过VS的功能多次跳转,找到函数PG_RETURN_BOOL(true)最根本的定义如下
#define BoolGetDatum(X) ((Datum)((X) ? 1 : 0))
是一个宏定义,用于将布尔值转换为Datum类型。这个宏接受一个参数X,如果X为真(非零),则返回1,否则返回0。这个转换过程是通过三元运算符? :实现的。在这个宏中,Datum是一个可以表示各种数据类型的通用数据类型。 当X为真(或者说,当X的值为非零)时,这个宏会返回1。这在数据库系统中非常有用,因为它允许我们将布尔值存储在一个可以表示各种数据类型的通用数据类型(即Datum)中。这样,我们就可以使用相同的接口来处理不同的数据类型,从而简化代码并提高代码的可维护性。此外,由于这个宏是在编译时展开的,所以它不会引入额外的运行时开销。
Datum的特性
-
Datum的特性: Datum是一种通用数据表示形式,它可以用于存储和传递不同数据类型的值,包括整数、浮点数、字符串、日期时间等。它是open gauss内部使用的一种数据格式,通常不会直接在SQL中使用,而是在C语言函数中处理。
-
函数参数和返回值: 在opengauss中,当你定义一个函数时,你可以指定函数的参数和返回值的数据类型。然而,在函数内部,参数和返回值通常需要使用Datum类型来进行处理。这是因为函数可能需要处理多种不同的数据类型,Datum提供了一种通用的方式来表示这些值。
-
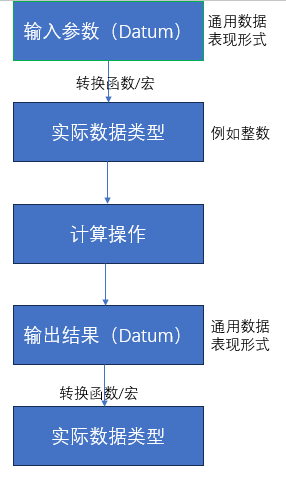
数据类型转换: 在函数内部,通常需要进行数据类型转换,将输入参数从Datum转换为实际的数据类型,或将计算结果从实际数据类型转换为Datum。opengauss提供了一组函数和宏来执行这些转换,例如DatumGetInt32用于将Datum转换为整数。如下图所示:
-
操作符函数: opengauss中的操作符函数(例如+、-、*、/等)通常使用Datum来表示输入参数和结果。这使得这些操作符可以适用于不同的数据类型,只要存在适当的数据类型转换函数。
-
系统函数和扩展: opengauss的系统函数和扩展通常也使用Datum来传递参数和处理结果。这使得系统函数可以与用户定义的数据类型和函数一起使用,从而增加了PG的灵活性和可扩展性
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









