







本文我们主要来介绍下字符串。
字符串主要有三种表示方式:普通字符串、原始字符串和长字符串。
1.普通字符串
用单引号 ' 或双引号 " 括起来的字符串
'Hello' 或 "Hello"
>>> 'Hello'
'Hello'
>>> "Hello"
'Hello'
>>> ss='\u0048\u0065\u006c\u006c\u006f'
>>> ss
'Hello'
>>> "Hello'world"
"Hello'world"
>>> 'Hello"world'
'Hello"world'常用的转义字符
| 字符表示 | Unicode编码 | 说明 |
| \t | \u0009 | 水平制表符 |
| \n | \u000a | 换行 |
| \r | \u000d | 回车 |
| \" | \u0022 | 双引号 |
| \' | \u0027 | 单引号 |
| \\ | \u005c | 反斜线 |
>>> s = 'Hello\n world'
>>> print(s)
Hello
world
>>> s = 'Hello\u000a World'
>>> print(s)
Hello
World
>>> s = 'Hello\t world'
>>> print(s)
Hello world
>>> s = 'Hello\" world'
>>> print(s)
Hello" world
>>> s = 'Hello\' world'
>>> print(s)
Hello' world
>>> s = 'Hello\\ world'
>>> print(s)
Hello\ world2.原始字符串
在实际的开发中,普通字符串中可能有很多转义符比较麻烦,可以使用原始字符串来表示,就是在普通字符串前面增加r即可。
>>> s = 'Hello\" world'
>>> print(s)
Hello" world
>>> s = r'Hello\t world'
>>> print(s)
Hello\t world3.长字符串
如果要使用字符串表示一篇文章,其中包含换行、缩减等排版字符,可以使用长字符串进行表示。用三个 ''' 或者三个 """ 括起来
>>> ss = """
... 大家好
... 今天是星期五
... 今天贴天气晴朗,温度30度
... 明天天气阴天,温度26度
... """
>>> print(ss)
大家好
今天是星期五
今天贴天气晴朗,温度30度
明天天气阴天,温度26度4.字符串与数字的相互转换
编程的过程中经常会遇到字符串与数字进行互相转换
a.字符串转换成数字
可以使用int()和float()实现,如果成功则返回数字,否则引发异常。
>>> int("80")
80
>>> int("80.0")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '80.0'
>>> float("90.0")
90.0
>>> int("AB")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'AB'
>>> int("AB",16)
171在默认情况下,int()函数將文字字符串参数当作十进制数字进行转换,所以int('AB')会失败。
b.將数字转换为字符串,可以用str()函数,str()函数可以將很多类型的数据都转换为字符串。
>>> str(123)
'123'
>>> money = 521.552
>>> type(money)
<class 'float'>
>>> str(money)
'521.552'
>>> str(True)
'True'5.格式化字符串
使用format()方法,不仅可以实现字符串的拼接,还可以格式化字符串,比如计算金额需要保留小数点后四位,数字需要右对齐等,可以用此方法。
a.想要將表达式的计算结构插入字符串,则需要占位符,对于占位符,我们用{}表示
>>> i = 32
>>> s = 'i * i = ' + str(i * i)
>>> s
'i * i = 1024'
>>> s = 'i * i = {}'.format(i * i)
>>> s
'i * i = 1024'
# 占位符可以有参数序号,序号从0开始,0被format()方法种的第1个参数替换;序号1被第2个参数替换
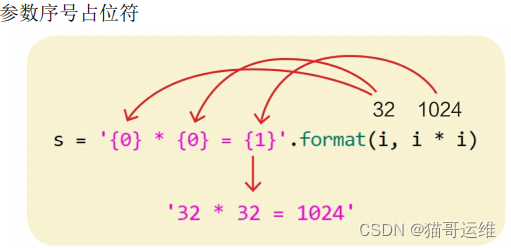
>>> s = '{0} * {0} = {1}'.format(i, i * i)
>>> s
'32 * 32 = 1024'
# 占位符中可以没有参数名,p1和p2是在format()方法种设置的参数名,可以根据参数名替换占位符
>>> s = '{p1} * {p1} = {p2}'.format(p1=i, p2=i * i)
>>> s
'32 * 32 = 1024'

b.格式化控制符
格式化控制符位于占位符索引或占位符名字的后面,之间用冒号分隔,
语法:{参数序号:格式控制符}或{参数名:格式控制符}。
| 格式控制符 | 说明 |
| s | 字符串 |
| d | 十进制整数 |
| f、F | 十进制浮点数 |
| g、G | 十进制整数或者浮点数 |
| e、E | 科学计数法表示浮点数 |
| o | 八进制整数,小写字符o |
| x、X | 十六进制整数,小写字母x,大写字母X |
>>> money = 7532.2551
>>> name = 'Tony'
>>> '{0:s}年龄{1:d}, 工资是{2:f}元。'.format(name, 20, money)
'Tony年龄20, 工资是7532.255100元。'
>>> '{0}年龄{1}, 工资是{2:0.2f}元。'.format(name, 20, money)
'Tony年龄20, 工资是7532.26元。'
>>> "{0}今天收入是{1:G}元。".format(name, money)
'Tony今天收入是7532.26元。'
>>> "{0}今天收入是{1:e}元。".format(name, money)
'Tony今天收入是7.532255e+03元。'
>>> "{0}今天收入是{1:E}元。".format(name, money)
'Tony今天收入是7.532255E+03元。'
>>> '十进制数{0:d}的八进制表示为{0:o}'.format(19)
'十进制数19的八进制表示为23'
>>> '十进制数{0:d}的十六进制表示为{0:x}'.format(19)
'十进制数19的十六进制表示为13'6.操作字符串
a.字符串的find()方法用于查找字符串
语法为str.find(sub[,start[,end]]),表示在索引start到end之间查找子字符串sub,如果找到,则返回最左端位置的索引;如果没找到,则返回-1。
>>> s_str = 'Hello world'
>>> s_str.find('e')
1
>>> s_str.find('l')
2
>>> s_str.find('l',4)
9
>>> s_str.find('l',4,6)
-1b.字符串替换
replace()
str.replace(old,new[,count]),表示new子字符串替换old子字符串,count指定替换old子字符串的个数,如果count被省略,则替换所有old子字符串。
>>> text = 'AB CD EF GH IJ'
>>> text.replace(' ','|',2)
'AB|CD|EF GH IJ'
>>> text.replace(' ','|')
'AB|CD|EF|GH|IJ'
>>> text.replace(' ','|',1)
'AB|CD EF GH IJ'c.字符串分割
split()
str.split(sep=None,maxsplit=-1),表示使用sep子字符串分隔字符串str,maxsplit是最大分割次数,如果maxsplit省略,则表示不限制分割次数。
>>> text = 'AB CD EF GH IJ'
>>> text.split(' ')
['AB', 'CD', 'EF', 'GH', 'IJ']
>>> text.split(' ',maxsplit=0)
['AB CD EF GH IJ']
>>> text.split(' ',maxsplit=1)
['AB', 'CD EF GH IJ']
>>> text.split(' ',maxsplit=2)
['AB', 'CD', 'EF GH IJ']本节示例
统计文章中单词出现的频率
# -*- coding: utf-8 -*-
"""
@Time: 2024/5/27 10:09
@File: tongji.py
@IDE: PyCharm
"""
# 一篇文章
wordstring = """
It was the best of times it was the worst of times.
it was the age of wisdom it was the age of foolishness.
"""
# 标点符号替换
wordstring = wordstring.replace('.', '')
# 分割单词
wordlist = wordstring.split()
wordfreq = []
for w in wordlist:
# 统计单词出现个数
wordfreq.append(wordlist.count(w))
d = dict(zip(wordlist, wordfreq))
print(d)
# 最终结果
{'It': 1, 'was': 4, 'the': 4, 'best': 1, 'of': 4, 'times': 2, 'it': 3, 'worst': 1, 'age': 2, 'wisdom': 1, 'foolishness': 1}















 2535
2535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











