







一.先复习之前学的DDL的
数据库操作(创建,查询,删除,使用数据库),表操作(创建,查询,修改,删除表)。
数据库操作:
create database[if not exist] +数据库名; //创建,中括号内可省略;
show databases; //查询所有数据库
select database(); //查询当前数据库
drop database[if not exist] +数据库名; //删除,中括号内可省略;
表操作:
create table +表名( //创建表
字段名 字段类型 comment '注释',
.....
.....)
comment '用户表';
show tables; //查询当前数据库的所有表
desc +表名; //查询表的结构
show create table+表明: //查询建表sql语句
alter table+表名 add +字段名 类型(长度) [comment]; //在表中添加字段
alter table+表名 change 旧字段名 新字段名 类型(长度) [comment];//修改字段名
alter table+表名 modify 字段名 新数据类型; //修改字段类型
alter table+表名 rename to+新表名; //修改表名
alter table+表名 drop+字段名; //删除字段名
drop table [if exist]+表名;//删除表
truncate table +表名;//删除指定表并重新创建该表
二.DML(数据操作语言):
对数据库表的数据记录进行增删改操作
我建立一张表格叫做emp,以下都是对此表格进行操作:

1.添加
insert into 表名 (字段名1,字段名2,....)values(值1,值2....) //字段名和值一一对应
insert into 表名 values(值1,值2....) //给全部字段名添加数据
insert into 表名 (字段名1,字段名2,....)values(值1,值2....) (值1,值2....) (值1,值2....) ..; //批量添加数据
insert into 表名 values(值1,值2....) (值1,值2....) (值1,值2....) .. ; //批量添加数据
2.修改
update 表名 set 字段名1=值1,字段名2=值2,...[where 条件]; //where条件可有可无,若无,会修改整张表的所有数据
3.删除
delete from 表名 [where 条件]; //where条件可有可无,若无,会删除整张表的所有数据,delete语句不能删除某个字段的值(可使用update)
DML实操datagrip代码(添加,修改,删除):
#truncate table emp;
#添加
insert into emp(id,name,workno,gender,age,idcard,entrydate) values(1,'周公','1','男',18,'12345678','2005-1-1'); #给指定字段添加数据
select * from emp; #展示表
insert into emp values(2,'张无忌','2','男',88,1738462,'2009-1-1'); #给全部字段添加数据
select * from emp; #展示表
select distinct name from emp;
select * from emp; #展示表
insert into emp(id,name,workno,gender,age,idcard,entrydate) values(3,'赵敏','3','女',23,'1839272x','2009-1-1'),(4,'赵小','4','女',22,'1839272x','2099-1-1');#批量添加数据
select * from emp; #展示表
insert into emp values(5,'敏儿','5','女',29,'1839272x','2001-1-1'),(6,'周芷若','6','女',44,'1839272x','2022-1-1');#批量添加数据
select * from emp; #展示表
#修改
update emp set name='钓鱼' where id=1; #修改id=1的name为'钓鱼'
select * from emp; #展示表
update emp set name='钓鱼',gender='女' where id=1; #修改id=1的name和gender
select * from emp; #展示表
update emp set entrydate='2010-1-1'; #修改所有员工的入职时间
select * from emp; #展示表
#删除
delete from emp where gender='女'; #删除gender='女'的数据
select * from emp; #展示表
delete from emp; #删除所有员工数据
select * from emp; #展示表三.DQL(数据查询语言):
1.基本查询
--查询多个字段
select 字段1,字段2,....from 表名;
select *from +表名;
--设置别名
select 字段1[as 别名1],字段2[as 别名2]...from 表名; //中括号内可省略
--去除重复记录
select distinct 字段列表 from 表名:
代码:
#查询指定字段
select name from emp;
select name,id,workno from emp;
select* from emp;
#设置别名
select workaddress as '工作地址' from emp;#将workaddress改名为'工作地址'
#查询员工工作地址不要重复
select distinct workaddress '工作地址' from emp;
2.条件查询
语法:
select 字段列表 from 表名 where 条件列表;
条件包括:比较运算符和逻辑运算符两大方面
代码:
#查询年龄<=77
select * from emp where age<=77;
#查询没有身份证号的员工
select *from emp where idcard is null ;
#查询有身份证号的员工
select *from emp where idcard is not null ;
#查询年龄不等于88的员工
select * from emp where age!=88;
#查询年龄在15-20(含)之间的员工
select * from emp where age<=20&&age>=15;
#另两种做法
select * from emp where age<=20 and age>=15;
select * from emp where age between 15 and 20;
#查询性别为女,年龄小于25岁的员工
select * from emp where age<=25&&gender='女';
#查询年龄为18或20或23的员工
select * from emp where age=18 or age=20 or age=23;
#另一种做法
select * from emp where age in(18,20,23);
#查询姓名只有两个字的员工
select * from emp where name like '__';
#查询身份证号最后一位是x的员工
select * from emp where idcard like '%x'; #%是什么意思忘记了,只记得语法3.聚合函数:一行数据作为一个整体,纵向计算
count,sum(对用户某字段名求和),max,min,avg(求平均)
select count(*) from emp;#利用count计算有多少员工
select count(idcard) from emp;#利用count计算有多少张idcard
select avg(age) from emp;#求所有员工年龄均值
select sum(age) age from emp;#求所有员工年龄总和,这里我起了一个别名叫age
select max(age) from emp;
select min(age) from emp;4.分组查询
语法:select 字段列表 from 表名 [where条件] group by 分组字段名 [having 分组后过滤条件];
where和having的区别:
--执行顺序不同:where先进行过滤,不满足where条件的更不用参与后面的分组,group by后利用having再次过滤
--判断条件不同:where 不能对聚合函数进行判断,而having可以(这里还不太懂)
#分组查询
select '性别' ,count(*) '数量' from emp group by gender;#根据性别分组,并统计男女员工数量#这里我犯了一个错误的
select gender '性别' ,count(*) '数量' from emp group by gender;#根据性别分组,并统计男女员工数量
select gender,avg(age) from emp group by gender;#根据性别分组,统计男女员工的平均年龄
#下面这一句注意执行顺序:from->where->group by->select,聚合函数->having
select workaddress ,count(*) count from emp where age<45 group by workaddress having count>=2; #查询年龄小于45,并根据工作地址分组,获取员工数量大于等于2 的工作地址
5.排序查询
语法:select 字段列表 from 表名 order by 字段1 排序方式1,字段2,排序方式2;
默认排序为升序asc,
#排序查询
select *from emp order by age asc; #根据年龄对公司员工升序
select *from emp order by age desc; #根据年龄对公司员工倒序
select *from emp order by age,entrydate desc; #根据年龄对公司员工升序,若age相同,则根据entrydate进行倒序6.分页查询
语法:select 字段列表 from 表名 limit 起始索引,查询记录数;
注意:起始索引从0开始,起始索引=(查询页码-1)*每页显示记录数;//这个是索引公式
不同数据库分页查询不同,datagrip用的是limit;
若查询的是第一页数据,起始索引可省略,直接简写为limit 10 ; //展示10条数据
#分页查询,为了方便查询,我向原表格插入多几条数据
select *from emp limit 0,10; #查询第一页员工数据,展示10条
#另一种写法
select *from emp limit 10;
select *from emp limit 10,10; #查询第二页员工数据每页展示10条,10,10是根据索引公式计算出的
总结DQL练习
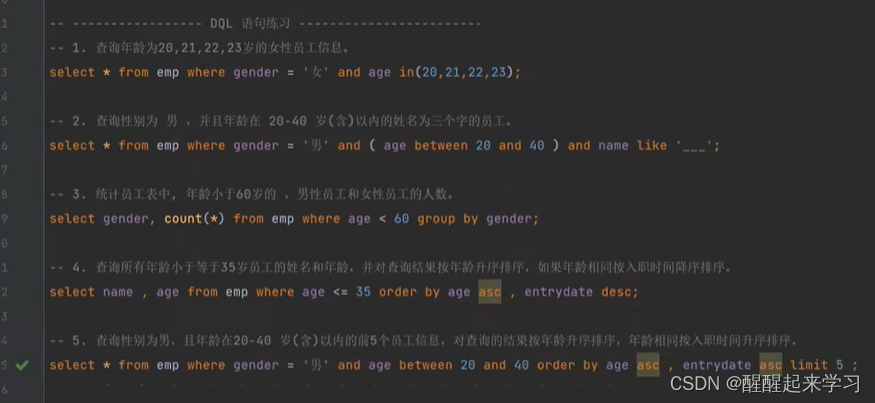

刚学习DQL需要注意语句的执行顺序,很重要!不然容易搞懵哦
先-------->后:
from->where->group by->select->having->order by->limit















 9622
9622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









