






常用API
Math类
帮助我们进行数学计算的工具类。
里面的方法都是静态的。
3.常见方法如下:
abs:获取绝对值 absExact:获取绝对值
ceil:向上取整 floor:向下取整 round:四舍五入
max:获取最大值 min:获取最小值
pow:获取a的b次幂 sqrt:开平方根 cbrt:开立方根
random:获取[0.0,1.0]之间的随机数
System类
工具类,提供了一些与系统相关的方法
时间原点: 1970,1月1日0:0:0,我国在东八区,有八个小时时差
1秒=1000毫秒
static void | arraycopy(Object src, int srcPos, Object dest, int destPos, int length) | 将指定源数组中的数组从指定位置开始复制到目标数组的指定位置。 src:数据源,要拷贝的数据从哪个数组来 srcPos:从数据源数组的第几个索引开始拷贝 dest:目的地,我要把数据拷贝到哪个数组中 destPos:目的地数组的索引 length:拷贝的个数 |
|---|
细节:
1.如果数据源数组和目的数组都是 基本数据类型,那么两者类型必须保持一致,否则会报错
2.在拷贝的时候需要考虑数组的长度,如果超出范围也会报错。
3.如果数据源数组和目的数组都是引用数据类型,那么子类类型可以赋值给父类类型
static long | currentTimeMillis() | 以毫秒为单位返回当前时间。 |
|---|
static void | exit(int status) | 终止当前运行的Java虚拟机 |
|---|
Runtime类
runtime 表示当前虚拟机的运行环境。只能有一个对象。
shutdown:关机,加上参数才能执行 -s :默认在1分钟之后关机-s -t 指定时间:指定关机时间
-a 取消关机操作 -r:关机并重启
Runtime.getRuntime().exec("shutdown -s -t 3600");-
-
longfreeMemory()返回Java虚拟机中的可用内存量。(单位byte)
-
-
-
longtotalMemory()返回Java虚拟机中的内存总量。(单位byte)
-
-
-
static RuntimegetRuntime()返回与当前Java应用程序关联的运行时对象。
-
-
-
longmaxMemory()返回Java虚拟机将尝试使用的最大内存量。(单位byte)
-
-
-
static RuntimegetRuntime()返回与当前Java应用程序关联的运行时对象。
-
-
-
voidexit(int status)通过启动其关闭序列来终止当前运行的Java虚拟机。
-
-
-
intavailableProcessors()返回Java虚拟机可用的处理器数。
获取cpu的线程数
-
object类
object是Java中的顶级父类。所有的类都直接或者间接的继承于object类
object类中的方法可以被所有子类访问,所以我们要学习object类和其中的方法。
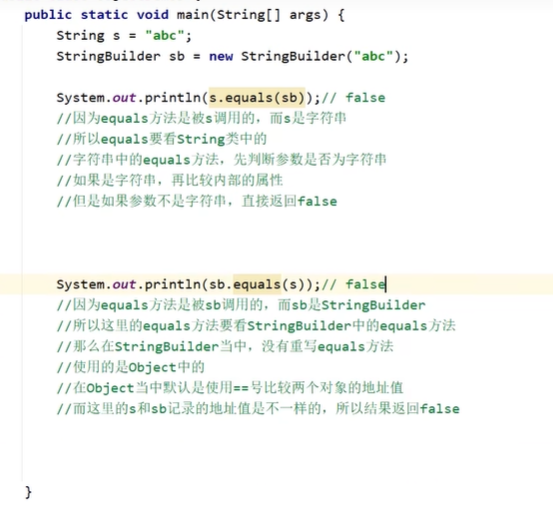
结论:
如果我们打印一个对象,想要看到属性值的话,那么就重写toString方法就可以了。再重写的方法中,把对象的属性值进行拼接。

底层中,equals是用 ==来比较地址值的,可以重写equals方法,可以快捷生成-按alt+insert
选equals()and hashCode() 。
对象克隆
把A对象的属性值完全拷贝给B对象,也叫对象拷贝,对象复制。
public static void main(String[] args) throws CloneNotSupportedException {
//1.先创建一个对象
Pet p1=new Pet("小狗");
//2.克隆
//细节:
//方法在底层会帮我们创建一个对象,并把原对象中的数据拷贝过去
//书写细节:
//1.重写Object类中的clone方法1
//2.让javabean类实现Cloneable接口
//3.创建原对象并调用clone就可以了。
Pet p2= (Pet) p1.clone();
System.out.println(p1);
System.out.println(p2);
}
----------------------------------------------
package com.htu.bean;
import java.util.Objects;
/*
* 宠物
* */
//Cloneable
//如果一个接口里面没有抽象方法
//表示当前的接口是一个标记性接口
//现在Cloneable表示一旦实现了,那么当前类的对象就可以被克隆
//如果没有实现,当前类的对象就不能克隆
public class Pet implements Cloneable{
private String name;
public Pet() {
}
public Pet(String name) {
this.name = name;
}
public String getName(){return name;}
public void setName(String name){this.name=name;}
@Override
public String toString(){
return "Pet{"+"'name='"+name+'\''+'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Pet pet = (Pet) o;
return Objects.equals(name, pet.name);
}
@Override
public Object clone() throws CloneNotSupportedException {
//调用父类中的clone方法
//相当于让个JAVA帮我们克隆一个对象,并把克隆之后的的对象返回出去。
return super.clone();
}
}
浅克隆与深克隆


浅克隆:不管对象内部属性是基本数据类型还是引用数据类型,都完全拷贝过来
深克隆:基本数据类型拷贝过来、字符串复用、引用数据类型会重新创建新的。
Object 中的克隆是浅克隆。
需要深克隆需要重写方法或者使用第三方工具类
package com.htu.bean;
import com.google.gson.Gson;
import com.htu.bean.Pet;
public class test01 {
public static void main(String[] args) throws CloneNotSupportedException {
//1.创建一个对象
int []data={1,2,3,4,5,6,7,8,9,10};
Pet p1=new Pet("小狗",data);
//2.克隆
Pet p2=(Pet)p1.clone();
int []arr= p1.getData();
// System.out.println(p1);
//System.out.println(p2);
//第三方工具
//1.第三方写的代码导入到项目中
//2.编写代码
Gson gson=new Gson();
//把对象变成一个字符串
String s=gson.toJson(p1);
//再把字符串变回对象就可以了
Pet pet=gson.fromJson(s,Pet.class);
//打印对象
arr[0]=100;
System.out.println(pet);
}
}
---------------------------------
package com.htu.bean;
import java.util.Objects;
import java.util.StringJoiner;
/*
* 宠物
* */
//Cloneable
//如果一个接口里面没有抽象方法
//表示当前的接口是一个标记性接口
//现在Cloneable表示一旦实现了,那么当前类的对象就可以被克隆
//如果没有实现,当前类的对象就不能克隆
public class Pet implements Cloneable{
private String name;
private int []data;
public Pet() {
}
public Pet(String name, int[] data) {
this.name = name;
this.data = data;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return data
*/
public int[] getData() {
return data;
}
/**
* 设置
* @param data
*/
public void setData(int[] data) {
this.data = data;
}
@Override
public String toString(){
return "角色编号为:"+name+arrToString();
}
public String arrToString(){
StringJoiner sj=new StringJoiner(",","[", "]");
for(int i=0;i<data.length;i++){
sj.add(data[i]+"");
}
return sj.toString();
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Pet pet = (Pet) o;
return Objects.equals(name, pet.name);
}
@Override
protected Object clone() throws CloneNotSupportedException {
//调用父类中的clone方法
//相当于让个JAVA帮我们克隆一个对象,并把克隆之后的的对象返回出去。
//转换成深克隆,方法一,重写方法---数组
//先把被克隆对象中的数组获取出来
int []data=this.data;
//创建新数组
int []newData=new int[data.length];
//拷贝数组中的数据
for (int i = 0; i < data.length; i++) {
newData[i]=data[i];
}
//调用父类中的方法克隆对象
Pet p=(Pet) super.clone();
//因为父类中的克隆方法是浅克隆,替换克隆出来对象中的数组地址值
p.data=newData;
return p;
}
}
总结:
1.toString():一般都会重写,打印对象时打印属性
2.equals():比较对象时会重写,比较对象属性值是否相同
3.clone():默认浅克隆
如果需要深克隆需要重写方法或者是使用第三方工具类。
Objects类
是一个对象工具类,提供了一些方法去完成一些功能。
BigInterger类
在java中,整数有四种类型:byte,short,int,long。
在底层占用字节个数:byte 1个字节 、short 2个字节、int 4个字节、long 8个字节。
构造方法
-
-
BigInteger(int numBits, Random rnd)构造一个随机生成的BigInteger,均匀分布在0到(2
numBits- 1)的范围内。
-
-
-
BigInteger(String val)将BigInteger的十进制字符串表示形式转换为BigInteger。
字符串中必须是整数,否则会报错。
-
-
-
BigInteger(String val, int radix)将指定基数中BigInteger的String表示形式转换为BigInteger
1.字符串中必须是整数,否则会报错。
2.字符串中的数字必须要跟进制吻合。
-
-
-
static BigIntegervalueOf(long val)返回一个BigInteger,其值等于指定的
long。静态方法获取BigInteger的对象,内部有优化。
细节:
1.能表示范围比较小,只能在long的取值范围之内,如果超出long的范围就不行。
2.在内部对常用的数字:-16~16进行了优化--提前把-16-16先创建好BigInter的对象,如果多次获取去不会重新创建新的对象。
-
总结:
1.对象一旦创建,内部记录的值不能改变。
2.如果BigInteger表示的数字没有超出long的范围,可以用静态方法获取。
3.如果BigInteger表示的数字超出long的范围,可以用构造方法获取
4.只要进行计算都会产生一个新的BigInteger对象。
方法:

package com.htu;
import java.math.BigInteger;
public class BigIntegerDemo2 {
public static void main(String[] args) {
// 创建BigInteger对象
BigInteger bd0=new BigInteger("12");
System.out.println(bd0);
//1.创建两个BigInteger的对象
BigInteger bd1=BigInteger.valueOf(100);
BigInteger bd2=BigInteger.valueOf(5);
//2.加法
BigInteger bd3=bd1.add(bd2);
System.out.println(bd3);
//3.除法,获取商和余数
BigInteger[] arr = bd1.divideAndRemainder(bd2);//0索引是商,1索引是余数
System.out.println(arr[0]+" "+arr[1]);
//4.比较是否相同
boolean result=bd1.equals(bd2);
System.out.println(result);
//5.次幂
BigInteger bd4=bd1.pow(2);
System.out.println(bd4);
//6.max-返回的是较大数的对象
BigInteger bd5=bd1.max(bd2);
System.out.println(bd5==bd1);
System.out.println(bd5==bd2);
//7.转为Int类型整数,超出范围数据有误
BigInteger bd6=BigInteger.valueOf(200L);
int i = bd6.intValue();
System.out.println(i);
}
}
BigDecimal
1.用于小数的精确计算
2.用来表示很大的小数

构造方法:
-
-
BigDecimal(double val)将
double转换为BigDecimal,它是double的二进制浮点值的精确十进制表示形式。
-
-
-
BigDecimal(String val)将
BigDecimal的字符串表示BigDecimal转换为BigDecimal。
-
-
-
static BigDecimalvalueOf(double val)转换一个
double成BigDecimal,使用double通过所提供的规范的字符串表示Double.toString(double)方法。
-
package com.htu;
import java.math.BigDecimal;
public class BigDecimalDemo2 {
public static void main(String[] args) {
//1.通过传递double类型的小数来创建对象
//细节:
//这种方式有可能是不精确的,所以不建议使用
/* BigDecimal bd1=new BigDecimal(0.01);
System.out.println(bd1);*/
//2.通过传递string表示的小数来创建对象
BigDecimal bd2=new BigDecimal("0.01");
System.out.println(bd2);
//3.通过静态方法获取对象
BigDecimal bd3=BigDecimal.valueOf(10);
System.out.println(bd3);
//细节
//1.如果要表示的数字不大,没有超出double的取值范围,建议使用静态方法
//2.如果要表示的数字大,超出double的取值范围,建议使用构造方法方法
//3.如果我们传递的是0~10之间的整数,包含0,包含10,那么方法会返回已经创建好的对象,不会重新nnew
}
}
方法:

package com.htu;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.math.RoundingMode;
public class BigIntegerDemo2 {
public static void main(String[] args) {
BigDecimal bd1=BigDecimal.valueOf(10.0);
BigDecimal bd2=BigDecimal.valueOf(3.0);
//1.加法
BigDecimal bd3= bd1.add(bd2);
System.out.println(bd3);
//2.除法
//细节:不能除尽的话会报错
/* BigDecimal bd4=bd1.divide(bd2);
System.out.println(bd4);*/
BigDecimal bd5=bd1.divide(bd2,2, RoundingMode.HALF_UP);
System.out.println(bd5);
}
}
正则表达式
1.校验字符串是否满足规则
2.在一段文本中查找满足要求的内容
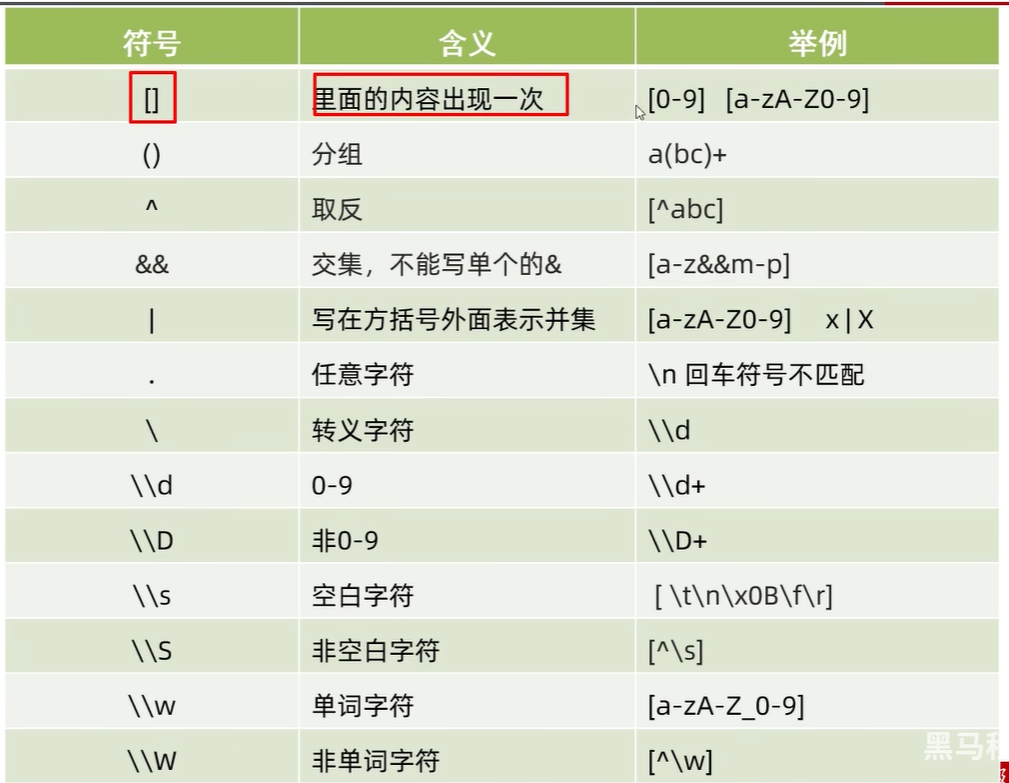
public boolean matches(String regex):判断是否与正则表达式匹配,匹配返回true1、字符类(只匹配一个字符)

eg:
package com.htu;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.math.RoundingMode;
public class BigIntegerDemo2 {
public static void main(String[] args) {
//一个[]只能匹配一个字符
//只能是a b c
System.out.println("-----------1------------");
System.out.println("a".matches("[abc]"));//true
System.out.println("z".matches("[abc]"));//false
System.out.println("zz".matches("[abc]"));//false
System.out.println("zz".matches("[abc][abc]"));//true
//不能出现a b c
System.out.println("-----------2------------");
System.out.println("a".matches("[^abc]"));//false
System.out.println("z".matches("[^abc]"));//true
System.out.println("zz".matches("[^abc]"));//false
System.out.println("zz".matches("[^abc][^abc]"));//true
//a到z A到Z(包括头尾的范围)
System.out.println("-----------3------------");
System.out.println("a".matches("[a-zA-Z]"));//true
System.out.println("z".matches("[a-zA-Z]"));//true
System.out.println("zz".matches("[a-zA-Z]"));//false
System.out.println("zz".matches("[a-zA-Z][a-zA-Z]"));//true
System.out.println("0".matches("[a-zA-Z]"));//false
//[a-d[m-p] a到d,或m到p
System.out.println("-----------4------------");
System.out.println("a".matches("[a-d[m-p]]"));//true
System.out.println("z".matches("[a-d[m-p]]"));//false
System.out.println("p".matches("[a-d[m-p]]"));//true
System.out.println("e".matches("[a-d[m-p]]"));//false
System.out.println("0".matches("[a-d[m-p]]"));//false
//[a-z&&[def]] a-z和def的交集 为 :d e f
//细节:如果要求两个范围的交集,那么需要写符号&&
//如果写成一个&,那么此时&表示就不是交集了,而是一个简简单单的&符号
System.out.println("-----------5------------");
System.out.println("a".matches("[a-z&&[def]]"));//false
System.out.println("a".matches("[a-z&[def]]"));//true
System.out.println("&".matches("[a-z&[def]]"));//true
System.out.println("f".matches("[a-z&&[def]]"));//true
System.out.println("0".matches("[a-z&&[def]]"));//false
//[a-z&&[^bc]] a-z和非bc的交集 等同于[ad-z]
System.out.println("-----------6------------");
System.out.println("a".matches("[a-z&&[^bc]]"));//true
System.out.println("b".matches("[a-z&&[^bc]]"));//false
System.out.println("0".matches("[a-z&&[^bc]]"));//false
//[a-z&&[^m-p]] a到z和除了m到p的交集 等同于[a-lq-z]
System.out.println("-----------7------------");
System.out.println("a".matches("[a-z&&[^m-p]]"));//true
System.out.println("m".matches("[a-z&&[^m-p]]"));//false
System.out.println("0".matches("[a-z&&[^m-p]]"));//false
}
}
2.预定义字符(只匹配一个字符)

\ 转义字符 改变后面那个字符原本的含义
package com.htu;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.math.RoundingMode;
public class BigIntegerDemo2 {
public static void main(String[] args) {
System.out.println("以下正则匹配只能校验单个字符");
System.out.println("----------------------------------");
//.表示任意一个字符
System.out.println("你".matches(".."));//false
System.out.println("你".matches("."));//true
System.out.println("你a".matches(".."));//true
// \\d只能是任意的一位数字
//简单来记:两个\表示一个\
System.out.println("a".matches("\\d"));//false
System.out.println("3".matches("\\d"));//true
System.out.println("33".matches("\\d"));//false
System.out.println("33".matches("\\d\\d"));//true
// \\w只能是一位单词字符 [a-zA-Z_0-9]
System.out.println("z".matches("\\w"));//true
System.out.println("2".matches("\\w"));//true
System.out.println("21".matches("\\w"));//false
System.out.println("你".matches("\\w"));//false
System.out.println("_".matches("\\w"));//true
// 非单词字符
System.out.println("你".matches("\\W"));//true
System.out.println("2".matches("\\W"));//false
}
}
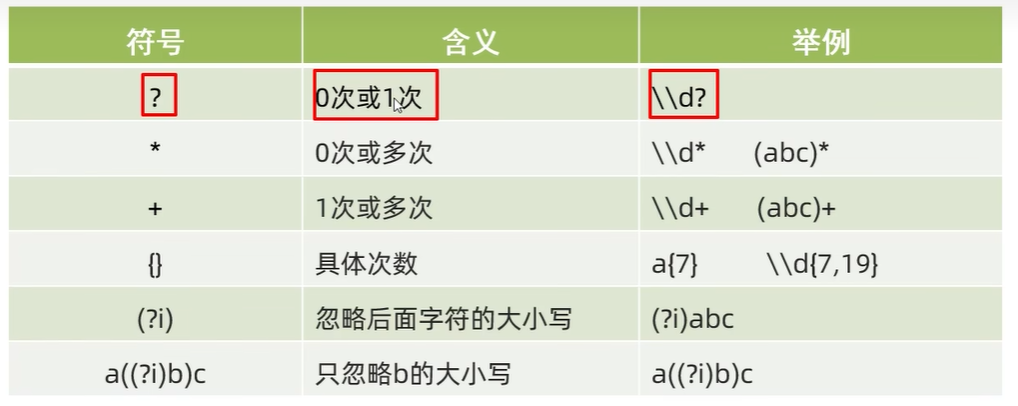
3、数量词

package com.htu;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.math.RoundingMode;
public class BigIntegerDemo2 {
public static void main(String[] args) {
//必须是数字 字母 下划线 至少6位
System.out.println("2442fsfsf".matches("\\w{6,}"));//true
System.out.println("244f".matches("\\w{6,}"));//false
//必须是数字和字符 必须是四位
System.out.println("23dF".matches("[a-zA-Z0-9]{4}"));//true
System.out.println("23_F".matches("[a-zA-Z0-9]{4}"));//false
System.out.println("23dF".matches("[\\w&&[^_]]{4}"));//true
System.out.println("23_F".matches("[\\w&&[^_]]{4}"));//false
}
}
4.正则表达式小结
正则表达式的作用:
1.验证字符串
2.爬虫
爬虫
Pattern类:表示正则表达式
Matcher类:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。在大串中去找符合匹配规则的子串。
String str="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在不久的未来Java17也会登上历史舞台";
//获取正则表达式的对象
Pattern p =Pattern.compile("Java\\d{0,2}");
Pattern p2=Pattern.compile("\\d{0,2}");
Matcher m2=p2.matcher(str);
while(m2.find()){
String s1= m2.group();
System.out.println(s1);
}
//获取文本匹配器的对象
//m:文本匹配器的对象
//str:大串
//p:规则
//m要在str中找符合p规则的小串
Matcher m=p.matcher(str);
//利用循环返回
/* while(m.find()){
String s1=m.group();
System.out.println(s1);
}
*/
/* //拿着文本匹配器从头开始读取,寻找是否有满足规则的子串
//如果没有,方法返回false
//如果有,返回true.在底层记录子串的启示索引和结束索引+1
//在底层索引会记录0和4
boolean b=m.find();
//方法底层会根据find方法记录的索引进行字符串的截取
//字符串的截取方法:subString(起始索引,结束索引);包头不保尾
//(0,4)但不包含4索引
//会把截取的小串进行返回
String s1=m.group();
System.out.println(s1);*/
-----------------------练习,带有选择性的
String str="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在不久的未来Java17也会登上历史舞台";
//需求1:爬取版本号为8,11,17,的java文本,但是只要java,不显示版本号
String regex1="Java(?=17||8||11)";
Pattern p1= Pattern.compile(regex1);//获取正则表达式的对象
Matcher m1=p1.matcher(str);//获取文本匹配器的对象
while(m1.find()){
String s1=m1.group();//返回截取的串
System.out.println(s1);
}
//需求2:爬取版本号为8,11,17的java文本,正确爬取结果为:java8,java11,java17 ,java17
String regex2="(?i)java[?=17||11||8]{0,2}";
Pattern p1=Pattern.compile(regex2);
Matcher m2=p1.matcher(str);
while(m2.find()){
String s2=m2.group();
System.out.println(s2);
}
//需求3:爬取除了版本号为8,11,17,的java文本
String regex3="^((?i)java[?=11||17||8]{0,2})";
Pattern p3=Pattern.compile(regex3);
Matcher m3=p3.matcher(str);
while(m3.find()){
String s3=m3.group();
System.out.println(s3);
}
//---------------------------------贪婪爬取和非贪婪爬取
//ab+:
//贪婪爬取:abbbbbbbbbbbbbbb-尽可能多的获取,默认为贪婪爬取
//非贪婪爬取:ab-尽可能少的获取,需要在数量词+ *的后面加上?
String str3="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+"abbbbbbbbbbb"+
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在不久的未来Java17也会登上历史舞台";
//需求1:尽可能多的获取
/* String regex4="ab+";
Pattern p4=Pattern.compile(regex4);
Matcher m4=p4.matcher(str3);
while(m4.find()){
String s4=m4.group();
System.out.println(s4);//abbbbbbbbbbb
}
*/
String regex5="ab+?";
Pattern p5=Pattern.compile(regex5);
Matcher m5=p5.matcher(str3);
while(m5.find()){
String s5=m5.group();
System.out.println(s5);//ab
}
正则表达式在字符串方法中的使用

 分组
分组
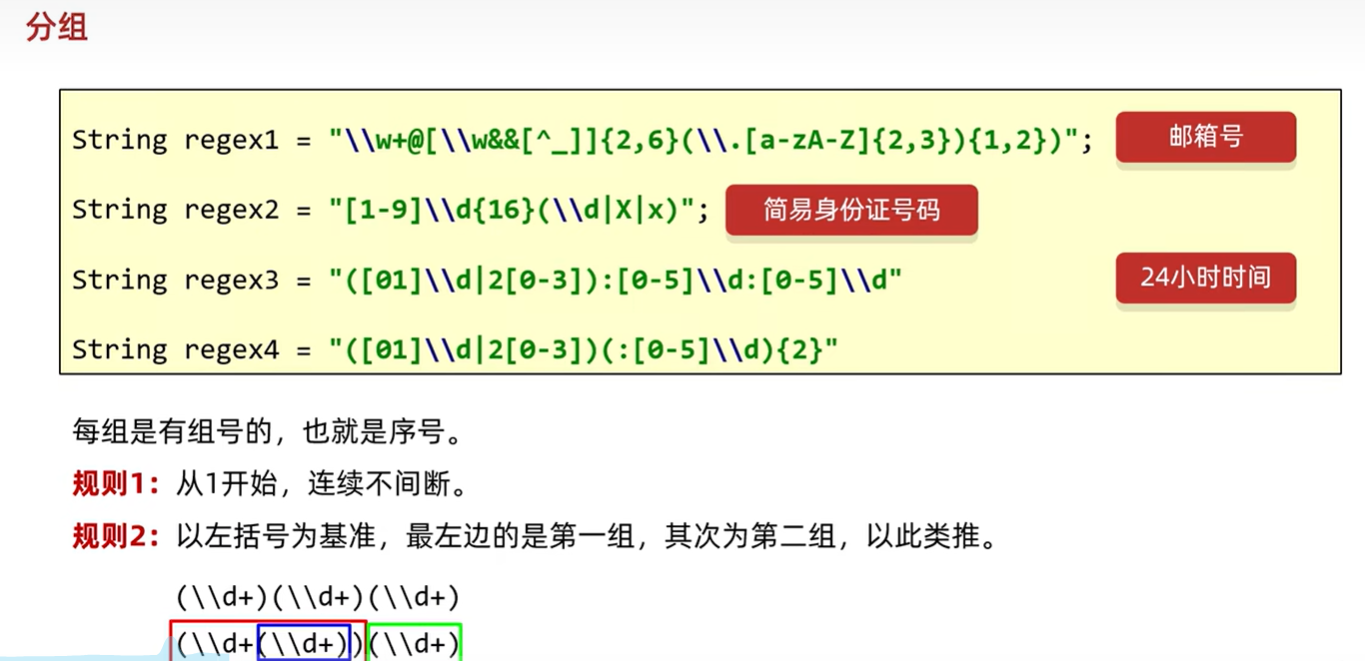
//---------------捕获分组练习
//捕获分组就是把这一组的数据捕获出来,再用一次
//需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符
//举例: a123a b456b &abc& a123b(false)
// \\组号:表示把第x组的内容再出来用一次
String regex1="(.).+\\1";
System.out.println("a123a".matches(regex1));
System.out.println("b456b".matches(regex1));
System.out.println("&abc&".matches(regex1));
System.out.println("a123b".matches(regex1));
//需求2:判断一个字符串的开始部分和结束部分符是否一致?可以有多个字符
//举例: abc123abc b456b 123789123 &!abc@! abc122223abd(false)
String regex2="(.+).+\\1";
System.out.println("abc123abc".matches(regex2));
System.out.println("b456b".matches(regex2));
System.out.println("123789123".matches(regex2));
System.out.println("&!abc@!".matches(regex2));
//需求3:判断一个字符串的开始部分和结束部分符是否一致?开始部分内部每个字符也需要一致
//举例: aaa123aaa bbb456bbb 111789111 &&abc&&
String regex3="((.)\\2*).+\\1";
System.out.println("aaa123aaa".matches(regex3));
System.out.println("bbb456bbb".matches(regex3));
System.out.println("121789121".matches(regex3));
System.out.println("&&abc&&".matches(regex3));
捕获分组
后续还要继续使用本组的数据。
正则内部使用:\\组号
正则外部使用:$组号
//需求:将字符串:我要学学编编编编程程程程程程。替换为:我要学编程
String str4="我要学学编编编编程程程程程程";
//(.)表示把重复内容的第一个字看做第一组
//\\1表示第一个字符再次出现
//+ 至少一次
//$1表示把正则表达式中第一组的内容,再拿出来用
String result=str4.replaceAll("(.)\\1+","$1");
System.out.println(result);//我要学编程
非捕获分组
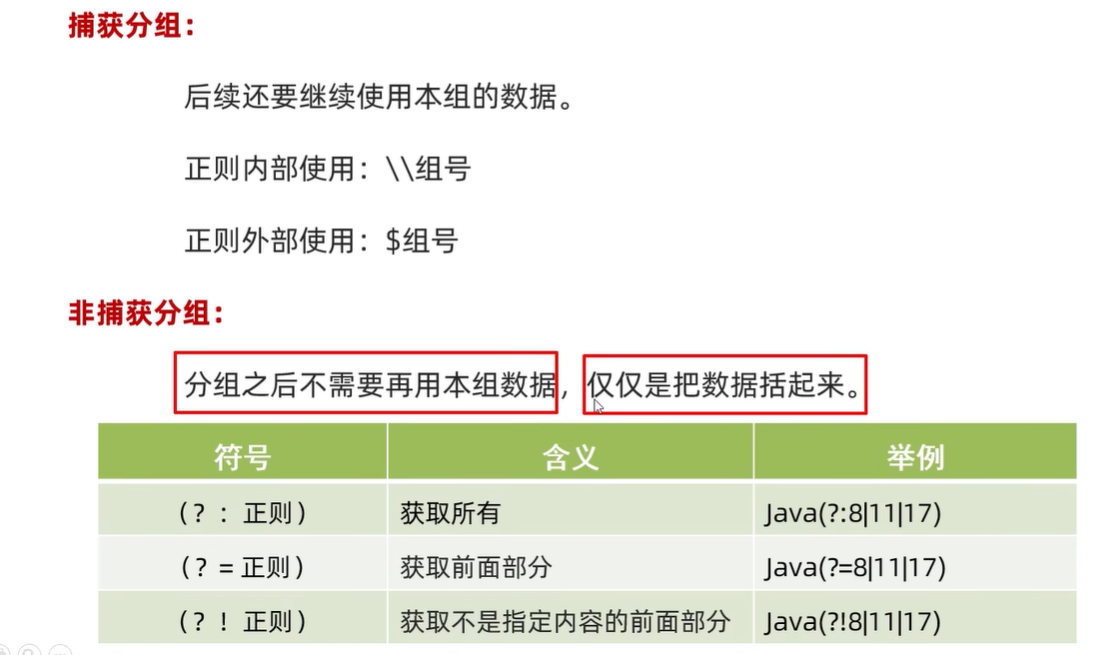
//非捕获分组:仅仅是把数据括起来,不占用组号
String regex1="[1-9]\\d{16}(?:\\d|X|x)\\1";//\\1报错,原因:(?:)是非捕获分组,此时是不占用组号的
//(?:)(?=)(?!)都是非捕获分组
JDK7之前时间相关类
1.Date 时间类
前提知识
1.世界标准时间:之前是格林威治时间简称GMT,目前世界标准时间(UTC)已经替换为:原子钟。
2.中国在东八区,世界标准时间+8小时
3.时间单位换算: 1秒=1000毫秒 1毫秒=1000微秒 1微秒=1000纳秒
Date类是一个JDK写好的javabean类,用来描述时间,精确到毫秒。
利用空参构造创建的对象,默认表示系统当前时间
利用有参构造创建的对象,表示特定的时间
/*
public Date() //创建Date对象,表示当前时间
public Date(long date) //创建Date对象,表示指定时间--从时间原点开始过了多少毫秒
public void setTime(long time) //设置、修改毫秒值
public long getTime() //获取时间对象的毫秒值
*/
//1.创建对象表示一个时间
Date d1=new Date();
// System.out.println(d1);
//2.创建对象表示一个指定的时间
Date d2=new Date(0L);
System.out.println(d2);
//3.
d2.setTime(1000L);
System.out.println(d2);
//4.
long time =d2.getTime();
System.out.println(time);
// setime();
}
private static void setime() {
//需求1:打印时间原点开始一年后的时间
Date d5=new Date(0L);//创建一个对象,表示时间原点
long time = d5.getTime();//获取时间原点的毫秒值
time=time+1000L*60*60*24*365;//加上一年的毫秒值
d5.setTime(time);//把计算后的时间毫秒值设置回d1中
System.out.println(d5);
}2.SimpleDateFormst 格式化时间
格式化:把时间编程我们喜欢的格式。

解析:把字符串表示的时间变成Date对象。


格式化的时间形式常用的模式对应关系:
y 年 M 月 d 日 H 时 m 分 s 秒
eg:2023-11-11 11:27:06 ---->yyyy-MM-dd HH:mm:ss;
或者是:2023年11月11日 11时27分06秒 ---->yyyy年MM月dd日 HH时mm分ss秒
//1.利用空参构造创建对象,默认格式
SimpleDateFormat s=new SimpleDateFormat();
Date d=new Date(0L);
String str =s.format(d);
System.out.println(str);//1970/1/1 上午8:00
//2.利用带参构造创建对象,指定格式
SimpleDateFormat s2=new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
Date d=new Date(0L);
String str2 =s2.format(d);
//System.out.println(str2);//1970年01月01日 08:00:00
//yyyy年MM月dd日 时 分 秒 星期
SimpleDateFormat s3=new SimpleDateFormat("yyyy年MM月dd日 HH时:mm分:ss秒 E ");
String str3 =s3.format(d);
System.out.println(str3);
//解析
String str="2023-12-12 11:13:22";
//细节:创建对象的格式要跟字符串的格式完全一致
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d4=sdf.parse(str);
System.out.println(d4.getTime());//1702350802000
3.Calendar 日历
Calendar代表了系统当前时间的日历对象,可以单独修改、获取时间中的年,月,日。
细节:Calendar是一个抽象类,不能直接创建对象。

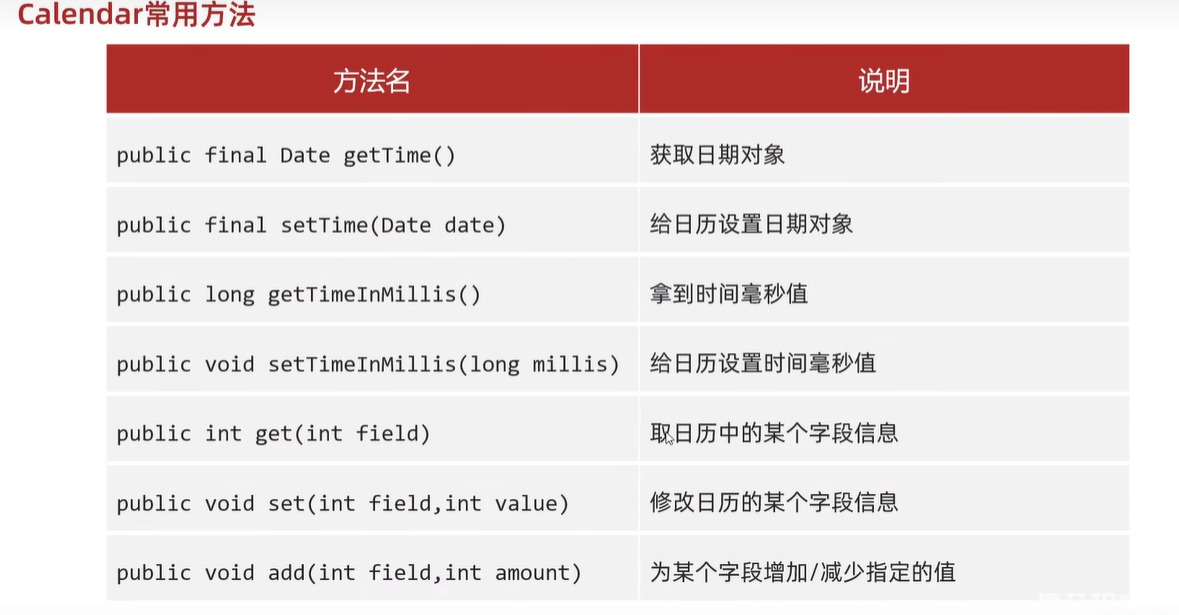
//1.获取日历对象
//细节1:Calendar是一个抽象类,不能直接new,而是通过一个静态方法获取到了子类对象
//底层原理:
//会根据系统的不同时区来获得不同的日历对象,默认表示当前时间
//会把时间中的纪元,年,月,日,时,分,秒,星期。等等的都放到一个数组当中
//0索引:纪元;1索引:年 2月 3一年中的第几周 4一个月中的第几周 5一个月中的第几天
//细节2:
//月份:范围0~11 如果获取出来的时0,那么实际上是1月。
//星期:在老外眼里,星期日是一周中的第一天
// 1->星期日 2->星期一
Calendar c=Calendar.getInstance();
//2.修改一下日历代表的时间
Date d =new Date(0L);
c.setTime(d);
System.out.println(c);
c.set(Calendar.YEAR,2004);
c.set(Calendar.MONTH,13);//年份会向后推
c.add(Calendar.YEAR,1);//正数 加,负数 减
//java在Calendar类中,把索引都定义为了常量
int year = c.get(Calendar.YEAR);
System.out.println(year);
int week = c.get(Calendar.DAY_OF_WEEK);
System.out.println(week);

JDK8新增时间相关类
JDK8时间类
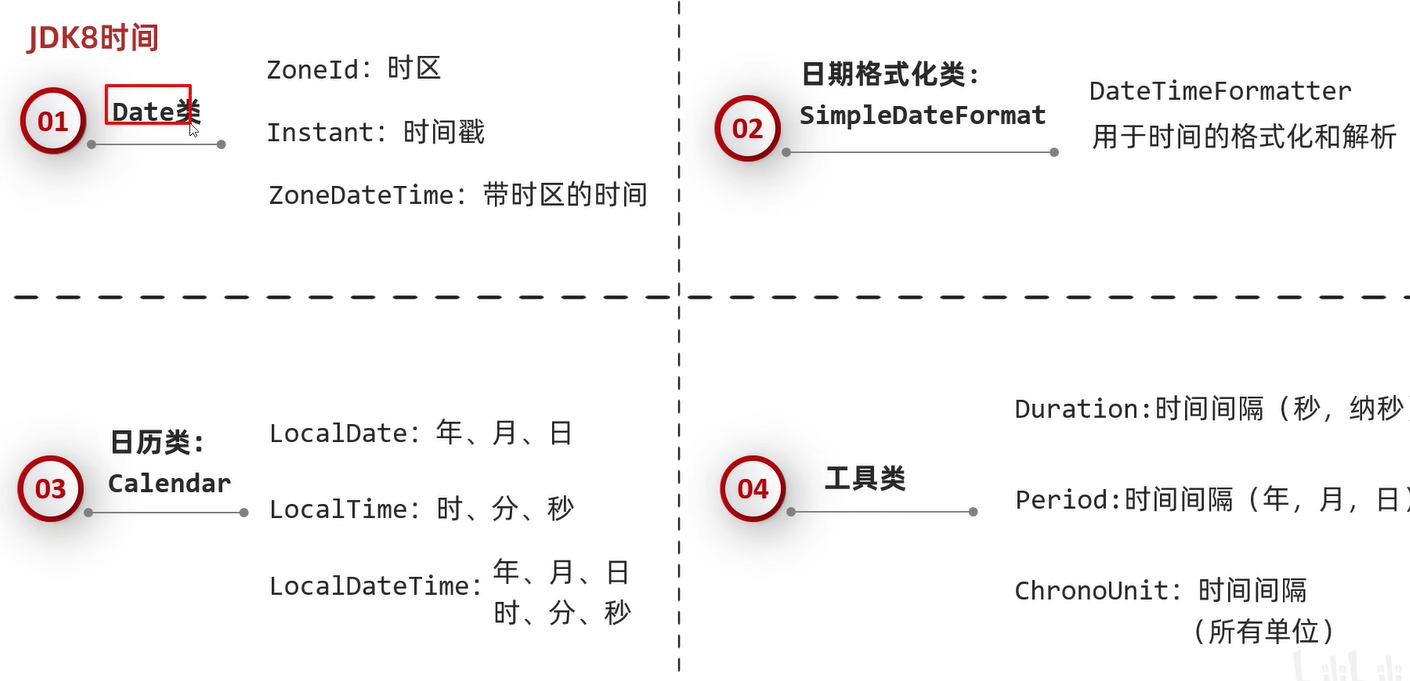
Zoneld时区
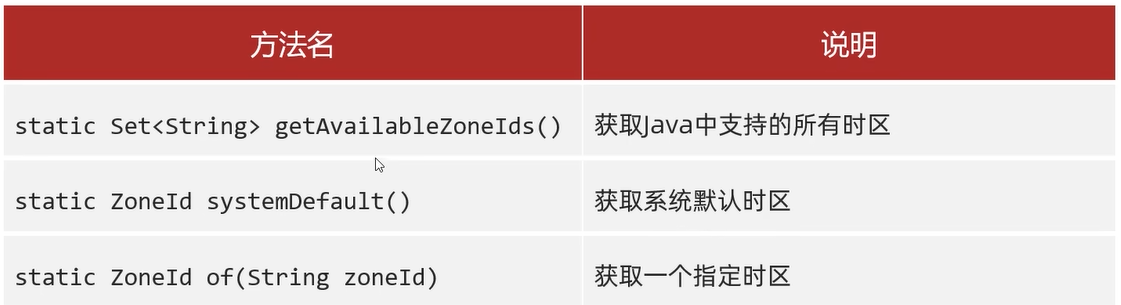
//1.获取所有时区的名称
Set<String> zoneIds= ZoneId.getAvailableZoneIds();
System.out.println(zoneIds.size());//603
System.out.println(zoneIds);
//2.获取当前系统的默认时区
ZoneId zoneId=ZoneId.systemDefault();
System.out.println(zoneId);//GMT+08:00
//3.获取指定时区
ZoneId zoneId1=ZoneId.of("America/Cuiaba");
System.out.println(zoneId1);
Instant时间戳
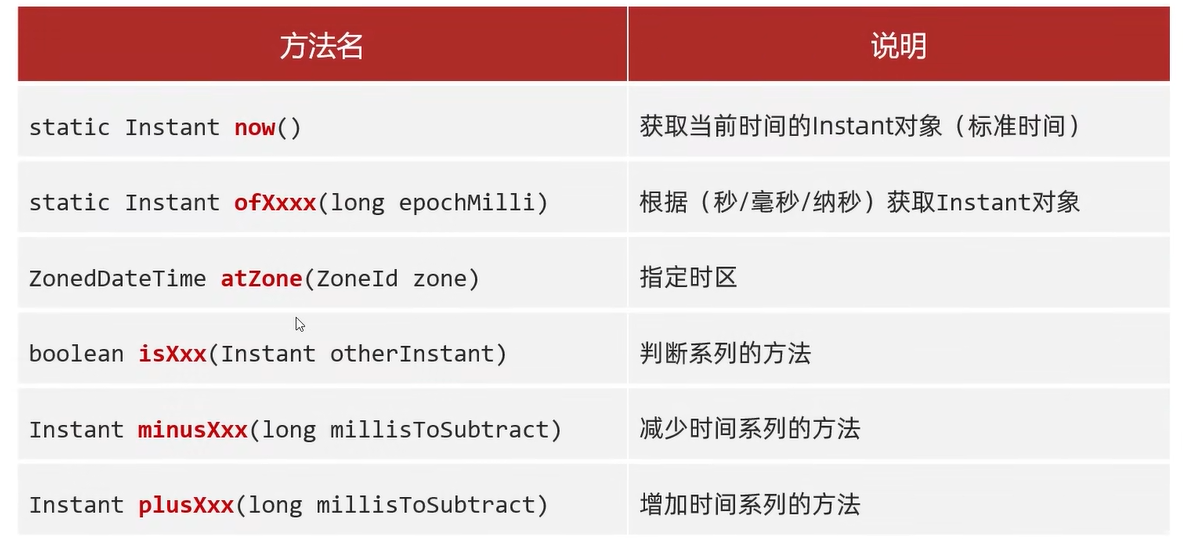
//1.获取当前时间的instant对象(标准时间)
Instant now = Instant.now();
System.out.println(now);//2023-09-24T07:18:16.450867900Z
//2.根据(秒、毫秒、纳秒)获取Instant对象
Instant instant1=Instant.ofEpochMilli(0L);
System.out.println(instant1);//1970-01-01T00:00:00Z
Instant instant2=Instant.ofEpochSecond(1L);
System.out.println(instant2);//1970-01-01T00:00:01Z
Instant instant3=Instant.ofEpochSecond(1L,1000000000L);
System.out.println(instant3);//1970-01-01T00:00:02Z
//3.指定时区
ZonedDateTime time = Instant.now().atZone(ZoneId.of("America/Cuiaba"));
System.out.println(time);//2023-09-24T03:24:59.933331500-04:00[America/Cuiaba]
ZoneDateTime带时区的时间
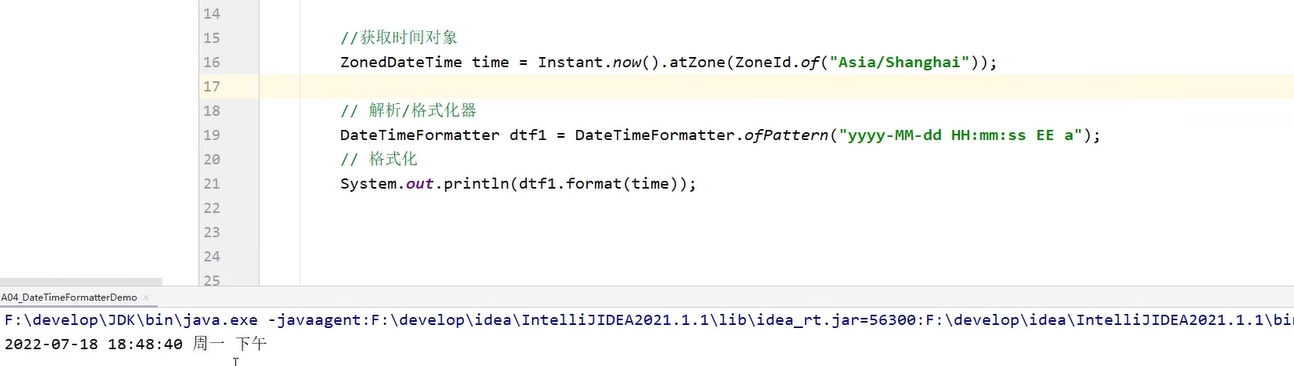
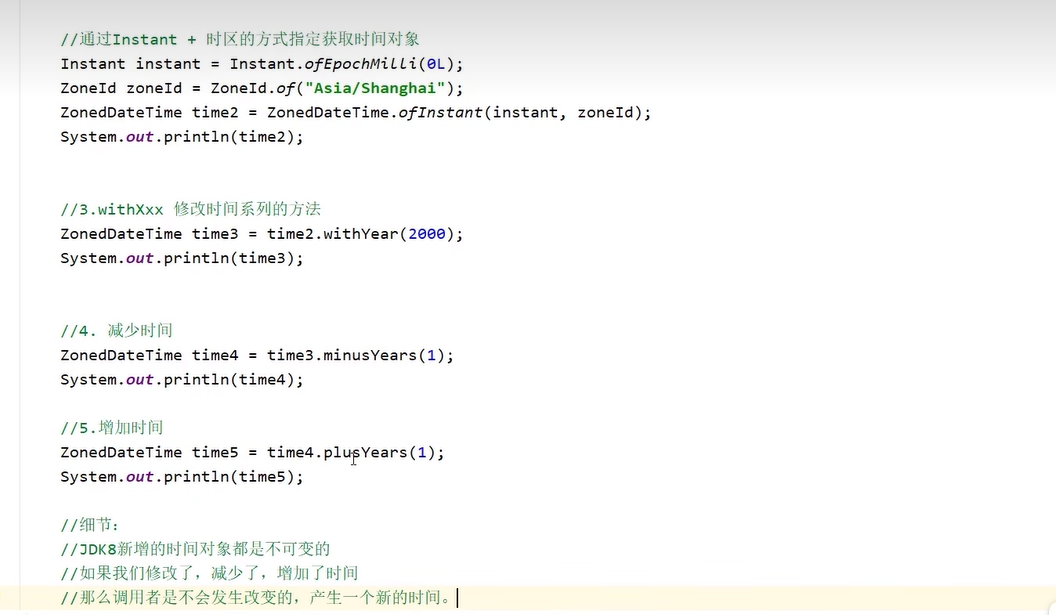 DateTimeFormatter用于时间的格式化和解析
DateTimeFormatter用于时间的格式化和解析

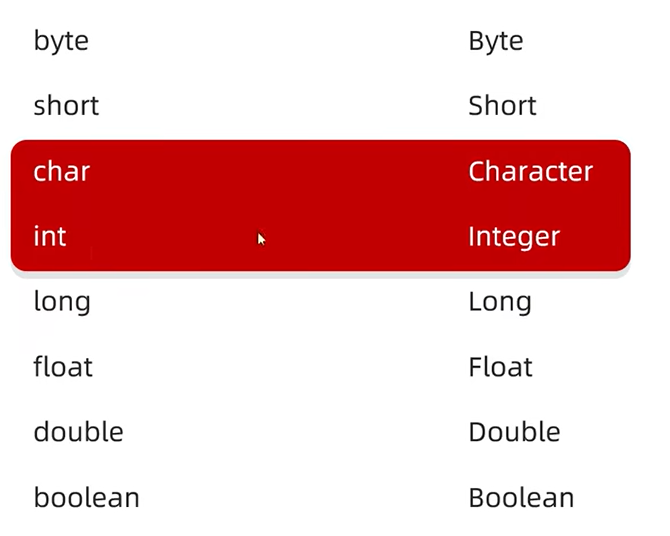
包装类
包装类:基本数据类型对应的引用数据类型
以Integer为例,其余都一样
Integer
JDK5之前:

package api;
public class IntegerDemo {
public static void main(String[] args) {
//1.利用构造方法获取Integer对象(JDK5之前)
Integer i1=new Integer(1);
Integer i2 =new Integer("1");
System.out.println(i1);//1
System.out.println(i2);//1
//2.利用静态方法获取Integer的对象(JDK5之前)
Integer i3=Integer.valueOf(123);
Integer i4=Integer.valueOf("123");
Integer i5=Integer.valueOf("123",8);
System.out.println(i3);//123
System.out.println(i4);//123
System.out.println(i5);//83
//3.这两种方式获取对象的区别(掌握)
//底层原理:
//因为在实际开发中,-128~127之间的数据,用的比较多
//如果每次使用都是new对象,那么太浪费内存了
//所以,提前把这个范围之内的每一个数据都创建好对象
//如果要用到了不会创建新的,而是返回已经创建好的对象。
Integer i6=Integer.valueOf(127);
Integer i7=Integer.valueOf(127);
System.out.println(i6==i7);//true
Integer i8=Integer.valueOf(128);
Integer i9=Integer.valueOf(128);
System.out.println(i8==i9);//false
//因为看到了new关键字,在java中,每一次new都是创建了一个新的对象
//所以下面的两个对象都是new出来的,地址值不一样
Integer i10=new Integer(127);
Integer i11=new Integer(127);
System.out.println(i10==i11);//false
Integer i12=new Integer(128);
Integer i13=new Integer(128);
System.out.println(i12==i13);//false
}
}
JDK5之后的机制:
package api;
public class IntegerDemo {
public static void main(String[] args) {
/* //在以前包装类如何进行计算
Integer i1=new Integer(1);
Integer i2=new Integer(2);
//需求:要把这两个数据进行相加得到结果3
//对象质检室不能直接进行计算的
//步骤:1.把对象进行拆箱,变为基本数据类型 2.相加 3.把得到的结果再次进行装箱(再变为包装类)
int result=i1.intValue()+i2.intValue();
Integer i3=new Integer(result);
System.out.println(i3);*/
//在JDK5的时候提出了一个机制:自动装箱和自动拆箱
//自动装箱:把基本数据类型会自动的变成其对应得包装类
//自动拆箱:把包装类自动的编程其对象的基本数据类型
//在底层,此时还会去自动调用静态方法valueof得到一个Integer对象,只不过这个动作不需要我们自己操作
//自动装箱
Integer i1=10;
Integer i2=new Integer(10);
//自动拆箱
int i=i2;
//在JDK5之后,int和Integer可以看作是同一个东西,因为在内部可以自动转化。
}
}
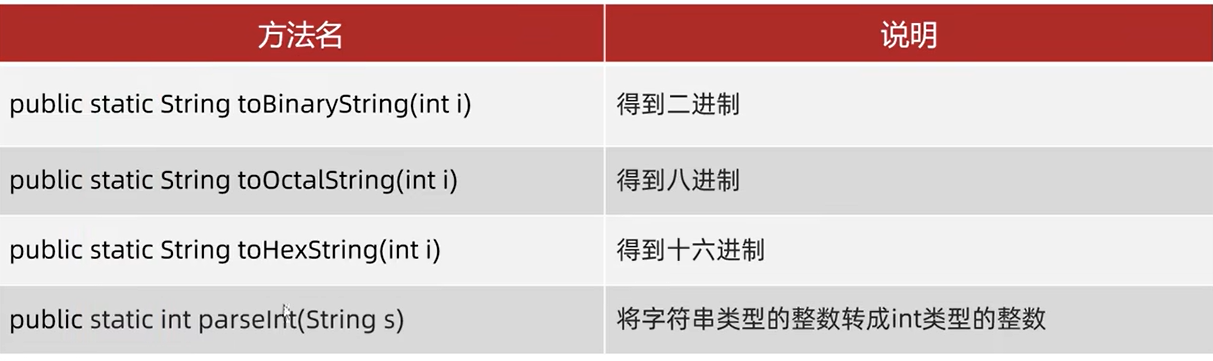
Integer成员方法
package api;
public class IntegerDemo {
public static void main(String[] args) {
//1.把整数转成2进制
String str1=Integer.toBinaryString(12);
System.out.println(str1);//1100
//2.把整数转成8进制
String str2=Integer.toOctalString(12);
System.out.println(str2);//14
//3.把整数转成16进制
String str3=Integer.toHexString(12);
System.out.println(str3);//C
//4.将字符串类型的整数转成int类型的整数
//强类型语言:每种数据在java中都有各自的数据类型
//在计算的时候,如果不是同一种数据类型,是无法直接计算的
int i=Integer.parseInt("123");
System.out.println(i);//123
//细节:1.在类型转换的时候,括号中的参数只能是数字不能是其他,负责代码会报错
//2.8中包装类中,除了character都有对应的parsexxx的方法,进行类型转换
String str="true";
boolean b=Boolean.parseBoolean(str);
System.out.println(b);//true
}
}
键盘录入改进
//以后如果想键盘录入,不管什么类型,统一使用nextLine
//特点:遇到回车才停止
Scanner sc=new Scanner(System.in);
String line=sc.nextLine();
double v=Double.parseDouble(line);
System.out.println(v+1);
案例:
package api;
public class IntegerDemo {
public static void main(String[] args) {
/*
* 键盘录入一些1~100之间的整数,并添加到集合中
* 直到集合中所有数据和超过200为止
* */
ArrayList<Integer> l=new ArrayList<>();
Scanner sc=new Scanner(System.in);
int sum=0;
do{
System.out.println("请输入");
String line=sc.nextLine();
int i=Integer.parseInt(line);
if(i<1||i>100){
System.out.println("数据输错");
continue;
}
sum=sum+i;
l.add(i);
}while(sum<=200);
for (int i = 0; i < l.size(); i++) {
System.out.print(l.get(i)+" ");
}
---------------------------------------------
/*
* 自己实现parseInt方法的效果,将字符串形式的数据转成整数
* 要求:
* 字符串中只能是数字不能有其他字符
* 最少一位,最多10位
* 0不能开头
* */
Scanner sc =new Scanner(System.in);
System.out.println("请输入:");
String line = sc.nextLine();
//判断是否符合规则
String regx="[1-9]\\d{0,9}";
if(line.matches(regx)){
//转换成整数
int num=0;
for (int i = 0; i < line.length(); i++) {
char c=line.charAt(i);
num=num*10+(c-'0');
}
System.out.println(num);
}
else
{
System.out.println("不符合规则");
}
}
}
常见算法
查找
顺序查找
package algorithmdemo01;
import java.util.ArrayList;
public class day01 {
public static void main(String[] args) {
//基本查找/顺序查找
//核心:从0索引开始挨个往后查找
//需求:定义一个方法利用基本查找,查询某个元素是否存在
//数据如下:{1331,235,89,56,12,0,456,455}
int []arr={1331,235,89,56,12,0,456,455,89,89,56};
int num=10;
ArrayList<Integer> result =new ArrayList<>();
result=basicSearch2(arr,num);
System.out.println(result);
}
//顺序查找
public static boolean basicSearch(int[] arr,int num){
for (int i = 0; i < arr.length; i++) {
if(num==arr[i]){
return true;
}
}
return false;
}
//课堂练习1
//需求:定义一个方法利用基本查找,查询某个元素在数组中的索引
//要求:不需要考虑数组中元素是否重复
public static int basicSearch1(int[] arr,int num){
for (int i = 0; i < arr.length; i++) {
if(num==arr[i]){
return i;
}
}
return -1;
}
//课堂练习2
//需求:定义一个方法利用基本查找,查询某个元素在数组中的索引
//要求:需要考虑数组中元素重复的可能性-返回所有索引
public static ArrayList basicSearch2(int[]arr, int num){
ArrayList<Integer> result=new ArrayList<>();
for (int i = 0; i < arr.length; i++) {
if(num==arr[i]){
result.add(i);
}
}
return result;
}
}
二分查找/折半查找
前提条件:数组中的数据必须是有序的
核心逻辑:每次排除一半的查找范围
过程:
- min和max表示当前要查找的范围
- mid是在min和max中间的
- 如果要查找的元素在mid的左边,缩小范围时,min不变,max=mid-1
- 如果要查找的元素在mid的右边,缩小范围时,max不变,min=mid+1
public class day01 {
public static void main(String[] args) {
//二分查找/折半查找
//核心:每次排除一半的查找范围
//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引
//数据如下:{1331,235,89,56,12,0,456,455}
int []arr={1,2,3,4,5,6,7,8,9,10};
int num=10;
System.out.println(binarySearch(arr,num));
}
//二分查找
public static int binarySearch(int[]arr,int num){
int min=0,max=arr.length-1,mid=arr.length/2;
while(min!=max){
if(num>arr[max]||num<arr[min]){
return -1;
}else if(num==arr[mid]){
return mid;
}else if(num==arr[min]) {
return min;
}else if(num==arr[max]){
return max;
}else if(num>arr[mid]){
//进入右部分
min=mid+1;
}else if(num<arr[mid]){
//进入左部分
max=mid-1;
}
mid=(max-min)/2+min;
}
return -1;
}
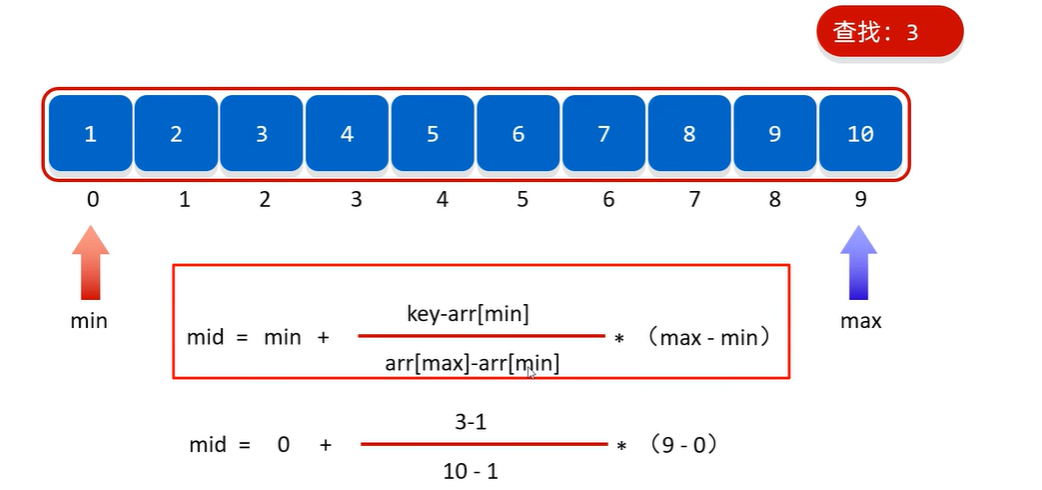
}插值查找--二分查找优化
前提条件:数组中的数据必须是有序且分布均匀的
过程:同二分查找,但mid的取值按照下面公式得到,让mid尽可能的靠近要查找的数据:
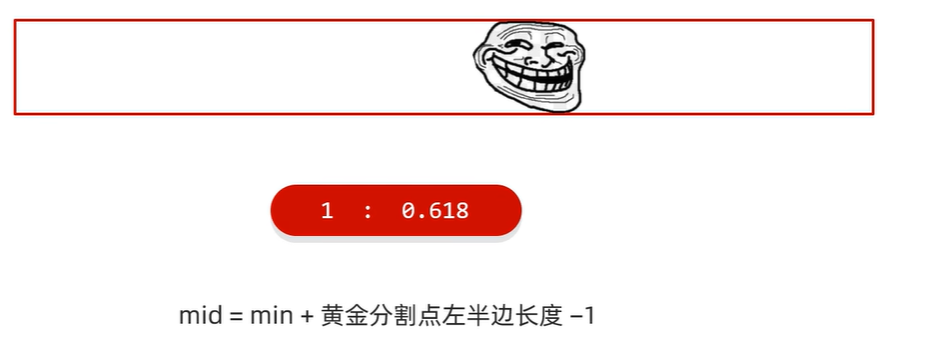
斐波那契查找-二分查找改进
过程:同二分查找,但mid的取值按照下面公式得到:
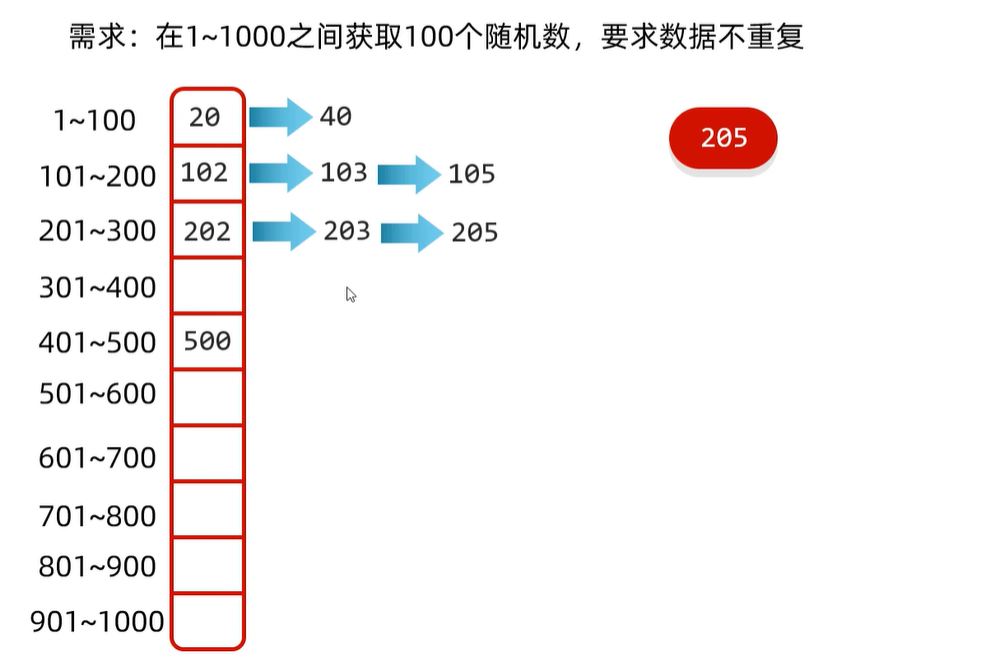
分块查找
分块原则1:前一块中的最大数据,小于后一块中的所有数据(块内无序,块间有序)
分块原则2:块数数量一般等于数字的个数开根号。比如:16个数字一般分为4块左右。
核心思路:先确定要查找的元素在哪一块,然后在块内挨个查找。
package algorithmdemo01;
public class day01 {
public static void main(String[] args) {
/*
* 分块查找:
* 核心思想:块内无序,块间有序
* 实现步骤:
* 1.创建数组blockArr存放每一块对象的信息
* 2.先查找blockArr确定要查找的数据属于哪一块
* 3.再单独遍历这块数据即可
* */
int []arr={16,5,9,12,
21,18,32,23,37,26,
45,34,50,48,
61,52,73,66};
//1.要把数据进行分块
//分几块:18开根号--》4
block blk1=new block(16,0,3);
block blk2=new block(37,4,9);
block blk3=new block(50,10,13);
block blk4=new block(73,14,17);
//创建数组存放对象(索引表)
block [] blockArr = {blk1,blk2,blk3,blk4};
//定义一个变量用来记录要查找的元素
int num=40;
System.out.println(BlockSearchIndex(blockArr,num,arr));
}
//2.查找blockArr确定要查找的数据属于哪一块
public static int BlockSearchIndex(block[] blk,int num,int[]arr){
int index;
for (int i = 0; i < blk.length; i++) {
if(blk[i].getMax()<num){//不在这一块
}else if(blk[i].getMax()>=num){//在这一块
index=i;
int start =blk[index].getStartIndex();
int end=blk[index].getEndIndex();
return BlockSearch(start,end,arr,num);
}
}
return -1;
}
//3.再单独遍历这块数据即可
public static int BlockSearch(int start,int end,int[] arr,int num){
for (int i = start; i <=end; i++) {
if(arr[i]==num){
return i;
}
}
return -1;
}
}
class block{
private int max;//记录最大的数
private int startIndex;//记录起始索引
private int endIndex;//记录结束索引
public block() {
}
public block(int max, int startIndex, int endIndex) {
this.max = max;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
/**
* 获取
* @return max
*/
public int getMax() {
return max;
}
/**
* 设置
* @param max
*/
public void setMax(int max) {
this.max = max;
}
/**
* 获取
* @return startIndex
*/
public int getStartIndex() {
return startIndex;
}
/**
* 设置
* @param startIndex
*/
public void setStartIndex(int startIndex) {
this.startIndex = startIndex;
}
/**
* 获取
* @return endIndex
*/
public int getEndIndex() {
return endIndex;
}
/**
* 设置
* @param endIndex
*/
public void setEndIndex(int endIndex) {
this.endIndex = endIndex;
}
public String toString() {
return "block{max = " + max + ", startIndex = " + startIndex + ", endIndex = " + endIndex + "}";
}
}
扩展的分块查找(无规律的数据)

扩展的分块查找(查找过程中还需要添加数据)--哈希查找
排序算法
冒泡排序:
1.相邻的数据两两比较,小的放前面,大的放后面。
2.第一轮比较完毕之后,最大值就已经确定,第二轮可以少循环一次,后面以此类推
3.如果数组中有n个数据,纵观我们只要执行n-1轮的代码就可以。
package algorithmdemo01;
public class day01 {
public static void main(String[] args) {
//冒泡排序
//定义数组
int[]arr={3,4,5,2,1,0,6,9,8,7};
//外循环:表示我要执行多少轮,如果有n各数据,那么执行n-1轮
for(int j=0;j<arr.length-1;j++){
//内循环:每一轮中我如何比较数据并找到当前的最大值
//-1:为了防止索引越界
//-i:提高效率,每一轮执行的次数应该比上一轮少一次
for(int i=0;i<arr.length-j-1;i++){
if(arr[i]>arr[i+1]){
//交换位置
int temp =arr[i+1];
arr[i+1]=arr[i];
arr[i]=temp;
}
}
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
}
}
选择排序
从0索引开始,拿着每一个索引上的元素跟后面的元素一次比较,晓得放前面,大的放后面,以此类推。
package algorithmdemo01;
public class day01 {
public static void main(String[] args) {
//选择排序
int[]arr={8,9,6,5,23,4,2,0,12,56,1};
//外循环:循环几轮 ,i表示这一轮中,我拿着哪个索引上的数据跟后面的数据进行比较并交换
for (int j = 0; j< arr.length-1; j++) {
//内循环:每一轮我要干什么
//拿着i跟i后面的数据进行比较交换
for (int i = j+1; i < arr.length; i++) {
if(arr[j]>arr[i]){
//交换
int temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
}
}
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
}
}
插入排序
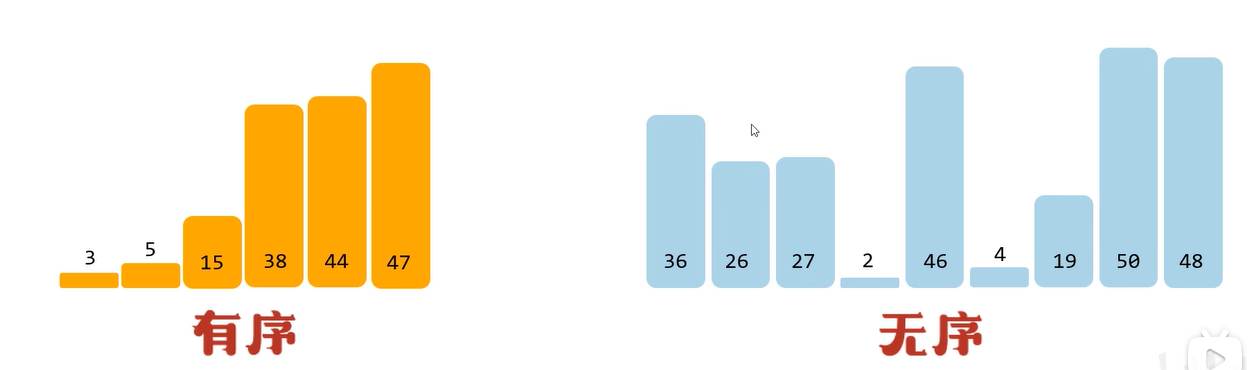
将0索引的元素到N索引的元素看作是有序的,把N+1索引的元素到最后一个当做是无序的。遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同的数据,插在后面.N的范围:0~最大索引
package algorithmdemo01;
public class day01 {
public static void main(String[] args) {
//插入排序
int []arr={8,9,56,23,0,45,7,5,6,5,10};
//1.找到无序的那一组数组是从哪个索引开始的
int start=0;
for (int i = 0; i < arr.length; i++) {
if(arr[i]>arr[i+1]){
start=i+1;
break;
}
}
//2.遍历从start开始到最后一个元素,依次得到无序的那一组数据值
for (int j=start; j<arr.length; j++) {
int i=j;//记录当前要插入数据的索引
while(i>0&&arr[i]<arr[i-1]){
//交换位置
int temp=arr[i];
arr[i]=arr[i-1];
arr[i-1]=temp;
i--;
}
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
}
}
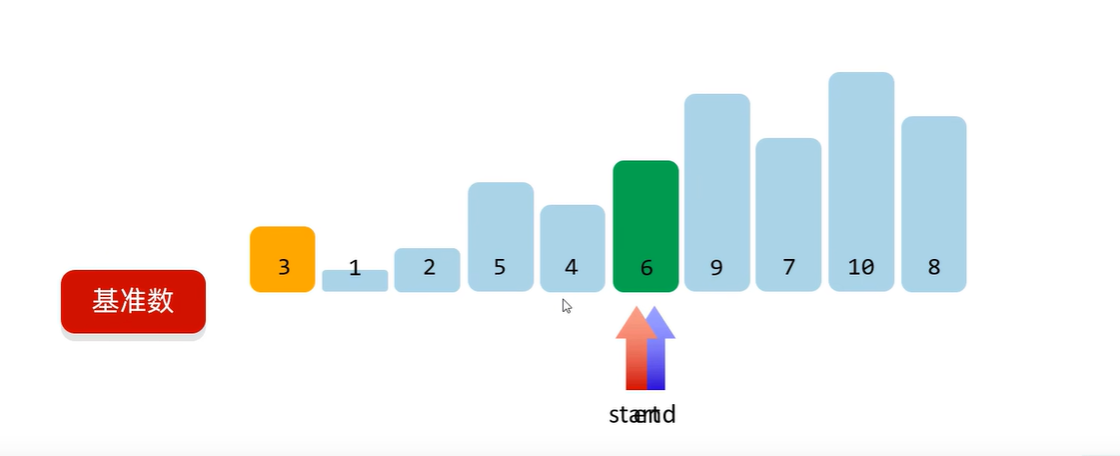
快速排序
递归算法:递归指的是方法中调用方法本身的现象。
递归一定要有出口
第一轮:把0索引的数字作为基准书,确定基准数在数组中正确的位置。比基准数小的全部在左边,比基准数大的全部在右边。
Arrays
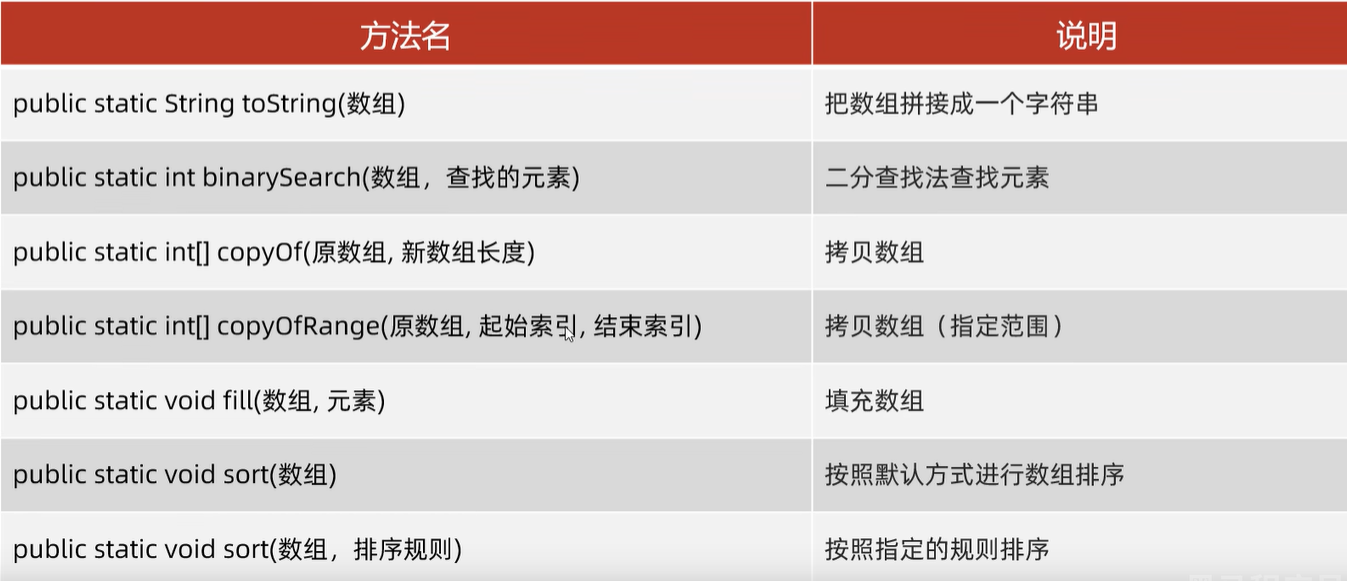
操作数组的工具类
package algorithmdemo01;
import java.util.Arrays;
public class myarrays {
public static void main(String[] args) {
//toString 将数组变成字符串
int [] arr={1,2,3,4,5,6,7,8,9,10};
System.out.println(Arrays.toString(arr));//[1, 2, 3, 4, 5, 6, 7, 8, 9,10]
//binarySearch 二分法查找
//细节1:二分查找的前提:数组中的元素必须是有序,数组中的元素必须是升序的
//细节2:如果要查找的元素是存在的,那么返回的是真实的索引
// 但是,如果要查找的元素是不存在的,返回的是-插入点-1
// 疑问:为什么要减1呢?
// 解释:如果此时,我现在要查找数字e.那么如果返回的值是-插入点,就会出现问题了。
// 如果要查找数字e.此时e是不存在的,但是按照上面的规则-插入点,应该就是-e
// 为了避免这样的情况,Java在这个基础上又减一。
System.out.println(Arrays.binarySearch(arr,10));//9
System.out.println(Arrays.binarySearch(arr,2));//1
System.out.println(Arrays.binarySearch(arr,11));//-11
//copyOf:拷贝数组
// 参数一:老数组
// 参数二:新数组的长度
// 方法的底层会根据第二个参数来创建新的数组
// 如果新数组的长度是小于老数组的长度,会部分拷贝
// 如果新数组的长度是等于老数组的长度,会完全拷贝
// 如果新数组的长度是大于老数组的长度,会补上默认初始值
int []newArr1=Arrays.copyOf(arr,2);
System.out.println(Arrays.toString(newArr1));//[1, 2]
int []newArr2=Arrays.copyOf(arr,10);
System.out.println(Arrays.toString(newArr2));//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
int []newArr3=Arrays.copyOf(arr,20);
System.out.println(Arrays.toString(newArr3));//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
//copyOfRange:拷贝数组(指定范围)
int []newArr4=Arrays.copyOfRange(arr,0,9);
System.out.println(Arrays.toString(newArr4));//[1, 2, 3, 4, 5, 6, 7, 8, 9]
//fill 填充数组
Arrays.fill(arr,100);
System.out.println(Arrays.toString(arr));//[100, 100, 100, 100, 100, 100, 100, 100, 100, 100]
//sort 排序 默认情况下,给基本数据类型进行升序排序。底层使用得是快速排序
int []arr2={10,2,3,5,6,1,8,9,4};
Arrays.sort(arr2);
System.out.println(Arrays.toString(arr2));//[1, 2, 3, 4, 5, 6, 8, 9, 10]
}
}
package algorithmdemo01;
import java.util.Arrays;
import java.util.Comparator;
public class myarrays01 {
/*
* public static void sort(数组,排序规则)按照指定的顺序排序
* 参数一:要排序的数组
* 参数二:排序的规则
* 细节:只能给引用数据类型的数组进行排序
* 如果数组时基本数据类型的,需要变成其对应的包装类
*
* */
public static void main(String[] args) {
Integer[]arr={1,5,6,8,2,3,4,7,9};
//第二个参数是一个接口,所以我们在调用方法的时候,需要传递这个接口的实现类对象,作为排序的规则。
//但是这个实现类,我只要使用一次,所以就没有必要单独的去写一个类,直接采取匿名内部类的方式就可以了
//底层原理:
// 利用插入排序+二分查找的方式进行排序的。
// 默认把0索引的数据当做是有序的序列,1索引到最后认为是无序的序列。
// 遍历无序的序列得到里面的每一个元素,假设当前遍历得到的元素是A元素
// 把A往有序序列中进行插入,在插入的时候,是利用二分查找确定A元素的插入点。
// 拿着A元素,跟插入点的元素进行比较,比较的规则就是compare方法的方法体
// 如果方法的返回值是负数,拿着A继续跟前面的数据进行比较
// 如果方法的返回值是正数,拿着A继续跟后面的数据进行比较
// 如果方法的返回值是0,也拿着A跟后面的数据进行比较
// 直到能确定A的最终位置为止。
// compare方法的形式参数:
// 参数一o1:表示在无序序列中,遍历得到的每一个元素
// 参数二o2:有序序列中的元素
// 返回值:
// 负数:表示当前要插入的元素是小的,放在前面
// 正数:表示当前要插入的元素是大的,放在后面
// 0:表示当前要插入的元素跟现在的元素比是一样的也会放在后面
//简单理解:
//o1-o2:升序排列
//o2-o1:降序排序
Arrays.sort(arr, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("o1:"+o1+" o2:"+o2);
return o2-o1;
}
});
System.out.println(Arrays.toString(arr));//[9, 8, 7, 6, 5, 4, 3, 2, 1]
}
}
Lambda表达式
面向对象:先找对象,让对象做事情。
函数式编程(Functional programming)是一种思想特点
函数式编程思想,忽略面向对象的复杂语法,强调做什么,而不是谁去做。
而我们要学习的Lambda表达式就是函数式思想的体现。
Lambda表达式的标准格式
Lambda表达式是JDK 8开始后的一种新语法形式。
()->{
}- ()对应着方法的形参
- -> 固定格式
- { } 对应着方法的方法体

注意点:
- Lambda表达式可以用来简化匿名内部类的书写
- Lambda表达式只能简化函数式接口的匿名内部类的写法
- 函数式接口:
- 有且仅有一个抽象方法的接口叫做函数式接口,接口上方可以加@Functionallnterface注解
小结:
1、Lambda表达式的基本作用?
简化函数式接口的匿名内部类的写法。
2、Lambda表达式有什么使用前提?
必须是接口的匿名内部类,接口中只能有一个抽象方法
3、Lambda的好处?
Lambda是一个匿名 函数 我们可以把Lambda表达式理解为是一段 可以传递的代码,它可以写出更简洁、更灵活的代码,作为一种更紧 凑的代码风格,使Java语言表达能力得到了提升。
lambda的省略规则:
省略核心:可推导,可省略
1.参数类型可以省略不写。
2.如果只有一个参数,参数类型可以省略,同时()也可以省略。
3.如果Lambda表达式的方法体只有一行,大括号,分号,return可以省略不写,需要同时省略。
package algorithmdemo01;
import java.util.Arrays;
import java.util.Comparator;
public class myarrays01 {
public static void main(String[] args) {
Integer[] arr={1,5,6,7,3,2,4,9,8};
//匿名内部类
Arrays.sort(arr, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
//lambda完整写法
Arrays.sort(arr, (o1,o2)->{
return o2-o1;
});
//lambda省略写法
Arrays.sort(arr, (Integer o1, Integer o2)->o1-o2);
System.out.println(Arrays.toString(arr));
}
}
案例

package algorithmdemo01;
import java.util.Arrays;
public class myarrays01 {
public static void main(String[] args) {
GirlFriend gf1=new GirlFriend("efag",17,157);
GirlFriend gf2=new GirlFriend("abd",18,157);
GirlFriend gf3=new GirlFriend("bebe",19,160);
GirlFriend gf4=new GirlFriend("gg",17,157);
GirlFriend[] gfs={gf1,gf2,gf3,gf4};
//排序--匿名内部类
Arrays.sort(gfs,
new Comparator<GirlFriend>() {
@Override
public int compare(GirlFriend o1, GirlFriend o2) {
//按年龄
double temp;
temp=o1.getAge()-o2.getAge();
//按身高排
temp=temp==0?o1.getHeight()-o2.getHeight():temp;
*//* if(temp==0){
temp=o1.getHeight()-o2.getHeight();
}*//*
//按名字排
temp=temp==0?o1.getName().compareTo(o2.getName()):temp;
*//*if(temp==0){
temp=o1.getName().compareTo(o2.getName());
}*//*
if(temp>0)
return 1;
else if(temp==0)
return 0;
else
return -1;
}
});
//lambda
Arrays.sort(gfs, (GirlFriend o1, GirlFriend o2) ->{
//按年龄
double temp;
temp=o1.getAge()-o2.getAge();
//按身高排
temp=temp==0?o1.getHeight()-o2.getHeight():temp;
/* if(temp==0){
temp=o1.getHeight()-o2.getHeight();
}*/
//按名字排
temp=temp==0?o1.getName().compareTo(o2.getName()):temp;
/*if(temp==0){
temp=o1.getName().compareTo(o2.getName());
}*/
if(temp>0)
return 1;
else if(temp==0)
return 0;
else
return -1;
});
System.out.println(Arrays.toString(gfs));
}
}
class GirlFriend{
private String name;
private int age;
private double height;
public GirlFriend() {
}
public GirlFriend(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
/**
* 获取
* @return height
*/
public double getHeight() {
return height;
}
/**
* 设置
* @param height
*/
public void setHeight(double height) {
this.height = height;
}
public String toString() {
return "GirlFriend{name = " + name + ", age = " + age + ", height = " + height + "}";
}
}
集合进阶
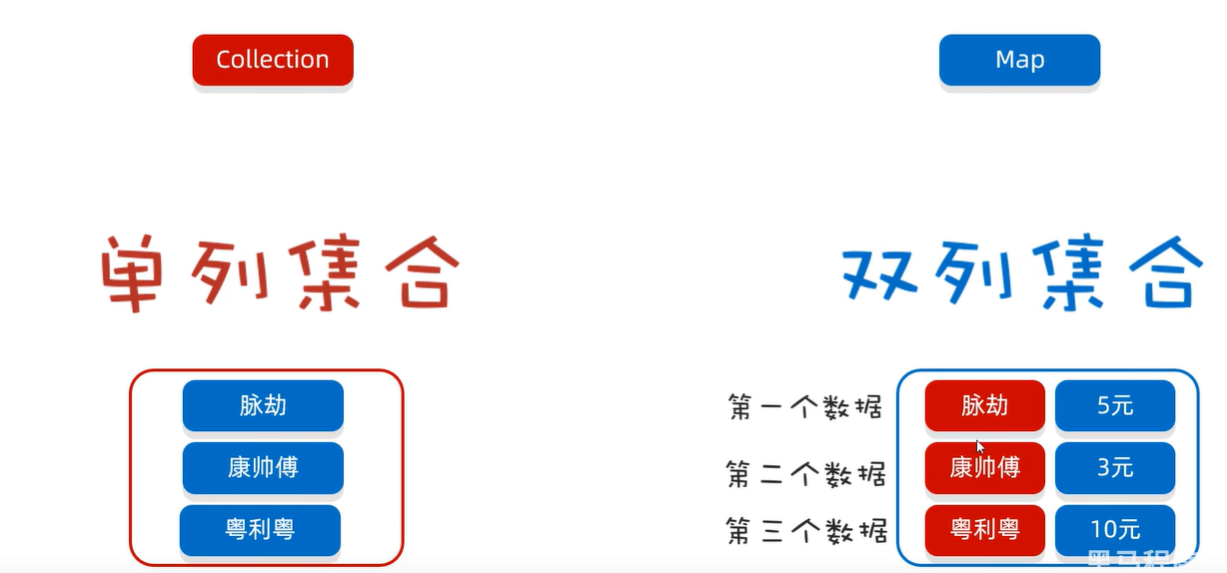
List系列集合:添加的元素是有序、可重复、有索引
Set系列集合:添加的元素是无序 不重复、无索引
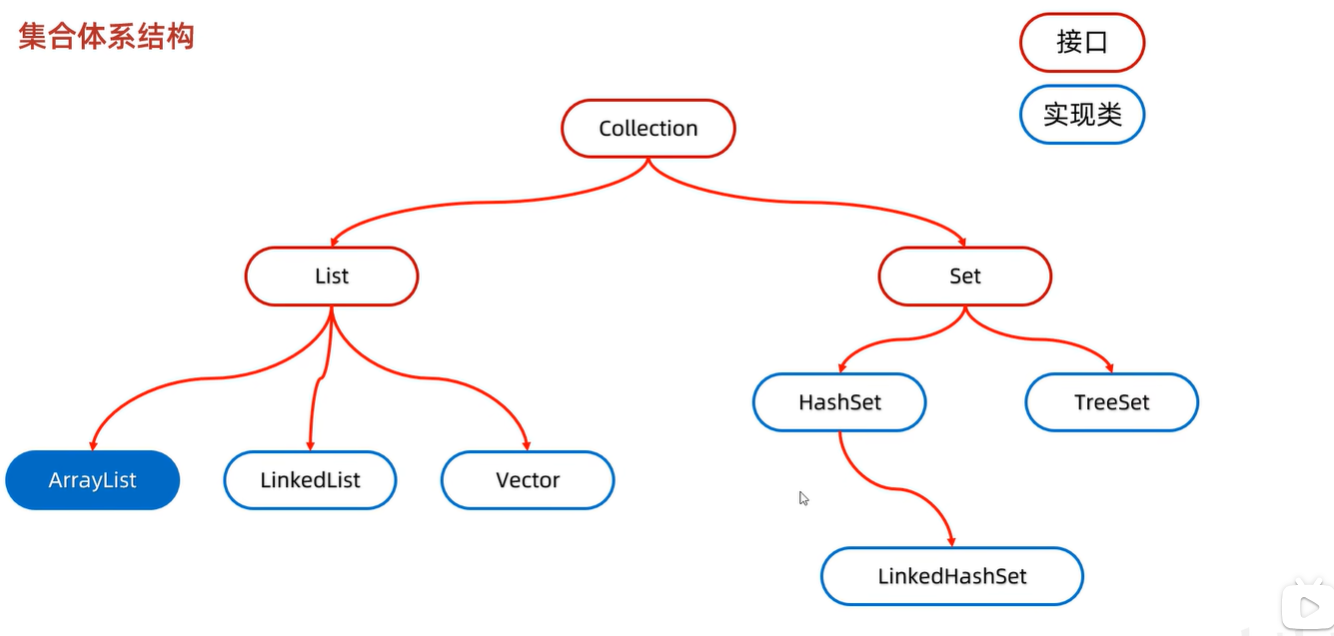
Collection
Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的。
| 方法名称 | 说明 |
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数/集合的长度 |
/*
* 注意点:collection是一个接口,不能直接创建他的对象。
* 所以,现在我们学习他的方法,只能创建他实现类的对象。
* 实现类:ArrayList
* */
//目的:为了学习Collection接口里面的方法
// 自己在做一些练习的时候,还是按照之前的方式去创建对象。
Collection<String> coll =new ArrayList<>();
//1.添加元素
细节1:如果我们要往List系列集合中添加数据,那么方法永远返回true,因为List系列的是允许元素重复的。
细节2:如果我们要往Set系列集合中添加数据,如果当能要添加元素不存在,方法返回true,表示添加成功。
// 如果当前要添加的元素已经存在,方法返回false,表示添加失败。
coll.add("aaa");
coll.add("bbb");
coll.add("ggg");
coll.add("fff");
coll.add("yyy");
System.out.println(coll);//[aaa, bbb, ggg, fff, yyy]
//2.clear
/* coll.clear();
System.out.println(coll);//[]
*/
//3.remove 删除
// 细节1:因为collection里面定义的是共性的方法,所以此时不能通过索引进行删除。只能通过元素的对象进行删除。
// 细节2:方法会有一个布尔类型的返回值,删除成功返回true.删除失败返回false
// 如果要删除的元素不存在,就会删除失败。
coll.remove("ggg");
System.out.println(coll);//[aaa, bbb, fff, yyy]
//4.判断元素是否包含
//细节;底层是依赖equals方法进行判断是否存在的。
//所以,如果集合中存储的是自定义对象,也想通过contains方法来判断是否包含,那么在javabean类中,一定要重写equals方法(快捷键Alt+insert)。
//字符串在底层已经重写过equals方法了
boolean result=coll.contains("bbb");
System.out.println(result);//true
//5.判断是否为空
boolean re=coll.isEmpty();
System.out.println(re);//false
//6.长度
int size=coll.size();
System.out.println(size);//4
Collection的遍历方式
原来的for遍历只有list能用,set用不了
迭代器遍历
迭代器不依赖索引
迭代器在Java中的类是lterator,迭代器是集合专用的遍历方式。
Collection集合获取迭代器
Iterator<E> iterator() //返回迭代器对象,默认指向当前集合的0索引lterator中的常用方法
boolean hasNext()//判断当前位置是否有元素,有元素返回true,没有元素返回false
E next()//获取当前位置的元素,并将迭代器对象移向下一个位置。
void remove() //从带带器指向的collection中移除迭代器返回的最后一个元素 //1.创建集合并添加元素
Collection<String > coll =new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
//2.获取迭代器对象
//迭代器器就好比是一个箭头,默认指向集合0索引处
Iterator<String> it=coll.iterator();
//3.利用循环不断地去获取集合中的每一个元素
while(it.hasNext()){
//4.next方法的;两件事情:获取元素并移动指针
String str=it.next();
if("bbb".equals(str)){
it.remove();
}
System.out.print(str+" ");//aaa bbb ccc
}
System.out.println();
System.out.println(coll);//[aaa, ccc]
细节注意点:
1,报错NoSuchElementException----当上面循环结束之后,迭代器的指针已经指向最后没有元素的位置
2,迭代器遍历完毕,指针不会复位-----需要重新遍历集合则需要重新获取一个新的迭代器对象
3,循环中只能用一次next方法----否则可能会报错NoSuchElementException;next方法与hasNext方法配套出现
4,迭代器遍历时,不能用集合的方法进行增加或者删除----报错ConcurrentModificationException;用迭代器的remove方法删除,添加暂时没有办法。
增强for遍历
- 增强for的底层就是迭代器,为了简化迭代器的代码书写的。
- 它是JDK5之后出现的,其内部原理就是一个lterator迭代器
- 所有的单列集合和数组才能用增强for进行遍历。
格式:
for(元素的数据类型 变量名:数组或者集合){
}
eg:
for(String s:list){}
//1.创建集合并添加元素
Collection<String > coll =new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
//s其实就是一个第三方变量,在循环的过程中依次表示集合中的每一个数据
for(String s:coll){
System.out.print(s+" ");
}
Lambda表达式遍历
得益于JDK8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式。
default void forEach(Consumer<? super T> action)://结合lambda遍历集合
//1.创建集合并添加元素
Collection<String > coll =new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
//2.利用匿名内部类的形式
//底层原理:--封装在ArrayList中
//forEach方法底层其实也会自己遍历集合,依次得到每个方法
//把得到的每一个元素,传递给下面的accept方法
/* coll.forEach(new Consumer<String>() {
@Override
//s就是依次表示集合中的每一个数据
public void accept(String s) {
System.out.print(s+" ");//aaa bbb ccc
}
});*/
//lambda表达式
coll.forEach(s-> System.out.print(s+" "));//aaa bbb ccc小结:
1.Collection是单列集合的顶层接口,所有方法被List和Set系列集合共享
2.常见成员方法: add, clear, remove, contains, isEmpty, size
3.三种通用的遍历方式:
- 在遍历的过程中需要删除元素,请使用迭代器。
- 仅仅想遍历,那么使用增强for或Lambda表达式。
List集合
- Collection的方法List都继承了
- List集合因为有索引,所以多了很多索引操作的方法。
| 方法名称 | 说明 |
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
//1.创建集合并添加元素
List<String> list=new ArrayList<>();
//2.添加元素
list.add("aaa");
list.add("bbb");
list.add("ccc");
//void add(int index,E element)
//细节:原来索引上的元素会依次往后移
list.add(1,"888");
//E remove(int index)
//细节:在调用方法的时候,如果方法出现了重载现象
//优先调用,实参跟形参类型一致的那个方法。
String remove=list.remove(0);
System.out.println(remove);
//E set(int index,E element)
String set=list.set(2,"000");
System.out.println(set);//返回被修改索引的元素
//E get(int index)
String s= list.get(0);//返回指定索引处的元素
System.out.println(s);
System.out.println(list);list集合的遍历方式
- 迭代器遍历
- 在遍历的过程中需要删除元素,请使用迭代器。
- 列表迭代器遍历
- 在遍历的过程中需要添加元素,请使用列表迭代器。
- 增强for遍历
- 仅仅想遍历,那么使用增强for或Lambda表达式。
- Lambda表达式遍历
- 仅仅想遍历,那么使用增强for或Lambda表达式。
- 普通for循环(因为List集合存在索引)
- 如果遍历的时候想操作索引,可以用普通for。
//1.创建集合并添加元素
List<String> list=new ArrayList<>();
//2.添加元素
list.add("aaa");
list.add("bbb");
list.add("ccc");
//迭代器
Iterator<String> it=list.iterator();
while(it.hasNext()){
String s=it.next();
System.out.print(s+" ");
}
//增强for
for(String s:list){
System.out.print(s+" ");
}
//lambda
list.forEach(s->System.out.print(s+" "));
//普通for
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i)+" ");
}
//列表迭代器
//获取一个列表迭代器的对象,里面的指针默认也是指向0索引的
//额外添加了一个方法:在遍历的过程中,可以添加元素--用迭代器的方法添加
ListIterator<String>it= list.listIterator();
while(it.hasNext()){
String str=it.next();
if("bbb".equals(str)){
it.add("333");
}
}
System.out.print(list);知识准备----数据结构
栈--先进后出,后进先出
队列--先进先出,后进后出
数组--查询快,增删慢
链表--查询慢,增删快
ArrayList集合底层原理
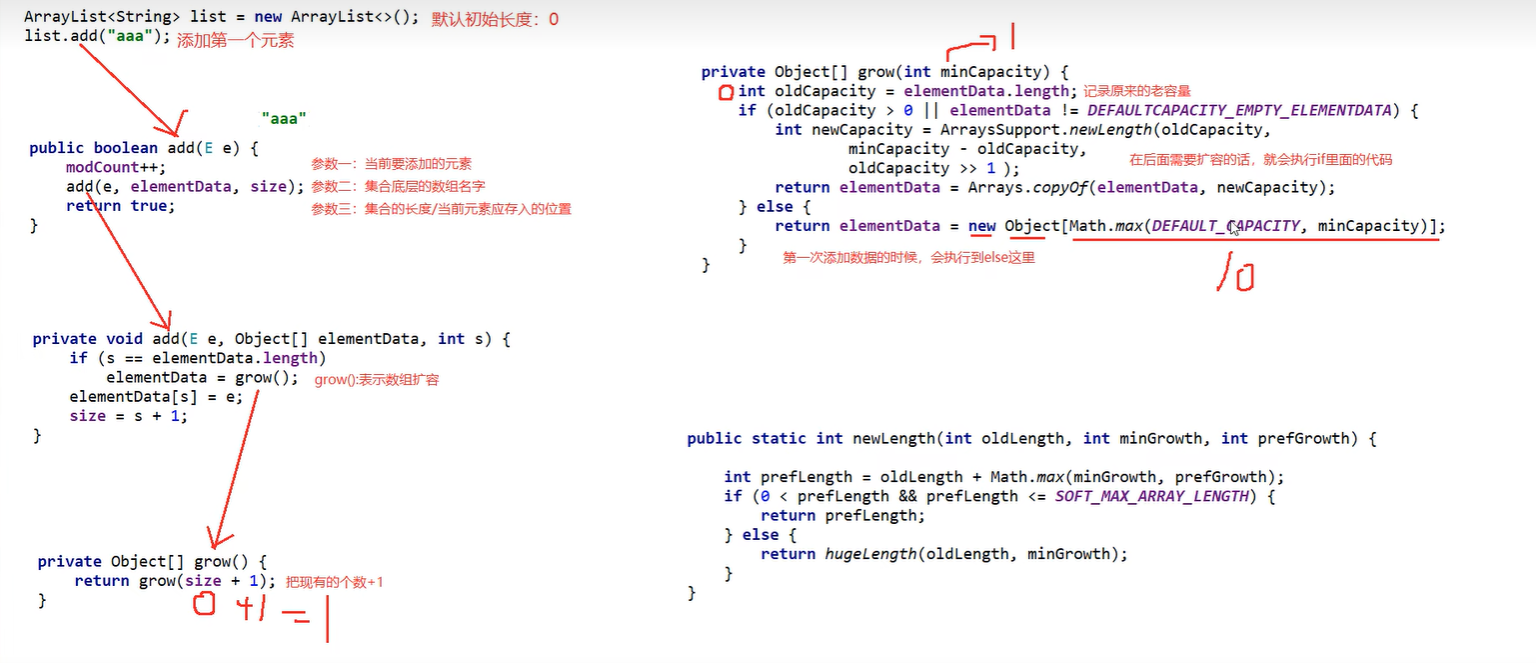
①利用空参创建的集合,在底层创建一个默认长度为0的数组
②添加第一个元素时,底层会创建一个新的长度为10的数组
③ 存满时,会扩容1.5倍
④如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准

LinkedList集合
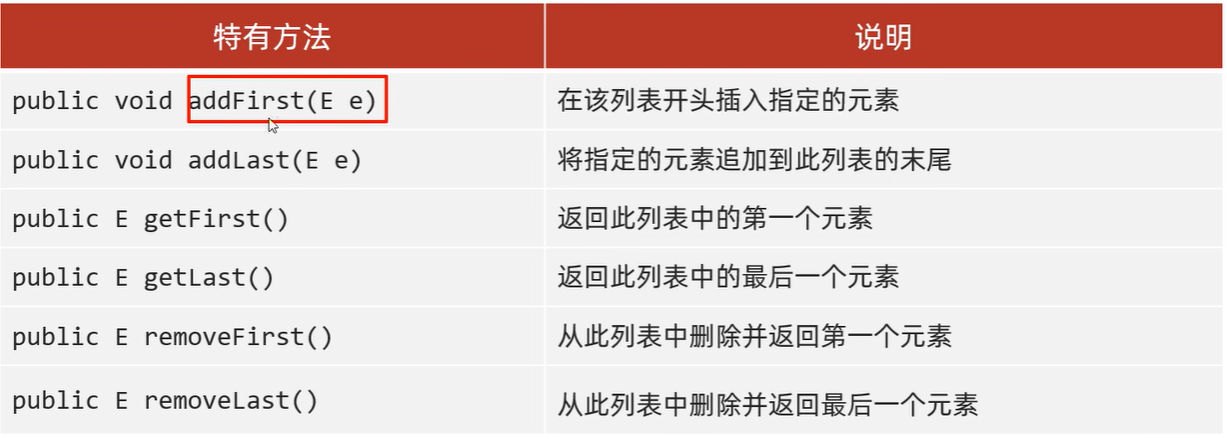
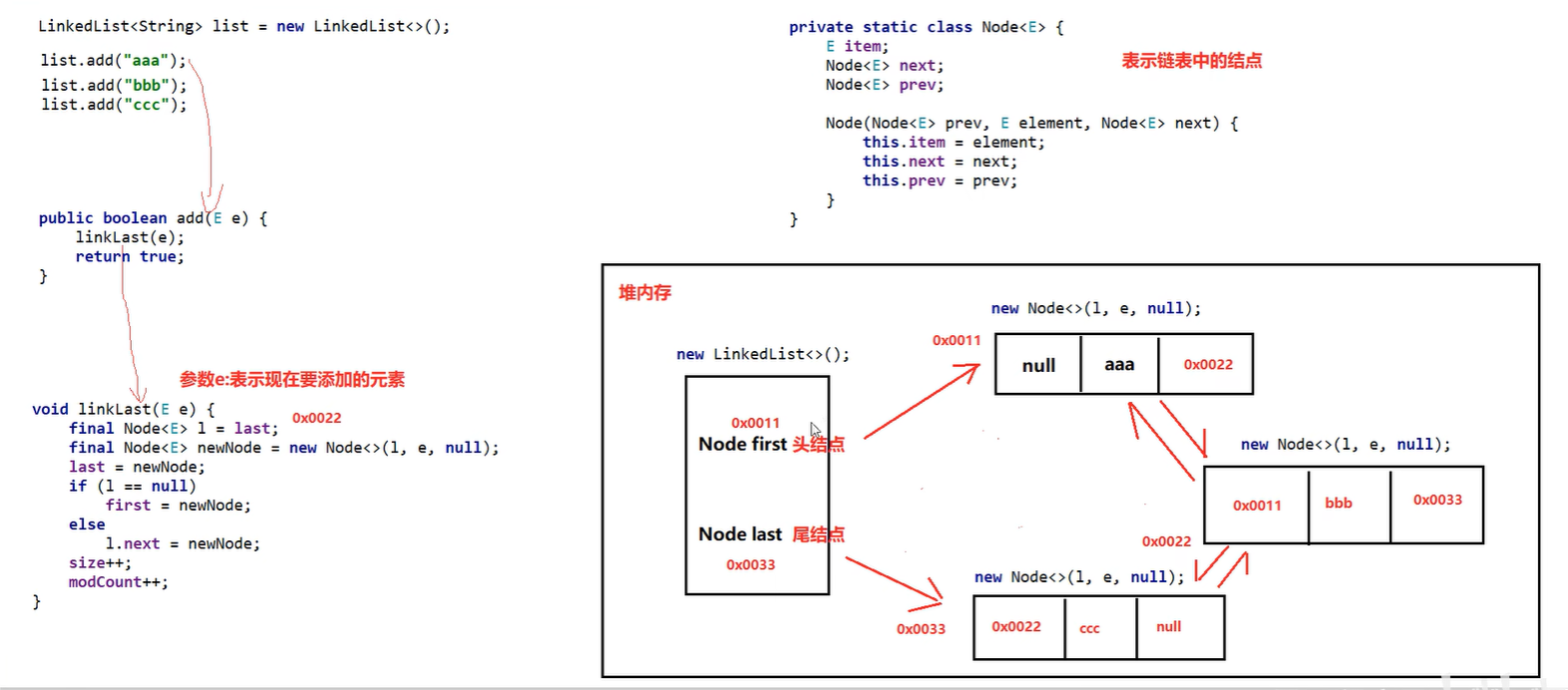
- 底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的。
- LinkedList本身多了很多直接操作首尾元素的特有APl
 底层源码
底层源码
迭代器底层源码

泛型
泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查
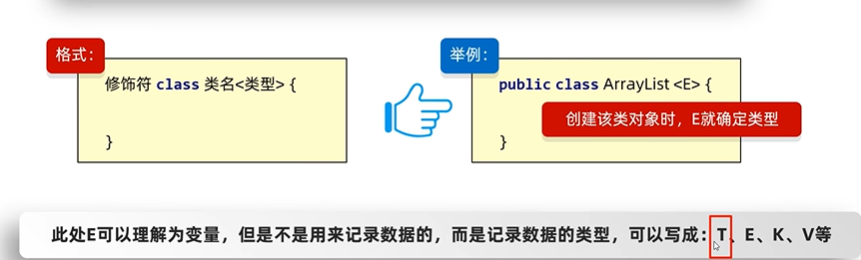
泛型的格式:<数据类型>
细节:
- 指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型
- 如果不写泛型,类型默认是Object
注意:泛型只支持引用数据类型
好处:
- 统一了数据类型。
- 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来。
import java.util.ArrayList;
import java.util.Iterator;
public class datedemo01 {
public static void main(String[] args) {
//结论:
/*
* 如果我们没有给集合指定恰当的类型,就认为所有的数据类型都是object类型
* 此时可以往集合添加任意的数据类型。
* 带来一个坏处:我们在获取数据的时候,无法使用他的特有行为。
* 此时推出了泛型,可以在添加数的时候就把类型进行统一。
* 而且我们在获取数据的时候,也省的强转了,非常的方便。
* */
ArrayList<String> list=new ArrayList();
list.add("aaa");
Iterator<String> it=list.iterator();
while(it.hasNext()){
String str=it.next();
System.out.println(str);
}
}
}
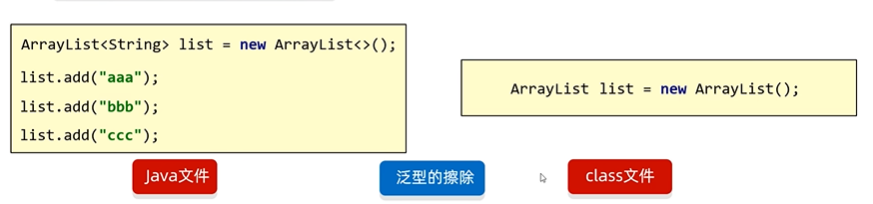
扩展知识:JAVA中的泛型是伪泛型
泛型可以在很多地方进行定义
类后面---》泛型类
方法上面---》泛型方法
接口上面--》泛型接口
泛型类
使用场景:当一个类中,某个变量的数据类型不确定时,就可可以定义带有泛型的类
import java.util.Arrays;
public class MyArrayList <E>{
Object[] obj=new Object[10];
int size;
public boolean add(E e){
obj[size]=e;
size++;
return true;
}
public E get(int index){
return (E)obj[index];
}
@Override
public String toString() {
return Arrays.toString(obj);
}
}
------测试
MyArrayList<String> mal=new MyArrayList<>();
mal.add("aaa");
mal.add("bbb");
mal.add("ccc");
System.out.println(mal.get(0));
System.out.println(mal);泛型方法
方法中参数类型不确定时
- 方案一:使用类名后面定义的泛型---类上定义的泛型在类中都能用
- 方案二:在方法声明上定义自己的泛型--只能在本方法中用

import java.util.ArrayList;
public class ListUtil {
private ListUtil(){}
//类中定义一个静态方法addAll,用来添加多个集合的元素
public static <E> void addALL(ArrayList <E> list,E e1){
list.add(e1);
}
}
--------
ArrayList<String> list=new ArrayList<>();
ListUtil.addALL(list,"aaa");
System.out.println(list);泛型接口
如何使用一个带泛型的接口
- 实现类给出具体类型
- 实现类延续泛型,创建对象时再确定具体类型
public class MyArrayList2 implements List<String> {...}
MyArrayList2 list=new MyArrayList2();
--------------------------------------------------------------
public class MyArrayList3<E> implements List<E> {...}
MyArrayList3<String> list3=new MyArrayList3<>();
泛型不具备继承性,但是数据具备继承性
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
method(list1);
method(list2);//报错
method(list3);//报错
//此时,泛型里面写的是什么类型,那么只能传递什么类型的数据
public static void method(ArrayList<Ye> list) {}
--------------------------------------------------------
class Ye {
}
class Fu extends Ye {
}
class Zi extends Fu {
}
泛型的通配符
应用场景:
1.如果我们在定义类、方法、接口的时候,如果类型不确定,就可以定义泛型类、泛型方法、泛型接口。
2.如果类型不确定,但是能知道以后只能传递某个继承体系中的,就可以泛型的通配符
关键点:可以限定类型的范围。
/*
希望:本方法虽然不确定是什么类型,但以后希望传递的是YeFuZi
此时:我们可以使用泛型的通配符:
?也表示不确定的类型
但可以进行类型的限定
? extendsE:表示可以传递E或者E所有的子类类型
? super E:表示可以传递E或者E所有的父类类型
*/
}
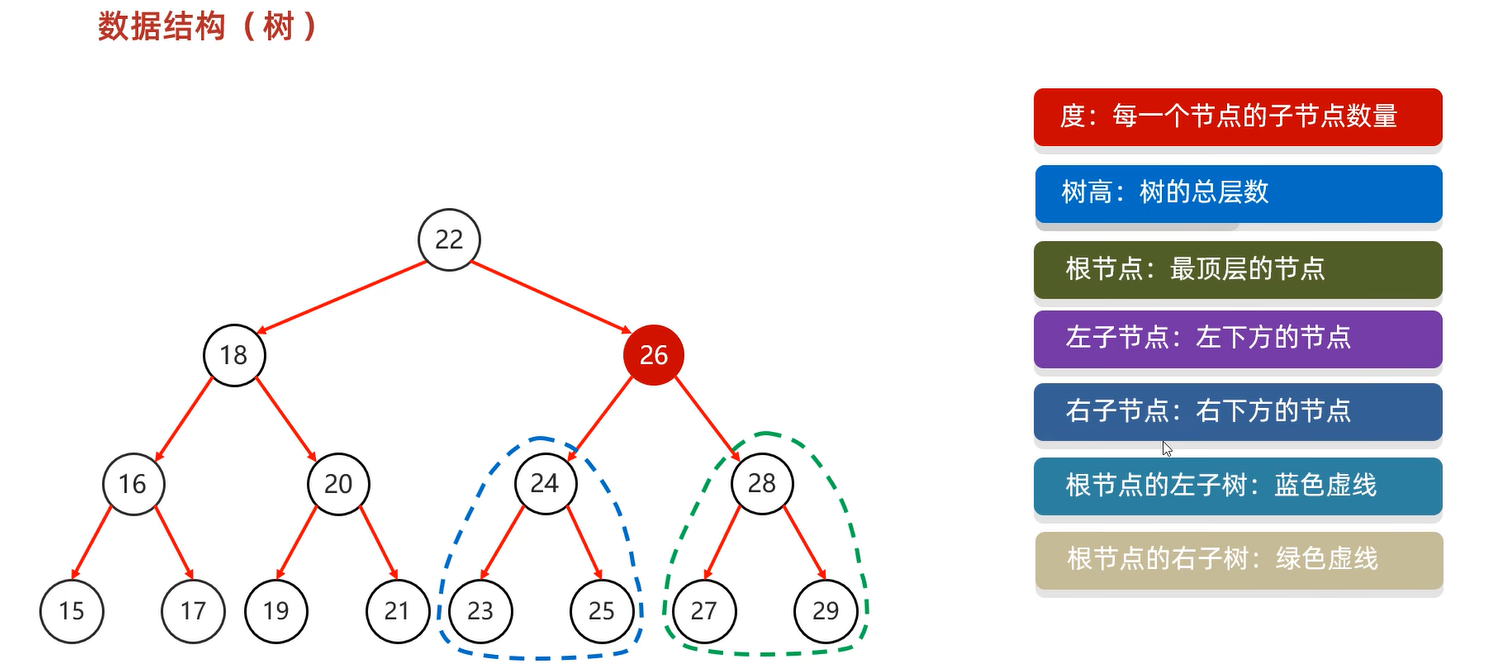
public static void method (ArrayList<? extends Ye> list){}数据结构(树)
二叉查找树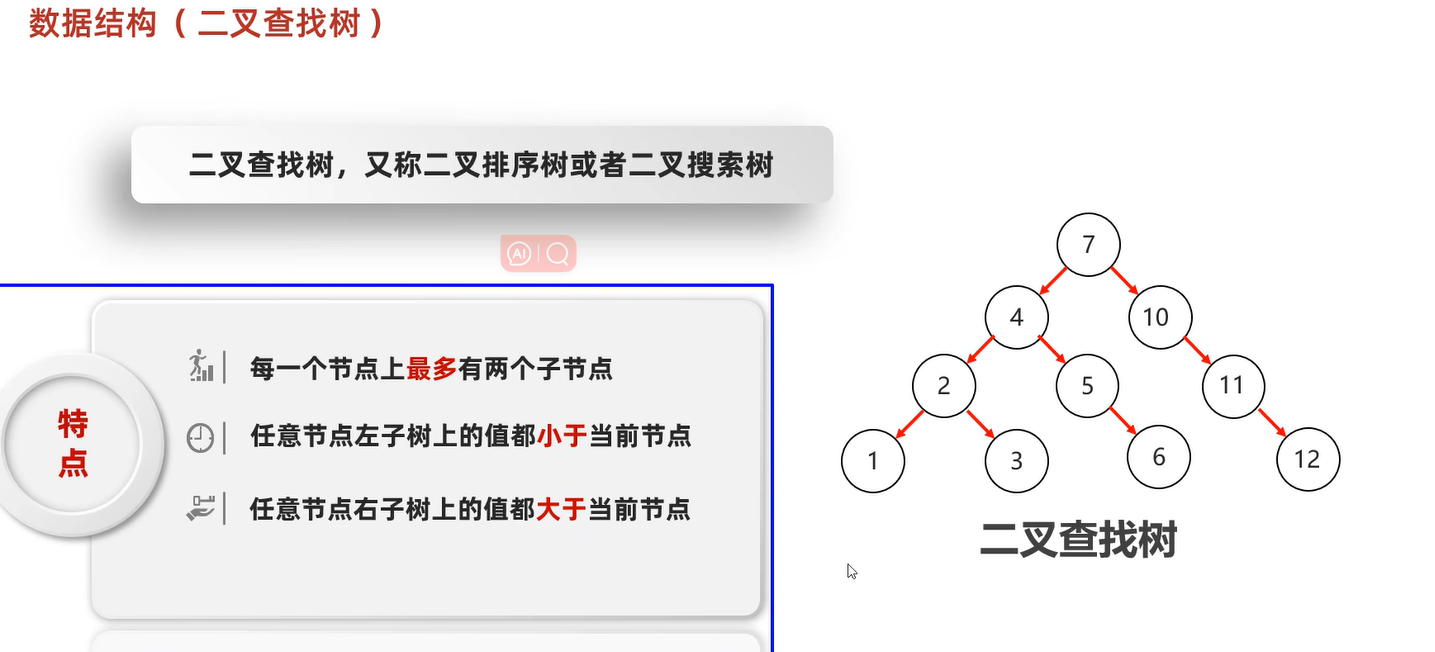
添加节点:
小的存左边,大的存右边,一样的不存
平衡二叉树
规则:任意节点左右子树的高度差不超过1
二叉树的遍历方式:
前序遍历
从根节点开始,按照当前节点,左子结点,右子结点的顺序遍历。
中序遍历
从最左边的子节点开始,按照左子结点,当前节点,右子节点遍历。
后序遍历
从最左边的子节点开始,按照左子结点,右子节点遍历,当前节点的顺序遍历
层序遍历
从根节点开始一层一层的去遍历
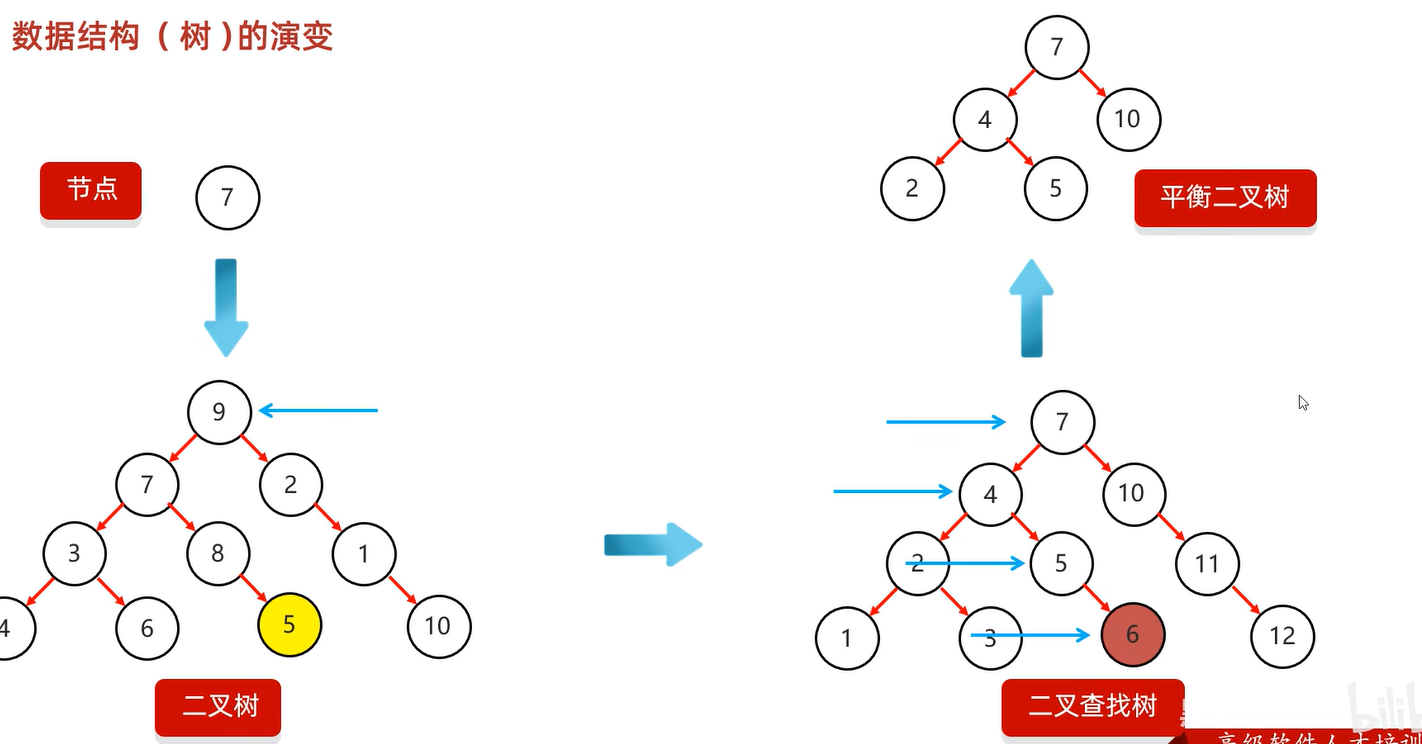
平衡二叉树左旋
确定支点:从添加的结点开始,不断的往父节点找不平衡的节点
步骤:1.以不平衡的点作为支点
2.把支点左旋降级,变成左子节点
3.晋升原来的右子节点
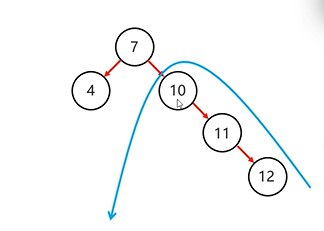 左旋后=》
左旋后=》
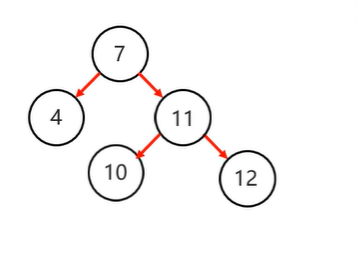
复杂情况:根节点为支点
步骤:1.以不平衡的点作为支点
2.将根节点的右侧往左拉
3.原先的右子节点变成新的父节点,并把多余的左子结点让出给已经降级的根节点当右子节点
 左旋后==》
左旋后==》
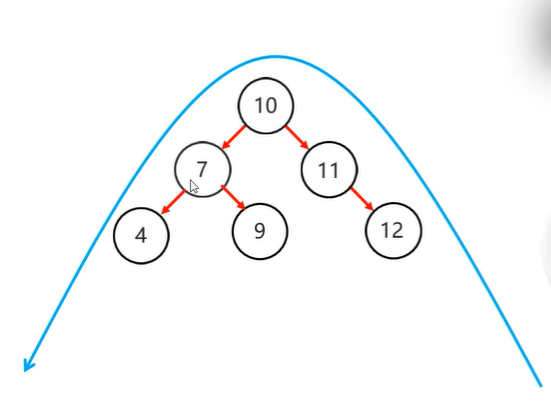
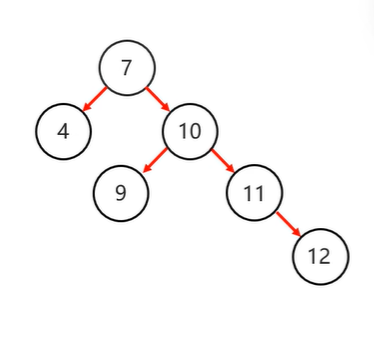
右旋=》同左旋
需要旋转的四种情况
1.左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡---》一次右旋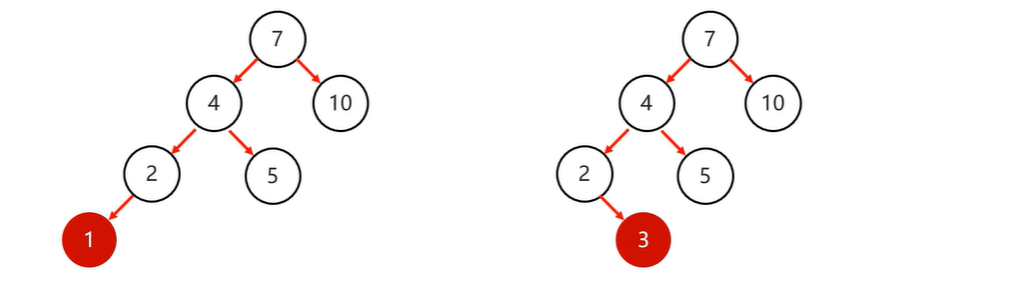
2.左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡
先局部左旋,再整体右旋
3.右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡==》一次右旋
4.右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡==》先局部右旋,再整体左旋
红黑树
是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色
每个节点可以是红或者黑;红黑树不是高度平衡的,它的平衡是通过“红黑规则”进行实现的、

红黑规则: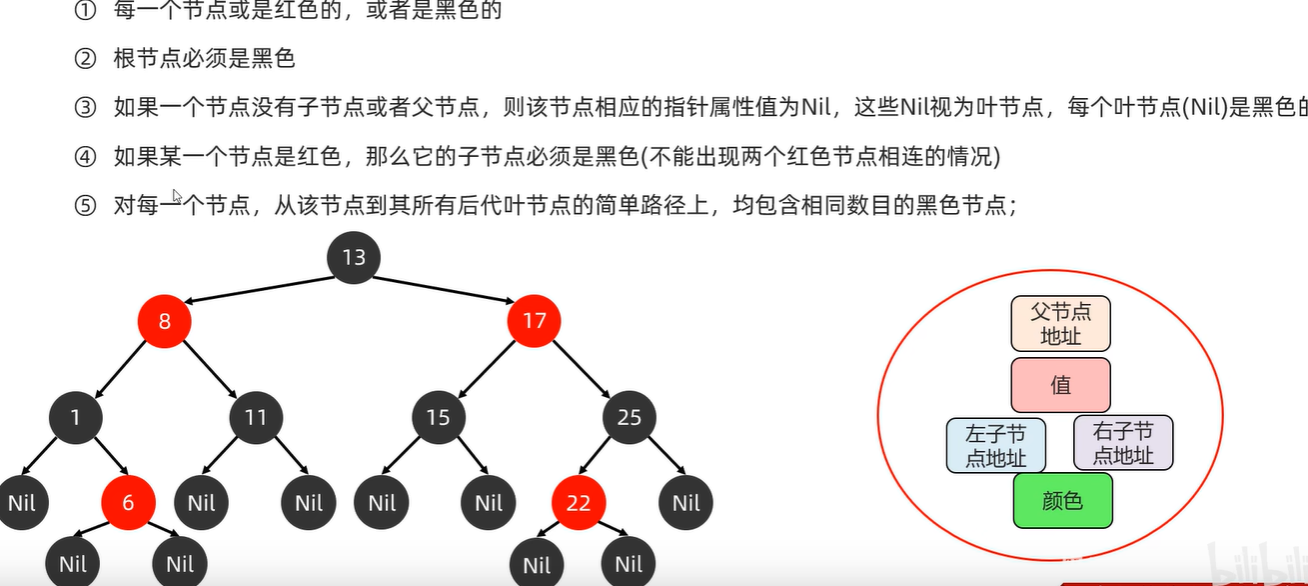
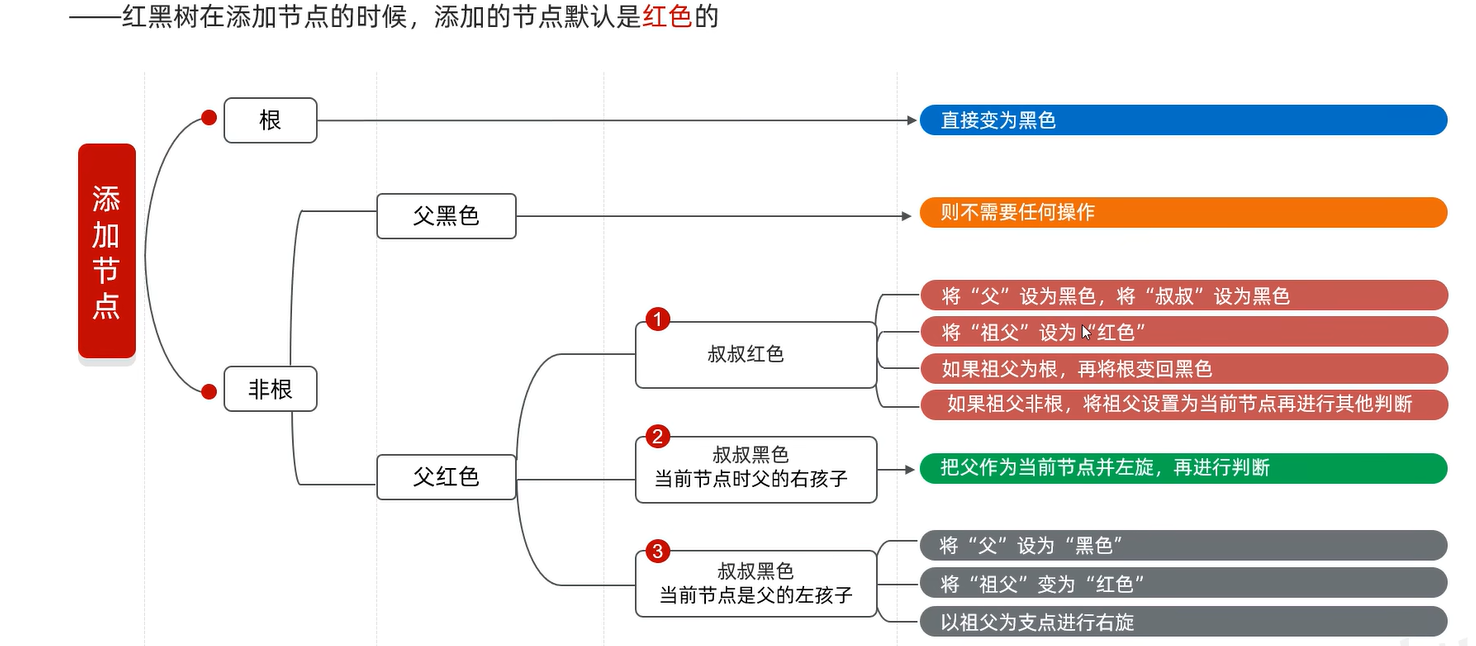
数据结构(红黑树)添加节点的规则
红黑树的增删改查性能都挺好,最浪费性能的是旋转,红黑树中旋转少。
Set集合
set集合的实现类
HashSet:无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet:可排序、不重复、无索引
set接口中的方法上基本与collection的API一致
IDEA的快捷键
ctrl+alt+m 选择语句,按 会抽取成一个方法。
ctrl+b 跟进
ctrl +alt+左键 回到上一步
ctrl+n搜索类
alt+7罗列出类的大纲视图 或者ctrl+F12,还可以直接输入字母搜索















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









