







HTTP报文概述
HTTP报文是HTTP应用程序之间传递的数据块。它们以文本形式的元信息开头,描述了报文的内容和含义,并可以包含可选的数据部分。这些报文在客户端、服务器和代理之间流动。
HTTP报文流动方向
在一次HTTP请求中,HTTP报文会从客户端流向代理,然后再流向服务器。在服务器完成处理后,报文会从服务器流向代理,再流向客户端。
请求报文和响应报文
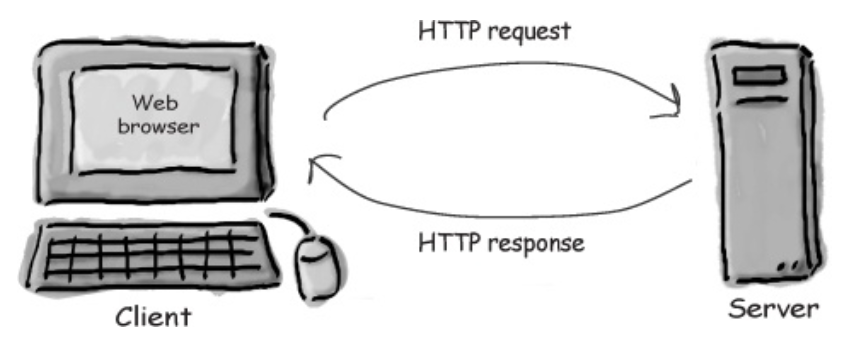
- 请求报文:请求报文是从客户端发送到服务器的报文。它包含了客户端对服务器的请求信息。
- 响应报文:响应报文是服务器作为响应发送到客户端的报文。它包含了服务器对客户端请求的响应结果。
以下是请求报文和响应报文的结构和组成部分的总结:
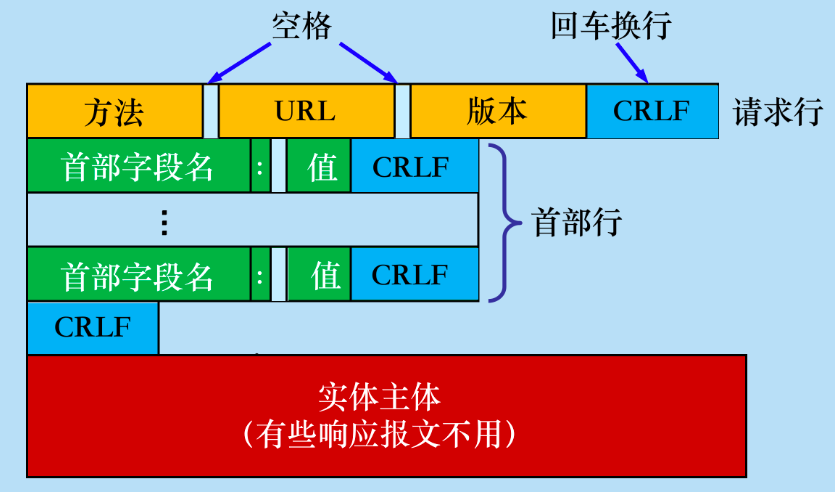
请求报文结构
| 报文部分 | 描述 |
|---|---|
| 请求行 | 包含请求方法、URL和HTTP协议版本 |
| 请求头部 | 包含关键字/值对,描述请求的信息 |
| 空行 | 标识头部的结束 |
| 请求包体 | 包含请求的数据,用于POST等请求方法 |
示例
POST /user HTTP/1.1 // 请求行
Host: www.user.com
Content-Type: application/x-www-form-urlencoded
Connection: Keep-Alive
User-agent: Mozilla/5.0. // 以上是请求头
(此处必须有一空行 | // 空行分割header和请求内容
name=world // 请求体(可选,如get请求时可选)
图解
响应报文结构
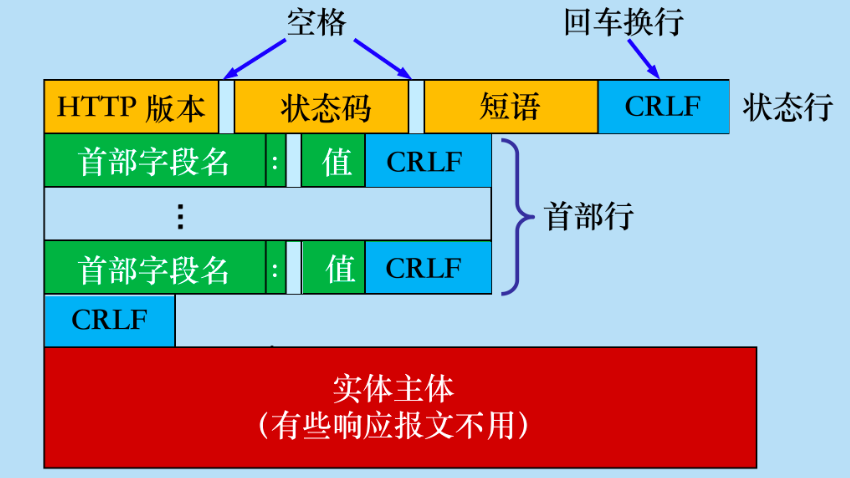
| 报文部分 | 描述 |
|---|---|
| 状态行 | 包含状态码和状态消息 |
| 响应头部 | 包含关键字/值对,描述响应的信息 |
| 空行 | 标识头部的结束 |
| 响应包体 | 包含响应的数据 |
示例
HTTP/1.1 200 OK // 响应行,表示请求成功,状态码为200
Date: Thu, 16 Jul 2023 15:30:00 GMT // 响应头,当前的日期和时间,标记响应生成时间
Server: Apache/2.4.18 (Ubuntu) // 响应头,服务器信息,指示响应的服务器软件和版本
Last-Modified: Thu, 16 Jul 2023 10:45:00 GMT // 响应头,上次修改时间,标记资源的最后修改时间
Content-Length: 88 // 响应头,响应体的长度,指示响应的内容长度为88个字节
Content-Type: text/html // 响应头,响应体的内容类型为HTML,指示响应的数据为HTML文档
Connection: Closed // 响应头,连接关闭,指示在响应后关闭连接,如果是Keep-Alive则表示保持连接
// 空行,用于分隔响应头和响应体,HTTP协议规定要使用一个空行来表示响应头和响应体的分隔。
<html> // 响应体,HTML文档的开始
<body>
<h1>Hello, World!</h1> // 响应体,显示的文本内容
</body>
</html> // 响应体,HTML文档的结束
图解
通过对HTTP报文的分析和理解,我们可以更好地理解和调试HTTP请求和响应。
请注意,HTTP报文还有其他一些特殊的头部字段和功能,但在本文中只涉及了最基本的部分。
请求与响应概述
HTTP通信由两部分组成: 客户端请求消息 与 服务端响应消息
浏览器发送HTTP请求的过程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yrpEiyox-1689487040542)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230629190944379.png)]](https://img-blog.csdnimg.cn/c433d65708ca46c5aecafa68a0c3c5da.png)
- 当我们在浏览器输入URL https://www.baidu.com 的时候,浏览器发送一个Request请求去获取 https://www.baidu.com 的html文件,服务器 把Response文件对象发送回浏览器。
- 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片、CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来。
请求目标(URL)
URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于windows的文件路径。
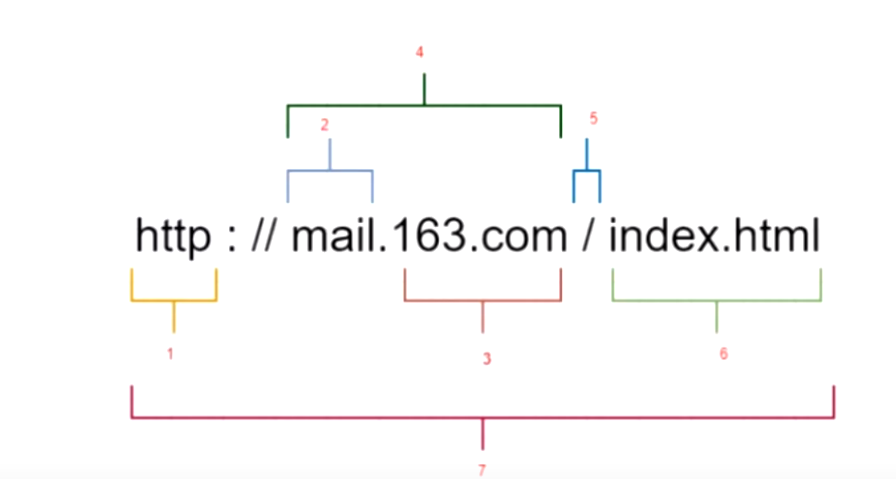
一个网址的组成:
- http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。
- mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。
- 163.com:这个是域名,是用来定位网站的独一无二的名字。
- mail.163.com:这个是网站名,由服务器名+域名组成。
- /:这个是根目录,也就是说,通过网站名找到服务器,然后在服务器存放网页的根目录。
- index.html:这个是根目录下的网页。
- http://mail.163.com/index.html:这个叫做URL,统一资源定位符,全球性地址,用于定位网上的资源。
请求行(Request Line)
- 请求行是HTTP请求报文的第一行,用于描述客户端向服务器发送的请求。
- 请求行由三个部分组成:请求方法、请求目标和HTTP协议版本。
- 请求方法表示对目标资源的操作类型,如GET、POST、PUT、DELETE等。
- 请求目标是客户端希望访问的资源的URL路径或相对路径。
- HTTP协议版本指定客户端和服务器之间使用的HTTP协议版本,如HTTP/1.1、HTTP/2等。
下表是对请求行中每个部分的解释:
| 请求方法 | 请求目标 | HTTP协议版本 |
|---|---|---|
| GET | /index.html | HTTP/1.1 |
| POST | /login | HTTP/1.1 |
| PUT | /data.json | HTTP/1.1 |
在上面的示例中,第一行表示了三个部分:使用GET方法请求目标为/index.html的资源,并使用HTTP/1.1协议版本。第二行使用POST方法请求目标为/login的资源。第三行使用PUT方法请求目标为/data.json的资源。
注意:请求行的每个部分之间使用空格进行分隔。
请求行是HTTP请求报文的重要组成部分,它提供了客户端对服务器所需资源的具体描述,以便服务器能够正确处理并返回相应的结果。
请求头(header)
请求头是HTTP请求的一部分,它包含了向服务器发送请求时的元信息和配置信息。通过请求头,我们可以告诉服务器一些关于我们的请求的附加信息,例如用户代理信息、所需的数据格式、请求的接受语言等。请求头通常是一个包含键值对的字典,每个键值对表示一个请求头字段。
常用的请求头字段
下表列出了一些常用的HTTP请求头字段及其作用:
| 请求头字段 | 作用 |
|---|---|
| User-Agent | 用于标识发送请求的用户代理(浏览器或爬虫) |
| Accept | 告知服务器可以接受的响应数据类型 |
| Accept-Encoding | 告知服务器可以接受的响应数据压缩格式 |
| Referer | 表示当前请求是从哪个页面或URL跳转过来的 |
| Cookie | 用于携带请求的Cookie信息,维持用户的登录状态 |
| Authorization | 在进行身份验证时,用于传递身份认证凭据 |
| Content-Type | 当发送POST请求时,指定请求体的数据类型 |
| Content-Length | 当发送POST请求时,指定请求体的长度 |
| If-None-Match | 在使用缓存时,用于标识资源的版本号,避免重复下载 |
| Host | 指定目标服务器的域名或IP地址 |
加粗的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头更为重要,但是这里需要注意的是并不意味这其余的不重要,因为有的网站的运维或者开发人员可能剑走偏锋,会使用一些比较不常见的请求头来进行爬虫的甄别
请求体(Request Body)和请求参数
- 请求体(Request Body)是HTTP请求报文中可选的部分,不在 GET 方法中使用,而是在POST方法中使用,用于向服务器发送附加的数据。
- POST方法通常用于需要客户填写表单的场合,通过请求体传递表单数据。
- 请求体的格式和内容取决于所发送的数据类型和服务器端的要求。
- 请求体的数据类型由Content-Type请求头字段指定。
- 常见的Content-Type类型包括application/json、application/x-www-form-urlencoded、multipart/form-data、text/plain和application/xml等。
- Content-Length请求头字段用于指定请求体的长度,以确保服务器正确解析请求报文。
补充解释:请求参数
- 请求参数是用于向服务器传递数据的信息,可以通过请求体或请求URL传递。
- 请求参数通过键值对的形式表示,如param1=value1¶m2=value2。
- 在请求体中,可以使用类似param1=value1¶m2=value2的形式编码多个请求参数。
- 在请求URL中,可以使用类似/chapter15/user.html?param1=value1¶m2=value2的形式传递请求参数。
下表是对请求体类型、示例和说明的总结:
| Content-Type | 请求体示例 | 说明 |
|---|---|---|
| application/json | {“name”: “John”, “age”: 25} | JSON格式的请求体 |
| application/x-www-form-urlencoded | name=John&age=25 | URL编码的表单数据 |
| multipart/form-data | (二进制数据流) | 用于上传文件或二进制数据 |
| text/plain | This is a plain text request body. | 纯文本格式的请求体 |
| application/xml | John25 | XML格式的请求体 |
补充解释:请求参数也可以通过请求URL中的查询字符串(query string)传递。例如,/chapter15/user.html?param1=value1¶m2=value2。
通过请求体和请求参数,客户端可以向服务器传递不同类型的数据,以实现复杂的操作和交互。
请求方法(Method)
HTTP请求可以使用多种请求方法,但是爬虫最主要就两种方法:GET和POST方法。
- get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
- post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用
post请求。
以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
GET与POST方法的区别:
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数都显示在浏览器网址上,即Get"请求的参数是URL的一部分。例如: http://www.baidu.com/s?wd=Chinese
- POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据。请求的参数类型包含在"Content-Type"消息头里,指明发送请求时要提交的数据格式。
注意:
网站制作者一般不会使用Get方式提交表单,因为有可能会导致安全问题。比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。并且浏览器会记录历史信息,导致账号不安全的因素存在。
案例-添加请求头发送请求
import requests # 导入requests模块,用于发送HTTP请求
response = requests.get('https://movie.douban.com/top250') # 发送GET请求并获取响应
print(response.text) # 打印响应内容
为什么请求不到数据????简单分析一下有哪些原因
- 可能被网站的反爬虫机制拦截:有些网站会采取一些反爬虫手段来限制爬虫程序的访问,例如设置请求头信息、验证码等。你可以尝试模拟浏览器行为,如设置合适的请求头信息,或者使用代理等方式绕过这些反爬虫机制。
- 可能需要登录或授权才能访问:如果网站需要登录或者授权才能获取数据,你需要先进行登录或者提供合适的身份认证信息。
- 可能网站的接口或页面发生了变化:如果网站的接口或页面结构发生了变化,你使用的代码可能不再适用。你可以尝试检查网站源代码、开发者工具等来确定接口或页面是否发生了变化,并相应地调整你的代码。
- 请求地址可能有加密
cookie(加密)
ssl加密
爬虫:模拟<伪装>客户端(浏览器,手机app。。。)用户批量请求服务器(百度,阿里, 。。。。)数据
爬虫模拟伪装时,添加headers可以模拟浏览器发送请求,以避免被目标网站识别为爬虫。headers是一个字典,包含了请求头的各种信息,例如User-Agent、Accept-Language等。这些信息可以告诉目标网站,我们的请求是来自于一个正常的浏览器,而不是一个自动化的爬虫程序。 通过设置合适的headers,我们可以使请求看起来更像是由真实用户发起的,提高爬取数据的成功率。常见的headers信息包括浏览器类型、操作系统、语言偏好等。不同的网站可能对headers的要求不同,因此需要根据具体情况来设置合适的headers。 需要注意的是,有些网站可能会对headers进行检测,如果发现headers中的某些字段不符合预期,可能会拒绝响应或采取其他反爬虫措施。因此,在编写爬虫时,需要仔细观察目标网站的请求头信息,并根据需要进行相应的伪装和配置。
import requests # 导入requests模块,用于发送HTTP请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3', # 设置请求头User-Agent,模拟浏览器访问
'Host': 'movie.douban.com', # 设置请求头Host,指定请求的目标主机
'Cookie': 'bid=HMEe4sq5cq8; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1688286002%2C%22https%3A%2F%2Fwww.google.com%2F%22%5D; _pk_id.100001.4cf6=b664f37d12f7536b.1688286002.; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.179853892.1688286003.1688286003.1688286003.1; __utmb=30149280.0.10.1688286003; __utmc=30149280; __utmz=30149280.1688286003.1.1.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utma=223695111.1154849834.1688286003.1688286003.1688286003.1; __utmb=223695111.0.10.1688286003; __utmc=223695111; __utmz=223695111.1688286003.1.1.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided)' # 设置请求头Cookie,用于访问需要登录的网站
}
response = requests.get('https://movie.douban.com/top250', headers=headers) # 发送带有请求头的GET请求并获取响应
print(response.text) # 打印响应内容
#添加请求头伪装,能够得到我们想要请求的数据
#需要添加的请求头字段,推荐加上
"""
Origin :资源的起始位置
User-Agent :浏览器的身份标识
Host :需要请求服务器的域名
Referer :防盗链
Cookies : 用户身份标识(能不加就不要加)
"""
User-Agent是HTTP请求头的一部分,用于标识发送请求的客户端(通常是浏览器或爬虫程序)。它包含了关于客户端的信息,例如浏览器类型、操作系统、版本号等。
User-Agent在爬虫中很重要,因为很多网站会根据User-Agent来判断请求的来源。一些网站可能会拒绝来自爬虫的请求,或者返回不同的内容给爬虫,以防止数据被大量抓取。通过设置合适的User-Agent,可以使请求看起来更像是由真实用户发起的,提高爬取数据的成功率。
User-Agent可以不是和你浏览器上一样的,但是要合理选择一个常见的浏览器User-Agent,以提高通过网站检测的概率。在网络上随便找一个User-Agent可能并不是一个好的选择,因为一些常见的爬虫User-Agent已经被网站加入了黑名单。建议使用一些常见的浏览器User-Agent,或者根据目标网站的要求自定义User-Agent,以确保请求能够正常通过。
# response.request 查看请求体信息
print(response.request.url) #查看请求体中的url地址
print(response.request.headers) #查看请求体中的请求头信息,requests模块在请求的时候会自动带上常见的请求头字段
print(response.request.method) #查看请求体中的请求方法
状态行(Status Line)
- 状态行是HTTP响应报文的第一行,用于描述服务器对客户端请求的响应状态。
- 状态行由三个部分组成:HTTP协议版本、状态码和状态消息。
- HTTP协议版本指定了服务器和客户端之间所使用的HTTP协议版本,如HTTP/1.1、HTTP/2等。
- 状态码是一个三位数字,表示服务器对请求的处理结果。
- 状态消息是对状态码的简短描述,提供了更详细的响应信息。
下表是对状态行中每个部分的解释:
| HTTP协议版本 | 状态码 | 状态消息 |
|---|---|---|
| HTTP/1.1 | 200 | OK |
| HTTP/1.1 | 404 | Not Found |
| HTTP/1.1 | 500 | Internal Server Error |
在上述示例中,第一行表示了三个部分:使用HTTP/1.1协议版本,状态码为200,状态消息为OK。第二行使用HTTP/1.1协议版本,状态码为404,状态消息为Not Found。第三行使用HTTP/1.1协议版本,状态码为500,状态消息为Internal Server Error。
状态行是HTTP响应报文的重要组成部分,它提供了关于服务器对客户端请求的处理结果的信息。状态码帮助客户端了解请求的成功与否,以及出现错误时的具体问题。
注意:
- 常见的状态码有200(OK,请求成功)、404(Not Found,未找到请求的资源)、500(Internal Server Error,服务器内部错误)等。
- 状态行的每个部分之间使用空格进行分隔。
通过状态行,服务器向客户端传递了对请求的处理结果,使客户端能够根据不同的状态码和状态消息来采取相应的操作。
响应头(Response Header)
- 响应头是HTTP响应报文中的一部分,位于响应行之后,用于传递关于响应的附加信息。
- 响应头包含了服务器对客户端请求的进一步描述,如日期、服务器信息、内容类型等。
- 响应头由多个键值对组成,每个键值对表示一条响应头字段。
下表是常见的响应头字段及其解释:
| 响应头字段 | 说明 |
|---|---|
| Date | 当前的日期和时间,标记响应生成时间 |
| Server | 服务器信息,指示响应的服务器软件和版本 |
| Last-Modified | 上次修改时间,标记资源的最后修改时间 |
| Content-Length | 响应体的长度,指示响应的内容长度 |
| Content-Type | 响应体的内容类型,指示响应的数据为何种类型 |
| Connection | 连接状态,指示在响应后是否关闭连接 |
| Set-Cookie | 设置Cookie,用于在客户端存储会话信息或其他数据 |
| Cache-Control | 缓存控制,指示客户端如何处理响应的缓存 |
| Expires | 过期时间,指示响应内容的过期时间 |
| Content-Encoding | 内容编码,指示响应内容的压缩或编码方式 |
通过响应头,服务器可以提供有关响应的附加信息,以帮助客户端正确解析和处理响应。客户端可以根据响应头字段来确定如何处理响应内容、缓存策略、数据类型等。
注意:
- 响应头字段是大小写不敏感的,但通常以首字母大写的形式呈现。
- 响应头字段之间使用换行符分隔。
响应头提供了关于响应的重要元数据信息,使客户端能够更好地理解和处理服务器的响应。
响应体(Response Body)
- 响应体是HTTP响应报文的一部分,包含了服务器返回给客户端的实际数据内容。
- 响应体通常包含了HTML、JSON、XML、图像、视频或其他类型的数据。
- 响应体的内容和格式取决于服务器返回的数据类型和客户端的请求。
下表是常见的Content-Type和响应体示例:
| Content-Type | 响应体示例 |
|---|---|
| text/html | Hello World! |
| application/json | {“name”: “John”, “age”: 25} |
| application/xml | John25 |
| image/jpeg | (二进制图像数据) |
| video/mp4 | (二进制视频数据) |
在上述示例中,Content-Type指定了响应体的数据类型。第一行使用text/html作为Content-Type,响应体为一个简单的HTML页面。第二行使用application/json,响应体为一个JSON对象。第三行使用application/xml,响应体为一个XML文档。最后两行表示了图像和视频数据的二进制表示。
响应体是HTTP响应报文中传输的实际数据,它提供了服务器返回给客户端的内容。客户端可以根据Content-Type来确定如何解析和处理响应体的数据。
注意:
- 响应体的长度可以通过Content-Length响应头字段来指定。
- 对于大型文件或数据,服务器通常使用分块传输编码(chunked transfer encoding)将响应体分割为多个块进行传输。
通过响应体,服务器可以向客户端传递所请求资源的实际内容,实现动态网页、API数据响应、图像和媒体文件的传输















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











