







在headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。
首先,让我们了解一下Cookie是如何在HTTP请求中传递的。
当浏览器第一次访问一个网站时,服务器会在响应中返回一个Set-Cookie头部,其中包含了一个名为"sessionID"的Cookie值。浏览器会将这个Cookie保存在本地,并在后续访问中自动将它包含在请求的Cookie字段中发送给服务器。这个Cookie值被浏览器保存在本地,以便在与该网站的后续交互中使用。
类似于你在购物时所得到的商店小票,互联网上的Cookie也起着类似的作用。当你访问一个网站时,服务器会在你的浏览器中创建一个Cookie,其中包含了一些重要的信息,如你在网站上的活动记录、登录状态等。浏览器会将这个Cookie保存下来。
下一次当你再次访问同一个网站时,浏览器会自动将保存的Cookie携带在请求中发送给服务器。通过这个Cookie,服务器能够认出你是之前的访问者,并根据你的个人喜好或登录状态来提供个性化的服务,比如显示你之前浏览过的商品、保持你的登录状态等。
通过Cookie,网站可以记住你的喜好和活动记录,为你提供更好的用户体验。比如,在购物网站上,Cookie可以帮助保存你的购物车内容,使你离开网站后再次访问时不会丢失已选购的商品。同时,Cookie还可以用于识别用户身份,确保只有授权用户可以访问特定的页面或功能。
然而,Cookie也存在一些缺点。它会增加网络流量,因为每次请求都会携带Cookie信息。此外,由于Cookie存储在用户的浏览器中,可能会受到黑客的攻击和利用。另外,由于浏览器的限制,Cookie只能在创建它们的域名下使用,无法在其他域名下获取和使用。
综上所述,Cookie是一种在互联网上存储用户信息的机制,帮助网站识别用户身份和提供个性化的服务。它类似于购物时的小票,用于在离开网站一段时间后返回时继续购物或保持已选购的商品。但我们也需要注意Cookie的安全性和浏览器的限制
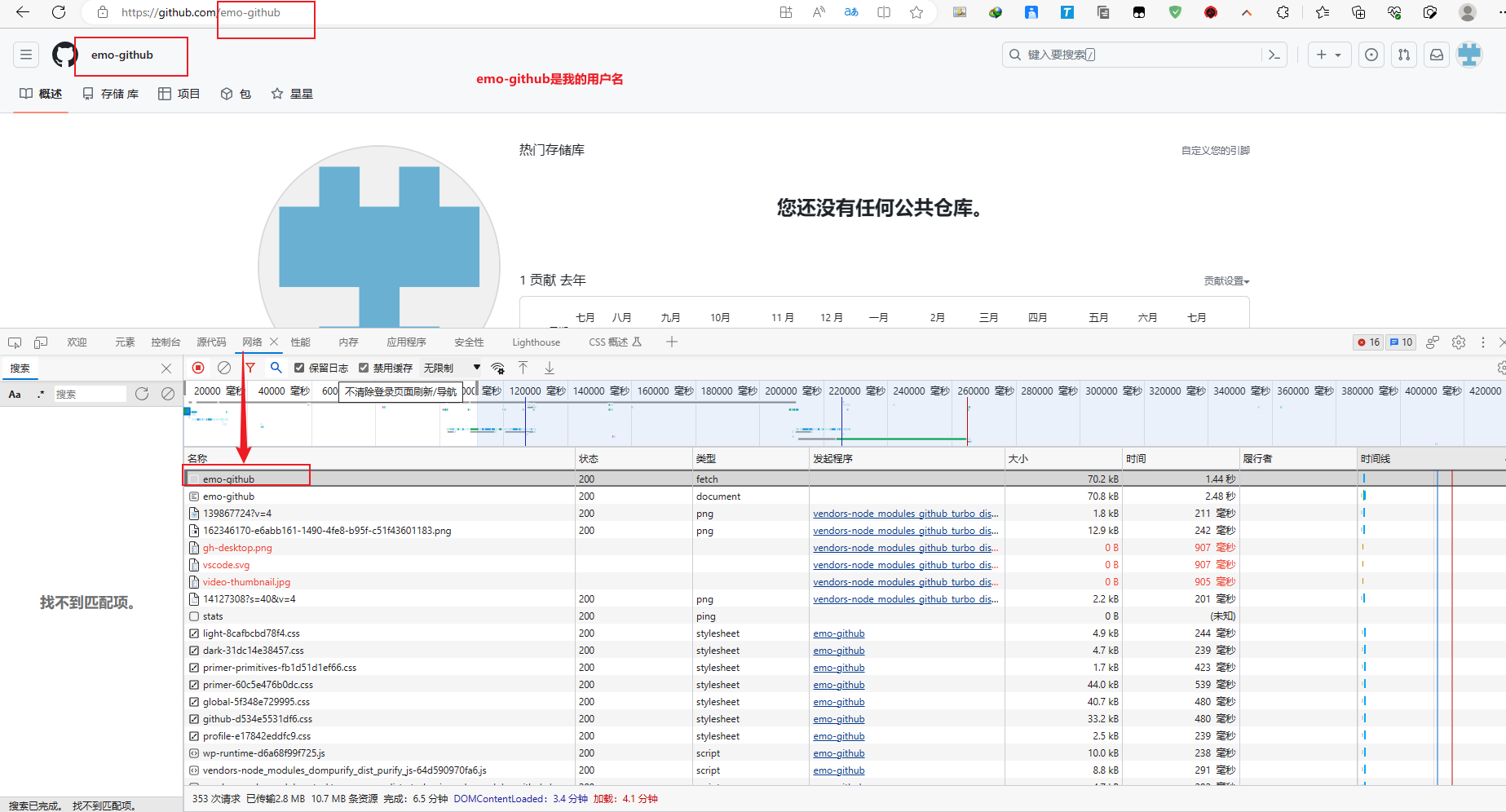
我们以github登陆为例:
github登陆抓包分析
- 打开浏览器,右键-检查,点击
Net work,勾选Preserve log - 访问github登陆的url地址
https://github.com/login - 输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Your profile访问
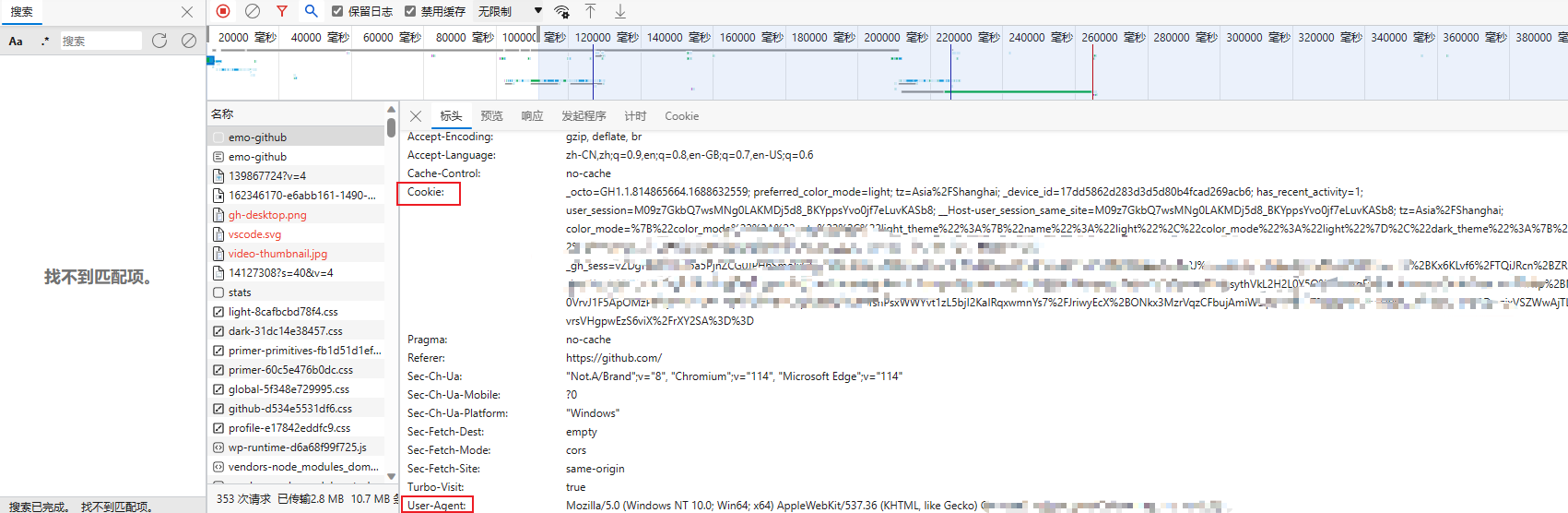
https://github.com/USER_NAME - 确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie
完成代码
- 从浏览器中复制User-Agent和Cookie
- 浏览器中的请求头字段和值与headers参数中必须一致
- headers请求参数字典中的Cookie键对应的值是字符串
运行代码验证结果
在打印的输出结果中搜索title,html中的标题文本内容如果是你的github账号,则成功利用headers参数携带cookie,获取登陆后才能访问的页面
示例代码展示(没有cookies):
# 导入requests模块,用于发送HTTP请求
import requests
# 要访问的GitHub用户资料页面的URL
url = 'https://github.com/USER_NAME'
# 构造请求头字典,包含User-Agent和Cookie等信息
headers = {
# 设置User-Agent,模拟浏览器发送请求
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
# 设置Cookie,用于身份验证或其他需要的信息
'Cookie': 'xxx这里是复制过来的cookie字符串'
}
# 发起GET请求,携带请求头参数
resp = requests.get(url, headers=headers)
# 打印响应的文本内容
print(resp.text)
运行效果:

示例代码展示(有cookies):
# 导入requests模块,用于发送HTTP请求和接收响应
import requests
# 定义请求头,设置用户代理(User-Agent)信息和Cookie
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'cookie': '_octo=GH1.1.814865664.1688632559; preferred_color_mode=light; tz=Asia%2FShanghai; _device_id=17dd5862d283d3d5d80b4fcad269acb6; has_recent_activity=1; user_session=M09z7GkbQ7wsMNg0LAKMDj5d8_BKYppsYvo0jf7eLuvKASb8; __Host-user_session_same_site=M09z7GkbQ7wsMNg0LAKMDj5d8_BKYppsYvo0jf7eLuvKASb8; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=emo-github; _gh_sess=vZDgHKIDHKFl5a5PjnZCG0JPH6SmoIxGFjgFUPRZJRmwEodGQdkye7SLZ3n6B9amGQe6P%2BZZsq%2BMn2Wkb9usRBRJ%2Bm0mEIpWENwa8jvuZt7z%2BJGrubtvG3%2BKx6KLvf6%2FTQiJRcn%2BZRs%2BaW1jEiyehy%2B5rPpwsjeruKvwb9BV1yf%2BQJOiNrq2i2u7waDegvtORzIj16VrNgajbN%2BUlaJ7DTuTeN4SLano6nVGgGUFOHltiCh2VVj9xiq7Rh1FkK5RurRqMHKzsythVkL2H2L0Y5Q%2B8ntqEy6XaOKvLnLAN9fUHSkrY7xvd2HHfp%2BMsCipZoPW%2B2FJ3cxZ9ku0VrvJ1F5ApOMzPnNysTw87NB94qt%2FkOEYHwpHHP%2FvA7TsnPsxWWYvt1zL5bjI2KaIRqxwmnYs7%2FJriwyEcX%2BONkx3MzrVqzCFbujAmiWDp3%2B7vTEIQq0u4xxhO3vMEm5ZDg%3D%3D--zixVSZWwAjTLtBjB--vrsVHgpwEzS6viX%2FrXY2SA%3D%3'
}
# 定义要请求的URL地址
url = 'https://github.com/emo-github'
# 发送GET请求并获取响应
response = requests.get(url, headers=headers)
# 打印响应内容并将其以UTF-8编码解析为字符串并输出
print(response.content.decode())
运行效果:

知识点:掌握 headers中携带cookie
cookies参数的使用
上一小节我们在headers参数中携带cookie,也可以使用专门的cookies参数
-
cookies参数的形式:字典
cookies = {"cookie的name":"cookie的value"}- 该字典对应请求头中Cookie字符串,以分号、空格分割每一对字典键值对
- 等号左边的是一个cookie的name,对应cookies字典的key
- 等号右边对应cookies字典的value
-
cookies参数的使用方法
response = requests.get(url, cookies) -
将cookie字符串转换为cookies参数所需的字典:
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')} -
注意:cookie一般是有过期时间的,一旦过期需要重新获取
# 导入requests模块,用于发送HTTP请求
import requests
# 要访问的GitHub用户资料页面的URL
url = 'https://github.com/USER_NAME'
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
# 构造cookies字典
cookies_str = '从浏览器中copy过来的cookies字符串'
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
lit('=')[-1] for cookie in cookies_str.split('; ')}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











