








1.概述
Apache Kafka最早是由LinkedIn开源出来的分布式消息系统,现在是Apache旗下的一个子项目,并且已经成为开源领域应用最广泛的消息系统之一。Kafka社区非常活跃,从0.9版本开始,Kafka的标语已经从“一个高吞吐量,分布式的消息系统”改为"一个分布式流平台"。
Kafka和传统的消息系统不同在于:
- kafka是一个分布式系统,易于向外扩展。
- 它同时为发布和订阅提供高吞吐量
- 它支持多订阅者,当失败时能自动平衡消费者
- 消息的持久化
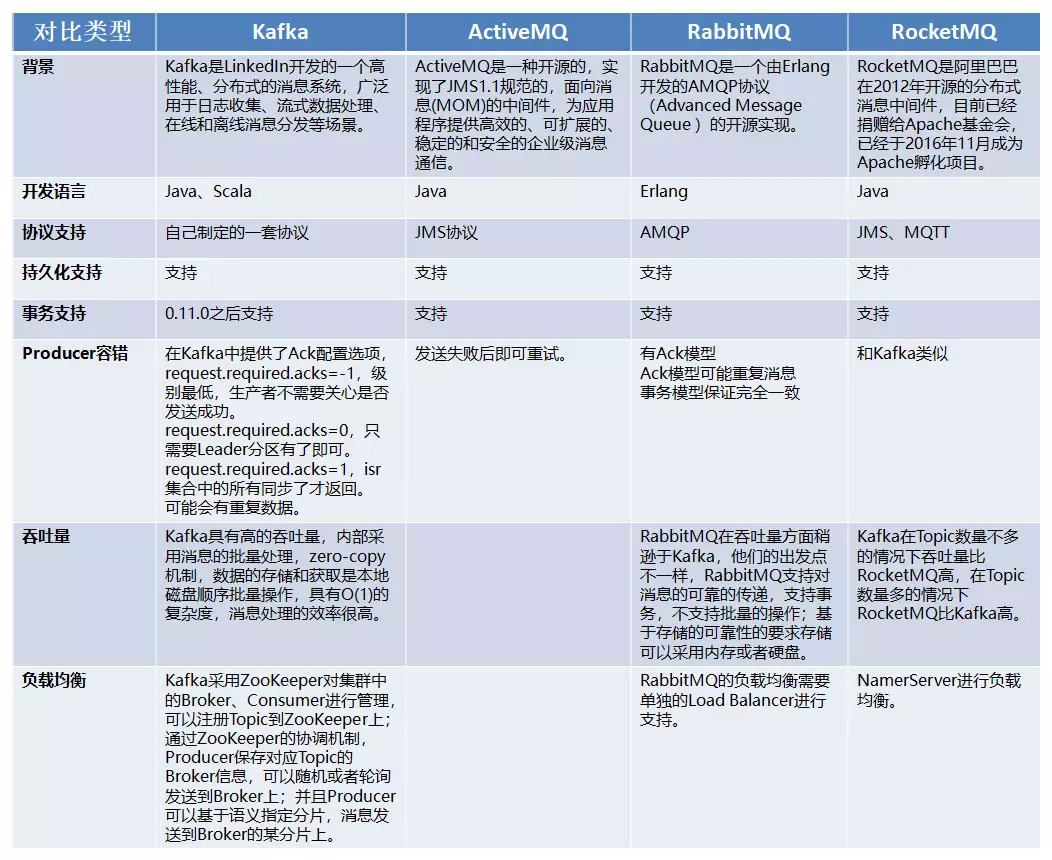
kafka和其他消息队列的对比:
2.入门实例
2.1生产者
producer

2.2 消费者

3.Kafka架构原理
对于kafka的架构原理我们先提出几个问题?
1.Kafka的topic和分区内部是如何存储的,有什么特点?
2.与传统的消息系统相比,Kafka的消费模型有什么优点?
3.Kafka如何实现分布式的数据存储与数据读取?
3.1Kafka架构图

3.2kafka名词解释
在一套kafka架构中有多个Producer,多个Broker,多个Consumer,每个Producer可以对应多个Topic,每个Consumer只能对应一个ConsumerGroup。
整个Kafka架构对应一个ZK集群,通过ZK管理集群配置,选举Leader,以及在consumer group发生变化时进行rebalance。

3.3Topic和Partition
在Kafka中的每一条消息都有一个topic。一般来说在我们应用中产生不同类型的数据,都可以设置不同的主题。一个主题一般会有多个消息的订阅者,当生产者发布消息到某个主题时,订阅了这个主题的消费者都可以接收到生产者写入的新消息。
kafka为每个主题维护了分布式的分区(partition)日志文件,每个partition在kafka存储层面是append log。任何发布到此partition的消息都会被追加到log文件的尾部,在分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,也就是我们的offset,offset是一个long型的数字,我们通过这个offset可以确定一条在该partition下的唯一消息。在partition下面是保证了有序性,但是在topi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 371
371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









