







前言
关于Redis的知识,总结了一个脑图分享给大家

1、在项目中缓存是如何使用的?为什么要用缓存?缓存使用不当会造成什么后果?
面试官心理分析
这个问题,互联网公司必问,要是一个人连缓存都不太清楚,那确实比较尴尬。
只要问到缓存,上来第一个问题,肯定是先问问你项目哪里用了缓存?为啥要用?不用行不行?如果用了以后可能会有什么不良的后果?
这就是看看你对缓存这个东西背后有没有思考,如果你就是傻乎乎的瞎用,没法给面试官一个合理的解答,那面试官对你印象肯定不太好,觉得你平时思考太少,就知道干活儿。
面试题剖析
项目中缓存是如何使用的?
这个,需要结合自己项目的业务来。
为什么要用缓存?
用缓存,主要有两个用途:高性能、高并发。
**高性能**
假设这么个场景,你有个操作,一个请求过来,吭哧吭哧你各种乱七八糟操作 mysql,半天查出来一个结果,耗时 600ms。但是这个结果可能接下来几个小时都不会变了,或者变了也可以不用立即反馈给用户。那么此时咋办?
缓存啊,折腾 600ms 查出来的结果,扔缓存里,一个 key 对应一个 value,下次再有人查,别走 mysql折腾 600ms 了,直接从缓存里,通过一个 key 查出来一个 value,2ms 搞定。性能提升 300 倍。
就是说对于一些需要复杂操作耗时查出来的结果,且确定后面不怎么变化,但是有很多读请求,那么直接将查询出来的结果放在缓存中,后面直接读缓存就好。
**高并发**
所以要是你有个系统,高峰期一秒钟过来的请求有 1 万,那一个 mysql 单机绝对会死掉。你这个时候就只能上缓存,把很多数据放缓存,别放 mysql。缓存功能简单,说白了就是 key-value 式操作,单机支撑的并发量轻松一秒几万十几万,支撑高并发 so easy。单机承载并发量是 mysql 单机的几十倍。
缓存是走内存的,内存天然就支撑高并发。
用了缓存之后会有什么不良后果?
常见的缓存问题有以下几个:
缓存与数据库双写不一致 、缓存雪崩、缓存穿透、缓存并发竞争后面再详细说明。
2、redis 和 memcached 有什么区别?redis 的线程模型是什么?为什么 redis 单线程却能支撑高并发?
面试官心理分析
这个是问 redis 的时候,最基本的问题吧,redis 最基本的一个内部原理和特点,就是 redis 实际上是个单线程工作模型,你要是这个都不知道,那后面玩儿 redis 的时候,出了问题岂不是什么都不知道?
还有可能面试官会问问你 redis 和 memcached 的区别,但是 memcached 是早些年各大互联网公司常用的缓存方案,但是现在近几年基本都是 redis,没什么公司用 memcached 了。
面试题剖析
redis 和 memcached 有啥区别?
redis 支持复杂的数据结构
redis 相比 memcached 来说,拥有更多的数据结构,能支持更丰富的数据操作。如果需要缓存能够支持更复杂的结构和操作, redis 会是不错的选择。
redis 原生支持集群模式
在 redis3.x 版本中,便能支持 cluster 模式,而 memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
性能对比
由于 redis 只使用单核,而 memcached 可以使用多核,所以平均每一个核上 redis 在存储小数据时比memcached 性能更高。而在 100k 以上的数据中,memcached 性能要高于 redis。虽然 redis 最近也在存储大数据的性能上进行优化,但是比起 memcached,还是稍有逊色。
redis 的线程模型
redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
-
多个 socket
-
IO 多路复用程序
-
文件事件分派器
-
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将产生事件的 socket 放入队列中排队,事件分派器每次从队列中取出一个 socket,根据 socket 的事件类型交给对应的事件处理器进行处理。
来看客户端与 redis 的一次通信过程:
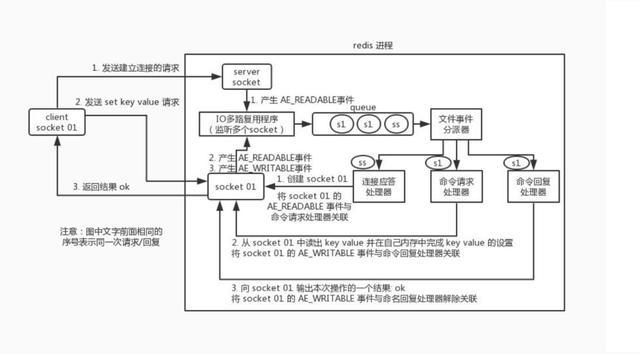
要明白,通信是通过 socket 来完成的,不懂的同学可以先去看一看 socket 网络编程。
客户端 socket01 向 redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。
文件事件分派器从队列中获取 socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的 AE_READABLE 事件与命令请求处理器关联。
假设此时客户端发送了一个 set key value 请求,此时 redis 中的 socket01 会产生AE_READABLE 事件,IO 多路复用程序将 socket01 压入队列,此时事件分派器从队列中获取到 socket01 产生的AE_READABLE 事件,由于前面 socket01 的 AE_READABLE 事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的 key value 并在自己内存中完成 key value 的设置。操作完成后,它会将 socket01 的 AE_WRITABLE 事件与命令回复处理器关联。
如果此时客户端准备好接收返回结果了,那么 redis 中的 socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok,之后解除 socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。
这样便完成了一次通信。
为啥 redis 单线程模型也能效率这么高?
-
纯内存操作
-
核心是基于非阻塞的 IO 多路复用机制
-
单线程反而避免了多线程的频繁上下文切换问题
3、redis 都有哪些数据类型?分别在哪些场景下使用比较合适?
面试官心理分析
除非是面试官感觉看你简历,是工作 3 年以内的比较初级的同学,可能对技术没有很深入的研究,面试官才会问这类问题。否则,在宝贵的面试时间里,面试官实在不想多问。
其实问这个问题,主要有两个原因:
-
看看你到底有没有全面的了解 redis 有哪些功能,一般怎么来用,啥场景用什么,就怕你别就会最简单的 KV 操作;
-
看看你在实际项目里都怎么玩儿过 redis。
要是你回答的不好,没说出几种数据类型,也没说什么场景,你完了,面试官对你印象肯定不好,觉得你平时就是做个简单的 set 和 get。
面试题剖析
**redis 主要有以下几种数据类型:**
-
string
-
hash
-
list
-
set
-
Zset(sorted set)
**string**
这是最简单的类型,就是普通的set和get,做简单的KV缓存。
hash
这个是类似 map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 redis 里,然后每次读写缓存的时候,可以就操作 hash 里的某个字段。
hset person name bingo
hset person age 20
hset person id 1 hget person name
person = {
"name": "bingo",
"age": 20,
"id": 1
}
复制代码**list**
list 是有序列表,这个可以玩儿出很多花样。
比如可以通过 list 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 lrange 命令,读取某个闭区间内的元素,可以基于 list 实现分页查询,这个是很棒的一个功能,基于 redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
# 0 开始位置,-1 结束位置,结束位置为-1 时,表示列表的最后一个位置,即查看所有。 lrange mylist 0 -1
比如可以搞个简单的消息队列,从 list 头怼进去,从 list 尾巴那里弄出来。
lpush mylist 1
lpush mylist 2
lpush mylist 3 4 5
# 1
rpop mylist
复制代码**set**
set 是无序集合,自动去重。
直接基于 set 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 jvm 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?
得基于 redis 进行全局的 set 去重。
把两个大 V 的粉丝都放在两个 set 中,对两个 set 做交集。
#-------操作一个 set-------
# 添加元素 sadd mySet 1
# 查看全部元素 smembers mySet
# 判断是否包含某个值 sismember mySet 3
# 删除某个/些元素 srem mySet 1 srem mySet 2 4
# 查看元素个数 scard mySet
# 随机删除一个元素 spop mySet
#-------操作多个 set-------
# 将一个 set 的元素移动到另外一个 set
s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4752
4752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









