







前言
在高并发系统当中,分库分表是必不可少的技术手段之一,同时也是BAT等大厂面试时,经常考的热门考题。
你知道我们为什么要做分库分表吗?
这个问题要从两条线说起:垂直方向 和 水平方向。
1 垂直方向
垂直方向主要针对的是业务,下面聊聊业务的发展跟分库分表有什么关系。
1.1 单库
在系统初期,业务功能相对来说比较简单,系统模块较少。
为了快速满足迭代需求,减少一些不必要的依赖。更重要的是减少系统的复杂度,保证开发速度,我们通常会使用石库来保存数据。

此时,使用的数据库方案是:一个数据库包含多张业务表。 用户读数据请求和写数据请求,都是操作的同一个数据库。
1.2 分表
系统上线之后,随着业务的发展,不断的添加新功能。导致单表中的字段越来越多,开始变得有点不太好维护了。
一个用户表就包含了几十甚至上百个字段,管理起来有点混乱。
这时候该怎么办呢?
答:分表。
将用户表拆分为:用户基本信息表 和 用户扩展表。

信息,比如:用户名、密码、别名、手机号、邮箱、年龄、性别等核心数据。
这些信息跟用户息息相关,查询的频次非常高。
而用户扩展表中存的是用户的扩展信息,比如:所属单位、户口所在地、所在城市等等,非核心数据。
这些信息只有在特定的业务场景才需要查询,而绝大数业务场景是不需要的。
所以通过分表把核心数据和非核心数据分开,让表的结构更清晰,职责更单一,更便于维护。
除了按实际业务分表之外,我们还有一个常用的分表原则是:把调用频次高的放在一张表,调用频次低的放在另一张表。
有个非常经典的例子就是:订单表和订单详情表。
1.3 分库
不知不觉,系统已经上线了一年多的时间了。经历了N个迭代的需求开发,功能已经非常完善。
系统功能完善,意味着系统各种关联关系,错综复杂。
此时,如果不赶快梳理业务逻辑,后面会带来很多隐藏问题,会把自己坑死。
这就需要按业务功能,划分不同领域了。把相同领域的表放到同一个数据库,不同领域的表,放在另外的数据库。
具体拆分过程如下:
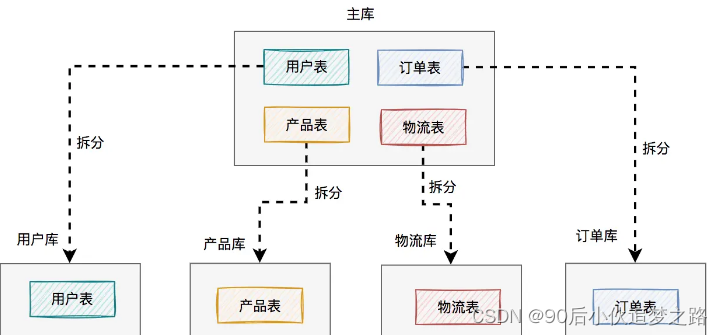
将用户、产品、物流、订单相关的表,从原来一个数据库中,拆分成单独的用户库、产品库、物流库和订单库,一共四个数据库。
在这里为了看起来更直观,每个库我只画了一张表,实际场景可能有多张表。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









