







一、Linux入门基础
第一节 Linux概述
-
网管就是第一个运维工程师
-
企业运行模式:铁三角 = 产品 + 研发 + 运维 流程走向:产品设计--> 项目研发--> 项目测试--> 项目上线--> 系统运维
-
运维部门:负责项目环境部署、上线、架构的搭建等等
-
成熟的企业的系统环境:开发环境、测试环境、准生产环境、生产环境、上线、生产
-
网站所用的编程语言:ASP/PHP/JSP
-
网站的运行模式
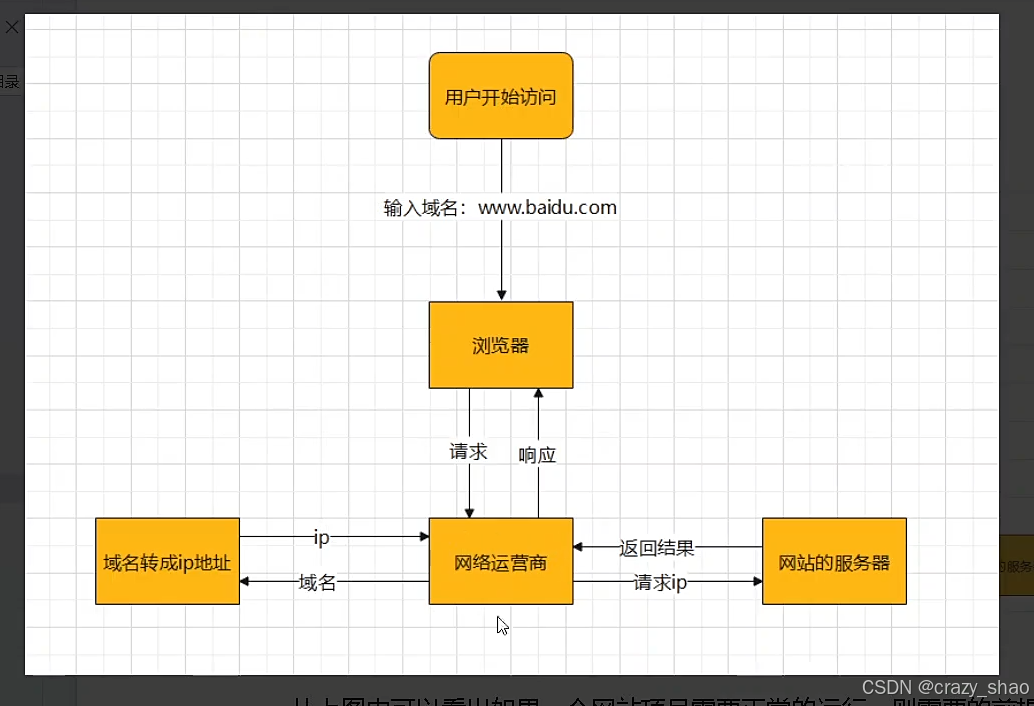
-
服务器的特性:高性能 + 标准化统一特性
-
IP地址:ipv4(常见)、ipv6(不常见)
-
域名:www. 域名中有几个 “ . ” 就是几级
-
服务器组成结构:CPU、主板、内存条、显卡、硬盘、电源、风扇、网卡、显示器、机箱、键盘鼠标等等。
-
操作系统概述:第一台计算机是1946年2月14日诞生
-
计算机分为2部分:硬件资源、软件资源
-
Linux操作系统的优点:高性能、稳定性(其开机时间可以好几年不关机、他还是开源的)、安全性高、充分利用资源
-
Linux的发展史
1.Lius-林纳斯·托瓦兹----Linux之父
2.Stallman-斯特曼:开源文化的倡导人
Linux的含义
1.狭义:由Linus编写的一段内核代码
2.广义:广义上的Linux是指由Linux内核衍生的各种Linux发行版本。(CentOS、Ubuntu)-
Linux的特点:开放性(开源)、多用户、多任务、良好的用户界面、优异的性能与稳定性
-
Linux系统的安装方式有2种:真机安装(替换Windows系统)和虚拟机安装
第二节 VMware和Linux系统安装
1、下载地址,下载VMware
https://www.vmware.com/cn/products/workstation-pro.html
2、双击安装
3、点击下一步
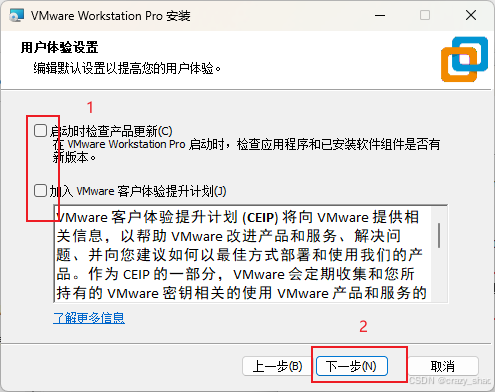
4、点击我接受,然后点击下一步
5、点击更改安装路径,选择之后默认选择,点击下一步
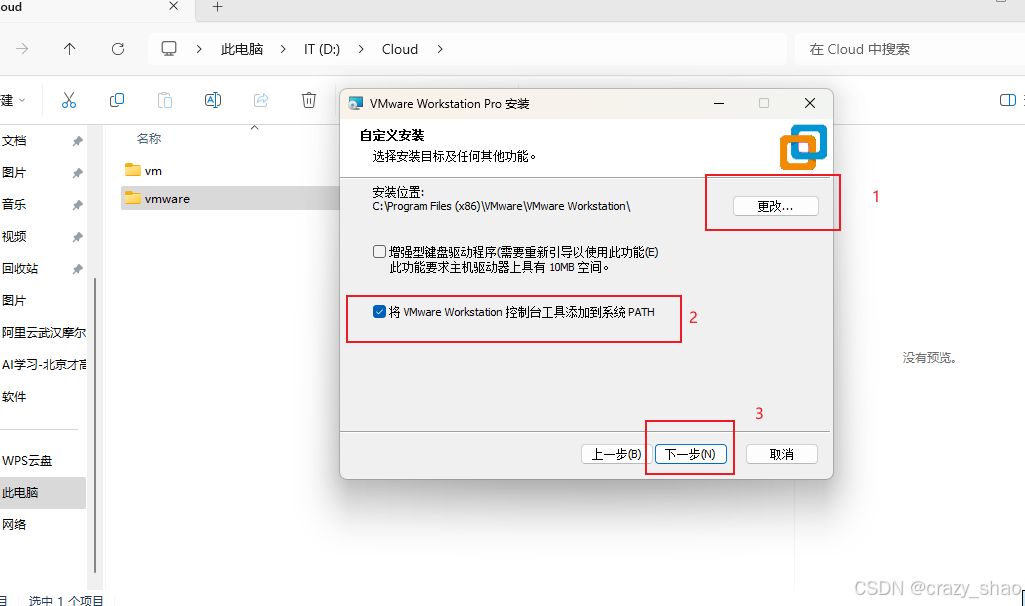
6、勾掉默认选的选项,点击下一步
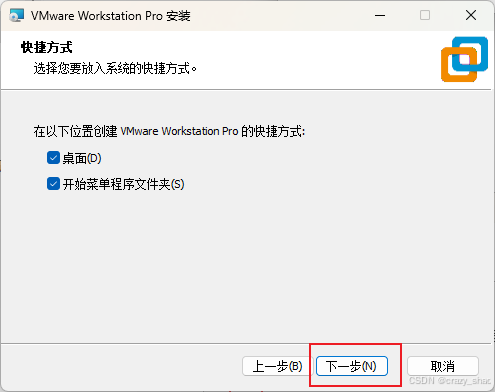
7、点击下一步
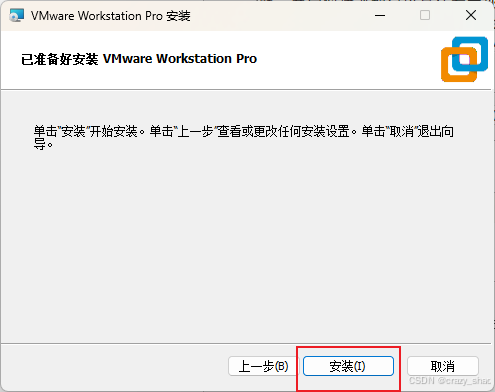
8、点击安装
9、点击许可证
10、输入有效的许可证,点击输入
11、安装完成
12、桌面双击打开,vmware安装成功
第三节 安装Linux系统
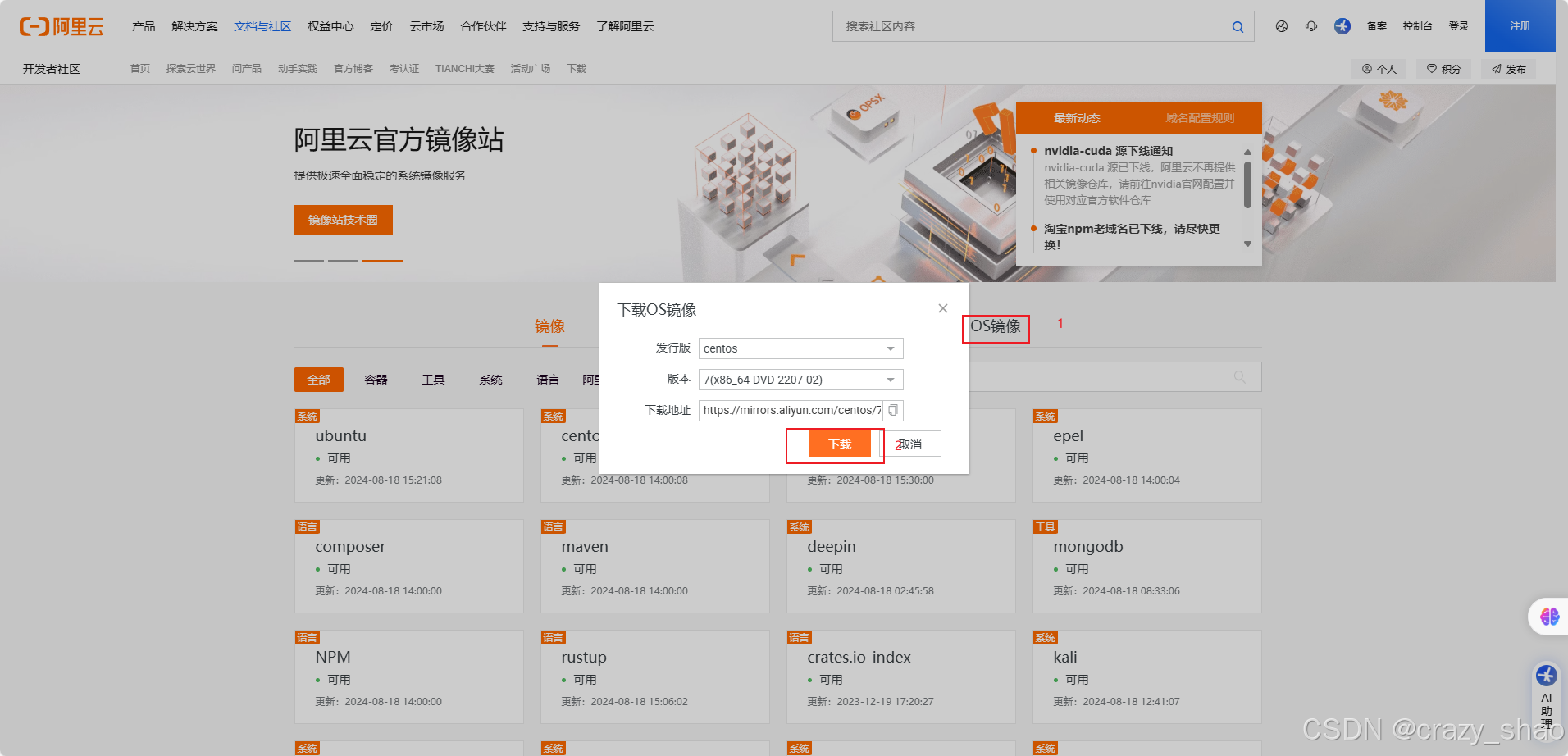
1、准备CentOS镜像
下载地址:阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区
2、点击OS镜像,选择版本下载
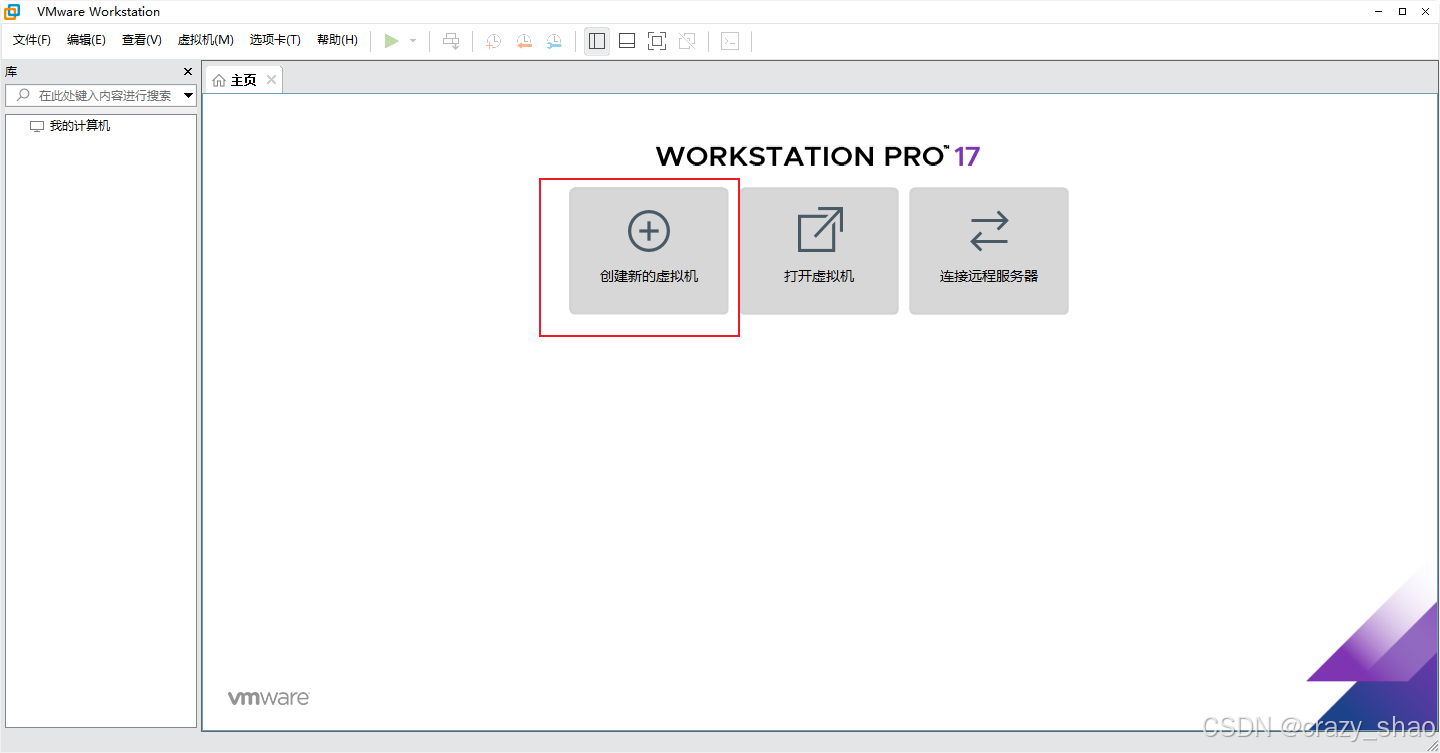
3、打开VMware,点击新建
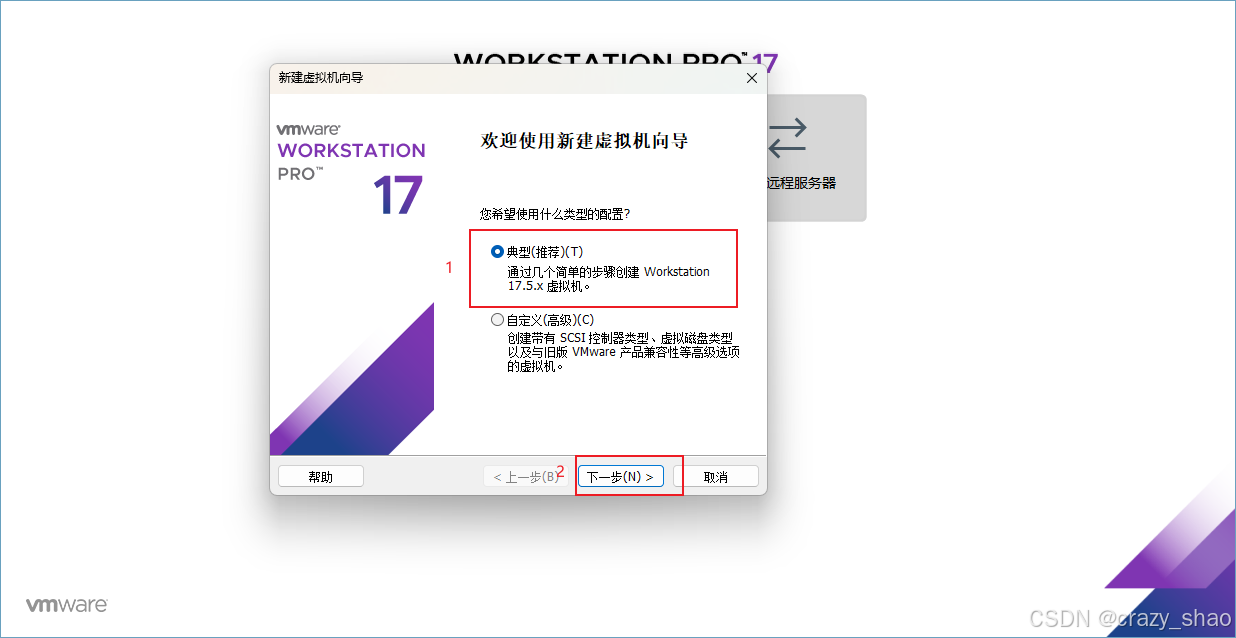
4、选择典型,点击下一步
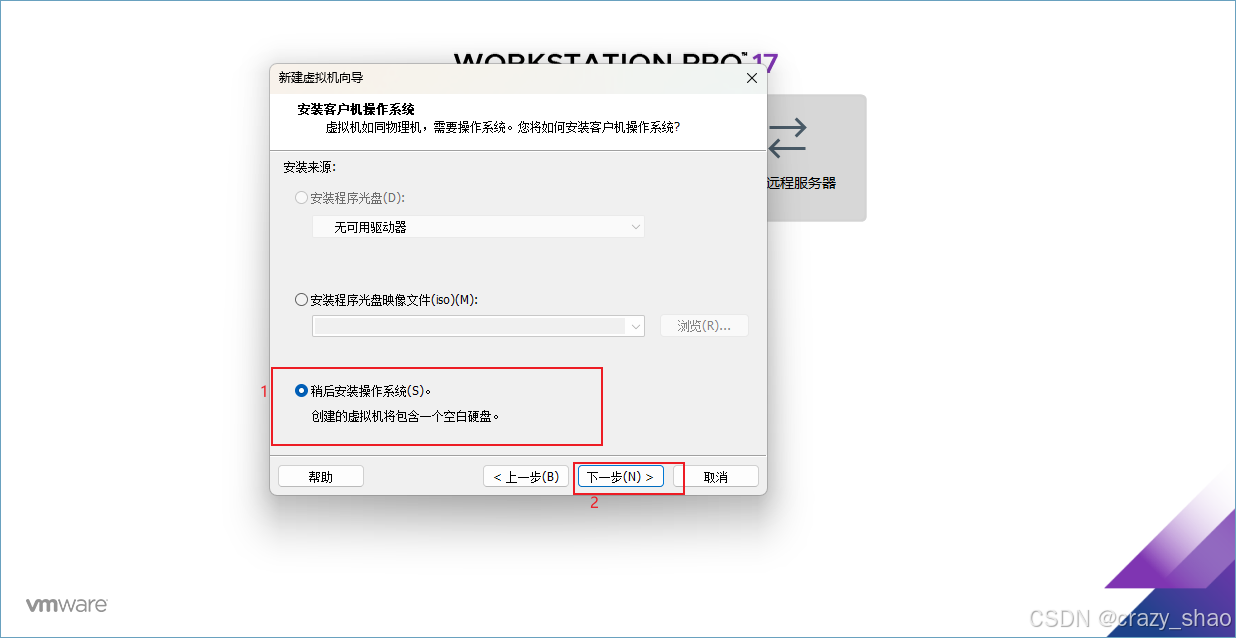
5、选择稍后安装操作系统,点击下一步
6、选择Linux,然后选择版本,点击下一步
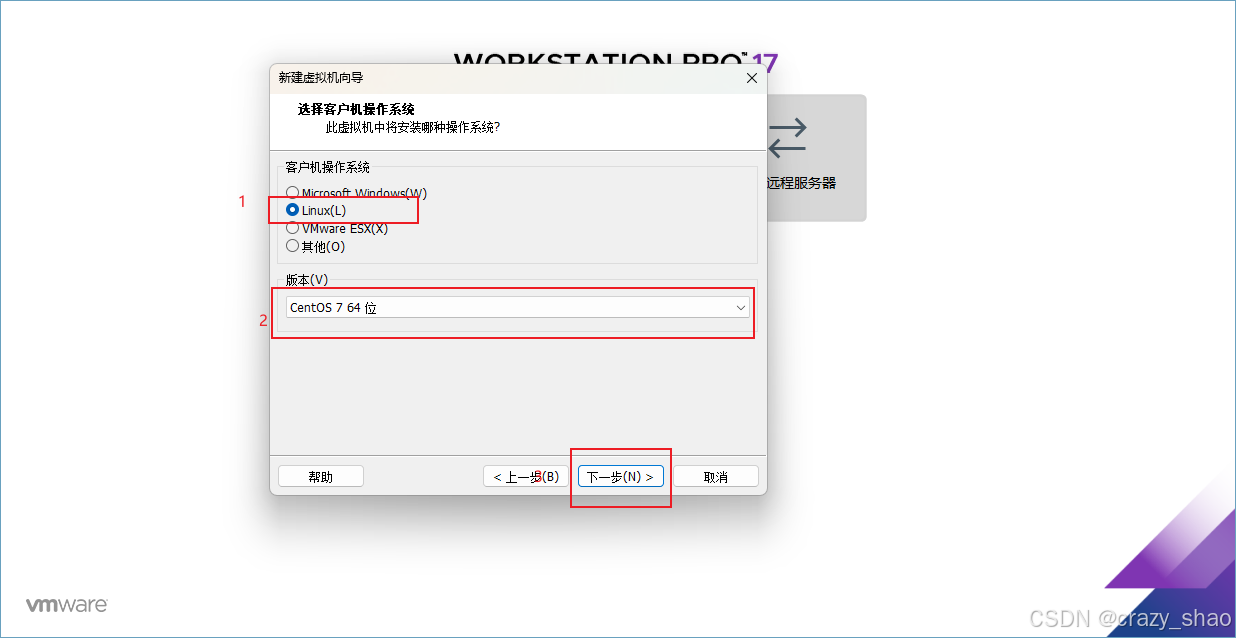
7、设置虚拟机名称,更改安装位置,然后点击下一步
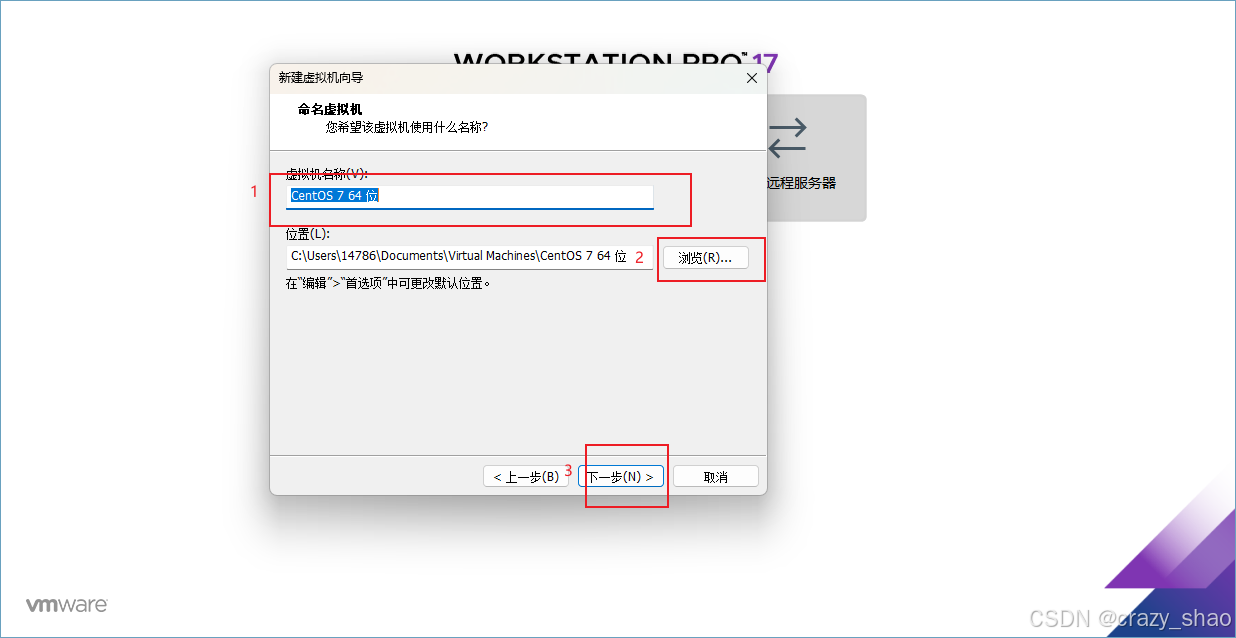
8、分配磁盘大小,默认20g,可以自定义,建议放的磁盘大于20g,点击下一步
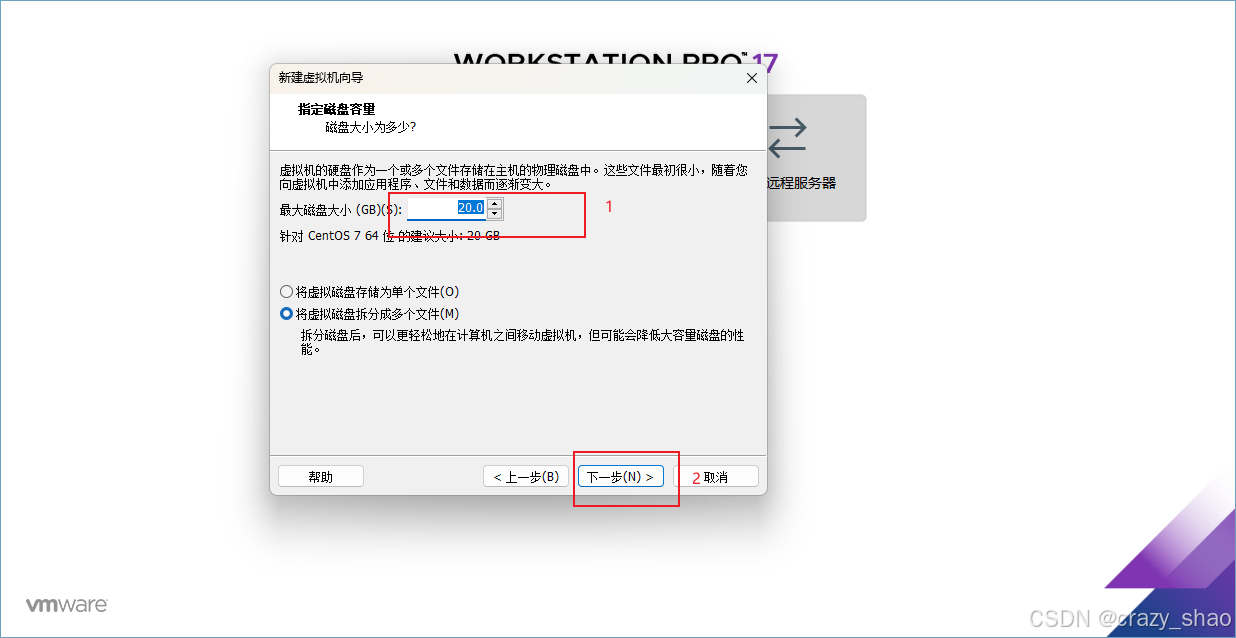
9、自定义硬件配置
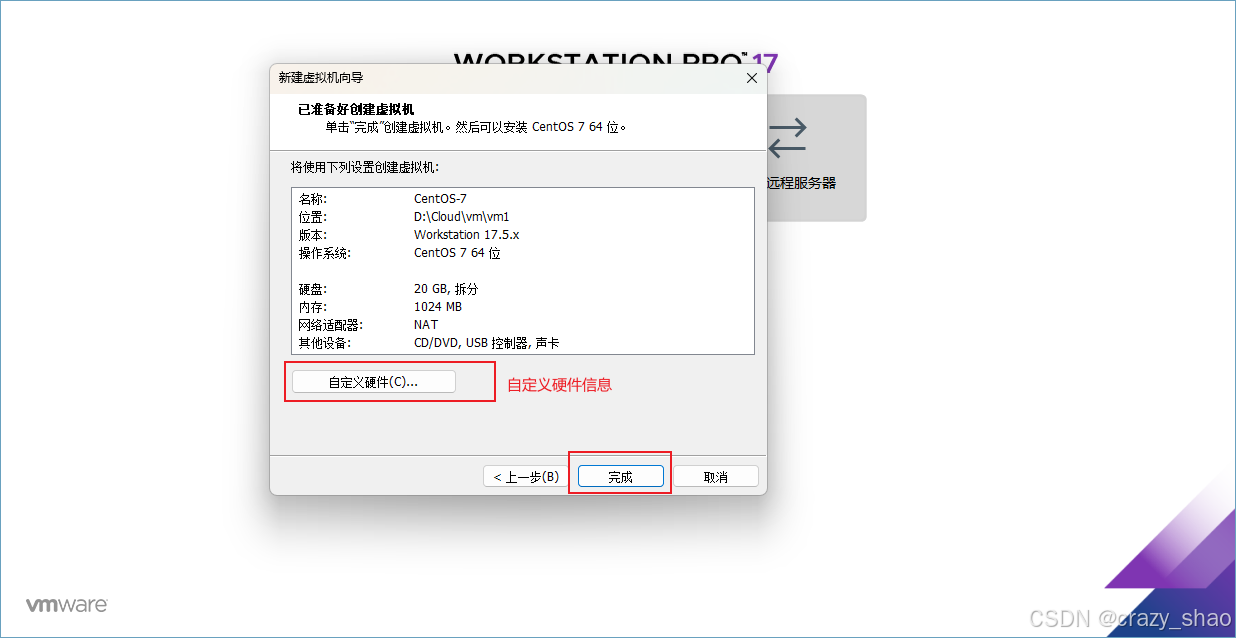
10、第一步点击内存,设置运行内存,尽可能地大一些,第二步自定义处理器,第三步,使用ISO映像文件配置,最后点击关闭
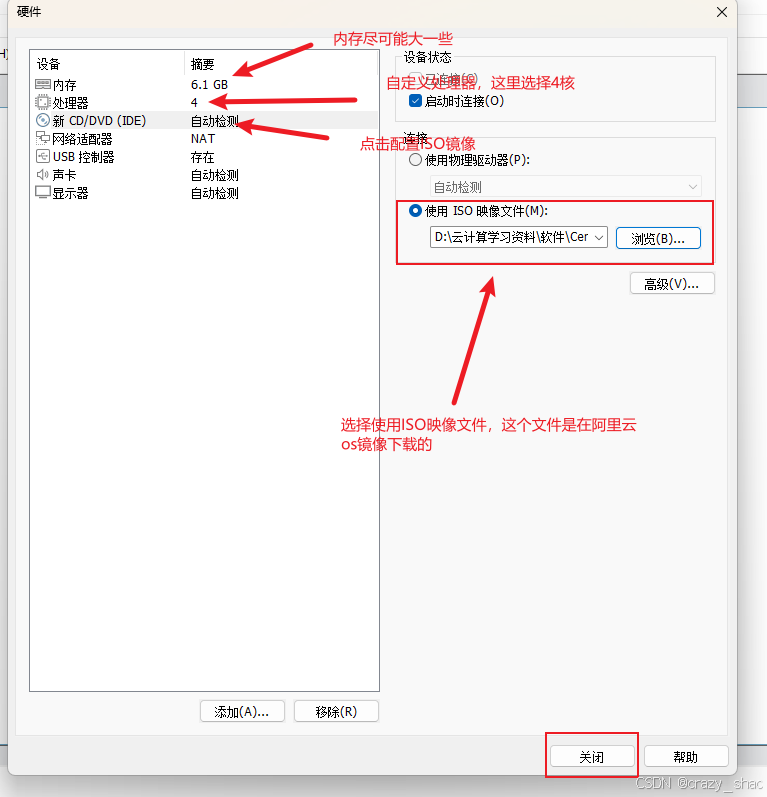
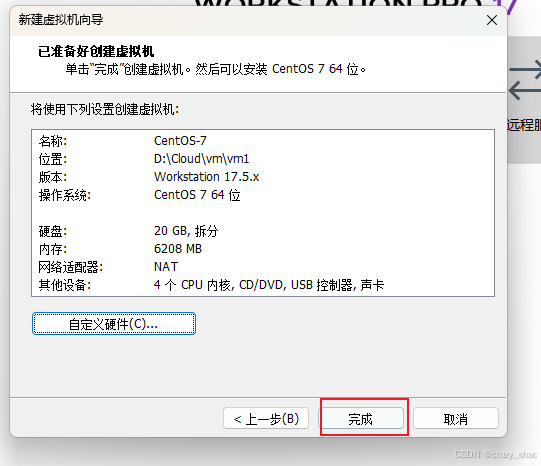
11、点击完成
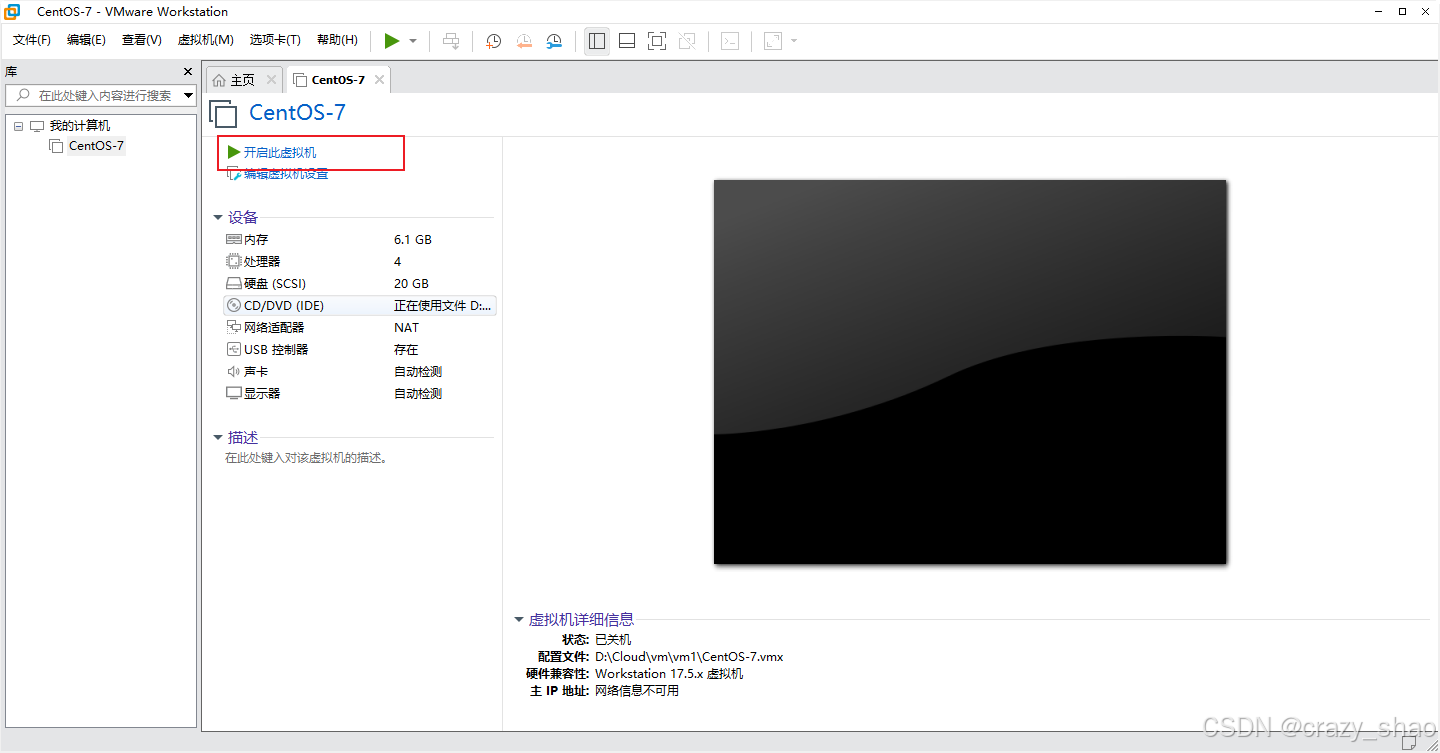
12、开启此虚拟机
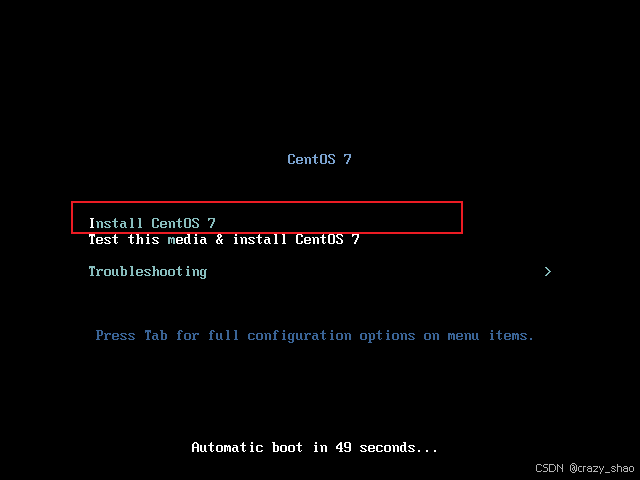
13、用鼠标(ctrl+alt唤出鼠标)或者键盘上下键选择图中选项按enter
14、选择中文,点击继续
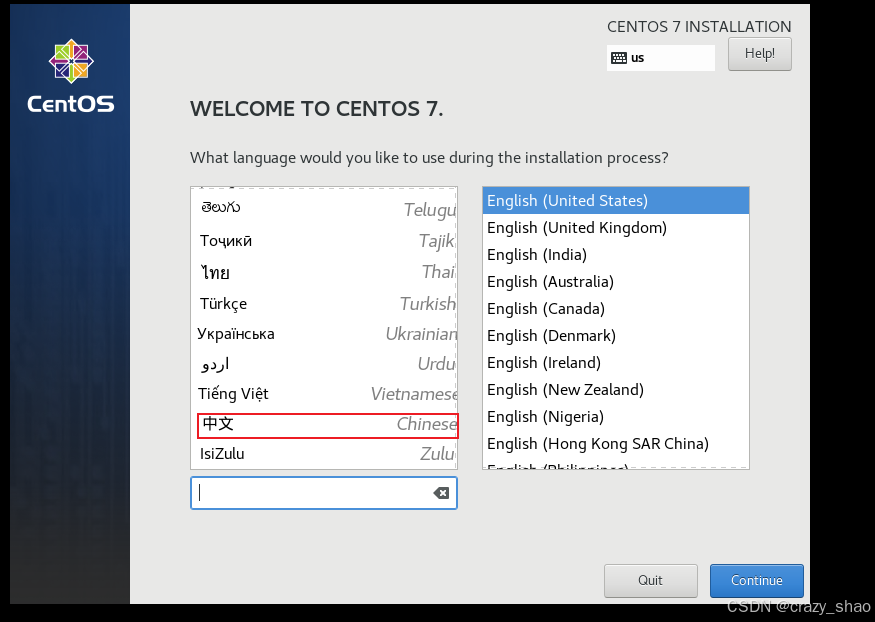
15、点击软件选择
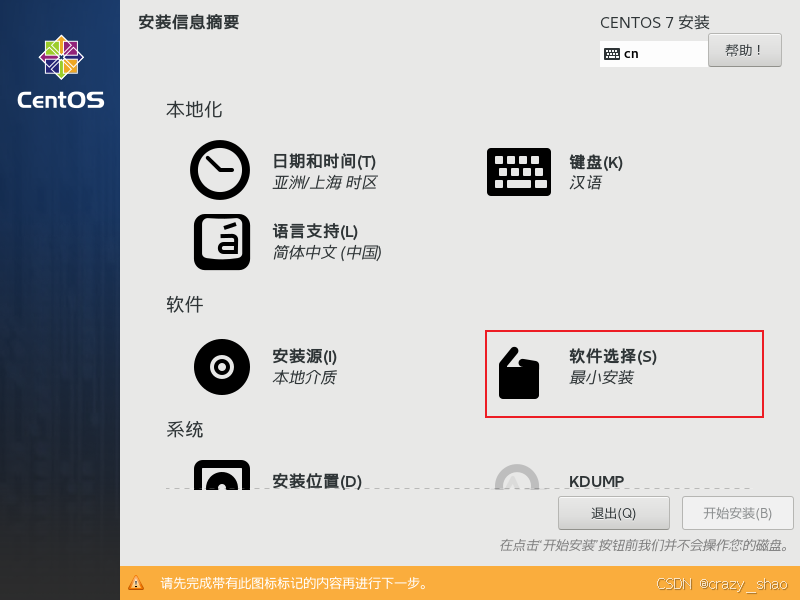
16、选择桌面,双击完成
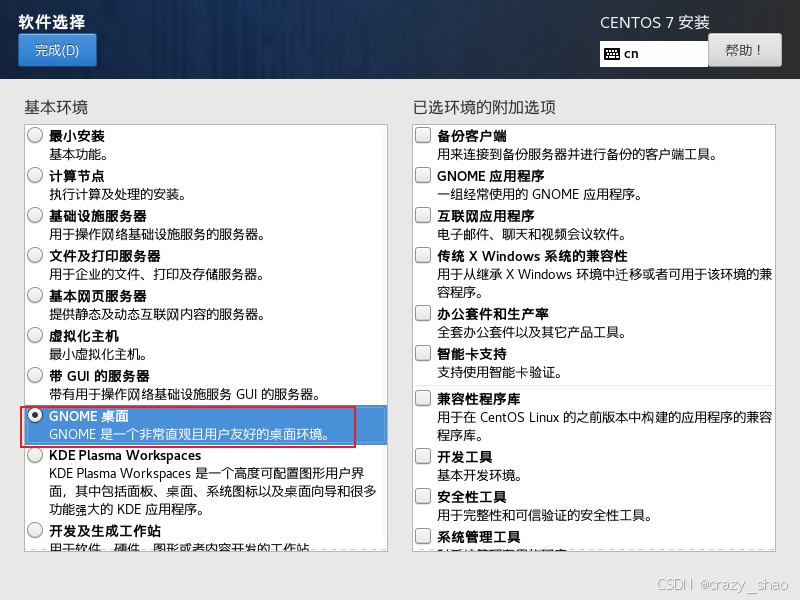
17、点击安装位置
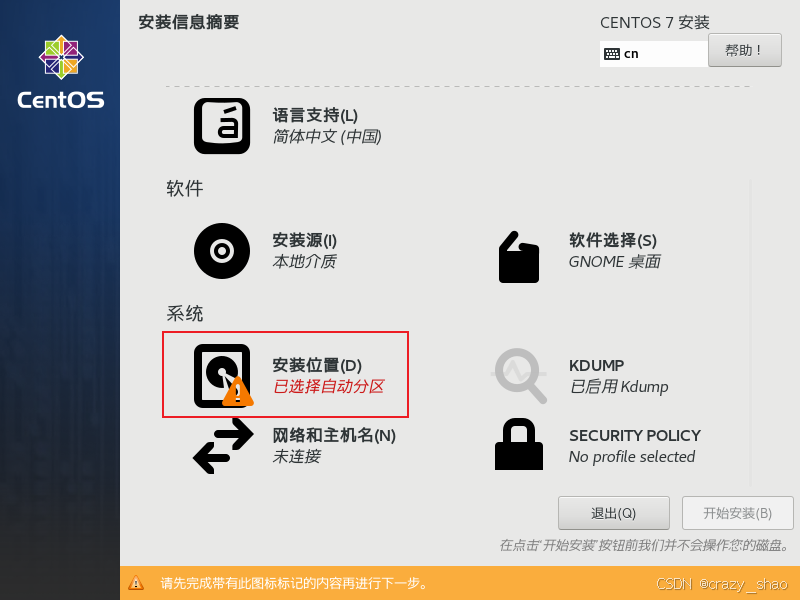
18、可以选择自动分配分区,双击完成
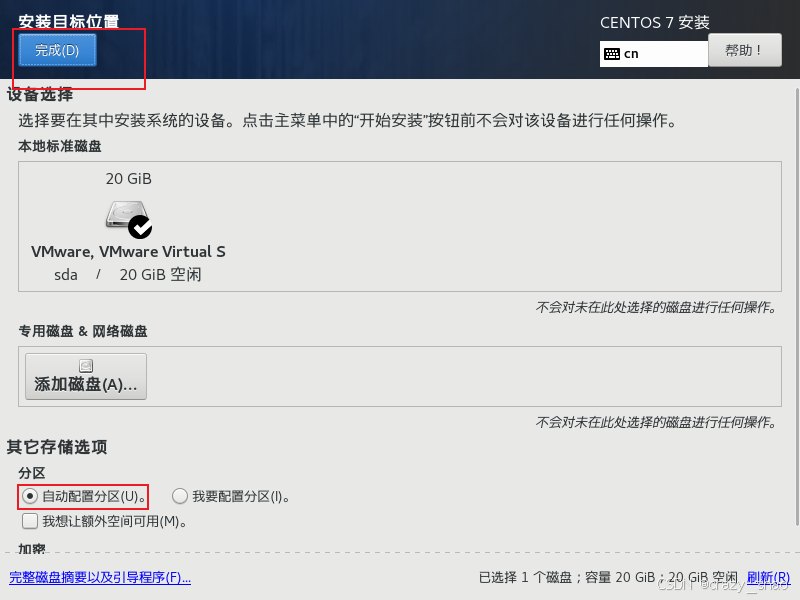
19、设置网络和主机,然后点击开始安装
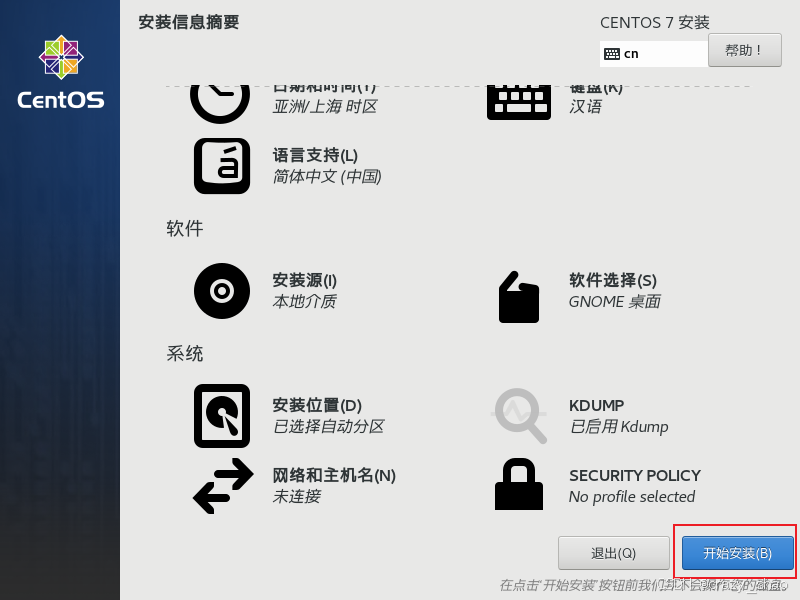
20、配置管理员root密码,设置完成后等待安装
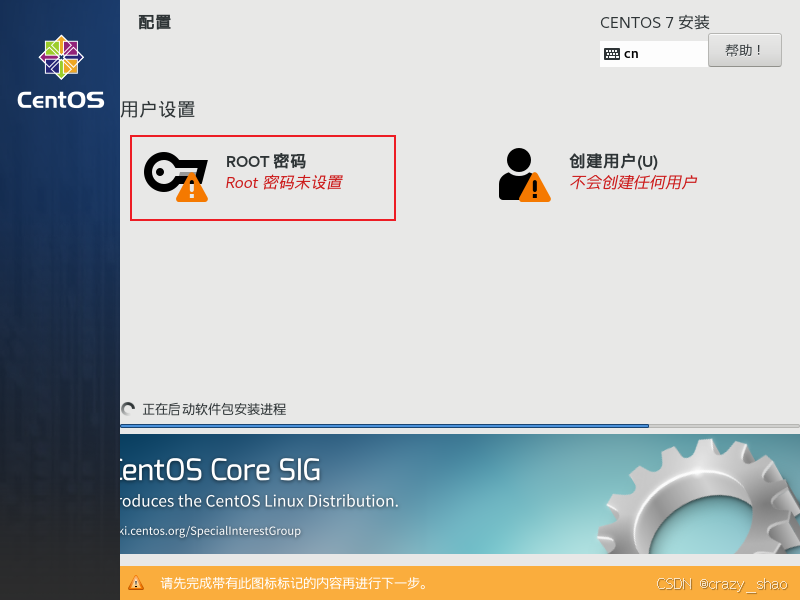
21、点击重启
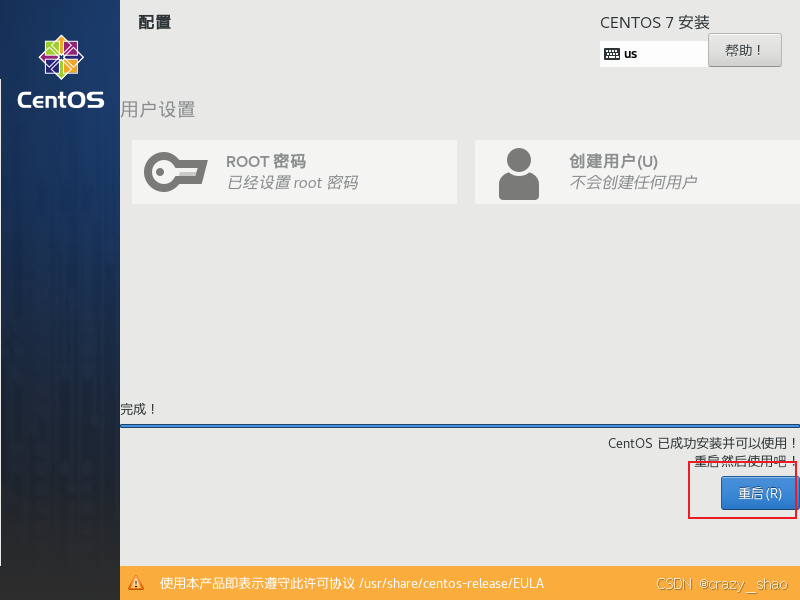
22、接受许可证,点击进去,勾选我接受,然后点击完成
23、前面没有配置网络可以在这里配置网络,点击进去,然后打开以太网,最后点击完成
24、最后点击完成配置

25、选择中文,点击前进
26、点击跳过
27、安装完成
第四节 远程连接工具的使用
1、常用的远程连接工具
-
Xshell: 这是一款Windows平台下的SHH客户端软件,支持SSH1、SHH2、SFTP、TELNET、RLOGIN等多种协议,功能丰富,包括多标签、多窗口、脚本录制、自定义快捷键等,适合各种使用需要求。但是,它只支持Windows平台,对于macOS、Linux等操作系统的用户不适用。
-
FinalShell:这是一款一体化的服务器网络管理软件,不仅是ssh客户端,还是功能强大的开发、运维工具。
-
PuTTY:这是一款基于shh、telnet、rlogin和串口连接的远程终端连接软件,支持Windows和Unix/Linux系统。它的主要功能是在本地与远程计算机安全地复制传输文件。
-
SecureCRT:这是一款功能强大的终端仿真程序,支持ssh、telnet、rlogin和串口连接,界面美观、操作简单,支持脚本编写、多标签页、自动登录、文件传输等功能。但是,它的价格比较高,主要适用于商业用户。
-
MobaXterm:知识一款功能全面的远程网络工具,包括ssh、x11、rdp、vnc、ftp、mosh等,以及Unix命令,登录之后默认开启sftp模式。
-
WinSCP:这是一款Windows环境下使用ssh的开源图形化sftp工具客户端,同时支持scp协议,主要功能是在本地与远程计算机安全地复制传输文件。
-
NxShell:这是一款开源的Linux远程管理工具,界面美观,支持sftp,适合日常远程管理Linux服务器。
2、查找服务器的ip地址
打开终端输入ip a 命令第五节 Linux快照&克隆
备份操作系统,在VMware中备份方式:快照和克隆
1、快照
又称还原点,就是保存在拍照时,系统的状态。在后期的时候随时可以恢复。(注重短期备份,或者是频繁备份)
2、克隆
就是复制的意思,侧重长期备份。做克隆必须关闭虚拟机。
3、快照与克隆的区别
克隆之后是2台虚拟机,快照之后依旧是一台设备(类似于Windows系统还原精灵的还原点)。在进行危险操作前建议使用快照。
第六节Linux注意事项及目录结构
1、Linux是严格区分大小写
Linux系统中创建大小写不同但同名的文件夹,两歌都会创建成功,Linux系统严格区分大小写。
2、Linux文件扩展名
在Windows中,依赖扩展名区分文件的类型,比如.txt,.exe, 但Linux不以文件扩展名区分文件。Linux系统是通过权限位来确定文件类型,Linux常见的文件有普通文件、目录、连接文件、块设备文件,在Linux中的一些特殊还是要求写“扩展名”的,Linux不依赖扩展名识别文件类型,写这些扩展名是为了帮助运维人员来区分不同的文件类型。
文件扩展名种类:
1)压缩包:Linux压缩包常见文件名: .gz,.bz2,.zip,.tar。
2)二进制软件包:Centos中使用魏晋至安装包RPM包,所有RPM包都是.rpm扩展名结尾不管是压缩包还是二进制包写这样的扩展名,都是为了让管理员一目了然。
3)程序文件.sh .py;
3、Linux中一切皆文件
所有内容都以文件形式保存
普通文件,分为一般文件(黑色)和可执行文件(绿色)
4、在Linux中所有存储设备必须在挂在之后才能使用
5、Linux系统的文件目录结构
所有文件都存储在根目录下,为树形结构
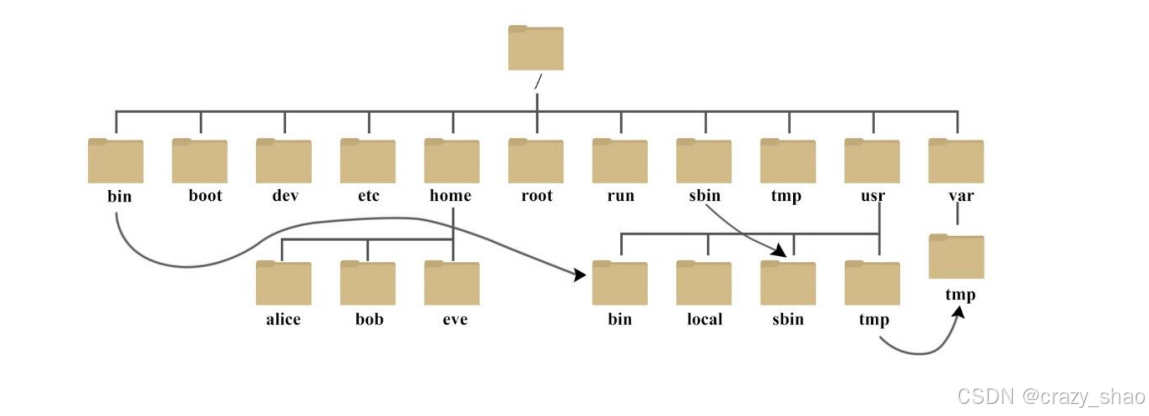
路径的概念:分为绝对路径和相对路径
绝对路径:不管当前工作路径是在哪,目标路径都是会从“/”磁盘下开始。绝对路径就是从根路径开始的
相对路径:除绝对路径之外的路径都成为相对路径,相对路径指的是一个相对物,一般就是当前的工作路径。
../:表示上一级目录
./:标签当前目录,相当于刷新目录
Linux系统中文件目录的用途
| 目录名 | 功能 |
| /bin | bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令 |
| /sbin | s 就是 Super User 的意思,是 Superuser Binaries (超级用户的二进制文件) 的缩写,这里存放的是系统管理员使用的系统管理程序 |
| /root | root用户的家目录(root用户是整系统中拥有最大权限的用户) |
| /home | 普通用户的家目录(所有普通用户都会在/home目录下) |
| /boot | 这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件 |
| /dev | dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。 |
| /etc | etc 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。 |
| /lib | lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。 |
| /media | linux 系统会自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下。 |
| /mnt | 系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在 /mnt/ 上,然后进入该目录就可以查看光驱里的内容了。 |
| /opt | opt 是 optional(可选) 的缩写,第三方程序的安装目录。默认是空的。 |
| /proc | proc 是 Processes(进程) 的缩写,/proc 是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 |
| /srv | 该目录存放一些服务启动之后需要提取的数据 |
| /sys | 这是 Linux2.6 内核的一个很大的变化。该目录下安装了 2.6 内核中新出现的一个文件系统 sysfs 。 sysfs 文件系统集成了下面3种文件系统的信息:针对进程信息的 proc 文件系统、针对设备的 devfs 文件系统以及针对伪终端的 devpts 文件系统。 |
| /tmp | tmp 是 temporary(临时) 的缩写这个目录是用来存放一些临时文件的。 |
| /usr | usr 是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。 |
| /var | var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。 |
| /run | 是一个临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。如果你的系统上有 /var/run 目录,应该让它指向 run。 |
第七节 命令入门&uname&ls
1、开启终端
2、终端提示符含义
[root@localhost ~]#
root:当前登录的用户名
@:分隔符
localhost:当前的主机名
~:当前用户所在的家目录,就是当当前位置
#:身份识别符,$表示普通用户,#表示超级管理员3、命令与选项
就是在Linux终端中输入的内容就是命令
Linux的格式
命令名 (空格) [选项] (空格) [参数]
命令名:执行命令的名字 如:ls、cd、mkdir、touch
空格:必须字符,至少一个
选项:执行命令所需要显示的属性信息
参数:命令作用的对象
注意:命令名与选项之间要有空格,选项与选项之间要有空格,选项与参数之间要有空格,空格是必不可少的一个字符,最少一个
在 linux 系统中, 当你输入一个命令,按一次 TAB 键,可以将命令补全,连按两次 TAB 键
可以列出所有以你输入字符开头的可用命令。所以这个功能被称为命令行补全。第八节 基础命令
1、uname 查看系统信息
uname -a2、ls 列出目录下信息
用法一:ls
含义:列出当前工作路径下的文件名称
用法二:ls /home/linux
含义:列出/home/linux目录下的文件名称
用法三:ls linux/
含义:列出当前工作路径下,linux目录下的文件名
用法四:ls 后面跟参数选项、路径
含义:在列出指定路径下的文件/文件夹的名称,并以指定的格式进行显示
常见参数:
-a:a代表all,表示显示所有的文件/文件夹,而且包含隐藏的文件/文件夹
-l:l代表list,表示以详细列表的形式进行展示
-h:以较高的可读性(文件的大小)来展示
例如:ls -l、ls -a、ls -la、ls -lh
ll等价于ls -l
用法五:ls -R
含义:用递归的方式查询所有目录
用法六:ls -d [指定目录]
含义:在 Linux 系统中,`ls -d` 命令的作用是:仅列出指定目录本身的信息,而不列出目录中的内容。例如,如果您有一个名为 `example` 的目录,当您输入 `ls example` 时,它会列出 `example` 目录下的所有文件和子目录。但如果输入 `ls -d example`,则只会显示关于 `example` 目录自身的信息,比如权限、所有者、修改时间等。再比如,当您面对一个包含多个子目录的目录结构,只想查看这些子目录自身的信息,而不想深入查看每个子目录中的内容时,使用 `ls -d` 就非常方便。
在Linux命令中语法中,可用多个选项合并为-abcd这种形式3、pwd
显示当前路径
含义:用于告诉用户当前所在路径4、cd
切换目录
语法:cd [路径]
cd ~ 切换工作目录到当前用户的家目录
cd 切换工作目录到当前用户的家目录
cd /home/linux 切换到/home/linux目录下
cd ../ 返回到上级目录
cd zhangsan 切换到当前目录下的zhangsan目录
cd - 上一次所在目录与现在目录来回切换5、clear
清除屏幕信息
命令:clear 可以用键盘组合键 ctrl + l = clear6、whoami
查看当前用户7、su [用户名]
更换登录账号8、reboot
重启操作系统9、shutdown
关机命令
语法: 直接输入shutdown 回车
shutdown: 系统在60s后关机
shutdown now: 系统立即关机
shutdown -h 20: 系统在20分钟后关机
shutdown -c:系统取消关机
扩展:poweroff 或者 init 0 或者 shutdown now 表示关机10、type
查看一个命令是属于内部命令还是外部命令
没有提示 shell内嵌 的都是外部命令!11、history
列出最近输入的一千条信息12、hostnamectl
centos7 中主机名分为三类:
静态主机名:也称为内核主机名,系统再启动时从/etc/hostname 内自动初始化的主机名,
相当于永久更改
瞬态主机名:是在系统运行时临时分配的主机名,例如,通过 DHCP 或 mDNS 服务器分配。
灵活主机名: 允许使用特殊字符的主机名,例如"aliyun's linux" 命令:hostnamectl
作用:读取或设置操作服务器的主机名
同时设置静态和瞬态主机名
用法:hostnamectl set-hostname 主机名
含义:设置该操作系统的主机名称为 aliyun.cloud
设置灵活主机名
用法:hostnamectl --pretty set-hostname 主机名
配置瞬态主机名
用法:hostnamectl --transient set-hostname 主机名13、help查看命令帮助
1、查看命令是系统内部命令还是外部命令
type ls
2、外部命令查看帮助
命令名 --help
3、内部命令查看帮助
help 命令名14、man手册查看帮助
man手册不分内外命令
用法: man 命令名
例如:man ls
支持搜索“/关键字”,按n向下搜索,按N向上搜索,按q退出
在 Linux 中,“man 5 group” 是指查看关于 “group” 的第五章节的手册页内容。
man手册查看帮助比help更加详细第九节 文件管理
1、Linux文件命名规则
一般来说除了字符"/",所有的字符都可以使用,但是不建议使用"<、>、?、*"等特殊字符
正常文件的命名规则:
①尽量都使用小写字母,因为 Linux 严格区分大小写
②如果需要对文件名进行分割,建议使用"_",zhoubao__2023_09_27
2、命名长度
目录名或者文件名的长度不能超过 255 个字符
3. 文件名的大小写
Linux 严格区分大小写,像 Linux、linux、Aliyun、aliyun 时互不相同的目录名和文件名,所以不建议使用字符的大小写来区分建议文件名一律使用小写。
4. Linux 文件的扩展名
在 Linux 中不以扩展名对文件类型进行区分,文件的扩展名只是方便运维人员更好的区分不同的文件类型,文件类型的区分是依靠权限位标识进行区分的,还可以通过文件的颜色进行区分它的类型。
5、创建目录
-
mkdir 创建目录
含义:根据目录的名称去创建一个目录 用法:mkdir 目录名称 -
mkdir -p 递归创建目录
用法: mkdir -p 目录1/目录2/目录3... 含义:-p 递归创建,从左边的路径开始一级一级的创建目录,直到路径结束 mkdir -vp 目录1/目录2/目录3/... -v含义:显示创建过程 -
使用mkdir同时创建多个目录
用法:mkdir 目录1 目录2 目录3 有规律:mkdir /tmp/file{01..03}
6、删除目录(必须是空目录)
-
rmdir 移除空目录
语法:rmdir 目录 -
rmdir 递归删除空目录
语法:rmdir -p 目录2/目录3/目录4/... 从左到右一级一级删除空目录 -
rmdir 同时删除多个目录
语法:rmdir 目录2 目录3 目录4 rmdir test{01..05} rmdir {test,ew,adfs}
7、文件创建
-
touch 创建文件
语法:touch 文件名称 含义:在Linux系统中的当前文件创建一个文件 -
使用touch命令同时创建多个文件
语法:touch 文件名称1 文件名称2 touch {1..6}.txt touch {dd,adgf,wew}
8、文件删除
-
普通删除
语法:rm [选项] 文件或文件的名称 -r:针对文件夹删除,-r 代表的是递归删除,先把目录下所有的文件先删除,然后在删除文件夹 -f:强制删除,不提示,直接删除 -
扩展
rm -rf /*,一定要慎重,代表删除根目录下所有的文件,如果没有备份,恢复的机率不高 rm:删除 -r:递归删除 -f:强制删除 /:代表根分区 *:代表所有
9、复制操作
-
cp(copy)复制操作
语法:cp [选项] 源文件或文件夹 目标路径 -r:递归复制,主要针对文件夹 -a:带所有属性的复制 -
cp [选项] 源文件或文件夹 目标路径/新文件或新文件名称
-
复制文件夹到指定路径
语法:cp -r 源文件夹名称 目标路径/
10、剪切操作mv(move)
-
mv基本操作
语法:mv 源文件或文件夹 目标路径 剪切语法和复制语法基本相同
11、重命名操作
什么是重命名?简单来说,就是给文件或问价夹更改名称
基本语法:
# mv 源文件或文件夹名称 新文件或文件夹的名称
# cd /tmp
# rm -rf * # touch a1.txt
# mkdir file
案例一:将 a1.txt 文件更名为 aa1.txt
#mv a1.txt aa1.txt
案例二:将 file 文件夹更名为 file.dir 文件夹
# mv file/ file.dir12、打包压缩与解压缩
-
概念
打包:在默认情况下,Linux 的压缩概念一次只能压缩一个文件。针对多文件或文件夹是无法直接进行压缩的,所以需要提前对多个文件或文件夹进行打包,这样才可以进行压缩操作 通过 dd 命令可以创建指定大小文件 # cd /tmp # rm -rf * # dd if=/dev/zero bs=1M count=5 of=a.txt # dd if=/dev/zero bs=1M count=10 of=b.txt # dd if=/dev/zero bs=1M count=15 of=c.txt # ls -lh 打包后 a.txt + b.txt + c.txt = abc.tar =30MB 打包只是将多个文件或文件夹打包放在一个文件中,并没有进行压缩,所以大小还是原来的 总和 压缩:压缩文件所占用的磁盘空间比集合中所有文件大小的总和都要小 -
在Linux系统中使用打包的操作
tar [选项] 打包后的名称.tar 多个文件或文件夹 选项说明: -c:打包 -f:filename,打包后的文件名称 -v:显示打包进度 -u:update缩写,更新原打包文件中的文件 -t:查看打包的文件内容 -
tar -tf 以及 tar -uf
tar -tf 打包后的文件名称 查看tar中的文件名称 tar -uf 打包后的文件名称 更新tar中的内容 -
打包并压缩(重点)
tar [选项] 压缩后的压缩包名称 要压缩的文件或文件夹 选项说明: -cf:对文件或文件夹进行打包 -v:显示压缩进度 -z:使用gzip压缩工具把打包后的文件压缩为.gz -j:使用bzip压缩工具把打包后的文件压缩为.bz2 -J:使用xz压缩工具把打包后的文件压缩为.xz -a:这个选项通常表示 “自动检测压缩格式”。它使得tar命令能够自动识别归档文件的压缩格式,并根据格式进行相应的解压操作。例如,如果归档文件是使用gzip压缩的,tar会自动识别并解压缩;如果是使用bzip2压缩的,也能正确处理。 压缩效率:gzip > bzip2 > xz 压缩率:gzip < bzip2 < xz 注意:最小化的未安装 bzip2 这个软件包因此报错,图形化默认安装! # yum -y install bzip2 -
对压缩包进行解压
tar -x 解压 tar -x 压缩包名称 -C 指定路径 => 解压到指定路径
13、zip压缩与解压
-
zip压缩
zip [选项] 压缩后的文件.zip 文件或文件夹 选项说明: -r:递归压缩,主要针对文件夹 zip格式在Windows以及Linux中都是可以正常使用 最小化需要安装 # yum -y install zip -
unzip解压缩
unzip 压缩包名称 =》 解压到当前目录 unzip 压缩包名称 -d 指定路径 =》 解压到指定路径
第十节 文件管理vim,vim编辑器
1、vi概述
vi(visual editor)编辑器通常被简称为 vi,它是 Linux 和 Unix 系统上最基本的文本编辑器,类似于 Windows 系统下的 notepad(记事本)编辑器。
2、vim编辑器
Vim(Vi improved)是 vi 编辑器的加强版,比 vi 更容易使用。vi 的命令几乎全部都可以在 vim 上使用。
3、vim编辑器的安装
Centos7 图形化通常都已经默认安装好了 vi 或 Vim 文本编辑器,我们只需要通过vim 命令就可以直接打开 vim 编辑器了有些精简版的 Linux 操作系统,默认并没有安装 vim 编辑器(可能自带的是 vi 编辑器)。当我们在终端中输入 vim 命令时,系统会提示"command not found"。解决办法:有网的前提下,可以使用 yum 工具对 vim 编辑器进行安装 # yum install vim -y
4、vim编辑器的4种模式
-
命令模式
使用 VIM 编辑器时,默认处于命令模式。在该模式下可以移动光标位置,可以通过快捷键对文件内容进行复制、粘贴、删除等操作。
-
编辑模式或输入模式
在命令模式下输入小写字母 a 或小写字母 i 即可进入编辑模式,在该模式下可以对文件的内容进行编辑
-
末行模式
在命令模式下输入冒号:即可进入末行模式,可以在末行输入命令来对文件进行查找、替换、保存、退出等操作
-
可视化模式(了解)
可以做一些列选操作(通过方向键选择某些列的内容)
5、vim四种模式关系
命令模式/编辑模式/末行模式/可视化模式
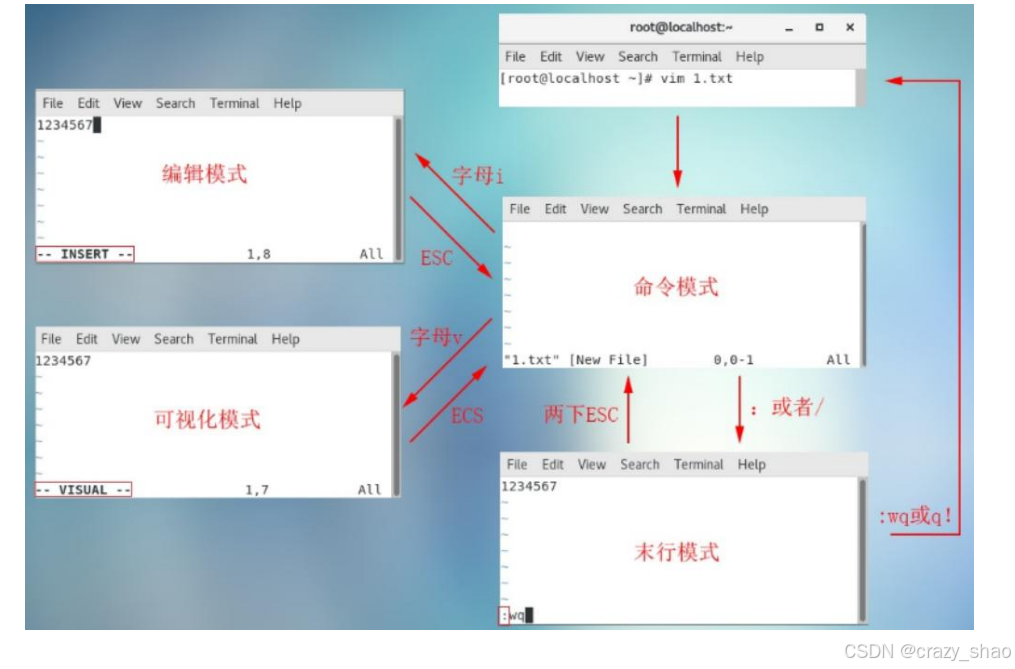
6、vim编辑器的使用
-
基本语法
① 如果文件已存在,则直接打开 ② 如果文件不存在,则 vim 编辑器会自动在内存中创建一个新文件 案例:使用 vim 命令打开 readme.txt 文件 # vim readme.txt
7、vim编辑器保存文件
在任何模式下,连续按两下 ESC 键,都可返回到命令模式。然后按冒号:,进入到末行模式,在末行模式下,输入 wq,代表保存并退出
8、vim强制退出不保存
在任何模式下,连续按两下 ESC 键,都可返回到命令模式。然后按冒号:,进入到末行模式,在末行模式下,输入 q!,代表强制退出但是不 保存文件。
9、命令模式可以进行的操作
-
如何进去命令模式
在 linux 系统中,当我们使用 vim 命令打开文件时,默认进去的模式就是命令模式,如果出去其他模式下,可以连续按两次 esc 键即可返回到命令模式
-
命令模式可以进行哪些操作
:set nu 显示行标 1、移动光标 键盘方向键 移动光标到首行:gg 移动光标到尾行:G shift + $ 行尾 shift + ^ 行首 2、翻屏 向上翻全屏 ctrl + b(before) 向下翻全屏 ctrl + f(after) 向上翻半屏 ctrl + u(up) 向下翻半屏 ctrl + d(down) 3、快速定位光标到指定行 行号+G或+gg 4、复制粘贴 1)复制当前行 按键:yy 粘贴:在想要粘贴的地方按下 p 键,按键完后会将内容粘贴在光标所在行的下一行,如果想要粘贴在光标所在行之前,则使用 P 键 2)复制多行,从当前行开始复制指定的行数,如复制 6 行,6yy 粘贴:在想要粘贴的地方按下 p 键,按键完后会将内容粘贴在光标所在行的下一行,如果想要粘贴在光标所在行之前,则使用 P 键 5、删除/剪切 在 vim 编辑器中,剪切于删除都是 dd 如果你剪切了文件,但是没有用 p 进行粘贴,就是删除操作,如果你剪切了文件,然后用 p 进行粘贴,这就是剪切操作 1)剪切/删除当前光标所在行 按键:dd (用 dd 删除后,下一行上移) 粘贴:p 2)删除/剪切多行 按键:数字 dd 粘贴:p 3) 删除/剪切光标所在行内容,但是下一行不上移 按键:D 6、撤销/恢复 撤销:u(undo) 恢复 7、替换 r
10、末行模式下的操作
-
如何进入末行模式
进入末行模式,在命令模式下使用冒号:的方式进入
-
末行模式下有哪些操作
文件保存、退出、查找、替换、显示行号、paste 模式等等
-
保存/退出
:w 代表对当前文件内容进行保存,保存完后,并没有退出该文件 :q 代表退出当前,但不保存内容,如果编辑了文件内容,是无法使用:q 退出该文件的 :wq 代表对文件内容先保存后退出 == 保存并退出 :q! 代表强制退出,不管有没有编辑文件内容,都直接退出该文件,已经编辑好的文件 内容不做保存
-
查找/搜索
在命令模式下,进入末行模式可以输入: 也可以输入斜杠/ 使用/ 基本语法: /搜索内容 案例: /hello 搜索到内容之后,会以高亮显示,取消高亮:noh 【no hight light】 基本语法 :/搜索内容 案例: :/hellp 取消高亮 #:noh 在一个文件中,搜索完后存在多个满足条件的结构。在搜索内容中切换上/下的结果,使用 大写 N 代表上一个结果,使用小写 n 代表下一个结果 n=next
-
文件内容的替换
需要在命令模式下使用冒号:进入末行模式 1)只替换当前光标所在这一行的第一个满足条件的结果 基本语法: :s/要替换的关键词/替换后的关键词/ + 回车 案例: #:s/c/3 2)替换光标所在行中的所有满足条件结果 :s/要替换的关键词/替换后的关键词/g g=global 全局替换 案例: #:s/c/3/g 3)针对整个文档中的所有行进行替换 :%s/要替换的关键词/替换后的关键词/g g=global 全局替换 案例: # :%s/c/3/g 4) 针对整个文档中的所有行进行替换。只替换每一行中满足条件的第一个结果 :%s/要替换的关键词/替换后的关键词 g=global 全局替换 案例: # :%s/c/3
-
显示行号
基本语法: :set nu nu = number,行号 取消行号: :set nonu
-
set paste 模式(扩展)
在 vim 中粘贴代码时,会出现代码多余缩进的问题。最终会是的代码变乱在粘贴代码 或数据前,可以开始 paste 模式 开户 :set paste :set nopaste o:粘贴到光标下一行 i:粘贴到光标行
11、编辑模式
-
编辑模式的作用
编辑模式主要是实现对文件的内容进行编辑的一个模式
-
如何进入编辑模式
在命令模式下,使用小写字母 a 或小写字母 i,进入编辑模式 (扩展)进入编加模式 o 在光标下一行插入 O 在光标上一行插入 a 在光标后一个字符插入 A 在光标所在行的行尾插入 i 在光标前一个字符插入 I 在光标所在行首插入 命令模式+ i :insert 缩写,代表在光标之前插入内容 命令模式+ a :append 缩写,代表在光标之后插入内容
-
退出编辑模式
在编辑模式中,直接按 ESC 键,就可以从编辑模式退出到命令模式
12、可视化模式操作
-
如何进入到可视化模式
在命令模式中,按 ctrl+v 用可视块 按小写 v 是可视 按大写 V 是可视行。 在可视模式中,使用方向键上下左右箭头选中需要复制的区域,按 y 进行复制,按 p 进行 粘贴
-
可视化模式操作
第一步:在命令模式下,按小写 v 进入可视化模式 第二步:移动方向键上下左右选择需要复制的内容,按 y 键进行复制 第三步:移动光标,停止需要粘贴的位置,按 p 进行粘贴操作
-
为配置问价添加多行注释
第一步:按 ESC 退回到命令模式,按 gg 切换到第一行 第二步:按 ctrl+v 进入到可视化区块模式(列模式) 第三步:在行首使用上下键选择需要注释的多行 第四步:按下键盘大写的"I"键,进入插入模式 第五步:输入#号注释符 第六步:输入完成后,连续按两次 esc 即可完成
-
为配置文件移除多行注释
第一步:按 ESC 退出到命令模式,按 gg 切换到第一行 第二步:按 ctrl+v 进入到可视化区块模式(列模式) 第三步:使用键盘上下方向键选中需要移除的#号注释 第四步:直接按 Delete 键即可完成删除注释操作或者按x也可以删除
13、vim编码器其他功能(了解)
-
代码着色
vim 是 vi 的升级版,比 vi 多一个代码着色的功能,此功能主要给程序员提供编程语言 的语法效果显示 案例: #vim index.php 写入内容 <?php echo 'hello world'; ?> 注意:通过命令:syntax on 开启着色功能,命令:syntax off 关闭着色功能
-
异常退出解决方案
什么是异常退出? 在编辑完文件后没有正常的:wq (保存并退出),而是突然遇到断电或关闭终端的情 况,就会出现异常退出 如何解决异常问题: 在上述界面按 D 键,或者使用 rm -rf 删除交换文件即可 #rm -rf .1.txt.swp
第十一节 查看文件内容
1、cat命令
查看文件内容 语法: # cat [选项] 文件名称 选项: -n:显示行编号
2、tac命令
倒序输入文件
倒序输入文件内容 语法: # tac 文件名称
3、head命令
基本语法: #head -n 文件名称 案例: #head -3 /etc/passwd #head /etc/passwd 显示前十行内容 功能:主要查看一个文件的前 n 行,如果不指定 n,默认显示前 10 行内容
4、tail 命令
基本语法: #tail -n 文件名称 案例: #tail /etc/passwd #tail -2 /etc/passwd 功能:查看一个文件的最后 n 行,如果不指定 n,默认显示后 10 行内容 可以使用 head 和 tail 命令通过管道“|” 查看文件的任意内容 例: # cat -n /tmp/pass| head -5 |tail -1 查看文件/tmp/pass 中第 5 行的内容 tail -f 文件名称 动态查看
5、more命令
基本语法: #more 文件名称 注意:more 命令在加载文件时,不是一点一点加载的,而是打开文件的时候就已经把 文件内容加载完到内存中。 所以当打开文件比较大时,可能会出现卡顿情况 more 命令具备交互功能,通过快捷键可以操作 more 这个阅读器 例: # more /var/log/message
| 按键 | 功能 |
|---|---|
| 回车键 | 向下移动一行 |
| d | 向下移动半页 |
| 空格键 | 向下移动一页 |
| b | 向上移动一页,后期引用,早期的more只能前进不能后退 |
| q | 退出more |
6、less分配显示文件内容
基本语法: #less 文件名称 注意:less 命令不是加载整个文件到内存,而是一点一点进行加载,相对于 more 而 言,less 读取大文件时,效率更高一点 例: # less /var/log/message
| 按键 | 功能 |
|---|---|
| 回车键 | 向下移动一行 |
| d | 向下移动半页 |
| 空格键 | 向下移动一页 |
| b | 向上移动一页 |
| 上下方向键 | 上下移动一行 |
| less -N | 显示行编号 |
| /字符串 | 搜索指定的字符串 |
| q | 退出less |
7、wc命令
基本语法: #wc [选项] 文件名称 wc 做统计 选项说明: -l:表示 lines,行数(以回车/换行符为标准) -w:表示 words,单词数(依照空格来判断单词数量) -c:表示 bytes,字节数 例: #wc pass 统计 pass 文件的行数、单词数、字节数 #wc -l pass 统计 pass 的行数 #wc -w pass 统计 pass 的单词数 #wc -c pass 统计 pass 的字节数 字节数:数字、字母一般 1 个字符=1 个字节,中文与编码格式有关,utf-8 编码格式, 1 个汉字占用 3 个字节
8、du命令
基本语法: #du [选项] 统计的文件或文件夹大小 选项说明: -s:summaries,只显示汇总的大小,统计文件夹的大小 -h:以较高的可读性显示文件或文件夹的大小 主要功能:查看文件或目录占用磁盘空间的大小 案例: #du pass 显示 pass 文件的大小,不带单位 #du -h pass 显示 pass 文件的大小,带单位 #du -s /var/log 统计/var/log 文件夹的大小 #du -sh /var/log 统计/var/log 文件夹的大小,带单位
9、find命令
基本语法:
#find 搜索路径 [选项]
选项说明:
-name:指定要搜索文件的名称,支持*星号通配符
-type:指定搜索的文件类型,f 代表普通文件,d 代表文件夹
-size: 指定文件大小
功能:用于帮助管理员查找文件的路径
案例:
#find /var -name "boot.log" -type f 在/var 搜索 boot.log 文件
#find / -name "boot.log" -type f 全盘搜索 boot.log 文件
#find / -name "tmp" -type d 全盘搜索 fq 目录
#find /var/log -name "*.log" -type f 在/var/log 下搜索名字为*.log 且是普通文件
# find /var/log/ -size +4M 搜索/var/log 大于 4M 的文件
扩展:find /tmp -name "*.txt" -exec cat {} \;
find /tmp -type d -exec ls {} \;
-exec:可以执行的动作
10、grep命令
语法: #grep [选项] 要搜索的关键词 搜索的文件名称 选项说明: -n :代表显示包含关键词的行号 功能:在文件中直接找到包含指定关键词的行,并高亮显示出这些信息 案例: #grep root /etc/passwd #grep -n root /etc/passwd 显示包含关键字 root 所在行的行号扩展: #grep 搜索的关键词 多个文件的名称 #grep network /var/log/* 扩展: -v:取反 -i:忽略大小写过滤出来 -o:只过滤想要的 ^:开头 $:结尾 -E:在 Linux 系统中,grep是一种强大的文本搜索工具,而grep -E(也可以写作egrep)用于启用扩展正则表达式搜索。 grep -E 'pattern1|pattern2' file.txt:在文件file.txt中搜索包含模式pattern1或者pattern2的行。
11、echo命令
基本语法: #echo "文本内容" 功能:在终端中输入指定的内容,并输出 案例: #echo "hello world"
12、>或>>重定向
“>” 标准输出重定向:覆盖输出,会覆盖原先的文件内容 “>>”追加重定向:追加输出,不会覆盖原始文件内容,只会在原始内容末尾继续添加 # rm -rf /tmp/* # echo "hello" > a.txt 有内容则覆盖,没有创建有内容 hello 的文件 # echo "world" >> a.txt 有内容则追加,没有创建有内容 world 的文件 # echo "linux" > a.txt
13、ln命令
作用:对文件或文件夹进做连接文件,ln 可以对文件进行软链接和硬链接 软连接(ln -s 命令): 软链接有着自己的 inode 号以及用户数据块。只不过用户数据块中存放的内容是另一文件 的路径名的指向。 基本用法: # ln -s 绝对路径/源文件名 绝对路径/链接文件名 软连接的特点: ① 不论是修改源文件,还是修改软链接文件,另一个文件中的数据都会发生改变。 ② 删除软链接文件,源文件不受影响。而删除原文件,软链接文件将找不到实际的数据, 从而显示文件不存在。 ③ 软链接会新建自己的 inode 信息和 block,只是在 block 中不存储实际文件数据,而存 储的是源文件的文件名及 inode 号。 ④ 软链接可以链接目录。 ⑤ 软链接可以跨分区 ⑥ 软链接会占用 inode 和 block。 硬链接(ln 命令): 硬链接可以视为普通的目录,但是所有的硬链接共用同一个 inode 号,只是文件名不同。 基本语法: # ln 绝对路径/源文件 绝对路径/链接文件名 硬链接特点: ① 不论是修改源文件,还是修改硬链接文件,另一个文件中的数据都会发生改变。 ② 不论是删除源文件,还是删除硬链接文件,只要还有一个文件存在,这个文件都可以被 访问。 ③ 硬链接不会建立新的 inode 信息,也不会更改 inode 的总数。 ④ 硬链接不能跨文件系统(分区)建立,因为在不同的文件系统中,inode 号是重新计算 的。 ⑤ 硬链接不能链接目录,因为如果给目录建立硬链接,那么不仅目录本身需要重新建立, 目录下所有的子文件,包括子目录中的所有子文件都需要建立硬链接,这对当前的 Linux 来讲过于复杂。 ⑥ 硬链接不会占用 inode 和 block。
第十二节 用户管理
1、Linux用户组管理
-
为什么了解用户和用户组
在生产环境中,管理服务器有多个账户, 不同账户对应的权限不同。
-
用户和用户组的关系
在 linux系统中,创建一个用户时,用户都会属于一个主组。在某些情况下。某个用户临时需要使用某个组的权限,那这个组就称为该用户的附属组。主组=亲爹 附属组=干爹。
-
用户组操作
用户组操作主要是:用户组的添加、用户组的修改一级用户组的删除 组:group 添加:add groupadd 添加组 修改:mod groupmod 修改组 删除:del groupdel 删除组 1、用户组添加 语法:groupadd [选项] 用户组的名称 -g:代表用户组的ID编号。自定义以组从1000开始,不能重复。 例: #groupadd hr #groupadd -g 1050 test 默认情况下,添加的用户组都会放在一个系统文件中,文件位置 /etc/group hr:x:1050: 在/etc/group文件中,一共三个冒号:,共四列 第一列:用户组的名称; 第二列:用户组的密码;使用一个 5x 进行占位,安全起见 第三列:用户组的ID;1-999 是系统用户组的编号,1000 以后的组 ID 是自定义组的编号 第四列:用户组内的用户信息(如果一个用户的附属组为该组,就会将该用户的名称显示在此位置) 2、用户组的修改 基本语法:groupmod [选项] 原来的组名称 -g:gid的缩写,修改用户的id -n:name的缩写,修改用户的名称 3、用户组的删除 语法:groupdel 组的名称
2、用户操作
用户操作主要是:用户的添加、用户的修改以级用户的删除:user
添加:add useradd 添加组
修改:mod usermod 修改组
删除:del userdel 删除组
-
用户的添加
基本语法:useradd [选项 选项的值] 用户名称 选项说明: -g:代表添加用户时指定的用户所属组的主组 -s:代表指定用户可以使用的shell类型,默认为/bin/bash(拥有大部分的权限)还可以时/sbin/nologin,/sbin/nologin不能用于登录操作系统。/bin/bash给人使用的,/sbin/nologin是给软件使用的 -G:代表添加用户时指定用户所属组的附属组,附加组可以指定多个,用“,”隔开即可 -u:代表添加用户时指定的用户ID编号,ID编号同样也是从1000开始 -c:代表用户的注释信息 -d:代表用户的家目录,默认为/home/用户名称,可以使用-d进行修改 -n:取消建立以用户名称为名的群组 -M:表示不创建用户主目录。通常情况下,创建用户时会自动创建一个对应的主目录,但在某些场景下,可能不需要为用户创建主目录 -r:“useradd -r” 是在 Linux 系统中用于创建系统用户的命令选项。 问题:当没有为 lisi 账户指定其所属的主组时,可以成功创建账号吗 答:在创建账户时,如果没有使用-g 明确指定用户所属的主组,默认情况下,系统会自定 在用户组中创建一个与用户 lisi 同名的用户组,该组就是 lisi 用户的主组 注意:新建的账户 lisi 并不能立马用于登录操作系统,linux 账户必须拥有密码后才能进行 登录
-
用户信息查询
基本语法:id 用户名称 功能:查询某个指定的用户信息 案例: #id jia uid=1004(jia) gid=1004(jia) groups=1004(jia),1002(whhr) uid: 用户编号 gid: 用户所属的主组的编号 groups: 用户的主组一级附属组信息,第一个是主组,后面跟的都是附属组信息,主组 只有一个,附属组有多个
-
用户文件内容
组: /etc/group 文件 用户: /etc/passwd 文件,每创建一个用户,就会在此文件中追加一行 # tail -3 /etc/passwd jia:x:1004:1004::/home/jia:/bin/bash yi:x:1005:1002::/home/yi:/sbin/nologin xiaohong:x:1006:1006:nihao:/home/xiaohong:/bin/bash 由上述输出内容可知,用户文件内容有 7 列 第一列:用户名称 第二列:用户的密码,使用一个 X 占位,真实密码密码存储于/etc/shadow 第三列:用户的 ID 编号,数字 第四列:用户的主组 ID 编号,数字 第五列:代表的注释信息,使用 useradd -c “备注信息” 用户名称 进行添加 第六列:用户的家目录,默认在/home/用户名称 第七列:用户可以使用的 shell 类型,使用 useradd -s /bin/bash 或 /sbin/nologin 用户 名称 进行修改
-
用户修改
基本用法:usermod [选项 选项值] 用户名称 -s: 修改用户可以使用的 shell 类型,如/bin/bash => /sbin/nologin -g: 修改用户所属的主组的编号 -l: login name 修改用户的名称 扩展: -L: 锁定用户,锁定后用户无法登录系统 lock -U: 解锁用户 unlock -G: 修改用户的附属组的编号信息 -d: 修改用户的家目录 -c: 修改用户的备注信息 案例 1:修改 zhangsan 账户的名称为 zs #usermod -l zs zhangsan 案例 2:修改账户 zs 的主组编号 #usermod -g 1060 zs 案例 3:修改账户 zs 的 shell 类型为/sbin/nologin #usermod -s /sbin/nologin zs 案例 4:禁止 Linux 用户登场操作 #usermod -L xiaohong
-
给用户设置密码
passwd命令给用户设置密码 语法:passwd 用户名称 功能:为某个用户设置密码(添加或者修改) 注意:只有root用户才能给其他用户设置密码,而普通用户只能修改自己密码 什么是交互式,就是输入命令后,会有提醒让你输入一些东西,非交互式就是输入命令直接返回[root@locahost ~]# 方式一:交互式 passwd 用户名称 注意:在Linux中,用户没有密码,则无法登录操作系统 方式二:非交互式 echo “123” | passwd --stdin 用户名称 扩展: "|" : 竖线 作用:管道是一种通信机制,用于进程与进程间的通信。主要功能是将前面一个进程的输出 (stdout)直接作为下一个进程的输入(stdin) 用户的密码文件: /etc/shadow # man 5 shadow
-
切换用户
su - 用户名称 -:横杠,代表切换用户时,切换到用户的家目录 功能:切换用户的账户 从 root 切换到普通用户,不需要输入密码, 退出普通用户输入命令 exit 从普通用户切换到 root,需要输入 root 密码 从普通用户切换普通用户,需要输入要切换的普通用户密码
-
wheel组
在 linux 系统中,理论上只有 wheel 组中的用户,才可以通过 su 命令切换到 root 账户; 默认所有普通用户只要指定 root 密码都能切换到 root。然后默认 wheel 组规则不生效 第一步:添加一个用户到wheel组 # useradd u1 # useradd u2 # passwd u1 # passwd u2 # usermod -G 10 u1 # cat /etc/group |grep wheel 第二步:开启wheel组 #vim /etc/pam.d/su 将#auth required pam_wheel.so use_uid 此行最前面的#删除
-
删除用户
基本语法:userdel [选项] 用户名称 -r:删除用户的同时,删掉用户的家目录 注意事项: 1、如果一个用户的主组是另一个用户的主组,那么删除这个用户的时候主组是不会被删除的 2、如果一个组是一个用户的主组,就不能直接删除此组,必须先删除用户 3、如果一个用户的家目录指定了非/home下,删除此用户时,不会删除该用户指定的家目录
第十三节 权限管理
1、权限的基本概念
在计算机系统的管理中,权限是指针对特定的用户具有特定的系统资源使用权力,在Linux 中分别有读、写、执行权限
| 表示 | 权限针对文件 | 权限针对目录 |
|---|---|---|
| 读r | 可以查看文件内容:cat | 可以查看目录中存在的文件名称,使用 ls |
| 写 w | 可以更改文件的内容:vim 修改 | 可以删除目录中的子文件或者新建子目录(rm) |
| 执行 x | 可以开启我能见当中目录的程序 | 程序,可以进入目录中(cd) |
注意:一般在给予目录或文件权限时,会使用套餐组合,给文件 w 权限就要给 r 权限,给目录读权限就有给执行权限
2、为什么要设置权限
①服务器中的数据是有价值
②员工的工作职责和分工不同
③应对外部的攻击
④内部管理的需要
3、Linux用户的身份类别
Linux 系统一般将文件权限分为 3 类:
read(读)
write(写)
execute(执行)
三大用户拥有对文件的读、写、执行权限
4、user文件的拥有者
谁常见的文件,谁就是该文件的拥有者
5、group文件所属组内用户
group 所属组内用户代表 与文件的所属组相同的组内用户
6、other其他用户
other 其他用户代表这些人既不是文件的拥有者,也不是文件所属组内的用户,这些用户就称为 other 其他用户
7、特殊用户root
在 linux 操作系统,root 拥有最高权限(针对所有文件),所以权限设置对 root 账户没有效果,在 linux 系统中,三大类用户有简称形式 user(u)、group(g)、other(o)
8、普通权限管理
-
ls -l 查看文件权限
基本语法:ls -l 简写:ll 注意:ll 命令是红帽以及 centos 系统特有的命令,其他操作系统可能不支持 ll 查看文件得到拆分的是:- rw-------. 1 root root 1259 4月 11 23:29 anaconda-ks.cfg 含义: -:文件的类型 rw- --- ---.:文件的权限 1:文件节点数 root:文件的所有者 root:文件的所属组 1259:文件大小 4月 11 23:29:文件的最后修改时间 anaconda-kd.cfg:文件名称 拆分rw-------为rw-、---、--- 的含义: rw-:user的权限 ---:group所属组的权限 ---:other的权限 -
文件类型以及权限的解析
Linux中有7种文件类型: -:普通文件 d:目录文件 l:软链接(类似Windows的快捷方式) b:block,块设备文件,硬盘、光驱等 p:管道文件 c:字符设备文件,串口设备、光猫等 s:套接口文件
-
文件或文件夹的权限设置---通过字母设置
基本语法:chmod = chang mod chmod [选项] 权限设置 文件或文件夹的名称 选项说明: -R:递归设置,主要用于文件夹的权限设置 三个方面: 第一个:确认要给哪个身份赋予权限 u、g、o、ugo(a) 第二个:添加权限(+)、删除权限(-)、赋予权限(=) 第三个:确认赋予用户什么样的权限,r、w、x 案例 1:给 test.txt 文件的拥有者,增加一个可执行权限 #chmod u+x test.txt 案例 2:给 test.txt 文件的拥有者,移除可执行权限 #chmod u-x test.txt 案例 3:给 test.txt 的所属组内用于赋予 rw 权限 #chmod g=rw test.txt 案例 4:给所有用户添加可执行权限 #chmod ugo+x test.txt 案例 5:给/linux 目录及其内部的文件统一添加 w 权限 #chmod -R a+w linux 案例 6:给/linux 目录设置权限,要求拥有者权限为 rwx,组内用户权限为 r-x,其他用户 为 r-x #chmod -R u=rwx,g=rx,o=rx linux chmod -R 755 linux
-
文件或文件夹的权限设置---通过数字设置
在网站上添加权限,一般会这样写,#chmod 777 a.txt,这种形式被称为数字形式权限文件权限与数字的对应关系
权限 对应数字 意义 r 4 可读 w 2 可写 x 1 可执行 - 最大权限 777: 第一个数字 7:代表文件拥有者权限 u 第二个数字 7:代表文件所属组内用户权限 第三个数字 7:代表其他用户权限 rwx=4+2+1=7 rw=4+2=6 rx=4+1=5 案例 6:给 test.txx 文件设置权限,要求拥有者权限为 rwx,组内用户权限为 r-x,其他用 户为 r-x #chmod 755 test.txt 案例 7:给 Linux 目录的所有用户设置 rwx 权限 #chmod -R 777 linux
9、文件拥有者以及文件所属组设置
文件拥有者:属主(所有者)
文件所属组:属组(所属组)
-
什么是属主与属组
属主:所属的用户,文档的所有者,一般是一个用户
属组:所属的用户组,一般是一个组
-
文件拥有者与所属组的查看
ls -l 简写:ll -rw-------. 1 root root 1259 4月 11 23:29 anaconda-ks.cfg anaconda-ks.cfg文件的所有者是root snaconda-ks.cfg文件的所属组是root
-
文件拥有者所属组设置
基本语法:chown ch = change,own = owner chown [选项] 文件拥有者名称:文件所属组名称 文件名 或 chown [选项] 文件拥有者名称.文件所属组名称 文件名 选项说明: -R:代表递归修改,主要针对文件夹
-
文件所属组设置
基本语法:chogrp ch=change,grp=group chgrp [选项] 新文件所属组名称 文件名称 选项说明: -R:代表递归修改,主要针对文件夹
10、特殊权限
-
特殊权限suid
suid 属性只能运用在可执行文件上,含义是开放文件所有者的权限给其他用户,即当普通用户执行该执行文件时,会拥有该执行文件所有者(root 用户权限)的权限。 suid 仅限于可执行文件,也就是 二进制文件,比如系统下的/usr/bin 下提供的命令,/usr/bin/ls、/usr/bin/rm suid 特殊权限只要用户设有 suid 的文件有执行权限,那么当用户执行此文件时,会以属主的身份去执行,一旦文件执行结束,身份的融合也会随之消失。 注意: suid 功能是针对二进制命令设置的,不能用在 shell 脚本上 用户权限位 x 位置处,如果有则为 s,无则为 S,表示该命令存在 suid 权限 用法:chmod u+s 文件路径 which cat:显示命令的绝对路径 案例: [root@localhost tmp]# cd /tmp [root@localhost tmp]# touch suid.txt [root@localhost tmp]# chmod 0 suid.txt [root@localhost tmp]# ll suid.txt ---------- 1 root root 0 5 月 15 23:03 suid.txt [root@localhost tmp]# echo "hello suid" > suid.txt [root@localhost tmp]# cat suid.txt hello suid [root@localhost tmp]# su - user01 上一次登录:三 5 月 15 22:52:11 CST 2024pts/0 上 [user01@localhost ~]$ cd /tmp/ [user01@localhost tmp]$ cat suid.txt cat: suid.txt: 权限不够 [user01@localhost tmp]$ exit 登出 [root@localhost tmp]# ll `which cat` -rwxr-xr-x. 1 root root 54080 11 月 17 2020 /usr/bin/cat [root@localhost tmp]# chmod u+s /usr/bin/cat [root@localhost tmp]# ll `which cat` -rwsr-xr-x. 1 root root 54080 11 月 17 2020 /usr/bin/cat [root@localhost tmp]# su - user01 上一次登录:三 5 月 15 23:04:52 CST 2024pts/0 上 [user01@localhost ~]$ cat /tmp/suid.txt hello suid 取消 suid # chmod u-s /usr/bin/cat
-
特殊权限sgid
SGID 属性可运用于文件或者目录,运用在文件的含义是开放文件所属组的权限给其他用户,当用户执行该执行文件时,会拥有该执行文件所属组用户的权限。 对于文件夹,为某个目录设置了 sgid 后,该目录文件属于属组;在这个目录下创建的文件、文件夹都会继承该目录的所属组。 对于二进制文件,若 g 具有 x 权限,并设置了 sgid 权限,其他用户可以获得属组的权限去执行该二进制文件 用法:chmod g+s 文件路径
-
特殊权限sticky(粘贴位)
sticky 权限只能运用于目录上,限制普通用户在此目录下只能删除自己的文件,不能删除其它用户创建的文件。sticky 权限 是起到防止被别人误删除的作用! 用法:chmod o+t 文件路径
-
通过数字修改文件的特殊权限
特殊权限数字表示方式: Suid 4 Sgid 2 Sticky 1 例: # chmod 4755 /usr/bin/cat 或 chmod u+s /usr/bin/cat # chmod 2777 /tmp/linux 或 chmod g+s /tmp/linux # chmod 1777 /tmp/dir_sticky 或 chmod o+t /tmp/dir_sticky # chmod 7777 文件名 表示: 对文件设置 u+s,g+s,o+t
11、ACL访问控制列表
-
使用场景
在基础权限中,用户对文件只有三种身份,就是属主、属组和其他人,每种用户身份拥有读(read)、写(write)和执行(execute)三种权限。但是在实际工作中,这三种身份实在是不够用……! 当要给一个用户与文件属主、属组、其他人权限都不相同的时候,我们就可以使用 ACL访问控制列表,也就是说,这个用户对于这个文件不属于三种身份的任何一种,是属于第四种身份,那么我们就需要使用 ACL 权限去给他赋予单独的权限!
-
查看acl权限
getfacl 文件或目录名称
-
设置文件的acl权限
语法:setfacl [选项] 文件或目录名称 选项说明: -m:修改acl策略 -x:去掉某个用户或组的权限 -b:删除所有acl策略 -R:递归,主要针对文件夹 -d:应用到默认访问控制列表的操作(继承效果) 案例 1: # rm -rf /tmp/* # mkdir /tmp/dir_acl # ll -d /tmp/dir_acl/ # su - user01 $ touch /tmp/dir_acl/user01.txt $ exit # setfacl -m u:user01:rwx /tmp/dir_acl/ # setfacl -m u:user02:4 /tmp/dir_acl/ # getfacl /tmp/dir_acl/ # su - user01 $ touch /tmp/dir_acl/user01.txt $ exit # su - user02 $ ls /tmp/dir_acl/ 注意: 无法访问是因为 dir_acl 对 user02 只设置了 r 权限,它只能看不能进因此会报此错 [user02@localhost ~]$ cd /tmp/dir_acl -bash: cd: /tmp/dir_acl: 权限不够 [user02@localhost ~]$ exit 从上面可以看出对 user01 和 user02 设置了 acl 权限后两个用户对 dir_acl 目录就有了第 四种身份,不受 ugo 权限控制 案例 2: # mkdir /tmp/dir_acl/test # setfacl -R -m u:user01:rw /tmp/dir_acl/ # getfacl /tmp/dir_acl/ # getfacl /tmp/dir_acl/test/ 给用户设置 group 的 ACL 权限 # setfacl -R -m g:user02:rwx /tmp/dir_acl/ # getfacl /tmp/dir_acl/test/ 案例 3: 移除单个用户 ACL 权限 # setfacl -x u:user01 /tmp/dir_acl/ # getfacl /tmp/dir_acl/ 移除全部 ACL 权限 # setfacl -m u:user01:rw /tmp/dir_acl/ # getfacl /tmp/dir_acl/ # setfacl -b /tmp/dir_acl/ # getfacl /tmp/dir_acl/ 案例 4: 移除目下所有文件的 ACL 权限 # setfacl -m u:user01:rw /tmp/dir_acl/ # getfacl /tmp/dir_acl/ # getfacl /tmp/dir_acl/test/ # setfacl -R -b /tmp/dir_acl/ # getfacl /tmp/dir_acl/ # getfacl /tmp/dir_acl/test/
12、umask
-
什么是umask
代表创建文件时的默认权限
root 创建文件默认权限是 644
普通用户创建文件默认权限是 664
-
查看umask值
#umask
-
修改umask
umask 022 永久修改 vim ~/.bashrc 在文档末尾添加umask022即可 保存并退出 su 切换用户生效
-
umask码作用
umask码使得用户创建目录和权限时,拥有默认的权限
创建文件的默认权限值
文件权限 = 初始权限(666)- umask
创建目录的默认权限值
初始权限(777) - umask
初始权限(777) ===》 转换成字母 r w x r w x r w x
umask如002 ===》 转换成字母 - - - - - - - w -
r w xr r w x r - x
7 7 5
13、隐藏权限
文件的隐藏权限,默认看不到的权限(对管理员也生效)
-
添加隐藏权限
基本语法: chattr +a/+i 文件名 选项: +a:限制用户只能追加内容,不能删除,剪切文件 +i:限制用户只能查看文件内容,不能删除,剪切,追加,修改文件 案例: # cd /tmp # rm -rf * # echo "hello linux"> a.txt # chattr +a a.txt # echo "hello" > b.txt # chattr +i b.txt
-
查看隐藏权限
基本语法:lsattr 文件名称 案例: # lsattr a.txt
-
删除隐藏权限
基本语法:chattr -a/-i # chattr -a a.txt # chattr -i b.txt
二、Linux基础管理
第一节 数据通信基础
详细内容请看PPT文件:2.1--2.2数据通信基础,
补充:
单模光纤和多模光纤的区别:
1、传输模式
单模:光以一种模式(基模)进行传输。
多模:光以多种模式同时进行传输。
2、传输距离
单模:长距离,几十甚至上百公里
多模:短距离,在几公里范围内,适用于局限网(LAN)
3、光源
单模:使用激光作为光源,分布式反馈激光器
多模:使用LED,成本相对较低
4、宽带
单模:宽带更高和更大的信息量
多模:数据传输速率相对较低
802.11n
IEEE 2009年发布。 1、高速度 最高理论数据600mbps,实际150--450Mbps 2、兼容性 向下兼容802.11 a/b/g标准
802.11ac
IEEE 2013年发布 1、速度 理论峰值6.93Gbs,实际传输速度在433---1.73G之间
第二节 IP地址分类及子网划分
1、IPv4地址介绍
-
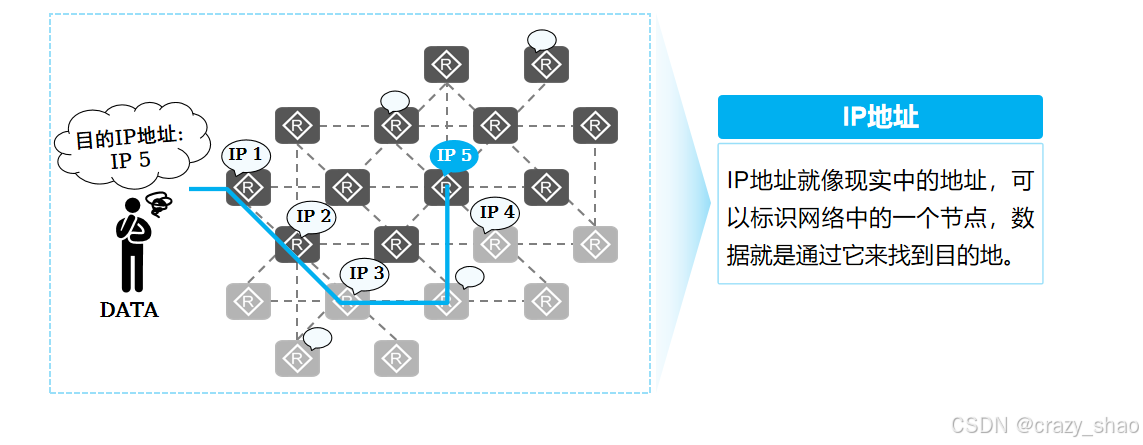
什么是IP地址
IP地址在网络中用于标识一个节点(或者网络设备的接口)。
IP地址用于IP报文在网络中的寻址。
-
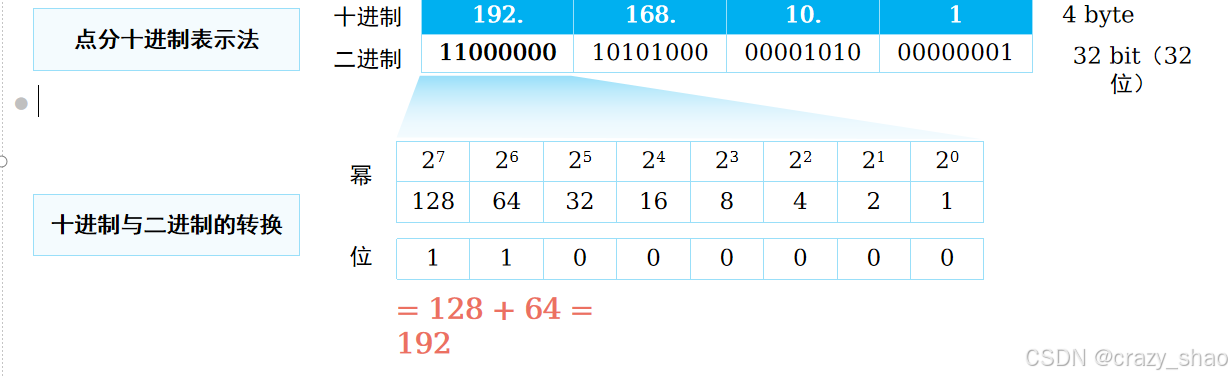
ip地址表示
一个IPv4地址有32 bit。
IPv4地址通常采用“点分十进制”表示。
IPv4地址范围:0.0.0.0~255.255.255.255
-
IP地址构成
网络部分:用来标识一个网络。
主机部分:用来区分一个网络内的不同主机。
网络掩码:区分一个IP地址中的网络部分及主机部分。

-
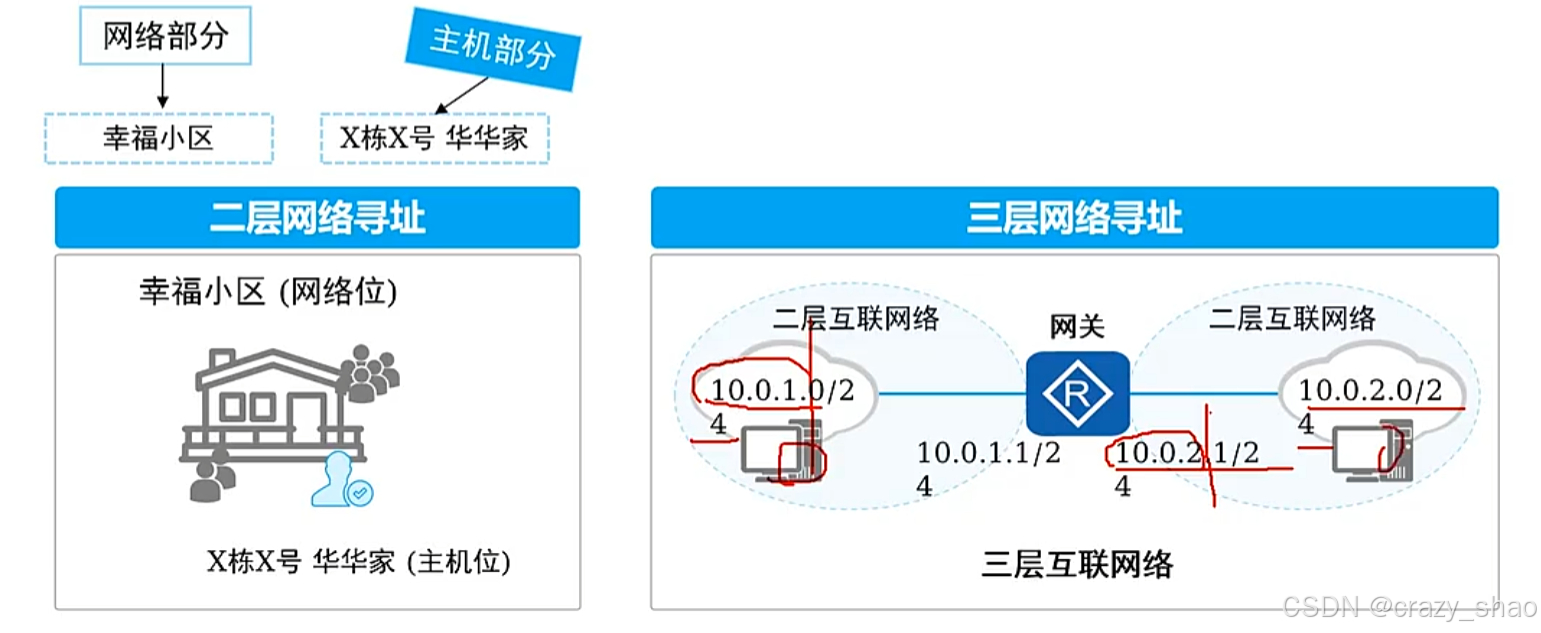
IP地址寻址
网络部分:用来标识一个网络,代表IP地址所属网络。
主机部分:用来区分一个网络内的不同主机,能唯一标识网段上的某台设备。
-
IP地址分类
为了方便IP地址的管理及组网,IP地址分成五类:
A类:0.0.0.0~127.255.255.255 -------00000000~01111111
B类:128.0.0.0~191.255.255.255 -------10000000~10111111
C类:192.0.0.0~223.255.255.255 ------- 11000000~11011111
D类:224.0.0.0~239.255.255.255 --------11100000~11101111
E类:240.0.0.0~255.255.255.255 --------11110000~11111111
A/B/C类默认网络掩码
A类:8 bit, 0.0.0.0~127.255.255.255/8,前八位是网络部分
B类:16bit,128.0.0.0~191.255.255.255/16 前16位是网络部分
C类:24bit,192.0.0.0~223.255.255.255/24 前24位是网路部分
-
IP地址类型
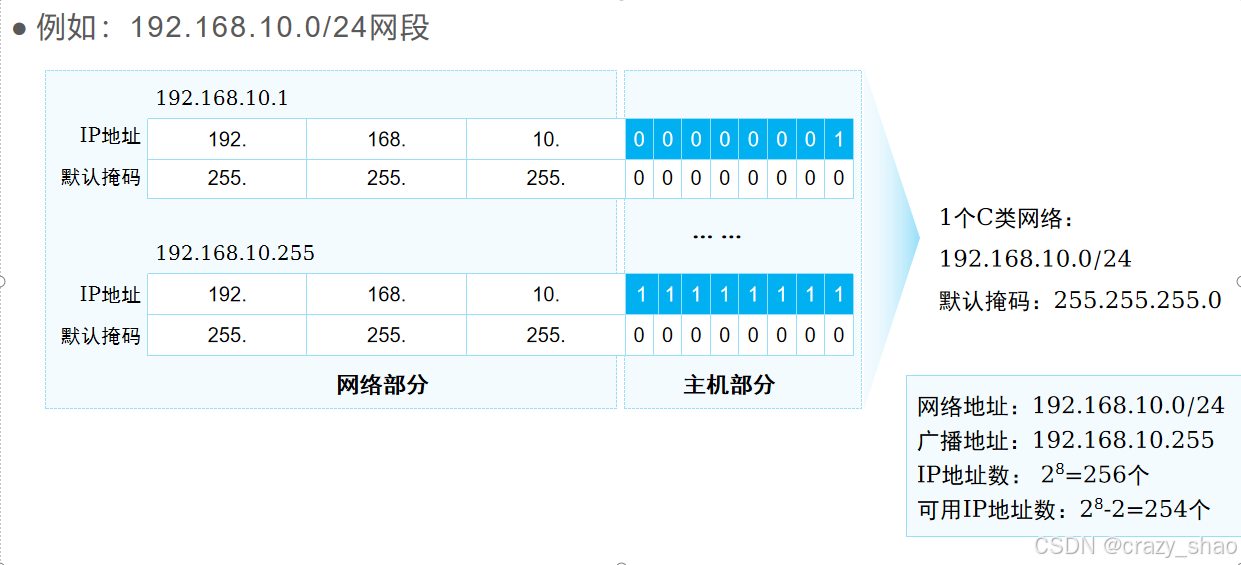
我们通常把一个网络号所定义的网络范围称为一个网段。
网络地址:用于标识一个网络。 例如:192.168.10.0/24 192.168.10. 00000000 广播地址:用于向该网络中过的所有主机发送数据的特殊地址 例如:192.168.10.255/24 192.168.10. 11111111 可用地址:可分配给网络中的节点或网络设备接口的地址。 例如:192.168.10.1/24 192.168.10. 00000001 注意:网络地址和广播地址不能直接被节点或网络设备所使用。 一个网段可用地址数量为:2ⁿ-2(n:主机部分的比特位数)
-
私网IP地址
公网IP地址:IP地址是由IANA统一分配的,以保证任何一个IP地址在Internet上的唯一性。这里的IP地址是指公网IP地址。
私网IP地址:实际上一些网络不需要连接到Internet,比如一个大学的封闭实验室内的网络,只要同一网络中的网络设备的IP地址不冲突即可。在IP地址空间里,A、B、C三类地址中各预留了一些地址专门用于上述情况,称为私网IP地址。
A类:10.0.0.0~10.255.255.255
B类:172.16.0.0~172.31.255.255
C类:192.168.0.0~192.168.255.255
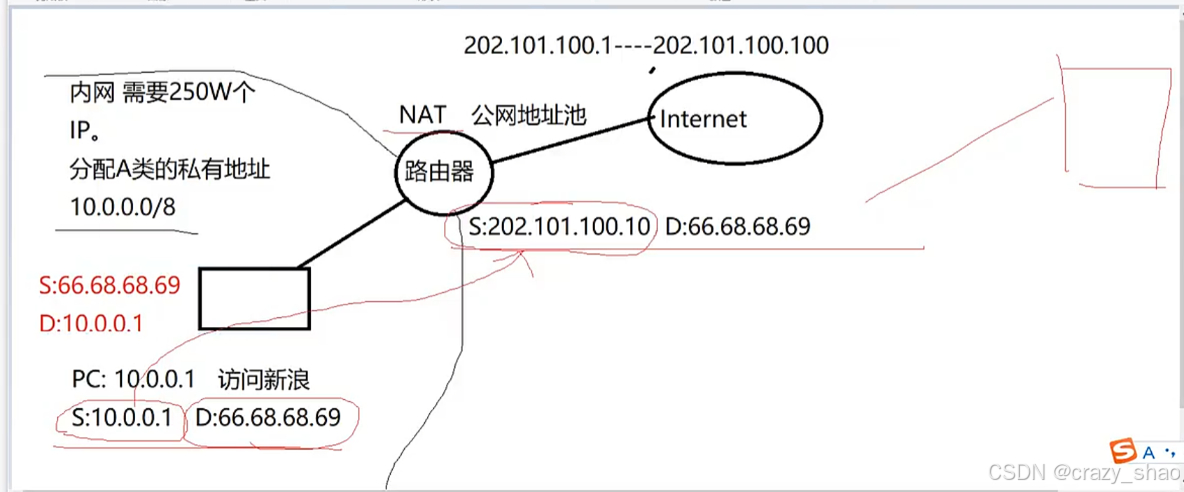
注意:为什么需要在A、B、C类地址里面各划分一段地址为私有地址?
ipv4公网地址一共43亿个。全球80亿人口,人均分配不到一个公网地址。手机、电脑、平板、汽车都需要上网。企业服务器、路由器、防火墙网络设备需要消耗大量的ip地址,如果全部都分配公网ip,很显然不够
企业内网用私有ip,需要上网的时候,由出口路由器或者防火墙上将私有ip地址转化为公有IP地址。上图案例分析。
学校机房、小公司几十个节点 -----》C类私有地址
几千个节点-----5w个节点 ------》B类私有节点
大型的央企,需要6w -----》百万节点需求 A类私有
-
特殊Ip地址
IP地址空间中,有一些特殊的IP地址,这些IP地址有特殊的含义和作用,举例如下。
| 特殊IP地址 | 地址范围 | 作用 |
|---|---|---|
| 有限广播地址 | 255.255.255.255 | 可作为目的地址,发往该网段所有主机(受限于网关) |
| 任意地址 | 0.0.0.0 | “任何网络”的网络地址;“这个网络上这个主机接口”的IP地址 |
| 环回地址 | 127.0.0.0/8 | 测试设备自身的软件系统 |
| 本地链路地址 | 169.254.0.0/24 | 当主机自动获取地址失败后,可使用该网段中的某个地址进行临时通信 |
-
ipv4 vs ipv6
由全球IP地址分配机构,IANA (Internet Assigned Numbers Authority)管理的IPv4地址,于2011年完全用尽。随着最后一个IPv4公网地址分配完毕,加上接入公网的用户及设备越来越多,IPv4地址枯竭的问题日益严重,这是当前IPv6替代IPv4的最大源动力.
ipv4:地址长度:32 bit
地址分类:单播地址、广播地址、组播地址
特点:地址枯竭、包头设计不合理、对ARP的依赖,导致广播泛滥
ipv6:地址长度:128 bit
地址分类:单播地址、广播地址、任播地址
特点:无限地址、简化的报文头部、IPv6地址自动部署
2、子网划分
-
为什么要划分子网
一个B类地址用于一个广播域,地址浪费。
广播域太庞大,一旦发生广播,内网不堪重负。
将一个网络号划分成多个子网,每个子网分配给一个独立的广播域。
如此一来广播域的规模更小、网络规划更加合理。
IP地址得到了合理利用。
-
VLSM(Variable Length Subnet Masking,可变长子网掩码)是一种子网划分技术,它允许在一个网络中使用不同长度的子网掩码,以更有效地分配 IP 地址空间。
-
如何进行子网划分--原网段分析
-
如何进行子网划分 --- 向主机借位
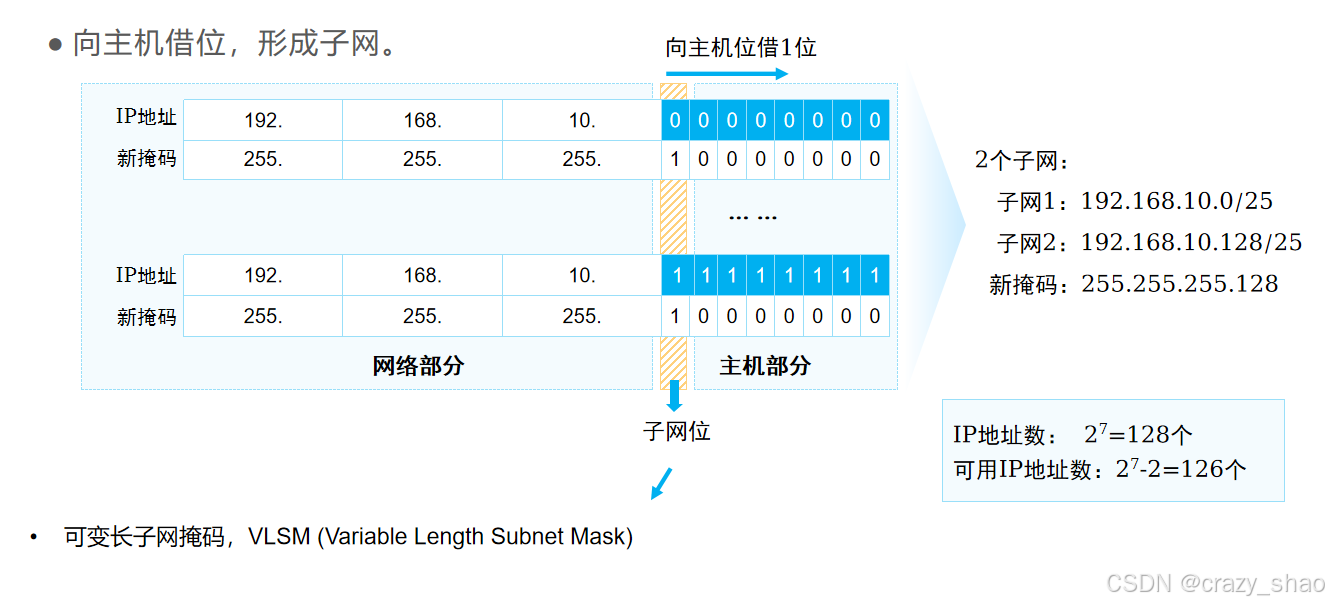
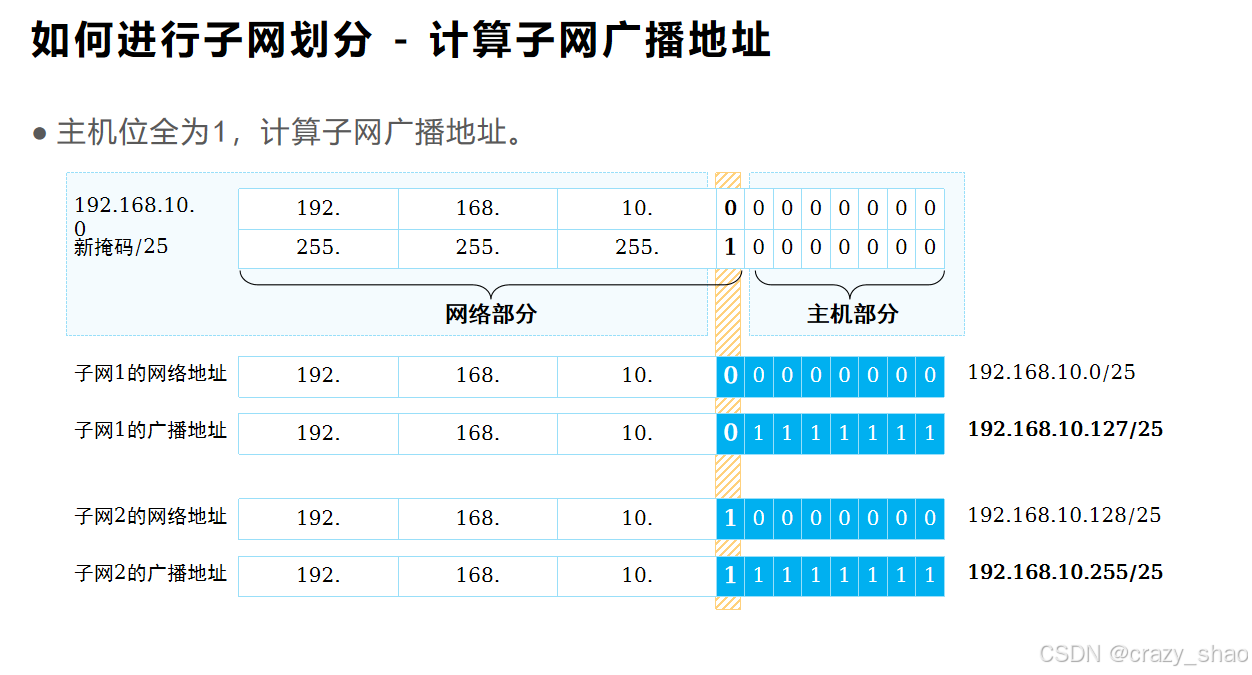
规则:
1、主机范围介于网络位和广播之间
2、每个子网广播地址减去网络地址等差相同,等差就是主机减1的数
3、下一个子网的网络位等于前一个子网广播进一位
4、借主机位产生新的子网是从左往右借,借n位,可以产生2的n次方个子网
-
无类域间路由器
CIDR的概念:忽略A、B、C类网络的规则,定义前缀相同的一组网络为一个块,即一条路由器条目。
-
CIFR的有点:
1、减少了网路数目,缩小了路由器由选择表
2、从网络流量、CPU和内存方面来说,开销更低
3、对网络进行编址时,灵活性更大
扩展:
按位与运算(&)是一种在二进制层面上对两个数进行操作的运算。 具体计算方法如下: 假设有两个二进制数 A 和 B,对它们的每一位进行如下操作: 如果该位上 A 和 B 均为 1,则结果的该位为 1;如果 A 和 B 中至少有一个为 0,则结果的该位为 0。 例如: 二进制数 1010(十进制为 10)和 1100(十进制为 12)进行按位与运算。 1010 1100 ---- 1000 结果为 1000(十进制为 8)。 在 IP 地址与子网掩码的按位与运算中,目的是确定网络地址。子网掩码中为 1 的位表示网络位,为 0 的位表示主机位。通过将 IP 地址与子网掩码进行按位与运算,可以将 IP 地址中的主机位清零,从而得到网络地址。
第三节 Linux网络管理
1、获取计算机的网络信息
基本语法:ifconfig 或 ip address 简写:ip a 使用 ifconfig 和 ip address 命令,获取计算机的网络信息 ifconfig ens33 直接获取网卡信息
ifconfig解析:
| ens33 | 是默认网卡 |
|---|---|
| lo | 环回网卡,127.0.0.1 作为固定 ip 代表本机 |
| virbr0 | 虚拟网络接口,vmware 安装 centos7 时,会产生 virbr0虚拟网络接口 |
inet 192.168.10.128 netmask 255.255.255.0 broadcast 192.168.10.255
| inet 192.168.10.128 | 代表 ens33 网卡的 ip 地址,一般远程登录就是使用该 ip |
|---|---|
| netmask 255.255.255.0 | 子网掩码 |
| broadcast 192.168.20.255 | 广播地址 |
ip address解析
| ens33 | 是默认网卡 |
|---|---|
| lo | 环回网卡,127.0.0.1 作为固定 ip 代表本机 |
| virbr0 | 虚拟网络接口,vmware 安装 centos7 时,会产生 virbr0虚拟网络接口 |
inet 192.168.10.128/24 brd 192.168.10.255 scope global noprefixroutedynamic ens33
| inet 192.168.10.128 | 代表 ens33 网卡的 ip 地址,一般远程登录就是使用该 ip |
|---|---|
| /24 | /24 表示子网掩码(255.255.255.0) |
| brd 192.168.10.255 | 广播地址 |
2、网卡配置
# cat /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=dhcp DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=ff43010e-f68c-447c-acab-91ed72fb86de DEVICE=ens33 ONBOOT=yes #参数解析 TYPE:代表网络类型,Ethernet 以太网 BOOTPROTO="dhcp":IP 的获取方式,dhcp 代表通过 dhcp 协议自动获取 IP 地址,static/none 代表手动配置 IP NAME="ens33":网卡的名称,ens33 UUID="ff43010e-f68c-447c-acab-91ed72fb86de":网卡的 UUID 编号(一定是唯一的) DEVICE="ens33":设备名称 ONBOOT="yes":代表网卡开机启动,yes 代表开机启动,no 代表不启动
-
配置动态ip地址
# vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet BOOTPROTO=dhcp DEVICE=ens33 ONBOOT=yes 网卡配置完成后,重启服务 # systemctl restart network.service # ip a
-
配置静态ip地址
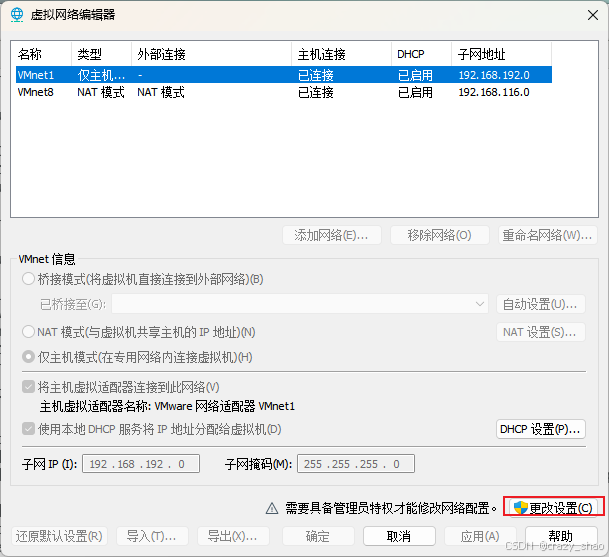
# vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet BOOTPROTO=none IPADDR=192.168.10.128 NETMASK=255.255.255.0 GATEWAY=192.168.10.254 DNS1=114.114.114.114 DNS2=8.8.8.8 DEVICE=ens33 ONBOOT=yes
这里的 GATEWAY 网卡要与你虚拟机 vmware 里保持一致
打开虚拟机,点编辑==>虚拟网络编辑器
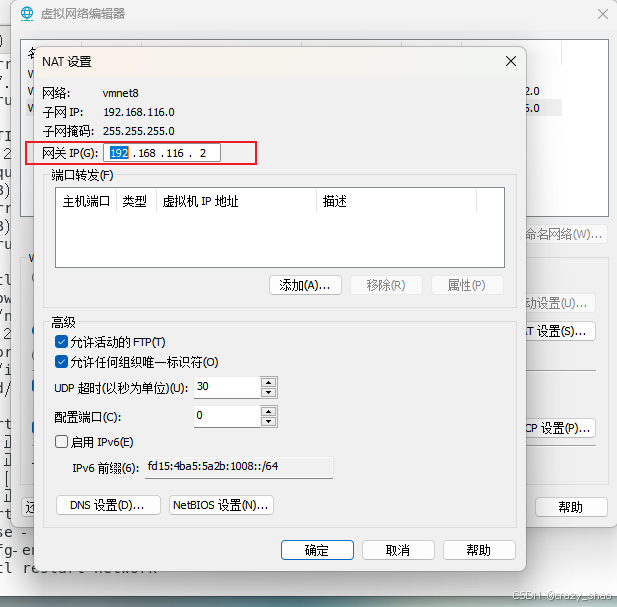
可以自行配置网段和网关,配置完成后点击确认即可。
-
网卡配置完成后重启服务
# systemctl restart network.service # ip a 注意:以上两种配置一定要配置正确不然会导致重启 network.service 不成功
-
查询计算机网络状态管理
查看网络服务状态 # systemctl status network 启动网络服务 # systemctl start network 重启网络服务 # systemctl restart network 停止网络服务 # systemctl stop network 如果在新装centos7时没有配置网卡,进入之后执行nmcli device connect ens33
3、自有服务管理
-
什么是自有服务
自有服务是一些特定的进程,一般指系统开机后就自动允许的进程,当客户向这些进程发起请求,服务器上的这些进程就会自动为客户提供服务。
-
systemctl 概述
Centos6 管理服务 命令: # service 服务名 start|stop|restart|status 例: # service sshd start # service sshd stop # service sshd restart Centos7 管理服务 命令: # systemctl start|stop|restart|status 服务名 例: # systemctl start sshd # systemctl restart sshd # systemctl stop sshd # systemctl status sshd
-
查看系统服务
# systemctl [选项] 说明: list-units --type service 列出所有的启动服务 list-units --type service --all 列出所有的服务 案例:列出所有启动的服务 #systemctl list-units --type service #systemctl list-units --type service | grep sshd 案例:列出所有的服务 #systemctl list-units --type service --all systemctl --quiet is-active --quiet:静默输出,不限显示
-
Linux管理系统
status 查看状态 基本语法: #systemctl status 系统服务的名称 案例: #systemctl status sshd 启动服务 start 基本语法: #systemctl start 系统服务的名称 #systemctl start network 停止服务 stop 基本语法: #systemctl stop 系统服务的名称 #systemctl stop sshd 重启服务 restart 基本语法: #systemctl restart 系统服务的名称 #systemctl restart sshd 热重载技术 reload #systemctl reload sshd 对于一些特殊服务,修改其配置文件后不能重启,但又需要让服务立即生效,此时可以使用 热重载技术 开机自启 #systemctl enable 系统服务的名称 #systemctl enable crond # systemctl status crond 开机不自启 #systemctl disable 系统服务的名称
4、Linux运行级别
-
什么是运行级别
running Level 。代表 Linux 系统的不同运行模式
-
Centos7 运行级别
Linux 中有七个运行级别,分别为 0~6
| 级别 | 描述 |
|---|---|
| 0 | shutdown立即关机,shutdown now |
| 1 | 单用户模式 |
| 2 | 多用户模式(没有NFS文件共享) |
| 3 | 字符模式(就是最小化模式) |
| 4 | 自定义模式 |
| 5 | 图形模式(如果在安装的时候没有选图形模式,是不能换的) |
| 6 | 重启模式 |
-
init命令
# 基本语法 # init 0 # init 1 # init 2 # init 3 # init 4 # init 5 # init 6
5、ntp时间同步服务
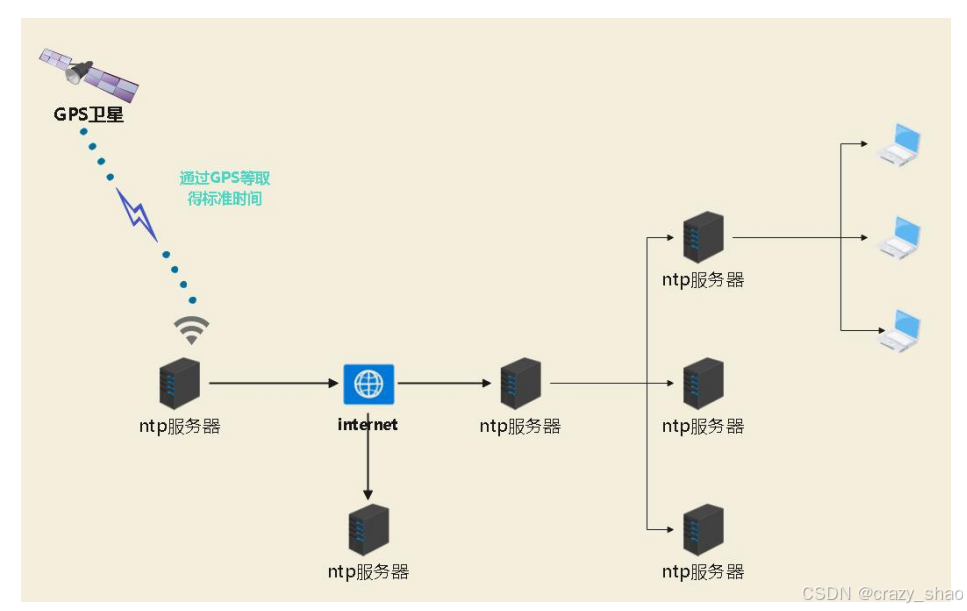
-
什么是ntp
network time protocal ,作用是用于同步各个计算机的时间的协议
-
ntp时间同步的原理
-
从哪里寻找NTP服务器
ntp授时网站:www.ntp.org.cn
-
ntp时间同步操作
# 手工操作 基本语法: ntpdate NTP服务的ip地址或域名 案例: #ntpdate cn.ntp.org.cn #ntpdate 203.107.6.88 # 自动同步 基本语法: 启动 ntpd 服务 #systemclt start ntpd 开机启动 #systemctl enabe ntpd 注意:图形化自带 ntp,最小化需要安装 yum -y install ntpdate
6、什么是软件包
一般在 windown 系统中.exe 是软件安装包
7、Linux系统下的软件包安装方式
-
RPM 软件包安装 软件名称.rpm
-
YUM 包管理工具 yum install 软件名称 -y
-
源码安装 下载源代码---编译----安装 很麻烦,稳定
8、二进制软件包
二进制包是由源码经过编译产生后的包,二进制包是 linux 系统下默认的软件安装包
Linux 有 2 大主流的二进制包管理系统:
①RPM 包管理系统 RedHat Package Manger(红帽软件包管理工具)功能强大,包括安
装、升级、卸载、查询等
②DPKG 包管理系统 主要应用在 debian 和 ubuntu 中作用类似于应用宝、豌豆荚
9、获取*.rpm 软件包
①去官网下载 rpm.pbone.net
②从镜像文件找
10、查询系统中安装的rpm
基本语法:#rpm -qa | grep 要查询的软件包名称 选项说明: -q:query 查询 -a:all,代表所有 案例: # rpm -qa |grep firefox
11、卸载centos系统中的rpm软件包
# rpm -e 软件名称 [选项] 选项说明: --nodeps:代表强制卸载 案例: 卸载 linux 系统中的火狐浏览器 ①使用 rpm -qa | grep firefox 命令查询软件包名称 #rpm -qa | grep firefox firefox-60.2.2-1.el7.centos.x86_64 ②卸载火狐浏览器 rpm -e firefox-60.2.2-1.el7.centos.x86_64
12、RPM软件包的安装
基本语法:# rpm -ivh 软件包名称.rpm 说明: -i:install安装 -v:显示进度条 -h:表示以#形式显示进度条 案例: 从光盘获取软件包 # lsblk # cd /run/media/root/CentOS\ 7\ x86_64/Packages/ # ls |grep firefox # cp firefox-91.11.0-2.el7.centos.x86_64.rpm /root/ # cd # ls # rpm -ivh firefox-91.11.0-2.el7.centos.x86_64.rpm
扩展:
lsblk是一个用于列出块设备信息的命令行工具,常用于 Linux 系统中。 一、主要功能 显示块设备列表: lsblk可以列出系统中的所有块设备,包括硬盘、固态硬盘、U 盘、光盘驱动器等。例如,在一台装有多个硬盘和一个 U 盘的计算机上运行lsblk,会显示出每个设备的名称,如sda、sdb、sdc等。 对于每个块设备,它会显示设备的类型,如磁盘(disk)、分区(part)等。这样可以让用户快速了解系统中有哪些可用于存储数据的设备。 展示设备层次结构: lsblk以树状结构显示块设备的层次关系,清晰地展示了硬盘与分区之间的关系。例如,如果一个硬盘被分成了多个分区,lsblk会显示出该硬盘以及其下的各个分区,分区通常以设备名称加上数字编号的形式表示,如sda1、sda2等。 对于一些特殊的块设备,如逻辑卷(Logical Volume,LV),lsblk也能显示其在卷组(Volume Group,VG)中的层次关系,帮助用户理解存储系统的布局。 提供设备属性信息: 除了设备名称和类型,lsblk还会显示一些重要的设备属性。例如,它会显示每个设备的大小,以方便用户了解各个存储设备的容量。比如,一个 1TB 的硬盘会显示其确切的容量大小,如 “931.5G”。 对于可移动设备,如 U 盘,lsblk可能会显示设备的挂载状态(mounted)或未挂载状态(unmounted),以及挂载点(如果已挂载)。这样用户可以快速确定哪些设备可以直接访问,哪些需要先进行挂载操作。 二、使用方法和示例 基本用法: 在终端中直接输入lsblk命令,即可列出系统中的块设备信息。例如: lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 49G 0 part / sdb 8:16 0 100G 0 disk └─sdb1 8:17 0 50G 0 part sdc 8:32 1 256M 0 rom 在这个例子中,sda、sdb是硬盘,sdc是光盘驱动器。每个硬盘下面的分区(如sda1、sda2、sdb1)显示了其与所属硬盘的关系。
13、rpm软件包升级
#rpm -Uvh 升级后的软件包名称.rpm 选项说明: -U:Update,更新操作 下载最新的软件包,使用 rpm -Uvh 包名 假设 firefox 是一个最新的包就可以用以下命令进行升级 rpm 包了 案例: # rpm -Uvh firefox-91.11.0-2.el7.centos.x86_64.rpm
14、rpm包常用选项使用
-q:查询软件包 -a:查询所有的软件包,一般和-q一起使用 -f:查询文件属于那个软件包 -l:列出已安装软件包中的文件 -e:删除已安装的软件包 --nodeps:不验证依赖关系 ① 查看系统中已安装的所有软件包 # rpm -qa # rpm -qa |wc -l ② 查看命令(二进制文件)是由哪个包安装的 # rpm -qf /usr/sbin/ifconfig 或 # rpm -qf `which ifconfig` ③ 查看已安装的软件包安装了哪些文件 # rpm -ql net-tools-2.0-0.25.20131004git.el7.x86_64 或 # rpm -ql net-tools ④ 删除已安装的软件包 # rpm -qa |grep firefox # rpm -e firefox-91.11.0-2.el7.centos.x86_64 # rpm -qa |grep firefox ⑤ rpm 包的依赖关系 # rpm -qa |grep mariadb # rpm -e mariadb-libs-5.5.68-1.el7.x86_64 ⑥ 删除 rpm 包不验依赖关系 # rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
15、源码安装
-
获取软件的源码包
可以去某个软件的官网获取,官网一般摆放的都是*.tar.gz
-
源码包安装
1) 解压不码包 tar -xvf 包名 -C 指定目录 2) 配置./configure(配置软件的安装路径,也可以不配置,不配置使用默认路径 /usr/local/以软件名称命令的目录) 3) 编译 make(将软件的源代码编译成类似于 rpm 包这种可以直接安装的软件) 4) 安装 make install (把编译好的程序进行安装到 Linux 系统) 案例: 使用源码安装 nginx 1、安装依赖包 #yum -y install zlib zlib-devel openssl openssl-devel pcre-devel #yum -y install gcc gcc-c++ autoconf automake libtool make cmake 2、下载源码 #wget http://nginx.org/download/nginx-1.22.1.tar.gz 3、解压nginx源代码 #tar -zxvf nginx/1.22.1.tar.gz 4、编译安装 #ls nginx-1.22.1 #cd nginx-1.22.1 #./configure #make #make install #cd /usr/local/nginx 5、查看nginx版本,判断软件是否安装成功 #./sbin/nginx -v nginx version: nginx/1.22.1
16、yum软件安装
-
什么是yum
yum(全称为 yellow dog updater,modifed)是在 RedHat、Centos、Fedora 等版中的shell 前端软件包管理器
安装难度:编译安装>rpm 安装>yum 安装(有网络+yum 源支持)
基于 rpm 包管理,可以从 Yum 源(指定服务器)自动下载 rpm 包并且安装,可以自动解决处理依赖关系,一次性安装所有依赖的软件包。
-
yum源配置
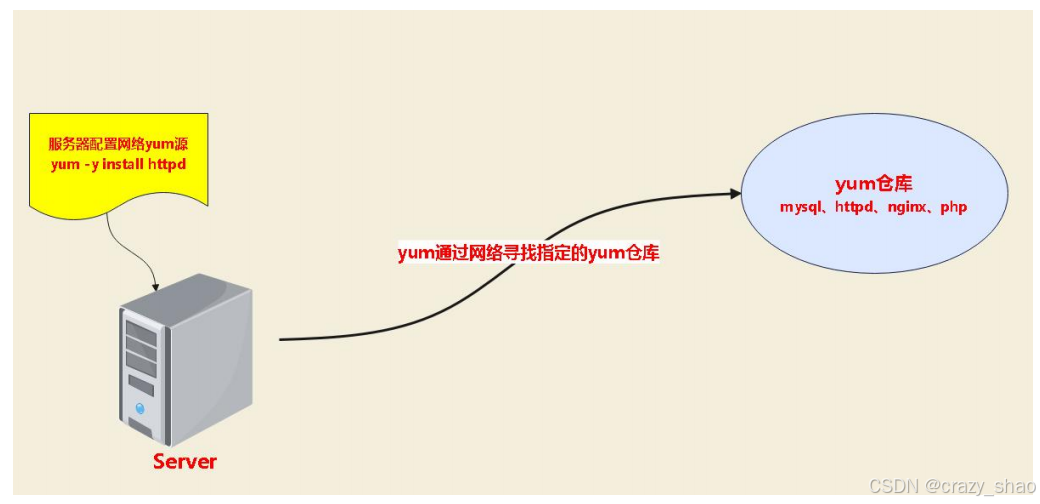
Cenos7 默认常用的 yum 源
CentOS-Base.repo 网络 yum 源配置文件
CentOS-Debuginfo.repo 内核相关的更新包
CentOS-fasttrack.repo 快速通道
CentOS-Media.repo 本地 yum 源配置文件
CentOS-Vault.repo 最近版本加入老本的 yum 配置
-
yum的主配置文件
yum的配置文件在/etc/yum.conf
# cat /etc/yum.conf
yum 配置文件解析(了解)
| 标识 | 描述 |
|---|---|
| [main] | 标签 |
| cachedir | yum下载的rpm包的缓存目录 |
| keepcache | 安装完成后是否保留软件包,0为不保留(默认),1为保留 |
| debuglevel | debug(调试)级别(0-10),默认2 |
| logfile | yum的日志文件所在的位置 |
| exactarch | 在更新的时候,是否允许被不同版本的rpm包 |
| obsoletes | 是一个 update 的参数,1 允许更新旧的 RPM 包,0 不允许。 |
| gpgcheck | 有1和0两个选择,是否进行gpg校验,以确定rpm包来源事有效和安全的,默认是0 |
| Plugins | 是否允许使用插件,默认是 0 不允许。 |
| installonly_limit | 允许保留多少个内核包 |
| bugtracker_url | 提交 bug 到指定的 url |
-
yum的子配置文件
yum 的子配置文件的路径在/etc/yum.repos.d/ 以.repo 结尾的文件 # cd /etc/yum.repos.d/
-
配置yum源
Linux 的 yum 源有两种:
一种是网络 yum 源需要连接外网才能使用
一种是本地 yum 源相当于离线的安装包仓库,不需要外网
-
配置网络yum源
步骤: 第一步: 进入阿里云的镜像官网,找到指定的网络 yum 源的下载路径,阿里云有 centos7 的常用两个镜像源,一个 epel 源,一个 centos 的基本源 阿里云的网络 yum 源 https://developer.aliyun.com/mirror/ 第二部: 下载网络 yum 源配置文件到指定的/etc/yum.repos.d/ 路径下 # wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
-
配置本地yum源
配置本地yum源注意事项:
1、必须配置本地仓库
2、yum的子配置文件必须是以.repo结尾的文件(/etc/yum.repos.d)
步骤:
第一步:准备本地仓库 将光驱挂载到指定的目录,作为本地仓库的源(光驱绑定了镜像,镜像有centos7常用的软件包)
1、创建挂目录
#mkdir /mnt/iso
2、挂载光驱到指定目录
mount 挂载源 挂载目录
#mount /dev/sr0 /mnt/iso
3、查看挂在状态
# df -h
4、设置开机挂载,并给执行权限(必须的********************************************************)
# echo "mount /dev/sr0 /mnt/iso" >> /etc/rc.d/rc.local
# chmod a+x /etc/rc.d/rc.local
第二步: 配置本地yum源的配置文件
# cat > /etc/yum.repos.d/iso.repo << EOF
[iso] 仓库标识
name=centos7 仓库名称
baseurl=file:///mnt/iso 指定一个固定的网络源,只能从该网络源下载安装rpm包
enabled=1 是否使用该yum源,1表示启用,0表示不启用
gpgcheck=0 是否执行gpg校验,1表示执行,0表示不执行
EOF
gpgkey=url 是定执行gpg校验的时候,需要使用key密钥文件
注意:
baseurl=file://挂载点目录绝对路径 设置本地 yum 源
baseurl=http://url 设置网络 yum 源
第三步:备份原有的yum子配置文件
# mkdir /etc/yum.repos.d/bak
# mv /etc/yum.repos.d/CentOS-* /etc/yum.repos.d/bak/
# ls /etc/yum.repos.d/
第四步:清理yum源,并建立元数据缓存
# yum clean all
# yum makecache fast
第五步:验证仓库
# yum repolist
看到以上仓库标识,仓库名称,及状态,且状态不为 0(仓库中软件包的数量为 4070 个)
表示配置成功,如果为 0 则有问题!
仓库状态为 0 可能原因:
仓库中是否有软件包
检查挂载点是否成功被挂载 df -h
配置文件未配置正确,检查配置文件,特别注意 baseurl=file:// 后面跟挂载点的绝对
路径
17、本地yum源卸载
删除子配置文件 # rm -rf /etc/yum.repos.d/iso.repo 卸载挂载点 命令:umont 挂载点或挂载源 # umount /dev/sr0 或 # umount /mnt/iso 注意:卸载时当前目录不能在/mnt/iso 目录中,否则执行 umount 命令会报错 查看挂载状态 # df -h 修改/etc/rc.d/rc.local vim /etc/rc.d/rc.local 将mount /dev/sr0 /mnt/iso 此行删除后wq保存
18、yum命令使用
-
安装软件包
语法: yum [选项] 包名 -y:直接安装不提示 案例 1: # yum install wget # yum -y install firefox 案例 2: # yum -y install mariadb* 安装所有以 mariadb 开头的软件包
-
覆盖安装的软件包
语法: yum reinstall 软件名 案例: # yum reinstall wget -y
-
查看命令是由那个软件包提供的
语法: # yum provides 二进制可执行文件(命令名) 案例 1: # yum provides cat 案例 2: # yum provides `which cat` 找到包名后就可以安装了 # yum -y install coreutils-8.22-24.el7_9.2.x86_64
-
搜索软件包
在仓库搜索软件包 语法: yum search 包名 案例 1: # yum search ifconfig 案例 2: # yum search chmod # yum provides chmod # yum search coreutils
-
删除软件包
语法: # yum remove 包名 案例: # yum -y remove net-tools
19、yum常用命令
| 命令 | 描述 |
|---|---|
| yum check-update | 检查可升级的rpm软件包 |
| yum upgrade | 升级所有可以升级的rpm软件包 |
| yum update | update事过时命令,会保留旧包 |
| yum update <group_name> | 仅升级指定的软件包组 |
| yum update kernel kernel-source | 升级指定的 rpm 包,如升级内核和内核源 |
| yum groupdate <group_name> | 升级组里面所有的软件包 |
| yum downgrade <group_name> | 软件包降级 |
| yum searceh <keyword> | 搜索匹配特定字符的 rpm 包 |
| yum list | 列出仓库中所有可以安装或更新的 rpm 包 |
| yum list updates | 列出仓库中所有可以安装或更新的 rpm 包 |
| yum list installed | 列出所有安装的 rpm 包 |
| yum list extras | 列出所有已经安装但是不在仓库的包 |
| yum list <package_name> | 列出指定的软件包 |
| yum deplist <package_name> | 查看程序的依赖情况 |
| yum info | 列出仓库中所有可以安装或更新的 rpm 包信 |
| yum info <pacakage_name> | 获取软件包的信息 |
| yum info updates | 列出仓库中所有可以更新的 rpm 包的信息 |
| yum info installed | 列出所有已经安装的软件包信息 |
| yum info extras | 列出所有安装但不在仓库中的软件包的信息 |
| yum provides <file_name> | 列出命令是由哪个包安装的 |
| yum grouplist | 列出所有软件包组 |
| yum groupinfo <group_name> | 显示组信息 |
| yum makecache | 更新本地缓存,常用 yum clean all |
| yum clean all | 清空 yum 源 |
| yum history list | 列出历史命令(包括 ID、命令、日期和时间、操作) |
| yum history list start_id..end_id | 列出 yum 某个区间看到历史命令,例如:yumhistory list 1..6 |
| yum history undo id | 恢复到 ID 所表示的 yum 命令执行前的状态 |
| yum history redo id | 再次执行 ID 所表示的 yum 命令 |
20、自建yum本地仓库
步骤:
-
第一步:
创建私有仓库目录
# mkdir /repo
-
第二步:
将rpm包同步到私有仓库目录(/repo)中
使用reposync命令将本地配置好的yum源的软件包同步到指定的目录中,图形化默认安装reposync命令,最小化安装yum -y install yum-utils
语法: reposync 选项 -r:指定本地已经配置的yum仓库的repo源名称 -p:指定下载的路径 案例: # reposync -r iso -p /repo # ls # ls Packages/
-
第三步:
将/repo制作为本地仓库
使用createrepo命令将指定目录制作成本地仓库,图形化默认安装,最小化需手动安装yum -y install createrepo
基本语法: createrepo 目录名 案例: # creatrepo /repo/
-
第四步:
配置子配置文件
# cat > /etc/yum.repos.d/local.repo << EOF >[local_iso] >name=local_centos7 >baseurl=file:///repo >gpgcheck=0 >enabled=1 >EOF # ls /etc/yum.repos.d/
-
第五步:
清空yum源
# yum clean all
-
第六步:
验证仓库
#yum repolist
第四节 进程管理
1、进程概述
-
什么是进程
进程就是一个运行中的程序,一个进程就是一个程序文件的 runtime 运行时。系统以进程为单位,来分配内存空间,每一个进程独享自己内存空间,彼此之间隔离,互不影响。一个程序的多进程运行方式,可以提高程序功能的并发性。
系统是以进程为单位,来分配一个独立的 “内存空间”!内存空间中,存放着系统分配给该进程的相关资源。
比如:一辆车想要跑起来,需要有加油站为其提供“资源”,这份资源就是汽油,而汽油需要一个油箱,来作为承载、容纳它的地方,这个油箱就是内存空间。
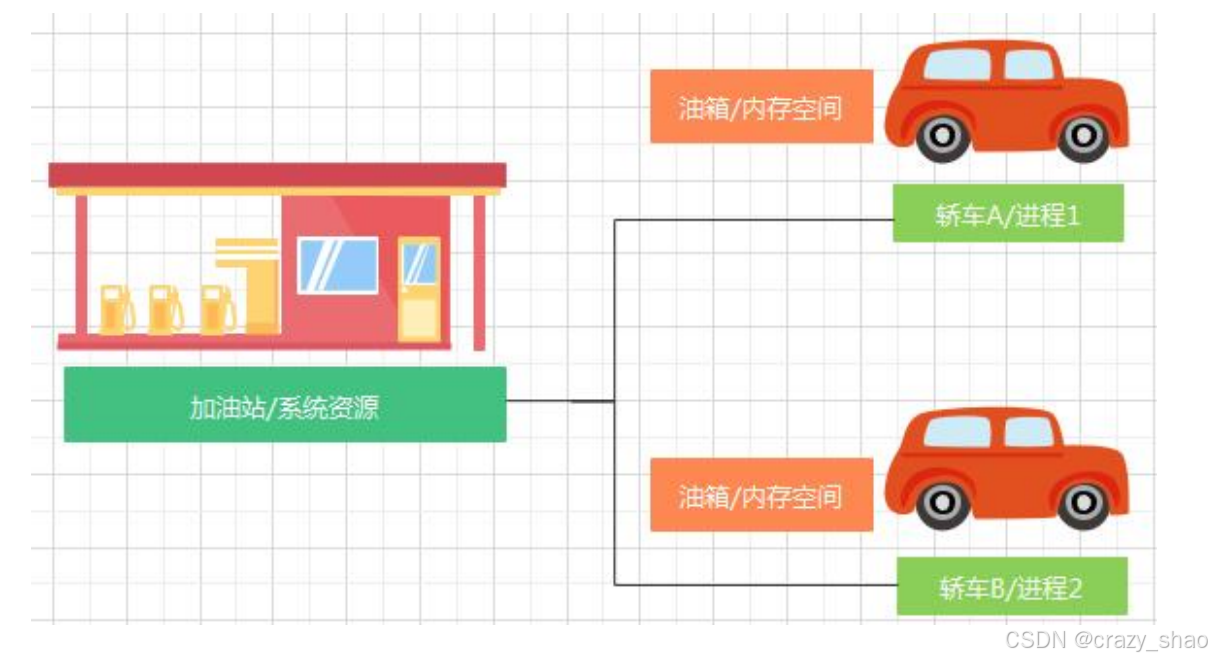
依据上图:
我们考虑一个问题,如果轿车 A 和轿车 B 同时上路,半途当中,轿车 A 因为自身的因素出现了故障,导致无法继续行驶,那么轿车 B 会一同出现故障码?答案是显而易见的。不会!因为两辆轿车,是独立的个体,所以当 A 出现问题后,B 仍然可以正常行驶……
如果一个系统同时有多个进程(这是必然的情况),我们又该如何进行区分呢?
在上图中,我们用轿车 A、轿车 B 来暂时代称,但是在现实当中,不同的车辆之间同样有区分的办法,那就是分发、标注独一无二的车牌号!而在进程当中,我们则以“进程号/PID”来对不同的进程进行区分。
总结一下进程的特点:
1、拥有唯一的PID进程编号,它是一个namespace名称空间,系统通过PID进程编号来区分并管理各个进程;
2、拥有属于自己的独享的内存空间,系统是以进程为最近本的对象来分配内存资源;
3、进程之间彼此隔离,互不影响;
4、一个程序可以创建一个或多个进程,一个进程可以服务于一个或多个程序
5、了解进程的权限
a、每个进程都会有一个运行用户账户和一个运行组账户
b、进程通过自己的运行用户账户和运行组账户来获取相应的权限
-
什么是线程
线程是一个进程可向 CPU 提交并执行的最大程序代码段,它是 CPU 可处理的最基本的代码处理单元。线程的意义:在单 CPU 架构中,单个 CPU 也或许无法一次性执行全部的进程代码,因此需要将进程代码分解为线程来分片执行;在多 CPU 架构中,多线程的程序编程设计,可以充分利用多 CPU 的并发处理能力,从而提高程序的运作性能。
所以,线程可以理解成是进程的下一级单位,但线程本身并不独立于进程,而是由进程本身的资源,所分解、延伸出来的存在。
在这里,最难以理解的一点,是线程隶属于进程,并且会共享所属进程的资源,如果把一个进程比喻成一个独立的人,那么线程就像是这个人延伸出去的手脚。所以当一个线程出现问题的时候,所属的进程就有可能会出问题,进而影响到相关的线程……
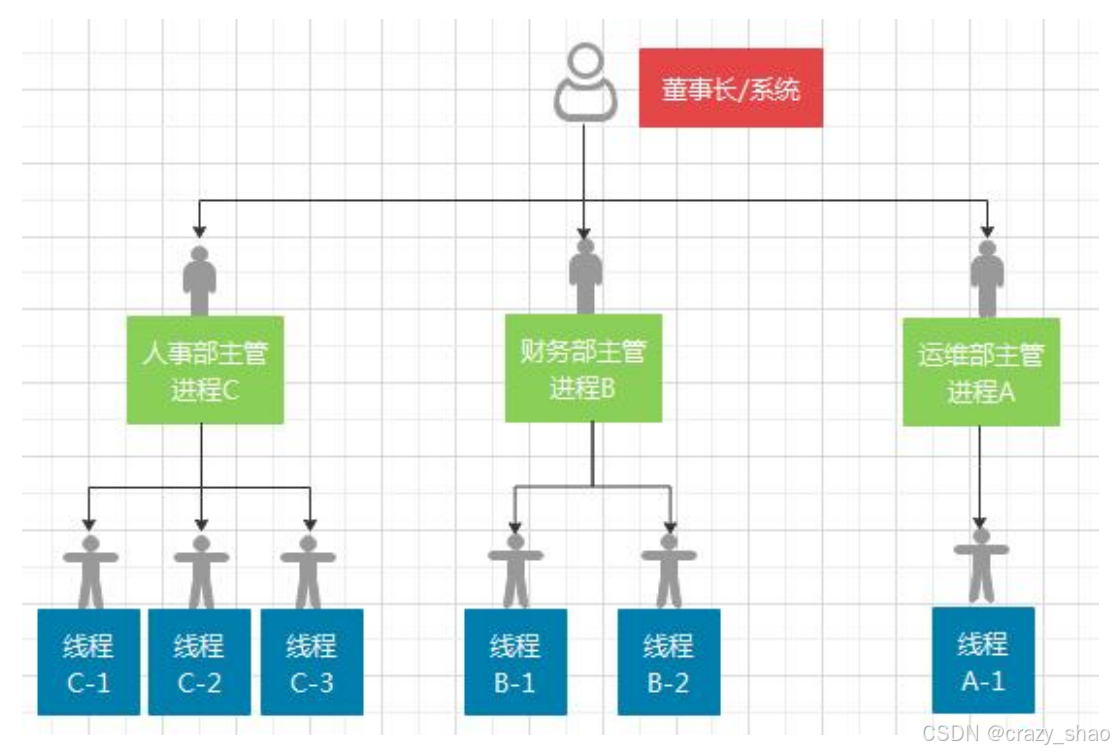
如上图:
如果 B-1 线程出现了问题,那么就有可能导致进程 B 整个出现问题,进而导致 B-2 线程也出现问题。
如果 B-1 线程出现了问题,是不会影响到 A-1 线程或是 C-1 等线程的,因为进程之间都是独立的!
总结线程的特点:
1、拥有唯一的LWP线程编号;
2、一个进程最少拥有一个线程,也可以拥有多个线程
3、一个进程中的多个线程,只能共享争用进程自身额拥有的内存空间,不会另行获取独享的内存空间。
4、一个进程中的线程之间,彼此不隔离,会相互影响。
-
进程的其他相关概念
1)了解父子进程
进程之父:PID=1 的进程,就是所有其他进程的父进程,CentOS_7.x 系统中的进程之父是systemd 进程。父子进程概述:一个程序至少产生一个进程,一个大程序会产生一个主进程,即父进程,然后产生多个子进程,从而可以获取更多的独立的内存空间。父进程衍生出来的子进程,在没有另外指定运行账户的情况下,均会继承父进程的权限。子进程可以继承父进程的可继承的数据,反之则不然。
查看父子进程:
# yum install -y httpd 安装:一个应用服务程序
# systemctl start httpd 运行:一个应用服务程序
# ps -efL | awk 'NR==1 || /httpd/{print}'
2)孤儿进程
什么是孤儿进程:
孤儿进程就是没有父进程的进程,孤儿进程并不会有什么危害,每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为 init(1)进程或 systemd(1)进程,init(1)进程或systemd(1)进程就好像是一个孤儿院,处理一切善后工作。
3)僵尸进程
僵尸进程是进程在关闭过程中的一种中间状态,类似于:在停尸间等待火化!所有子进程在关闭之后,均会成为僵尸进程,然后等待父进程来处理,最终释放子进程 PID,如果父进程妥善处理了,就一切正常,最终释放子进程 PID。
是否有危害性:
如果父进程因为各种原因未能妥善处理,则会留下僵尸进程,从而耗费有限的 PID 标识符资源
如何发现:僵尸进程?
一个正常运行的系统,僵尸进程的停留时间通常不会很长,因此不会看见!
查看:僵尸进程 [进程状态值 = Z] 的就是 僵尸进程

2、进程管理命令
-
ps命令
ps 是显示瞬间进程的状态。静态的查看系统当中进程的信息。 语法: ps [基本选项] [列表选择选项] [输出格式选项] [显示线程选项] [杂项选项] 基本选项: -A:所有的进程均显示出来,与-e具有相同的效果 -f:输出全格式(默认包含:UID、PID、PPID、C、STIME、TTY、TIME、CMD -a:显示现行终端机下的所有进程,包括其他用户的进程 -u:以用户为主的进程状态 x: 通常与a这个参数一起使用,可列出较完整信息 L:列出所有字段名称 -o|o| --format<format>:指定输出的字段 -C:指定要查找的进程名称 例如:-C nginx:指定要查找的进程名称为 “nginx”。这将筛选出所有名称为 “nginx” 的进程。
了解重要字段含义
列出所有的字段名称:ps L # ps L
| 关键字 | 描述 |
|---|---|
| USER | 进程的运行用户 |
| TTY | 进程的终端(切换终端的快捷键 ctrl+Alt+F1~F6,用 tty 命令查看当前终端号)TTY 为“?”时,表示不依赖任何终端运行 |
| SID | 会话ID |
| PGID | 进程组ID |
| PID | 进程ID |
| PPID | 父进程ID |
| %CPU | cpu的占用率 |
| %MEM | 内存的占用率 |
| VSZ | 允许进程访问 的虚拟内存大小,单位kb包含了:swap 空间占用 |
| RSS | 进程在内存的实际占用大小单位 KB ,包含了:可共享内存,不包含:swap 空间占用 |
| STAT,S | 进程的状态 |
| TIME | 进程运行的时长 |
| COMMAND,AMD | 进程运行的命令 |
| WCHAN | 显示进程正在等待的内核事件名称,正在运行中的进程将显示一个[ - 破折号 ] |
| PRI | 进程优先级的当前有效值,数值越大,优先级越高,动态变化范围是: 0 ~ 139 |
| NI | 进程优先级的用户调整值,数值越大,优先级越低,手动调整范围是:-20 ~ 19 |
ps命令实列
-A:显示所有进程 # ps -A -u:显示指定用户相关进程 # ps -u root -ef : 显示进程,及其父进程的信息 # ps -ef -aux:常用组合 # ps aux 或 ps -aux -o 显示指定的进程字段 # ps -A -o user,pid,ppid,%cpu,%mem,stat,pri,ni,cmd 进程 STAT 状态 # man ps < 高优先级(对其他用户不好) N 低优先级(对其他用户很好) L 已将页面锁定到内存中(用于实时和自定义 IO) s 是会话领导者 l 是多线程的(使用 CLONE_THREAD,就像 NPTL pthreads 一样) + 在前台进程组中
-
top命令
top 命令周期性自动捕获进程的运行时信息。动态查看进程信息!
# top 重要: -d:指定每两次屏幕刷新之间的时间间隔 -p:通过指定监控进程ID来仅仅监控某个进程的状态 -c:显示整个命令行(包括命令参数),而不只是显示命令 -b:批量模式执行,用来将输出重定向到指定文件,一般配合-n指定输出几次统计信息 -n:表示更新n次后终止更新,选项后跟一个整数。 -u:显示指定用户 -U:显示指定UID的进程 了解: -S 指定累计模式,每个进程的 CPU 时间为该进程及关闭的子进程所累加的时间 -s 使 top 命令在安全模式中运行。这将去除交互命令所带来的潜在危险 -i 使 top 不显示任何闲置或者僵尸进程
top命令所展示字段的含义
| 字段 | 描述 |
|---|---|
| PID | 进程id |
| USER | 进程所有者的有效用户名 |
| PR | 优先级 |
| NI | 优先级调整值(即nice值),值越小,优先级越高 |
| VIRT | 进程使用的虚拟内存总量,单位kbtye,VIRT=SWAP+RES |
| RES | 进程使用的未被换出的物理内存大小,单位Kbtye,RES=CODE+DATA |
| SHR | 共享内存 |
| S | 睡眠状态,各种进程(状态标识符)D= 不可中断的睡眠状态 R= 运行,S=睡眠,T=跟踪/停止,Z=僵尸进程 |
| %CPU | 上次更新到现在的CPU占用百分比 |
| %MEM | 进程使用的物理内存百分比 |
| TIME+ | 进程使用的cpu时间总计,单位1/100秒 |
| COMMAND | 命令名/命令行 |
top 命令前五行输出重点信息详解:
1)load average 平均负载率

过去 1、5、15 分钟的 cpu 负载,与 CPU 核心数相关,1 核 平均负载小于 1 正常,2 核 平均负载小于 2 正常,3 核小于 3 正常。以此类推,值越大表示 CPU 负载越重,一般最好不要超过 CPU 负载的 80%。
2) 任务(进程)

显示:任务总数 184 个,1 个正在运行的进程,183 个睡眠进程,0 个停止进程,0 个僵尸进程。
3) CPU 状态

3.1 us 用户空间占用 CPU 百分比
6.6 sy 内核空间占用 CPU 百分比
0.0 ni 用户进程空间内改变过优先级的进程占用 CPU 百分比
89.0 id 空闲 CPU 百分比
0.0 wa 等待输入输出的 CPU 时间百分比
0.0 hi 硬件 CPU 中断占用百分比
0.5 si 软中断占用百分比
0.0 st 虚拟机占用百分比
4) 物理内存状态

5989132 total 物理内存总量=free+used+buff/cache
4943092 free 空闲内存总量
563872 used 使用的物理内存总量
482168 buff/cache 用于内核缓存的内存量
5) SWAP 交互分区状态

2097148 total 交换分区总量
2097148 free 空闲交换分区总量
0 used 使用的交换分区总量
5159496 avail Mem 可用的物理内存(包含:MemFree 和可回收的已用内存)
top运行中界面中,按钮功能(区分大小写)
着重记: 1: 显示所有CPU占用情况 P: 以CPU占用率大小的顺排列表示进程列表 M: 以内存占用率大小的顺序排列进程列表 h: 显示帮助 n: 设置在进程列表所显示进程的数量 q: 退出top 了解 s 改变画面更新频率 l 关闭或开启第一行 top 信息的表示 t 关闭或开启第二行 Tasks 和第三行 Cpus 信息的表示 m 关闭或开启第四行 Mem 和 第五行 Swap 信息的表示 N 以 PID 的大小的顺序排列表示进程列表 b 打开/关闭加亮效果 案例 1: 每隔 5 秒,捕获一次进程信息。 # top -d 5 案例 2: 捕获 1 次进程信息,并将捕获信息保存到指定文件中 # top n 1 -b > /tmp/top.txt 案例 3: 捕获进程信息,并显示命令的详细参数 # top -c 案例 4: 捕获指定用户的进程信息 # top -u root 案例 5: 捕获指定进程号(一个获多个)的进程信息 # top -p 1 # top -p 1,2,3,4
-
netstat和ss命令
1)netstat命令
netstat 命令的功能:显示网络连接、路由表、接口统计信息、伪装连接和多播成员。注意: 图形化的服务默认是安装了 net-tools 软件包的,最小化是没有安装的 # yum -y install net-tools
常用方式: # netstat -r # 显示:本机路由表 # netstat -tunp # 显示:网络连接,即:socket 网络套接字 # netstat -tunlp # 显示:侦听端口,即:socket 网络套接字 -t:tcp -u:UDP -n:解析本机地址加端口 -l:监听 tup和unp要组合用
2)ss命令
ss 命令的优势:
优势 1:相比 netstat 命令,ss 命令可以获取更多的 TCP/UDP 状态信息
优势 2:相比 netstat 命令,ss 命令更加高效
因为 netstat 命令直接[cat /proc/net/tcp],因此,执行速度会很慢,如果遇到上万个连接,netstat 命令等于浪费生命。 ss 命令利用到了 TCP 协议栈中 tcp_diag。tcp_diag是一个用于分析统计的模块,可以获得 Linux 内核中第一手的信息,因此 ss 命令的性能会好很多。
常用方式: # ss -tunp 显示:网络连接,即:socket 网络套接字 # ss -H -tunp 显示:网络连接,即:socket 网络套接字,不显示标题行 注意:更新之后 iproute 软件包,才支持 -H 选项 # ss -tunlp 显示:侦听端口,即:socket 网络套接字 # ss -H -tunlp 显示:侦听端口,即:socket 网络套接字,不显示标题行 注意:更新之后 iproute 软件包,才支持 -H 选项
-
lsof命令列出进程打开的文件
安装:yum install -y lsof 功能:列出进程打开的文件 常用方式举例: 01. 列出:所有活动的进程所打开的文件 # lsof 02. 列出:以 user01 用户身份运行的进程所打开的文件 # lsof -u user01 03. 列出:指定 PID 进程号的进程所打开的文件……以进程号 8533 为例 # lsof -p 8533 04. 列出:执行指定命令的进程所打开的文件 # lsof -c vim 05. 列出:指定 port 端口的进程信息 # lsof -i:22 输出字段解释: COMMAND: 进程的名称 PID: 进程标识符 PPID: 父进程标识符(需要指定-R 参数) USER: 进程所有者 FD: 文件描述符,应用程序通过文件描述符识别该文件 TYPE: 与文件关联结点的类型; DEVICE: 设备号 SIZE/OFF: 文件大小/偏移量,以字节为单位 NODE: 文件节点 NAME: 文件挂载点和文件所在的系统 FD 文件描述符类型列表: cwd: 当前目录 txt: 程序文本,如应用程序二进制文件或共享库 Lnn: 库引用 library references (AIX) err: 文件描述符信息错误 jld: jail 目录(FreeBSD) ltx: 共享库文本(代码和数据) mxx: 十六进制内存映射类型编号 xx m86: DOS 合并映射文件 mem: 内存映射文件 mmap: 内存映射设备 pd: 父目录 rtd: 根目录 tr: 内核跟踪文件(OpenBSD) v86: VP/ix 映射文件 0: 标准输入 1: 标准输出 2: 标准错误
-
free命令查看内存的使用情况
作用:显示计算机的内存使用情况 基本语法: #free [选项] 选项: -m:以 MB 的形式显示内存大小 -g:以 GB 的形式显示内存大小 -h: 以人性化可读的方式显示内存大小 案例: #free #free -m #free -g
-
df命令查看磁盘的剩余空间
作用:显示磁盘剩余空间的大小 基本语法: #df [选项] -h: 以较高的可读性显示磁盘剩余空间的大小 -i: 显示 inode 信息而非块使用量和-h 一起使用 -T: 显示文件系统类型和-h 一起使用 案例: # df -ih # df -Th # df -h
3、进程的状态
linux 是一个多用户,多任务的系统,可以同时运行多个用户的多个程序,就必然会产生很多的进程,一个 CPU 不可能同时处理多个进程,因而每个进程会有不同的状态。接下来我们重点介绍几种常见的进程状态。
-
R状态:运行状态
R 状态表示:正在 CPU 上运行或者进入 CPU 可执行队列的进程。 # ps a -o user,cmd,stat
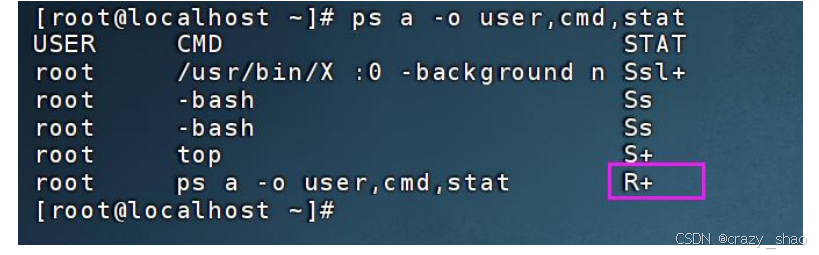
a 显示具有终端 (tty)的所有进程,或与 x 选项一起使用时显示所有进程
-
S状态:可中断唤醒的睡眠状态
S(大写)状态 表示:可以被唤醒的睡眠进程, 当前尚未进入 CUP 运行队列
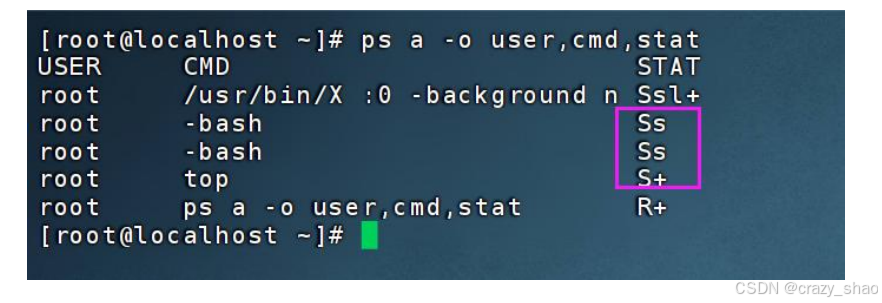
-
D状态:不可中断唤醒的睡眠状态
在进程与某些硬件进行交互时,可能需要处于不可中断唤醒的睡眠状态,从而避免交互过程被打断,防止设备陷入不可控的状态,这种不可中断唤醒的睡眠状态总是非常短暂,因此,基本上不可能捕捉到不可中断唤醒的睡眠状态。
-
T状态:被控制信号停止(Ctrl+z)暂停进程
我们可以 Ctrl+z 暂停一个前台进程,如果之后需要继续运行,则可以使用 jobs 和 fg来恢复运行。类似于缩放到后台,避免影响此刻需要做的其他操作。
查看:进程的 T 暂停状态 # ps -A -o user,pid,ppid,stat |grep "T" 查看:与当前会话关联的后台进程 # jobs -l 恢复运行:编号为 1 的后台进程 # fg 1
-
其他状态
t 在跟踪期间,被调试器停止
X 表示: 死了(应该是永远看不到此状态值的)
Z 表示: 僵尸状态,进程已终止,但未被父进程回收
< 高优先级
N 低优先级
L 有些页被锁进内存
S 包含子进程
+ 位于前台的进程组
l 多线程
4、进程的基本管理
控制进程前台、后台运行
ctrl + z 将正在执行的任务暂停放入后台
jobs -l 查看后台任务
fg 任务编号 将任务调回前台
bg 任务编号 在后台继续运行任务
-
进程调度
1)暂停进程
使用 ctrl + z 将正在执行的任务暂停放入后台 # vim 1.txt
2)查看后台进程
# jobs # jobs -l [root@localhost ~]# jobs [1]+ 已暂停 vim 1.txt [root@localhost ~]# jobs -l [1]+ 16957 已暂停 vim 1.txt [1] + 进程号 16957 进程 pid 停止 进程状态 vim 1.txt 进程名 -l 显示进程的 pid
3)后台进程调度到前台
将进程放入后台运行 使用 & 符将进程放入后台运行 # ping 127.0.0.1 > /tmp/ping.txt & # jobs -l # fg 1 使用 ctrl + z 将进程放入后台暂停 将后台暂停的进程激活 # bg 1 # jobs -l
注意:以上打开进程后不管是放入后台还是放在前台,关闭终端进程关闭
4)将进程放入后台运行并脱离终端
语法: nohup 命令 & 功能:nohup 故名思议就是忽略 SIGHUP 信号,确保:运行中的后台作业,一律不接收当前会话的 leader 领导进程发来的 SIGHUP 信号。一般搭配&一起使用,方可不占用控制终端的标准(错误)输出,而是直接输出到 nohup.out 文件中。&表示以后台进程组来运行一个进程组。 # cd /tmp/ # nohup ping 127.0.0.1 另开终端 # ls # tail -f nohup.out 按 ctrl + c 结束进程 # nohup ping 127.0.0.1 > /tmp/ping.txt & # jobs -l 关闭终端进程仍然在后台运行
-
进程的控制
可以通过信号通知进程执行指定的动作!
SIGNAL 信号概述
了解 SIGNAL 信号机制:进程间通信的一种通信内容,signal 信号全称为软中断。 注意,信号只是用来通知某个进程发生了什么事件,并不给该进程传递任何数据。由进程根据收到的信号来判断需要执行的动作。
SIGNAL 信号种类
| 信号 | 值 | 描述 |
|---|---|---|
| SIGKILL | 9, KILL | 强制立即终止进程 |
| SIGTERM | 15, TERM | 正常关闭进程 |
| SIGHUP | 1, HUP | 终端挂起信号,通常用于通知进程重新加载配置文件或重新启动 |
| SIGSTOP | 19,STOP | 停止信号,暂停进程的执行 |
| SIGCONT | 18, CONT | 继续信号,恢复被暂停的进程的执行 |
| SIGINT | 2, INT | 终端中断信号,通常由 Ctrl+C 键触发,用于中断正在运行的进程 |
| SIGQUIT | 3, QUIT | 不同于 SIGINT,这个是会产生 core dump 文件的。 进程终止并且产生 core 文件 |
| SIGUSR2 | 12, USR2 | 用户自定义信号 进程终止 |
| SIGUSR1 | 10, USR1 | 用户自定义信号 进程终止 |
| SIGWINCH | 28, WIHCH | 当控制终端窗口大小变化时,SIGWINCH 信号发送到进程 |
-
kill命令
通过进程 ID 发送信号通知进程执行对应动作 基本语法: kill 选项 进程 ID 常用选项 -l 列出信号名称 -n SIG 是信号编号 -s SIG 是信号名称 信号编号含义 9 杀死进程,强制结束进程 15 正常结束进程,是 kill 命令的默认信息 案例 1: 查看信号 # kill -l 案例 2: 正常关闭进程 # ping 127.0.0.1 另开终端 # ps -ef |grep ping # kill -n 15 26531 或 # kill -15 26531
-
pkill命令
通过信号并以进程名称通知进程执行指定的动作 基本语法: #pkill [options] <pattern> 案例: 针对进程名称所对应的进程 PID 发送信号编号,来强制终止进程 # pkill -9 httpd 针对 PID 进程文件中的进程 PID,发送信号名称,来强制终止进程 # pkill -KILL -F /run/httpd/httpd.pid
-
killall命令
杀死所有同名的进程 基本语法: #killall [信号编号] 进程名称 案例: 安装包含 killall 命令的工具包 # yum install -y psmisc 杀死指定名称的进程 # killall httpd 杀死指定名称的进程组 # killall -g httpd 发送 HUP 重载信号,重载指定名称的进程 # killall -s Hup httpd 发送 HUP 重载信号,重载指定名称的进程组 # killall -s Hup -g httpd
5、进程优先级
-
什么是进程优先级
Linux 是一个多用户、多任务的操作系统,系统中通常运行着非常多的进程。哪些进程优先运行,哪些进程后运行,就由进程优先级来控制。
什么时候使用到进程的优先级?
当负载过高时,如 cpu 的使用率>=90%以上。这个时候进程的优先级就会起作用
-
查看进程的优先级
PR 优先级 ,数值越小优先级越高
NI 优先级,数值越小优先级越高。可以认为更改。
NICE = 绅士 NICE 值越高 代表这个人越绅士
NI 值范围:-20~19
-
调整进程的优先级
1)使用top调整进程的优先级
第一步:使用命令获取到到你要调整的进程信息 #ps -ef | grep crond 第二步:运行 top 命令,然后按“r",输入要调整进程的 PID 编号 #top 按 r,输入要调整的进程的 PID 编号,按回车 PID to renice [default pid = 30037] 1220 第三步:根据提示,充值 NICE 值 Renice PID 1220 to value -5 第四步:按 q 退出 top 模式,然后使用 top -p PID 编号,只查询某个进程的信息 #top -p1220
2)使用renice命令调整进程的优先级
基本语法: #renice [NI 优先级设置的数组] 想调整的进程 ID 案例:使用 renice 调整 crond 的优先级 第一步:获取服务的 PID #ps -ef | grep crond 第二步:使用 renice 命令调整 1220 的 NICE 值 #renice -10 1220
3)使用nice命令调整进程的优先级
基本语法: #nice [NI 优先级设置的数字] 想调整的进程名称 nice 命令只能调整没有运行的程序(***********************************) 第一步:将程序停止,如 crond 服务 #kill PID 或 #systemctl stop crond 第二步:启动并制定优先级 #nice -n -15 crond 注意:nice 除了调整进程的优先级外,还可以启动进程 第三步:确认优先级 # ps -ef | grep crond # top -p 1934
第五节 磁盘管理
某天接到短信报警提示,显示某主机的根分区空间使用率超过 85%,该主机用于影评(mysql)和报表数据库(oracle)。经查看发现其中 MySQL 数据库的数据文件存放在/usr/local/mysql/中,占用根文件系统空间导致。由于前期规划不合理,没有将业务数据和系统数据分开。经研究决定,要将影评的数据库单独放到另一块磁盘上,并且实现逻辑卷管理。
任务要求
1)保证数据库完整的情况下将影评数据库迁移到另外一块新添加的磁盘上
2)考虑到数据增长情况,新磁盘使用 lvm 逻辑卷管理,方便日后动态扩容
任务拆解
-
需要有一块可用硬盘(需要在虚拟机里增加一块硬盘)
-
使用 lvm 方式管理磁盘(学习 lvm 相关的知识点)
-
迁移数据库(MySQL)业务维护时间(23:00—)
1>停监控(根据情况)
2>停前端应用
3>停 MySQL 数据库
4>备份数据库(全备)
5>将原有的数据库同步到新的设备存储上(数据同步 rsync)
6>启动数据库(保证没有问题)
7>启动前端应用
8>测试人员测试
9>开门营业(记得打开监控)
从以上案例中可以看到,服务器的磁盘空间可用性,影响着整个业务的正常运行,需要做到的是如何保证磁盘空间的可用性,和申缩性是一个很大的考验,因此需要对磁盘进行合的安排和管理。
1、磁盘的基础知识
-
磁盘的接口类型
个人电脑版,硬盘接口分为 IDE 类型和 SATA 类型
IDE 类型

SATA 类型

服务器版,硬盘接口分为 SCSI 类型和 SAS 类型
SCSI 类型

SAS 类型

-
磁盘的命名方式
windows 中硬盘的命名方式一般为 C 盘、D 盘、E 盘 ......
而 linux中硬盘的命名方式为
| 系统 | IDE并口 | SATA串口 | SCSI接口 |
|---|---|---|---|
| RHEL5 | /dev/hda、/dev/hdb | /dev/sda、/dev/sdb | /dev/sda、/dev/sdb |
| RHEL6 | /dev/sda、/dev/sdb | /dev/sda、/dev/sdb | /dev/sda、/dev/sdb |
| RHEL7 | /dev/sda、/dev/sdb | /dev/sda、/dev/sdb | /dev/sda、/dev/sdb |
-
磁盘设备的命名
如:/dev/sda2
s=硬件接口类型(sata/scsi),d=disk(硬盘),a=第1块硬盘(b,第二块),2=第几个分区 /dev/hd h=IDE硬盘/dev/hdd3 /dev/vd v=虚拟硬盘 /dev/vdf7
-
磁盘的分区方式
MBR <2TB fdisk 4个主分区或者3个主分区+1个扩展分区(N个逻辑分区)
MBR(Master Boot Record)的缩写,由三部分组成,即:
1)Bootloader(主引导程序)=446字节 硬盘第一个扇区=512字节引导操作系统的主程序。
2)DPT分区表(Disk Partition Table)=64字节分区表保存了硬盘的分区信息,操作系统通过读取分区表内的信息,就能够获得该硬盘的分区信息每个分区需要占用16个字节大小,保存有文件系统标识、起止柱面号、磁头号、扇区号、起始扇区位置(4个字节)、分区总扇区数目(4个字节)等内容分区表中保存的分区信息都是主分区与扩展分区的分区信息,扩展分区不能直接使用,需要在扩展分区内划分一个或多个逻辑分区后才能使用逻辑分区的分区信息保存在扩展分区内而不是保存在MBR分区表内,这样,就可以突破MBR分区表只能保存4个分区的限制。
3) 硬盘有效标志(校验位)=2个字节
GPT >2TB gdisk(parted) 128个主分区
*注意*:从MBR转到GPT,或从GPT转换到MBR会导致数据全部丢失!
-
磁盘的工作原理

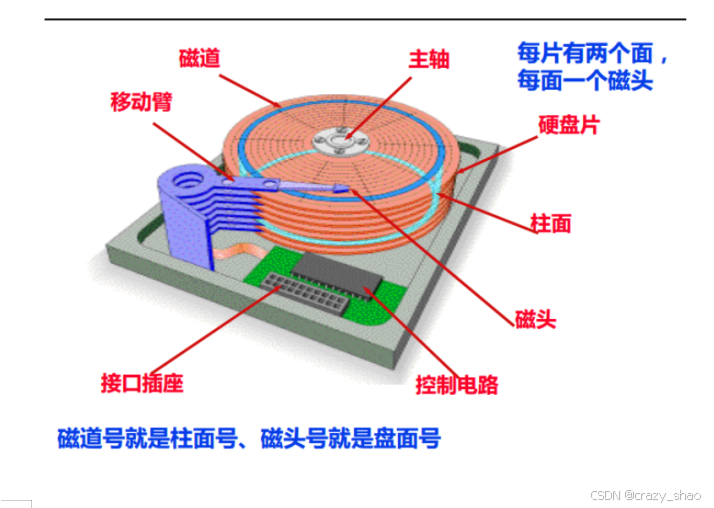
2、磁盘分区管理
-
分区步骤
1)新建分区fdisk /dev/sdb
2)更新分区表(刷新分区表)
3)格式化分区-->文件系统mkfs.ext4 /dev/sdb1
4)挂载使用-->mount【开机自动挂载|autofs自动挂载】
-
fdisk分区管理与使用
查看磁盘挂载状态 # lsblk # df -h
-
查看当前设备分区情况
查看所有磁盘 # fdisk -l 硬盘容量 = 柱面数 × 盘面数(磁头数) × 扇区数 × 扇区大小(一般为 512 字节) 注意:“dos 分区”并不是以操作系统的不同而划定的分区体系,而是指使用“主引导记录(MBR)”的分区体系 查看指定磁盘 # fdisk -l /dev/sdb
--------------------------------------------------------fdisk分区--------------------------------------------------------
准备一块硬盘,虚拟机关机,添加一块硬盘
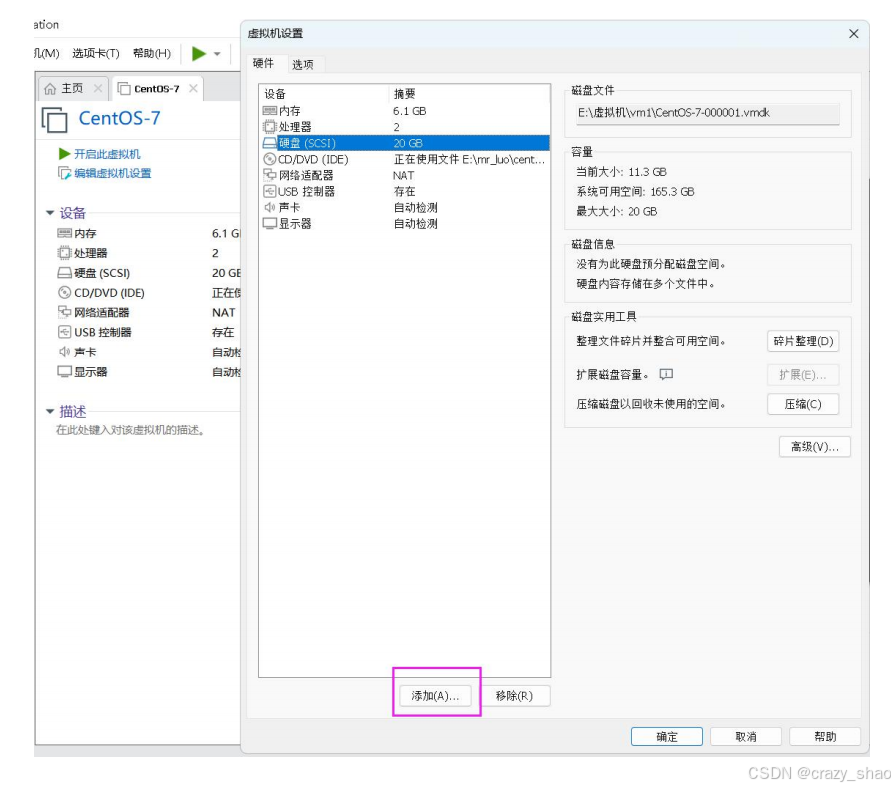
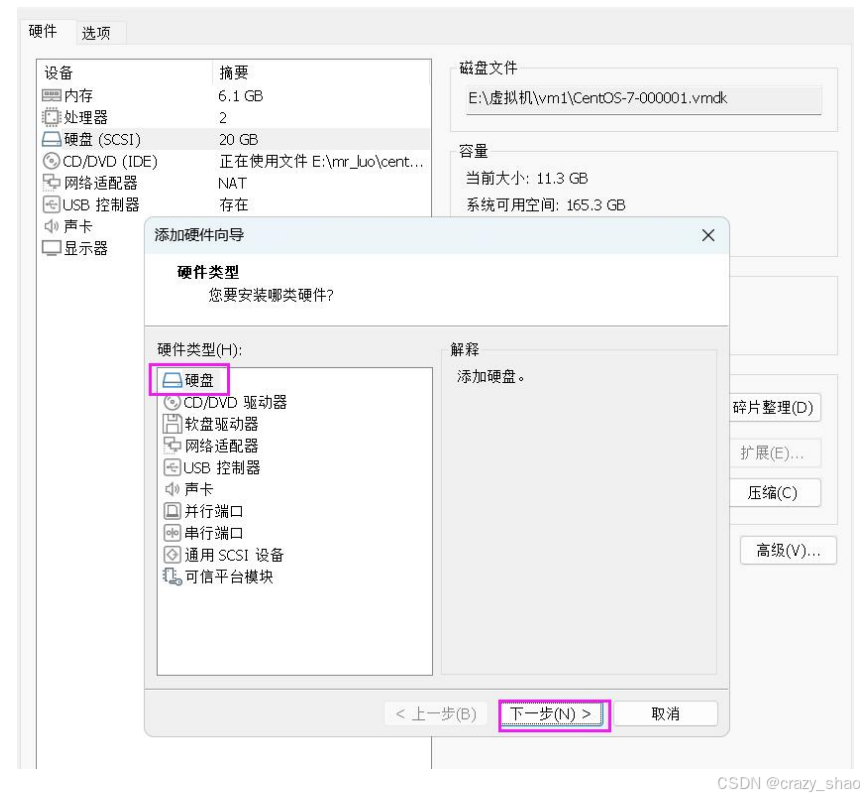
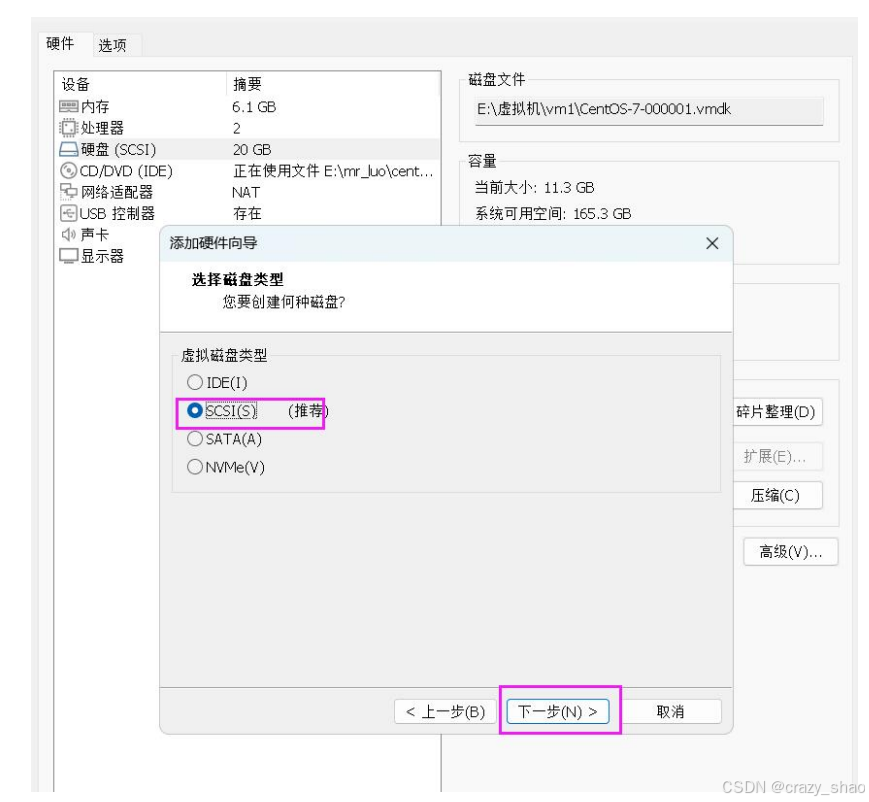

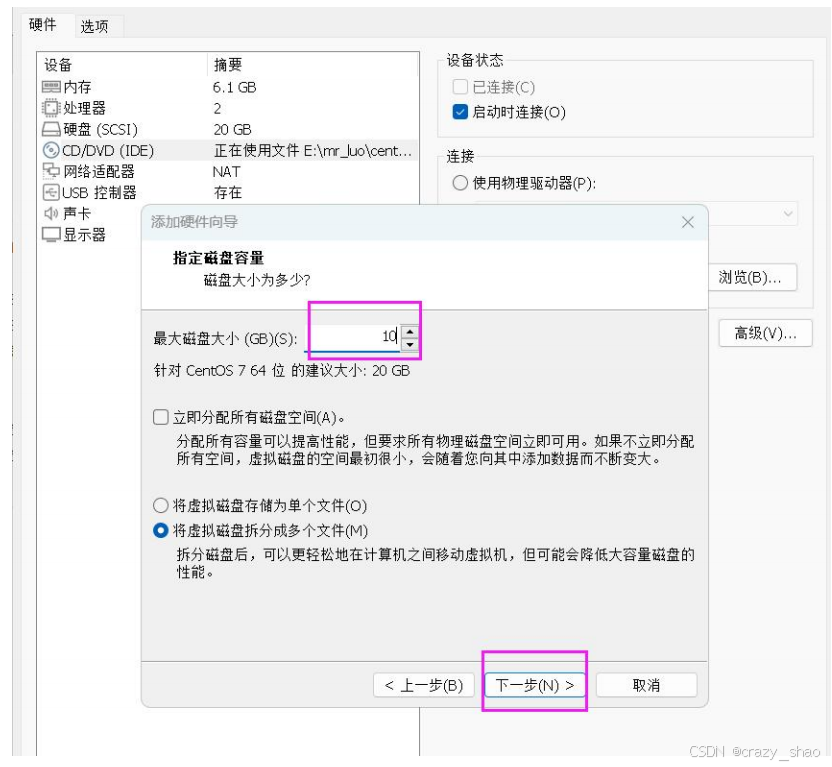
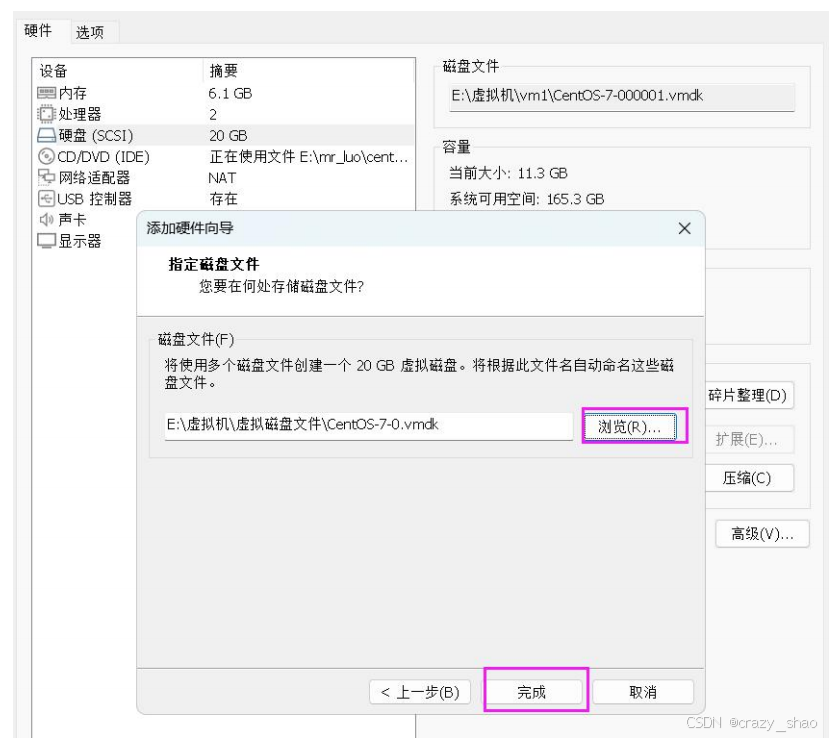
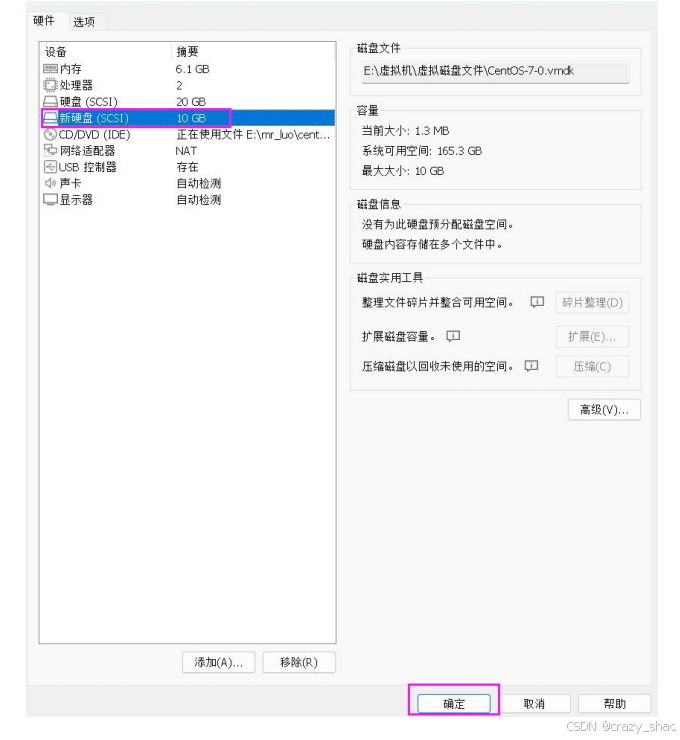
-
查看所有设备
# fdisk -l
第一步 创建分区
# fdisk /dev/sdb
Command(m for help): m 输出帮助信息
Commandaction
a toggle a bootable flag 设置启动分区
b edit bsd disklabel 编辑分区标签
c toggle the dos compatibility flag
d delete a partition 删除一个分区
l list known partition types 列出分区类型
m print this menu 帮助
n add a new partition 建立一个新的分区
o create a new empty DOS partition table 创建一个新的空白 DOS 分区表
p print the partition table 打印分区表
q quit without saving changes 退出不保存设置
s createa new empty Sun disklabel 创建一个新的空的 SUN 标示
t changea partition's system id 改变分区的类型
u changedisplay/entry units 改变显示的单位
v verifythe partition table 检查验证分区表
w write table to disk and exit 保存分区表总结:
-
最多只能分 4 个主分区,主分区编号 1-4
-
逻辑分区大小总和不能超过扩展分区大小,逻辑分区分区编号从 5 开始
-
如果删除扩展分区,下面的逻辑卷分区也被删除
-
扩展分区的分区编号(1-4)
第二步 刷新分区表
# partx -a /dev/sdb BLKPG: Device or resource busy error adding partition 1 BLKPG: Device or resource busy error adding partition 2
第三步 格式化
分区完成后需要格式化才能挂载使用,格式化需要指定文件系统类型,在 Linux 系统中,文件系统类型对于存储设备的性能和兼容性具有重要影响。Linux 支持多种文件系统类型,其中一些常见的文件系统类型包括:
ext2: 这是 Linux 早期常用的文件系统,适用于那些分区容量不是太大且更新不频繁
的情况,例如/boot 分区。
ext3:作为 ext2 的改进版本,ext3 支持日志功能,能够帮助系统从非正常关机导致的
异常中恢复。
ext4:这是 ext 文件系统的最新版,提供了很多新的特性,包括纳秒级时间戳、创建和使用巨型文件(16TB)、最大 1EB 的文件系统,以及速度的提升。
XFS:由 SGI 开发,支持最大 8EB 的文件系统,特别擅长于处理大文件和大数据存储。
格式化命令 mkfs 用法: mkfs [选项] [-t <类型>] [文件系统选项] <设备> [<大小>] # mkfs.xfs /dev/sdb1 或 # mkfs -t xfs /dev/sdb1
第四步挂载使用
创建挂载点 # mkdir /sdb 挂载分区 # mount /dev/sdb1 /sdb/ 查看挂载状态 # lsblk 或 df -h 开机挂载 方式一: # echo "mount /dev/sdb /sdb/" >> /etc/rc.d/rc.local # chmod a+x /etv/rc.d/rc.local 方式二: vim /etc/fstab 挂载 fstab 中的所有文件系统(自动挂载),执行命令后会自动根据 fstab 中的设置进行自动挂载 # mount -a 通过 UUID 挂载需要查看设备的 UUID # blkid /dev/sdb1
格式说明
<devices> <dir> <type> <options> <dump> <pass>
第一列: 挂载设备(也可以使用设备的 UUID)
第二列: 挂载点目录
第三列: 文件系统类型
第四列: 挂载选项 default
default 使用默认选项: rw, suid, dev, exec, auto, nouser, and async
noauto 不自动挂载,只能使用 mount -a 挂载
user 允许任意用户挂载此文件系统
owner 允许设备所有者挂载
nofail 如果该设备不存在,请不要报告该设备的错误
第五列: 是否进行 dump 进行备份:0 不备份 1 每天备份 2 其他不定期的备份
第六列: 是否用 fsck 检验扇区:0 不检验 1 检验(根目录) 2 检验(其他需要检验的目录)1 在 2 的前面检验
/etc/fstab/与/etc/rc.d/rc.local 两者区别
开机挂载 mount /etc/fstab 与/etc/rc.d/rc.ocal 差不多,差别就是如果你程序依赖于 NFS的话还是的放到 fstab 比较好。程序启动先加载/etc/fastab 文件,放 fstab 里面会在程序启动前加载上 NFS 文件系统,放到 rc.local 里往往造成程序启动加载时找不到路径-
卸载
卸载 # mount /dev/sdb1 查看状态 # df -h 删除开机挂载 # vim /etc/rc.d/rc.local 或 /etc/fstab 思考:卸载后/sdb 的数据是否还存在?
-
删除分区
删除分区先,先将分区卸载 # fdisk /dev/sdb
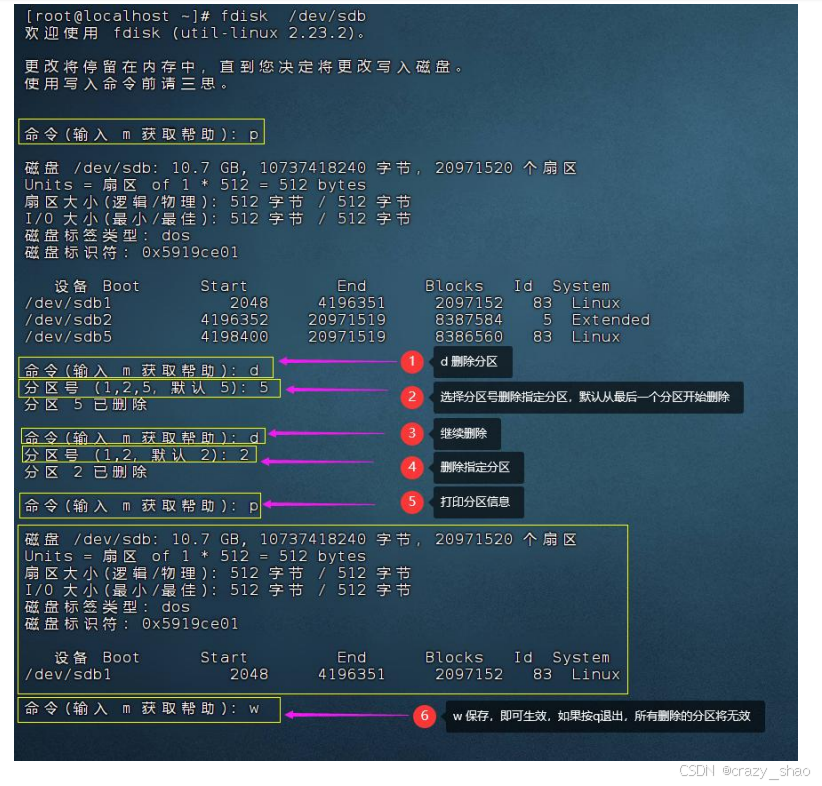
# fdisk -l /dev/sdb 注意:删除有数据的分区注意进行数据备份,将分区挂载后,备份数据再进行删除!
-
parted分区管理与使用
parted主要管理GPT的分区类型
在 64 位 Linux CentOS 中,最多可以创建 128 个 GPT 分区,而 MBR 最多支持 4 个主分区!
GTP 支持 2TB 以上的硬盘分区,而 MBR 只支持 2TB 以内的硬盘分区!
-
parted分区
用法:parted [选项]... [设备[子命令 [参水]...]...] 常用选项 -s:--script 从不提示用户 常用子命令 print 打印分区情况 mklabel 创建新的分区类型 mkpart 创建新的分区 rm 删除分区 查看所有设备的分区情况 # parted -l 打印指定设备分区表 # parted /dev/sdb print # parted /dev/sda print 提示:msdos,表示 MBR 分区表 创建GPT的分区表类型 # parted /dev/sdb mklabel gpt # parted /dev/sdb print 创建分区 # parted /dev/sdb mkpart gpt 0% 5G # parted /dev/sdb print 提示:第 2048 个扇区是系统推荐的第一分区的起始扇区,也可以使用 0% # parted -s /dev/sdb mkpart gpt 5G 7G # parted -s /dev/sdb mkpart gpt 7G 100% # parted /dev/sdb print 删除分区 # parted /dev/sdb rm 3 # parted /dev/sdb rm 2 挂载使用 与 fdisk 中的操作一致! 卸载 与 fdisk 中的操作一致!
-
逻辑卷管理
1)LVM 功能特性
LVM :中文含义是逻辑卷管理器,它是一种在 Linux 系统中被广泛使用的分区管理机制,具备极其良好的可扩展性。
许多 Linux 使用者安装操作系统时都会遇到这样的困境:如何精确评估和分配各个硬盘分区的容量!
如果当初评估不准确,一旦系统分区不够用时可能不得不备份、删除相关数据,甚至被
迫重新规划分区并重装操作系统,以满足应用系统的需要。
LVM 是 Linux 环境中对磁盘分区进行管理的一种机制,是建立在硬盘和分区之上、文件系统之下的一个逻辑层,可提高磁盘分区管理的灵活性。
2)LVM 概念
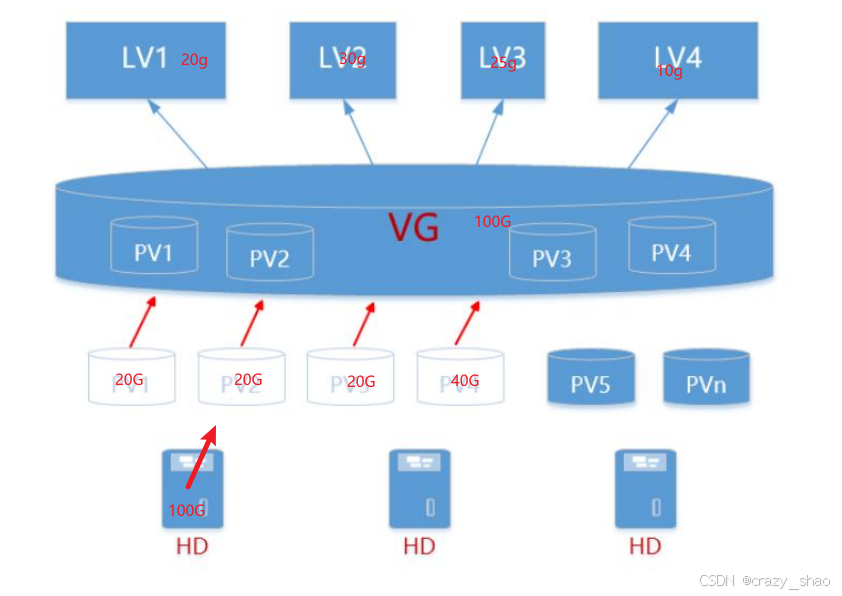
物理卷(Physical Volume,PV)
物理卷是底层真正提供容量,存放数据的设备,它可以是整个硬盘、硬盘上的分区等。
卷组(Volume Group, VG)
卷组建立在物理卷之上,它由一个或多个物理卷组成。即把物理卷整合起来提供容量分配。 一个 LVM 系统中可以只 有一个卷组,也可以包含多个卷组。
逻辑卷(Logical Volume, LV)
逻辑卷建立在卷组之上,它是从卷组中“切出”的一块空间。它是最终用户使用的逻辑设备。逻辑卷创建之后,其大小 可以伸缩。
物理区域 PE(physical extent)
每一个物理卷被划分为称为 PE(Physical Extents)的基本单元,具有唯一编号的 PE 是能被 LVM 寻址的最小单元。PE 的大小可指定,默认为 4 MB。 PE 的大小一旦确定将不能变,一个卷组中的所有物理卷的 PE 的大小是一致的。
4MB=4096kb=4096kb/4kb=1024 个 block
说明:
-
硬盘读取数据最小单位 1 个扇区 512 字节
-
操作读取数据最小单位 1 个数据块=8*512 字节=4096 字节=4KB
-
lvm 寻址最小单位 1 个 PE=4MB
逻辑区域 LE(logical extent)逻辑卷也被划分为被称为 LE(Logical Extents) 的可被寻址的基本单位。在同一个卷组中,LE 的大小和 PE 是相同的,并 且一一对应。
真实的物理设备==>逻辑上(命令创建)==>物理卷(pv)==>卷组(vg)==>逻辑卷(lv)==>逻辑卷格式化==>挂载使用
3)逻辑卷创建
步骤:
第一步: 分区
# parted /dev/sdb print
# umount /dev/sdb1
# parted /dev/sdb rm 1
# parted -s /dev/sdb mkpart gpt 0% 3G
# parted -s /dev/sdb mkpart gpt 3G 6G
# parted -s /dev/sdb mkpart gpt 6G 100%
# parted /dev/sdb print
第二步:创建物理卷
# pvcreate [选项] devices
# pvcreate /dev/sdb{1..2} 或 # pvcreate /dev/sdb1 /dev/sdb2
查看物理卷
# pvs 或 #pvscan
第三步:创建卷组
# vgcreate [选项] vg_name pv_name
# vgcreate vg01 /dev/sdb{1..2} 或 # vgcreate vg01 /dev/sdb1 /dev/sdb2
查看卷组
# vgs 或 # vgscan
第四步:创建逻辑卷
# lvcreate [选项] vg_name
-L 指定逻辑卷大小
-n 指定逻辑卷名称
注意:逻辑卷的空间是从卷组中分配的,因此逻辑卷的大小不能超过卷组的大小
# lvcreate -L 4G -n lv01 vg01
# lvs 或 # lvscan
第五步:格式化逻辑卷
# mkfs.xfs /dev/vg01/lv01
第六步:挂载使用
# mkdir /lvm
# mount /dev/vg01/lv01 /lvm
# lsblk 或 # df -h
第七步:开机挂载
# echo "/dev/vg01/lv01 /lvm xfs default 0 0" >> /etc/fstab
# tail -5 /etc/fstab
如果没有手动挂载,可以使用 mount -a 根据 fstab 文件自动挂载设备
# mount -a
4)逻辑卷扩容
需求
在线将逻辑卷 lv01 扩容成 8G
思路:
-
查看/lvm 目录所对应的逻辑卷是哪一个 /dev/mapper/vg01-lv01
-
查看当前逻辑卷所在的卷组 vg01 剩余空间是否足够
-
如果 vg01 空间不够,得先扩容卷组,再扩容逻辑卷
-
如果 vg01 空间足够,直接扩容逻辑卷
步骤: 第一步:查看 lvm 目录属于哪个卷组 # df -h # lvs 第二步:查看卷组的剩余空间 # vgs 查看卷组空闲空间不足,需要先对 vg01 扩容,再进行逻辑卷扩容 需要准备物理设备,将物理设备做成物理卷,再将新的物理卷扩容到卷组! 第三步:创建物理卷 # parted /dev/sdb print # pvcreate /dev/sdb3 # pvs 第四步:扩容卷组 # vgextend [选项] vg_name pv_name # vgextend vg01 /dev/sdb3 # vgs 第五步:扩容逻辑卷 # lvextend [选项] /path/lv_name 常用选项: -L 指定扩容大小 # lvextend -L +4G /dev/vg01/lv01 # lvs -L +4G 将/dev/vg01/lv01 扩大 4G # df -h 第六步:扩容文件系统 ext4 的文件系统扩容 用法: resize2fs lv_name # resize2fs /dev/vg02/lv01 xfs 的文件系统扩容 用法:# xfs_growfs lv_name # xfs_growfs /dev/vg01/lv01 # df -h 查看逻辑卷扩容成功
5)逻辑卷删除
步骤:
第一步:卸载
# umount /dev/vg01/lv01
提示:删除配置文件中的内容,不然下次重启机器,机器不能正常开机。
# vim /etc/fstab
# tail -3 /etc/fstab
# df -h
第二步: 删除逻辑卷
# lvremove [选项] lvm_name
# lvscan
第三步:删除卷组
# vgremove [选项] vg_name
# vgs
# vgremove vg01
第四步:删除物理卷
# pvremove [选项] pv_name
# pvs
# pvremove /dev/sdb{1..2}
6)逻辑卷快照
逻辑卷快照的作用是,允许我们在不中断服务的情况下捕获逻辑卷在某个时间点的状态,从而进行备份、恢复或测试等操作。LVM 快照是一个特殊的逻辑卷,它保存了原始逻辑卷在某个时间点的数据镜像。快照使用写时复制(Copy-on-Write)技术,这意味着在快照创建时,并不会立即复制整个卷的数据。相反,只有当原始卷上有数据块被修改时,这些被修改的数据块才会被复制到快照预留的空间中。因此,快照的大小通常远小于原始卷。
先创建一个 lv02 的逻辑卷
# pvcreate /dev/sdb{1..3}
# vgcreate vg02 /dev/sdb{1..3}
# lvcreate -L 8G -n lv02 vg02
# lvs
# lvdisplay /dev/vg02/lv02
本次创建成 ext4 的文件系统,用 xfs 也可以
# mkfs.ext4 /dev/vg02/lv02
创建挂载点挂载使用
# mkdir /mnt/lv02
# mount /dev/vg02/lv02 /mnt/lv02/
# ls -l /mnt/lv02/
使用标准的 ext2/ext3 档案系统格式才会产生的一个目录,目的在于当档案系统发生错误
时, 将一些遗失的片段放置到这个目录下
# df -h
在/mnt/lv02 中准备数据
# cd /mnt/lv02
# cp /etc/passwd /mnt/lv02
# dd if=/dev/zero count=10 bs=1M of=linux.txt
# ll -h
创建快照
用法: lvcreate [选项] lvm_name
-L 指定快照大小
-n 指定快照名称
-s 表示创建快照
# lvcreate -s -n lv02_snap -L 1G /dev/vg02/lv02
# lvs
模拟 lvm 数据丢失
# ls
# rm -rf passwd
# ls -l
快照恢复数据
用法:
# lvconvert [选项] snap_name
# cd
# umount /mnt/lv02
提示:恢复快照需要将原来的逻辑卷卸载
# lvconvert --mergesnapshot /dev/vg02/lv02_snap
# lvs
提示: 快照是一次性的,恢复完后,快照就会自动删除
# mount /dev/vg02/lv02 /mnt/lv02/
# cd /mnt/lv02/
# ls -l
数据已恢复
快照使用场景(扩展)
应用场景:
/var/lib/mysql
-
锁表
-
备份【逻辑|物理备份】100G 物理备份 /var/lib/mysql/xxx
-
解锁
-
创建快照
-
解锁
-
挂载快照
-
备份到指定地方
-
删除快照
快照实现自动扩容(扩展)
修改逻辑卷配置文件参数
# vim /etc/lvm/lvm.conf
snapshot_autoextend_threshold = 80
snapshot_autoextend_percent = 20
当快照使用到 80%时,自动扩容 20%;当 snapshot_autoextend_threshold = 100 表示关闭自动扩容
三 Linux高级管理
第一节 Linux中防火墙firewelld
1、什么是防火墙
防火墙主要用于防范网络攻击,防火墙一般分为软件防火墙、硬件防火墙
2、防火墙的作用
主要作用是保护系统免受未经授权的访问和攻击。它有助于防止黑客利用系统中的安全漏洞,以及限制对特定网络服务的访问。
3、linux防火墙分类
Centos6==>防火墙=>iptables防火墙 防火墙系统管理工具
Centos7=>防火墙=>firewalld防火墙
4、firewalld防火墙
firewalld 工具是一个面向用户,方便用户的防火墙配置工具,系统内核依然是基于 iptables 规则来工作的。firewalld 工具其实就是在帮我们配置 iptables 防火墙规则。
-
firewalld防火墙服务管理
启动防火墙 # systemctl start firewalld 停止防火墙 # systemctl stop firewalld 重启防火墙 # systemctl restart firewalld 查看防火墙状态 # systemctl status firewalld 设置开机启动 # systemctl enable firewalld 设置开机不启动 # systemctl disable firewalld 重载防火墙 # systemctl reload firewalld
-
防火墙zone的概念
firewalld相比于iptables增加区域(zone)的概念,在firewalld中不同的区域会预先准备不同的防火墙策略集合。
| 区域名 | 默认规则(策略) |
|---|---|
| trusted | 允许所有数据包 |
| home | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、mdns、ipp-client、amba-client与dhcpv6-client服务相关,则允许流量 |
| internal | 等同于home区域 |
| work | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、ipp-client、dhcpv6-client服务相关,则允许流量 |
| public | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh、dhcpv6-client服务相关,则允许流量 |
| external | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh服务相关,则允许流量 |
| dmz | 拒绝流入的流量,除非与流出的流量相关;而如果流量与ssh服务相关,则允许流量 |
| block | 拒绝流入的流量,除非与流出的流量相关 |
| drop | 拒绝流入的流量,除非与流出的流量相关 |
对应的配置文件位置
# ll /lib/firewalld/zones
5、防火墙命令及策略
管理防火墙策略,可以通过firewalld的管理工具 firewalld-cmd来对firewalld进行防火墙的策略配置。
-
firewalld-cmd工具常用命令
查看防火墙状态 # systemctl status firewalld 或 # firewall-cmd --state 查看当期活动zone信息 # firewall-cmd --get-actvie-zones 查看默认的zone # firewall-cmd --get-default-zone 设置默认的zone # firewall-cmd --set-default-zone=zone_name 查看指定zone的详细信息 # firewall-cmd --info-zone=zone_name 查看当前zone可用的服务 # firewall-cmd --list-services 查看所有的zones # firewall-cmd --list-all-zones 查看当前所有zone名称 # firewall-cmd --get-zones 查看现有的规则 # firewall-cmd --list-all 重新加载防火墙规则 # firewall-cmd --reload
-
基于服务配置firewalld策略
基于服务添加策略 基本语法: 临时修改 # firewall-cmd --add-service=service_name 永久修改(重载生效) # firewalld-cmd --add-service=service_name --permanent # firewalld-cmd --reload 案例: 安装httpd服务,并配置防火墙规则,httpd是一个web服务,安装后可以通过访问虚拟机的ip地址加上访问端口80,即可访问到一个apache服务的界面 安装 # yum -y install httpd 启动 # systemctl start httpd 查看状态 # systemctl status httpd 查看端口 # ss -taunlp |grep 80 测试访问 http://192.168.10.128/ 配置firwalld规则 # firewall-cmd --list-all # firewall-cmd --add-service=http 备注:服务必须在/usr/lib/firewalld/services目录中 # ll /usr/lib/firewalld/services|grep http # firewall-cmd --list-all http://192.168.10.128/ # firewall-cmd --reload # firewall-cmd --list-all # firewall-cmd --add-service=http --permanent
-
基于服务删除策略
基本语法: 临时修改(重载失效) # firewall-cmd --remove-service=service_name 永久修改(重载生效) # firewall-cmd --remove-service=service_name --permanent # firewall-cmd --reload 案例: 临时删除 # firewall-cmd --remove-service=http 永久删除 # firewall-cmd --remove-service=http --permanent # firewall-cmd --reload
-
基于端口配置firewalld策略
基于端口添加策略 基本语法: 临时修改(重载失效) # firewall-cmd --add-port=port/protocol 永久修改(重载生效) # firewall-cmd --add-port=port/protocol --permanent # firewall-cmd --reload 案例: 临时修改 # firewall-cmd --add-port=80/tcp 永久修改 # firewall-cmd --add-port=80/tcp --permanent # firewall-cmd --reload
-
基于端口删除策略
基本语法: 临时修改(重载失效) # firewall-cmd --remove-port=port/protocol 永久修改(重载生效) # firewall-cmd --remove-port=port/protocol --permanent # firewall-cmd --reload 案例: 临时修改 # firewall-cmd --remove-port=80/tcp 永久修改 # firewall-cmd --remove-port=80/tcp --permanent # firewall-cmd --reload
-
基于规则配置firewalld策略
基于规则添加策略 基本语法: 临时生效,重载失效 # firewall-cmd --add—rich-rule='"rule 规则明细" action' 永久修改,重载生效 # firewall-cmd --add-rich-rule='"rule 规则明细" action' --permanent # firewall-cmd --reload action 对添加的策略实现的动作 动作 Reject 拒绝,对进来的流量直接拒绝 Accept 接收,对进徕的流量接收 Drop 丢弃,对进来的流量包直接丢弃 reject与drop区别 DROP动作只是简单的直接丢弃数据,并不反馈任何回应。需要Client等待超时,Client容易发现自己被防火墙所阻挡 REJECT动作则会更为礼貌的返回一个拒绝(终止)数据包,明确的拒绝对方的连接动作。连接马上断开,Client会认为访问的主机不存在。 使用Firewalld和rich rules常见的网络访问控制场景: 源和目标地址过滤: 允许特定网段地址的访问: # firewall-cmd --add-rich-rule='rule family=ipv4 source address=192.168.10.0/24 accept' 允许特定ip地址访问: # firewall-cmd --add-rich-rule='rule family=ipv4 source address=192.168.10.10 accept' 服务过滤: 允许特定的服务的访问: # firewall-cmd --add-rich-rule='rule family=ipv4 service name=http accept' 协议过滤: 允许特定协议的访问: # firewall-cmd --add-rich-rule='rule family=ipv4 protocol value=icmp accept' 源和目标端口过滤: 允许从特定端口访问特定目标端口: # firewall-cmd --add-rich-rule='rule family=ipv4 service name=ssh source port=1024-65535 destination port=22 accept' 高级条件过滤: 限制特定IP地址的访问速率: # firewall-cmd --add-rich-rule='rule family=ipv4 source address=192.168.0.10 limit value=3/m burst=5 accept' 表示源地址192.168.0.10 允许每分钟三次封包,每次封包的数量包不能超过5个! 网络地址转换和端口转发: 启用源地址转换: # firewall-cmd --add-rich-rule='rule family=ipv4 source address=192.168.0.10 masquerade' 启用源地址192.168.0.10伪装
-
基于规则删除策略
基本语法: 临时修改(重载失效) # firewall-cmd --remove-rich-rule='rule 规则明细" action ' 永久修改(重载生效) # firewall-cmd --remove-rich-rule='rule 规则明细" action ' --permanent # firewall-cmd --reload 临时删除 # firewall-cmd \ --remove-rich-rule='rule family=ipv4 source address="192.168.10.0/24" port port="80" protocol="tcp" accept' 永久删除 # firewall-cmd \ --remove-rich-rule='rule family=ipv4 source address="192.168.10.0/24" port port="80" protocol="tcp" accept' --permanent # firewall-cmd --reload
第二节 计划任务
1、什么是计划任务
操作系统设置任务不可能完全由人去操作,对一些特定时间点的任务,我们可以设置计划任务,让服务在规定时间去执行。
2、windows中的计划任务
win11为例打开任务计划:打开控制面板-->windows工具-->任务计划程序
3、Linux中的计划任务
-
周期性计划任务
基本语法: # crontab [选项] -l:list,显示当前已经设置的计划任务 -e:使用vim编辑器编辑计划任务文件 ① 计划任务的编辑 计划任务的规则语法格式,以行为单位,一行就是一个计划分 时 日 月 周 要执行的命令(必须使用命令的完整路径,可以使用which查看) 取值范围 分:0-59 时:0-23 日:1-31 月:1-12 周:0-7,0和7表示星期天 四个符号 : *:表示取值范围中的每一个数字 -:做连续区间表达式的,表示1-7;可以写为1-7 /:表示每多少个执行一次,如:每30分钟一次,*/30 ,:表示多个取值,例如每个月的1号5号15号执行,1,5,15 ② 计划任务案例 案例1:每月1、10、22日的4:45 重启network服务 定制格式 分 时 日 月 周 /usr/bin/systemctl restart network 45 4 1,10,12 * * /usr/bin/systemctl restart network 案例2:每周六、周日的1:10分 重启network服务 定制格式 分 时 日 月 周 /usr/bin/systemctl restart networktl restart network 10 1 * * 6,7 /usr/bin/systemctl restart network 案例3:每天18:00到23:00之间每隔30分钟重启network服务 定制格式 分 时 日 月 周 /usr/bin/systemctl restart networktl restart network */30 18-23 * * * /usr/bin/systemctl restart networktl restart network 案例4:每隔两天的上午8点到11点的第三分钟和第十五分钟执行一次重启network服务 定制格式 分 时 日 月 周 /usr/bin/systemctl restart networktl restart network 3,15 8-11 */2 * * /usr/bin/systemctl restart networktl restart network 案例5: 每月每周每天每小时每分钟,创建一个内容为1的文件名为readme.txt的文件 #crontab -e * * * * * /usr/bin/echo 1 >> /root/readme.txt 注 意: 计划任务设置完成后,确保计划任务服务是运行状态 #systemctl status crond #systemctl start crond ③ 计划任务权限 crontab 通过 /etc/cron.allow(白名单) 和 /etc/cron.deny(黑名单) 文件来限制用户是否可以使用 crontab 规则如下: 如果文件/etc/cron.allow存在,则只允许在cron.allow提及的用户名使用。 如果/etc/cron.allow不存在,则检查/etc/cron.deny,然后允许cron.deny未提及的每个用户名在使用。 空的/etc/cron.deny表示每个用户都可以使用crontab。 如果两者都不存在,则只允许超级用户在使用。 白名单优先级优于黑名单,如果一个用户同时存在两个名单文件,则会被默认允许创建计划任务 ④ 计划任务的保存文件 计划任务的文件具体保存在/var/spool/cron/用户名称 案例: # crontab -e */5 * * * * /usr/bin/touch /tmp/linux.txt # su - u1 $ crontab -e */5 * * * * /usr/bin/touch /tmp/u1.txt $ exit # ll /var/spool/cron/ 注意: 如果删除计划任务文件,等于删除了计划任务,也可以通过创建文件来创建计划任务 ⑤ 计划任务日志程 在实际应用中,一般会通过计划任务日志,去 查看任务的运行情况 # tail -f /var/log/cron

-
一次性计划任务at
在linux系统下,有两个命令可以实现计划任务:crontab与at(第三方安装)
crontab:每天定时执行计划任务
at:一次性定时执行任务
① 安装at 图形化自带at,最小化需安装 #yum install at -y ② 启动atd服务 # systemctl start atd # systemctl enable atd ③ 案例 案例1:三天后下午5点执行/bin/ls # at 5pm+3 days at>/bin/ls >> /root/readme.txt at>ctrl+d 注意:按键盘上的ctrl + d 键保存退出 案例2:明天下午18点,输出时间到指定的文件中 # at 18:00 tomorrow at>date > /root/readme.txt at>ctrl+d (退出) 查看还没有执行的计划任务 # atq 或 # at -l 查看计划任务的详细信息 # at -c 2 删除指定的计划任务 #atrm 任务id 删除任务 # atrm 2 # atrm 3 计划任务权限 at通过 /etc/at.allow(白名单) 和 /etc/at.deny(黑名单) 文件来限制用户是否可以使用 at 规则与crontab一致!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









