







1、 引言
1.1 背景介绍
神经网络在近年来的机器学习和深度学习领域中得到了广泛应用,尤其在文本分类任务中表现出了显著的优势。文本分类是自然语言处理(Natural Language Processing,NLP)中的一项基础任务,旨在将文本片段(如句子、段落或文档)分配到一个或多个类别中。常见的文本分类任务包括情感分析、垃圾邮件检测、主题分类等。
神经网络在文本分类中的应用主要得益于其强大的特征提取和模式识别能力。传统的文本分类方法依赖于手工设计的特征,而神经网络,特别是深度神经网络,可以通过自动学习数据中的复杂模式,从而提高分类性能。以下是几种常用的神经网络模型在文本分类中的应用:
-
多层感知器(Multilayer Perceptron,MLP):MLP是一种前馈神经网络,具有输入层、隐藏层和输出层。尽管MLP在处理线性可分问题上表现良好,但其在处理复杂的非线性问题时存在局限性,特别是当输入数据具有时序或空间关系时。
-
卷积神经网络(Convolutional Neural Network,CNN):CNN通过卷积层和池化层,能够有效提取输入数据中的局部特征。CNN最初用于图像处理,但在文本分类任务中也表现出色,尤其在捕捉局部n-gram特征方面。
-
递归神经网络(Recurrent Neural Network,RNN):RNN特别适用于处理序列数据,如文本和时间序列数据。RNN通过其循环结构,可以捕捉输入序列中的长短期依赖关系。然而,RNN在处理长序列时可能会遇到梯度消失或梯度爆炸问题。
-
长短期记忆网络(Long Short-Term Memory,LSTM):LSTM是RNN的一种变体,通过引入门控机制,可以更好地捕捉长时间依赖关系,解决了标准RNN在处理长序列时的不足。
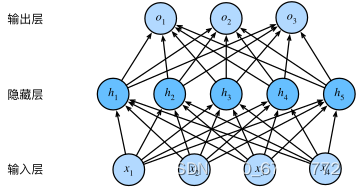
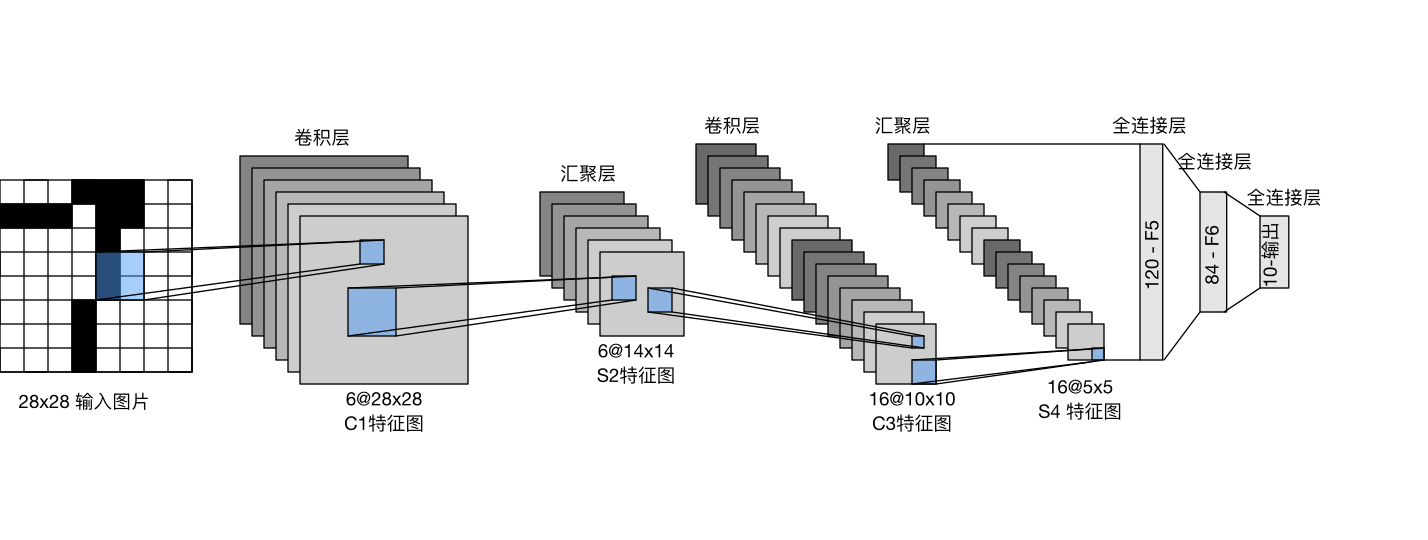
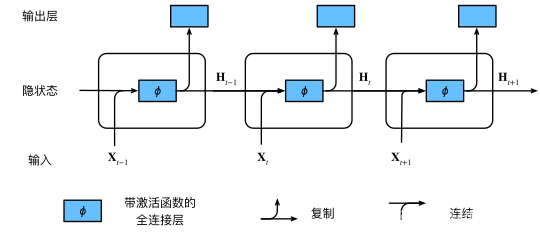
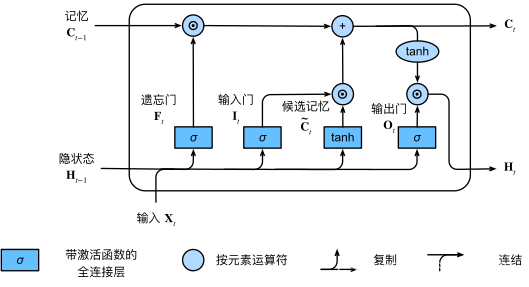
以上图片来自:《动手学深度学习》 — 动手学深度学习 2.0.0 documentation (d2l.ai)
在姓氏分类任务中,神经网络被用来根据给定的姓氏预测其所属的国籍。姓氏分类具有一定的实际应用价值,如在社交媒体分析、市场研究、用户个性化推荐等领域。姓氏分类的挑战在于姓氏的多样性和变异性,以及不同国籍之间的重叠特征。因此,利用神经网络的强大学习能力,可以在此任务中获得良好的分类效果。
1.2 实验目的
本实验的主要目标是比较多层感知器(MLP)和卷积神经网络(CNN)在姓氏分类任务中的表现。具体目标如下:
-
构建并训练多层感知器模型:通过MLP模型对姓氏数据进行分类,了解其在多类分类任务中的表现。MLP模型的设计将基于前馈神经网络,包含一个或多个隐藏层和一个输出层。
-
构建并训练卷积神经网络模型:通过CNN模型对姓氏数据进行分类,探索其在捕捉姓氏局部特征方面的优势。CNN模型将包含卷积层、池化层和全连接层,以提取姓氏中的关键模式。
-
性能比较:通过实验对比MLP和CNN两种模型在姓氏分类任务中的准确率、训练时间和模型复杂度。性能比较将帮助我们理解不同神经网络结构在处理文本分类任务时的优劣。
-
探讨Dropout对模型性能的影响:在模型训练过程中引入Dropout技术,探讨其对防止过拟合和提高模型泛化能力的影响。
通过以上实验步骤,我们希望能够系统地了解不同神经网络模型在姓氏分类任务中的表现,为后续的模型优化和应用提供依据。
2、感知器与多层感知器
2.1 感知器简介
感知器(Perceptron)是神经网络中最基础的构建单元之一,也是最早提出的人工神经网络模型之一。它由Frank Rosenblatt于1958年提出,旨在模拟生物神经元的基本功能。感知器的基本结构和工作原理如下:
基本结构:
一个典型的感知器由以下几个部分组成:
-
输入层(Input Layer):包含多个输入节点,每个节点代表一个输入特征。输入层接受外部输入信号,可以是文本数据、图像数据或其他类型的数据。
-
权重(Weights):每个输入节点都有一个对应的权重,这些权重表示输入信号的重要程度。在训练过程中,权重会不断调整,以便模型能够更好地学习数据中的模式。
-
加权和(Weighted Sum):感知器对输入信号进行加权,并计算所有加权输入的总和。
-
偏置(Bias):偏置是一个额外的可调参数,用于调整模型的输出。偏置可以看作是输入信号总和的一个固定补充值,帮助模型更好地拟合数据。
-
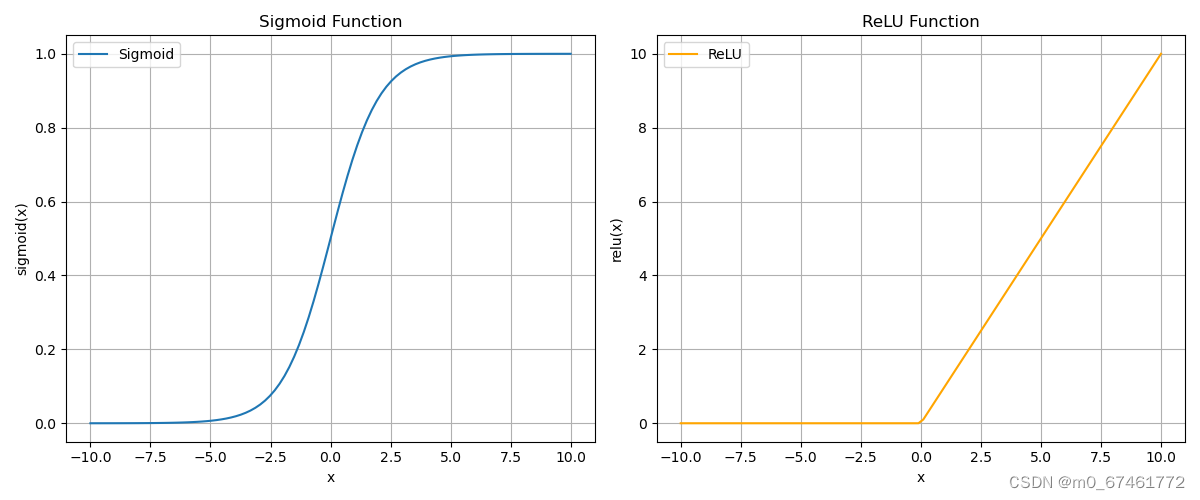
激活函数(Activation Function):感知器通过激活函数对加权和进行处理,激活函数将加权和转换为输出信号。常见的激活函数包括阶跃函数、Sigmoid函数和ReLU函数等。
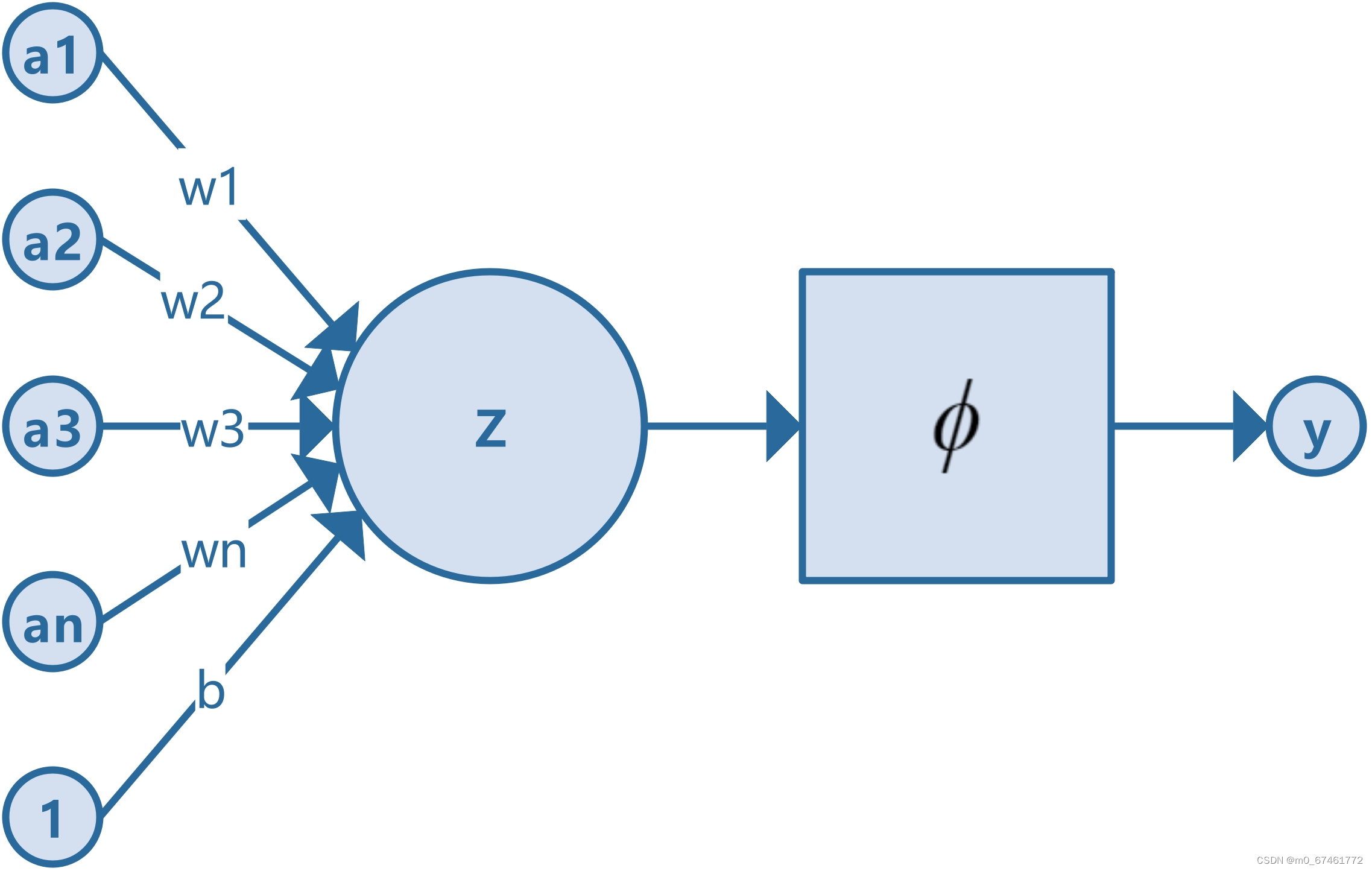
工作原理:
感知器的工作原理可以概括为以下几个步骤:
-
接收输入:感知器接收多个输入信号,每个信号用
表示,其中
表示第
-
加权输入:感知器将每个输入信号与对应的权重
相乘,得到加权输入
。
-
计算加权和:感知器对所有加权输入进行求和,并加上偏置
,计算出加权和
:
4. 激活函数:感知器将加权和 输入到激活函数中,得到最终输出
:
其中,为激活函数。
5. 输出信号:激活函数的输出 就是感知器的输出信号,用于下一层神经元的输入或直接作为模型的预测结果。
示例代码:
以下是一个简单的二分类感知器的示例代码,使用Python和PyTorch实现,该感知器用于判断输入数据是否属于某一类别:
1. 定义感知器模型:
class Perceptron(nn.Module):
def __init__(self, input_dim):
super(Perceptron, self).__init__()
self.fc = nn.Linear(input_dim, 1) # 全连接层
def forward(self, x):
z = self.fc(x) # 计算加权和
y = torch.sigmoid(z) # 使用Sigmoid激活函数
return y
这里定义了一个简单的感知器模型,包含一个全连接层和一个Sigmoid激活函数。
2. 初始化模型、损失函数和优化器:
input_dim = 2
model = Perceptron(input_dim)
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.01)
初始化感知器模型,使用二元交叉熵损失函数和随机梯度下降优化器。
3. 生成示例数据:
data = torch.tensor([[0.0, 0.0], [0.0, 1.0], [1.0, 0.0], [1.0, 1.0]])
labels = torch.tensor([[0.0], [1.0], [1.0], [0.0]]) # XOR问题
生成一些示例数据,这里使用XOR问题作为示例。
4. 训练模型:
num_epochs = 1000
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
loss_values.append(loss.item()) # 记录损失值
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
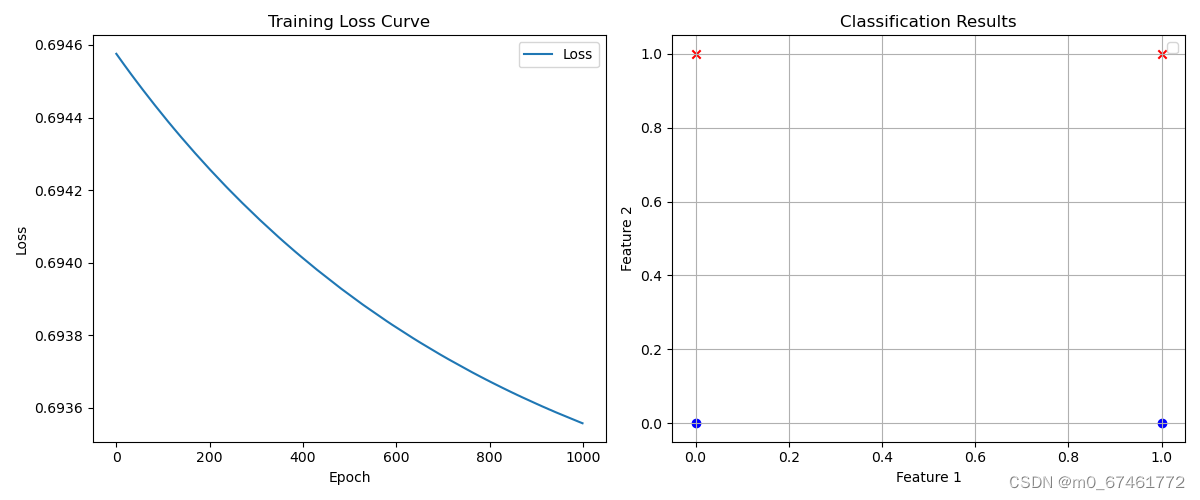
5. 绘制损失曲线:
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(range(num_epochs), loss_values, label='Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
6. 测试模型并绘制分类结果:
with torch.no_grad():
test_data = torch.tensor([[0.0, 0.0], [0.0, 1.0], [1.0, 0.0], [1.0, 1.0]])
predictions = model(test_data)
predicted_labels = predictions.round()
# 提取预测结果
test_data = test_data.numpy()
predicted_labels = predicted_labels.numpy()
# 绘制分类结果
plt.subplot(1, 2, 2)
for i, (x, y) in enumerate(zip(test_data, predicted_labels)):
if y == 0:
plt.scatter(x[0], x[1], color='red', marker='x', label='Class 0' if i == 0 else "")
else:
plt.scatter(x[0], x[1], color='blue', marker='o', label='Class 1' if i == 1 else "")
plt.title('Classification Results')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
结果:

2.2 感知器的局限性
感知器的一个主要局限性是它只能解决线性可分的问题。也就是说,如果数据集中的各个类别可以通过一条直线(在二维情况下)或一个超平面(在更高维情况下)来分割,那么感知器可以很好地处理。然而,对于非线性可分的问题,感知器则无能为力。例如,经典的XOR(异或)问题就是一个典型的非线性可分问题,感知器无法解决这个问题。这也就是为什么上文的代码运行结果是错误的。
为了解决这些局限性,研究人员提出了多层感知器(MLP),通过增加隐藏层和使用非线性激活函数,使其能够处理复杂的非线性问题。
2.3 多层感知器的概念与优势
多层感知器是一种前馈神经网络,由输入层、一个或多个隐藏层和输出层组成。每一层中的神经元与前一层的神经元完全连接,通过加权和偏置的线性组合,经过非线性激活函数的作用,将输入映射到输出。
结构概述:
- 输入层:接收外部输入数据,输入层的每个神经元代表一个输入特征。
- 隐藏层:位于输入层和输出层之间,可以有一个或多个隐藏层。隐藏层中的神经元对输入数据进行复杂的特征提取和非线性变换。
- 输出层:将隐藏层的输出转换为最终的预测结果。
公式表示:
假设输入向量为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









