






爬取《斗破苍穷》前三十章小说
1.分析思路
1.1分析url
第一章:http://book.doupoxs.com/doupocangqiong/1.html
第二章:http://book.doupoxs.com/doupocangqiong/2.html
第三章:http://book.doupoxs.com/doupocangqiong/3.html
第四章:http://book.doupoxs.com/doupocangqiong/4.html
....
由此可以分析url中的变量。
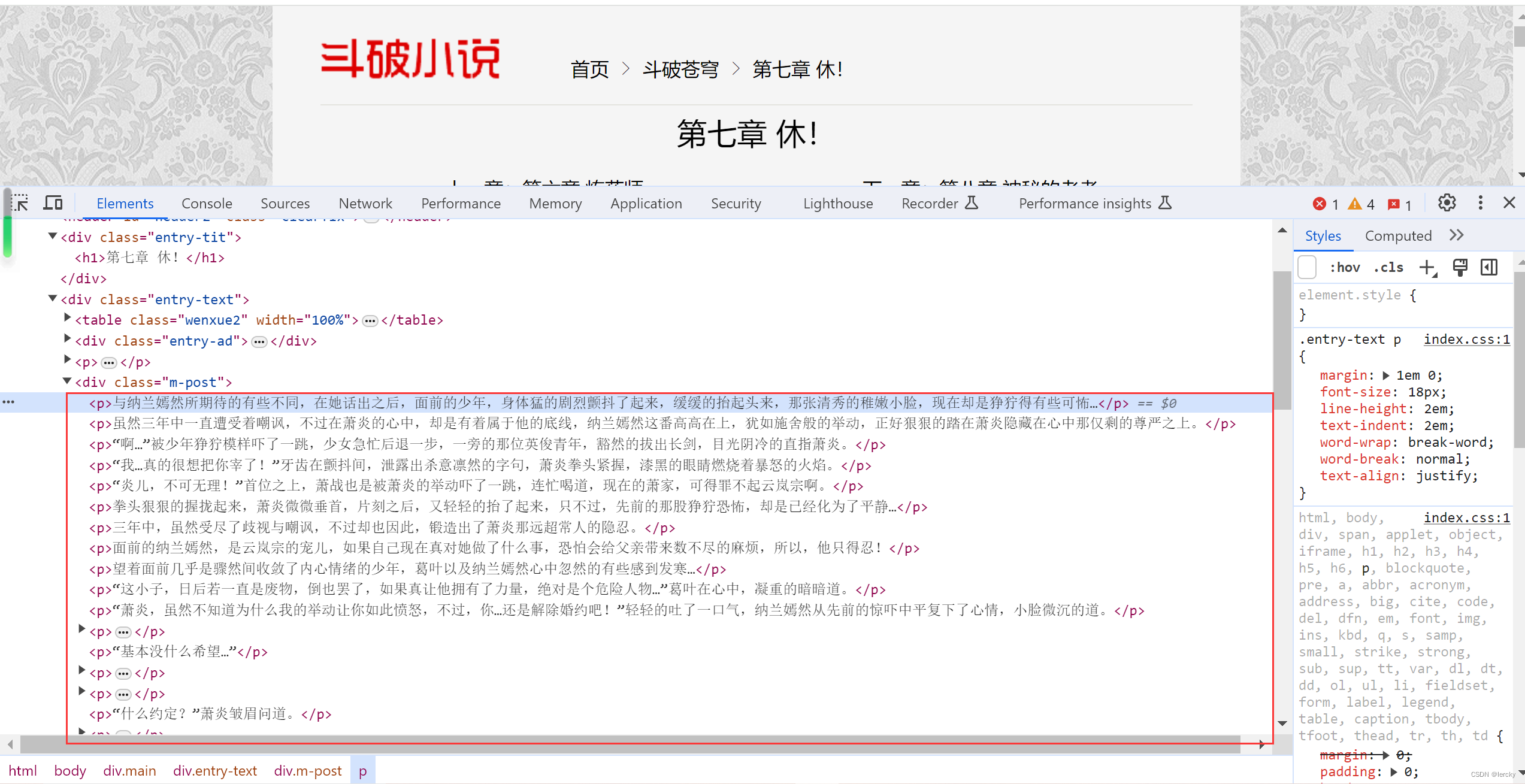
1.2.分析内容,我们需要爬取的是小说内容
通过点击检查,分析网页代码,可以得出小说的内容是由标签<p>content</p>
由此推断出我们可以使用正则表达式‘<p>(.*?)</p>’去匹配内容
2.代码
# 1.导包
import requests
import re
import time
# 2.请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
# 3.打开你要写入的文件
f = open('D:\python爬虫\小说—斗破苍穹.txt','a+')
# 4.写一个get_info的函数
def get_info(url):
# 函数中:a.获取请求信息
res = requests.get(url, headers=headers)
# b. 判断请求的状态码是否为200
if res.status_code == 200:
# c.利用正则表达式匹配出内容,用findall()函数
contents = re.findall('<p>(.*?)</p>', res.content.decode('utf-8'), re.S)
# d.因为findall()函数返回的内容是列表,所以用for循环取出并写入txt文件且换行
for content in contents:
f.write(content + '\n')
else:
pass
if __name__ == '__main__':
# 5.构造多页url
urls = ['http://book.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in range(1, 31)]
# 6.利用for循环取出url,且调用get_info函数。
for url in urls:
get_info(url)
time.sleep(1)
# 7.关闭文件
f.close()

















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









