







目录
编译程序基础:
编译程序的基础是把某种高级语言书写的源程序翻译成与之等价的目标程序(汇编语言程序或机器语言程序)。编译程序的工作过程分为6个阶段:
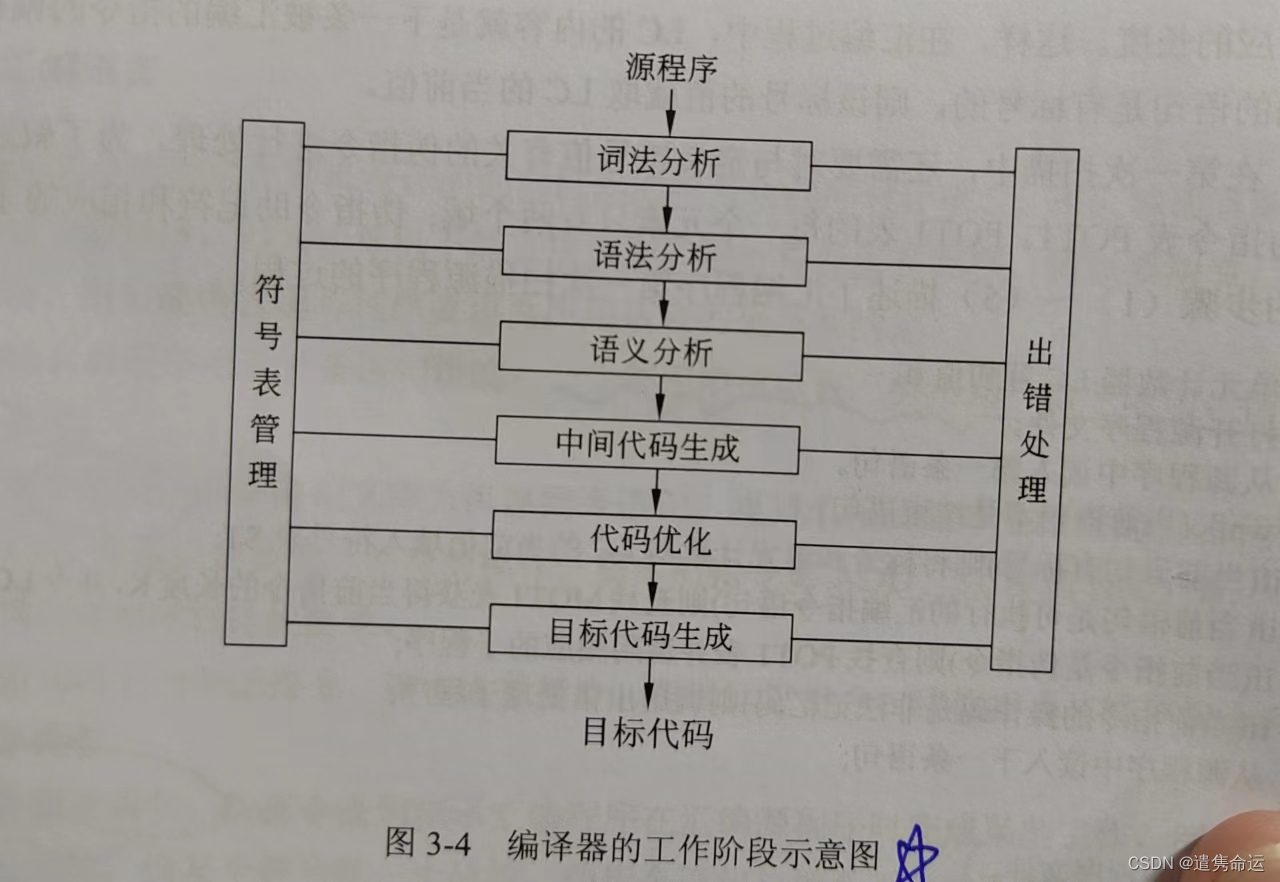
词法分析:
词法分析是编译过程的第一阶段,这个阶段的任务是对源程序从前到后(从左到右)逐个字符地扫描,从中识别出一个个“单词”符号。
语法分析:
语法分析的任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,如“表达式”“语句”“程序”等。语法规则就是各类语法单位的构成规则。通过语法分析确定整个输入串是否构成一个语法上正确的程序。
词法分析和语法分析本质上都是对源程序的结构进行分析。
语义分析:
语义分析阶段主要分析程序中各种语法结构的语义信息,包括检查源程序是否包含静态语义错误,并收集类型信息供后面的代码生成阶段使用。只有语法和语义都正确的源程序才能被翻译成正确的目标代码。
语义分析的一个主要工作是进行类型分析和检查。
中间代码生成:
工作是根据语义分析的输出生成中间代码。
代码优化:
优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段进行。
目标代码生成:
任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码。
符号表管理:
作用是记录源程序中各个符号的必要信息,以辅助语义的正确性检查和代码生成,在编译过程中需要对符号表进行快速有效地查找、插入、修改、删除等操作。
出错处理:
在编译时发现程序中的错误后,编译程序应采用适当的策略修复它们,使得分析过程继续下去,以便在一次编译过程中尽可能多地找出程序中的错误。
正规表达式和正规集:
| 正规式 | 正规集 |
|---|---|
| ab | 字符串ab构成的集合 |
| a|b | 字符串a、字符串b构成的集合 |
| 由0个或多个a构成的字符串集合 | |
| 所有由所有字符a和b构成的串的集合 | |
| a | 以a为首字符的a、b字符串的集合 |
| 以abb结尾的a、b字符串的集合 |
运算符的优先级是:“*”(闭包) > (连接) > "|"(或)。
若两个正规式表示的正规集相同,则认为二者等价。例如:b =
b,
=
。
有限自动机:
是一种识别装置的抽象概念,它能准确的识别正规集。分为确定的有限自动机、不确定的有限自动机。
确定的有限自动机和不确定的有限自动机的判断:
就是看关于该结点的路径相同数字是否到达不同的结点,如果相同数字不同结点就是不确定的有限自动机。
1,确定的有限自动机DFA:
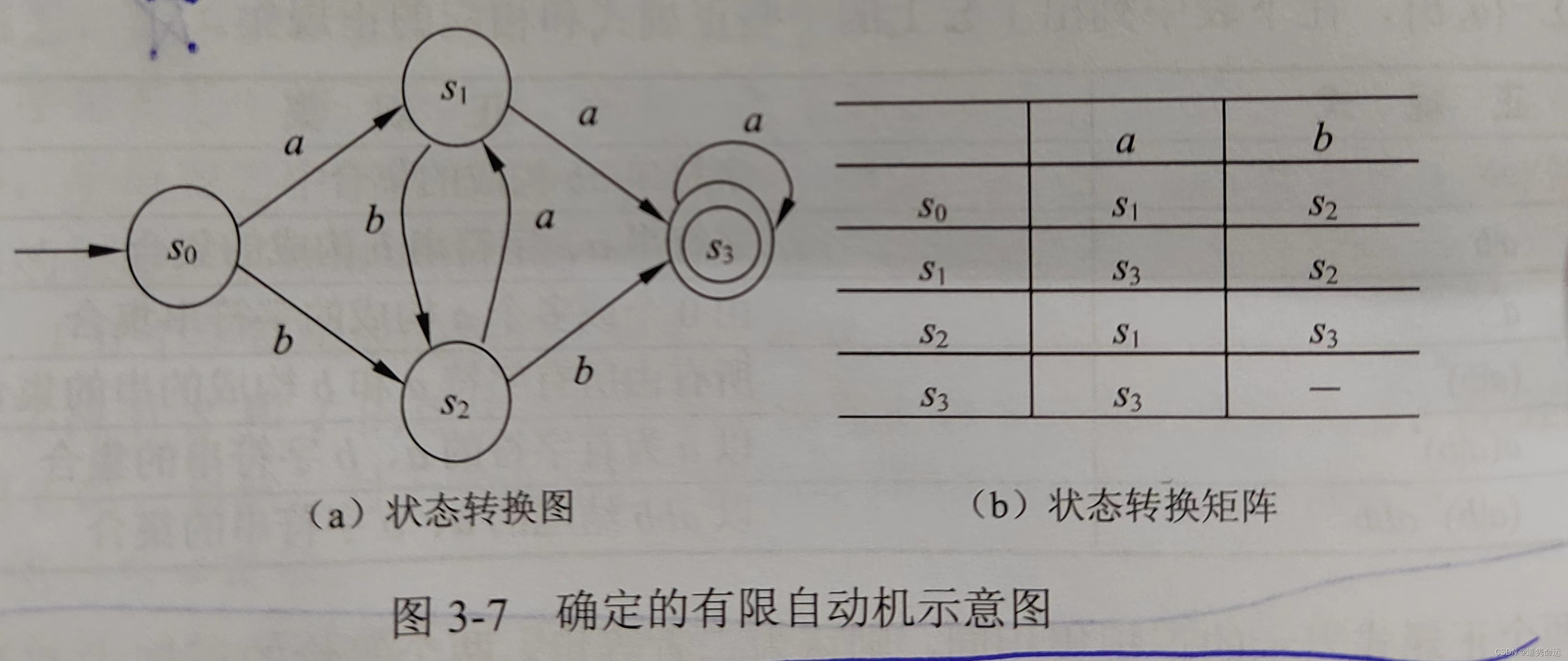
一个DFA可以用两个直观的方式表示:状态转换图、状态转换矩阵。
状态转换图是一个有向图,简称转换图。例如:(s0为初态、s3为终态)
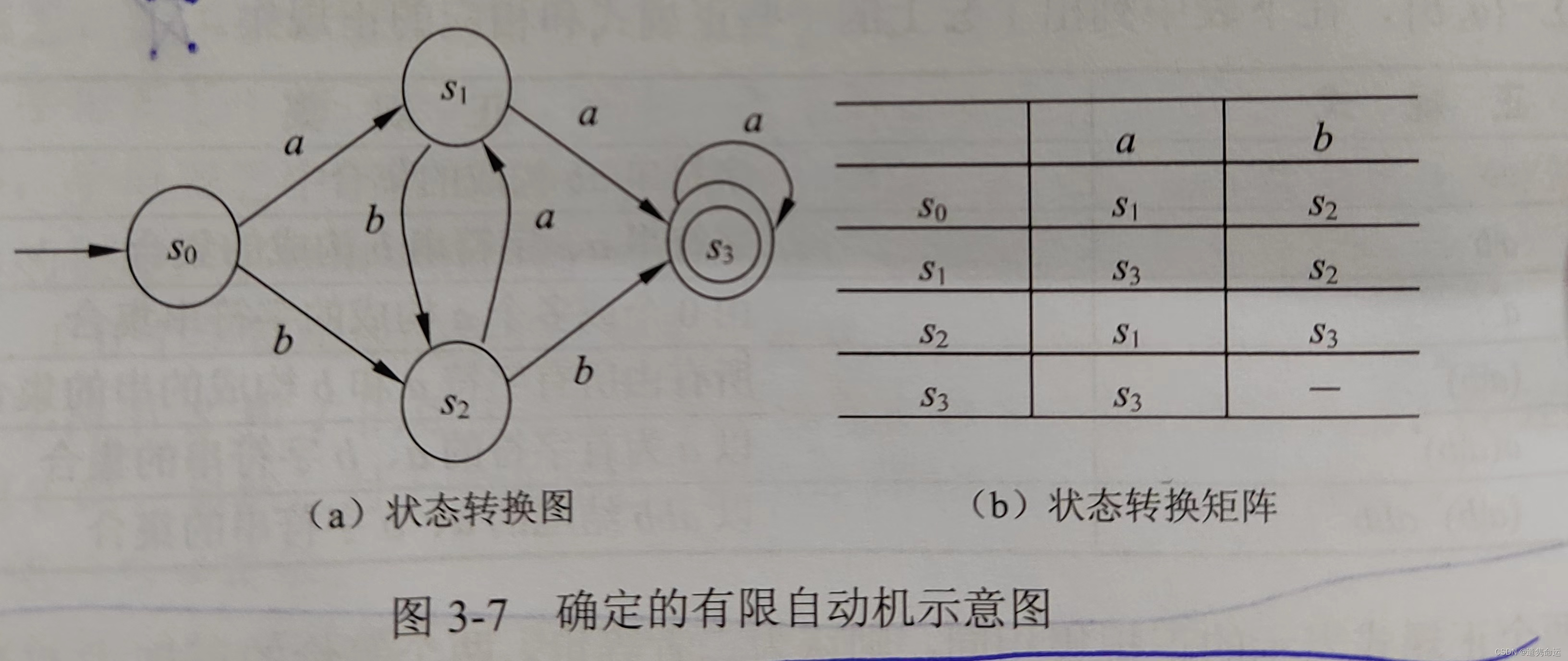
确定的有限自动机能识别的语言是能够从初态到终态的标记串。例如上图的aaa、aaaa是能够识别的有限自动机语言。
2,不确定的有限自动机NFA:
DFA是NFA的特例。
词法分析器的任务是把构成源程序的字节流翻译成单词符号序列。
手工构造词法分析器的方法是先用正规式描述语言规定的单词符号,然后构造相应有限自动机的状态转换图,最后依据状态转换图编写词法分析器(程序)。
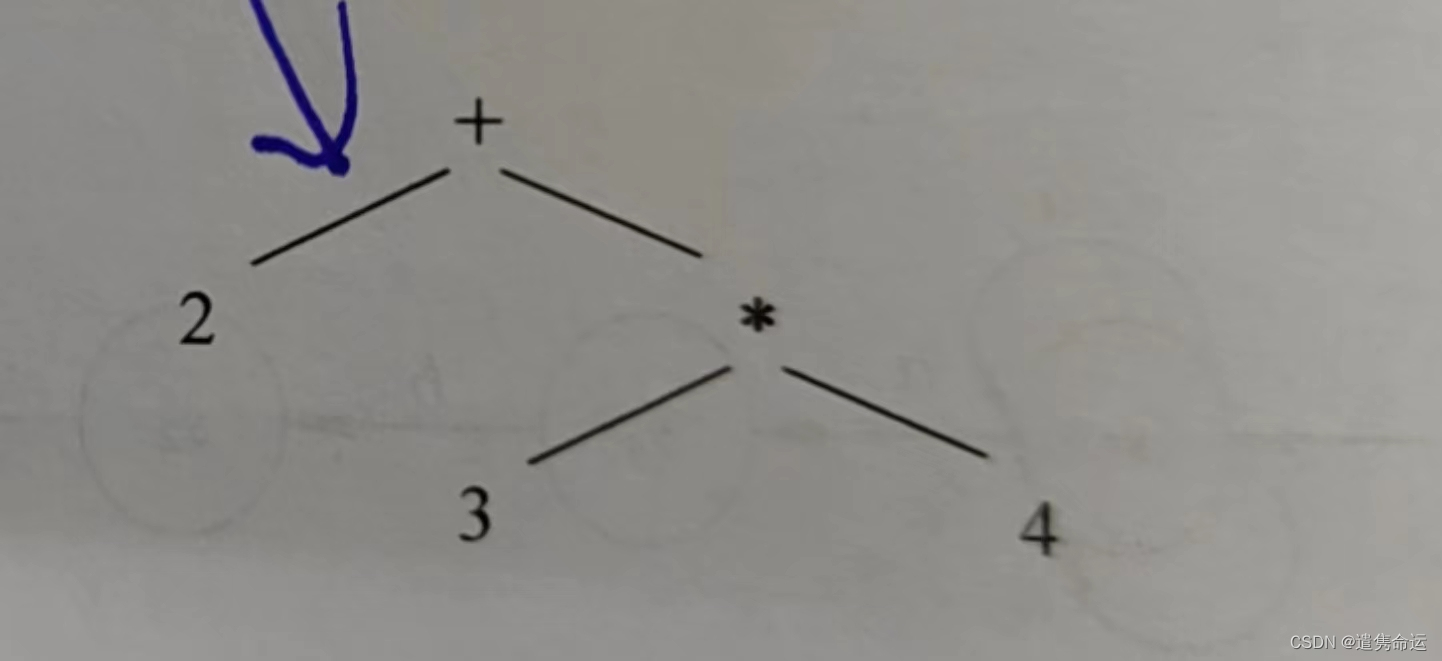
语法分析(语法树):
程序设计语言的语法常采用上下文无关文法描述。文法不仅规定了单词如何组成句子,而且刻画了句子的组成结构。形式文法是一个规则系统,它规定了单词在句子中的位置和顺序,也描述了句子的层次结构。
对于2+3*4的语法树是:
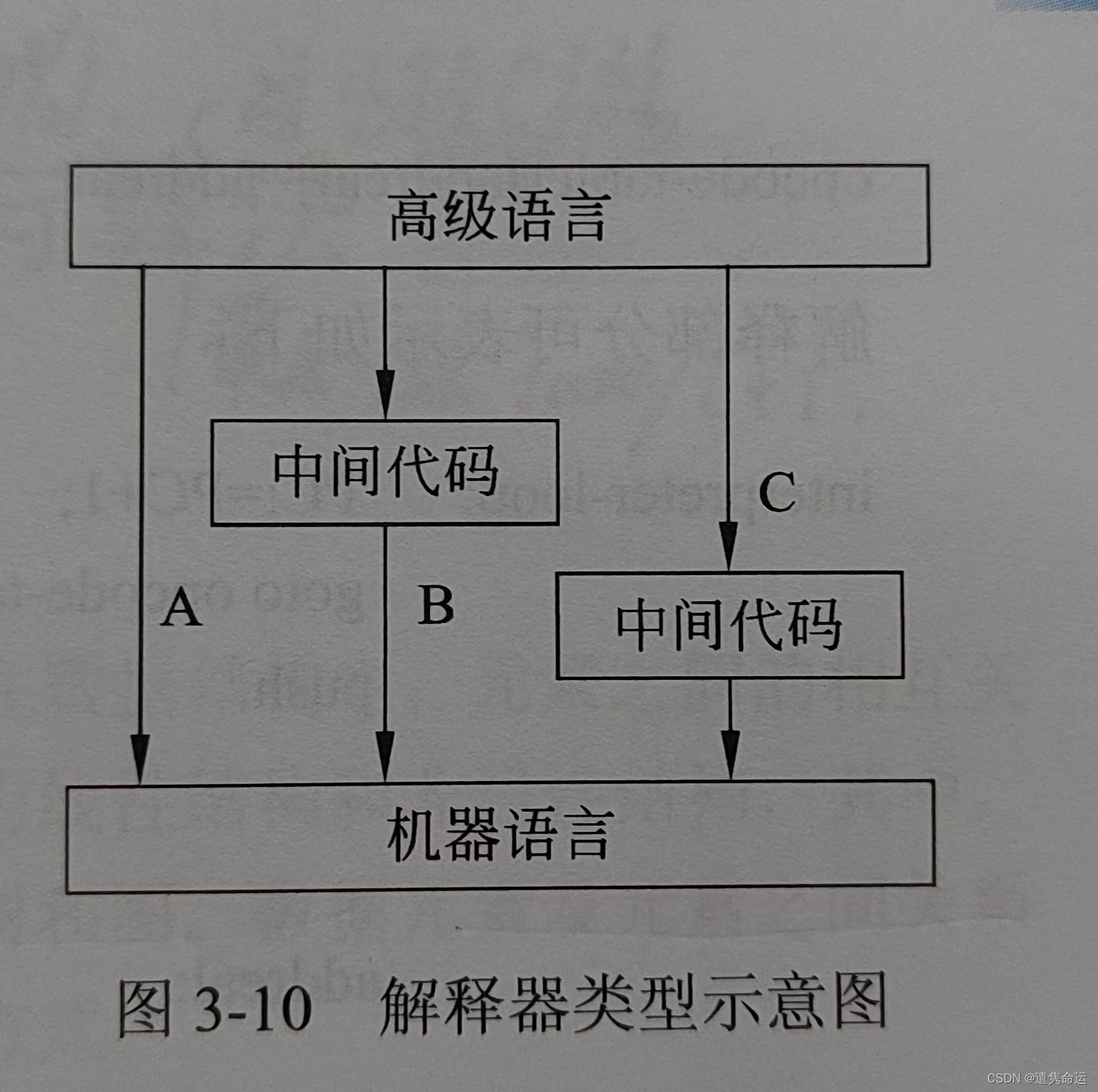
解释程序基础:
解释程序是另一种语言处理程序,它直接执行源程序或源程序的内部形式。
解释程序的系统一般分为两部分:
1,分析部分:包括与编译过程相同的词法分析、语法分析、语义分析程序,经语义分析后把源程序翻译成中间代码,中间代码常采用逆波兰表示形式。
2,解释部分:用来对第一部分产生的中间代码进行解释执行。
















 3001
3001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











